
基于数据挖掘技术的高校图书馆用户行为模式应用研究*
——以南京工业大学为例
2017-01-04 06:07:57吕丹丹
图书馆研究 2016年6期
吕 远,吕丹丹
(1.南京工业大学信息服务部,江苏南京211800;2.南京工业大学教学事务部,江苏南京211800)
基于数据挖掘技术的高校图书馆用户行为模式应用研究*
——以南京工业大学为例
吕 远1,吕丹丹2
(1.南京工业大学信息服务部,江苏南京211800;2.南京工业大学教学事务部,江苏南京211800)
数据挖掘技术在众多行业领域已得到广泛应用,图书馆行业也在积极探索利用大数据分析加强和提高自身业务和服务水平。基于数据挖掘算法和大数据分析,详细分析了大学生在校期间在图书馆的借阅行为模式,并得到了一系列模型结果。这些结果可为图书馆为师生提供有针对性的个性化服务提供相应的决策支持,加快图书馆服务方式由被动服务向以用户需求驱动的主动服务方式的转变。
数据挖掘;图书馆;数据清洗;关联分析;分类分析
“大数据”的概念最早由全球最有影响力的咨询公司麦肯锡提出,经过几十年的发展,大数据理论体系已相当完备,现已成功广泛应用于商业领域当中。
由于知识传播与利用形式不断变化,各种新技术机制在知识创造、组织、传播和应用中扮演着越来越重要的角色[1],使得传统的知识服务体系难以满足新形势下的各种新需求。当下的知识服务不局限于图书馆自身的基础服务体系,更包括结构化和非结构化的海量数据的深度分析、竞争力分析、创新力分析、预测性分析等高附加值服务,为服务用户提供有价值的决策支持和智慧服务。
笔者基于大数据技术充分挖掘学生在校期间在图书馆的借阅行为模式,得到了一系列结论模型。这些结果可以为图书馆提供更加量化的数据支撑和决策支持,实现图书馆知识服务模式和管理方式的转变。
1 数据仓库与数据挖掘技术介绍
1.1 数据仓库
数据仓库(Data Warehouse)一词首先由IBM公司研究员Barry Devlin和Paul Murphy于1988年提出,目的为解决企业的集成问题。1992年,目前公认的数据仓库之父Bill Inmon对数据仓库做了如下定义:数据仓库就是面向主题的、集成的、稳定的、不同时间的数据集合,用以支持经营管理中的决策制订过程[2]。自此,整个社会真正拉开了数据仓库得以大规模应用的序幕。数据仓库的构架如图1所示。
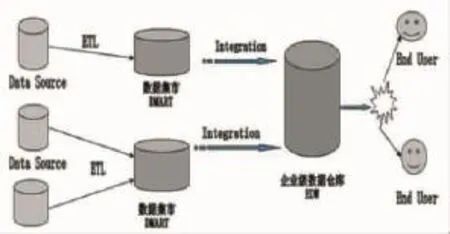
图1 数据仓库构架图
1.2 数据挖掘
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
数据挖掘技术可以分为预言(Predication)和描述(Description)两大类。具体包括关联分析、序列模式、分类、聚集、异常检测等技术,它们分别从不同的角度对数据进行挖掘。下面简单介绍本文中用到的数据挖掘技术:
(1)关联分析。关联分析作为一种无监督机器学习方法(Unsupervised Learning),是数据挖掘中最常用的方法之一。它的核心在于发现存在于大量数据集中的关联性或相关性,从而揭示出一个事物中某些属性同时出现的规律和模式。关联分析的严格定义如下[3]:
令为一个文字符组成的集合,每个文字符号代表一个项目,由一个或一个以上的项目组成的集合称为项目集。令数据库D是由一群交易T所组成的集合,每个T为一个项目集,代表交易记录,TI,每个交易记录有一个唯一的编码,称为TID。如果Xl且XT,则定义T包含X。以图书馆的应用来看,每一本书就是一个交易项目,一个读者在一段时间内来图书馆借阅馆藏图书的集合就是一笔交易。
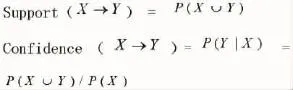
关联规则挖掘最终希望找出数据库D中所有支持度和置信度大于最小支持度和最小置信度的规则,其中最小支持度与最小置信度的阈值可由使用者设定。
(2)分类分析。分类分析是一种有监督机器学习方法(Supervised Learning)。它通过对已知类别训练集的分析,为每个类别建立分类分析模型,然后用这个分类分析模型对数据库中的其他记录进行分类,以此预测新数据的类别,描述重要数据类的特征或预测未来的数据趋势。
分类分析的输入集是一组记录集合和几种类别的标记。每一条记录包含若干条属性(attribute),组成一个特征向量。训练集的每条记录还有一个特定的类标签(类标签)与之对应。该类标签是系统的输入,通常是以往的一些经验数据。一个具体样本的形式可为样本向量在这里Vi表示字段值,C表示类别。常用的分类算法有决策树算法、贝叶斯网络、神经网络算法、遗传算法等。
2 图书馆读者行为模式数据挖掘
