
基于垂直数据格式频繁闭项集的选择性集成算法的研究
2016-11-09 07:31吴陈杨镕华
电子设计工程 2016年19期
吴陈,杨镕华
(江苏科技大学 江苏 镇江212000)
基于垂直数据格式频繁闭项集的选择性集成算法的研究
吴陈,杨镕华
(江苏科技大学 江苏 镇江212000)
集成学习是现今机器学习领域研究的热点问题,选择性集成通过对基分类器进行选择来提高集成分类器的泛化能力,降低预测开销。模式挖掘是一种将问题转化为事务数据库中模式的全新挖掘策略。本文将垂直数据格式频繁闭项集的模式挖掘方法应用于分类器的选择过程,利用垂直数据结构、频繁闭项集及模式挖掘方法的优势,提出一种预测性能更好、更加高效的选择性集成分类算法。
选择性集成;垂直数据格式;频繁闭项集;模式挖掘;分类器
分类器集成是将若干个学习得到的基分类器以某种方式组合来解决同一个学习任务,国际机器学习界的权威学者Dietterich曾在《AIMagazine》杂志上将集成学习列为机器学习领域的四大研究方向之首,人们发现通过将基学习机集成得到的集成学习机的预测效果显著优于单个学习机[1]。随着大批量的学者进行集成学习的研究,人们发现没有选择的集成存在一些缺陷,与单个学习机相比,随着基学习机数量的增加,具有负影响的基分类器存在的可能性增大,冗余基分类器增多,导致它们所需的存储空间增大,预测速度明显下降。为了解决这个问题,2002年,周志华等人首先提出了“选择性集成”的概念,理论分析和实验研究表明,基于某种衡量标准,通过将效果不好的基学习机剔除能够得到预测精度高、速度快、存储消耗少的集成学习机[2]。
1 研究现状
最早是通过枚举法得到最优的基分类器集,但是随着基分类器的数量增加,计算量极大,所以枚举法不可行,通过近十年的研究,根据算法采用的选择策略不同将选择性集成方法分为迭代优化法、排名法、分簇法以及模式挖掘法[3]。赵强利将常用算法GASEN、FS、OO(迭代优化法)、MDSQ(排序法)、CPF(分簇法)和PMEP(模式挖掘法)从预测性能、选择时间、集成分类器大小三方面进行比较,通过采用十字交叉验证法进行实验得出结论PMEP和MDSQ算法精度最佳、分类器选择时间较少,但是对于实时性要求较高的领域,优先考虑PMEP[4]。由此可见,模式挖掘法作为一种全新的分类器选择策略,具有明显的性能优势,需要我们进行更加深入的研究。
2 基于模式挖掘的选择性集成算法
模式挖掘是一种将问题转化为事务数据库中模式的全新挖掘策略。常用的模式挖掘方法有:Apriori算法、FP-growth算法、Max-Miner算法等,在如此多的算法中,基于内存的算法已经成为主流,为了在内存中完成频繁模式的挖掘就必须在算法中选择一种可以将数据集压缩在内存中的数据结构,目前FP-Tree已经成为最常见的选择。赵强利提出了一种将模式挖掘应用于选择性集成的方法,一种基于FP-Tree的快速选择性集成算法(CPM-EP)算法[5],与现有的选择性集成策略相比较,该算法在泛化能力、计算开销方面具有显著的优势。