
基于聚类分析的中国31省市经济发展现状评析
2016-11-12 06:55:50肖瑶
黄冈师范学院学报 2016年5期
肖 瑶
(安徽大学 经济学院,安徽 合肥 230601)
基于聚类分析的中国31省市经济发展现状评析
肖瑶
(安徽大学 经济学院,安徽 合肥 230601)
根据多元统计中的系统聚类法和K-均值法,将全国31个省市依照其经济发展状况大致分成4类,区分了经济发达省市和偏远落后省市,并在分类的基础上对不同类别的省市作出大体的评价,这不仅有助于全国经济的统筹发展,也有助于不同省市之间优势互补、互相借鉴发展模式。
聚类分析;经济发展;转型
一、文献综述
我国作为全世界最大的发展中国家,仍面临着经济发展不均衡、贫富差距明显等问题。总体上来看,我国近几年经济发展速度放缓,GDP增速由2007年的14.16%逐步下降到2015年的6.9%。失业率上升、国际金融危机、体制改革等原因固然会影响全国的经济运行,但分区域来看,有的省市产能过剩有的省市产能不足,有的省市劳动力短缺而有的省市劳动力过剩,这些原因并不能笼统而含糊地一带而过,所以,将全国31个省市的经济发展状况划分归类成相应的类别,将有助于党中央根据不同类别的经济发展特点制定相应的发展政策,统筹规划,取长补短,作出正确的决定。
在对我国31个省市的经济发展状况作出类别划分的问题上,国内外学者对此还未做出过多研究。不过就现有资料表明,大多学者都运用聚类分析做出了简要的分类。聚类分析是多元统计分析中如何对样品或指标进行分类的一种统计方法,针对不同的统计科研问题可以运用不同的聚类分析方法,各类聚类分析方法在其特性、算法、可操作性上都有所不同。聚类分析的过程和方法在地区经济发展评价方面具有一定的实用性,可以得出科学的分析结果,但王玻、李从东(2009)认为,聚类分析方法还存在一定的局限性,虽然聚类分析法来解决分析各学科方方面面的实际问题, 其定量分析的准确性能是毋庸置疑的, 但是初始指标的选择往往也是影响最终结果的重要因素,很多人为控制因素对参数输入、停机条件将有影响,当面对数据过于庞大,维度高度复杂的情况时,聚类分析不能给出一个很好的操作方法,从而无法保证得出高质量的聚类结果。[1]148-151所以,还有学者通过主成分分析、判别分析、因子分析等方法和聚类分析相互验证,从而得出更可靠的分析结果。
