
基于支持向量机的内幕交易识别研究
2016-12-05 02:32赵小康
财经问题研究 2016年10期
沈 冰,赵小康
(西南大学经济管理学院,重庆 400700)
基于支持向量机的内幕交易识别研究
沈 冰,赵小康
(西南大学经济管理学院,重庆 400700)
内幕交易的识别问题一直是证券市场的难题,学术界进行了大量有益的探索,却难以得到满意的结果。本文选取了从2000—2015年被我国证监会或司法机关查处的内幕交易案例作为研究样本,利用支持向量机模型对内幕交易进行识别。研究结果表明:累积超额收益率、股价波动持久性、超额换手率、股价信息含量以及股权制衡度是有效识别内幕交易的重要指标,总体识别准确率达到了86.18%,该模型的识别效果比较理想。
证券市场;内幕交易;支持向量机
各国证券市场的内幕交易频繁发生,已引起社会各界的广泛关注,证券监管机构对此也十分重视,各国证券监管机构对内幕交易的监管及打击力度都在不断加强。美国证券监管机构对内幕交易的打击力度一直走在世界各国前列。2013年,美国对冲基金巨头SAC资本合伙公司被指控为内幕交易罪,并为此支付了18亿美元的罚金,这是迄今为止美国证券监管机构对内幕交易开出的最大罚单。作为新兴的证券市场,中国的内幕交易尤为严重,对证券市场造成了极大的负面影响。中国证监会对内幕交易问题也越来越重视,中国证监会前主席郭树清在任期间曾提出对内幕交易“零容忍”,现任证监会主席刘士余表示要保护中小投资者的利益,严厉打击内幕交易。近年来,中国证监会采取了一系列措施,查处了一批内幕交易案件。可见,各国证券监管机构对内幕交易都是难以容忍的。
为了防范内幕交易的发生,需要证券监管机构采取有效的监管措施。目前,中国证监会在内幕交易的监管方面效率不高,一般都是通过举报或者现场突击检查等,偏重于事后监管,一般在内幕交易发生1—2年后才查处出来,而且查处的案件偏少,监管效率还有待提高。随着云计算和大数据的兴起,使得对内幕交易的监管进行事前识别成为可能。通过选取恰当的识别指标和识别模型,建立内幕交易的识别系统,然后运用大数据分析,一旦发现异动,可以立即跟踪可疑证券账户,最后再进行核查,这样就能够在第一时间发现并制止内幕交易的发生,提高监管效率。
然而,我国学术界对内幕交易识别方面的研究还处于探索阶段,在内幕交易识别指标的选取、识别模型的构建方面还存在不少问题,缺乏一套科学、适用的内幕交易识别系统,难以为证券监管机构建立有效的识别系统提供支撑。
一、文献综述
国外学者对证券市场内幕交易的研究起步较早,研究成果较多,这些研究主要集中在内幕交易的影响及监管等方面。Jaffe[1]采用事件法,率先提出发生内幕交易的股票的超常收益率显著不为零。Kyle[2]认为内幕交易会提高股票的买卖价差,交易成本会相应增加,从而降低证券市场的流动性。Leland[3]采用理性预期模型,发现内幕交易会使内幕交易者受益,外部交易者受损,内幕交易的净福利增加,内幕交易行为应该被禁止。