尽管如此,该方法仍存在一定的不足:在基分类器的选取过程中并没有充分考虑到单个分类器的分类能力以及各成员分类器之间的差异性,造成最终的集成分类器因混入了性能不好的、冗余的分类器导致准确性下降、计算开销增大;当数据很多、数据库很大时,构造基于主存的FP树有时是不现实的;当最小支持度较低或数据集中存在长模式时,频繁模式挖掘可能产生大量的频繁项集,如为了得到一个长度为100的频繁项集,首先必须导出(2^100-1)个频繁项集,并且很多频繁模式是没有区别力的。
基于以上优缺点,文中对基于FP-Tree的快速选择性集成算法进行改进,研究了一种将垂直数据格式频繁闭项集的模式挖掘方法[6]应用于选择性集成的集成策略(ICPM-EP),以提高分类器的泛化能力、降低计算开销。
2.1算法思想
算法的主要思想是:将对分类器的选择问题转换为对频繁模式的挖掘问题[7],在挖掘的过程中,首先将事务数据库用垂直数据格式表示,根据各分类器的准确性与差异性对分类器进行筛选剔除,然后将闭频繁模式压缩到一棵FP树,加快统计、检索速度,并减少占用的内存空间,最后利用贪婪算法获得相应的集成分类器。
在该算法中,将所有基分类器对校验样本集的分类结果保存在一个预测结果表中,表中的每一行保存着一个分类器的标识号和该基分类器分类正确的样本标识号。将事务数据库用垂直格式表示,能够直观地观察出各分类器的准确性及差异性,根据判断准则,对预测结果表进行精简,去掉准确性差、差异性小等冗余的分类器;根据闭项集的概念能够有效的去除冗余频繁模式,避免了由于数据库大、数据为长模式而导致FP树无法实现的问题。
2.2ICPM-EP算法模型
该模型主要包括:用垂直数据格式表示事务表、对分类器进行筛选、获取闭频繁项集的FP树、通过贪婪算法获取集成分类器几个步骤。ICPM-EP算法模型如图1所示。
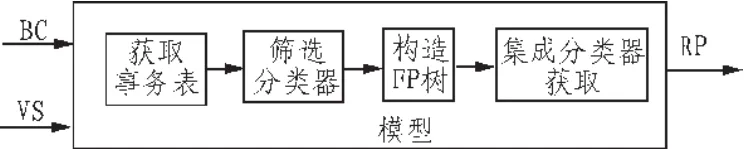
图1 ICPM-EP算法模型
算法实现描述如下:
伪代码:


2.3算法实现过程
在该算法中,首先初始化结果集;然后将各分类器对校验样本集分类正确的标识号保存在分类结果表中,并根据分类器的准确性及各分类器的差异性对基分类器进行筛选,去除准确性差、差异性小的冗余分类器;对所有可能的分类器结果k[1,L],根据闭频繁项集的概念获得去除冗余后的FP树;然后基于获得的FP-tree获取k对应的集成分类器的结果;最后从所有结果中选取对校验样本集VS预测精度最高的作为最终的输出结果。
下面将从获取垂直数据格式事务表,精简事务表,FP-tree的构建以及分类器的选择4个步骤进行详细介绍。
2.3.1获取垂直数据格式事务表
L个分类器对校验样本集VS中的样本依次进行分类,并将分类正确的样本标识号及频繁项目的支持计数保存在预测结果表中。表中的每一行包含3个属性,分别是分类器标号、该分类器对应的事务列表以及分类正确的样本个数,分别用Cid、VSset、num表示。据此,即得到垂直数据格式预测结果表。
