
不对称内存计算平台OLAP查询处理技术研究
2016-11-29 09:34:26张延松张宇周恒王珊
华东师范大学学报(自然科学版) 2016年5期
张延松,张宇,周恒,王珊
(1.中国人民大学DEKE实验室,北京100872; 2.中国人民大学信息学院,北京100872; 3.中国人民大学中国调查与数据中心,北京100872; 4.国家卫星气象中心,北京100081)
不对称内存计算平台OLAP查询处理技术研究
张延松1-3,张宇4,周恒1,2,王珊1,2
(1.中国人民大学DEKE实验室,北京100872; 2.中国人民大学信息学院,北京100872; 3.中国人民大学中国调查与数据中心,北京100872; 4.国家卫星气象中心,北京100081)
给出了一种面向当前和未来不对称内存计算平台的OLAP查询处理技术.不对称内存计算平台是指配置有不同计算类型的处理器、不同存储访问设备的计算机,因此需要对OLAP查询处理模型按不同的计算特点进行优化存储配置和实现算法设计,从而使OLAP查询处理的不同阶段更好地适应相应的存储与计算设备的硬件特点,提高硬件设备的利用率,更好地发挥硬件的性能.提出了3阶段OLAP计算模型,将传统基于迭代处理模型的OLAP查询处理过程分解为计算密集型和数据密集型负载,分别由功能完备的通用处理器和并行计算能力强大的协处理器分而治之地完成,并最小化不同存储与计算设备之间的数据传输代价.实验结果表明基于负载划分的3阶段OLAP计算模型能够较好地适应CPU-Phi不对称计算平台,实现通过计算型硬件加速计算密集型负载,从而加速整个OLAP查询处理性能的目标.
内存计算;不对称计算平台;内存联机分析处理
0 引言
硬件技术的发展推动数据库技术的升级.计算机硬件技术发展的一个重要反映是晶体管制造工艺水平的持续提高,晶体管制造工艺主要体现在CPU/GPU和内存技术的进步. CPU制造工艺从1971年的10 μm提升到2015年的14 nm,未来还将推出7 nm工艺.随着CPU和GPU制造工艺的迅速提高,在单位面积的芯片上能够集成更多的晶体管.晶体管集成技术的提升在处理器和内存架构设计上产生了巨大的影响.如图1(a)-(f)所示,处理器在晶体管的集成技术的不同技术路线产生了不同类型的处理器.多核CPU采用了L1-L2-L3多级缓存结构,大量晶体管用于构建控制电路与LLC(Last Level Cache),仅有5%左右用于计算单元ALU,主要通过高性能缓存加速数据访问性能,图1(a)中间部分面积较大的晶体管单元为LLC.当前多核CPU已达到22个处理核心,55 MB LLC.协处理器(coprocessor,如图1(b)和1(c))Cache较小,核心数量众多但功能相对简单,大约40%的晶体管用于构建计算单元,主要通过更多的并发线程来掩盖内存访问延迟.例如NVIDIA K80双GK210核心采用28 nm工艺,集成的晶体管数量超过71亿个,每个GK210核心有2880个流处理器.代号Knights Landing的新一代Xeon Phi处理器采用14 nm工艺制造,拥有72亿个晶体管,集成了72个x86核心,搭配16 GB MCDRAM缓存.
通用处理核心的复杂数据处理能力与大规模计算核心强大的并行计算能力相结合产生了融核设计思想.图1(d)显示了AMD融核架构的APU结构,将多核处理器与GPU处理器集成到一个芯片上,使处理器同时具有两种不同的计算特性.图1(e)为下一代Intel Phi处理器Knight Landing的主处理器架构,由众核处理器直接构建主处理器,从而提供一个兼容x86架构的高性能计算平台.下一代Xeon处理器将使用Xeon+FPGA的异构计算模式[1](见图1(f)),将FPGA集成到Xeon处理器内部,提供定制的计算能力和更低的计算功耗.
存储技术同样随着晶体管集成技术的发展而不断进步.图1(h)为IBM的eXFlash DIMM内存[2],提供了基于内存插槽的非易失性大容量存储,为内存计算提供了大容量持久存储介质.图1(i)显示了3D内存的基本结构,通过芯片堆叠技术显著提升内存的容量和带宽性能,新一代采用3D芯片堆叠技术的内存架构相较于DDR3内存速度有10倍的提升.图1(j)显示了Intel的3D XPointDIMM结构[3],通过独特的3D集成技术提供非易失、大容量、高性能存储,Q可用作SSD,也可用作新型非易失内存.

图1 不同类型的处理器与存储技术Fig.1Different types of processors and memory technologies
硬件技术的飞速发展提供了多样化的存储与计算平台,也构建了一个不对称的内存计算平台,即内存计算面对的不仅是对称的多核处理器和DRAM,而且包含了多核处理器、协处理器、融核处理器和DRAM内存、非易失内存、Flash闪存等性能特征存在显著不同的异构存储与计算平台.硬件技术的发展与变化为内存数据库技术带来的直接挑战是如何将负载的特点与计算设备的特点相匹配,如何将不同访问类型的数据在不同访问特点的异构存储设备上进行分布,从而实现负载本地计算的最大化,更好地发挥新型存储和计算设备的性能.
