
高效优化的XML索引推荐系统
2016-11-29 02:54徐谦
哈尔滨师范大学自然科学学报 2016年2期
徐 谦
(黑龙江工程学院)
高效优化的XML索引推荐系统
徐 谦
(黑龙江工程学院)
XML数据库日益庞大,日益高度结构化,查询也越来越复杂.提出一种XML索引推荐系统,它紧密联结查询优化器,能够解决XML索引推荐问题.
XML索引;查询优化器;候选索引集;评估配置
0 引言
XML语言的丰富性和优化配置潜在的复杂性,为XML索引推荐带来巨大难度,使搜索算法作用显著.提高优化器效率,减少其评估命令数量也同样重要.
该文提出一种XML索引推荐器,它在考虑数据更改而产生的索引更新成本的前提下,可以为指定的数据库和查询工作量自动推荐最佳索引集模式.
这个XML索引推荐器的关键特征就是与XML数据库系统的查询优化器紧密联结.依靠查询优化器列举候选索引模式,评估特定索引配置的查询效益;运用优化器的索引选择和成本估算能力,确保推荐的索引确实应用并有效.
该文其余部分结构如下:
运用一个算法列举候选XML索引.
运用一个泛化算法扩展候选索引集.
采用两种新颖算法,搜索索引配置空间,以找到适合于硬盘预算的最佳配置.
一种技术,提高优化器效率,减少评估索引配置的命令数量.
采用DB2原型版本执行XML索引推荐器,以TPoX基准进行实验研究.
1 XML索引推荐系统的框架结构

图1 XML索引推荐框架
图1表示了XML索引推荐器的结构.索引推荐过程框架如下:首先,依靠查询优化器列举一个特定的候选索引集.然后,将它扩展成为能够满足现在和将来工作负荷复杂查询的泛化索引集.通过两种新的优化模式运用查询优化器.第一种,称作列举索引模式,优化器接受查询并且列举相关索引.第二种,称为评估索引模式,优化器评估索引配置的查询成本.优化模式将索引推荐过程与查询优化器紧密联结,无须复制优化器已有的功能.新模式中,需要修改查询优化器,创建一个虚拟索引集.这个虚拟索引集不能用于查询,只创建在特定的查询模式中,目的是泛化查询.
当虚拟索引集创建完成,启动优化器,以评估模式估算成本.
使用数据库系统工程中的统计收集命令,为XML数据收集统计数据,供虚拟索引使用.
XML索引推荐系统考虑到因更新、删除和插入等操作而产生的索引更新成本,会从计算效益减去配置中所有索引的维护成本[1]. 该文运行一个例子,包含下面两种TPoX基准的查询的工作负荷[2].
Q1: Return a security having the specified Symbol
for $sec in SECURITY(’SDOC’)/Security
where $sec/Symbol= "BCIIPRC"
return $sec
Q2: List securities in a particular sector given a yield range
for $sec in SECURITY(’SDOC’)/Security[Yield>4.5]
where $sec/SecInfo/*/Sector= "Energy"
return
2 以优化模式产生基本索引集
为得到查询必需的基本候选索引集,XML索引推荐系统必须与优化器的索引匹配过程紧密联结,利用其详尽的查询解析、索引匹配、类型检验和查询改写功能而无需复制.
利用查询优化器的索引匹配能力列举候选XML索引集,必须修改优化器以创建一个特定的列举索引查询优化器模式.首先,在XML数据上创建一个虚拟的、广泛的索引,模式是//*.这个 //*虚拟索引,虚拟地索引XML数据中的所有元素,由此匹配查询中的任何可以回应索引的XPath模式.然后,查询优化器进行优化查询.在索引匹配后,收集查询到所有与这个//*匹配的索引模式,优化过程终止.
这个列举模式包括了只出现在查询重写中的索引.例如,表1中的C1, C2和C3,是被DB2优化器为查询例子Q1和 Q2.列举的模式,C1和C2只各自出现在Q1and Q2查询重写中.所有这三个候选考虑到决定索引模式的目标节点的条件.
