
视频动态纹理分类创新实验设计
2016-12-06 10:25李映,杨炯
实验室研究与探索 2016年5期
李 映, 杨 炯
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
视频动态纹理分类创新实验设计
李 映, 杨 炯
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)

设计了一个面向实际应用场景的创新实验。该实验设计基于Matlab 2010软件,以动态纹理视频为实验对象,采用线性动态系统模型参数进行动态纹理特征描述,并将其从低层特征描述转换到中层语义描述,形成视觉词典,最后基于现有分类器进行动态纹理图像的分类实验。该创新实验涵盖了“数字图像处理与分析”中的绝大部分知识点,并在此基础上进行了知识的拓展,使学生在更加深刻理解课程中重点内容的同时还可以锻炼自己动手解决实际问题的能力,初步培养学生的创新能力。
动态纹理; 创新实验设计; 视觉词典
0 引 言
传统纹理随着时间的演变就形成了动态纹理,因此,动态纹理具有时间相关重复特征,是一类比较特殊的视频数据[1]。其在自然界中广泛存在,如风中飘扬的旗子、随风摆动的树木、森林中的大火等动态纹理。由于这些动态纹理是一种空间重复且随时间变化的随机过程,在时间上具有某种稳定特性的图像序列[2-3],因此具有时空的某种自相似性,分类这些含有动态纹理的动态场景非常具有挑战性,但这类动态场景却是实际应用中必须解决的一个关键问题。现有动态纹理识别的方法主要包括基于光流场的方法、基于时空几何属性的方法、基于局部时空滤波的方法和基于模型参数的方法[4]。基于模型的动态纹理识别技术很多,如混合动态纹理模型[5]与分层动态纹理[6],基于混沌特征的动态纹理分类方法[7]。目前基于模型动态纹理识别技术最经常采用的模型之一就是LDS(Linear Dynamical System)动态纹理模型[8]。本文依据该模型进行动态纹理分类的实验设计,利用Ravichandran等[8]提出的算法设计并实现动态纹理分类。该实验在LDS线性动态系统模型的基础上,解决了当前分类算法无法解决的变化视角和不同尺寸下动态纹理的分类问题。
由于动态纹理分类是后期图像理解和实际应用的一个关键环节,并且需要综合应用图像各方面的知识,在这一动态纹理分类的创新实验中,学生可以从系统的角度对图像处理、分析和理解有更深入、更准确的直观性的认识。在图像特征提取阶段,学生可以理解和掌握如何将原始图像数据通过转换变成有利于图像分类的特征,进行数据的抽象。在图像分类解决,学生还可以学到如何将提取的特征转换为符合人类表述的语义表达,通过抽象的简单语义描述进行场景分类。最终在这个创新实验中贯穿图像处理与分析的主线:图像分析→图像理解的图像工程线路。因此为了培养和锻炼学生学习知识与应用知识两方面能力的结合,并将学习知识主动转化为对知识的应用能力,强化学生将所学图像处理知识,综合应用于实际视频内容理解的能力,利用实际应用中遇到的具有挑战性的动态场景中的纹理分类设计创新实验,具有非常好的教学意义。
实验设计具体步骤为:① 使用线性动态系统参数作为动态纹理的特征描述符;② 将BoF(Bag of Feature)词袋算法流程扩展到动态纹理分类中,形成基于BoS(Bag of System)系统袋的算法流程。
1 实验设计框架
动态纹理具有运动和外观的特征,根据这两大类特征,现有动态纹理识别的方法分为两类,其一是根据动态纹理的运动特性进行识别;另一类则是将运动和外观结合得到纹理的有效表达[9]。
