
基于变量组合集群分析法的小麦蛋白质近红外光谱变量选择方法研究
2016-11-30 06:23赵环宦克为郑峰石晓光
长春理工大学学报(自然科学版) 2016年5期
赵环,宦克为,郑峰,石晓光
(长春理工大学 理学院,长春 130022)
基于变量组合集群分析法的小麦蛋白质近红外光谱变量选择方法研究
赵环,宦克为,郑峰,石晓光
(长春理工大学 理学院,长春 130022)
为了解决小麦蛋白质的近红外光谱信息复杂、共线性严重及全光谱建模的预测能力不足等问题,采用一种新的变量选择方法——变量组合集群分析法(VCPA)对小麦蛋白质的近红外光谱进行特征波长选取。首先利用二进制矩阵采样策略(BMS)和指数衰减函数(EDF)删除无信息变量,优选小麦中蛋白质近红外特征波长,然后结合偏最小二乘法(PLS)建立预测模型。与其他变量选择方法相比,VCPA所选用的波长点最少,模型的预测能力最强,VCPA算法所采用的BMS变量采样策略弥补了蒙特卡洛采样方法的不足。研究结果表明,VCPA算法可以有效选择小麦蛋白质近红外光谱特征波长,提高预测模型的可靠性和适用性。
小麦;近红外光谱;变量组合集群分析法;特征波长;二进制矩阵采样;指数递减函数
随着现代化学分析仪器的发展,应用近红外光谱分析从复杂的分析系统生成的高维度化学和生物学数据时变量选择方法是一个重要的环节。变量选择的目标和意义被总结为三个层面:(1)提高模型的预测精准性;(2)通过减少维度灾难进而更快的进行模型计算;(3)提供一个更容易理解的潜在变量数据的生成过程。然而,在面对变量多样本少的情况时,在众多变量中找到一组满足上述三个方面的最佳变量组合是较难的。随着化学计量学的发展,国内外提出了大量的变量选择方法,并以不同的方式处理上述三个问题。如粒子群算法[1](PSO)、遗传学算法[2-4](GA)、无信息变量消除法(UVE)、蒙特卡洛无信息变量消除法[5](MC-UVE)和随机蛙跳算法[6](RF)等。虽然国内外提出了大量的变量选择方法,但是很少有算法考虑了变量组合因素的影响。本文首次运用了变量组合集群分析法[7](VCPA)对小麦蛋白质的近红外光谱进行了特征变量选取,该方法考虑到了所有可能有相互影响的变量的自由组合,对比其他变量选择方法的预测精准性,评价模型的预测性能,结果表明,VCPA算法是一种可行的变量选择方法。
1 实验仪器及样品采集
1.1 实验仪器
