
基于在线评级和评论的评价者效用机制研究
2016-12-28 02:05:22施晓菁孙晓蕾
中国管理科学 2016年5期
施晓菁,梁 循,孙晓蕾
(1.中国人民大学信息学院,北京 100872;2.中科院科技政策与管理科学研究所 100190)
基于在线评级和评论的评价者效用机制研究
施晓菁1,梁 循1,孙晓蕾2
(1.中国人民大学信息学院,北京 100872;2.中科院科技政策与管理科学研究所 100190)
互联网中对产品和服务的评价越来越受到重视,因为评价能够消除消费者的不确定性,辅助其做出购买决策。大多数在线购物网站中用户的评价包括评级和评论。现有的评价反馈系统和评价研究往往只单独关注评价者之间的评级或评论,而忽略了两者之间的有机统一。评价者的评级并不一定反映评价者的真实评价,很多评价者更倾向于选择评论文本来表达自己的真实情感。本文以从淘宝网抓取的852071条评价数据为基础,通过分析评价者评级和评论之间的不一致性,结合RFM模型,考虑评级和评论两种信息形成的评价效用,提出了RFMA模型来计算评价者的总体评价效用。并据此对好的与不好的评价者进行区分,进一步为消费者的购买决策提供支持。通过对评价者的总体分析可以得出,本文提出的机制更加具有可用性和有效性。
评级和评论的不一致性;评价;评价者;RFMA
1 引言
在线交易机制和环境使得消费者对产品和服务掌握的信息不充分,因为消费者在购买产品前不能看见或使用它。但是若消费者信任该服务提供商,那么即使他事先未看见或未使用商品,他也会做出购买决策。当用户需要做出是否与某个服务提供商进行交互的决定时,往往非常在意商家的信誉[1]。而判断某个实体是否值得信任是非常困难的,因为在线交流媒体使得我们远离了原先熟悉的交互方式[2]。因此,大部分在线购物网站为消费者提供了评价(在本文中,评价是包括评级与评论的整体)反馈机制,消费者在购买商品后能以评级和评论的形式进行评价。由于评级往往以数字等级的形式展示,这些购物网站可以方便地将消费者的评级集合起来,提供商品总体评分的信息,帮助消费者直观地了解评价者对商品的总体评价。但是出于种种原因,人们的评级往往不能真实地反映他们的倾向,且评级所包含的信息太过单一,评论文本信息逐渐成为了人们决策的重要参考。很多消费者通过查看评论文本来了解商品的好坏。研究表明,在线商品评论显著地影响着消费者的购买决策和B2C电子商务网站的产品销售[3]。评论使得消费者能够集合社区中集体智慧来帮助自己做出购买商品和服务的决策[4]。一方面,在线消费者常常通过衡量他人对某件商品的评论来制定自己的购买决策;另一方面,商品制造商可以从在线商品评论中获得启发,从而支持广泛的管理活动,如品牌塑造、客户关系管理、产品研发以及质量管理[5]。不论买家还是卖家,作为在线商品评论的读者都希望从中获得有助于制定决策的信息。
很多用户在各种社交媒体上发表和共享大量的评论,为消费者提供了丰富的决策参考信息。但这也带来了很大的问题:面对海量评论,评论阅读者可能迷失其中,无法有效识别和利用其中有价值的信息来判断商品的真实质量[6]。另外,虽然在线评论的文本内容十分丰富,可为人们提供海量的信息资源,但并非所有评论都有价值,其中包括许多随意或虚假的评论。由于网络的匿名性、非面对面地接触、沟通成本低廉等特征[7],评论的质量往往参差不齐。评论的海量性及其质量的不确定性,使得消费者不容易从中获得所需的信息,干扰了消费者对商品质量的判断,从而影响了消费决策。