动态纹理识别主要分为训练阶段和预测阶段。在训练阶段,通过训练集中的视频获得词典BoS与训练视频序列的特征向量H=[h1,h2,…,hK]T。在预测阶段,利用训练阶段获得的词典获得预测视频的特征向量。通过前两个阶段获取的训练集特征向量与预测集特征向量H′,根据已知的训练集中视频的类标签,分类得出特征向量的类别。图1给出了动态纹理分类的整体流程图。
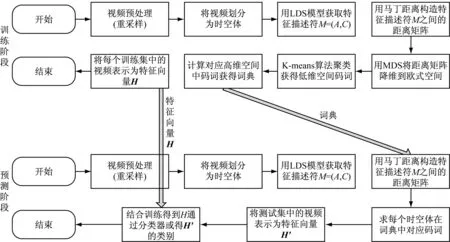
图1 动态纹理分类实验总体框架结构
(1) 训练阶段。从训练数据集中获取大量的训练视频,经过重采样得到所需尺寸的动态纹理视频,然后将视频序列划分为时间域和空间域都不重叠的大小为σ×σ×τ时空体(σ为空间域的大小,τ为时间域的大小),接着利用动态纹理模型来建模时空体,获得可以表示该时空体的模型参数元组M=(A,C),利用模型参数间的马丁距离来构建时空体之间的距离矩阵。然后利用高维空间中点间距离的多维标度法(Multi-dimensional Scaling,MDS)[10]进行降维处理,给出欧氏空间的点集,同时保留其在高维非欧氏空间的关系。在降维的过程中,不会特别指定降维后欧氏空间的维数。降维后的空间是欧氏空间,接着使用K-means聚类算法[11]进行聚类,获得欧氏空间中的聚类中心,然而这些聚类中心并不对应到任何一个原始线性动态系统时空体。由于从低维内嵌空间到原始高维空间并不存在明显的映射关系,为了获得原始高维空间中的码词,选择低维空间中到聚类中心距离最小的点对应的高维空间的系统参数为高维空间的码词,构成所需词典。最后使用词频法(Term Frequency,TF)[12-13]表示动态纹理视频,获得训练集中表示动态纹理特征向量。
(2) 预测阶段。预测集视频经过与预测阶段同样的重采样、分割、建模等处理过程,然后利用马丁距离获得特征描述符M=(A,C)与词典的距离矩阵。在词典中选择距离特征描述符距离最小的码词作为该特征描述符的码词,使用词频法TF,获得预测集中动态纹理视频的特征向量H′。通过训练阶段获取的训练集特征向量与已知的训练集中视频的类标签,预测得出特征向量H′的类别。
2 具体实验步骤的实现
BoF方法[14]应用于计算机视觉的灵感来自于文档检索领域。在文档检索中,通过关键词分布情况的差异性识别该文档。在该实验中,采用类似BoF方法的处理流程,不同之处在于实验中使用特征描述符的分布取代关键词的分布。BoF方法典型处理如下:
(1) 从训练集图片中提取特征和对应的特征描述符;
(2) 通过使用类似K-means的聚类算法形成字典,聚类中心代表词典中的字码;
(3) 用字典表示训练集中的每张图片;
(4) 选择一个分类器,将新图片词分布与训练集中已有词分布进行比较,推断类别。
BoS基本处理流程与BoF方法类似,主要不同点在于用线性动态系统参数作为特征描述符取代传统时空特征,这也造成获取特征描述符不再处于欧氏空间。因此引入一种新的降维处理方法,使降维后特征处于欧氏空间,并从这些特征描述符中获取词典。基于BoS动态纹理分类过程如图2所示,包括特征提取、词典形成、词典描述和分类。
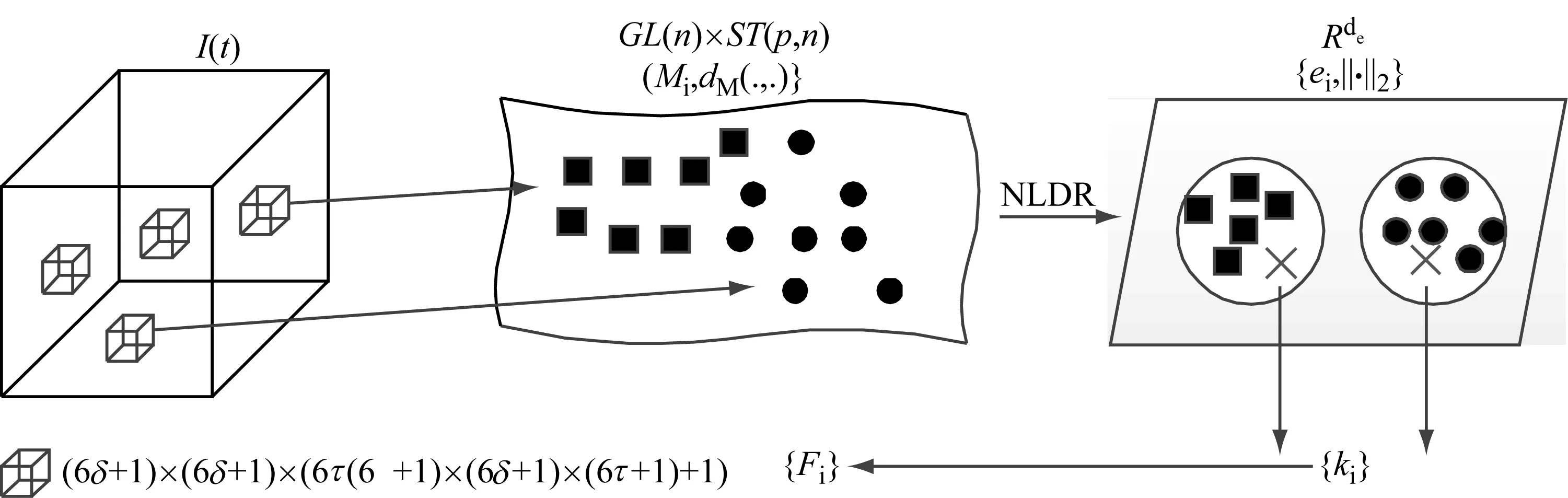
(a) (b) (c)
2.1 LDS模型参数计算
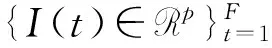