Scott和 John[4]从财务虚假陈述的角度出发,构建了内幕交易的识别模型,得到56%—60%的识别准确率。Huddart和Petronib[5]发现内幕交易者一般在内幕信息公布之前进行内幕交易,而在临近内幕信息公布时减少内幕交易,从而增加了内幕交易的监管难度。Wu[6]发现内幕交易发生的概率与上市公司股东权利大小有关,股东权利越大,内幕交易发生的概率越大,证券市场对内幕交易的反应也就越大。Beny[7]研究发现,内幕交易法律法规越严格的国家,证券价格越能反映各种信息,越不容易被操纵。Fernandes和Ferreira[8]则认为,不同的国家在实施内幕交易监管法规的前后,股票价格的信息含量会发生变化,代理成本越高的国家,对内幕交易的监管效果越差。
国内学者汪贵浦[9]以换手率作为内幕交易的识别指标,利用Logistic识别模型,得到了超过70%的总体识别成功率。史永东和蒋贤锋[10]以股票的收益率和换手率作为识别因子,得出了内幕交易总体识别率为75%的结论。张宗新等[11]等以收益率、β值、流动性指标等作为识别指标,使用决策树模型对内幕交易进行识别,识别效果较好。而李心丹等[12]则运用行为金融学,建立了内幕交易行为的动机结构模块(SEM)识别模型。张宗新[13]改进了Logistic识别模型,并引入了神经网络模型,使得内幕交易的识别效果得到一定的提高。黄素心[14]利用股票市场表现、市场微观结构、公司财务和公司治理方面的指标,构建了内幕交易的识别模型。唐齐鸣和张云[15]从公司治理的角度对内幕交易进行了实证研究,认为内幕交易的根本原因是公司治理不善。贝政新和袁理[16]把市场指标作为识别指标,从利好与利空信息角度出发,得出了利好与利空条件下的内幕交易识别准确率。许永斌和陈佳[17]利用市场变量和公司治理变量,对Logistic和BP神经网络模型进行比较,发现BP神经网络模型的识别能力更加优越。郭万山和钟彩艳[18]运用事件研究法和神经网络模型法对内幕交易问题进行了实证研究,并对这两种方法的识别效果进行了比较。而宋力和李焕婷[19]从治理结构、股票表现、财务状况三方面选取了59个识别指标,利用Logistic模型,发现超常累计收益率等7个指标的识别效果比较理想。经煜甚[20]研究发现,在《司法解释》出台之后,内幕交易的监管有效性大幅提高,对内幕交易行为起到了一定的震慑作用。李香丽和孙绍荣[21]则认为中国内幕交易的监管主要停留在定性分析阶段,造成了监管执行难的问题。因此,应加大定量分析力度,建立科学的监管模型,确定监管指标,才能提高内幕交易的监管效率。
总体来说,国内外学者对证券市场内幕交易的相关问题进行了广泛的研究,尤其是对内幕交易的影响及监管方面研究比较全面和深入,而对内幕交易识别方面的研究相对较少,在识别指标的选取、识别模型的构建方面还缺乏比较系统的研究,有效的内幕交易识别系统还没有建立起来。因而,本文将对我国证券市场内幕交易的识别问题进行研究。
