
SQL Server数据库到HBase数据库的模式转换和数据迁移研究
2016-11-19 06:10张华东邵秀丽吴军王志刚
智能计算机与应用 2016年5期
张华东 邵秀丽 吴军 王志刚


摘要:大数据背景下,SQL Server关系型数据库的存储容量暴涨,如何高效的实现把SQL Server数据库中的数据迁移到HBase分布式数据库,是亟需解决的一个关键问题。讨论研究了两种数据库之间的差异之后,首先提出了数据库模式之间的转换,把SQL Server数据表的模式,按照不丢失关系的原则,转换成HBase下的表模式;然后根据不同的表间关系的数据迁移的规则,实现SQL Server数据库中的数据迁移到HBase数据库。因为表间转换关系和数据迁移规则的预定义,实现了一键完成数据的迁移。
关键词:SQLServer;HBase;迁移;模式;转换
中图分类号 TP393 文献标识码 A
0 引言
SQL Server是关系型数据库、按行存储,而HBase是分布式的非关系型数据库、按列存储。由于各自的这些特点,在建立数据库表模式时,SQL Server须指定表名、表中所有的字段及类型和主外键[1];而HBase在建立表模式时,须指定表名、列族和行键,但具体的列族中有哪些列是在插入数据时以键值对的形式出现,并且表间没有主外键的关联关系[2]。基于两者的这些不同特点,本文首先给出了SQL Server数据库到HBase数据库表模式转换的解决方案。HBase数据库中各个列族的数据会分散存储到不同的节点,而相互之间通过行键关联[3][4]。在SQL Server中关系表的数据,须存储到同一张HBase表的不同列族,才能在不损失效率的情况下实现快速有效查找。如何根据表模式转换的规则[5-6],从SQL Server数据库中获取到关联的数据,然后准确的插入到HBase表的对应列族中,文中研究给出了在适应大数据量的情况下,基于分页的数据迁移方案[7][8]。
1 表模式转换的整体解决方案
通过连接SQLServer数据库,获取指定数据库中所有表的相关信息(列名、列类型、主键、外键),然后根据表间关系的规则定义去发现SQLServer数据表中的关系,最后根据表模式转换规则定义,遍历关系转换成HBase表模式[9]。调用Java的工具包,配置和实例化HAdmin对象,调用添加HBase表列族的API函数把转换后的表模式执行到HBase数据库,从而建立HBase表模式,整体方案如图1所示。
2 获取Sql Server数据库表模式
数据库表模式的主要信息包括表名、列名、列类型、列约束以及主键、外键信息。数据库表模式的获取,也就是先获取到所有的数据库表的表名称,根据表名称依次获取主外键、列的相关信息,再将数据保存到TableDef的对象中,图2给出了获取Sql Server数据库表模式的处理过程。
获取Sql Server数据库中指定数据库的所有表的表模式按照如下步骤设计展开:
首先,执行StringBuffer sql = new StringBuffer("Select NAME FROM ") .append(database).append("..SysObjects Where XType='U' ORDER BY Name");SQL查询得到数据库中所有的用户表的表名称,并保存到List
然后,根据表名执行Sql查询获取到一条数据表中的数据,得到结果集rs;rs.getMetaData()来解析提取到该数据表的元数据信息ma,至此就可以得到表的列数ma.getColumnCount(),以及各列的详细信息,包括列名Ma.getColumnName(i)、列类型ma.getColumnTypeName(i)、列类型长度ma.getColumnDisplaySize(i),其中i表示当前结果集中列的序号。
最后,就是获取表的主外键和关联关系信息,这也是把Sql Server数据库表模式转换到Hbase表模式的最重要的信息。具体的实现过程如下:
先通过meta =JDBCSqlTest.getConnection().getMetaData();取得数据库连接元数据,数据库的元数据信息包括了数据库中所有表的主键、外键及其他信息,这里只关注主外键的信息,并且可根据表名查找到指定表的主外键信息。
获取数据库表的主键的信息,可通过meta.getPrimaryKeys(null, null, tableName);获取到主键信息引用key。表中的主键列,具有相同的主键名,主键列COLUMN_NAME通过key.getString("COLUMN_NAME")获取,主键名PK_NAME则可通过key.getString("PK_NAME")得到。再使用key.next()可以获取下一条主键信息,直到为空可以获取到该表所有主键信息。
获取数据库表的外键的信息,可通过meta. getImportedKeys (null, null, tableName);获取到外键信息头指针forignKey。每个表可与其他多张表发生关联,因此就会有多组外键关系,每组外键关系都有特定的外键名,该表的哪几列与另一张表的哪几列关联。这里表的外键信息记录就比较复杂,下面做具体说明。
因为同一个外键关系,所关联的数据库表是唯一的,在关系记录时,使用外键名作为键值,通过实例化外键组对象时,就可以唯一指定外键的关联表。该表的外键列与关联表的列就可以一一对应,从而完整记录外键的关联信息。使用forignKey.next()可以获取下一条外键信息,直到为空即可得到该表所有外键信息。
以上获取到的数据库所有表的信息都会写到一个XML文件中。XML文件是较为通用的数据交换的文件格式,作为一个中间结果的保存[10]。这里也是考虑到实现的扩展性,以及可检测性。如果用户在经过模式转换后,对结果的正确性仍无法评判,就可以查看XML文件,如此即能较直接的发现不准确的问题所在。
3 SQL Server表间关系的读取
根据已经获取的SQL Server表模式信息,建立表模式对象间的引用关系。由此即可总结出关系查询蕴含的一般性的规律,按此规律则可自动搜索表间的关系[11-12],从而依据不同的表间关系执行不同的模式转换。
读取生成的SQL Server数据库表的XML文件,首先判断该表是否有外键,如果有,根据外键关系,可读取外键关系表,然后递归检查外键关系,直到该表没有外键时,按表名实例化该表的TableDef对象。对于有外键关系表的表实例化,须把外键关系表的对象的引用记录下来,在接下来研究展开表间关系的发现时,将能够直接获取到关系表的实例。
可以直接通过获取到的TableDef对象的ForeignKeyGroup的pkTableName,得到关联表的表名,遍历TableDef列表找到表名相同的对象,返回对象,并将其加入到当前表的关联表的列表中即可。继续判断是否还有其他的外键关联表,如果有可针对性地根据表名查到下一个关联表的对象,加入到关联表列表中。实现过程的查找步骤如下:
1)获取到每个外键组的PKTableName即关联表的表名;
2)根据表名查找到表对象,并返回;
3)把返回的表对象保存在该表的关联表列表中。查找是否还有下一个关联表,如果有则回到第一步继续执行。
查找过程中,通过表名查找TableDef列表,假设SQLServer表个数为n,每个表的关联表的个数为k,最大时间复杂度为n*(n-k-1+n-k-2+…+n)=n*(kn-3k2/2+k/2)=kn2-3k2n/2+kn/2(即O(n2))。使用列表存储表对象,最大时间复杂度较高,在实例化每个TableDef时,考虑根据表名的频繁查询,可以使用Hash表结构,表名作为key值,实例对象作为value存储。至此最大时间复杂度就变成了O(n)。
这样就直接建立了表和相关联表之间的直接引用关系,在查找表表间特定关系时,能够较快地获取到关系间的特征,以及关联表的详细内容详情。
综合上述得到的表间的关系,可通过深度遍历每张表,从而找到与该表关联的其他所有表的信息。但是对于实际的数据库系统,在建立表以及确定表间的关系的过程中,研究发现真正用于连接多张表的特征复杂查询时[13-14],对关系表间的层次关系低于3层的这些表的查询较为频繁,而且此时也能够满足大多数系统的需求。