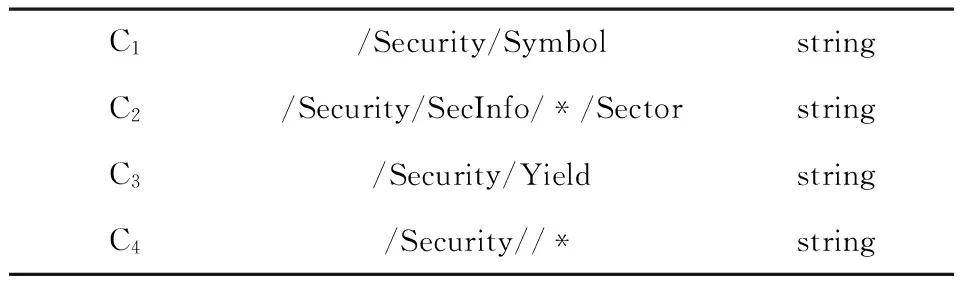
表1 基本和泛化索引
通过这个优化模式,XML索引推荐系统产生了一个基础的候选集.
3 扩展出更加广泛的泛化索引集
为识别具有相似模式的、对现有和将来查询都有用途的复杂查询模式,必须从基础索引集扩展出更广泛的泛化索引集.
例如,在Q1and Q2查询中,下面的两种XPath路径表达式,被查询优化器识别为索引/Security/Symbol和/Security/SecInfo/*/Sector的候选.以两种路径表达为基础,扩展候选集到包括更多概括性模式/Security//*. 这个新的路径表达覆盖了两种初始路径表达以及数据中潜在的其他路径表达,例如 /Security//Industry.
为找到更多泛化索引模式,泛化算法交替地对每一组基本候选索引集和产生的泛化索引集用进行泛化.这个过程持续到找不到新的泛化XML索引模式为止.泛化原则要兼顾两个XPath路径表达式,找到两种路径间的普遍结点.一种新结构的、泛化的XML表达模式符合这种兼容性考虑,于是这个新表达被加入到候选集中.泛化前,要检验两个模式的兼容性,例如数据类型和命名空间.每组泛化过程都分两个步骤,代表要索引的结点最终步骤和导向这一结点的步骤.

表2 算法Ⅰ
路径表达模式是一个链接的列表,其中每个结点就是一个路径步骤.组泛化过程有两个功能:generalizeStep (算法Ⅰ见表2)和advanceStep.每个函数返回一个或者更多泛化列表.将这个泛化模式提交为genXPath .发起一个generalizeStep(null , pi, pj)的起始命令,pi和 pj指向头结点.泛化中pi和 pj指向newNode,并将newNode加入genXPath.检验是否pi和 pj具有同样的命名.如果有,这个新泛化的结点和原来结点保留同样的命名.如果没有,使用通配符标签*.newNode的导航轴由genAxis (pi.axis , pj.axis )决定,如果至少有一个输入是派生轴则返回派生轴 (//) ,否则返回子轴.运用isLast (p)测试是否 p指向最后步骤.
另一个函数,advanceStep,根据表3中总结的泛化候选集合规则,前移指针pi 和pj,逐一巡查表达式列表.
根据第一条规则,最后一步泛化完成以后,两种表达式的巡查结束.
在最后步骤上的节点,只能用另一个最后步骤上的节点泛化,所以,第二条规则和第三条规则,测试这样的情况:一条表达式已经到达了它的最后步骤,而另一条表达式还没有.第四条规则处理中间两步的泛化.可以得到生成三种泛化:(1)把两种表达式的指针,前移一步,并泛化它们.(2)和(3),试图找到第一种(第二种)表达式的第一个节点,出现在第二个(第一个)表达式中的情形,并一起泛化它们.

表3 推进函数原则
在(2)、(3)中,如果找不到这样的节点,就不用执行泛化了.(2)和(3)是针对同一节点重复出现的情形,进行泛化.比如,/a/b/d 和/a/d/b/d ,会生成 /a//d和 /a//b/d.表格2中的规则0,是生成Xpath之前的最后重写步骤.在这个步骤中,出现在表达式中间的一个或多个相邻的/*,被下一个步骤中的子轴取代.
