
纺织科技英语强化训练的词汇分类方法
2016-11-30 02:36李岗岗赵婷婷
西安工程大学学报 2016年4期
李岗岗,赵婷婷
(运城学院 大学英语教学部, 山西 运城 044000)
纺织科技英语强化训练的词汇分类方法
李岗岗,赵婷婷
(运城学院 大学英语教学部, 山西 运城 044000)
为了提高纺织科技英语强化训练的水平,实现词汇信息的准确分类,提出一种基于英语词汇语义指向性信息素浓度聚焦和模糊C均值聚类的纺织科技英语强化训练词汇分类模型.通过分析纺织科技英语强化训练词汇分布数据结构,构建词汇语义特征序列模型,除去词汇语义指向性信息素浓度聚焦特征,采用改进的模糊C均值聚类算法实现词汇优化分类.仿真结果表明,采用该方法进行纺织科技英语强化训练词汇的分类,具有较好的语义特征聚焦性能,分类准确度较高,收敛性较好,提高了对词汇的查准性能.
纺织科技;英语强化训练;词汇分类;语义
0 引 言
纺织科技英语词汇分布复杂,对其熟练掌握的难度较高,需要进行纺织科技英语词汇强化训练,通过对用于纺织科技英语强化训练词汇进行优化分类,采用语义信息处理方法实现英语词汇的信息融合和特征提取,提高对纺织科技英语词汇强化训练的对象性和针对性.通过对纺织科技英语词汇进行语义信息融合和检索,实现词汇信息的准确分类,提高纺织科技英语强化训练水平,研究用于纺织科技英语强化训练的词汇分类方法具有重要意义.
由于纺织科技英语强化训练的词汇为一组非线性语义特征序列,采用语义本体模型构建和语义特征提取方法进行英语词汇的分类研究具有可行性.传统方法中,对用于纺织科技英语强化训练的词汇分类方法主要有K-Means法、模糊C均值聚类算法、K均值聚类算法、遗传算法、粒子群进化算法以及BP神经网络模糊控制算法等[1-3],用于纺织科技英语强化训练的词汇是通过云计算和云存储方式进行加工和处理,通过提取词汇的语义信息特征,对特征进行分类处理,结合信息融合法和分裂法实现词汇分类,根据上述原理,相关学者进行了词汇分类算法研究,其中,文献[4]提出基于混沌特征扰动模糊C均值聚类的英语词汇语义特征分解和聚类算法,采用特征分割方法进行词汇属性特征提取和统计,使得用于纺织科技英语强化训练的词汇属性特征提取过程满足收敛性要求,提高词汇数据分类的准确性,但是该算法计算开销较大,特征分类实时性不好;文献[5]提出基于序贯重采样蚁群滤波的纺织科技英语强化训练词汇优化聚类方法,该方法舍弃了低权值聚类中心的多样性信息,降低了计算开销,提高了数据聚类的收敛性,但是在较大词汇相关信息的扰动时,词汇分类的信息融合中心出现失真和位置偏移,导致词汇分类准确度下降,性能不佳[6-10].因此,提出一种基于英语词汇语义指向性信息素浓度聚焦和模糊C均值聚类的纺织科技英语强化训练词汇分类模型.构建纺织科技英语强化训练词汇分布数据结构分析和词汇语义特征序列模型,提取英语词汇语义指向性信息素浓度特征,对提取的词汇语义信息特征进行模糊C均值聚类算法研究和改进,实现词汇的有效分类,最后通过仿真实验进行了性能测试,得出有效性结论.