本文探讨了基于当前和未来不对称内存计算平台硬件特征的内存OLAP查询处理技术,通过负载划分将传统的迭代处理模型分解为具有较强数据局部性的3阶段计算模型,使不同阶段的计算特征与负载特征、数据分布特征以及存储和计算硬件特征相匹配,更好地适应不对称内存计算平台的特性,提高内存OLAP查询处理的性能与效率.本文第1节介绍了研究背景及相关工作,第2节给出了基于负载特征划分的3阶段内存计算模型,第3节通过实验验证3阶段内存计算模型的性能特征,最后在第4节概括本文的工作.
1 研究背景和相关工作
1.1 研究背景
随着硬件技术的发展,内存计算平台呈现多样化的趋势.从处理器技术发展趋势来看,通用的多核处理器结构复杂、成本高昂、能耗显著、核心集成数量较少,基于对称同构多核处理器的计算平台在大规模实时分析处理领域将逐渐被异构非对称的计算型处理器所取代.
图2显示了当前和未来内存计算平台可能的技术选择.位于主板的主处理器(host processor)能够直接访问内存,需要处理器能够独立运行系统.除传统的通用多核CPU之外, AMD融核APU处理器在CPU中集成了具有较强并行计算能力的GPU,实现CPU与GPU对相同地址空间数据的直接访问与处理.Intel Phi下一代的Knights Landing采用Silvermont核心替代原来的P54C核心,可以作为主处理器使用,从而提供更加强大的内存计算能力. FPGA在一些数据密集型负载中得到广泛的应用,如Netezza使用FPGA作为数据库加速卡进行前端数据流的简单、数据密集型处理.Intel未来的Xeon处理器中将集成FPGA,面向应用定制处理器,提高处理器面向负载特征的性能.通过PCI-E通道连接的独立协处理器,如Intel Xeon Phi、NVIDIA GPGPU、FPGA等具有强大的并行处理能力,通常具有较大的本地高带宽内存,但需要通过带宽相对较低的PCI-E通道访问大容量内存,现阶段主要的技术挑战是协处理器强大的并行计算能力和PCI-E传输瓶颈之间的矛盾,未来的设备互联技术,如PCI-E 4.0、NVLink、Omni Path等技术能够大幅度提高协处理器与CPU内存或协处理器之间的数据传输性能,从而使协处理器强大的并行计算能力得到更好的发挥.

图2 不对称处理器与存储技术Fig.2Asymmetric processor and storage technologies
从内存层面来看,主存在现代3D内存技术的支持下将获得更大的容量、更高的带宽以及非易失性,是内存计算的重要高性能存储设备.协处理器内存通常为8-24 GB,一般作为协处理器的本地缓存使用,也可以作为计算密集型负载的驻留存储和计算存储.PCI-E Flash闪存卡是一种大容量存储设备,当前能够提供高达6.4TB的设备存储容量,可以作为内存计算的二级内存使用,从而提高内存计算的性价比.FPGA良好的集成性使其可以集成到大容量PCI-E Flash闪存卡中,从而实现将一部分数据处理工作下推到最底层的数据存储层.
硬件技术的日新月异为内存数据库技术提出很多技术挑战.内存数据库的算法设计以传统的基于通用多核处理器多级cache硬件架构为基础,但新兴的计算型处理器通常采用大量处理核心、更高向量处理能力、较小cache的硬件架构,因此内存数据库在算法设计上需要从cache-conscious算法设计升级为architecture-conscious算法设计,使内存数据库的关键算法设计能够更好地适应未来不同的处理器特点.同时,需要在内存数据库查询处理模型的设计上改变以同构内存访问和计算为假设的思想,需要根据不对称的计算与存储资源特点对查询处理任务进行分解,将负载的特征、数据的特征与存储和计算资源的特征相匹配,达到优化资源配置,减少不同负载处理的耦合度,提高不对称内存计算性能和效率.
1.2 相关工作分析
虽然内存数据库已经成为当前数据库的主流技术,但对内存数据库核心算法的研究仍在继续,尤其以内存连接算法研究为代表.从近年来的研究技术路线来看,一个热点讨论问题是在现代处理器硬件架构下,cache-oblivious还是cache-conscious能够获得更高的性能. cache-oblivious性能占优意味着连接算法采用简单的设计并且对不同硬件平台具有自动适应能力,cache-conscious性能占优则意味着连接算法必须挖掘硬件特性以获得更高的性能,算法复杂度相对较高.文献[4]通过实验对比了cache-oblivious的无分区哈希连接算法与cache-conscious的radix分区哈希连接算法的性能,指出无分区哈希连接算法的主要代价集中在哈希探测产生的内存访问代价,可以通过现代处理器支持的并发多线程和自动预取机制提高性能;radix分区哈希连接算法的主要代价集中在radix分区过程,时间和空间代价均较高,但哈希探测性能较高.文献[5]进一步优化了[4]的算法设计,通过SIMD等硬件技术进一步优化算法性能,从而使radix分区哈希连接算法优于无分区哈希连接算法,证明了基于硬件特性的优化技术仍然能够带来更高的性能.文献[6]通过SIMD技术对排序归并算法和哈希算法进行优化,radix分区哈希连接算法的综合性能最优,证明了radix分区哈希连接算法的优势.