(1)
(2)
其中:z(t)∈Rn是t时间段的隐藏状态;A∈Rn×n代表隐藏状态的动态性;C∈Rn×n将隐藏状态转换为系统的输出;C0∈Rp是视频序列像素值的均值;w(t)~N(0,R)和Bv(t)~N(0,Q)分别是度量和过程噪声。隐藏状态的维数n是线性动态系统的序;p是视频序列或者视频块中一帧的像素数。
实验中动态模型的参数(C0,A,C,Q,R)采用主成分分析方法[15]来求取。该动态模型的优点在于它将由C建模的时空块外观特征和由A建模的动态性特征相互分离。因此,给定一动态纹理时空视频块,就可以使用元组M=(A,C)来表示,既描述了动态纹理的动态性又描述了动态纹理的整体外观。
2.2 词典形成
从LDS系统参数的计算步骤中,获得LDS的描述是以元组M=(A,C)来表达的。但这个元组的表示处于非欧氏空间,不能直接用适用于BoF聚类的方法。实验中采用马丁距离来表示元组之间的相似性。
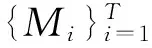
(3)
通过式(3)可以获得想要的词典C={F1,…,FK},其中Fi=(Ai,Ci)。
2.3 基于词典的视频描述
一旦获得K个码词,每个视频序列都可以用这个词典来描述。实验中采用直方图H=[h1,h2,…,hK]T∈RK的形式来实现视频的描述。假设第i个视频序列中码词k出现cik次,N为所有视频序列的数量,Nk为出现码词k的视频序列的数量。实验设计中将通过两种不同的表达方法来描述视频序列。
(1) TF,定义如下:
(4)
其中:k=1,2,…,K;i=1,2,…,N。
(2) 逆文本词频法(Term Frequency-Inverse Document Frequency,TF-IDF),定义如下:
(5)
这两种方法都有各自的优点。TF的表达形式比较简洁,该方法只考虑新的测试视频序列中码词分布情况;TF-IDF减弱了所有类共有特征的影响,突出了视频序列具有区别性特征的影响。一旦计算出直方图H后,使用L1范数进行标准化。
2.4 分 类
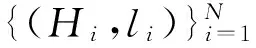
3 实验结果
实验数据集为 “DynTex”数据库。本文提取该数据库中8类视频序列:20个静态水面视频、20个旗帜视频、20个喷泉视频、6个电梯视频、20个草地视频、20个大海视频、9个交通视频、20个树木视频作为实验原始数据。在实验中,一半用来训练,另一半用来测试。图3中展示了数据库中一些视频序列的截图。下面给出在该创新实验平台上的几个实验验证结果。