图 1 纺织科技英语强化训练词汇 分类总体构架Fig.1 Vocabulary classification framework of textile science and technology English intensive training
1 词汇分布数据结构分析
为了实现对用于纺织科技英语强化训练词汇的优化分类,首先需要分析用于纺织科技英语强化训练词汇在词汇信息云存储系统中的分布式结构模型,用于纺织科技英语强化训练的词汇采用的是I/O虚拟计算机和USB接口层进行词汇信息和存储和传输调度,设当前英语词汇的信息流在时序滑动窗口中的第i个语义特征几何结构本体模型记为CF=
根据图1所示的总体模型,采用字符串的匹配技术,将标记为Mountain的节点以及模型利用字符串匹配方法进行相似度特征分解,得到S1和S2间相似度的公式为
(1)
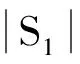
2 特征提取及模型实现
2.1 词汇语义指向性信息素浓度聚焦特征提取模型
通过对纺织科技英语词汇进行语义信息融合和检索,实现词汇信息的准确分类,可提高纺织科技英语强化训练水平.传统方法采用基于序贯重采样蚁群滤波算法的纺织科技英语强化训练词汇分类,由于特征提取过程中抗干扰性不强,词汇分类信息融合中心出现失真和位置偏移,导致词汇分类准确度下降[16-20],为了克服传统方法的弊端,本文提出一种基于英语词汇语义指向性信息素浓度聚焦和模糊C均值聚类的纺织科技英语强化训练词汇分类模型,首先给出基础概念.
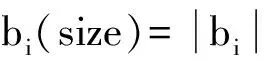
定义2 (词汇语义指向性信息素浓度的聚集交叉项)若词汇语义指向性信息素浓度特征提取的时频平面任意点(t,f)通过聚类相似性特征提取,记SB,则令聚类目标函数在采样时序i时的邻近点(t-t′,f-f′)上的近邻样本数为SBi={bi-w+1,bi-w+2,...,bi},来自多分量时频坐标(t,f)的函数为联合搜索X、Y所得到的词汇信息相似度交叉项.若词汇分类窗口数为n,则词汇语义指向性信息素浓度sbi(span)=n*p.
根据上述定义,得到词汇语义指向性信息素浓度聚焦特征对象结构的干扰向量模型表达式为

(2)
式中:a(t)为概念间层次关系本体模型的信息幅度.节点概念深度特征空间的尺度信息z(t)的瞬时幅度可通过离散傅里叶变换计算,构建词汇语义指向性信息素浓度的相关函数.假设英语词汇数据库中语义信息数据挖掘过程的特征分布的有限数据集为
(3)
式中:P(X)、P(Y)是语义内容X、Y在集合页面数的动态差异性特征.通过词汇语义指向性信息素浓度聚焦特征提取和分类,得到n个样本特征分解结果,以此为特征输入进行词汇分类.
2.2 词汇分类算法改进实现
在上述进行词汇语义指向性信息素浓度聚焦分析的基础上,在英语词汇主题特征空间中,采用领域知识和模式匹配方法,结合模糊C均值聚类进行词汇分类算法改进,在词汇语义指向性梯度下降方向,计算词汇分类融合中心权值为
(4)

(5)
对于含有n个样本的有限数据集,构造短文档向量空间,其中主题特征样本为xi,i=1,2,…,n,英语词汇语义指向性扰动矢量为
(6)
对短文档的向量空间进行相位合成,把语义特征数据集合X分为K类,采用模糊C均值算法对用于纺织科技英语强化训练的词汇进行正则化计算及加权平均,结合两个词语相似性的度量实现分类控制和模糊判决,判决函数为
(7)
式中:Vi为向量空间词汇分类中心的第i个矢量.根据个体最优和搜索词条的向量空间得到第i个聚类中心矢量,修正每个向量vi,则模糊划分矩阵表示为
(8)

图 2 用于纺织科技英语强化训练的 词汇文本特征匹配Fig.2 Lexical text feature matching for intensive training in textile science and technology English
式中:c为搜索步数;μik为最大特征值的词语泛函集,由此实现基于词汇语义指向性信息素浓度聚焦的词汇分类.利用主题词表实现对用于纺织科技英语强化训练的词汇的特征匹配,实现框图如图2所示.