本次实验选用的光谱仪是德国卡尔蔡司的MCS611NIR光纤光谱仪,其光谱范围为950~1690nm,自制光纤束,样品皿,计算机,环带光纤耦合漫透射反射接收器和光源为OSRAM64258,12V,20W卤钨灯。每个小麦样品采集3条光谱,计算出每个样品三条吸光度的平均值,建立小麦蛋白质预测模型。
1.2 样品采集
本次实验所使用的实验数据来自国家粮食局北京东方孚德研究中心提供的93个小麦样品和93个小麦蛋白质化学值数据,选用校正集和预测集的分类方法为Kennard-Stone(K-S)算法,运用K-S算法将北京东方孚德研究中心所提供的93个小麦样品分为61个校正集和32个预测集。如表1所示:

表1 小麦的蛋白质含量值统计表
2 模型评价及光谱预处理
模型评价参数的作用是检验通过校正集样本建立的预测模型可靠性。在近红外光谱多元校正建模过程中,经常采用的模型评价参数为预测残差平方和(PRESS),交互检验均方根误差(RMSECV),预测值与实际值之间的相关系数(R)等,本次实验采用的模型评价参数分别是建模均方根误(RMSEC)、校正集决定系数(RC2)和预测均方根误差(RMSEP)。
光谱数据采集时产生的高频噪音和低频噪音会影响近红外光谱与小麦蛋白质含量之间的相关关系,进而影响预测模型的可靠性,为了避免这些高频噪音和低频噪音的影响,本文采用小波包(WTP)对光谱信号进行去噪处理,得到更加准确的小麦蛋白质近红外光谱数据[8],如图1所示。
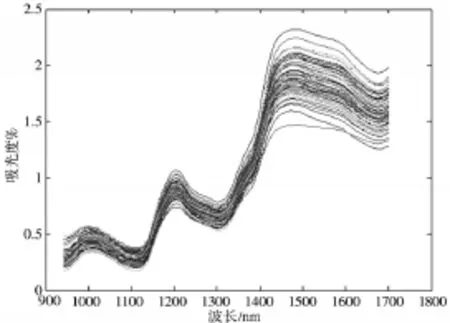
图1 WTP降噪后小麦近红外光谱图
3 VCPA特征变量选择方法的研究
3.1 VCPA算法原理
VCPA是一种新的变量选择算法,该算法首先运用二进制矩阵采样法(BMS)从变量空间中采样k组变量子集,其次运用偏最小二乘法(PLS)分别计算出这k组变量子集的RMSECV,保留RMSECV最小的σ×k组变量子集,统计这σ×k组变量子集中每个变量出现的频率,通过指数衰减函数(EDF)去掉出现频率较小的波长点,将所保留的变量重复BMS采样和EDF消除,此过程重复N次,剩余了L个光谱变量,最后计算出这L个变量之间的所有变量组合的RMSECV,其RMSECV值最小的变量组合即为最终所选取的特征变量组合。
3.2 基于VCPA的特征变量选择