从整体经济规模、综合经济水平来看,我国31个省市一般认为可以被分为3到5类。梁国巍、王传美、童恒庆(2003)运用分层聚类法将全国各省市综合经济水平分为3类。[2]他们的研究显示,东部省市经济发展明显快于西部,尤其第一类别作为直辖市,经济基础好,人口密度大,人均受教育水平高,竞争力强,经济发展居于较高水平。第二类省市善于利用自身优势,沿海省市贸易发达,老工业地区实力雄厚,自然资源丰富地域旅游业水平高。第三类省市多为偏远内陆或山区,农业为主,工业落后。王玻,李从东(2009)用谱系聚类法,采用欧式距离作为分类统计量。得出结论认为将全国31个省市按地区经济规模划分为4类最为合理。[1]148-151得出结论与前几年的结果相比,近年来有些城市经济规模稳步前进如西部省市云南、广西等自治区的综合经济规模有明显的改进。祝新亚、李许坚(2011)在对我国主要省市综合实力评价指标进行选取时,经济指标占了很大一部分,其根据聚类分析得出的2008 年各省综合实力发展层次也可以作为本文按经济发展分类的依据。[3]可以看出老牌工业区、沿海省市、内陆、中部地区分别对应着不同的经济发展水平。
从影响经济水平的各个变量看来,金相郁(2004)利用经济变量和次聚类法和对中国区域进行划分,层次聚类法的好处就是划分过程不受其他因素的影响,只受选定变量的影响,所以他以国内生产总值年增长率为基准的区域聚类将全国分为3个类别,东部地区的一些省、市明显地聚成为一类区域,而中西部地区的划分并不明显;按照人均GDP的聚类分析,将全国分为5大类,东部地区分成四个区域, 中西部地区聚成一个区域;按城镇居民平均人均可支配收入和各省农村居民家庭平均人均纯收入的聚类分析,将全国分为5大类,中西部地区的区别不明显,并且,东部地区内部出现不同类型的区域。[4]陈爱娟、程雪(2010)按国际劳务竞争力,将全国31省市划分为4类,沿海省市如上海、浙江、广东经济基础雄厚,人力资源丰富,贸易口岸多,人口较为集中,对外贸易占有一定优势为第一类。而第四类多为中部省份以及西部省份,这些省份深居内陆,自然条件导致经济发展程度和国际贸易发展程度相对较低,中部省份以及西部省份相对来讲国际劳务竞争力比较弱,东部省份和沿海省份国际劳务竞争力相对较强,各省市之间国际劳务竞争力差别巨大。[5]朱冰洁,李玉山(2012)按城镇居民收入,将全国31省市划分为4类,得出结论东部发展快于西部。
由于聚类分析的指标选取在很大程度上影响着分类的结果,所以前人的研究只能给我们的分析作为一种参考,并不能全盘接纳。在制定发展政策时,不同省市对经济发展的侧重点各不相同,因此有必要在作出政策决策之前选取与经济发展目标相符合的指标作为衡量标准,剔除与本省市经济发展无关的变量,筛选出影响决策的主要变量,从而有针对性的制定出合理的发展政策。
二、研究方法
全国31个省市之间经济发展存在着不同程度的相似性,本文采用聚类分析法将31个省市进行分类,使得同一类中的对象之间的相似性比其他类中的对象相似性更强。聚类分析法的目的就是使类间对象的同质性最大化和类与类间的对象的异质性最大化。