湖面

电梯

旗帜

喷泉

草地

大海

交通

树木
图3 动态纹理视频库中8类视频部分截图示例
3.1 视频时空体大小对分类性能的分析
实验中首先将视频序列划分为时间域和空间域都不重叠的大小为σ×σ×τ时空体,σ为空间域的大小,τ为时间域的大小。对于σ和τ取不同的值,其中σ∈{20,30,60},τ∈{15,25},σ可以取3个值,τ可以取2个值,这样就出现了6种不同的时空体大小。对于6种不同的时空体,使用秩为n的线性动态系统进行建模,实验中n的值取3。对于6种不同大小时空体分别独立进行实验。为了能够划分出不重叠的时空体,并且在划分的过程中不存在剩余视频未被划分,需要对视频序列空间域进行重采样,使其达到需求的尺寸。原始数据库中视频每一帧的大小为352×288,每个视频包含的帧数都大于100帧。对视频每帧进行重采样,重采样后视频每帧大小为360×300,这样就可以完整的利用整个视频并且不进行重叠的划分。
图4给出了不同尺寸时空体的动态纹理识别率结果。在实验中分别使用了3种不同类别的组合来进行实验,3组不同的类别分别为:湖面、喷泉、大海;草地、树木、湖面;电梯、交通、旗帜。图4给出的动态纹理识别率是这三组实验的平均值。从图4可以看出,识别率最高的时空体为20×20×25,最低的为60×60×15,空间尺寸σ变大后识别率降低,时间尺寸τ变大后识别率便上升。根据上面的分析,可以得出在较小空间尺寸σ较大时间尺寸τ情况下,识别率较高,但随着空间尺寸σ的变小,视频序列被划分的时空体增加,在降维聚类的过程中耗费的时间也相应增加了大约2倍。鉴于识别率与时间的综合考虑,在实验中选用时空体尺寸为30×30×25。