因此,及时有效地识别在线评论文本中有价值的信息对提高消费者的决策效率和效果至关重要。针对这一点,许多B2C 电子商务网站,如淘宝、亚马逊、京东商城等,提供在线商品评论的效用评价功能——依据每条评论获得的“有用”投票数占总投票数的比例对商品评论进行排序,获得支持票数越多的评论,其排名越靠前[8],通过这样的手段来帮助评论阅读者识别评论的价值。但是该指标需要长时间累积,无法及时提供最新发布的评论的有用性信息,应用效果有待衡量[9]。这是因为人们往往只对前几条评论进行浏览,已经置顶的评论更加有机会被浏览而被重复投票,而一些新发布的高品质的评论则因为没有及时获得足够的有用投票而被忽略。
评级信息的单一性,使得由此设计的商品总体评分制度不能准确反映评价者的观点。评论信息的复杂性与主观性,使得潜在消费者难以直接从中快速获得有用的观点。通过前期研究发现,评价者对某件商品给出的评级与评论经常存在相反或不一致的现象,如评价者给出的评级为好评,评论内容却是“质量不怎么样,习惯性好评”。为解决当前B2C 电子商务网站对在线商品评论的效用评价的局限性,学术界提出了一系列基于文本挖掘和信息质量评价理论的解决方案。但是很少有研究关注到评级信息与评论信息的不一致性,也几乎没有研究考虑将其进行有机统一,对整体评价进行效用分析。另外,评价者本身是否为一个好的评价者,对于潜在消费者是否决定采纳这条评价有着重要的影响。如何判别评价者的评价效用,也是评价研究中十分重要的一个方向。
针对这些问题,在本文的研究中,我们设计并提出了一种评价效用衡量机制,通过引入营销领域的RFM模型,以评价者的评级和评论信息作为评价效用(A)这一新指标,提出RFMA模型来对评价者本身的评价能力进行分析,从而对评价者进行分类,从中找出好的评价者。蔡淑琴[10]等已将RFM模型引入到对意见领袖的识别中,并添加了情感(S)这一新指标。但是仅以情感值的大小作为新指标进行输入,而未区分情感的正负向以及进一步考虑情感在其中所起的作用。本文引入评论情感的正负向来对评价者的评级和评论的不一致性进行衡量,并将这种不一致体现在对评价者的效用衡量上,充分使用了评级和评论信息。
以下是本文的三个主要研究问题:
(1)如何衡量评级和评论之间的不一致性。评级和评论之间的不一致性会造成混乱,因此衡量其不一致性在本文提出的机制中有着重要作用。我们使用了文本情感分析的方法对评论的情感倾向进行衡量,并与评级进行比较。
(2) 如何衡量单次评价的效用。购物之后的评价反馈包括数字的评级和文本的评论。为了充分利用评论包含的信息,本文使用PageRank方法衡量评级的效用,并使用基于LDA主题模型的相似度方法衡量评论的效用,提出了将两种信息相结合的评价效用衡量机制,同时还给出了可信度。
(3)如何衡量评价者的评价能力与评价效用并区分好与不好的评价者。根据新提出的RFMA模型,综合得到评价者的总体评价效用。通过模型分类与人工分类的比较,衡量本文提出的机制对评价者评价能力的分类效果。
2 模型和方法
在线购物网站已经成为人们购物不可或缺的平台。但是,信息不对称和信誉问题导致用户不能放心地在网上进行购物。现有的评论效用研究往往只单独考虑评论本身,而忽略了评级与评论的有机统一。如何将用户的两种评价信息统一到衡量体系中,是一个重要的研究方向。在本节中,我们提出一种新的集成RFM模型并结合评级和评论两种信息的评价者评价效用衡量机制(RFMA),为用户的购买决策提供重要支持。
2.1 RFM测量
RFM模型是客户关系管理领域中一种定量分析模型,其基本思想是通过三个客户行为指标来判断客户价值,即近度(Recency)、频度(Frequency)和值度(Monentary)。近度表示客户最近一次交易离现在的时间间隔,频度表示客户在一定时期交易的次数,值度表示客户在一定时期内交易的总金额。近度值越低,频度值越高,值度值越高,则客户的价值也越高。