4 搜索优化配置适应空间预算
候选集列举和泛化之后,XML索引推荐系统掌握了一个扩展的候选索引集.下一步就要搜索包含候选索引集的索引配置的空间,以寻找到效益最大,且适应用户空间大小的索引配置.
这个组合的搜索问题可以建模为一个0/1背包问题,并且是NP完全问题[3].背包的大小是用户特定的硬盘空间预算.候选索引集是放到背包加密系统中的细目,具有成本.
采用两种搜索方法,探索法贪婪搜索能够确保查询中使用尽可能多的索引.上下搜索能够找到一种尽可能泛化的配置.
4.1 探索法贪婪搜索
贪婪搜索可以选择到的泛化性索引,但它总是做出在当前看来是最好的选择,并不从整体最优上加以考虑,所做出的仅是在某种意义上的局部最优解[4],因此有可能与其他索引指向重复,而优化器计划只能执行一次索引.解决办法是先选择索引,再汇集查询,然后去除从未使用过的索引.同时,尽可能立刻删除冗余的索引,并马上回收他们占用的空间.
探索法贪婪搜索最大化地保留了搜索最初目标的效益,并且保留了一个查询的XPath模式点位图.这个点位图用来确认,新加入配置中的泛化索引,并非已有索引的复制.
当一个概括性的索引,xgeneral ,被加到推荐的索引配置中,它必须比他所概括的其他索引x1,x2, …,xn“更好”.定义 IB (X),索引集X的改进效益为现有配置效益.一个概括性索引要加到配置中,必须满足以下两种探索条件:
IB(xgeneral) ≥ IB(x1,x2,…,xn)
大多数时候,泛化索引比他们泛化的具体索引大,尽量选择对现在工作负荷最佳的最小配置.价值 β是个门槛,指定多大的增加可以接受.在实验中得到,当 β = 10%时,工作优良.
4.2 上下搜索
探索法贪婪搜索的弊端是当工作负荷即使微小变化,推荐配置就可能失效[5].而XML丰富的结构允许用户提出查询,要求读取轻微变化的数据元素.于是,XML索引推荐系统用上下搜索以达到这一目标.
在上下搜索中,构建一个候选索引集的直接线形图表(DAG) ,并且泛化他们.每个在DAG中的结点代表一种XML模式,基于我们的候选泛化算法,结点具有这种模式的概括性.例如,当泛化两个候选集 /Security/Symbol and /Security/SecInfo/*/Sector,去得到/Security//*,在DAG中将为 /Security//*创建一个结点,并且这个结点将是两个候选集的根.
最后,拥有一个了DAG,将这个DAG的根源作为现行配置.因为泛化索引都很大,这个配置容易超过硬盘空间预算,但是它也更容易获得最大化效益.
然而,泛化索引集可能零或负效益,因为两个原因:(1)因为在工作负荷中更新、删除和插入操作而导致的高维护成本.(2)不能被优化器计划执行使用.为此,加了一个预处理解析过程,从搜索空间去除没有效益的索引.然后,用具体的(更小的)子索引集交替取代一个泛化性索引,重复这个步骤直到现行配置适应硬盘空间预算.
有两个版本的上下搜索算法.第一种版本,上下搜索简版,忽略索引相互影响,索引集效益的总和被计算成配置的效益.第二种版本,上下搜索全版,可以更技术,更合理地评估配置的效益.
4.3 有效率的效益评估
效益评估由于索引相互间作用而更加复杂.一个索引查询的效益会产生变化,取决于是否存在其他索引[6].评估时要考虑到索引间相互影响,所以,将配置中所有索引创建为虚拟索引集.
追踪每个索引,x,它的查询操作产生基本候选索引模式.从x中受益的操作被称之为受影响的集.评估配置的效益,只需对这个受影响的集进行总体优化.
分出更小的子配置,每一个子配置中都包括相互影响的索引,这些索引与受影响的集重叠.保留一个以前评估过的子配置的缓存,评估某个子配置是否可以在缓存中找到.交替地合并受影响的集的子配置,直到不能再合并.