根据上述分析,用于纺织科技英语强化训练词汇分类的实现步骤描述为
(1) 输入主题词中的语义特征数据集合X到语义信息搜索引擎中;
(3) 对每个文档di计算描述文本的语义信息向量vi,vi=((w1,t1),(w2,t2),…(wj,tj)),其中,wj表示文档中词汇语义指向性;tj表示wj的叙词表特征值;

(5) 对各分向量进行标引、存储和检索,通过树状层次结构进行信息拓扑,得到英语词汇分类结果集R(X)的中心向量C(X),选择搜索结果满足:
(9)
(6) 同样,计算出英语词汇Y的语义指向性信息素浓度,综合词语相似度结果确定词汇分类的中心向量C(Y),则X、Y的相似度为
(10)
根据语义相似性比较词语特征值,通过英语词汇语义指向性信息素浓度聚焦和模糊C均值聚类,实现纺织科技英语强化训练词汇分类.
3 仿真实验与结果分析
为了测试改进词汇分类算法在实现纺织科技英语强化训练词汇分类中的性能,进行仿真实验.实验采用Matlab仿真软件,仿真实验中,测试数据来自于Textile Science Technology纺织科技实验室提供的CWT200G纺织科技英语强化训练词汇分数据库,英语词汇特征信息采样的归一化初始频率f1=0.8Hz;终止频率f2=0.15Hz;纺织科技英语强化训练词汇的图一聚类空间半径设为R=16,词语相似度的特征片段阈值设为μ=12;主题词表特征空间的维度设置为20;其他参量设定为Gmax=30;D=12;c=3;NP=30;词汇分类的干扰强度扰动范围为-10~10dB;干扰比特率为0.67 Bps/s;词汇分类的加速因子为2.根据上述仿真环境和参数设定,进行用于纺织科技英语强化训练的词汇分类仿真,纺织科技英语强化训练的词汇为一组语义特征序列,进行语义特征序列时域模型构建和采样,得到两个采样通道的原始数据信息的采样时域波形,如图3所示.以上述采样的英语强化训练词汇语义特征为训练集(imf1)和测试集(imf2),进行英语词汇语义指向性信息素浓度聚焦分析,计算英语词汇分类的相似度信息,构建主题词表,得到英语词汇语义指向性信息素浓度聚焦结果如图4所示.

图 3 纺织科技英语强化训练词汇语义特征序列时域模型构建浓度聚焦 图 4 英语词汇语义指向性信息素Fig.3 Vocabulary semantic feature sequence time domain model construction of textile science Fig.4 English lexical semantic orientation pheromone concentration focusing and technology English intensive training
抽取主题词表中纺织科技英语强化训练词语对共2 902对,进行词汇分类,得到词汇分类结果如图5所示,从图可见,采用本文方法进行词汇分类,具有较好的语义特征聚焦性能,分类的准确度较高,收敛性较好.为了定量对比算法性能,采用本文方法和传统方法,以英语强化训练词汇分类查准率为测试指标进行对此分析,得到仿真结果如图6所示,从图6可见,采用本文方法进行英语词汇分类,提高了对词汇的查准性能.

图 5 主题词表词语分类输出仿真结果 图 6 查准率对比 Fig.5 Simulation results of thesaurus Fig.6 Precision comparison words classification output
4 结束语
本文提出一种基于英语词汇语义指向性信息素浓度聚焦和模糊C均值聚类的纺织科技英语强化训练词汇分类模型.通过分析纺织科技英语强化训练词汇分布数据结构构建词汇语义特征序列模型,提取英语词汇语义指向性信息素浓度特征,在此基础上,进行模糊C均值聚类算法研究和改进,实现词汇的有效分类.研究结果表明,采用本文方法进行纺织科技英语强化训练词语的语义特征分析和词汇分类,准确度较高,抗干扰性能较好,词汇查准率高,展示了较好的应用性能.
[1] 孙延.基于蚁群算法的纺织企业生产调度技术研究[J].电子设计工程,2015,23(18):116-118.
SUNYan.Researchonschedulingworkshopproductionofmoderntextileenterprises[J].ElectronicDesignEngineering, 2015, 23(18):116-118.
[2] 文天柱,许爱强,程恭. 基于改进ENN2 聚类算法的多故障诊断方法[J]. 控制与决策, 2015, 30(6): 1021-1026.
