
基于Skinner理论的无人机应急威胁规避方法
2016-11-22 11:17:23魏瑞轩何仁珂张启瑞许卓凡赵晓林
北京理工大学学报 2016年6期
魏瑞轩, 何仁珂, 张启瑞, 许卓凡, 赵晓林
(空军工程大学 航空航天工程学院,陕西,西安 710038)
基于Skinner理论的无人机应急威胁规避方法
魏瑞轩, 何仁珂, 张启瑞, 许卓凡, 赵晓林
(空军工程大学 航空航天工程学院,陕西,西安 710038)
对于突发紧急威胁情况,常规的无人机规避方法在实时性和适用性方面存在不足. 在研究生物体条件反射机制的基础上,将无人机应急规避行为理解为在外界威胁刺激下的一种应激性,提出了基于威胁紧迫度的Skinner理论. 模拟飞行员在紧急防撞情况下的拉杆动作,将阶跃信号作为无人机应急动作指令,运用动作评价算法计算输出最佳策略. 采用Skinner理论和统计学方法进行在线训练,形成威胁状态与规避动作的匹配,从而建立完整的条件反射过程. 实验结果表明,基于Skinner理论的规避方法对突发威胁情况具备有效的规避能力.
无人机;条件反射;威胁规避;应急机制
威胁规避常用的模式是感知-规避(sense & avoid, S&A),方法包括:解算制导律的方法、实时路径规划的方法、基于决策的方法等[1-2]. 这些方法的计算复杂度是无人机威胁规避产生延时的主要因素. 计算延时将影响无人机威胁规避的机动时机,从而大大降低面临威胁情况下本机的生存率. 对于突发威胁,考虑到无人机与威胁相对运动速度大、传感器探测范围有限,无人机威胁规避所允许的延时条件极为苛刻. 因此,应急威胁规避机制必须能在极短时间内做出机动,优先确保无人机安全,而非优先考虑规避决策的优化问题. 无人机应急威胁规避可以类似理解为本机安全受外界刺激所做出的反应,研究无人机突发威胁下的应激(irritability)机制对于解决应急威胁规避问题很有借鉴意义. Skinner 操作条件反射(operant conditioning,OC)理论[3],提出了通过训练不断强化动作的条件反射机制,以动作-强化刺激-动作的方式进行强化训练. 近来年,该理念在机器人领域进行了应用性研究[4-5].
针对面向突发威胁的无人机应急规避问题,本文将Skinner理论框架与无人机威胁规避策略相结合,提出了从感知到规避的条件反射式应急机制. 用本机与威胁的相对位置度量威胁紧迫度,以此模拟外界刺激信号;类比飞行员在紧急避撞状态下的机动动作,以阶跃信号作为无人机指令做大幅度规避机动. 借鉴Monte Carlo方法和模拟退火(simulated annealing, SA)算法,通过不断训练强化刺激到动作的映射,实现从感知到规避的条件反射.
1 基于威胁紧迫度的Skinner理论
Skinner理论根据感受器感知外界刺激做出相应动作,通过动作产生的状态进行动作选取的调整. 为模拟条件反射的外界刺激,用威胁紧迫度来度量无人机面临的威胁程度,以此作为刺激信息和动作评价信息. 然后以随机方式选择取动作,对机动后本机与威胁的相对距离判断规避效果,用统计学方法进行概率的调节. 同时,在事件记忆机制中用增量多层判别回归树(incremental hierarchical discriminant regression, IHDR)方法将训练的知识“经验”进行存储,使威胁环境类型与规避动作形成匹配映射关系.
1.1 威胁紧迫度定义
无人机规避的动机来自于威胁的逼近,本文以威胁紧迫度表示. 相对于无人机,威胁的位置可以表示为
(1)
式中:P(t)为t时刻威胁i的位置;P(0)为威胁i的初始位置,vi为威胁i的速度;vu为无人机u的速度
(2)
式中ψu(t)为无人机的偏航角. 无人机威胁规避的安全性由相对距离决定,当威胁逼近设定的无人机安全距离时,危险系数高,反之则低. 在传感器探测范围内,相邻的探测时间本机与威胁相对距离越小,威胁度越大. 威胁紧迫度定义为
L(t,t+1)=1-ΔP(t,t+1)ddefP>ddef
其他, (3)
式中:ddef为定义的规避距离;ΔP(t,t+1)为相邻时刻的相对距离变化量. 当相对距离大于规避距离时,认为无人机安全;反之,相对距离越小,威胁紧迫度越大. 威胁紧迫度描述了无人机在威胁状态下的规避动机.