内存数据库的算法研究同样延伸到众核协处理器平台.在文献[7]中,radix连接的radix分区操作在CPU端执行,分区后的数据传输到GPU端,通过nested loop或二分查找算法完成分区数据上的连接操作.GPU相对CPU拥有大量的核心与硬件级并发线程,内存访问的优化不同于CPU通过cache缓存减少内存访问延迟,而是通过大量并发内存访问线程掩盖内存访问延迟,因此更加适合cache-oblivious的无分区哈希连接算法[8,9].文献[10]进一步探索了基于融核APU上的查询优化技术,通过协同CPU与GPU核心的任务调度和优化不同内核之间的数据共享访问提高查询处理性能.相对于GPU需要用CUDA或OpenCL对算法重写,Xeon Phi由于其与x86兼容的指令系统而更容易从CPU平台迁移到Xeon Phi协处理器平台.文献[11]将文献[5]提供的开源哈希算法优化为Xeon Phi版本并进行测试,实验结果表明Xeon Phi的众多核心和更多的线程能够有效地降低内存访问延迟,cache-oblivious的无分区哈希连接算法较CPU平台有较大的性能提升,甚至优于radix分区哈希连接算法的性能.最新的研究[12]对算法再次进行全面的SIMD优化设计,挖掘了Xeon Phi 512位向量处理能力,进一步优化了算法在Xeon Phi端的性能,并使radix分区哈希连接算法再次优于无分区哈希连接算法.值得注意的是,Xeon Phi与CPU具有类似的L1-L2 cache结构,因此经过充分优化后具有与CPU类似的性能特征.但radix分区哈希连接算法需要双倍的内存空间来支持对两个连接表的radix分区操作,降低了Xeon Phi协处理器有限内存的利用率.内存哈希连接算法的研究同样扩展到FPGA平台[13],FPGA相对于CPU支持更深的流水线和数以千计的并发内存访问线程,不借助cache机制而达到较高的内存访问性能,在相似内存带宽性能的CPU和FPGA平台上基于文献[5]的两种内存哈希算法较CPU平台有成倍的性能提升.除通用的内存哈希连接算法之外,文献[14]研究了OLAP中基于主-外键参照完整性约束关系和代理键机制[15]的外键连接优化技术,通过对OLAP模式的分析提出了代理键地址映射机制,并基于数组存储模型设计了以维代理向量参照地址访问为基础的数组地址参照访问AIR算法,并通过Benchmark测试验证了其较好的性能.AIR算法是一种依赖简单数组存储和数组地址访问操作的外键连接算法,算法效率高并且易于向协处理器平台迁移.
哈希连接是内存数据库最重要的算法,也是内存OLAP性能决定性的操作符.连接操作性能优化技术研究的一个显著趋势是借助先进硬件的性能获得提升,需要使算法设计与硬件特点相匹配.在未来的处理器技术中,Intel Xeon Phi KNL可以将整个板上内存用作16 GB的L3 cache,提高了cache-oblivious算法优化的应用范围,而NVIDIA GPGPU、FPGA等处理器则更加注重大规模并发线程的内存访问性能,因此,在内存连接算法的研究上不能完全依赖cache-oblivious或者cache-conscious设计,而要使算法具有对不同类型硬件平台的适应性,提高内存利用率,优化内存随机访问性能.
2 不对称内存计算平台OLAP查询优化技术
处理器和存储技术的分化产生了不对称的内存计算平台,查询处理的整个过程被物理地分配给不同硬件性能特点的存储设备和处理器,因此,如何减少数据在不同处理器和存储设备之间的传输代价、使查询负载适合不同的处理器计算特性对于提高不对称内存计算平台的性能和效率具有重要的意义.
2.1 内存OLAP不对称存储模型
OLAP模型是一种多维数据模型,由数量众多但数据量极小的维表和巨大的事实表构成,维表由主键和代表维层次等属性的描述性字段构成,事实表由维表外键和代表数量关系的度量属性组成.

