
一种有效的W eb服务聚类方法
2016-11-09 07:31马传宾翟社平马蒙雨
电子设计工程 2016年19期
马传宾,翟社平,马蒙雨,郭 琳
(西安邮电大学 计算机学院,陕西 西安710121)
一种有效的W eb服务聚类方法
马传宾,翟社平,马蒙雨,郭 琳
(西安邮电大学 计算机学院,陕西 西安710121)
将功能相似的Web服务聚类是一种有效的服务发现方法,而聚类的关键在于服务之间语义相似度的计算。目前国内外主流使用
、信息检索和基于本体的方法计算相似度,这些方法存在语义信息缺失等问题,并且聚类方法只考虑到简单数据类型的处理。本文提出一种同时包含处理简单数据类型和复杂数据类型的本体学习方法,利用本体学习和信息检索相结合的方式(Hybrid term similarity,HTS)进行Web服务聚类。实验结果表明,该方法能够有效地提高Web服务的聚类效果。
语义Web;Web服务;本体学习;Web服务发现
随着Internet中Web服务数量的增加,服务的自动发现面临着很大的挑战。Web服务聚类能够根据输入、输出、前提和效果即IOPEs(inputs,outputs,pre-conditions and effects),将功能相似的服务进行聚类,从而能够有效地进行服务发现。采用相似度计算方法来计算服务特征的相似度SoFs(Similarity of features),服务特征相似度的总和,即为服务相似度。目前聚类算法使用了一些相似度计算方法,例如基于关键字的方法、信息检索和基于本体的方法等,然而由于服务资源的异质性和独立性,基于关键字的方法并不能准确地计算出术语的语义相似度,另外,信息检索方法主要针对纯文本格式内容,但Web服务通常包含了较多复杂的结构,基于本体的方法,虽然本体有助于提取语义相似度,但如何定义多个高质量的本体依然存在问题。
为了解决这些问题,本文将简单数据类型和复杂数据类型相结合,通过分析二者的语义模式丰富本体学习的内容,从而有效地进行Web服务聚类。
1 相关研究工作
Rajendran等[1]提出一种采用动态代理框架来自动进行Web服务发现方法。Wen等[2]提出一种采用WordNet和本体来计算服务相似度的方法。Schmidt等[3]提出一种采用P2P方式进行 Web服务发现的方法。杨楠等[4]提出一种由 SCML(Service Composition Management Language)出发自动转化BPEL(Business Process Execution Language)并在引擎中自动部署、发布、执行的方法,并证明该方法对流程自动发布具有一定的可用性。刘建晓等[5]设计了一种基于关系数据库中自身连接的快速准确实施Web服务聚类的方法.该方法可以提高计算服务间相似度的效率。翟社平等[6]提出了一种基于概念理解的规划方法,解决了语用Web服务中私有本体概念之间的协商和理解问题。陈彦萍[7]提出一种基于调节熵和社会认知算法的Web服务组合算法,用于解决Web服务组合最优问题。徐小良等[8]利用领域本体将Web服务形式化为领域概念的集合,提出一种基于图论聚类的服务发现方法,提高了服务发现效率。朱志良等[9]提出一种特殊的考虑到编程风格和命名规范的预处理方法,然后结合SCAN算法,能够有效的提高Web服务的聚类效果。
在WSDL中,服务特征的描述通常包含复合术语,目前大多数方法中只对其进行简单分词并直接进行句子分析,导致术语只做了简单的分析处理,影响了服务相似度计算的准确性。复合术语包含的本体关系应该充分被利用,但是所提及的大多数方法并没有在Web服务聚类时考虑到复杂数据类型。文中提出了一种考虑复合术语和复杂数据类型的方式进行语义相似度计算的方法。