假设L=10,对应的分类器标号分别为C1,C2,…,C10,校验样本集VS中共有12个样本,标号分别为S1,S2,…,S12,可得垂直数据格式预测结果表如表1所示。
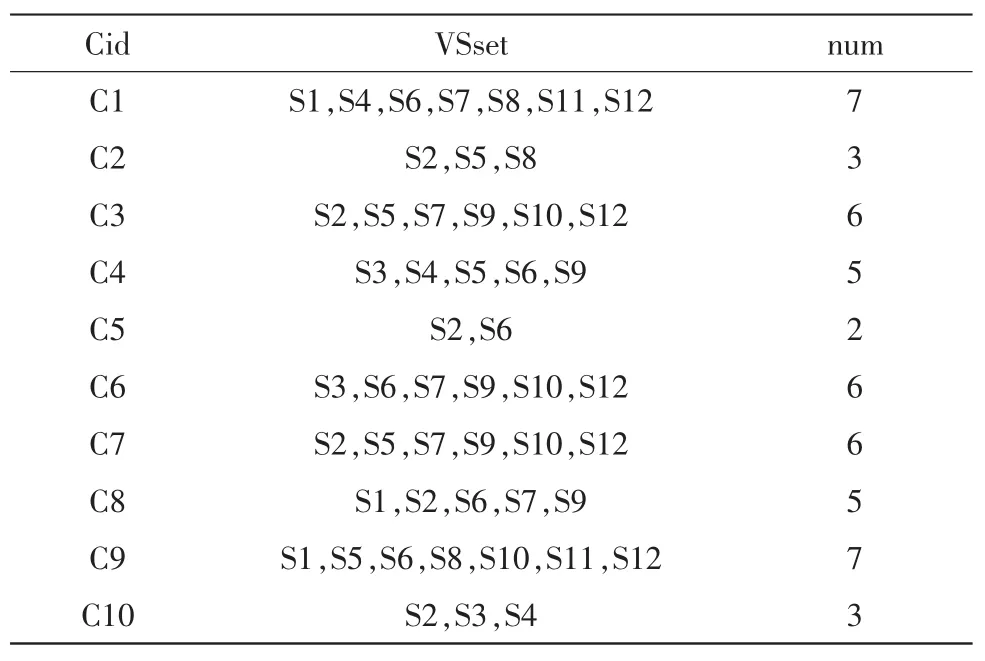
表1 垂直数据格式预测结果表
2.3.2精简事务表
通过对各分类器进行选取来达到对垂直数据格式事务表进行精简的目的。实现方法主要分为两步:一、根据各分类器准确性对分类器进行排序;二、根据分类器的准确性与差异性采用合适的停止准则对分类器进行简单筛选,首先,如果一个分类器分类正确的样本集对于另一个分类器均能分类正确,则将这个分类器去除,去除分类器C5;其次,去除分类器准确性较差的分类器,去除掉准确性小于最大分类器一半的分类器,如去除C2、C10;最后,根据差异性准则选择出差异性小的分类器删除,如果总的分类器数目少于2 k个,则添加新的基分类器重复此步骤,直到简化后的基分类器的个数大于2 k为止。差异性准则判断如下:
将两个分类器Ci、Cj(i!=j)之间的差异性Div(i,j)定义为两个分类器均分类正确所占的比例。如果两分类器的差异性大于平均差异性,则保留两分类器,若小于平均差异性,则删除。
2.3.3构建FP树
根据精简的垂直数据构建FP树,首先用垂直数据投影事务,由于各分类器的事物列表递增排列,所以只需要扫描各项目事务的表头事务就可以构建最小事务,避免了从头到尾扫描事务列表。依据垂直数据投影事务的过程如表2所示。
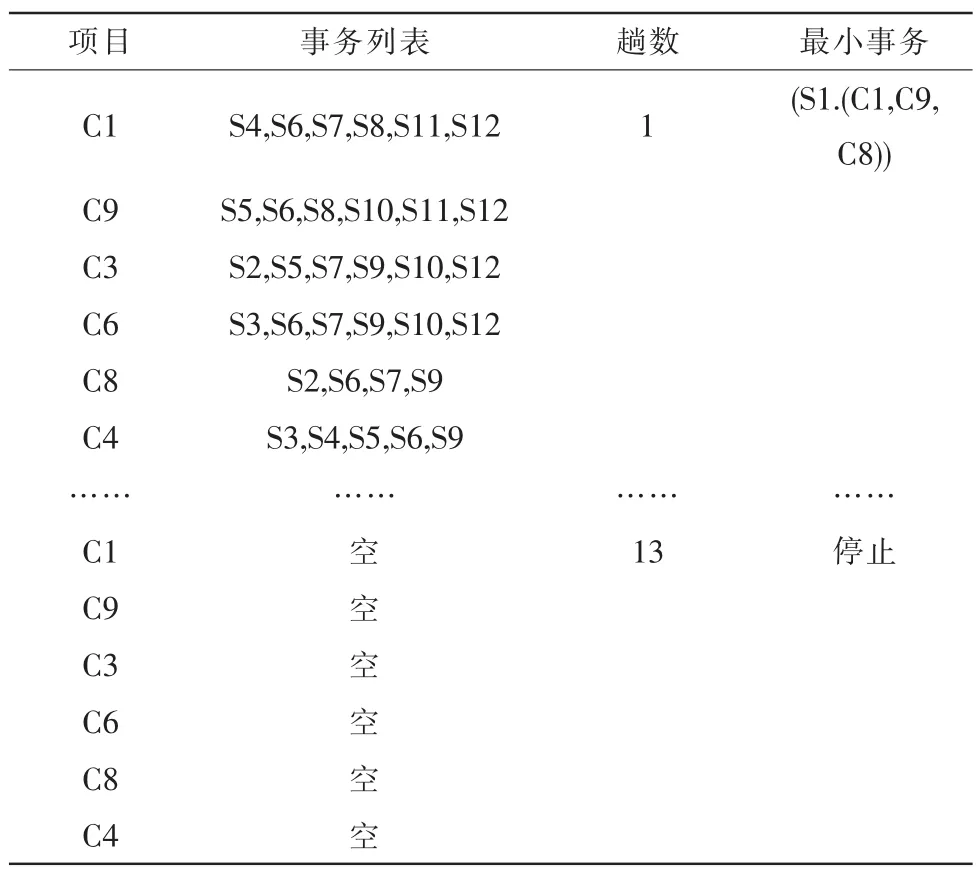
表2 垂直数据投影事务的过程表
然后将满足支持度的投影事务插入到FP树中,直到所有满足支持度的最小事务被插入到FP树为止,在插入过程中保证所有的频繁项集都是闭项集。FP树的存储结构不同于水平数据格式的结构,其存储结构分为FP树本身和垂直频繁项目头。FP树本身与水平数据的FP树存储结构中的FP树本身相同,不同的是频繁项目头表,垂直频繁项目头表是由分类器名称(C_name)、支持计数(S_count)、项目对应事务的头指针(H_link)、项目对应事务的尾指针(T_link)以及FP树项目链头(N_link)5个域组成。FP树创建的过程中,垂直项目头表的变化如下图所示。其中FP树创建前,扫描数据库一次后垂直项目头表如图2所示。第一个事务插入FP树后垂直项目头表如图3所示。

图2 扫描数据库一次后垂直项目头表图
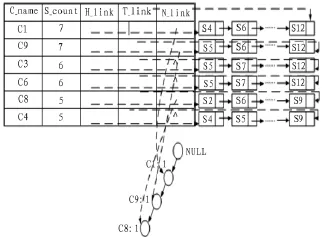
图3 第一个事务插入FP树后垂直项目头表图
2.3.4选择基分类器
根据构造的FP树进行基分类器的选择采用贪婪方法。主要分为以下几步:
步骤一:初始化结果集,PR.set=null;PR.correct=0,其中PR.set为入选的基分类器的集合,PR.correct为对应基分类器集合对事务分类正确的数目。
步骤二:创建Path-table表,FP树按照从左到右的顺序将从根节点到叶子节点出现的分类器及该路径的count值记录在表中。该表的每一行代表FP树的一条路径。原始Pathtable表如表3所示。