图3 SSB不同类型数据量和查询时间占比Fig.3Proportions of Different Datasets and Processing Time of Star Schema Benchmark
以SSB数据集为例(SF=100,事实表包含600 000 000记录),如图3所示,四个维表数据量占比为0.86%,事实表外键数据量占比为19.34%,事实表度量列数据量占比为79.80%;在[14]中基于AIR算法的维表处理、外键连接和聚集计算三个阶段执行时间占比分别为7.11%、86.43%和6.46%.20%的外键列上的计算代价超过OLAP查询总代价的80%,而这部分外键连接操作适合通过新兴的计算型处理器进行加速,较小的外键通常能够实现协处理器内存驻留存储,从而最小化内存与协处理器之间的PCI-E数据传输代价.以SSB数据集为例,在SF=100的数据集中四个外键列大小为9.6 GB,小于主流Xeon Phi与GPGPU的16 GB和24 GB内存,也就是说一个协处理器可以支持SF=100的OLAP外键存储和其上的连接加速任务.
在内存OLAP应用中,维表数据量和其上的选择、投影、分组等操作执行时间较短,维表可采用内存存储或闪存存储.事实表外键相对于度量列较小,但其上的外键连接操作占OLAP查询时间的比重最高,属于计算密集型负载,需要将其驻留存储于最接近计算单元的存储设备中,如协处理器内存或主存.事实表度量列数据量最大,但其上的聚集计算执行时间较短,属于数据密集型负责,可以将其存于闪存等低成本、大容量存储设备中以提高内存OLAP查询处理的性价比.
2.2 内存OLAP三阶段计算模型
我们以数据为中心,将OLAP查询处理分解为三个独立的计算阶段.第一阶段是维表处理阶段,将OLAP查询中维表上的选择、投影、分组操作应用在维表上,生成分组投影向量,并对分组投影向量采用轻量字典表压缩,将投影出的分组成员存储在数组字典表中,数组下标作为压编码更新到分组投影向量中.第二阶段是事实表外键列计算阶段,事实表外键与维表投影向量执行外键连接操作,与分组投影向量连接的结果存储在度量向量中,记录每个事实表记录是否满足连接条件及相应的多维形式的分组编码.第三阶段通过度量向量在事实表度量列上执行分组聚集计算,度量向量起到位图索引的作用,按位置访问OLAP查询相关的度量属性列,并根据度量向量中存储的多维分组编码进行聚集计算.三个计算阶段之间输入与输出的是较小的维表分组投影向量和事实表度量向量,在数据按存储和计算设备划分时能够最小化不同计算任务之间的数据传输代价.
在维表处理阶段,我们使用基于代理键的外键连接技术.在数据仓库中具有主-外键参照完整性约束关系的被参照表中使用代理键[15]作为主键,然后更新外键为代理外键.OLAP查询在维表上的操作生成代理向量,即以代理键为偏移地址的向量,外键连接操作转化为向代理向量的地址映射访问,即文献[14]所述的AIR算法.我们进一步放松了文献[14]中基于数组存储的强约束条件,通过逻辑代理键保持被参照表主键逻辑地址映射特性,解决了数据库异位更新机制(out-of-place update)导致的代理键与物理偏移地址不对应问题.图4显示了逻辑代理键映射机制的实例,其中surrogate key列为逻辑代理键列,数据库只需要维护代理键唯一、连续分配,并不需要保持物理存储顺序.查询结果输出为代理向量,即以逻辑代理键为下标的向量,投影操作的结果映射到逻辑代理键值对应的向量单元中,由代理向量与外键列完成基于代理键地址映射的外键连接操作.

图4 逻辑代理键映射Fig.4Logical surrogate key mapping
OLAP查询在维表上按WHERE子句投影出GROUP BY子句对应的分组属性作为代理向量,代理向量中的空值代表对应逻辑代理键记录不满足WHERE谓词条件,非空值作为当前维上输出的分组属性分量.代理向量通过字典表数据压缩将OLAP查询投影出的分组向量进一步压缩,通过数组字典表存储代理向量中的分组值,以分组字典数组下标作为代理向量压缩编码.在SSB和TPC-H大部分OLAP查询中分组为低势集,维表上的代理向量通常可以压缩为int 8类型(表示28-1个分组).由于维表较小且涉及复杂的数据类型、函数及表达式处理,维表处理阶段由CPU负载,并输出经过字典表压缩后的分组投影向量.
在事实表外键列计算阶段,基于代理键地址引用访问的AIR算法将哈希连接算法简化为外键向代理向量的地址映射访问,从而消除了复杂的哈希表设计,提高了AIR算法的代码执行效率,并且易于向GPU、Xeon Phi、FPGA等复杂数据管理能力弱、并行计算能力强大的协处理器进行部署.图5描述了在不对称内存计算平台上的外键连接实现策略.当协处理器为主处理器或者与CPU访问相同的内存地址空间时,由并行计算能力更加强大的协处理器(如APU中的GPU单元、Xeon Phi KNL主处理器、FPGA、Xeon+FPGA中的FPGA单元等)执行事实表外键连接操作,并生成度量向量.度量向量由各维代理向量分组压缩编码构造的多维数组地址编码构成,通过多维地址编码进一步压缩多分组属性存储空间.