1.2 操作条件反射算法
Skinner自动机定义如下
(4)
式中:t为时间;s为状态集;o为动作集;M为动机;F:s(t)×o(t)→s(t+1)表示状态转移;G:s(t)→o(t)表示动作选择;A表示Skinner算法.
动机M决定了本体在某一情况下是否进行动作,与强化训练中动作概率选择的增减有关. 状态转移F是动作引起的状态变化s(t)→s(t+1),由无人机在威胁状态下规避机动产生的结果. 这一过程可产生对动作的评价,即根据状态变化测量本机与威胁的相对距离,以此评价上一时刻动作o(t)是否合理,并在下一时刻对动作概率进行调整. 动作选择G是基于Monte Carlo方法的概率式选择机制,是强化训练的重要环节. 强化分为正强化和负强化,表现为状态与动作之间映射概率的增减. 当前动作引起下一时刻状态符合预期时,则概率增加;反之减小. 对于无人机威胁规避,预期由威胁紧迫度L(t,t+1)来衡量,当规避动作导致下一时刻L减小时,则概率增加,反之减小. 本文采用Metropolis函数进行定义
(5)
1.3 事件记忆机制
通过Skinner方法进行强化训练所产生的无人机威胁规避行为,将作为知识“经验”进行存储. 随着训练的不断增多,信息量越来越大,知识库也随之增大. 如何对知识进行有效组织和存储,对无人机在面临威胁情况下进行快速地行为检索和匹配至关重要. 本文用IHDR方法作为事件记忆机制算法,进行知识存储.
IHDR方法以根节点到叶节点的树状存储结构完成知识的分类回归,可较好地处理高维空间的聚类问题. 对于一个训练样本(xt,yt),t=0,1,2…,先进行输出空间y聚类,再映射到输入空间x实现二次聚类. 一个节点处在树中的位置越深,其x簇变化量越小,当节点的样本量足够小时,则该节点可以作为分裂为一个叶节点. 对于无人机威胁环境,输入空间用于描述威胁与本机的状态信息,由相对位置P(t),速度v确定. 输出空间用于描述无人机控制指令ψd(t). 映射定义为
(6)
知识存储具体步骤参见文献[6].
2 应急威胁规避机动策略
在突发威胁的紧急情况下,无人机威胁规避应首先考虑规避后本机的安全,兼顾规避策略的最优问题. 应急机动具有突发性特点,往往由一次性动作完成. 采用文献[7-8]的线性化模型,模拟飞行器在突发威胁情况下的“拉杆”动作,将阶跃信号作为无人机规避机动指令. 假设对偏航角控制施加一个阶跃信号ψd(t),其响应曲线ψ0(t)主要由调节阶段和稳定阶段构成. 上升时间为Δtr,最大振幅为Amax,偏航角改变量Δψ. 定义归一化响应为
(7)
式中:ψ(t)为时刻t的偏转角;ψi为初始偏转角;Δψ为指令偏转角与初始偏转角的差. 上升时间和最大振幅可以被指令信号表示,其线性化模型为
(8)
(9)
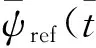
(10)
(11)
(12)
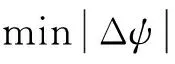
3 仿真实验
针对突发威胁情况,首先进行在线无人机威胁规避训练,使无人机形成威胁与动作的映射关系,并具备条件反射式应急规避能力;然后分别在单一威胁场景、连续威胁和地形威胁场景下进行测试. 仿真实验条件:软件Matlab 7.0;计算机配置:Windows XP操作系统,CPU为Inter Core i3,主频3.3 GHz.
3.1 威胁规避训练
威胁分别从无人机探测范围边界的左侧、正前、正下、左前、右前、左下、右下方向以100 m/s的速度直线飞行. 场景编号分别为1,2,3,4,5,6,7. 本机速度14 m/s,安全距离50 m,最高温度θ为1 000 ℃,k为常数1.