不同的聚类分析方法所得出的结果也略有不同,为了保证研究的客观性,我们采用两种聚类分析方法以及进行验证,分别是系统聚类法和K-均值法。
在系统聚类法中,我们先将N个样品分成N类,然后计算N类之间的相互距离,把距离最近的两类合并成一类,从而得到N-1类,再从N-1类中找出距离最近的两类加以合并,从而得到N-2类,依次进行下去,最后,N类样品均归为一类,画出聚类图则可以决定分为多少类,每类各有哪些样品。[6]43-44
K-均值法可以事先选定聚类个数,把每个样品聚集到其最近均值的类中,在修改的过程中,重新计算接受新样品的类和失去样品的类的均值,直到各类无元素进出。[6]43-44
三、聚类分析的具体运用和结果
本文根据数据的可得性,并参考了以往文献资料,从国家统计局网站和各省市2014年统计年报中选取了9个能够表明各省市经济运行总体情况的指标。分别为:年末常住人口、地区生产总值、消费品零售总额、公共财政预算收入、公共财政预算支出、人均可支配收入、全社会固定资产投资、居民人均消费支出、进出口总额。具体指标数据见表1。
虽然我们有9个指标的数据描述出了31个省市的经济发展大体运行情况,但是否有必要将这9个指标都作为分类变量则需要进一步的筛选。先对这9个指标进行降维处理,9个分类变量量纲各自不同,先确定用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,此时,由于涉及到相关,9个变量可不用标准化处理,将来的相似性矩阵里的数字为相关系数。如果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。
从表2指标相似性矩阵中我们可以看到,社会消费品零售总额、公共财政预算收入、公共财政预算支出与地区生产总值的相关系数都大于0.9,于是这4类没有必要都作为聚类变量,选出其中一种即可,本文选择地区生产总值。
由于各个指标的量纲不同,为了防止指标取值的分散程度较大,我们先对各取值做标准化处理。数据经过标准化处理后,再依次用不同聚类方法进行聚类分析。对于分类数的抉择,根据经验资料以及文献整理,我国31个省市一般认为可以被分为3到5类,本文中认为划分为4类较为合理。分析结果见表3。
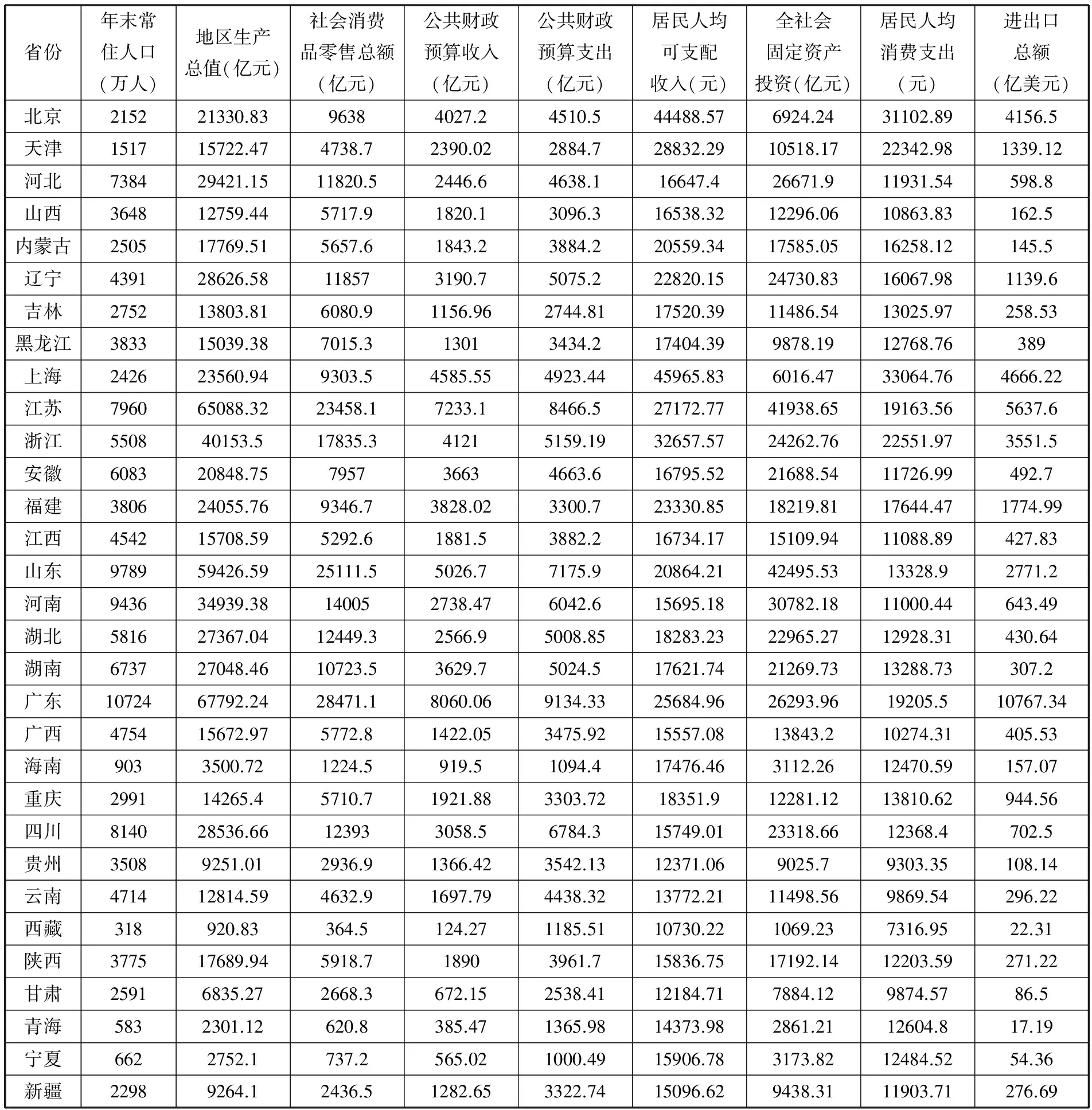
表1 全国31个省市各指标数据
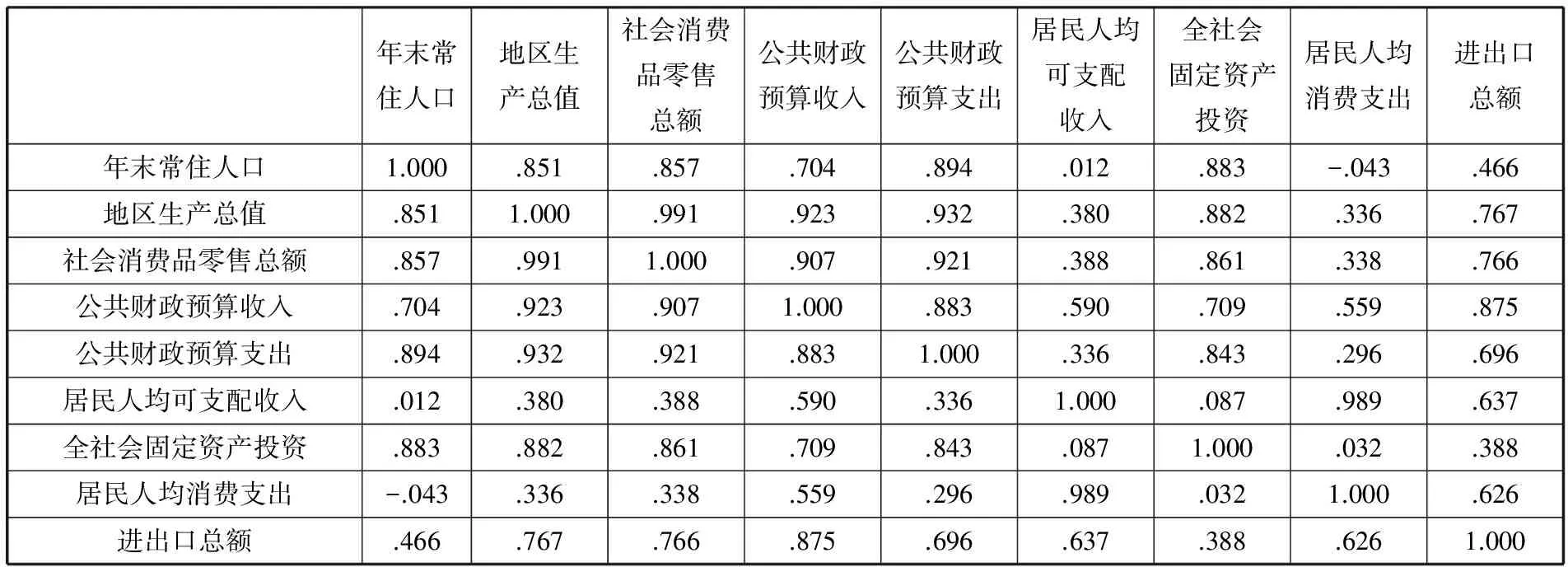
表2 各指标相似性矩阵

表3 聚类分析结果
四、评价分析