例如,评估包括 表格1中C1, C2和 C3的索引配置的效益,我们最初分别放置他们到子配置中.因为 C2和 C3是列举自相同的查询Q2中,我们合并他们的子配置,生成两个子配置{C1} and {C2, C3}.考虑到与其他索引相互作用,估算 C2的效益,就只需评估{C2, C3}的效益,而不包括{C1}.因此,只需发起对受影响集C2和C3的优化命令,不用优化整个工作负荷.
5 用实验证明XML索引推荐系统高效
5.1 实验设置
修改DB2 9 查询优化器,创建支持XML索引推荐系统的两种新优化模式的原形文本.这些新模式在优化器中作为实验模式.客户端侧XML索引推荐系统用JavaTM 1.5执行,与原形服务器经由JDBC交流.在有两个 Intel R Xeon R 2.8GHz CPUs 和 4GB 运行内存的SUSE Linux R 10 Dell PowerEdge 2850服务器上进行实验.这些数据库存在一个146GB 10K RPM SCSI 驱动中.
实验运用XML基准:TPoX.
5.2 推荐效率
索引推荐系统执行五种组合的搜索算法:(1)没有探索法的贪婪搜索.(2)探索法贪婪搜索,(3)上下搜索简版(4)上下搜索全版.图2显示了不同硬盘空间预算下,不同搜索算法的加速估算.
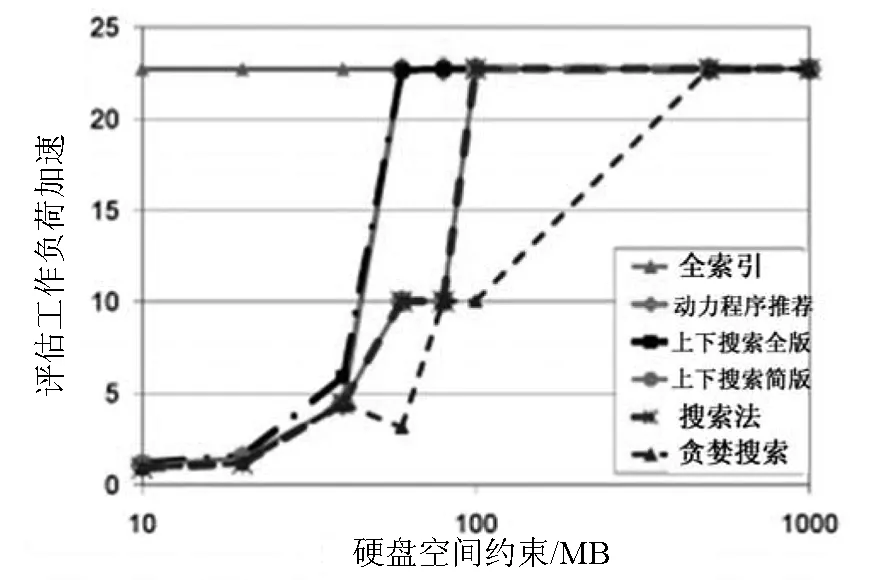
图2 评估加速
当硬盘空间预算增加,加速也增强.贪婪搜索甚至比全索引需要更大的硬盘空间.探索法搜索和上下搜索简版都得比贪婪搜索加速好,加速效果接近动力程序搜索.上下搜索全版考虑到了索引间相互影响,加速表现最好.
图3显示,上下搜索全版的优异表现来之不易.图表显示,索引推荐时间伴随硬盘空间预算的变化而变化.上下搜索全版运行时间超过探索法贪婪搜索7倍还多.但是,随硬盘空间增加,上下搜索全版运行时间明显改进.

图3 推荐系统运行时间
5.3 推荐泛化索引
为证明XML索引推荐器能够推荐更多泛化的、对未来复杂查询更加有益的索引,首先阐释在工作负荷中可能找到多少泛化索引.
表4显示列举索引集模式下,工作负荷查询中优化器泛化的索引集数量,当工作负荷的查询数量增加,泛化的候选索引集的总数量也增加.数量显示即使这些随机的、只有很少、或者没有普遍性的工作负荷,也能够通过加入泛化索引而扩展候选索引集的数量高达50%.
