
基于改进的Single-Pass算法微博话题发现
2016-11-14 03:27陈龙稳
现代计算机 2016年29期
陈龙稳
(四川大学计算机学院,成都 610065)
基于改进的Single-Pass算法微博话题发现
陈龙稳
(四川大学计算机学院,成都610065)
详细介绍传统的Single-Pass算法并分析它的特点和不足之处,并针对传统的Single-Pass算法对输入顺序敏感的问题,提出一种改进方法,即找出含有话题信息丰富的微博客文本优先聚类,得到初始的话题簇,再对余下的微博客文本进行聚类以提高聚类的精度。对话题发现的流程:文本预处理、向量模型的构建、Single-Pass聚类、凝聚层次聚类进行详细的描述,实验结果表明该方法在召回率、准确率、F值指标上均优于传统的方法。
微博;Single-Pass;话题;聚类
0 引言
以新浪微博为代表的微博客是年轻一代网民获取资讯、分享信息的重要平台,由于平台准入的门槛低,所有注册用户都可以对同一话题发表自己的看法、评论别人发表的信息。当参与的网友众多时,话题热度会飙升,相关的帖子数量也随之猛涨,而用户的精力却十分有限,不可能通过阅读所有帖子来获取相关话题的有用知识,话题检测与追踪技术可以有效解决此类问题[1]。微博客的话题检测技术不仅可以为用户展示当前微博讨论的话题,还可以为政府部门提供舆情监督和舆情引导以及为商业决策提供数据依据,因此成为当前学术界一个热门的研究方向。
1 微博客的特点
微博客话题发现不同于传统的话题发现,传统的话题检测(发现)主要针对的是新闻文章等篇幅较长、表意清楚的文章,一篇文章通常包含一个或几个话题。而微博的长度普遍较短,少则几个字、十几个字,最多也就一百多字。微博短文本的特点主要体现在:①文本表达口语化,不规则用词多、网络用语多;②文本特征词少且稀疏,使得特征之间的相关性难以度量[2];③文本样本数量巨大,分布高度不平衡,少部分的短文本在整体中占有较大比重[2];④内容多样、随意性大,不同的用户可以随时随地根据自己的喜好自行组织语言、自行发布信息;⑤内容碎片化、表意不完整,大部分的微博客文本内容都很短小,且发布者只是简略的发表自己的所见所闻或当时的感受,没有对事件进行完整的描述。针对微博客的这些特点,现在有很多话题发现算法,其中比较经典的方法是Single-Pass聚类算法。
2 Single-Pass算法
2.1经典的Single-Pass算法
Single-Pass算法是一种增量式的聚类算法,它的主体思想是:首先设置一个相似度的阈值ε,并把待聚类的文本排好序,然后对于每一个待聚类的文本,和之前各个聚类中的文本进行相似度的比较,如果相似度均小于阈值ε,则增加一个新的聚类且把此文本分配给该聚类;否则把该文本分配给与其相似度最大的聚类。
经典的Single-Pass算法存在一些问题:
(1)对文档的输入顺序敏感,如果先聚类的文档质量不高,含有的话题内容不够丰富,则最终形成该话题的聚类结果不够理想。
(2)每个待聚类的文档要与之前所有已经聚类的文档逐个进行相似度的计算并与阈值ε比较,当文档数很多时,后期的聚类计算量会很大,效率低下。针对这一问题,孙胜平[3]等引入话题向量来表示话题聚类簇,这样新来的微博客文本只需和话题向量进行相似度的计算,如果相似度小于阈值则以此微博客文本创建一个新的话题聚类簇,否则把它并入到与它相似度最大的话题聚类簇中,并用该微博客文本更新此话题聚类簇的话题向量。
2.2改进的Single-Pass算法
针对经典的Single-Pass算法存在的第一个问题,本文做出如下改进:
由于微博客一般字数较少,含有的话题信息较少,而字数较多的微博客含有的话题信息一般比较丰富,因此可以选择字数较多微博客文本首先进行聚类形成初始的话题聚类簇,再把剩下的微博客聚类到前面的话题簇中,这样初始的话题簇含有比较丰富的话题信息,可以大概的表示该话题,减少后续微博客文本误分类的可能性。
对于第二个问题,本文采用孙胜平的方法,引入话题向量来表示一个话题簇。
3 基于改进的Single-Pass算法微博客话题发现
3.1文本预处理
去掉微博客中对话题表示没有作用的内容,如音频、视频、超链接、特殊符号,然后对处理后的微博客文本进行词法分析,这里选用的是中国科学院计算技术研究所研制的汉语词法分析系统NLPIR(又名ICTCLAS2013),它的主要功能包括中文分词;词性标注;命名实体识别;用户词典功能;支持GBK编码、UTF8编码、BIG5编码[4]。对分词后的文本去掉连词、代词、介词、标点符号等对文本意思表达没有作用的停用词。