VCPA算法是一种考虑了所有变量组合效应的新算法,首先应用主成分分析(PCA)得到校正集建模数据的最大主成分数为13,其次通过对其他控制参数的大量实验测试,设定为:采样次数,k=1000;迭代次数N=50;k个变量子集中优秀子集所占的比率σ=10%;二进制采样矩阵M中每个变量被采样的次数占总采样次数的百分比α=0.5,剩余变量数目L=14。
通过BMS对校正集变量进行1000次变量采样,此过程不仅能得到1000组不同的变量组合,而且还能确保每个变量具有相同的被采样概率,通过PLS分别计算出这1000组变量组合的RMSECV,得到1000个不同的RMSECV,最后选出RMSECV值最小的100组变量组合,所选的100组变量组合的RMSECV如图2所示。
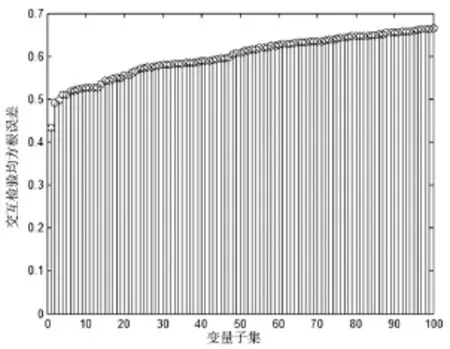
图2 二进制矩阵采样法所采样的1000个变量子集
统计这100组变量组合中每个变量出现的频率,并通过EDF删除这100组变量组合中出现频率较小的变量,得到一个新的校正集数据,之后对这个新的校正集数据继续做1000次BMS采样、RMSECV最小的100个变量组合筛选、统计每个变量出现频率和EDF变量删除。此过程循环50次之后只剩下了14个光谱变量,最后通过PLS计算出这14个光谱变量之间所有变量组合的RMSECV,其RMSECV值最小的变量组合为最终通过VCPA所选取的特征变量组合。其保留的特征光谱波长为969.5178nm,1002.711nm,1006.35nm,1115nm,1131.815nm,1138.49nm,1251.015nm,1254.12nm,1281.813nm,1561.12nm,1691.09nm。如图3所示:
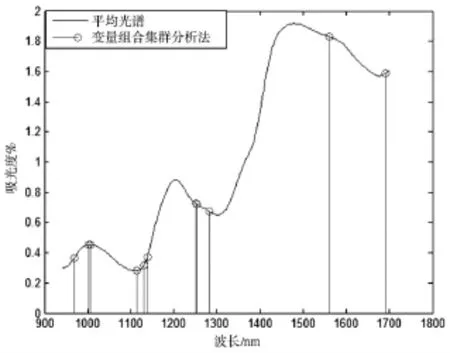
图3 平均光谱和VCPA保留的波长
运用通过VCPA选取的特征变量结合PLS建模,所得模型的RMSEC为0.2779,RC2为0.9210,RMSEP为0.3530,预测集决定系数(RP2)为0.8932,所得模型校正集的实际值与预测值之间的散点图和预测集的实际值与预测值之间的散点图如图4所示。
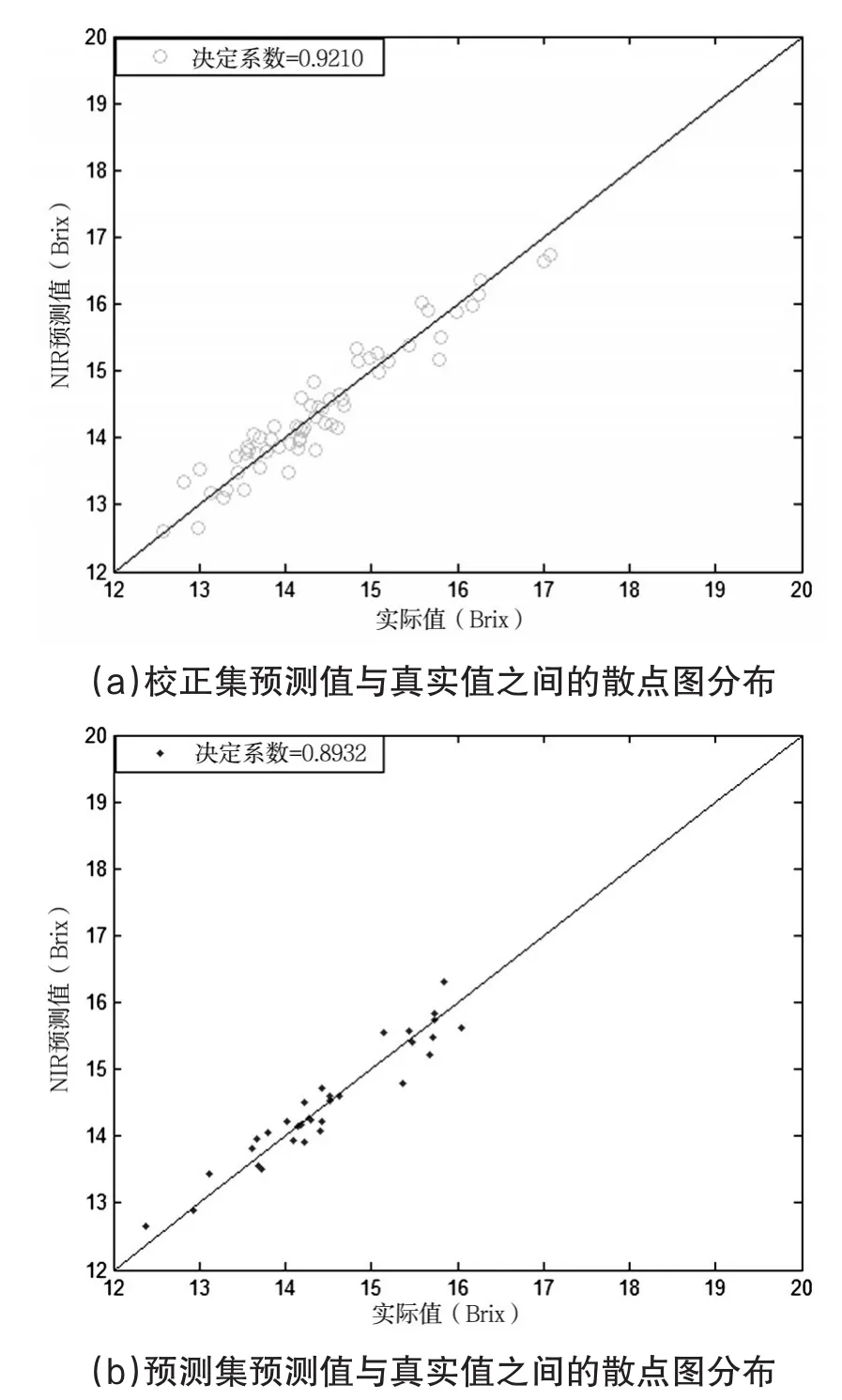
图4 基于WTP-VCPA-PLS的小麦蛋白质含量的预测值与真实值之间的散点图分布
4 结果分析