在组内聚类法中,由于第四类中包含浙江省同时还包含了新疆、西藏、内蒙古等省,它们明显不能归为一类,则用组内聚类法不合理。在最短距离法中,最短距离法有链接聚合的趋势,大部分样品都被聚集在一类中,导致这样的聚类效果并不好,并且第四类中,天津、浙江等省明显不该和新疆、西藏等省归为一类,则用最短距离法不合理。最长距离法和ward法得到了相同的分类结果,但第三类中,内蒙古和浙江、天津市明显不该归为一类,则用这两种方法并不合理。重心法和组间聚类法得到了相同的分类结果,但第四类中天津和内蒙古、宁夏等省市明显不能归为一类,则用这两种方法并不合理。在K-均值法中,第一类为经济发达省市,人均消费支出均处于全国领先水平,第二类省份外贸经济发达,人均消费水平较高,第三类多为平原地区,经济基础薄弱,但劳动力资源丰富。第四类地区多为偏远省市,经济基础水平受到地理条件限制,社会经济资源匮乏,尤其是人力资源缺乏,这构成了其经济发展的瓶颈。以此看来采用K-均值法将全国31个省市分成相应4类较为合理。
第一类北京、天津、上海、浙江人均消费支出均在22000元以上,是全国贸易中心城市,北京作为首都,政治、经济实力雄厚,上海对外贸易发达,交通便利,跨国公司和国际商贸组织大多坐落在此,天津和浙江作为沿海城市,地理位置优越,人口密度大,劳动力受教育水平高。
第二类江苏和广东,在改革开放之后,江苏和广东发展迅速,随着对外开放步伐的加快,2014年江苏和广东的进出口总额已分别达5637.6和10767.34亿美元,在全国31个省市中遥遥领先。但是对比第一类省市,广东发展起步晚,经济实力没有第一类城市雄厚。
第三类河北、辽宁、安徽、山东、河南、湖北、湖南、四川,劳动力资源丰富,但劳动力整体教育水平不高,教育投资较少,并且劳动力大多流向第一、第二类省市。经济增长主要依靠内需拉动,由于地理位置的原因,外贸水平偏低,多以第一产业、第二产业为主。这类省市若想提高经济发展水平,需要得到国家政策的支持,发挥人力资源优势,加大教育投资力度,努力发展服务业,加快经济转型。
第四类山西、内蒙古、吉林、黑龙江、福建、江西、广西、海南、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆,这些省市地理位置偏远,物资匮乏,经济发展在一定程度上还依赖于第一产业,但另一方面,这些省市自然资源丰富,应大力发展旅游业,发挥本省优势,国家也应对这些省份给予政策扶持。