二、内幕交易识别的理论分析
由于内幕交易违背了证券市场的“三公”原则,损害了广大投资者的合法权益,是证券监管机构打击的重点,使得内幕交易者在进行交易时总是想方设法隐藏自己的非法行为,以免被发现而受到处罚。然而,不管内幕交易者如何掩盖自己的行为,总会露出一些蛛丝马迹,从某些指标的异常变化中反映出来。因而,通过相关指标的异常变化就可以对内幕交易进行识别。
一般来说,知情者在利用上市公司的内幕信息进行内幕交易的过程中,往往会在内幕信息正式公布之前一段时间内买卖相关公司的证券,尤其是一些机构者和大户,由于资金流较大,买进的证券较多,这样就容易造成该公司证券成交量和价格的异常变化。而成交量的变化和价格的波动又会吸引一部分趋势投资者的跟风,使其采取相应的投资行为,这样就会加剧成交量和价格等相关指标的异常波动。因而,通过研究上市公司内幕信息正式公布之前相关指标的异常变化情况,就可以对相关上市公司的内幕交易进行识别。相关的研究表明,选取恰当的识别指标与识别模型,构建有效的内幕交易识别系统,大体上就可以判断某家上市公司的证券是否出现了内幕交易,进而有针对性地采取相应的防范措施。
同时,证券监管机构还可以利用云计算和大数据分析,对涉嫌内幕交易的投资者进行分析,对相关投资者的交易数据、资金流向等进行数据挖掘和分析,一旦发现交易数据出现异常情况,就及时跟踪可疑的证券交易账户,分析相关账户异常交易的原因,了解和调查该投资者的开户信息、社会关系、关联交易情况、银行资金流动情况、最近的通话情况、QQ及微信的聊天记录等。通过调查和分析,可以进一步判断该投资者是否参与了内幕交易,这样就可以对内幕交易进行识别,并尽早采取相应措施加以预防和制止。
因此,选取恰当的识别指标、识别技术和识别方法,就可以对证券市场的内幕交易行为进行识别。内幕交易的识别流程如图1所示。
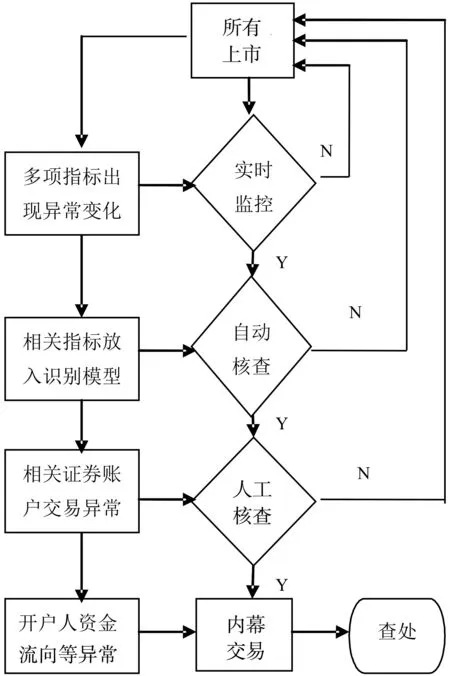
图1 内幕交易的识别流程图
三、基于支持向量机的识别模型
(一)支持向量机模型
支持向量机(Support Vector Machine,SVM)由Vapnik[22]在1995年首先提出的一种基于统计学习理论的VC维理论、结构风险最小原理基础上的识别模型,是一种新的机器学习技术。它的优势主要体现在解决小样本、非线性和高维模式的识别中。由于它具有较强的泛化能力、学习技能以及取得全局最优解等多种优点,开始被一些学者应用于金融领域,比如信用评分和保险理赔预测等。Kumar 和 Ravi[23]研究表明,支持向量机的识别能力超过其他识别方法。目前,该模型还很少运用到内幕交易的识别中,本文把它运用到我国证券市场内幕交易的识别中。支持向量机识别模型的原理如下:
把样本的数据集T={(x1,y1),…(xn,yn)}∈(X×Y)n作为支持向量机的训练样本,其中,xi∈X=Rn,yi∈Y=±1,i=1, 2, …, n。根据支持向量机的原理,可以构成最优目标函数式:
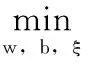
s.t.[(w·xi)+b]≥1-ξi
ξi≥0,i=1,2,…,n
(1)
式(1)中,w表示权重向量,‖w‖2/2表示最小的分类面,即最优分类面。C表示惩罚因子,主要是为了控制对错分样本惩罚的程度。ξi表示松弛变量,一般在出现线性不可分时,才会增加这一变量。利用Lagrange优化方法,就可以转化成对偶问题,并引入核函数K(x,x′),则式(1)可以转化为:

0≤αi≤C,i=1,2,…,n
(2)
式(2)中,αi表示Lagrange乘子。 把核函数引入后,就可以把非线性分类问题转化为高维空间线性分类问题。研究表明,Guass径向基核函数的支持向量机速度最快,分类效果也最佳。鉴于此,本文采用Guass径向基核函数,即:
(3)
(二)模型参数的确定
基于Guass径向基核函数的支持向量机,需要确定模型的两个参数,即惩罚因子C和核参数σ2。如果参数选择不当,可能会出现模型过度拟合或拟合不够的情况,这样就会影响到识别的效果。本文利用粒子群优化(Particle Swarm Optimization,PSO)算法来确定和优化这两个参数。粒子群优化是由kennedy和Eberhart在1995年开发的一种全局优化算法,来源于模拟一个简化的社会模型。该算法根据每一个个体对环境的适应程度,将它们逐步转移到较好的区域,最终寻找最优解。因而,用粒子群优化来确定模型的参数,识别效果比较理想。
四、样本及变量的选择
(一)样本的选取与数据来源
本文选取从2000年初至2015年底被中国证监会或司法部门依据内幕交易法律法规查处的上市公司,*由于证券市场的内幕交易往往比较隐蔽,收集证据比较困难,查处内幕交易是一个十分复杂的过程,往往会滞后一段时间,有时内幕交易发生之后经过几年才被查处。在已经查处的案件中,内幕交易发生的时间段为2000—2014年。共有123家作为研究的黑色样本。另外,我们还按照1∶1的比例配对选取了123家上市公司作为白色样本。配对的白色样本与黑色样本尽量同在一个交易所、同属一个行业、公司规模相当。最终选取的样本一共有246个,包括123个黑色样本和123个白色样本。为了验证识别模型准确率的需要,本文把2000年初到2011年底的148个样本作为模型的训练样本,把2012年初到2014年底的98个样本作为模型的测试样本。
选取样本的时间区间对研究内幕交易的识别十分重要,如果把样本的时间区间设置太长,可能会误把其他因素也被纳入到识别模型之中,容易引起识别结果的偏差;反之,如果把样本的时间区间设置太短,可能会使内幕交易效应难以显现出来,研究结论的真实性会受到质疑。至于理想的时间区间应该选多长,学术界并没有统一的标准。本文借鉴张宗新等[11]的研究成果,上市公司重大信息正式公布之前的30个交易日,发生内幕交易的可能性最大。因而,本文也选择这一时间区间来进行研究。在分析过程中,如果样本在研究期间出现了股本变动,为了保持数据的连续性,要对相关的证券价格进行复权处理,全部采取向后复权后的数据。本文的数据来源于国泰安(CSMAR)数据库,使用的软件主要有SPSS 19.0和Matlab 7.1。