运用VCPA结合PLS所建立的小麦蛋白质含量预测模型,其预测结果对比其他建模方法GA-PLS,RF-PLS,MC-UVE-PLS和全光谱建模,结果如表2所示,为了避免每种建模方法在运行过程中随机性对变量选择结果的影响,我们将每种变量选择方法运行50次,取RMSEP最小的变量组合作为每种变量选择方法的最终运行结果。
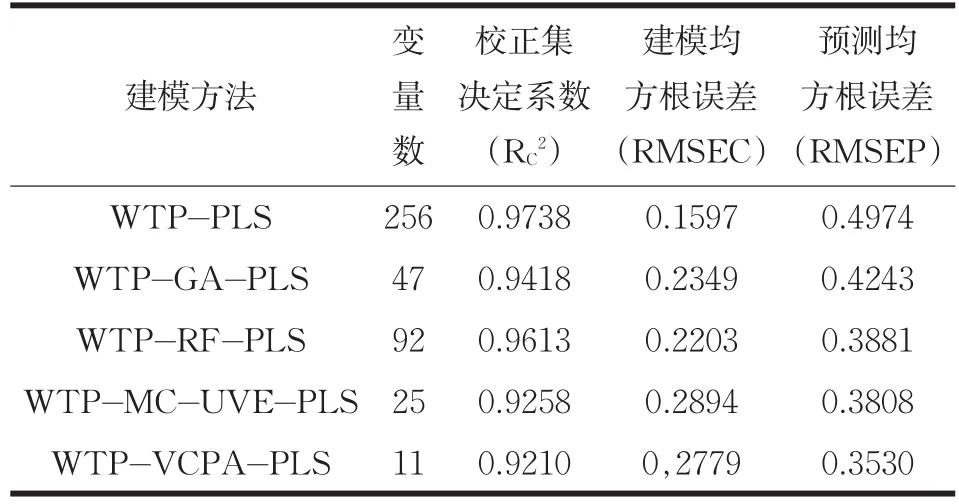
表2 小麦蛋白质含量预测结果比较
对比运用不同建模方法得到的小麦蛋白质含量的预测结果,从表2中可以看出基于每种变量选择方法的PLS所得预测精准度都要强于基于全光谱的PLS建模,这表明在建立小麦蛋白质含量预测模型前执行变量选择是必要的,相比之下,通过WTP-VCPA-PLS建立的小麦蛋白质含量预测模型精准度最佳,对比WTP-PLS的预测结果,其RMSEP由0.4974下降到了0.3530,预测精准度提升了29%,此外,WTP-VCPA-PLS,WTP-GAPLS,WTP-RF-PLS和WTP-MC-UVE-PLS都采用了较少的变量进行建模,这一现象证明了,运用较少的变量建立小麦蛋白质含量预测模型可以实现更好的预测能力。对比WTP-VCPA-PLS与WTP-GA-PLS可以看出,其RMSEP由0.4143下降到了0.3530,这是因为VCPA所采用的EDF变量删除策略每执行一次,一些贡献较小的变量就会被删除,随着EDF的执行,变量空间会越来越小,进而在更小的变量空间确立最佳变量组合,提高了有用变量之间的组合概率,避免了无信息变量和干扰变量的影响。对比WTP-VCPA-PLS与WTP-RFPLS和WTP-MC-UVE-PLS可以看出其RMSEP分别由0.3881,0.3808下降到了0.3530,这是因为WTP-RF-PLS和WTP-MC-UVE-PLS采用的蒙特卡洛采样策略不能保证每个变量具有相同的被采样概率,而VCPA所采用的BMS采样策略弥补了蒙特卡洛采样的不足。
5 结论
利用VCPA算法选择小麦蛋白质近红外特征波长,建立PLS预测模型,与全光谱PLS建立的小麦蛋白质含量预测模型相比,其RMSEP由0.4974下降到了0.3530,预测精准度提升了29%,光谱变量由全光谱的256个下降到了11个,极大的减少了变量数目,简化了模型,研究证明,VCPA算法可以有效选择小麦蛋白质近红外光谱的特征波长,简化模型,提高计算效率,增强模型的可靠性。
[1] 梁逸曾,徐青松.复杂体系仪器分析——白、灰、黑分析体系及其多变量解析方法[M].北京:化学工业出版社,2012:242-247.
