
情感分类综述
2016-11-14 03:27李超男
现代计算机 2016年29期
李超男
(四川大学计算机学院,成都 610065)
情感分类综述
李超男
(四川大学计算机学院,成都610065)
随着电子商务和媒体社交工具的普及,互联网上充斥着极其丰富的信息资源。商业界、政界和学术界敏感的认识到这些数据的宝贵,大批研究者开始分析抽取这些数据中的信息。情感分类受到研究者们的密切关注,因为有效的情感分析可以引导人们消费、帮助商家改进研究新产品、对社会舆情进行监控等。介绍情感分类的机器学习方法和侧重解决的问题,并对目前情感分类的研究进展进行总结归纳。
情感分类;情感分析;评价指标;特征选择
0 引言
目前,随着媒体社交工具如微博、微信等的蓬勃发展,人们越来越喜欢在网上发表自己的情感和观点。因此,对网络上这些大量的带有情感的数据进行分析分类对于电子商务中用户决策和舆情监控等有重要的意义。情感分类是一种特殊的文本分类,它对包含有主观倾向性的文本进行分析整理得到文本发表者对某种观点的支持与否,如人们对于“衣服”的“尺码、布料、做工、设计”等属性的情感倾向。本文从机器学习方法和情感分类侧重关注要解决的问题对情感分类研究工作进展进行分析、阐述、总结。
1 情感分类的机器学习方法
1.1有监督学习的情感分类
监督学习是一种根据给定标签的数据集不断调整函数参数使其达到期望目标的机器学习任务。Pang首次运用监督学习方式进行情感分类;他在文献[1]中比较了朴素贝叶斯、最大熵和支持向量机三种分类算法及特征选择策略(Bigram、Unigram、Parts-of-Speech)及词位置和特征权重的选择在情感分类中的效果,证明了情感分类任务比主题分类要复杂困难[1]。
此后,很多研究者致力于提高监督学习的情感分类研究。如Kim和Hovy借助主题来进行英语词和句子的情感分类,后来他们利用使用语义角色标注的语义结构从网络新闻媒体中分析文本发布者和该文本主题的观点[2]。Balamurali and Joshi使用词义特征(WordNet中的同义反义词集)进行情感分类,实验结果表明比基于词特征的分类效果要好得多[3]。不同于传统词袋模型,Bespalov等将文档看做BON (bag-ofngram,(n>3))并使用latent n-grams解决这种方法引发的维度灾难[4]。
1.2半监督学习的情感分类
半监督学习是在大量没有标注的数据集(US)和少量已标注数据集 (LS)上进行学习的问题。协同学习(Co-training)、自学习、Transductive SVM和EM是最常见的算法。Co-training是用在数聚集特征划分到的不同特征集上独立学习到的分类器在无标注数据集上进行分类或者标注。Wan就采用Co-training方法使用少量有标注的英文语料在大量的无标注中文语料上进行了高效的中文情感分类[5]。Li和Huang也采用了协同学习方法对分成个人和非个人两种类别的文本清醒半监督情感分类[6]。Dasgupta和Ng采用以将明确的容易提炼的和模糊的难以分类的评论区分开来为主要思想的半监督方法进行极性分类[7]。
另外值得一提的是,Sindhwani和Melville采用基于文章和词的二部图即用词的先验知识结合未标记语料进行情感分类[8]。形、音、义是语言的三个属性,其中义尤其重要。研究文本的词义语义信息无疑对于自然语言处理数据挖掘有很重要的意义。随着深度学习算法的日益成熟,自然语言处理研究者们将深度学习算法逐渐引入NLP任务中并取得较好效果。Zhou和Chen提出了一种由RBM和无监督学习方法结合构造的半监督学习算法AND[9]。
1.3无监督学习的情感分类
无监督学习的情感分类仅在未标注的数据集上进行学习,他们提取未标注数据集的情感倾向特征然后根据这些特征给数据集打上情感类别的标签。最典型的无监督学习是聚类,聚类使得数据集中的数据按照某些相似的特征分类组织。聚类类型有划分聚类(K-means、CLARA、PCM)、层 次 聚 类 (CURE、ROCK、CHEMALOEN)、基于密度聚类(DBSCAN、FDC、OPTICS)、基于网格聚类(SING、CLIQUE)和基于模型聚类(COBWEB、CLASSIT)。以往的无监督情感分类大多数都是借助种子词集实现,例如:Turney抽取含有形容词和副词短语的语料,之后计算这些短语与种子词“poor”及“excellent”的点互信息,然后用得到的点互信息计算短语的情感倾向得分[10]。