随着r提高,流经各受热面的烟气流速增加,加强了对各受热面的扰动程度,各受热面烟气对流放热系数均呈显著增长趋势。对于各受热面传热系数,随着r提高,炉膛上部分隔屏过热器及后屏过热器受热面传热系数基本不变;高温过热器传热系数略有增长;尾部烟道的省煤器传热系数增长显著。
WENTianzhu,XUAiqiang,CHNEGGong.Multi-faultdiagnosismethodbasedonimprovedENN2clusteringalgorithm[J].ControlandDecision, 2015, 30(6): 1021-1026.
[3] 邢长征, 刘剑. 基于近邻传播与密度相融合的进化数据流聚类算法[J]. 计算机应用, 2015, 35(7): 1927-1932.
XINGChangzheng,LIUJian.Evolutionarydatastreamclusteringalgorithmbasedonintegrationofaffinitypropagationanddensity[J].JournalofComputerApplications, 2015, 35(7): 1927-1932.
[4] 陶新民, 宋少宇, 曹盼东,等. 一种基于流形距离核的谱聚类算法[J]. 信息与控制, 2012,19(3): 307-313.
TAOXinmin,SONGShaoyu,CAOPandong,etal.Aspectralclusteringalgorithmbasedonmanifolddistancekernel[J].InformationandControl, 2012,19(3): 307-313.
[5]GLENTISGO,JAKOBSSONA,ANGELOPOULOSK.Block-recursiveIAA-basedspectralestimateswithmissingsamplesusingdatainterpolation[C]∥InternationalConferenceonAcoustics,SpeechandSignalProcessing(ICASSP),Florence, 2014: 350-354.
[6]SUNW,SOHC,CHENY,etal.Approximatesubspace-basediterativeadaptiveapproachforfasttwo-dimensionalspectralestimation[J].IEEETransactionsonSignalProcessing, 2014, 62(12): 3220-3231.
[7] 田刚, 何克清, 王健, 等. 面向领域标签辅助的服务聚类方法[J]. 电子学报, 2015, 43(7): 1266-1274.
TIANGang,HEKeqing,WANGJian,etal.Domain-orientedandtag-aidedwebserviceclusteringmethod[J].ChineseJournalofElectronics, 2015, 43(7): 1266-1274.
[8] 吴涛,陈黎飞,郭躬德. 优化子空间的高维聚类算法[J]. 计算机应用, 2014, 34(8): 2279-2284.
WUTao,CHENLifei,GUOGongde.High-dimensionaldataclusteringalgorithmwithsubspaceoptimization[J].JournalofComputerApplications, 2014, 34(8): 2279-2284.
[9] 辛宇,杨静,汤楚蘅,等. 基于局部语义聚类的语义重叠社区发现算法[J]. 计算机研究与发展, 2015, 52(7): 1510-1521.
XINYu,YANGJing,TANGChuheng,etal.Anoverlappingsemanticcommunitydetectionalgorithmbasedonlocalsemanticcluster[J].JournalofComputerResearchandDevelopment, 2015, 52(7): 1510-1521.
[10]LIAOLüchao,JIANGXinhua,ZOUFumin,etal.Aspectralclusteringmethodforbigtrajectorydataminingwithlatentsemanticcorrelation[J].ChineseJournalofElectronics, 2015, 43(5): 956-964.
[11] 余晓东,雷英杰,岳韶华,等.基于粒子群优化的直觉模糊核聚类算法研究[J].通信学报,2015,13(5):99
YUXiaodong,LEIYingjie,YUEShaohua,etal.ResearchonPSO-basedintuitionisticfuzzykernelclusteringalgorithm[J].JournalofCommunication, 2015,13(5):99.
[12]XINYu,YANGJing,TANGChuheng,etal.Anoverlappingsemanticcommunitydetectionalgorithmbasedonlocalsemanticcluster[J].JournalofComputerResearchandDevelopment, 2015, 52(7): 1510-1521.
[13] 马俊涛,高梅国,董健. 基于稀疏迭代协方差估计的缺失数据谱分析及时域重建方法[J]. 电子与信息学报, 2016, 38(6): 1431-1437.