如图1所示,每个点表示一次训练,按时间先后顺序,训练从高温状态到冷却状态. 由于采用对数表示,训练次数分布并不均匀. 对于不同威胁场景,温度下降状态不一样,训练次数与温度下降状态变化相关,通过反复大量训练都呈现出从高温到冷却的一般性趋势. 表明Skinner机制可以通过训练,根据规避情况来不断调整威胁类型与动作的匹配,从而实现最佳映射.
3.2 动态突发威胁规避
通过训练,无人机具备了一定的威胁规避应急反应能力. 为测试对于一般性威胁的反应表现,分别设置单一威胁规避场景和连续威胁规避场景进行仿真实验.
单一威胁规避仿真场景如图2,图3所示.
在单一威胁规避仿真场景中,本机速度25 m/s,威胁速度100 m/s. 威胁沿直线飞行,与本机在第0 s同时启动,在第20 s进入本机规避范围,本机立即做出规避动作. 从参数中可以看出,规避时无人机作大幅度机动,在较短时间内偏离原航向,动作幅值在允许范围内. 约在60 s时航向基本稳定,航线与原航线直线投影平行距离约为50 m,表明经过训练后的Skinner机制无人机能根据威胁状态,在短时间内以较优动作进行规避.
连续威胁规避仿真场景如图4,图5所示.
在连续威胁规避仿真场景中,本机速度为28 m/s,威胁1速度70 m/s,威胁2速度100 m/s. 威胁1与本机在第0 s同时启动. 第32 s威胁1进入本机规避范围,本机做出第一次规避动作,本机立即做大幅度机动. 约在第79 s进入稳定状态,稳定后航线与原航线直线投影平行距离小于50 m. 威胁2在第86 s启动,在第116 s进入本机规避范围,本机做第二次规避. 150 s后进入稳定状态,稳定后航线与原航线直线投影平行距离小于20 m. 表明Skinner机制的方法具备连续威胁规避的能力.
3.3 地形威胁规避
针对现实任务环境中存在的多种威胁类型,设置包括地形在内的动静态威胁场景,测试算法对复杂威胁环境的适用性. 具体参数如表1.
威胁1启动时间第0 s,威胁2启动时间第46 s,本机启动时间第40 s. 如图6,图7所示,第43.3 s威胁1进入规避范围,无人机做第一次规避机动,向山峰1方向靠近. 第50.8 s山峰1进入规避范围,无人机做第二次规避机动,根据威胁范围,第二次机动偏航角明显小于第一次. 第56.8 s先后遭遇威胁2和山峰2,按威胁紧迫度算法,以距离优先原则选择最近的威胁2做规避机动,同时导致与山峰2距离增大,威胁紧迫度降低,无需再进行重复机动. 无人机可以实现对复杂动静态威胁进行有效规避.
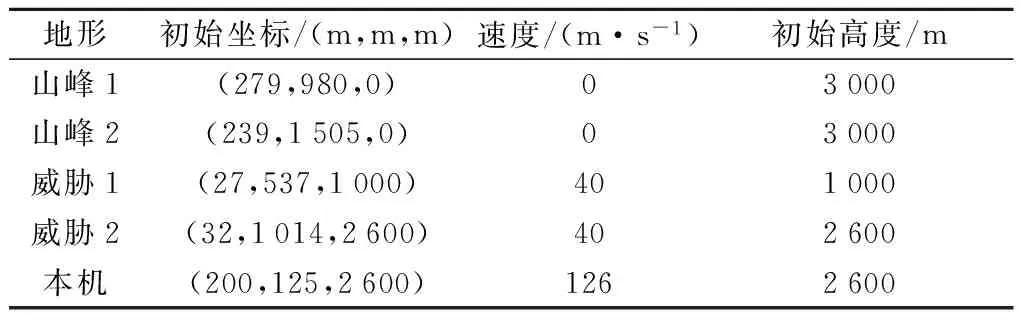
表1 初始参数
4 结 论
研究了生物体条件反射机理,并结合威胁规避特点,将威胁状态作为刺激条件,提出基于威胁紧迫度的Skinner理论. 并将Skinner理论与底层控制算法相结合,将规避效果作为评价指标对无人机进行应急规避训练,从而使其具备一般性的应急规避能力. 本文的不足之处在于,退火过程需要进行反复大量的训练,将造成训练时间大幅延长. 下一步将改进基于统计学的方法,使训练过程以较快速度实现退火.