图5 基于代理键参照访问的外键连接实现Fig.5Surrogate key referencing oriented foreign key join implementation
当协处理器为PCI-E加速卡时,如NVIDIA GPGPU、Xeon Phi、FPGA加速卡等,我们将PCI-E加速卡的本地内存作为外键列存储器,加速OLAP的外键连接操作.对于给定的OLAP数据集,PCI-E加速卡加速全部外键连接操作所需要的内存大小为,其中wi表示n个外键宽度及度量向量宽度,R表示外键列行数.当数据集较大时,可以根据需求配置多个加速卡实现计算密集型外键连接操作的内存计算.较小的维代理向量在OLAP查询执行时由CPU通过PCI-E通道传输到加速卡内存执行外键连接操作,生成度量向量通过PCI-E通道传输回CPU内存,完成后续的聚集计算,或者由协处理器基于度量向量通过PCI-E卡间的通道访问PCI-E Flash闪存卡完成聚集计算任务.
在聚集计算阶段,度量向量中存储的多维数组压缩编码可以作为分组键值执行哈希分组聚集计算;当多维分组压缩编码较小时,即多个分组压缩编码所构建的多维数组较小(通常低于LLC slice,即2.5 MB,支持655 360个int类型分组聚集结果)时,可以使用多维数组进行聚集计算,度量向量中存储的多维数组压缩编码直接映射为多维数组下标.
当在PCI-E大容量Flash闪存卡上集成了FPGA时,可以进一步将聚集计算阶段下推到Flash闪存卡的FPGA单元中.度量向量传输到Flash闪存卡,由嵌入式FPGA根据度量向量按位置访问度量列并执行基于多维数组的分组聚集计算,减少度量列在PCI-E通道的传输代价.在聚集计算算法设计中只使用向量和多维数组,算法易于在FPGA中实现.
2.3 不对称内存计算平台OLAP查询处理基本策略
通过前面的算法设计,我们实现了OLAP模式中具有典型的复杂数据管理特征的维表、具有计算密集型处理特征的事实表外键列、具有数据密集型访问特征的事实表度量列在不同存储层次上的分布以及与数据相关的计算负载在不同处理单元上的分布,将负载的特征与处理单元的特征相结合,计算密集型的外键连接操作由并行计算能力强大的协处理器完成,从而实现通过硬件加速卡加速OLAP关键操作性能的目标.
本文提出的3阶段计算模型的意义是将OLAP查询中数据量占比20%但计算量占比80%的计算密集型外键连接负载独立出来,并通过代理键索引机制简化外键连接算法,使其更易于部署在协处理器上进行加速.三个计算阶段之间通过简单的向量数据结构进行驱动, Q减少了数据传输量,也简化了后续计算的复杂度.基于度量向量的聚集计算将位图索引访问和多维数组聚集计算结合起来,简化算法设计,使之更加易于部署在嵌入式FPGA等芯片中而集成到Flash卡中,实现存储设备上的计算.
简化每个阶段的数据结构与算法设计,将查询处理过程解耦合为向量驱动的独立计算过程等优化技术可以根据不对称内存计算平台的资源灵活分配不同的负载任务,提高存储和计算资源的利用率,更好地利用硬件加速器提升关键计算性能,优化OLAP查询性能.
3 实验分析
不对称内存计算平台查询优化技术的核心是通过众核协处理器的高并行处理性能加速OLAP查询中最为关键的外键连接操作的性能,从而起到通过硬件协同处理加速OLAP整体性能的效果.我们在文献[16]已验证基于GPU的3阶段OLAP计算模型的性能,其性能的决定因素为事实表外键连接性能.
为验证众核协处理器对外键连接操作的加速效率,我们在一台DELL PowerEdge R730服务器上进行外键连接算法测试,服务器配置有2块Intel Xeon E5-2650 v3@2.30 GHz 10核CPU,共20个核心,40个线程,512 GB DDR3内存.操作系统为CentOS,Linux版本为2.6.32-431.el6.x86 64,gcc版本为4.4.7.服务器配置了一块Intel Xeon Phi 5110P@1.053 GHz协处理器,其中集成了60个核心,每核心支持4线程,共计240线程,Phi 5110P协处理配置有8 GB内存,协处理器内置操作系统的Linux版本为2.6.38.8+mpss3.3,gcc版本为4.7.0.服务器还配置了一块NVIDIA K80 GPU加速卡,K80拥有4992 cuda核心和24 GB GDDR5显存,显存带宽达到480 GB/s.
我们在文献[5]提供的开源NPO、PRO算法的基础上增加了AIR算法.在数据生成器中屏蔽了对R表的shuffler过程,使R表使用代理键作为主键,S表需要进行shuffler过程,使之符合主-外键约束的一般场景.AIR算法实现中模拟了R表上的谓词操作,在NPO算法的BUILD过程对R表进行过滤,生成R表代理向量,然后S表根据主键映射到R表代理向量,完成连接操作.AIR算法生成的R表代理向量可以使用不同的数据类型,如int 8、int 16或int 32,根据对SSB、TPC-H等查询中维表分组投影的分析,我们主要使用int 8作为过滤器数据类型,模拟维过滤位图及分组向量存储.在实验中R表和S表采用int 32数据类型key和payload,key的值域(232-1)能够满足数据仓库维表主键的取值范围,考虑到内存数据库普遍采用数据压缩技术,我们在实验中并未使用int 64数据类型.我们在测试中对比2块Xeon CPU与1块Xeon Phi协处理器的性能,CPU端算法测试设置为40线程,Xeon Phi端算法测试设置为240线程.