为简化问题的复杂性,仅考虑3种表之间的关系。各类关系的内容概述如下。
1) NEST_3关系。一张表包含两张以上的关系表,如图3所示。
图3 NEST_3关系
Fig.3 The relation of NEST_3
通过遍历所有Sql Server的表,执行前述步骤得到表的列表,若关联表的个数大于1,即认为该表与关联表之间是NEST_3的关系。此时该表作为关系记录对象中的主表,关联表的列表作为关系记录中的关系表的列表。
2) NEST_2关系。一张表仅包含一张关系表,并且该关系表没有其他关系表,如图4所示。
通过遍历所有Sql Server的表,执行前述步骤得到表的列表,若关联表的个数等于1,然后得到关系表。若关系表的关联表的个数为0,则定义为NEST_2的关系。此时该表作为关系记录对象中的主表,关联表作为关系记录中的关系表。
3) INLINE关系。一张表仅包含一张关系表,并且该关系表至少包含一个其他关系表,如图5所示。
通过遍历所有Sql Server的表,以上步骤得到的表的列表,若关联表的个数等于1,然后得到关系表。若关系表的关联表的个数大于0,则该关系为INLINE的关系。此时该表作为关系记录对象中的主表,一级关系表和各个二级关系表分别作为多个INLINE关系的关系记录中的关系表。
以上得到了所有自定义的关系,但是不难推知这种关系发现的算法,在得到全部自定义关系的同时,会产生关系的包含,为此就需要去除已经存在关系包含的关系,随即将研究引进一个去重的操作。
这里关系的查找,本文遵循的是逐个遍历所有的TableDef表,并且根据每个表记录的关联表的个数,决定查找的类型(NEST_3/NEST_2/INLINE)。比如,如前文所述的当前表的关联表的个数,大于1时,进行NEST_3关系的查找;等于1时,进行NEST_2和INLINE关系的查找,进一步地找到关联表,再一步递归查找,但查找层数却仅限为3。鉴于层数的限制,显然可见此时的时间复杂度则为O(n)。
根据关系的定义进行分析可知,重复的关系产生,必然是在2个表的关系和2个以上的表关系之间。更为确切地说,就是NEST_2关系的只可能与INLINE关系的关联表重复,或者与NEST_3中的其中一个关系重复。最终就会得到如下的关系形式。算法过程如下:
1) 遍历所有的已找到的关系列表,当前关系与列表中后面的每个关系依次比较。
2) 判断当前关系与被比较关系中哪方的关系类型是NEST_2,如果都不是则返回null,说明当前关系不是重复的关系。其中一个是NEST_2,进入下一步。
3) 若当前关系NEST_2关系间的比较过程如图6所示。
此时,假定已找到关系的个数为n,去重的操作为两两之间的比较,总的比较次数为
,因此时间复杂度为O(n2)。
关系去重之后得到的关系中同一类别的关系,在同一个类型名称下面作为其中的一个分组。获取到的所有数据表的关系的信息都会保存到RelativeRecord对象列表中。
4 HBase表模式的创建
由于HBase表都是独立的表,表间没有关系建立的字段描述,因此在SQL Server表模式转换到HBase表模式时,须关注的就是表间的关系如何转换到HBase的一张表中[15]。考虑到HBase表有列族的概念,每个列族又可以有不同的列,这就可以把表间关系记录到HBase表的列族之间的关系,从而能够较好地保存SQL Server表间的关系。以下分别对表和表间关系的转换进行分析。
首先是把每个基本表的表模式变换到Hbase表模式,变换的规则是Sqlserver的表名作为Hbase的表名,该表的表名同时作为Hbase第一个列族的列族名,该表的字段名作为该列族的列名,如图7所示。重要的是,把该表的主键列指定为Hbase表的行键列。
逐个遍历SQL Server数据库获取到的TableDef列表中的对象,根据TableDef的Name属性实例化HTableDef对象,获取到TableDef的主键,设置为HTableDef行键列。这一数据表的基本变换,就是确保所有的数据表在HBase中都有对应的表名存在。实际执行过程如图8所示。