3.2构建空间向量模型 (Vector Space Model,VSM)
设所有待聚类的文本集合为D={D1,D2,…,Dn},则单个文档Di可以表示为向量Di,即:
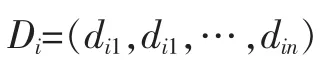
其中,n为所有文档的经过预处理和停用词过滤后的词汇个数,dij为文档Di含有的第j个词,当文档含有该词时dij=1,不含有该词时dij=0。
由于在文档中,不同的词对文档内容的贡献度不同,因此需要对词进行加权处理,常用的加权方法有布尔函数加权、TF-IWF加权、归一化的TF-IDF加权等。其中用的最多的是归一化的TF-IDF加权,本文采用的是这种加权方法。
TF-IDF(Term Frequency-Inverse Document Frequency),即词频-反文档频率,词频TF表示一个词在文档中出现的频率,反文档频率IDF表示词在整个文档集中出现的频率。当一个词在本文档中出现的次数较多而在其他文档中很少出现,则它的TF-IDF值较大,该词的权重也较大。
TF的计算公式为:
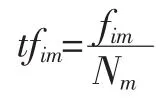
其中,fim表示文档Dm中第i个词出现的次数,Nm表示Dm中词的个数。
IDF的计算公式为:
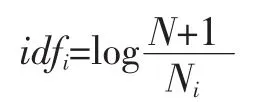
其中,N表示文档总数,Ni表示包含词i的文档个数。
则权值可表示为:

一般会对词的TF-IDf作归一化处理,设文档Dm的第i个词的权重为wmi,则该词的归一化TF-IDF值wmi为:
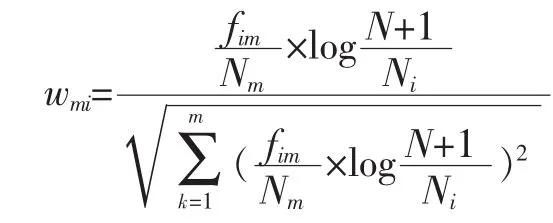
则经过归一化TF-IDF加权后的单个文档Dm可以表示为向量Dm,即:
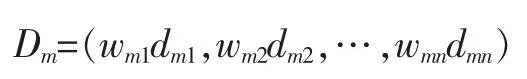
而两个文档之间的相似性,可以用余弦相似度来衡量,记文档Di,Dj之间的余弦相似度为sim(Di,Dj),则有:
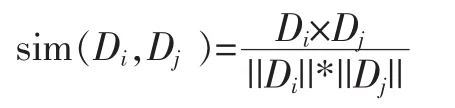
3.3算法执行的步骤
基于改进的Single-Pass算法话题发现的主要思想是:首先对微博客进行文本的预处理,去掉无用的信息,然后把微博客表示成词向量形式,运用改进的Single-Pass算法先对内容丰富的微博客文本进行聚类再对余下的微博客文本进行聚类,对得到的话题簇向量运用凝聚层次聚类[5]进行最终的聚类,最终得到的聚类结果即为发现的话题簇。具体步骤如下:
将微博客经文本预处理后表示为归一化TF-IDF加权的空间向量模型。
得到含词较多的微博客文本向量集,记为S,余下的微博客文本向量集记为T。
对于S中文本向量,设置一个比较高的相似度阈值ε(为了得到凝聚度高的数量不太少的话题簇用于凝聚层次聚类),第一个文本向量记为该话题的话题向量,对于后面的文本向量,与之前的话题向量逐一进行比较,如果都小于阈值,则用该向量新建一个话题,否则把其归为和它相似度最大的聚类簇中,并用此文本向量更新话题向量。直到S中的向量都进行了聚类。
343 耳石复位联合药物对继发性良性阵发性位置性眩晕患者的应用效果 于红霞,王淑珍,李英杰,武晓玲,郝智军
对于T,在S聚类结果的基础上,用同样的方法进行聚类。
得到经3、4聚类的结果U={u1,u2,…,un},其中ui包含聚类的文本向量和表示该聚类簇话题向量。
设置一个较大的聚类相似度阈值k(为了最终得到几个话题簇,而不是一个话题簇),进行凝聚层次聚类,对于两个话题向量,当它们的相似度大于k时才聚类,否则不予聚类。得到最终的话题簇。
4 实验结果及分析
实验采用的数据集是从BigDataOPC平台爬取的微博客语料,包括“天津塘沽爆炸”、“导游侮辱游客”、“养老金改革”、“全面开放二胎”、“拐卖儿童入刑”这5个热点话题各1000条及作为干扰的微博客500条。
实验采用的性能评价指标为准确率、召回率和F值,各指标含义如下所示。
准确率(Precise)表示聚类算法检测出来的属于该话题的的博客数(A)与该聚类簇所有博客数(B)的比值,记为P,则:

召回率(Recall)表示聚类算法检测出来的属于该话题的的博客数(A)与属于该话题的所有博客数(C)的比值,记为R,则:
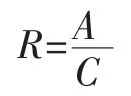
F值(F-measures)是准确率和召回率的调和平均,计算公式如下:

用原始Single-Pass算法(引入了话题向量)加凝聚层次聚类算法得到的结果如表1所示,用改进的Single-Pass算法加凝聚层次聚类算法得到的结果如表2所示。

表1
表2
由结果可知,经过改进后的Single-Pass算法在准确率、召回率和F值上均优于原始的Single-Pass算法,这是由于改进的方法初始的聚类文本含有丰富的话题信息,能够比较好的建立初始话题,在后续的微博客文本聚类中能够减少错误聚类的可能性。
5 结语
本文针对初始聚类的微博客文本可能表示话题能力不足的问题,改进了Single-Pass算法并应用到微博客话题发现中,实验表明这种改进对微博客话题发现的性能有一定的的提升。
未来可以针对微博客的特点研究出新的方法来进一步改善话题检测的精度,同时本文只是根据微博客中的文本信息进行话题发现,如何充分利用微博客中的图片、视频、社会网络关系来发现话题是未来一个研究的重点。
[1]彭敏,官宸宇,朱佳晖,等.面向社交媒体文本的话题检测与追踪技术研究综述[J].武汉大学学报理学版,2016,3:197-217.
[2]蒋盛益,麦智凯,庞观松,等.微博信息挖掘技术研究综述[J].图书情报工作,2012,56(17):136-142.
[3]孙胜平,张真继.中文微博客热点话题检测与跟踪技术研究[D].北京:北京交通大学,2011.
[4]NLPIR[EB/OL].http://ictclas.nlpir.org/docs.
[5]Pangning T,Steinbach M,Kumar V.数据挖掘导论[M].北京:人民邮电出版社,2006.
WeiBo;Single-Pass;Topics;Clustering
Find Weibo Topics Based on the Improved Single-Pass Algorithm
CHEN Long-wen
(College of Computer Science,Sichuan University,Chengu 610065)
Introduces the traditional Single-Pass algorithm in details and analyses its characteristics and disadvantages,and in view of the traditional Single-Pass algorithm is sensitive to the problem of input sequence.In order to solve the problem and improve the accuracy of clustering,proposes an improved method,namely,identifies the topic information rich microblog text to cluster to get the initial cluster result,then clusters the rest of the micro blog text.Topic discovery process:text pretreatment,vector model build,Single-Pass algorithm,hierarchical clustering algorithm has carried on the detailed description.The test shows that the method on the recall ratio and accuracy,F value index is superior to the traditional method.
1007-1423(2016)29-0022-04
10.3969/j.issn.1007-1423.2016.29.005
陈龙稳(1990-),男,湖北黄冈人,在读硕士研究生,研究方向为数据挖掘、话题检测与追踪
2016-07-19
2016-09-10
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
信息安全研究(2016年4期)2016-12-01
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
博客天下(2015年2期)2015-09-15
博客天下(2009年12期)2009-08-21