本文将RFM模型用于测量在线评价者的评价能力,需要对三个指标的含义进行修正。其中R、F指标可以直接进行类比。M指标原本为客户在一定时期内交易的总金额,但是评价对其他人影响的购买金额无法准确统计。蔡淑琴[10]等使用其他用户对在线口碑做出的有用性判断作为指标M。本文作者在对实际在线购物网站进行观察后发现,大部分的评价者并不使用该功能,且该功能需要长时间进行累积,不具有可用性。而对于评价者,其发布评论的本身特征才是用于衡量评价者评价能力的合理指标。因此,本文对这三个指标修正如下:(1) 近度(R)表示评价者三个月内最近一次发布评价到当前的时间间隔,以天为时间单位。(2) 频度(F)定义为评价者在最近三个月内进行评价(有评论内容)的次数。(3) 值度(M)则表示评价者发表的评论的长度平均值,以字数为单位。
由于R、F、M三个指标的度量单位和取值存在较大差异,且影响方向并不相同,所以需要对原始数据进行标准化处理。R′、F′、M′分别表示标准化后的R、F、M,计算公式如下式(1):
(1)
其中Rmin和Rmin分别表示R的最大值与最小值,Fmax和Fmin分别表示F的最大值与最小值,Mmax和Mmin分别表示M的最大值与最小值。
2.2 评级和评论的比较
从用户的生成内容中可以分析用户的情感倾向,从而获得对其他用户有用的参考信息。为了确定用户发布内容的倾向性,一些情感分析的方法已经被提出,其中大部分是基于文本分析的[11]。因此,为了探究评价者在评级和评论上的不一致性,本文对评论文本进行短文本情感倾向分析。将评论的情感倾向转化为可量化的数字,从而与评级的好(1)、中(0)、差评(-1)进行比较。本文采用的是基于Shen Yang等[12]提出的MBEWC方法进行改进的计算方法。以HowNet[13]情感词典为基础,对文本进行分句、分词、标注、情感处理等后,通过词语的语义相似度计算,综合计算短文本的情感倾向。
本文使用HowNet语义相似度计算软件及其提供的情感和评价词汇构建模糊情感本体库,得到正负向两个情感词典。每个词汇对正负向情感词典有不同的隶属度。在这里选取隶属度大的那个情感类作为该词的情感类,隶属度最大值就是这个词的情感强度。若出现隶属度相同的情况,则将该词判断为中性词。
在中文中,程度副词经常与情感词一起出现从而改变了情感词的情感强烈程度。为了更好地分析评论本文中的情感强度,我们设定了一个程度副词词典(Degree words dictionary),从HowNet中抽取58个程度副词并将其分成7类。我们在情感词的上下文中设置一个大小为5的检测窗口,如果在检测窗口中有程度副词出现,则按照表1中所给的赋值相应改变情感词的情感强度。

表1 程度副词
否定词的出现往往会改变情感词倾向性。同样从HowNet中人工抽取10个否定副词建立否定副词词典(Negative Words Dictionary)。在情感词上下文设置了一个大小为5的检测窗口,若在检测窗口内出现否定词,就对词的情感值取反。
综合上述规则,每条评论的情感值计算如式(2):
(2)
其中,Sensibility(wk)表示词汇的情感值(即情感类的隶属度);l表示否定副词的个数;valueadv表示程度副词的取值。
最终每条评论都能得到一个数值的情感值。为了能更好地与评级进行比较,我们对评论的情感值做一个处理,将情感值大于0的评论归为好评,情感值小于0的归为差评,而情感值等于0的归为中评。
2.3 评级的效用衡量