只考虑每个单词的极性然后通过计算该词语在各个极性中频数的多少决定文档的情感倾向效率是很低的,如:“完美”一词表现出了直观的积极性,但若是“完美的混乱”这个短语所表达的情感倾向就不同了;基于单个词的向量空间模型虽在学习词法信息方面取得很大成功,但它们不能准确捕捉长短语或句子多表达的综合信息。Weichselbraun and Poria就在句子层面即结合上下文环境进行情感分类[11]。Richard Socher团队依次提出向量矩阵空间,递归神经网络RNN,MV-RNN和RNTN等基于语义分析树结构的方法进行句子层面语义分析[12]。
2 情感分类任务研究的问题
2.1领域适应性
情感分类具有领域相关性,研究者发现监督学习的情感分类方法在训练测试集分属不同领域的数据集上分类效果较差。Hu和Liu研究发现对产品的评论分类结果与在新闻和文学上的评论分类结果是不同的[13]。所以解决领域适应性问题是情感分类的重要研究方向。研究者们一直在寻找一种有效的映射方法,使得一个领域的数据集特征可以映射到另一个领域的数据集特征,即找到这些特征的相关性。领域适应中的训练集的选取、特征选择和各种分类器的融合是具体的研究内容。Alec Go和Richa Bhayani用推特上的博文进行情感分类,这种数据集对于模型的建立非常重要,训练出来的模型适用于其他领域[14]。吴琼和刘悦提出基于热传导模型思想的框架进行跨领域情感分类[15]。
跨领域要求有大的涉及多领域的训练数据集,如果采用有监督的方式就会耗费大量人工去标注数据集,所以绝大多数采取半监督或者无监督方法去自动学习数据集的特征。Deschacht and Moens提出了隐含词语言模型,这个模型是无监督的,它通过对词汇进行聚类减少了语义角色标注中词汇化特征的稀疏性[16]。聚类缓解了词汇化特征的稀疏性,但是在句法结构上提取的特征的稀疏性几乎没有方法进行有效的解决。在图形处理计算视觉领域可以有效地自动学习发现图片数据集的高层次特征并取得巨大成功的深度学习算法引起了NLP学者们的视线。庄涛就采用可以学习到两个领域的公共特征的DBN模型减少了领域特征之间的稀疏性。Glorot和Bordes采用一种叠加自动去噪编码器(Stacked Denoising Auto-Encoders)和稀疏整流装置单元结合的深度学习方法用于情感分类,而他们设计的模型在含有22个领域的评论上效果很好[17]。
2.2数据不平衡
数据不平衡就是指收集的数据集中各类数据分布及其不均匀,如二分类问题,属于正例和负例的数据比例为500:1,这种现象就属于数据不平衡。在情感分类问题中,实际收集到的语料集大多是不均匀的,传统的分类方法将会将类别偏向多数的类别降低分类器的分类性能。解决数据不平衡问题有两种思路:第一种是数据层面,既然数据平衡那么就寻找适当的抽样算法让数据达到平衡,具有代表性的抽样方法有重采样(欠采样和过采样)、SMOTE、Informed Undersampling等;第二种是算法层面,主要考虑数据错分即多的一类被分为少数,少数被分为多数这种误分类所导致的代价函数,最主要的算法思想就是代价敏感学习。
3 情感分类评价指标
一般情感分类器采用以下三个评价指标:正确率和召回率(查全率)以及F-score。

表1
正确率P和召回率R的计算公式分别如下:
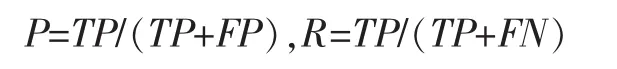
F-score表示准确率和查全率的调和平均值。
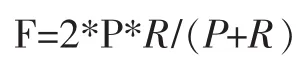
4 结语
情感分类作为自然语言处理中文本分类的一种,在商界和学术界都得到了很大关注,是科研工作者们的研究热点也在研究过程中获得很大进展。本文从机器学习方法和情感分类侧重研究的问题出发,介绍了一系列的相关工作。情感分类技术中文本的表示(VSM、词组、概念)、文本特征选择方法(信息增益、χ2统计量、互信息……)、特征权重计算(TF-IDF、TFC、ITC、熵……)、分类器设计这些因素的选择至关重要。目前的研究工作主要侧重于文本特征的提取和分类模型的创建。
[1]Pang B,Lee L,Vaithyanathan S.Thumbs up:Sentiment Classification Using Machine Learning Techniques[C].Proceedings of the ACL-02 Conference on Empirical Methods in Natural Language Processing-Volume 10.Association for Computational Linguistics,2002:79-86.