表3 原始Path-table表
步骤三:选择分类器:从Path-table表中选择出count最大的的路径对应的分类器,记为classifier[i],其中i表示行数。
当count[i]+|PR.set|>K(K为选择的分类器的个数)时,说明选择K个分类器无法满足多数投票法的规则,则将该行从表中删除重复该步骤,直到count[i]+|PR.set|<=K,此时PR. set=PR.set+classifier[i],PR.correct=PR.correct+count[i]。最后将入选的分类器从该表中删除得到更新的Path-table表。第一次更新后的Path-table表如表4所示。

表4 第一次更新后的Path-table表
步骤四:重复步骤三直到count[i]+|PR.set|=K或Path-table表为空,返回最终结果PR。
实验比较:
为了验证算法的有效性,本课题将对SelectBest,基于水平格式模式挖掘的选择性集成算法(CPM-EP)以及基于垂直数据格式的频繁闭项集选择性集成学习算法(ICPM-EP2)进行比较。
实验所采用的数据集为 KEEL-dataset中的 Text Classification data sets。
实验中,利用weka平台,采用java语言进行编程实现,采用5次交叉验证的方法,训练生成5个BP神经网络、5个C4.5决策树、5个朴素贝叶斯,5个SVM,在多数据集上比较多种实验结果,结果用均值表示。为避免单个数据集对结果的影响较大,将对精确度数值的比较转换为对排名的比较,通过排序比较各分类算法的优缺点,各分类器比较结果如表5所示。
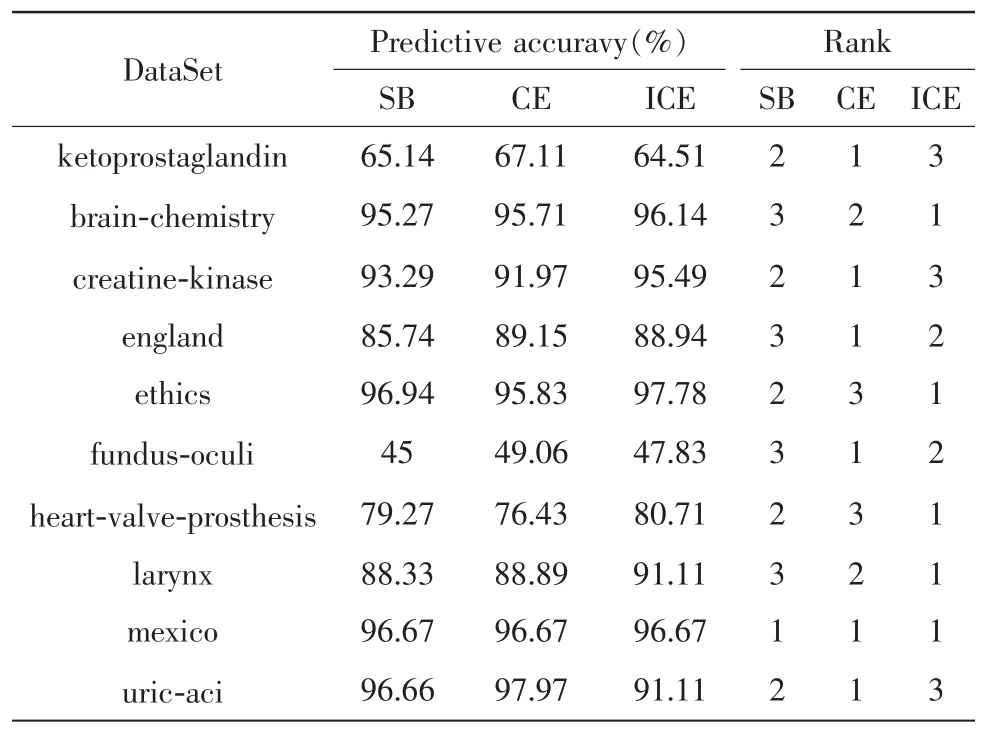
表5 分类器比较结果
3 实验结果
从实验的排名中可以看出,CE、ICE的正确率明显高于SB,ICE的正确率并没有低于CE,但由于ICE修减了搜索空间,理论上显著提高了速度。
4 结 论
文中基于垂直数据格式、频繁闭项集的特点,提出了一种将垂直数据格式和频繁闭项集的模式挖掘应用于选择性集成方法。利用垂直数据格式的特点,在模式挖掘前对分类器进行筛选,将准确率更高、差异性更大的分类器应用于选择的过程,利用频繁闭项集的特点,选择出有区别能力的模式,使得在确保准确率的前提下提高了速度,并且避免了由于数据库过大导致FP树无法实现的问题。
[1]侯勇,郑雪峰.集成学习算法的研究与应用[J].计算机工程与应用,2012(34):17-22.
[2]张春霞,张讲社.选择性集成学习算法综述[J].计算机学报,2011(8):1399-1410.
[3]张翔,周明全,耿国华.Baggin中文文本分类器的改进方法研究[J].小型微型计算机系统,2010(2):281-284.
[4]赵强利,蒋艳凰,除明.选择性集成算法分类与比较[J].计算机工程与科学,2012(2):134-138.
[5]赵强利,蒋艳凰,徐明.基于FP-Tree的快速选择性集成算法[J].软件学报,2011(4):709-721.