评级是评价者最基本的评价信息,目前大多数在线购物网站都使用评级信息来进行商品总体评分计算。不同于简单的加和计算,为了衡量评价者的评级质量,我们使用的方法来源于Brin[14]等提出的用于部分搜索引擎的PageRank算法。本节使用的方法基于这样的假设:商品的质量可以由多数原则来衡量。即若一件商品的大多数评级都为好评,那么我们有理由相信这件商品的质量较好;若针对某一商品的大多数评级为差评,那么这件商品很有可能质量很差。
由于评价者的评级是用数字表示的好、中、差评三种类别,通过针对一个商品的所有评级的频率分布来计算每个独立评级的质量。根据评价者对同一商品给出的评级将其分组,组内的评价者被认为相互给出最大的支持。组间的支持则由每个评级的不一致性来界定。那么,评级i的质量可被定义为QRi,是由所有组对其支持的总和来决定的,具体公式如式(3)所示:
(3)
其中,QRj是评级j的质量;Ej,i是评级j对评级i的支持;Ni和Nj分别是给出评级i和评级j的评论者数量。某个组对其他组及其本身的支持度总和为1。所有QRi的总和也为1。
另外,QRi的置信度由评级的数量Ni(即对某个商品的某类评级总数)决定。基于Chen[15]等所使用的来源于Breslow[16]等提出的统计指数,如表2所示的分段函数将用于计算QRi的置信度CRi。
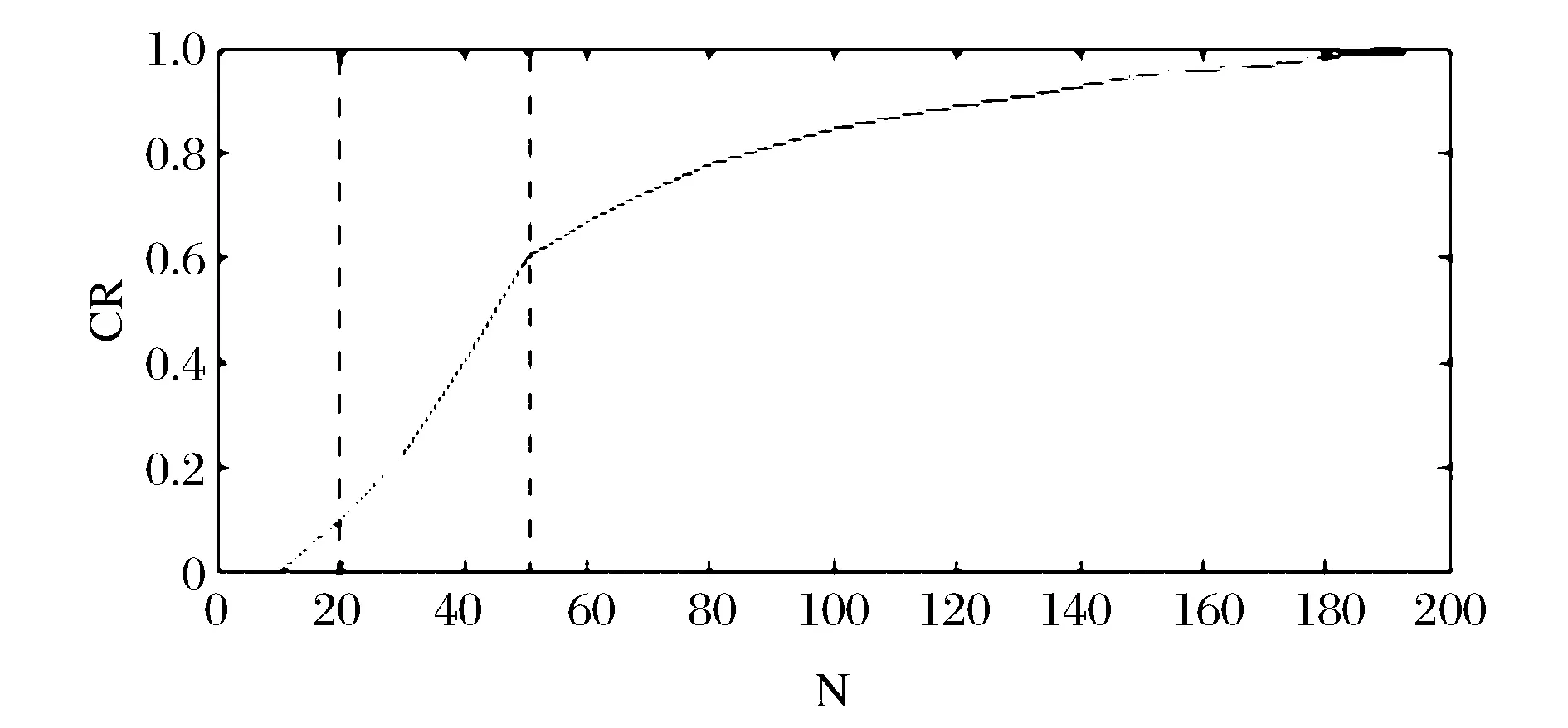
图2 CR分段函数
2.4 评论的效用衡量
除了以数字表示的评级,评价者的评论文本其实包含了更多的信息。我们可以看出评论者满意或是不满意的原因等评级无法表达的信息。因此,如何计算评论的效用,是本文研究的一个重点。Hu Nan等[17]认为蕴含较强极性和个人观点的商品评论可能并不可靠。我们认为,能够反映大多数其他消费者观点的评论才有可能是一篇好的评论。郝媛媛[6]等提出,评论内容的正负向情感混杂度对评论有用性存在显著正向影响,且评论中观点句的主观与客观表达形式的混杂度也对评论有用性存在显著正向影响。淘宝网在每个商品评价页面给出了商品评价的总体标签,包括商品的客观属性和主观评价结果,并且包含了正负向两种情感倾向,因此我们以淘宝网自身评价页面的标签作为标准评论,计算评价者评论与其相似度,以此作为评价者评论的效用。
由于文档的主题分布是文档向量空间的单纯形映射,所以在文档的主题表示情况下,计算两条评论的相似度可以通过计算与之对应的主题概率分布来实现。由于主题是词向量的混合分布,因而使用KL (Kullback-Leibler)距离作为相似度度量标准。公式如(4):
(4)
其中p和q分别为两条评论的主题概率分布。但是由于KL距离非对称,使用变化后的JS (Jensen-Shannon) 距离进行衡量,公式如(5):
(5)
那么第l条评论的质量QCl由公式(6)来衡量。其中pl是第l条评论的主题概率分布,而s是标准评论的主题概率分布:
QCl=DJS(pl,s)
(6)
以每个评价者在每个商品所属品类下的评论个数比上其所有评论个数作为评论的置信度CC。
2.5 评价效用指标A测量
在分别得到评级和评论的效用和置信度后,我们对单次评价的效用进行衡量。在衡量单次评价的总体效用时,我们基于这样的两个假设:大多数人的评价是可信的;个人的评论与评级相一致才有可能是好的评价。当评级与评论情感倾向不一致时,即使评论本身的效用很高,我们也认为这次评价不是一个好的评价,因为网站只使用评级对商品进行总体计分,而虚高的总分会使评论阅读者产生混乱。评价的总价值AQ可由如下公式(7)得出。
(7)
消费者在在线购物网站中购买很多商品,并做出评价反馈,累积了很多历史评价信息。将评价者的历史评价效用AQ进行累加并计算均值得到指标A,标准化计算见下式(8):
(8)