2 方法描述
文中使用WSDL文档进行Web服务聚类。首先,抽取描述服务功能的特征;其次,通过本体学习构建本体;然后,采用基于术语相似度的本体学习和信息检索的方法计算特征相似度。通过特征整合,计算服务相似度值并通过凝聚层次聚类算法进行Web服务聚类。聚类方法的体系结构,如图1所示。
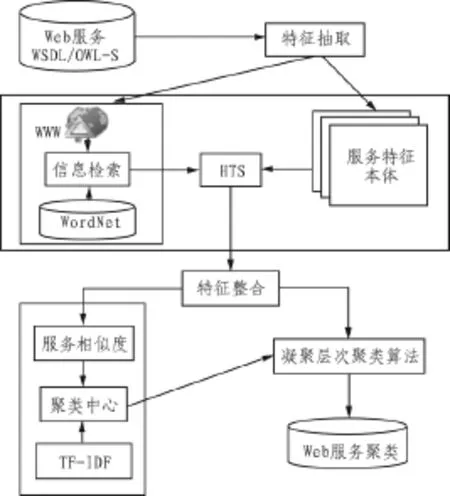
图1 聚类方法架构图
2.1特征提取
由于Web服务中通常有多个复杂数据类型,因此采用式(1)计算复杂数据类型的平均相似度。

其中,sx和ry表示服务Si和服务Sj的复杂数据类型,m表示服务Si中sx的个数,n表示服务Sj中ry个数。
2.2相似度计算
2.2.1本体学习
本体学习目的是精确地识别服务文档中的语义。本文通过在服务特征中挖掘复合术语隐含的语义来自动构建本体。首先,若该特征为复合术语,则将它切分成简单术语,如切分AuthorOfNovel成为3个元素(Author,of,Novel);然后过滤并移除停用词,得到(Author,Novel);计算其TF-IDF,TF-IDF值代表了本体概念的重要程度,对其升序排列后,获取大于预先设定阈值T的术语,通过模式分析方法找出术语的隐含关系。
本体是共享概念模型的明确规范化说明。本体关系描述了概念之间以及概念属性之间的相互作用。本文仅考虑两种类型关系,即概念层次(上下位关系)和3元组关系(主体-谓词-客体)。C为概念{C1,C2,…Cn}的集合,其中Ci代表SiF(服务Si中的特征F)。LSC(Ci)表示概念Ci的下位概念Cx的集合;LGC(Cx)表示Cx的上位概念Ci的集合,PROP(Ci)表示概念Ci的属性集合。
定义1(上下位关系):若∃Ci∈LSC(Cj)∩LGC(Ci),则概念Ci和Cj存在上下位关系。其中概念Ci可以是简单术语(如Employee)也可以是复合术语(OrganizationEmployee)。如果一个概念是复合术语,则右半部分术语是概念(Employee)的首部,左半部分术语是概念(Organization)的修饰术语。
规则1:(首部-修饰关系规则):首部和修饰表示词项的上下位关系[10]。
属性包括数据属性和对象属性,其中数据属性指概念中的数据,对象属性指概念间的关系。
定义2(属性关系):若∃Cj∈PROP(Ci),则Cj和Ci存在属性关系。该属性关系可以是对象属性或者数据属性。
定义2.1(数据属性关系):若∃Pi∈PROP(Cj),则Pi和概念Cj存在数据属性关系。其中Pi是概念Cj中的数据。
规则2:(复合名词规则):若复合术语t中简单术语均是名词,则概念Mt和数据t存在数据属性关系。
定义2.2(对象属性关系):若∃(Ci∈PROP(Cj))∩(Cj∈PROP(Ci)),则概念Ci与概念 Cj存在对象属性关系。
规则3(概念与修饰规则):若概念Ci与概念Cj的修饰术语相同,则概念Ci与Cj存在对象属性关系。
规则4(修饰规则):若概念Ci的修饰部分与概念Cj的修饰部分相同,且不存在与该修饰术语相同的概念,则Ci与Cj存在对象属性关系。
规则5(复杂数据类型-简单数据类型规则):本体概念Ci表示在WSDL文档d中的复杂数据类型,Cj与Ci为不同的概念,Cj表示在d中简单类型或者其他复杂数据类型,若复杂数据类型Ci包含名称为p,且数据类型为Cj的概念,则Ci和Cj存在对象属性关系(Ci-p-Cj)。
根据规则1构建上下位关系,根据规则2产生数据属性关系,根据规则3和规则4产生对象属性关系。若服务的特征为复杂数据类型,则规则5产生更多的对象属性,从而丰富本体。
2.2.2基于术语相似度的信息抽取