(二)变量的选取与确定
1.变量的选取
本文把内幕交易发生的概率作为识别模型的因变量,把样本的收益性指标、波动性指标、流动性指标、市场相关性指标和股权结构性指标作为识别模型的自变量。其中,收益性指标由日均收益率和累积超额收益率构成;波动性指标由股价收益波动率和股价波动持久性构成;流动性指标由超额换手率和非流动比率构成;市场相关性指标由系统性风险和股价信息含量构成;股权结构性指标由股权集中度和股权制衡度构成。研究变量的具体说明如表1所示。
2.识别因子的确定
并不是前面所有的指标都适合用来作为识别模型的识别因子,一般选择黑色样本与白色样本差异显著的指标更适合作为识别因子,识别效果更加理想。为了确定模型的识别因子,本文利用非参数的Mann-Whitney U检验和Kolmogorov-Smirnov检验,对两类样本的各个变量是否存在显著差异进行检验,非参数检验结果如表2所示。结果表明,两类样本的Return、CAR、Sum、ΔTurnover、INFO与Z在1%或5%的置信水平下都存在显著的差异。而Volatility、Illiquidity、Beta及Herf指标的差异都不显著。在识别模型中,我们只纳入两类样本差异显著的指标,剔除两类样本差异不显著的指标。
虽然两类样本的Return和CAR都在1%或5%的置信水平下存在显著差异,但由于这两个变量都属于收益性指标,相关性比较高,相对来说,CAR的差异更显著,为了避免出现多重共线性的问题,我们在模型中把Return排除。因而,本文最终确定的识别因子为CAR、Sum、ΔTurnover、INFO和Z。
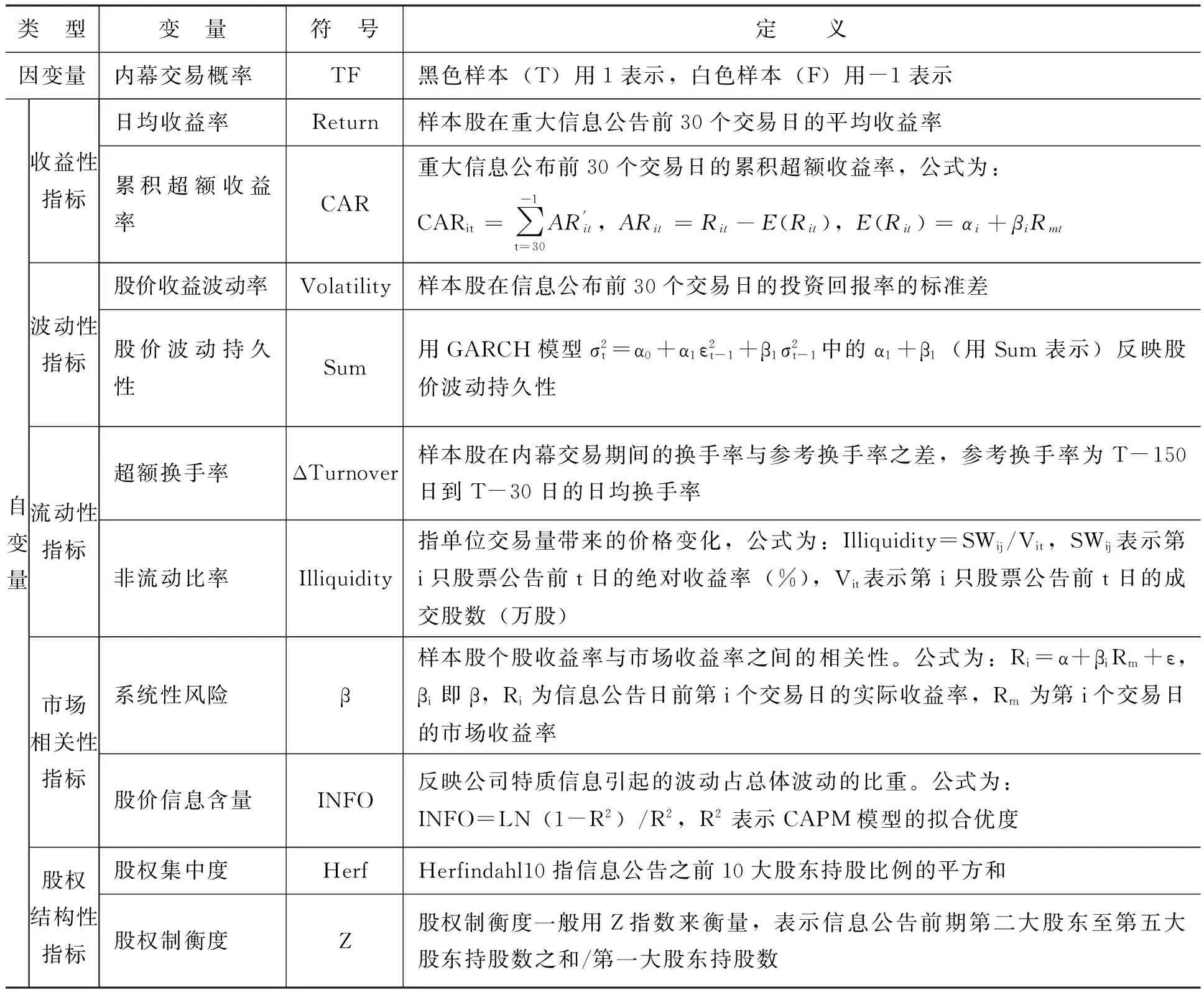
表1 研究变量说明
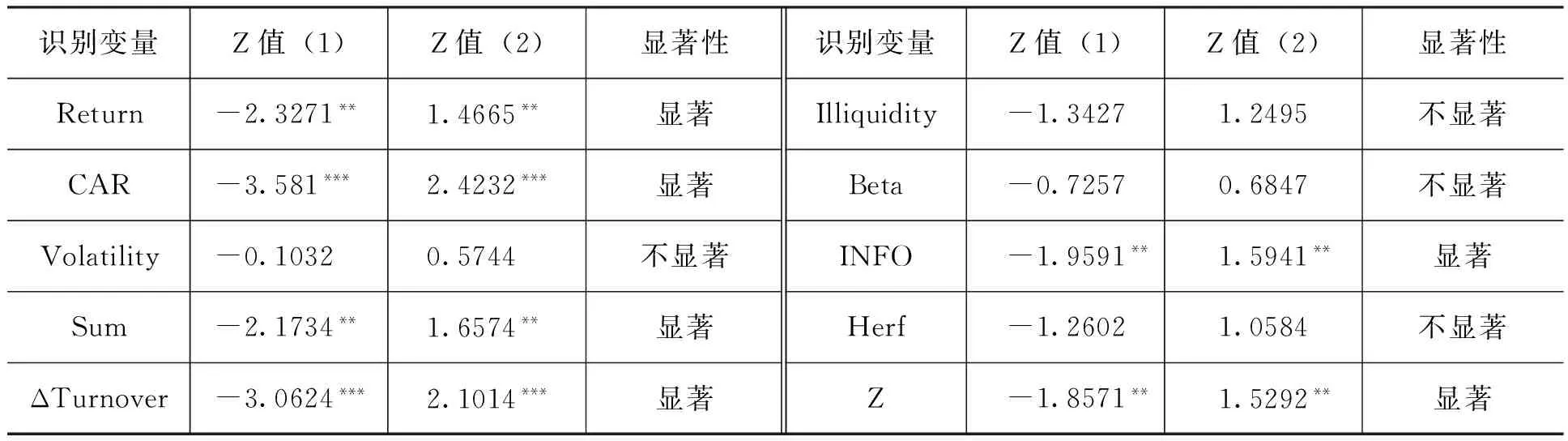
表2 两类样本各变量的非参数检验
注:为了对比两类样本各变量的差异是否显著,Z值(1)为运用非参数的Mann-Whitney U检验的Z值,Z值(2)为Kolmogorov-Smirnov检验的Z值。***和**表示在1%和5%的显著性水平下显著。
五、实证结果与分析
(一)描述性统计
我们对黑色样本与白色样本在重大信息公布之前30个交易日的识别因子进行描述性统计,表3显示了CAR、Sum、ΔTurnover、INFO及Z的描述性统计结果。

表3 两类样本识别因子的描述性统计
(二) 实证结果分析