[2]Kim S M,Hovy E.Determining the Sentiment of Opinions[C].Proceedings of the 20th International Conference on Computational Linguistics.Association for Computational Linguistics,2004:1367.
[3]Balamurali A R,Joshi A,Bhattacharyya P.Harnessing Wordnet Senses for Supervised Sentiment Classification[C].Proceedings of the Conference on Empirical Methods in Natural Language Processing.Association for Computational Linguistics,2011:1081-1091.
[4]Bespalov D,Qi Y,Bai B,et al.Sentiment classification with Supervised Sequence Embedding[C].Joint European Conference on Machine Learning and Knowledge Discovery in Databases.Springer Berlin Heidelberg,2012:159-174.
[5]Wan X.Co-training for Cross-Lingual Sentiment Classification[C].Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP:Volume 1-Volume 1.Association for Computational Linguistics,2009:235-243.
[6]Li F,Huang M,Zhu X.Sentiment Analysis with Global Topics and Local Dependency[C].AAAI.2010,10:1371-1376.
[7]Dasgupta S,Ng V.Mine the Easy,Classify the Hard:a Semi-Supervised Approach to Automatic Sentiment Classification[C].Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP:Volume 2-Volume 2.Association for Computational Linguistics,2009:701-709.
[8]Sindhwani V,Melville P.Document-Word Co-Regularization for Semi-Supervised Sentiment Analysis[C].2008 Eighth IEEE International Conference on Data Mining.IEEE,2008:1025-1030.
[9]Zhou S,Chen Q,Wang X.Active Deep Networks for Semi-Supervised Sentiment Classification[C].Proceedings of the 23rd International Conference on Computational Linguistics:Posters.Association for Computational Linguistics,2010:1515-1523.
[10]Turney P D.Thumbs up or Thumbs Down:Semantic Orientation Applied to Unsupervised Classification of Reviews[C].Proceedings of the 40th Annual Meeting on Association for Computational Linguistics.Association for Computational Linguistics,2002:417-424.
[11]Weichselbraun A,Gindl S,Scharl A.Extracting and Grounding Context-Aware Sentiment Lexicons[J].IEEE Intelligent Systems,2013,28(2):39-46.
[12]Socher R,Perelygin A,Wu J Y,et al.Recursive Deep Models for Semantic Compositionality over a Sentiment Treebank[C].Proceed
ings of the Conference on Empirical Methods in Natural Language Processing(EMNLP).2013,1631:1642.
[13]Hu Y,Lu R,Li X,et al.Research on Language Modeling Based Sentiment Classification of Text[J].Journal of Computer Research& Development,2007,44(9):1469-1475.
[14]Go A,Bhayani R,Huang L.Twitter Sentiment Classification Using Distant Supervision[J].CS224N Project Report,Stanford,2009,1:12.
[15]吴琼,刘悦,沈华伟,等.面向跨领域情感分类的统一框架[J].计算机研究与发展,2013,50(8):1683-1689.
[16]Deschacht K,Moens M F.Semi-Supervised Semantic Role Labeling Using the Latent Words Language Model[C].Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing:Volume 1-Volume 1.Association for Computational Linguistics,2009:21-29.
[17]Glorot X,Bordes A,Bengio Y.Domain Adaptation for Large-Scale Sentiment Classification:A Deep Learning Approach[C].Proceedings of the 28th International Conference on Machine Learning(ICML-11).2011:513-520.
Sentiment Classification;Sentiment Analysis;Evaluation Index;Feature Selection
Overview of Sentiment Classification
LI Chao-nan
(College of Computer Science,Sichuan University,Chengdu 610065)
With the popularity of e-commerce and social media tools,Internet is full of extremely abundant source of information.Businessman,government staff and academia realized the great value of these data,which many researchers have begun to extract information from these data.Sentiment classification attract the attention of researchers,because the effective sentiment analysis can guide consumption,help to developing new products and monitoring public opinion and so on.Introduces the machine learning methods and key problems of the sentiment classification,and gives a summary to the research progress of the sentiment classification.
1007-1423(2016)29-0041-04
10.3969/j.issn.1007-1423.2016.29.009
李超男(1991-),女,河南濮阳人,研究生硕士,研究方向为数据挖掘
2016-07-12
2016-10-10
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
计算机世界(2020年50期)2020-01-15
铁道通信信号(2019年6期)2019-10-08
青年生活(2019年23期)2019-09-10
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