通过信息抽取方法计算相似度,采用式(2)计算简单术语的相似度,然后采用式(1)计算平均相似度。
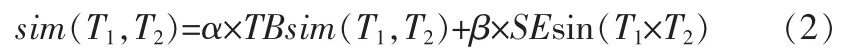
其中,其中TBsim(T1,T2)表示基于词库的术语相似度值,SE sin(T1,T2)是SEB相似度值,α和β的取值范围为[0,1],且α+β=1。
其中,WebPMI作为SEB的计算方法。
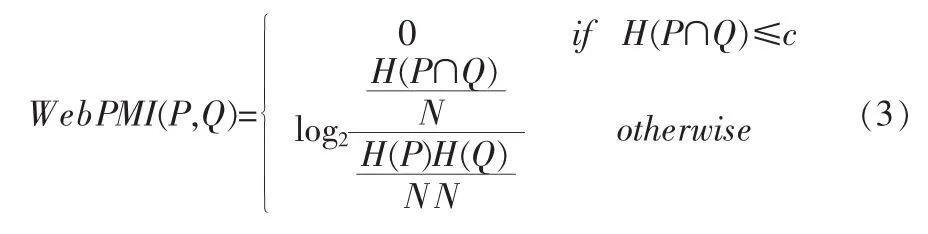
其中,H(P)和H(Q)各自代表查询P和Q的页数。H(P∩Q)代表P和Q联合查询。若H(P∩Q)低于阈值c,则该项系数为0,因为两个术语可能出现在同一页。N表示搜索引擎索引的文档数。
2.2.3相似度计算
文中采用过滤器计算服务相似度。
精确匹配:若Ci≡Cj,则SiF完全匹配SjF;
属性-概念匹配:若Ci∈PROP(Cj),则 SiF和SjF属性-概念匹配;
属性-属性匹配:若 Ci∈PROP(Ck)∩Cj∈PROP(Ck),则SiF和SjF属性-属性匹配;
嵌入匹配:若Ci∈LSE(Cj),则SiF和 SjF嵌入匹配;
兄弟匹配:若 Ci∈LSC(Ck)∩Cj∈LES(Ck),则 SiF和 SjF兄弟匹配;
包含匹配:若Cj>Ci,则SiF和SjF包含匹配。
逻辑失败匹配和失败匹配:若Ci和Cj在相同的本体中,但不能匹配以上6种模式,则SiF与SjF逻辑失败匹配。若Ci和Cj在异构的本体中,则SiF与SjF失败匹配。
根据基于逻辑匹配的程度应用过滤器,精确匹配>属性-概念匹配>属性-属性匹配>嵌入匹配>兄弟匹配>包含匹配>逻辑失败匹配>失败匹配。
若两个概念是精确匹配,则相似值为最大值1,。若是其他匹配(不包含失败匹配),则采用式(4)计算相似度。
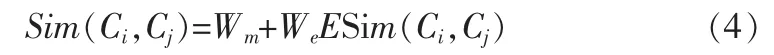
其中Wm和We的取值范围为[0,1],具体由匹配的过滤器决定;ESim(Ci,Cj)表示边缘相似度,采用式(5)计算。
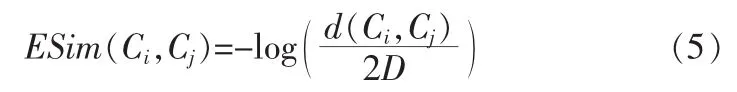
其中d(Ci,Cj)表示概念Ci和Cj最短的距离,D表示本体最大深度。
如果两个概念位于异构的本体中(即两种服务为失败匹配),则采用信息检索术语相似度的方法来计算特征相似度。
2.3特征整合与聚类
式(6)为通过整合特征计算服务Si和Sj最终的相似度值SSc(Si,Sj),用于进行Web服务聚类。

其中WN,WON,WCT,WOP和WI取值范围均为[0,1]。
文中采用自下而上的凝聚层次聚类算法[11-12],算法流程为:
1)设定目标簇类数n;
2)每一个服务样本作为一个簇类;
3)计算邻接矩阵;
4)repeat
5)找到分属两个不同类簇,且距离最近的服务样本对,将其合并;
6)CN=当前簇类数目;
7)计算各个簇类中所有服务的中心值;
8)选择各个簇类中最大值的服务作为簇类中心;
9)until CN=n。
3 实验结果与分析
实验的系统环境配置如表1所示。测试数据是从Web服务库中抽取的Educational、Film、Vehicle、Medical和Food 5个领域相关的WSDL文档。

表1 系统环境配置
3.1本体样本
图2为经过本体学习之后得到的本体片段,展示了由复杂数据类型得到的对象属性关系。如概念 University和educational_employee存在对象属性关系(University-hasvice-chancellor-educational_employee)。
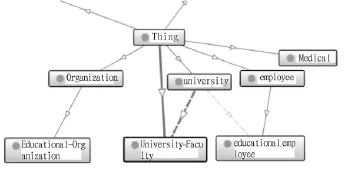
图2 本体样本
图3为图2中本体相关的部分OWL文件。