MAJuntao,GAOMeiguo,DONGJian.Sparseiterativecovarianceestimation-basedapproachforspectralanalysisandreconstructionofmissingdata[J].JournalofElectronics&InformationTechnology,2016, 38(6): 1431-1437.
[14]KARLSSONJ,ROWEW,XUL,etal.Fastmissing-dataIAAwithapplicationtonotchedspectrumSAR[J].IEEETransactionsonAerospaceElectronicSystems, 2014, 50(2): 959-971.
[15]PARKHR,LIJie.Sparsecovariance-basedhighresolutiontimedelayestimationforspreadspectrumsignals[J].ElectronicsLetters, 2015, 51(2): 155-157.
[16] 刘俊,刘瑜,何友,等. 杂波环境下基于全邻模糊聚类的联合概率数据互联算法[J]. 电子与信息学报, 2016, 38(6): 1438-1445.
LIUJun,LIUYu,HEYou,etal.Jointprobabilisticdataassociationalgorithmbasedonall-neighborfuzzyclusteringinclutter[J].JournalofElectronicsandInformationTechnology, 2016, 38(6): 1438-1445.
[17]BAESH,YOONKJ.Robustonlinemultiobjecttrackingwithdataassociationandtrackmanagement[J].IEEETransactionsonImageProcessing, 2014, 23(7): 2820-2833.
[18]JIANGX,HARISHANK,THAMARASAR,etal.Integratedtrackinitializationandmaintenanceinheavyclutterusingprobabilisticdataassociation[J].SignalProcessing, 2014,14(14):241-250.
[19]LIL,XIEW.Intuitionisticfuzzyjointprobabilisticdataassociationfilteranditsapplicationtomultitargettracking[J].SignalProcessing, 2014,14(26):241-250.
[20]ZHAOH.Nationallaureatesfortextilescienceandtechnology[J].ChinaTextile, 2015,13(1):60-62.
编辑、校对:赵 放
Vocabulary classification method for intensive training of textile science and technology English
LI Ganggang,ZHAO Tingting
(Department of College English, Yuncheng University,Yuncheng 044000,Shanxi,China)
In order to improve the training of textile science and technology English,and complete the accurate classification of lexical information. A new vocabulary classification model is proposed for textile science and technology English intensive training based on the semantic orientation of English lexical semantic orientation and fuzzy C-means clustering. By vocabulary distribution data structure analyzing,a semantic feature sequence model is construded, removing lexical semantic directivity pheromone concentration focus characteristics,and using the improved fuzzy C-means clustering algorithm to achieve optimal classification of vocabulary. The simulation results show that the vocabulary classification, has better focusing semantic features, classification accuracy,and convergence, and it can improve the vocabulary recall and precision performance.
textile science and technology; English intensive training; vocabulary classification; semantic
1674-649X(2016)04-0440-06
10.13338/j.issn.1674-649x.2016.04.006
2016-02-12
运城学院教学改革项目(JG201428)
李岗岗(1985—), 男,甘肃省天水市人,运城学院讲师,研究方向为二语习得与测试及语言学.
E-mail:lgg-snow@163.com
李岗岗,赵婷婷.纺织科技英语强化训练的词汇分类方法[J].西安工程大学学报,2016,30(4):440-445.
LI Ganggang,ZHAO Tingting.Vocabulary classification method for intensive training of textile science and technology English[J].Journal of Xi′an Polytechnic University,2016,30(4):440-445.
TP391
A
猜你喜欢
电声技术(2022年4期)2022-06-15
中学生数理化(高中版.高考数学)(2021年10期)2021-12-02
声学与电子工程(2021年1期)2021-04-19
中学生数理化(高中版.高考数学)(2021年12期)2021-03-08
中学生数理化(高中版.高考数学)(2021年12期)2021-03-08
中学生数理化(高中版.高考数学)(2020年9期)2020-10-28
作文成功之路·小学版(2020年9期)2020-10-28
人大建设(2018年11期)2019-01-31
人间(2015年10期)2016-01-09
散文百家(2014年11期)2014-08-21