3.1 测试数据集
我们首先对比了文献[5]使用的Workload A和B,其数据集对应的连接表R和S的设置如表1所示.我们将Workload A和B中的key与payload数据宽度统一设置为4字节,能够满足OLAP应用中主键的值域和基于压缩技术的数据存储需求.

表1 参考负载测试集Tab.1Referenced workloads dataset
为更好地分析不同的外键连接算法在内存OLAP中的性能,我们模拟典型OLAP Benchmark中的外键连接操作,选用的数据集为SSB、TPC-H和TPC-DS中相应的外键连接操作,包括维表与事实表之间的外键连接操作以及具有主-外键参照完整性约束关系的事实表之间的外键连接操作,数据集大小设置为SF=100,对应TPC-H网站官方测试的最小数据集.各数据集中连接表的记录行数如表2所示.

表2 基准测试数据集Tab.2Datasets for benchmark testing
3.2 外键连接性能测试结果分析
由于Intel Xeon E5-2650 v3与Intel Xeon Phi 5110P的主频不同,因此我们以纳秒每记录(ns/tuple)作为性能指标.
图6显示了AIR、NPO和PRO外键连接算法在CPU和Xeon Phi端的执行性能,其中无分区哈希连接算法NPO的主要代价是共享哈希表内存访问,Xeon Phi的并发多线程内存访问机制能够提高内存访问性能,因此NPO的性能在Xeon Phi端较高;PRO算法依赖于cache大小进行优化,CPU具有更高的每核心cache大小,而Xeon Phi上有更高的并发处理线程,总体来看,其性能在CPU端和Xeon Phi端差距不大;AIR算法中的代理向量较小,CPU较大的cache能够较好地加速其性能,当R表较小时,CPU较大的cache使AIR算法在CPU端的性能优于Xeon Phi端,当R表较大时,CPU的cache缓存优化和Xeon Phi的多线程优化具有类似的性能.需要注意的是,我们在实验中使用2块Xeon 10核处理器与1块Xeon Phi 60核协处理器进行性能对比,单Xeon Phi协处理器的性能与2块Xeon 10核处理器持平.
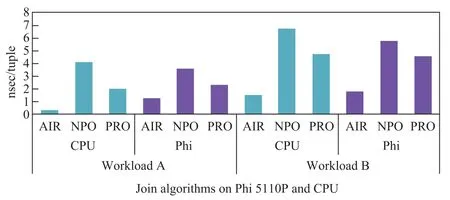
图6 外键连接算法性能对比Fig.6Performance comparison for foreign key join algorithms
图7显示了SSB和TPC-H基准中各外键连接操作在CPU和Xeon Phi上的性能对比.首先,AIR使用代理向量的内存开销低于NPO算法中的哈希表,因此能够支持全部测试,而NPO在TPC-H中较大的连接表时超出Xeon Phi的内存而不能执行,PRO算法的raidx分区操作需要2倍的内存空间,在SSB和TPC-H测试中超出内存容量而不能执行测试.从算法内存效率来看,AIR优于NPO,NPO优于PRO.其次,从算法性能来看,SSB数据集中维表较小,更适合CPU较大cache上的优化,因此AIR算法与NPO算法在CPU上的性能优于Xeon Phi上的性能.TPC-H除supplier表较小外其他表均较大,在大表连接时Xeon Phi的性能优于CPU.
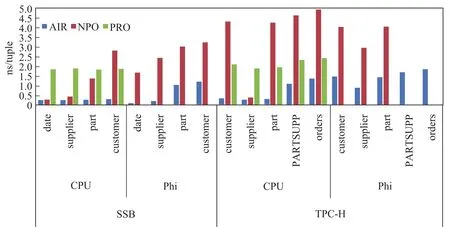
图7 SSB、TPC-H基准外键连接算法性能对比Fig.7Performance comparison for foreign key join algorithmsin SSB and TPC-H
TPC-DS相对于SSB和TPC-H有更多的维表,但维表记录数量较少且记录增长缓慢.AIR算法的代理向量通常低于L2 cache,因此Xeon Phi与CPU都有较好的cache访问性能,Xeon Phi更多的线程使AIR算法的性能优于CPU.NPO算法在较少和中等记录量时CPU的性能优于Xeon Phi,在较大记录量时Xeon Phi的性能优于CPU.PRO算法在CPU端的性能略优于Xeon Phi端的性能,CPU较大的cache和较高的主频更加有利于PRO算法性能的提高.