2.1 确立数据挖掘的主题和目标
本文以南京工业大学2012级本科生为研究对象,分两个维度分别对读者在图书馆的借阅行为进行数据挖掘:分析四年期间(2012~2016年)读者在图书馆的使用情况;运用关联分析算法和分类算法对读者的行为模式进行进一步挖掘。
2.2 建立数据仓库
南京工业大学图书馆的汇文管理系统是基于Oracle(以下简称SQL)数据库系统,其中有很多数据表。本研究需要从其历史借阅记录表、图书MARC表、读者基本信息表、读者证件表中利用SQL语句导出需要的属性列,并且经过进一步的清洗、合并、整理、格式转换,以备使用。
原始读者表中有846 845条数据,MARC表中604 896条数据,证件表中140 093条数据,借阅表中有625 473条数据。借助于VBA程序和SQL语句,进行以下数据清洗操作:将研究对象限定为2012年至2016年在校本科生;将借阅时间限定在2012年9月1日之后;为便于以时间特性为指标进行数据挖掘,将借阅时间拆分为年、月、日、分、周5个属性列;由于原始数据中学院属性列的值非常不统一,有的是专业名,有的是班级名,因此需对学院属性列进行重新填充值;为便于以图书类别为指标进行数据挖掘,将索书号拆分为大类(索书号首位)和小类(索书号前两位)两个部分;为后续关联分析方便,将读者7天之内的借阅行为视为一次“购物篮”行为,即认为读者在这7天之内的借阅行为具有连续性,并且在借阅记录表中增加最常用索书号小类属性列(共183个图书小类,选取出现频率大于100以上的小类,共76个);对脏数据做进一步清洗整理,包括空值、空格、重复记录、特殊字符等。
之后,将数据导出至Navicat和Spss中,得到下面三类数据:馆藏图书表bookinfo(共计520 131条数据);借阅记录表lendhist(共计165 287条数据);读者基本信息表readerinfo(共计6 318条数据)。
2.3 数据挖掘并分析结果
基于之前建立的数据仓库,利用Spss和Clementine软件[4-5],分别从两个维度对图书馆读者的行为习惯进行挖掘,并找出相关数据之间的联系。
2.3.1 图书馆使用情况数据分析
根据读者的特性,分别以性别、学院、年级为指标,借助于直方图或饼状图进行大方向的分析,了解读者行为上的大致趋势,并且可以根据需要加上图书大类和小类的指标,对不同专业读者、学院的借阅喜好做进一步的分析。
数据显示,男生更偏向借阅的前三类图书依次为T、O、I,女生则更偏向借阅I、T、O。根据中图法,T代表工业技术类图书、O代表数理科学和化学类、I代表文学类。这说明女生更偏向借阅一些文艺类图书,而男生则对理工科图书更感兴趣,图书馆在采购相关图书的时候可以在这几大类图书上适当倾斜。
各年借阅量数据显示,2013年图书借阅量最大,而这一年正好是大一下学期到大二上学期这一段时间,2016年最少,也就是大四下学期这段时间。针对大一上学期、大二下学期和大三的同学,图书馆可多组织一些推广活动,采取积极有效的措施吸引他们前来借阅,增加这一类用户群的使用黏度。
分别以月、周、小时为时间指标进行分析,可以看出,读者在3月和9月借阅量最大,这跟刚刚开学有关。另外,临近考试周期间借阅量也有较大增长。一周之内,前三天的借阅量最大,占到一周总借阅量的几乎一半的比例。而在一天的时间段里,20点、17点、16点这三个时间段借阅量最大。图书馆可以根据这些数据,合理调配人员,优化资源配置,降低人力成本。
各个学院由于专业不同,对各个图书大类的需求存在很大差别,如建筑学院对T类图书需求最大,外语学院对H类图书需求最大,法学院对D类图书需求最大。另外学生从大一到大四,对O类图书的需求逐渐减少,而对T类图书的需求则逐渐增多。从月份和图书大类关系可以看出T类图书三月份需求最大,而八月份所有图书的需求量都是最小的。图书馆可以根据这些挖掘出的信息对不同学院不同专业的学生和老师提供个性化服务,提高学生自主学习的学习效率。
2.3.2 读者行为模式分析
基于之前建立的数据仓库,运用分类算法和关联分析算法,挖掘数据中隐藏的信息,这些信息有些是明显的,但更多则是很容易被决策者忽略的现象,这些现象可为决策者提供重要的参考依据。笔者利用的分析工具是Spss Modeler(Clementine)。
(1)分类分析。决策树算法是分类分析算法中的一种,数据流如图2所示。笔者将利用该算法对性别、大类和月份之间的关系进行挖掘。将借阅历史记录导入Spss Modeler中之后,在建模选项卡下选择C5.0(即C&R Tree)模型建模,[Fields]中输入[Target]为[大类],[Inputs]为[月份]、[性别],执行后如图3所示(Viewer显示):