总的看来,不论是系统聚类还是K-均值法我们都可以看出北京、上海这两个特大型城市均居于全国领先水平,它们分别是我国政治、经济中心,是中国规模最大、综合实力最强的两个城市,属于经济发达地区,分别已经完成工业化而进入后工业化时期。沿海省市经济较为发达,在经济全球化的今天,外贸出口在很大程度上影响着一个省市的经济发展水平,这些省份充分利用发达国家和地区调整产业结构、转移劳动密集型产业的机遇,积极吸引外资,大力发展外向型经济。而中部地区和老工业地区省份经济发展则较为落后,它们主要依靠内需拉动经济增长,对外贸依存度不高,并且由于受经济基础、自然条件等方面的制约,老工业基地以资源消耗、环境污染为代价的粗放型经济增长模式已严重威胁其可持续发展。这些地区与率先改革开放的东部沿海地区相比,经济发展有相当的差距。大部分内陆偏远省份,由于地区开放程度较低,吸收外部资金及技术、人才等促进经济发展因素能力较弱,导致近年来经济增长缓慢。
[1]王玻,李从东.地区经济规模评价的多元统计分析及其适用性比较[J].经济与管理,2009(2).
[2]梁国巍,王传美.多元统计方法在分析各地区综合经济水平中的应用[J]. 中南民族大学学报(自然科学版),2003(9)68-70.
[3]祝新亚,李许坚.基于聚类分析和判别分析的我国主要省市综合实力状况评价[J].北方经济,2011(4)16-18.
[4]金相郁.中国区域划分的层次聚类分析[J].城市规划汇刊,2004(2)23-28.
[5]陈爱娟,程雪.我国各省市国际劳务竞争力聚类分析[R]. Proceedings of 2010 International Conference on Management Science and Engineering (MSE 2010) (Volume 4):161-164.
[6]何晓群.多元统计分析[M].北京:中国人民大学出版社,2012.
责任编辑周觅
F061.3
A
1003-8078(2016)05-0019-05
2016-04-07doi:10.3969/j.issn.1003-8078.2016.05.06
肖瑶(1991-),女,安徽安庆人,安徽大学经济学院2014级硕士研究生。
猜你喜欢
当代水产(2019年11期)2019-12-23 09:03:46
电子测试(2017年15期)2017-12-18 07:19:27
领导决策信息(2017年35期)2017-10-20 09:12:26
领导决策信息(2017年34期)2017-10-20 05:07:05
中国公路(2017年6期)2017-07-25 09:13:56
领导决策信息(2016年27期)2016-10-23 10:05:58
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
中国土地科学(2014年4期)2014-03-01 03:25:34
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