[2] Leardi R.Application of genetic algorithm–PLS for feature selection in spectral data sets[J].Chemometr,2008,14(5-6):643.
[3] Leardi R,Genetic algorithms in chemometrics and chemistry a review[J].Chemometr,2001,15(7):559-569.
[4] Yun Y H,Cao D S,Tan M L,et al.A simple idea on applying large regression coefficient to improve the genetic algorithm–PLS for variable selection in multivariate calibration[J].Chemometr.Intell. Lab.Syst,2014(130):76-83.
[5] Yun Y H,Wang W T,Tan M L,et al.A strategy that iteratively retains informative variables for selecting optimal variable subset in multivariate calibration[J].Anal.Chim.Acta,2014(807):36-43.
[6] 朱逢乐,何勇,邵咏妮.应用近红外高光谱成像预测三文鱼肉的水分含量[J].光谱学与光谱分析,2015(1): 113-117.
[7] Yun Y H,Wang W T,Deng B C,et al.Using variable combination population analysis for variable selection in multivariable calibration[J].Anal.Chim. Acta,2015,862:14-23
[8] 张贺龙,邸旭,石晓光,等.基于小麦近红外漫反射光谱的小波阈值去噪方法研究[J].长春理工大学学报:自然科学版,2010,33(4):46-49.
Research on Variable Selection of Protein in Wheat Near Infrared Spectroscopy Based on Latent Projective Graph
ZHAO Huan,HUAN Kewei,ZHENG Feng,SHI Xiaoguang
(School of Science,Changchun University of Science and Technology,Changchun 130022)
In order to solve the near infrared spectra of wheat protein complex information,collinearity serious and full spectrum of modeling prediction ability is insufficient,a new method of variable selection is adopted what variable combination population analysis(VCPA) on the near infrared spectrum characteristics of wheat protein wavelength selection.Based on the features of the binary matrix sampling(BMS) and uninformative variable elimination strategy of index decreasing function(EDF),VCPA explored optimally the efficient wavelength from the NIR spectroscopy the wheat to develop models for prediction the protein of the wheat.The results showed that the performance of VCPA model was superior to the performances from others selection variables method with the least variable.Good prediction performance was obtained for protein of wheat.the BMS variable sampling strategy made up for the deficiency of the Monte Carlo sampling method.The study demonstrated that VCPA could effectively select the characteristic wavelengths of NIR spectral to improve the model robustness and applicability.
Wheat;Near infrared spectroscopy;Variable combination population analysis;Characteristic wavelengths;Binary matrix sampling;index decreasing function
O657.33
A
1672-9870(2016)05-0051-04
2016-05-05
2014年度国家公益性行业(气象)科研专项课题(GYHY201406037);2011年高等学校博士学科点专项科研基金联合资助项目(20112216110006)
赵环(1990-),男,硕士研究生,E-mail:545149375@qq.com
宦克为(1982-),男,博士,讲师,E-mail:huankewei@126.com
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
肝博士(2022年3期)2022-06-30
海外星云(2021年9期)2021-10-14
国学(2020年1期)2020-06-29
中国医学影像学杂志(2018年9期)2018-10-17
摄影之友(影像视觉)(2017年10期)2017-11-07
摄影之友(影像视觉)(2017年1期)2017-07-18
中国光学(2015年5期)2015-12-09
食品工业科技(2014年23期)2014-03-11
无机化学学报(2014年1期)2014-02-28