总体来说,AIR算法在较小维表时在Xeon Phi有较好的加速性能,PRO算法在Xeon Phi上也有接近一倍的性能提升(图7和图8中1块Xeon Phi与2块Xeon多核CPU性能接近).在当前PCI-E形式的Xeon Phi协处理器中,AIR算法更适合较小维表对应的外键连接操作,不仅维表代理向量传输代价低,而且能够获得较高的性能收益,当维表较大时,AIR算法更适合在CPU平台上执行.NPO算法则适合于较大维表的外键连接操作,但维表子集在PCI-E通道传输代价也相应较高.PRO算法虽然加速性比较稳定,但其2倍的内存空间消耗降低了Xeon Phi协处理器内存的利用率.未来Xeon Phi KNL主处理器可以直接访问内存数据,更加适合较大表的外键连接操作加速.

图8 TPC-DS外键连接算法性能对比Fig.8Performance comparison for foreign key join algorithms in TPC-DS

图9 NVIDIA GPGPU K80外键连接算法性能对比Fig.9Performance comparison for foreign key join algorithms on NVIDIA GPGPU K80
我们用CUDA语言实现AIR算法,并在最新的NVIDIA GPGPU K80上执行以上各Benchmark的外键连接性能测试.K80使用了4992个流处理器,具有极强的并行处理能力.图9列出了本文所使用的SSB、TPC-H、TPC-DS、Workloads等Benchmark中的外键连接操作使用AIR算法(CPU)、AIR算法(Phi)、NPO(Phi)、PRO(Phi)以及AIR算法(GPU)时的查询执行总时间,其中AIR算法(GPU)执行时间极短,我们使用了另一个较小的坐标轴标示其外键连接执行时间.图9中可以看到,AIR算法在2块10核Xeon E5-2650 v3CPU上与1块Xeon Phi 5110P协处理器上具有较好的外键连接执行性能,均低于哈希连接算法NPO和PRO在Xeon Phi协处理器上的执行时间.AIR算法在K80 GPU上的执行时间几乎为常量,稳定在30-45微秒之间,其众多的cuda核心、高并发内存访问线程和高带宽内存在AIR算法的代理外键内存访问时有极高的性能.
以上实验在中高端10核处理器Xeon E5-2650 v3、中端Xeon Phi 5110P协处理器、高端的NVIDIA GPGPU K80上的实验结果证明了AIR算法对于cache优化(Xeon E5-2650 v3、Xeon Phi 5110P)及并发内存访问优化(K80)都有较好的性能与适应性,适合在未来不对称处理器平台上面向计算密集型处理器的负载优化,并通过先进硬件性能的优化加速OLAP查询整体性能.
4 结论
本文给出了一种面向未来不对称内存计算平台的OLAP查询优化技术,其主要设计思想体现在3个方面:①通过schema-conscious设计和代理键索引机制的优化工作提出了基于代理向量参照访问的外键连接技术,消除复杂的内存哈希表结构,简化连接操作数据结构与算法设计,提高外键连接操作的代码执行效率,使算法更好地适应cache及并发多线程内存访问机制,提高算法对cache-conscious和cache-oblivious设计的适应性;②通过对OLAP查询处理过程的重组,将SPJGA操作分解为SPG+J+A三个计算阶段,分别绑定较小的维表、固定大小的事实表外键列及较大的事实表度量列,实现数据密集型任务与计算密集型任务在数据集上的划分,有效地分离了不同类型的负载,通过基于向量数据结构的优化最小化三个计算阶段之间的数据传输代价;③基于不同类型的不对称计算及存储架构提出了基于3阶段计算模型的分布式存储与计算策略,将数据密集型负载与计算密集型负载在通用处理器与计算型处理器之间优化配置,通过新兴的众核协处理器加速决定OLAP性能的外键连接操作,达到提高性能和降低系统改写代价的目标.
实验结果表明,基于代理键索引机制和代理向量参照访问的外键连接操作的性能较传统的内存哈希连接算法具有更高的性能和更加简单的实现技术,能够更加灵活地适应以cache为中心和以并发内存访问为中心的不同类型硬件体系结构,在通用CPU和众核协处理器平台均有较优的性能,其简化的算法设计进一步降低了迁移到未来众核协处理器平台的代价.
[1]SEBASTIAN ANTHONYIntel unveils new Xeon chip with integrated FPGA,touts 20x performance boost [EB/OL].(2014-01-19)[2015-12-25].http://www.extremetech.com/extreme/184828-intel-unveils-new-xeon-chipwith-integrated-fpga-touts-20x-performance-boost.
[2]JIM H.IBM launches flashDIMMs[EB/OL].(2014-01-20)[2015-12-25].http://thessdguy.com/ibm-launchesflash-dimms/.
[3]ANTON S.Intel:First 3D XPoint SSDs will feature up to 6GB/s of bandwidth[EB/OL].(2015-08-28)[2016-03-16].http://www.kitguru.net/components/memory/anton-shilov/intel-first-3d-xpoint-ssds-will-feature-up-to-6gbs-of-bandwidth/.