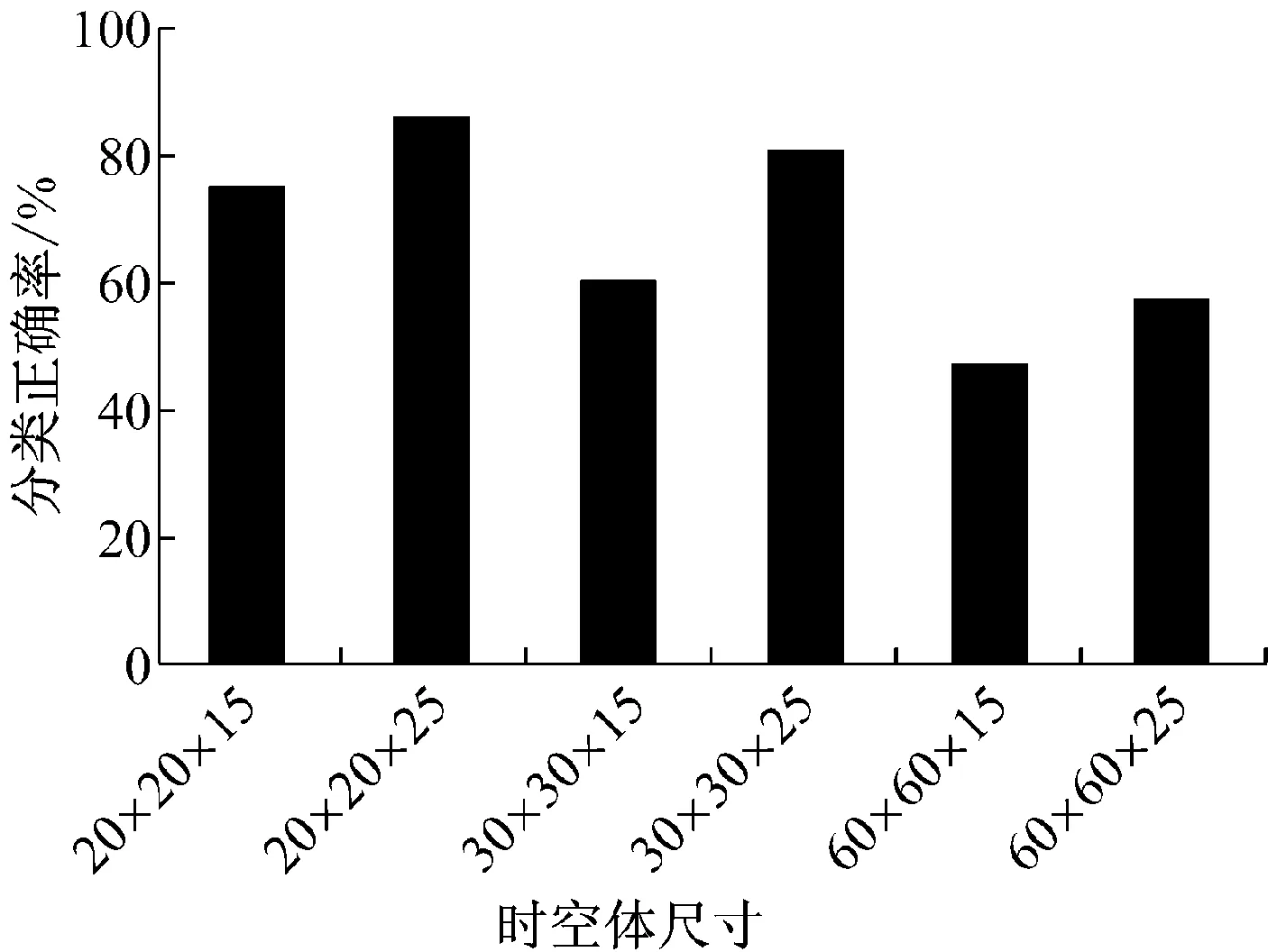
图4 不同时空体大小动态纹理识别率
3.2 聚类中心个数对分类性能影响分析
视频被划分为不重叠的时空体后,利用线性动态系统获得描述时空体的参数。但由于获取的参数处于非欧氏空间,为了获得词典,需要进行降维处理,将处于非欧氏空间的参数降维到欧氏空间。实验中采用高维空间中点之间距离的多维标度法(Multi-dimensional Scaling,MDS),该方法在给出欧氏空间的点集的同时保留了其在高维非欧氏空间的关系。实验平台搭建时直接使用Matlab中Y=cmdscale(D)函数实现降维。在降维的过程中,不会特别指定降维后欧氏空间的维数。然后使用K-means聚类算法进行聚类,同样也是直接调用Matlab中自带函数[IDX,C]=kmeans(Y,K)进行聚类,聚类中心数量K的值取8~96间以8为倍数的值。
图5给出了不同聚类中心数量的动态纹理识别率结果。该实验,仍采用3种不同的类别组合来进行实验,三组不同的类别分别为:湖面、喷泉、大海;草地、树木、湖面;电梯、交通、旗帜。图5显示的不同聚类中心数量动态纹理识别率是这三组实验的平均值。
从图5可见,随着聚类中心的增加分类正确率也在不断地上升,分类效果最好的聚类中心数量为96个。但在聚类中心大于72个后,其分类正确率增长幅度就很少了。这样,在聚类中心大于72个后,聚类中心的增加对于分类正确率的影响已经很小很小。在接下来的试验中,将使用的聚类中心数量为80个。
3.3 特征描述与分类分析
经降维聚类后获取了词典,对于视频序列的表示