利用Matlab7.1软件,把因变量及识别因子输入到基于支持向量机的识别模型中,模型的参数由粒子群优化算法来进行确定。在进行模型识别时,先要确定惩罚因子C的范围与步长,本文确定的C的范围是2-10—210之间,步长是0.1000。模型识别结果表明,当该模型的参数C为4.5800,σ2为3.0500时,该模型的识别效果达到最佳,总体识别准确率达到了86.18%,而国内外同类研究的总体识别准确率一般在80%左右,因而,模型的总体识别效果比较理想。训练样本的识别准确率为85.81%,说明模型对训练样本的拟合程度较高;测试样本的识别准确率达到86.73%,说明该模型对内幕交易识别的效果较好。从黑色样本与白色样本的识别准确率来看,该模型对黑色样本与白色样本的总体识别准确率分别为85.37%和86.99%,具体如表4所示。可见,上市公司重大信息公布之前30个交易日的累积超额收益率、股价波动持久性、超额换手率、股价信息含量和股权制衡度是有效识别内幕交易的重要指标。基于支持向量机的识别模型具有较高的分类精度和较好的泛化性能,适合作为我国证券市场内幕交易的识别模型。

表4 支持向量机模型的识别结果
对于有些涉嫌内幕交易的上市公司没有被识别出来,原因可能在于大盘处于弱势,内幕交易者买卖相关公司证券的数量较少,没有引起普通投资者的跟风,导致相关证券价格涨跌幅度不大,交易量变化不明显,波动幅度较小。因而,利用相关的指标难以识别,需要通过其他识别方式进行弥补,如通过云计算和大数据分析对证券交易账户在信息敏感期的异常交易数据进行识别等。
而一些上市公司被误判为内幕交易,原因可能在于这些上市公司的证券受其他因素的影响,如各种市场传闻或被人为操纵等,这些证券表现比较活跃,走势相对独立,证券价格涨跌幅度较大,交易量变化比较明显,波动性增加,这样就容易被模型误判为内幕交易。因此,对于模型识别出来涉嫌内幕交易的上市公司,还不能直接定性为内幕交易,还需要通过其他方式进一步确认。
六、研究结论
本文选取了2000年初到2015年底被中国证监会或司法机关查处的内幕交易案例作为研究的黑色样本,并按照1∶1的比例配对选取了白色样本。利用支持向量机识别模型,把上市公司重大信息公布之前30个交易日的累积超额收益率、股价波动持久性、超额换手率、股价信息含量和股权制衡度5个指标作为识别因子,对我国证券市场的内幕交易进行识别。研究表明,该模型的总体识别准确率达到了86.18%,其中,训练样本的识别准确率为85.81%,测试样本的识别准确率为86.73%,识别准确率高于同类研究水平,说明该模型的识别效果比较理想。可见,用这5个指标来识别我国证券市场的内幕交易是十分有效的。因此,中国证监会在防范内幕交易时要有所侧重,可以对这5个指标进行重点监控,并利用这些指标,建立内幕交易的识别系统,利用大数据进行实施监测,提高监管精度和监管效率,尽量减少内幕交易的发生,以保护中小投资者的合法权益,促进我国证券市场的健康发展。
[1] Jaffe, J.F.Special Information and Insider Trading[J].Journal of Business, 1974,47(3):410-428.