[1] Alonso-Mora J, Naegeli T, Siegwart R, et al. Collision avoidance for aerial vehicles in multi-agent scenarios[J]. Autonomous Robot, 2015,39(1):101-121.
[2] Bertuccelli L F, Wu A, How J P. Robust adaptive Markov decision processes: planning with model uncertainty[J]. IEEE Control Systems, 2012,32(5):96-109.
[3] Wolf R, Heisenberg M. Basic organization of operant-behavior as revealed in drosophila flight orientation[J]. Journal of Comparative Physiology A, 1991,169(6):699-705.
[4] 任红格,阮晓钢.Skinner 操作条件反射的一种仿生学习算法与机器人控制[J].机器人,2010,32(1):132-137.
Ren Hongge, Ruan Xiaogang. A bionic learning algorithm based on Skinner’s operant conditioning and control of robot[J]. Robot, 2010,32(1):132-137.(in Chinese)
[5] Ren H G, Ruan X G. The Skinner automaton: a psychological model formalizing the theory of operant conditioning[J]. Science China: Technological Sciences, 2013,56(11):2745-2761.
[6] Weng J, Hwang W. Incremental hierarchical discriminant regression[J]. IEEE Transaction on Neural Networks, 2013,56(11):2745-2761.
[7] Melega M, Lazarus S, Lone M, et al. Autonomous sense & avoid capabilities based on aircraft performances estimation[J]. Journal of Aerospace Engineering,2012:1-26.
[8] Melega M, Lazarus S, Savvaris A, et al. Multiple threats sense and avoid algorithm for static and dynamic obstacles[J]. Journal of Intelligent & Robotic Systems,2015,77:215-228.
(责任编辑:李兵)
Skinner-Based Emergency Collision Avoidance Mechanism for UAV
WEI Rui-xuan, HE Ren-ke, ZHANG Qi-rui, XU Zhuo-fan, ZHAO Xiao-lin
(Institute of Aeronatics and Astronautics Engineering, Air Force Engineering University, Xi’an, Shaanxi 710038, China)
The urgent threat collision condition is hazardous for UAV, it is difficult for traditional methods to ensure safety due to the poor performance in real-time and applicability. Conformed to operant conditioning theory, the urgent collision avoidance behavior of UAV could be regarded as irritability in the outside stimulatory, and then the improved Skinner theory based on threat level was proposed. A step command was used as control signal, which was similar with pilot’s maneuver in the urgent threat collision condition, and performances estimation algorithm was applied to output optimized strategy. On-line training was conducted based on Skinner theory and statistics to map the threat condition and maneuver, then all the elements of operant conditioning model were completed. The result shows that, the proposed method can handle urgent threat collision well.
UAV; operant conditioning; collision avoidance; emergency mechanism
2016-03-09
国家自然科学基金资助项目(61573373,61503405)
魏瑞轩(1968—),男,博士,教授, E-mail:lnzrds@163.com.
V 279.2
A
1001-0645(2016)06-0620-05
10.15918/j.tbit1001-0645.2016.06.013
猜你喜欢
装备制造技术(2020年3期)2020-12-25 05:21:52
红领巾·探索(2020年5期)2020-05-19 15:28:03
当代陕西(2019年12期)2019-07-12 09:12:02
汉语世界(The World of Chinese)(2019年1期)2019-03-18 01:50:16
小学科学(学生版)(2018年9期)2018-09-21 09:13:52
家教世界(2017年11期)2018-01-03 01:28:49
英语学习(2015年2期)2016-01-30 00:23:16
小哥白尼·军事科学画报(2014年8期)2015-04-07 03:54:50
计算机与网络(2013年23期)2013-04-16 23:13:30
电脑迷(2012年9期)2012-04-29 02:08:25