图5 不同聚类中心数量下动态纹理识别率
方法,实验可以选用前面提到的词频法TF与逆文本词频法TF-IDF。在分类算法上,可以使用的分类算法有三种:k-最邻近算法(k-NN)、朴素贝叶斯分类法、内核支持向量机分类算法。图6给出了不同特征描述结合不同分类器时的动态纹理识别率结果。该实验同样使用与前面相同的3种不同的类别组合来进行实验。图6给出的动态纹理识别率是这三组实验的平均值。
由图6可以看出,词频的分类正确率要比逆文本词频法的分类正确率要高,在分类算法上,朴素贝叶斯算法要比SVM支持向量机分类算法与K-means最邻近分类算法。从这个实验中发现分类效果较好的组合是词频法的描述与朴素贝叶斯分类算法的结合。

图6 不同的特征描述结合不同的分类器的动态纹理识别率结果
3.4 类别数量对分类性能的影响分析
图7给出了类别数量不同的动态纹理识别率结果。在本实验中测试了2~6类动态纹理的分类效果。在每类中平均进行3次的实验,动态纹理识别率是3次实验的平均值。由图7可以看出两类的分类正确率最高,大于95%,最低的分类正确率为6类,仅有约45%。随着分类种类的增加,分类正确率也在降低。