此后,将是根据关系中的主表的表名找到Hbase中对应的Hbase表,继而循环遍历相关表,把相关表作为该Hbase表的列族加入,相关表的字段作为新列族的列,相关表的表名作为新列族的列族名称,如图9所示。
在定义HBase表的描述时,其实仅需描述HBase表有哪些列族即可。研究指出每个列族有一些列,只是用于提供说明在数据导出完成后,整个HBase表的一个完整的结构描述。为了做到SQL Server语法的解析通过[16],能够更好地对结果数据集进行精确筛选,也就是把原相关表中的列名作为HBase表中这个列族的列,保证了数据列名的一致性。
如前探讨所述,通过给每一个表都建立了同名的HBase表,在遍历关系的过程中,需要根据主表的表名,迅速定位到该HBase表的实例化对象。为了能够在表的数量较为可观时,达成这一目的,即需在建立HBase对象时,将每个HBase对象都保存到Map
其中,判断是否有下一个关联表,目的是把关联表作为主表的列族添加到Hbase表的定义中。Hbase表在建立初始,需要制定HBase的表名和列族这些关键的信息,此时关于列族中的列的数目,在Hbase表的生成描述中,可以无需指定,而只是当插入数据表中数据时再真实呈现每个列族中包含有哪些列即可。
为了保存表间的关系,HBase数据表的冗余存储即已成为必须。每个关系中的主表在Hbase中都有对应表名的表存在,在关系表模式的转换过程中,假设关系有n个,关系中关联表的个数为k(k 把HBase表模式使用JAR包提供的API创建到HBase分布式数据库中,其数据的流向和处理如图11所示。 通过表模式转换的操作把生成的Hbase表结构创建到Hbase数据库,可以循环遍历已经得到的Htable列表,根据Htable得到的Htable实例对象,首先检查Hbase数据库中是否已经存在该表,若存在直接删除,然后再重新创建该表。创建Hbase表时,根据名称实例化HTableDescriptor对象htd,向该对象加入Htable表的列族,最后HBaseAdmin对象执行createTable(htd)即可把该Hbase表成功建立于Hbase数据库中,创建过程如图12所示。 很显然,在妥善结束了Hbase表的描述后,此时关于HBase表的创建工作,只是遍历n个表项,也就是在O(n)的时间内就会完成。 实现数据库中多张数据表间存在关系,研究可以下面的3张表间的关系作为例子,说明程序实现关系的查询,及最后形成的Hbase结构。 Comment表作为一个关系表,记录User对Goods的评价信息,一个用户可以对多个商品进行评价,同一个商品也能得到多个用户的评价,表间的关联信息如图13所示。在数据库中则表现为NEST_3的关系形式,自动转换到HBase数据库中。 通过执行程序,NEST_3关系的发现,会在XML文件中记录,主表是哪张表,以及关系中的中间表和关系表的信息,其中Set集合中第一张表是中间表,第二张表是与主表间有NEST_3关系的表。此后先对Comment表展开基本的表模式转换生成HTableDef对象,再查找RelativeRecord中以Comment为主表的所有的关系记录,根据表间关系的转换规则进行表模式的转换,把这种SQL Server数据库中的关系模式也添加到HTabelDef对象中,由此也就完成了HTableDef对象的生成工作,接下来就是把HTableDef对象记录的HBase表的模式插入到HBase数据库中。最后循环遍历HTable列表,完成HBase表模式的创建, 5 SQL Server数据库数据迁移到HBase数据库 根据SQLServer数据库表的模式转换规则,以及转换后生成的HBase表,再结合HBase数据插入的特点,就可以把已生成关系的表中的数据依次导入到Hbase数据库中[17]。 在分析Hbase数据库数据插入方法的基础上,针对每个SQL Server数据表得到数据集,每一行按列名和对应值实例化Put对象,Put对象实例化的参数为该行数据的主键值。