[2] Kyle,A.S.Continuous Auctions and Insider Trading[J].Econometrica,1985,53(6):1316-1335.
[3] Leland, H.E.Insider Trading: Should It Be Prohibited[J].Journal of Political Economy, 1992,100(4):859-887.
[4] Scott,L.S., John,T.S.Fraudulently Misstated Financial Statements and Insider Trading: An Empirical Analysis[J].The Accounting Review, 1998,73(1):131-146.
[5] Huddart, B.K.,Petronib, S.What Insiders Know about Future Earnings and How They Use It: Evidence From Insider Trades[J].Journal of Accountancy, 2003:35(3):315-346.
[6] Wu,J.Corporate Governance and Insider Trading[R].Duke University Working Paper, 2004.
[7] Beny, L.A Comparative Empirical Investigation of Agency and Market Theories of Insider Trading[R].University of Michigan Working Paper, 2004.
[8] Fernandes, N., Ferreira, M.Insider Trading Laws and Stock Price Informativeness[J].Review of Financial Studies , 2009,22(5): 1845-1887.
[9] 汪贵浦.中国证券市场内幕交易的信息含量研究[D].西安:西安交通大学博士学位论文,2002.
[10] 史永东,蒋贤锋.内幕交易、股价波动和信息不对称[J].世界经济,2004,(12) :55-65.
[11] 张宗新,潘志坚,季雷.内幕交易的股价冲击效应:理论与中国股市证据[J].金融研究,2005,(4):144-154.
[12] 李心丹,施东晖,傅浩,等.内幕交易与市场操纵的行为动机与判别监管研究[N].中国证券报,2007-08-17.
[13] 张宗新.内幕交易行为预测:理论模型与实证分析[J].管理世界,2008,(4):24-35.
[14] 黄素心.中国证券市场内幕交易的实时监控、行为甄别与最优监管[D].武汉:华中科技大学博士学位论文,2008.
[15] 唐齐鸣,张云.基于公司治理视角的中国股票市场非法内幕交易研究[J].金融研究,2009,(6):95-100.
[16] 贝政新,袁理.中国股票市场内幕交易行为甄别监控机制研究[J].上海商学院学报,2009,(5):79-84.
[17] 许永斌,陈佳.基于数据挖掘思想下的中国证券市场内幕交易判别研究[J].经济学家,2009,(1):77-84.
[18] 郭万山,钟彩艳.我国股市内幕交易行为的识别方法与实证检验[D].沈阳:辽宁大学硕士学位论文,2012.
[19] 宋力,李焕婷.证券市场内幕交易行为识别研究[J].商业经济,2012,(3):96-97.
[20] 经煜甚.我国证券市场内幕交易监管有效性及市场反应研究[D].上海:上海交通大学硕士学位论文,2014.
[21] 李香丽,孙绍荣.中国上市公司控制权市场内幕交易的ARIMA监管模型的实证研究[J].西安财经学院学报,2015,(5):35-39.
[22] Vapnik, V.N.The Nature of Statistical Learning Theory[M].New York: Springer,1995.
[23] Kumar, P.R., Ravi, V.Bankruptcy Prediction in Banks and Firms via Statistical and Intelligent Techniques: A Review[J].Expert Systems with Applications, 2007,180(1) :1-28.
(责任编辑:杨全山)
2016-08-02
国家社会科学基金项目“我国证券市场内幕信息操纵的形成与预警研究”(13BJY174);重庆市社会科学规划项目“中国股市内幕交易的形成机理与识别机制研究”(2012YBJJ028)
沈 冰(1969-),男,四川简阳人,博士,副教授,硕士生导师,主要从事金融市场与证券投资研究。E-mail:shenbing@swu.edu.cn
赵小康(1991-),男,重庆人,硕士研究生,主要从事金融市场研究。E-mail:15923531264@163.com
F830.91
A
1000-176X(2016)10-0059-07
猜你喜欢
证券市场导报(2023年9期)2023-09-22
证券市场导报(2023年6期)2023-06-09
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
证券市场导报(2017年5期)2017-11-27
法治研究(2016年4期)2016-12-01
高中生学习·高三版(2016年9期)2016-05-14
家用汽车(2016年4期)2016-02-28
新高考·高二数学(2015年11期)2015-12-23
证券市场导报(2015年5期)2015-11-22