图7 不同动态纹理类别识别率
4 结 语
该实验设计主要是基于动态纹理模型实现动态纹理的分类的创新实验训练。该实验整体流程主要分为训练和预测两个阶段。实验的核心在于将BoF词袋扩展到动态纹理分类中,使用类似BoF的步骤进行动态纹理分类。在特征提取中,使用线性动态系统的参数来取代传统的时空特征;在词典获取过程中,因为获取的模型参数处于非欧氏空间,对其降维到欧氏空间后,使用K-means算法进行聚类,得到聚类中心及词典中的码词。最后给出了具体的实施细节与参数设置情况,并针对较大影响实验结果的四个因素:视频块的大小、聚类中心的数量、视频描述方法、分类算法分别进行讨论与实验对比。实验表明,若视频原始帧大小为352×288,在视频被划分为30×30×25的时空块,聚类中心选为80个,用TF词频法描述视频,分类算法选择朴素贝叶斯分类算法时,程序运行时间和分类正确率会取得较好的结果。
从整个实验设计到实现,可以较好地锻炼学生的理论与实践相结合的能力,并可以初步培养学生从学术的角度进行实验验证和分析,为进一步培养学生的学术创新能力奠定了基础。
[1] Soatto S, Doretto G, Wu Y N. Dynamic Textures[C]∥Proceedings of the 8th International Conference onComputer Vision. Vancouver, Canada, 2001:439-446.
[2] Chetverikov D,Péteri R. A brief survey of dynamic texture description and recognition [C]∥InternationalConference on Computer Recognition Systems, 2005: 17-26.
[3] Doretto G, Chiuso A, Wu Y N,etal. Dynamic textures [J]. International Journal of Computer Vision, 2003, 51(2): 91-109.
[4] Zhao Guoying, Matti P. Dynamic Texture RecognitionUsing Local Binary Patterns with an Application toFacial Expressions [J]. IEEE Transactions on PatternAnalysis and Machine Intelligence, 2007, 29 (6):915-928.
[5] Chan A B, Vasconcelos N. Modeling, clustering, and segmenting video with mixtures ofdynamic textures [J]. IEEE Trans Pattern Anal Machine Intell, 2008, 30(5):909-926.
[6] Chan A B, Vasconcelos N. Layered dynamic textures [J]. IEEE Trans Pattern Anal MachineIntell, 2009, 31(10):1862-1879.
[7] 王 勇, 胡士强. 基于混沌特征的运动模式分割和动态纹理分类[J]. 自动化学报, 2014, 40(4): 604-614.
[8] Ravichandran A, Chaudhry R, Vidal R. Categorizing dynamic textures using a bag of dynamical systems [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(2): 342-353.
[9] 王 硕. 基于小波变换的动态纹理分类[D]. 哈尔滨:哈尔滨工程大学, 2010.
[10] Cox T F, Cox M A A. Multidimensional Scaling [M]. Chapman andHall, 1994.
[11] MacQueen J B. Some Methods for classification and Analysis of Multivariate Observations [C]∥Proceedings of 5-th Berkeley Symposium on Mathematical Statistics and Probability, Berkeley, University of California Press, 1967: 281-297.
[12] Luhn Hans Peter. A Statistical Approach to Mechanized Encoding and Searching of Literary Information [J]. IBM Journal of Research and Development (IBM), 1957, 1(4): 315.
[13] Sivic J, Zisserman A. Video Google: A Text RetrievalApproach to Object Matching in Videos [C]∥Proc IEEE Int’l Conf Computer Vision, 2003: 1470-1477.
[14] Csurka G, Dance C, Fan L,etal. Visual categorization with bags of keypoints [C]∥Workshop on Statistical Learning in Computer Vision, ECCV. 2004, 1(1-22): 1-2.
[15] Duda R O, Hart P E, Stork D G. Pattern classification[M]. John Wiley & Sons, 2012.
Design of Innovation Experiment for Classifying Dynamic Texture in Video
LIYing,YANGJiong
(School of Computer Science and Technology, Soochow University, Suzhou 215006, China)
The experiment courses of digital image processing and analysis focus on the experiment of low-level image processing, and most experiments are used to verify the results of the methods in image processing. Therefore, we designed an innovation experiment for actual application scenario. Based on Matlab 2010 software and video of dynamic texture, the experimental design adopted the parameter of linear dynamic system model as the feature description of dynamic texture, then transited the low-level features to middle-level semantic description to form the visual dictionary, lastly implemented the dynamic texture image classification experiment using existing classifiers. The experiment covered most knowledge of the digital image processing and analysis, and extended the knowledge of image understanding. So that students could more profound understanding of the key content in the course, as well as improving students’ ability of solving the practical issue, and cultivating students’ preliminary innovation ability.
dynamic texture; design of innovation experiment; visual dictionary
2015-05-06
软件工程国家特色专业建设点(TS2455);苏州大学计算机与信息技术国家级实验示范中心开放性课题——机器视觉创新实验室建设项目资助
李 映(1976-),女,江苏苏州人,硕士,实验师,研究方向:图形图像处理。Tel.:13962123096; E-mail:youngj@suda.edu.cn
杨 炯(1971-),男,江苏苏州人,硕士,实验师,研究方向:实验技术。Tel.:13962123096; E-mail:youngj@suda.edu.cn
TP 391.41
A
1006-7167(2016)05-0071-06
猜你喜欢
电讯技术(2022年3期)2022-03-27
计算机工程(2020年3期)2020-03-19
文苑(2019年24期)2020-01-06
文苑(2019年24期)2020-01-06
中国听力语言康复科学杂志(2019年3期)2019-06-24
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
中关村(2014年5期)2014-05-15
自然资源遥感(2014年3期)2014-02-27
当代修辞学(2013年4期)2013-01-23