[6]李洪波,周莉,张吉赞.用垂直数据格式构建FP增长树的算法[J].计算机工程与应用,2009(8):161-164.
[7]赵强利.基于选择性集成的在线机器学习关键技术研究[D].北京:国防科学技术大学,2010.
Research of selective ensemble besed on vertical data and closed pattern
WU Chen,YANG Rong-hua
(Jiangsu University of Science and Technology,Zhenjiang 212000,China)
Ensemble learning is an active research in the machine learning field.Ensemble pruning can improve the generalization ability and reduce the cost forecastby selecting the base classifier.Patternmining isa newminingmethod which can transform the problem into pattern in the database transaction.In this paperwe take fulladvantage of patternmining used vertical data structure and closed pattern to propose a forecasting better performance,more efficient selective ensemble classification algorithm.
ensemble pruning;vertical data structure;closed pattern;patternmining;classifier
TN302
A
1674-6236(2016)19-0069-04
2015-10-12稿件编号:201510066
吴陈(1962—),男,湖北天门人,博士,教授。研究方向:人工智能与模式识别,粗糙集理论及应用,数据挖掘与知识发现。
猜你喜欢
河南水利年鉴(2020年0期)2020-06-09
计算机与数字工程(2018年10期)2018-10-23
天津科技大学学报(2018年4期)2018-08-22
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
电脑知识与技术(2017年6期)2017-04-26
科技与创新(2016年17期)2016-11-04
中南民族大学学报(自然科学版)(2014年1期)2014-08-06
江西理工大学学报(2013年1期)2013-03-20
中南民族大学学报(自然科学版)(2011年2期)2011-02-07
浙江师范大学学报(自然科学版)(2010年2期)2010-01-11