如果是关联表,根据主表外键的值作为关联表的主键值,查询得到关联表的信息,进而添加到Put对象中。最后执行HBase接口,执行到HBase数据库中[18]。整体方案如图14所示。 这里分为主表数据的导入和关联表数据的导入。主表数据的导入相对比较简单,只是查询到所有的数据,使用主键列的值作为行键实例化Put对象,再把列名和列对应的值,依次添加到Put对象即可。关联表数据的插入相对复杂,需要先根据关系获取每个行键对应的关联表的数据,然后再根据行键实例化对象,依次添加行数据的所有列和对应的值添加到Put对象。其他后续把生成的Put对象列表,调用HBase数据库的接口函数完成数据的导入。
HBase数据导入,需要使用Hbase数据表的行键值实例化Put对象,数据插入时,还要制定需插入的键值对所在的列族。并且键值对中,值必须先根据对应的Java基本数据类型转化为byte[]字节数组,才能将其作为Put对象的参数值。
因为只要给定行键值,实例化Put对象,Hbase的API函数就能把数据插入到正确的位置。因此对关系表的导入,只需要找到该条关系表数据对应主表的数据的主键,即对应Hbase表的行键,就可以完成关系表的数据插入操作。下面将分别论述基础表信息的导入和关联表信息的导入。
5.1 基础表信息的导入
基础表信息的导入,循环遍历HTable表,依次实现如下的操作过程。
1) 首先执行Sqlserver 数据库查询操作,得到全部数据。逐条遍历每条结果数据,得到该条数据的行键值,使用该行健的值实例化Put对象。然后获取该HTable表的表名列族的所有列以及对应列的值,根据列族和列的名称获取该列的类型,再把对应列的值转换成字节数组,最后添加到Put对象中,完成该行一个列数据的导入。循环完成所有列值添加到put对象。
2) 把所有数据行生成的Put对象加入到List
5.2 关联表信息的导入
关联表信息的导入,按模式转换的情况也分为3种情况。首先是循环遍历所有的关系信息列表,然后依据相应情况执行下面的操作过程。
1) INLINE关系
INLINE关系的记录形式中,包括了中间的关联表信息,实质上INLINE关系里主表和关联的中间表之间包含有一组的NEST_2的关系,具体的数据导入可参见2)。2张表之间的INLINE关系,在数据导入时需借助于中间的关联表,设计可概述如下:
先根据每页的大小逐页的得到主表的主键和外键值的集合,这里的主键值作为行键的值,用于实例化Put对象。
循环遍历外键值的集合,根据对应外键的值找到关系表与主表对应的数据的行,把该INLINE关系表的数据逐行导入。先是执行中间表和INLINE表的关联查询,其中筛选条件是2张表的关联的键值相同并且中间表的主键值等于主表的外键关键列的值,即会得到对应行键的INLINE表的所有主键值和外键值的集合。然后遍历行键的值集合实例化Put对象,根据查询得到的与行键相关的INLINE表的数据行, 向Put对象的列族中添加该行每列对应的值,完成所有列与列值的添加,把Put对象添加到List
直到行键循环结束执行Hbase的API函数,一次执行List
假设主表有m行数据,则对应的中间表至多有m行(数据表之间的一对一、多对一的关系)与之关联。同理,中间表对应的INLINE表至多有m行数据。根据主表查找中间表需要O(m)的时间,得到中间表之后,再查找INLINE表需要O(m)的时间。因此,在INLINE关系的数据导入,时间复杂度为O(n)。
2) NEST_2关系
NEST_2关系的模式转换,先根据关系中主表的表名获取到HBase表对象,
此后执行Sql查询,得到主表的主键和外键列对应值的集合,保存到List
循环遍历主键和外键值的集合,根据主键列的HBase中的数据类型,转换生成字节数组rowKey,使用rowKey实例化Put对象。
根据关系表关系表的主键和与主表外键对应的值,查询得到关系表的数据结果集合。按行遍历结果集合,按列名和值对应的形式添加到Put对象中。所有的遍历结束得到List