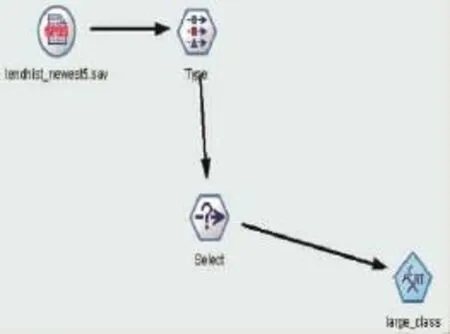
图2 决策树算法数据流图示

图3 决策树图示
可以看出男生在图书馆更倾向于借阅T类图书,而女生的借阅行为在不同月份有明显差别,在暑假刚开学的一个月和学年的下学期期间更倾向于借阅I类图书,其他时间段则更可能借阅T类图书。这可能与刚开学期间没有考试压力,学生有时间借阅课外书以扩充知识面有关。
(2)关联分析。关联分析数据流如4图示。笔者利用Apriori关联分析算法对读者借阅的图书小类进行分析,找出与读者借阅图书关联最紧密的图书小类。通过这样的挖掘,可以实现图书的自动化推荐,也可以找出读者对图书类别喜好的倾向。
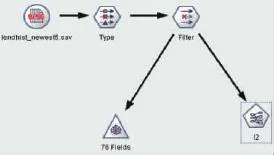
图4 关联分析数据流图示
首先从Spss导入借阅图书历史数据,然后在Spss Modeler中建立相关模型。在Type节点中设置角色时,可不必设置目标字段,只需在“Apriori建模”节点设置“后项”即可。另外需在过滤节点中将与关联分析关系不大的字段过滤掉,如id、 cert_id、dept、location等字段。为在建模节点中设置后项字段时更具针对性,有必要再添加一个网络节点,提前直观地了解一下不同图书小类之间关联程度。
执行网络节点,得到结果如图5所示:
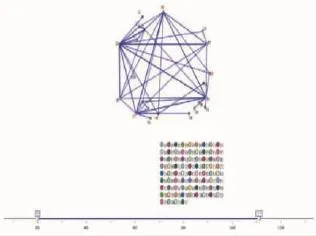
图5 关联分析执行结果之Web网状图示
在图5中,线的粗细和颜色的深浅代表联系的强弱,可以明显地看到I2与I5、I2与B8、I2与H3有着非常强的关联。
在建模选项卡下选择“Apriori模型”节点,添加到数据流中。
设置该模型的最低条件支持度为5%,最小规则置信度为10%,执行结果如图6所示:
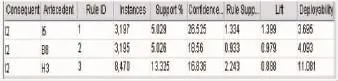
图6 关联分析执行结果图示1
设置该模型的最低条件支持度为5%,最小规则置信度为17%,执行结果如图7所示:

图7 关联分析执行结果图示2
设置该模型的最低条件支持度为5%,最小规则置信度为25%,执行结果如图8所示:

图8 关联分析执行结果图示3
根据中图法,I2代表中国文学类,H3代表常用外国语类,I5代表各国文学,B8代表思维科学、逻辑学和美学。由上面执行结果可以看出,在借阅了I2类别图书的情况下,会有26.525%的读者借阅I5类图书,18.56%的读者借阅B8类图书,16.836%的读者借阅H3类图书。这几个类别的图书都偏向于文科类图书。同样的过程,还可以分析其他类别图书的关联性,例如TP类别等。
2.4 应用知识
以上数据挖掘的结论可以作为图书馆开展服务的一个依据,在借书率较高的时间段,按需分配较多的人力资源,以缓解高峰借阅时间的人力不足,在借书率较低的时间段,可以适当减少值班人员,节约人力成本。
另外,在图书馆馆藏布局方面,可将关联度比较高的图书大类排在一起,提升用户体验度,增加图书的流通效率。
图书馆还可以依据以上分析结果,对不同专业、不同年级和不同学院的学生提供个性化服务,为他们推荐最相关的图书;并且针对借阅量较低的年级和学院,可适当多开展一些推广服务,一方面增加图书馆的服务品质,同时可以增加用户对图书馆的使用黏度。
3 总结和进一步思考
对读者在图书馆的行为模式进行数据挖掘的过程中,还有一些需要改进和注意的地方:
(1)本课题基于读者的借阅历史记录、读者个人信息、MARC信息建立的数据仓库,实际上还有一部分用户对图书馆的使用仅仅是查询文献信息,可能并没有真正借阅书籍。因此为更精确地获取读者行为模式,还应加入读者在图书馆各个阅览室(包括电子和期刊阅览室)的登记信息、OPAC系统的查询日志记录等。
(2)由于高校学生对互联网依赖度较高,图书馆主页是大部分用户对图书馆资源使用的第一入口,因此可通过对图书馆主页服务器的日志和各个栏目下的点击量进行数据分析,获取用户对图书馆电子资源的使用情况。
(3)本课题数据仓库建立的过程较为曲折,很大程度上是由于汇文管理系统的限制和图书馆新生信息录入时操作不规范造成,包括从汇文导出海量数据时出现的各种bug、新生基本信息中学院信息的缺失等,这些问题需要人工处理,工作量较大,同时也带来了一定的数据误差。
毫无疑问,数据挖掘技术在未来的时间必然是图书情报领域应用的主流技术之一,为图书馆知识服务方式的转变提供了新的思路,更是向数字化云图书馆转变的一个强力助推器。尽管其也存在着一些亟待解决的问题,但随着市场和信息技术的发展进步,这些争议和难题都将得到清晰的解决方案。大数据技术在图书情报界的应用发展还需要业界人员的共同努力。