其中Amax和Amin分别是A的最大值和最小值。
2.6 RFMA模型权重确定
我们希望对评价者本身的评价能力进行衡量。在RFMA模型下,评价者的整体评价效用可以表示成式(9):
U(ci)=WR×R′(ci)+WF×F′(ci)+WM×M′(ci)+WA×A′(ci)
(9)
其中R(ci),F(ci),M(ci),A(ci)分别表示评价者ci的四个指标值;而WR,WF,WM,WA则分别表示四个指标的权重,且WR+WF+WM+WA=1。
Hughes[19]认为RFM中三个变量权重相等,并未给予不同划分。但Stone[20]在对信用卡进行实证分析后,认为各个指标的权重并不相同。本文认为这几个权重存在一定的差异,因此采用层次分析法来进行比较分析,通过两两比较矩阵(一致性比例CR=0.0097<0.1)最终得到四个指标的权重分别为:
[WR,WF,WM,WA]=[0.0953,0.1598,0.2773,0.4676]
其中A的权重最大,即认为评级和评论的效用是影响评价者效用高低的最主要因素。
2.7 评价者评价效用衡量
为测试上述提出的机制对评价者整体评价效用分类能力,衡量评价者的整体评价效用,按照Ghose和Ipeirotis[21]提出的方法进行分类。
(1)对评价者是否为好的评价者进行人工标注。我们以人工的方法对评价者评价效用进行区分。按照这些基本原则:评价的个数、评级与评论的一致性、评论的篇幅、评论内容的客观性与主观性。
(2)确定一个合适的分界值θ将评价者分为好的和不好两类。平均评价效用≥θ的评价者被分类为“好的评价者”,而平均评价效用<θ的评价者被分类为“不好的评价者”。
(3)将模型分类结果与人工分类结果做比较。判断评价者是否为好的评价者是一种二值分类,借助二维列联表计算查准率、查全率及两者合成的综合指数,以此来评估模型的效果。见表3。
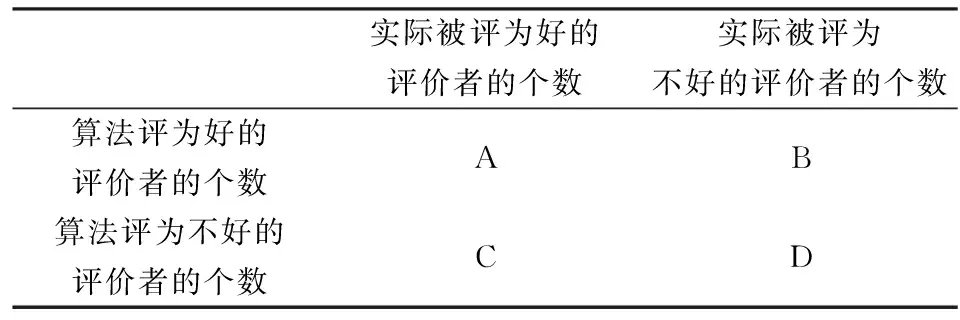
表3 分类评估列联表
其中,好的评价者的查准率:
(10)
好的评价者的查全率:
(11)
综合指数:
(12)
3 实验
3.1 数据及来源
作为一个C2C网上交易平台,淘宝在中国拥有最多的商品列表,最高的转化率,超过8千万的注册用户,以及在2亿5千多万的网民中最高的普及率[22]。因此本实验选择淘宝平台作为数据来源。通过编写爬虫程序随机抽取1个店铺的商品列表页商品的所有评价者,去掉其中匿名的用户及历史购买次数小于30的用户。将选取出来的183名评价者作为研究对象,根据他们的历史评价记录进行计算,共得到8303条历史评论。另外,本文还抽取了所有这些评价者的历史评价中的商品的所有评价(剔除无效数据)共852071条。所有的数据收集工作在2014年5月24到6月7日之间完成。数据抓取的结构图见图1。

图1 数据抓取结构
3.2 情感词典的构建
从HowNet提供的情感词汇和评价词汇表中,我们抽取了与网上购物评价相关的正负向词汇,其中正向词汇1131个,负向词汇1710个。所有183个用户的历史评论数据进行分词、去除停用词等预处理后,利用HowNet提供的语义相似度计算软件分别与正负向词汇进行相似度计算,分别得到正负向相似度词典,格式为(词1,词2:相似度)。在两个词典中,对同一个词只保留相似度最大的那一行,最终得到正负向情感词典。
3.3 评论文本效用计算
LDA主题模型的Gibbs Sampling方法已经有了各种实现,本文使用Matlab软件的topictoolbox工具包进行计算。我们将进行分词、去停用词等预处理后的文本数据处理成工具包所需的输入形式。对于所考察的183名评价者,分别对其所有的评价进行评论文本的衡量,得到每条评论与标准评论的相似度,作为评论文本的效用。