执行Hbase的API函数,把List
图16 NEST_2关系表信息的导入
Fig. 16 Import of NEST_2 table information
这里NEST_2关系,是主表与直接外键关联表的关系,假设主表有n行,与之关联表就有n行,遍历n行数据,根据主表主键实例化对象,调用api插入HBase数据库,其时间复杂度也就是O(n)。
3) NEST_3关系
这种关系的导入,就是多个Nest_2关系的导入。具体地,Nest_3关系中的主表和其他关联表之间均按照NEST_2关系的导入方式进行导入,循环遍历所有的关联表,完成NEST_3关系的导入。
6 实验结果对比分析
从SQL Server向HBase数据库迁移数据,因为要保留之前的关系,HBase数据库中必然要有更多数据冗余,才能够通过单张表把关系给记录下来。数据库中的关系越复杂,主表中的数据越多这种冗余就会越大。为了使数据迁移的结果较为明显,以少量数据为例进行对比说明,更为清楚。
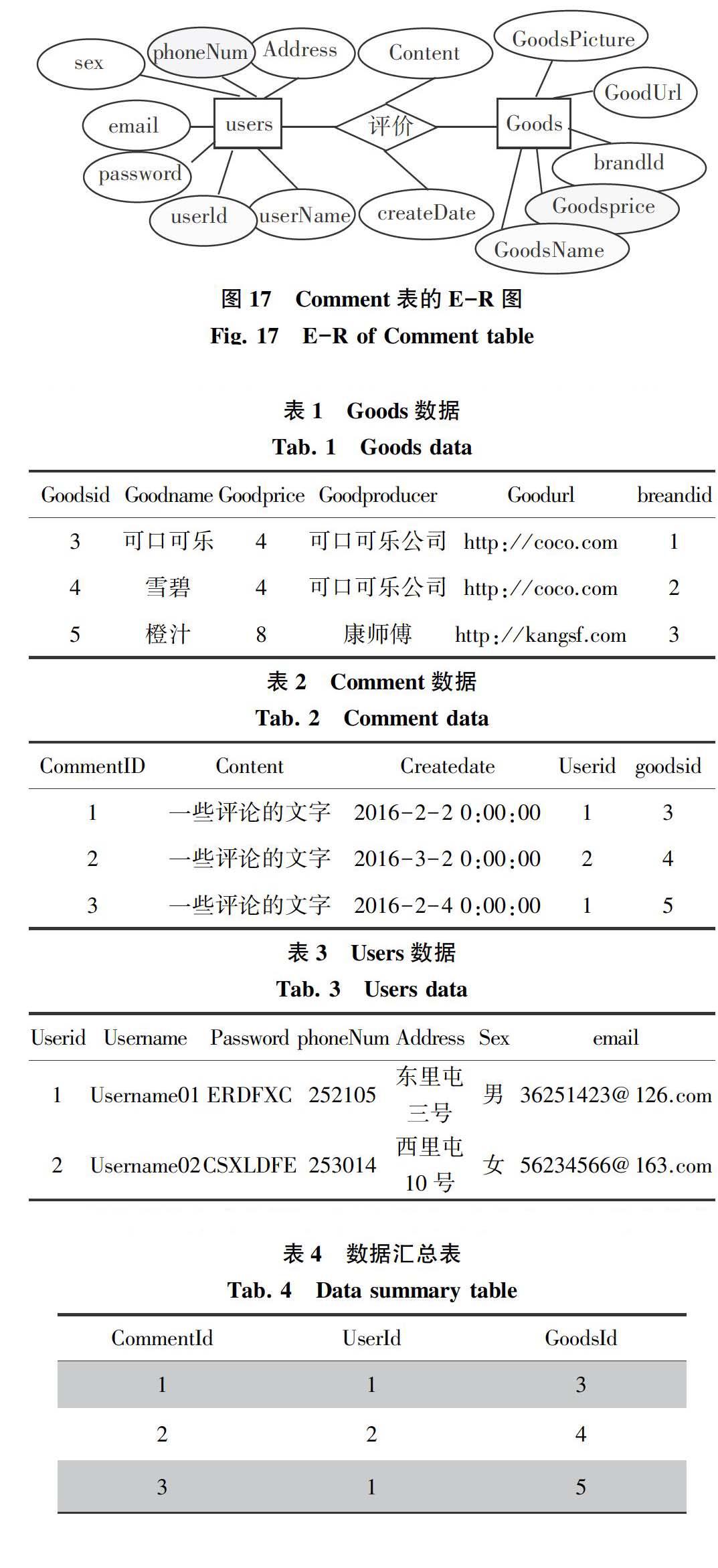
首先,对比说明中构建了3张表,在SQL Server数据库中的关系是NEST_3关系。Comment表记录的是Users表中某个User对Goods表中某个Good的评价信息,很明显形成了如图17所示的ER关系。
图17 Comment表的E-R图
Fig.17 E-R of Comment table
其中,每张表对应的实验数据如表1~表3所示。考虑到数据库字段中/英文的差异,在实验数据的填写上,既有中文、又有英文。而在研究的HBase数据库中,中文的字段值在Scan查询中是无法确认查看的,而英文的字段值,却能够通过列的value属性直接查看得到,从而验证导入数据的正确性。
根据当前表中的数据,汇总到同一张表中,可得综合简要结果。这里Comment表作为主表,根据Comment表的UserId/goodsId字段的值,可以得到如下的结果,如表4所示。
分析以上的关联关系,可知Hbase表中应该有3行数据,每行数据的行键依次为1/2/3,行键的值转换为byte[]字节数组后的值依次为\x00\x00\x00\x01,\x00\x00\x00\x02,\x00\x00\x00\x03。对应行键1的Users列族的userId为1,即column=Users:userId, value=\x00\x00\x00\x01;Goods列族的goodsId为3,即column=Goods:goodsId, value=\x00\x00\x00\x03。其他类推,并且要确保列族的列的数量要与SQL Server表的字段数相同。
在此,针对HBase数据库进行查询,由HBase查询得到的结果数据集,能够看出Goods和Users的重复内容较多。Comment表中已经有了Users和Goods表的主键的值,然而在Users和Goods列族中该列的值仍会重复出现。
由研究查询结果还能看到Users和Goods列族中都有特殊的列,比如vipId/brandId,这2个列明显是其他表的主键,当前列族的外键。也就是NEST_3关系,并没有递归到所有的关联表,然后在同一张表中保存相关的数据。因此,这种模式转换和数据迁移,只能够有效的处理和保存原SQLServer数据表的比较直接的关联表中关系。
7 结束语
本文通过设计和实现SQL Server数据库中表模式的转换和表中数据的迁移,分析了过程中算法实现和表间关系的定义,综合考虑SQL Server数据库和HBase数据库之间的不同,针对彼此的特点实现了两者数据库中数据的一键模式转换和数据迁移。通过对迁移前后,各数据库中数据的对比分析,本文提出的解决方案能够正确实现数据迁移,并且有效保留了SQL Server数据表间的关系。
HBase作为非关系型数据库,在保留原有SQLServer数据表间关系的同时,势必形成数据的冗余。并且本文在表间关系的自动发现的规则定义,仅考虑了3级的层次关系,对于一般的数据库是适用的。在不同的应用场景下,还需根据特定的需求设计具有针对性的表间关系的规则定义。