[1]张晓林.研究图书馆2020:嵌入式协作化知识实验室[J].中国图书馆学报,2012(1):11-20.
[2]INMON W H.Building the Data Warehouse,3rd Edition[M]. Indianapolis:John Wiley&Sons,Inc,2002.
[3]AGRAWAL R,IMIELINSKI T,SWAMI A.Mining association rules between sets of items in large databases[J].Acm Sigmod Record,1993(2):207-216.
[4]萧文龙.实战SPSS统计学[M].北京:中国水利水电出版社,2015.
[5]王国平,郭伟宸,汪若君.IBM SPSS Modeler数据与文本挖掘实战[M].北京:清华大学出版社,2014.
(编发:王域铖)
Research and Application of University Library User’s Behavior Model Based on the Data Mining Techniques:A Case Study of Nanjing Tech University Library
LV Yuan1,LV Dan-dan2
(1.Dept.of Information Service,Nanjing Tech University,Nanjing 211800,China; 2.Dept.of Teaching Affairs,Nanjing Tech University,Nanjing 211800,China)
Data mining techniques are widely used in many industry areas and the library industry also actively explores the application of big data analyses to strengthen its own business.Based on the data mining techniques,this paper analyzes the behavior model of undergraduate students during the four years in the library and makes a series of results.These conclusions can offer corresponding knowledge and decision supporting for library to provide personalized service to teachers and students,and accelerate the transformation from passive service mode to user needs driven active service mode.
data mining;library;data cleaning;relational analysis;classification analysis
G250
G250
2095-5197(2016)06-0108-05
吕远(1988-),男,助理馆员,硕士,研究方向:web开发、大数据技术;吕丹丹(1985-),女,助理研究员,硕士,研究方向:教育信息化、数据库。
2016-10-21
*本文系南京工业大学图书馆研究基金项目(项目编号:NJTECHLIB201508)、南京工业大学宣传部党建与思想政治教育课题项目(项目编号:SZ20160316)成果。
猜你喜欢
大众投资指南(2021年35期)2021-02-16 01:06:26
自然资源信息化(2019年4期)2019-03-29 03:20:48
新闻传播(2018年2期)2018-12-07 00:56:02
电力与能源(2017年6期)2017-05-14 06:19:37
电子制作(2016年15期)2017-01-15 13:39:15
山东工业技术(2016年15期)2016-12-01 05:31:24
信息通信技术(2015年6期)2015-12-26 01:16:46
中国教育信息化(2015年10期)2015-08-23 11:43:42
新闻传播(2015年4期)2015-07-18 11:11:31
新闻传播(2015年12期)2015-07-18 11:02:41