4 结果及分析
我们的实验分成两部分:第一部分是对于原始评级和评论及其区别的观察;第二部分则是对于我们所构建的评价效用机制的实现和分析。
4.1 评级和评论的不一致性
对于每个评价者,我们分别统计了他们历史评价中的好、中、差评的个数,以及进行了情感分析后的评论数据中得分为1、0、-1的个数,结果如下图2(a)、2(b)所示。

图2(a) 评价者评级的好、中、差评分布
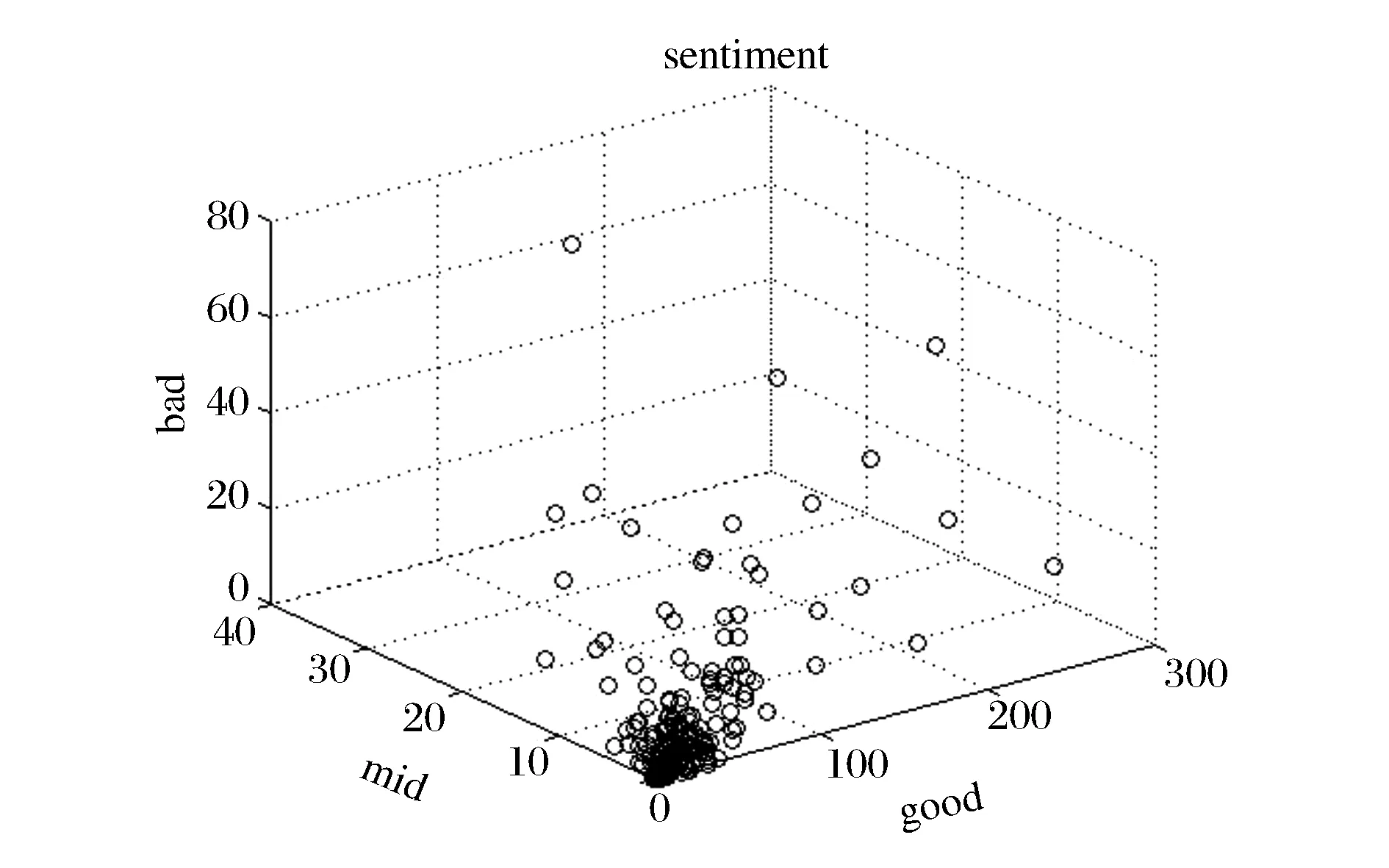
图2(b) 评价者评论(情感分析后)的好、中、差评分布
从图2(a)中可以直观地看出,原始的评级基本上集中在好评,中评和差评很少。进行了情感分析后,图2(b)显示了评级的分布向中评和差评轴偏移,也就是中评和差评的个数变多了。这种现象符合我们对在线购物评价的认知:消费者在评级时往往不能真实表达自己的感受,习惯性好评或是担心被商家报复而给予好评;在文字评论中,消费者能够直接表达真实的评价信息。这是由于现有的在线购物评价系统只以评级作为商品总分计算的来源造成的。
同时,我们计算了评级和评论(情感分析后)的好、中、差评个数的欧氏距离,并画出其概率密度曲线,见图3和图4。可以看到评价者评级与评论的不一致性的分布具有长尾现象,大部分的评价者具有一定的不一致性,完全一致和完全不一致的评价者较少。这也符合我们对现实中评价者的认知,评价者们并不会完全隐藏自己的真实感情。

图3 评级与评论好、中、差评的欧氏距离(标准化后)
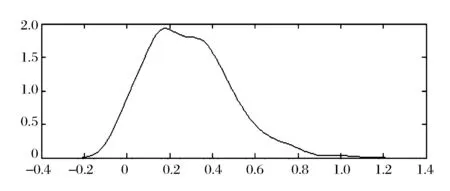
图4 概率密度分布
为了更进一步地分析评级与评论的不一致性,我们将不同的商品归结为鞋服配饰类、手机数码类、彩妆个护类、母婴用品类、家居物业类、食品类、运动户外用品类与花鸟文娱类这八个大类,分别探究评价者对不同类别商品的评级与评论的好、中、差评分布情况。图5选取了其中最为典型的鞋服配饰类、彩妆个护类与家居物业类这三个类别进行展示。同时将评价者进行编号,方便比较,可以看到如G1、J10、F16等点都发生了较大的偏移。整体来说,鞋服配饰类的偏移最大,居家物业类次之,彩妆个护类
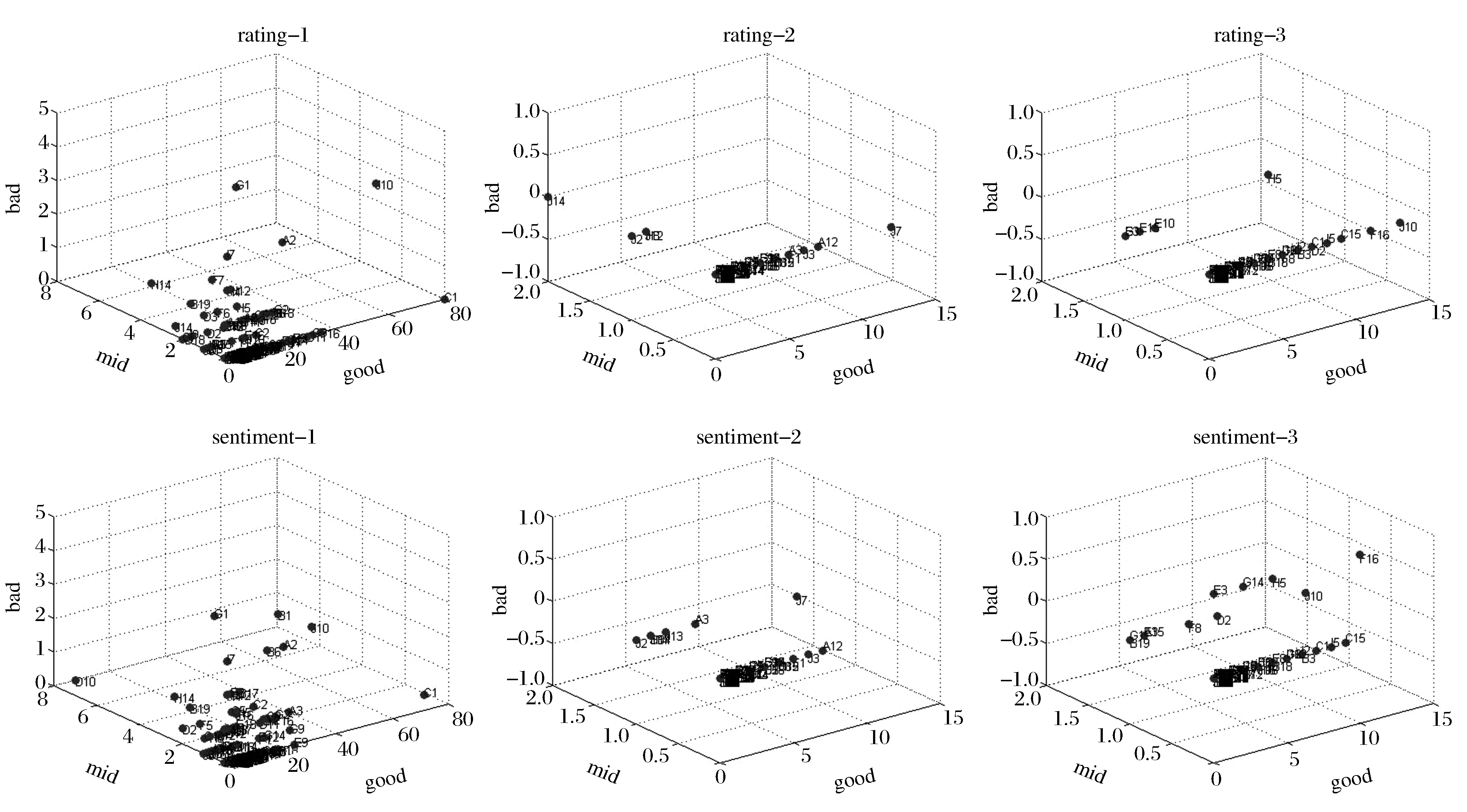
图5 rating-1到rating-3分别是评价者评级在鞋服配饰类、彩妆个护类与居家物业类的好中差评分布;sentiment-1到sentiment-3分别是评价者评论(情感分析后)在鞋服配饰类、彩妆个护类与居家物业类的好中差评分布
最小。这是因为鞋服配饰类的商品与卖家质量参差不齐,也是消费者的购买主体,导致出现的评价差异很大,往往包含较多的不一致现象。而彩妆个护类的商品使用效果具有较大的个体差异性,评价者所给出的评价也带有较强的主观性,反而能够较为真实地反映情感倾向。
进一步地,我们可以从图6对三种评级的均值看出,经过情感分析后,中评变化不大,但是差评个数却是增加了。
通过对评价者评级与评论的不一致性结果进行分析,并对原始数据进行观察,我们对评价者评级与评论的不一致性的原因进行了总结:(1)评价者担心负面的评级会遭到卖家的报复而选择正面的评级,但在评论里表达了自己的负面情感;(2)评价者的个体标准差异性导致评论里表达对商品较为满意,评级却是中差评;(3)操作误差。

图6 情感分析前后好中差评均值
4.2 评价者评价效用分析
为了衡量评价者的评价效用,区分评价者的评价能力,我们按照前述方法对其进行模型分类与人工分类的比较。对只用评级效用、只用评论效用、使用评论效用、RFM模型效用、RFMA模型效用这五者都分别进行分类比较,见表4、5、6、7、8。