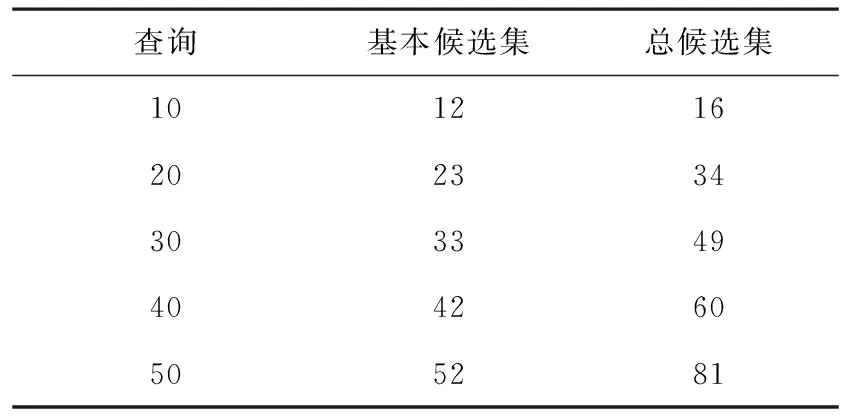
表4 估算候选索引集

表5 推荐泛化(G)和具体(S)索引数
阐释的第二个问题是多少泛化索引集能够被上下搜索的算法推荐及其效益.
表5显示不同的硬盘空间预算下,运用探索法贪婪搜索,上下搜索简版和上下搜索全版的泛化和具体索引集数量.探索法贪婪搜索推荐表现保守.上下搜索,则相反,硬盘空间越多,它推荐的泛化索引越多.
为显示加速效果,执行一个实验,其中用来评估推荐配置的测试工作负荷与训练工作负荷并不相同.图4显示在硬盘空间2GB的预算下,变化训练工作负荷大小,测试工作负荷的估算加速.数字显示是在一定硬盘空间下,上下搜索非常高效,可以泛化从训练工作负荷到测试工作负荷、从可见到未可见的查询.而探索法贪婪搜索没有这个能力.

图4 泛化未可见查询

图5 泛化未可见查询一实际加速
6 结束语
该文提出了一个索引推荐系统,能够为指定的XML数据库和查询工作负荷推荐最佳索引集.这个推荐系统列举和评估索引时,紧密地联结查询优化器.它运用搜索算法,超越训练工作负荷推荐有用途的索引集,并且最小化优化器命令数量,操作极为高效.在DB2原形文本中执行XML索引推荐系统,显示它所推荐的索引,极大地加速了工作负荷查询.
[1] Elghandour, Aboulnaga A, Zilio D C,et al.与优化器高度匹配的索引推荐,发表滑铁卢大学技术学刊2013-22,2013.
[2] Nicola M,Kogan I,Schiefer B.“XML 操作过程基准”,数据管理国际会议,2007.https:/sourceforge.net/projects/tpox.
[3] Valentin G,Narasaya V R.有效的Microsoft SQL Server成本驱动索引选择工具.国际海量数据大会,1997.
[4][5] Kleinberg J,Tardos E.算法设计.北京:清华大学,2006.
[6] 季玉梅.一种基于XML模式的XML索引技术.北京工业大学学刊,2013.
(责任编辑:季春阳)
Highly Optimal XML Index Recommendation
Xu Qian
(Heilongjiang Institute of Technology)
XML database systems are increasingly large, highly structured and increasingly complex to be queried. In this paper, an XML Index Advisor coupled with the query optimizer tightly `` is proposed which make it efficiently easy to recommend the best set of XML indexes and expand more useful generalized set of indexes candidates.
XML index;Query optimizer;Indexes candidates;Estimate configurations
2016-01-19
TP274
A
1000-5617(2016)02-0079-05
猜你喜欢
今日农业(2022年16期)2022-09-22
今日农业(2022年14期)2022-09-15
电子制作(2022年1期)2022-01-28
电子制作(2021年14期)2021-08-21
数学物理学报(2020年2期)2020-06-02
安顺学院学报(2020年1期)2020-04-05
当代水产(2019年1期)2019-05-16
现代计算机(2019年6期)2019-04-08
今日农业(2019年14期)2019-01-04
商(2012年11期)2012-07-09