[4]BLANAS S,LI Y,PATEL J M.Design and evaluation of main memory hash join algorithms for multi-core CPUs [C]//SIGMOD.2011:37-48.
[5]BALKESEN C,TEUBNER J,ALONSO Get al Main-memory hash joins on multi-core cpus:Tuning to the underlying hardware[C]//ICDE.2013:362-373.
[6]ALBUTIU M-C,KEMPER A,NEUMANN T Massively parallel sort-merge joins in main memory multi-core data-base systems[J].VLDB Endowment,2012,5(10):1064-1075.
[7]HE B,YANG K,FANG Ret al.Relational joins on graphics processors[C]//SIGMOD.2008:511-524.
[8]YUAN Y,LEE R,ZHANG XThe yin and yang of processing data warehousing queries on GPU devices[J]. PVLDB,2013,6(10):817-828.
[9]PIRK H,MANEGOLD S,KERSTEN M L.Accelerating foreign-key joins using asymmetric memory channels [C]//ADMS@VLDB.2011:27-35.
[10]HE J,LU M,HE B.Revisiting co-processing for hash joins on the coupled CPU-GPU architecture[J].VLDB Endowment,2013,6(10):889-900.
[11]JHA S,HE B,LU M,et al.Improving main memory hash joins on Intel Xeon Phi processors:an experimental approach[J].Proceedings of TheVldb Endowment,2015,8(6):642-653.
[12]POLYCHRONIOU O,RAGHAVAN A,ROSS K A.Rethinking SIMD vectorization for in-memory databases [C]//SIGMOD Conference.2015:1493-1508.
[13]HALSTEAD R J,ABSALYAMOV I,NAJJAR W A,et al.FPGA-based Multithreading for In-Memory Hash Joins[C]//Conference on Innovative Data Systems Research.2015.
[14]ZHANG Y,ZHOU X,ZHANG Y,et al.Virtual Denormalization via Array Index Reference for Main Memory OLAP[J].IEEE Transactions on Knowledge and Data Engineering,2016,28(4):1061-1074.
[15]ALEKSIC S,CELIKOVIC M,LINK S,et al.Face off:Surrogate vs.natural keys[C]//Advances in Databases and Information Systems-14th East European Conference.2010:543-546.
[16]张宇,张延松,陈红,等.GPU semi-MOLAP:一种适应GPU的混合OLAP查询处理模型[J].软件学报,2016,27(5): 1246-1265.
(责任编辑:李万会)
Research on OLAP query processing technology for asymmetric in-memory computing platform
ZHANG Yan-song1-3,ZHANG Yu4,ZHOU Xuan1,3,WANG Shan1,2
(1.DEKE Lab,Renmin University of China,Beijing100872,China; 2.School of Information,Renmin University of China,Beijing100872,China; 3.National Survey Research Center at Renmin University of China,
Beijing100872,China; 4.National Satellite Meteorological Center,Beijing100081,China)
This paper proposes an OLAP query processing technology for nowadays and future asymmetric in-memory computing platform.Asymmetric in-memory computing platform means that computer equips with different computing feature processors and different memory access devices so that the OLAP processing model needs to be optimized fordifferent computing features and implementation designs to enable the different processing stages to adapt to the characteristics of corresponding storage and computing hardware for higher hardware utilization and performance.This paper proposes the 3-stage OLAP computing model,which divides the traditional iterative processing model into computing intensive and data intensive workloads to be assigned to general purpose processor with full fledged functions and coprocessor with powerful parallel processing capacity.The data transmission overhead between different storage and computing devices is also minimized. The experimental results show that the 3-stage OLAP computing model based on workload partitioning can be adaptive to CPU-Phi asymmetric computing platform,the acceleration on OLAP query processing can be achieved by accelerating computing intensive workload by computing intensive hardware.
in-memory computing;asymmetric computing platform;in-memory OLAP
TP311
A
10.3969/j.issn.1000-5641.2016.05.011
1000-5641(2016)05-0089-14
2016-05
国家863计划项目(2015AA015307);中央高校基本科研业务费专项资金项目(16XNLQ02);华为创新研究计划(HIRP 20140507,HIRP 20140510)
张延松,男,博士,副教授,研究方向为内存数据库.E-mail:zhangys ruc@hotmail.com.
张宇,女,博士,研究方向为OLAP,GPU数据库.E-mail:zyszy511@hotmail.com.
猜你喜欢
科学与财富(2021年4期)2021-03-08 10:14:32
科学与财富(2020年34期)2020-03-11 18:58:06
当代陕西(2019年13期)2019-08-20 03:54:22
软件导刊(2018年3期)2018-03-26 02:14:46
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
计算机工程(2014年6期)2014-02-28 01:25:40
电子设计工程(2014年12期)2014-02-27 11:58:03
测绘科学与工程(2014年5期)2014-02-27 07:06:14
电脑爱好者(2009年13期)2009-07-07 09:52:52