分别计算得到好的评价者的查准率、查全率和综合指数见下表9。

表4 分类评估列联表(评级效用)

表5 分类评估列联表(评论效用)

表6 分类评估列联表(评价效用)

表7 分类评估列联表(RFM模型效用)
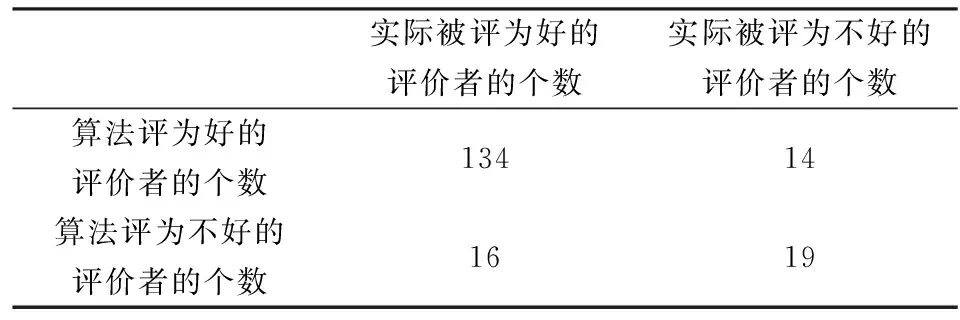
表8 分类评估列联表(RFMA模型效用)

表9 评价者分类计算结果
从表中结果可以看出,虽然在查准率方面稍逊于以RFM模型效用来区分的分类效果,但是在查全率和综合指数上,结合了评级和评论的评价效用机制要远远优于其他几种方法。说明本文提出的机制对于是否为好的评价者有较强的区分能力。
5 结语
本文以中国最大的在线购物网站淘宝网为数据来源,以为评价阅读者及时提供评价效用,并帮助评价阅读者区别评价者的评价能力为目标,结合文本挖掘中的情感分析和LDA主题模型研究方法,引入客户营销模型RFM,结合评级和评论两种信息,提出以RFMA模型对评价者评价效用进行衡量的机制,并据此对评价者进行分类,区分好与不好的评价者。该机制不仅能够帮助消费者从海量评价信息中识别出具有价值的部分,还能结合评级和评论两种信息来提升消费者的决策效率。另外,潜在消费者在阅读评价时,除了看重评价本身的效用,还关注评价者的评价能力,即评价者是否为好的评价者。基于RFM模型提出的RFMA模型为评价者的评价效用衡量找出了新的机制,并且可以作为购物平台实现对评价者进行分类的基础,为进一步完善现有的信誉系统提供了新的思路。实验结果表明,本文提出的机制对于区分评价者具有很好的效果。
在研究过程中发现,标准评论的选取会对评论的效用结果产生较大的影响。本文选取的是淘宝评价页面的标签,在后续研究中,可以通过自主提取标签来改进研究结果。另外,由于LDA主题模型需要预先设定主题个数,主题个数对于词项的分布有较大的影响,如何科学地确定有效的主题个数也是后续需要开展的研究。
[2] Jøsang A, Ismail R, Boyd C.A survey of trust and reputation systems for online service provision[J].Decision support systems, 2007, 43(2): 618-644.
[3] Park D H, Lee J, Han I.The effect of on-line consumer reviews on consumer purchasing intention: The moderating role of involvement[J].International Journal of Electronic Commerce, 2007, 11(4): 125-148.
[4] Chen Mao, Singh J P.Computing and using reputations for internet ratings[C]//Proceedings of the 3rd ACM conference on Electronic Commerce.Tampa,Florida,USA,October 14-17,2001.
[5] Dellarocas C.The digitization of word of mouth: Promise and challenges of online feedback mechanisms[J].Management science, 2003, 49(10): 1407-1424.