参考文献
[1] 王堪美. 基于数据分发服务的监控与存储研究[D]. 北京:中国科学院大学, 2013.
[2] 冯晓普. HBase存储的研究与应用[D]. 北京:北京邮电大学, 2014.
[3] GEORG L. HBase: The Definitive Guide[J]. Andre, 2011, 12(1):1 - 4.
[4] TAYLOR R C. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics[J]. Bmc Bioinformatics, 2010, 11 Suppl 12(6):3395-3407.
[5] 李颖, 李建民, 林振荣. 用JSP/Servlet和JavaBeans技术实现SQL Server表与DBF文件的相互转换[J]. 计算机与现代化, 2007(1):95-97.
[6] 刘雅辉. DBMS间模式转换技术应用研究[D]. 北京:北方工业大学, 2009.
[7] 舒清录. 基于.NET的异构数据源数据迁移技术[J]. 计算机技术与发展, 2010, 20(3):109-112.
[8] 胡晓鹏, 李晓航, 李岗. 一种基于XML映射规则的数据迁移方法设计和实现[J]. 计算机应用, 2005, 25(8):1849-1852.
[9] (美)George. HBase权威指南[M]. 北京:人民邮电出版社, 2013.
[10] 李雯, 谢辅雯, 邹道明. XML数据交换技术的应用与研究[J]. 计算机与现代化, 2008(1):91-93.
[11] 王晴. 关系数据库与SQL Server教程(教材)[M]. 北京:中国人民大学出版社, 2009.
[12] 尼马·贾拉利, 埃里克·塞德拉, 尼普恩·阿加瓦尔,等. 用于访问关系型数据库系统中的分层数据的高效索引结构: 美国,CN02819168.4[P].2005-01-05.
[13] KENT W. A simple guide to five normal forms in relational database theory[J]. Communications of the ACM,1983,26(2): 120-125.
[14] Cattell R. Scalable SQL and NoSQL data stores[J]. ACM SIGMOD Record, 2010, 39(4): 12-27.
[15] GEORGE L. HBase: the definitive guide[M]. Sebastopol, USA:O'Reilly Media, 2011.
[16] 孙兆玉, 朱鸿宇, 黄宇光. 一种SQL语法分析的策略和实现[J]. 计算机应用, 2007, 27(S1):18-20,23.
[17] 邵开丽, 姜伟, 吕举文. 一种大规模数据快速并行导入工具的研究与实现[J]. 计算机应用与软件, 2015,32(9):26-30.
[18] YANG J, FENG X. Loading Data into HBase[M]// WONG W E, ZHU T .Computer Engineering and Networking.Switzerland:Springer International Publishing, 2014:265-271.
猜你喜欢
资治文摘(2016年7期)2016-11-23
资治文摘(2016年7期)2016-11-23
人间(2016年28期)2016-11-10
课程教育研究·学法教法研究(2016年21期)2016-10-20
中国市场(2016年33期)2016-10-18
大学教育(2016年9期)2016-10-09
成才之路(2016年26期)2016-10-08
成才之路(2016年25期)2016-10-08
科技视界(2016年20期)2016-09-29