[6] 郝媛媛, 叶强, 李一军.基于影评数据的在线评论有用性影响因素研究[J].管理科学学报, 2010, 13(8): 78-88.
[7] Harrison-Walker L J.The measurement of word-of-mouth communication and an investigation of service quality and customer commitment as potential antecedents[J].Journal of Service Research, 2001, 4(1): 60-75.
[8] 杨铭, 祁巍, 闫相斌.在线商品评论的效用分析研究[J].管理科学学报, 2012, 15(5): 65-75.
[9] Ghose A, Ipeirotis P G.Designing novel review ranking systems: Predicting the usefulness and impact of reviews[C]//Proceedings of the ninth international conference on Electronic commerce,Minneapolis,MN,USA,August 19-22,2007.
[10] 蔡淑琴, 马玉涛, 王瑞.在线口碑传播的意见领袖识别方法研究[J].中国管理科学, 2013, 21(2): 185-192.
[11] Rabelo J C B, Prudêncio R C B, Barros F A.Leveraging relationships in social networks for sentiment analysis[C]//Proceedings of the 18th Brazilian symposium on Multimedia and the Web,São Paulo,Brazil,October 15-18,2012.
[12] Shen Yang, Li Shuchen, Zheng Ling, et al.Emotion mining research on micro-blog[C]//Proceedings of 1st IEEE Symposium on Web Society,Lanzhou,China,August 23-24,2009.
[13] 刘群,李素建.基于知网的词汇语义相似度的计算[C]//第三届汉语词汇语义学研讨会,台北,2002.
[14] Brin S, Page L.The anatomy of a large-scale hypertextual Web search engine[J].Computer networks and ISDN systems, 1998, 30(1): 107-117.
[15] Chen Mao, Singh J P.Computing and using reputations for internet ratings[C]//Proceedings of the 3rd ACM conference on Electronic Commerce,Tampa,Florida,USA,October 14-17,2001.
[16] Breslow N E, Day N E.Statistical methods in cancer research[M].Lyon: International Agency for Research on Cancer, 1987.
[17] Hu Nan, Pavlou P A, Zhang Jie.Can online reviews reveal a product's true quality?: Empirical findings and analytical modeling of Online word-of-mouth communication[C]//Proceedings of the 7th ACM conference on Electronic Commerce,Ann Arbor,Michigan,USA,June 11-15,2006.
[18] Blei D M, Ng A Y, Jordan M I.Latent dirichlet allocation[J].the Journal of machine Learning research, 2003, 3: 993-1022.
[19] Hughes AM.Boosting response with RFM[J].American Demographics, 1996, 5: 4-9.
[20] Stone B, Jacobs R.Successful direct marketing methods[M].Lincolnwood, IL: NTC Business Books, 1988.
[21] Ghose A, Ipeirotis P G.Designing novel review ranking systems: Predicting the usefulness and impact of reviews[C]//Proceedings of the ninth international conference on Electronic commerce,Minneapolis,MN,USA,August 19-22,2007.
[22] Ou C X, Davison R M.Technical opinion Why eBay lost to TaoBao in China: The glocal advantage[J].Communications of the ACM, 2009, 52(1): 145-148.
Rater Utility Mechanism Research Based On Online Rating and Comment
SHI Xiao-jing1, LIANG Xun1, SUN Xiao-lei2
(1.School of Information, Renmin University of China, Beijing 100872, China;2.Institute of Policy and Management, Chinese Academy of Sciences, Beijing 100190, China)
Appraisals for products and services are increasingly important on the Internet, as they eliminate consumers’ uncertainty, and help them to make purchase decision.Raters’ appraisals for products are divided into ratings and comments in most online shopping sites.The existing online reputation system and appraisal studies tend to focus on the user rating or comment respectively, but ignore the organic unification between them.User ratings do not fully reflect users’ real evaluation, as they are inclined to express their true feelings by comments.On the basis of the 852071 appraisal captured from Taobao, this paper proposes RFMA model to calculate raters’ appraise quality, which combines RFM model and considers two kinds of information containing rating and comment by analyzing the inconsistency of rating and comment.Then the good raters and bad raters are distinguished, and further support for consumer purchase is provided.The proposed RFMA model finds a new mechanism for measuring raters’ effectiveness.It can be used as a basement for shopping platform to classify the raters, and provide a new way of thinking to further improve the existing online reputation system.Through analyzing all of the raters, it can be concluded that the mechanism of combining the comments is more available and effective.
inconsistency of rating and comment; appraise; rater; RFMA
1003-207(2016)05-0149-09
10.16381/j.cnki.issn1003-207x.2016.05.017
2014-06-27;
2014-12-21
国家自然科学基金资助项目(71531012,71271211);京东商城电子商务研究项目(413313012);北京市自然科学基金资助项目(4132067);中国人民大学品牌计划项目(10XNI029)
简介:梁循(1965-),男(汉族),北京人,中国人民大学信息学院教授,研究方向:数据挖掘、网络金融、社会计算,E-mail:xliang@ruc.edu.cn.
F272.5
A
猜你喜欢
少儿美术(2019年7期)2019-12-14 08:06:22
运筹与管理(2019年6期)2019-07-10 03:36:32
统计与决策(2019年2期)2019-03-05 06:00:58
股市动态分析(2016年22期)2016-12-27 17:06:46
海外华文教育(2016年6期)2016-06-15 20:28:12
中国塑料(2016年9期)2016-06-13 03:18:48
IT时代周刊(2015年8期)2015-11-11 05:50:22
现代农业(2015年5期)2015-02-28 18:40:44
现代农业(2015年5期)2015-02-28 18:40:42
投资与理财(2009年8期)2009-11-16 02:48:40