图3 图2本体相关owl文件
3.2结果分析
为了评估聚类的效果,本实验从5个领域中获取了350个WSDL文档,对比了包含复杂数据类型的本体和信息检索方法HTS(C)与未包含复杂数据类型的HTS方法,根据文献[13-15]采用准确率(P)、召回率(R)和F-Measure作为评测指标。


其中,NMij表示在簇j中类i的元素个数。NMj表示簇j中元素的个数,NMi表示类i中元素个数。
F-measure是对上述两种指标的平均。
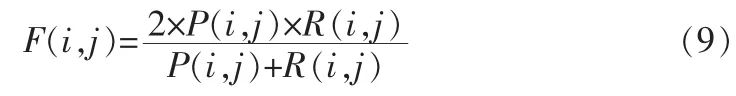
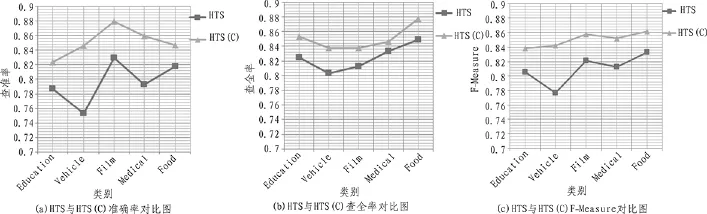
图4 HTS与HTS(C)对比图
从图4(a)、图4(b)、图4(c)可以看出,在考虑复杂数据类型之后采用HTS方法,即HTS(C),比未考虑复杂数据类型的HTS方法有更高的准确率、召回率、F-measure,意味着属于这些组的Web服务更多地、更准确地放到对应的簇中。
4 结束语
文中在Web服务中考虑了复杂数据类型,介绍了若干个能够应用于本体学习的规则,获得了更多的数据属性和对象属性,丰富扩展了本体,最终提高Web服务聚类的性能。下一步工作是考虑通过引入本体映射提高相似度的计算,以及通过服务聚类提高服务发现的性能。
[1]Rajendran T,Balasubramanie P.An optimal agent-based architecture for dynamic Web service discovery with QoS[C]//International Conference on Computing Communication& Network Technologies,2010:1-7.
[2]Wen T,Sheng G,Li Y,et al.“Research on Web service discoverywith semanticsand clustering,”in proc[C].6th IEEE Joint International Information Technology andArtificial IntelligenceConference,China,August,2011:62-67.
[3]Schmidt C,Parashar M.A Peer-to-Peer approach to web servicediscoveryworldwideweb-internet&Web information systems[J].2004,7(2):211-229.
[4]杨楠,马力,陈彦萍.ActiveBPEL中组合服务自动部署的研究和实现[J].西安邮电学院学报,2010(5):107-110.
[5]刘建晓,王健,张秀伟等.一种基于RDB中自身连接的Web服务聚类方法[J].计算机研究与发展,2013,50:205-210.
[6]翟社平,魏娟丽,李增智.一种服务本体规划理解的语用Web服务发现算法[J].解放军理工大学学报,2008,9(5):440-444.
[7]陈彦萍,田改玲,张建科.基于调节熵函数的Web服务组合算法[J].西安邮电大学学报,2013,4:64-70.
[8]徐小良,陈金奎,吴优.基于聚类优化的Web服务发现方法[J].计算机工程,2011(9):68-70.
[9]朱志良,苑海涛,宋杰,等.Web服务聚类方法的研究和改进[J].小型微型计算机系统,2012,33(1):96-101.
[10]王盛,樊兴华,陈现麟.利用上下位关系的中文短文本分类[J].计算机应用,2010(3):603-606,611.
[11]郭景峰,赵玉艳,边伟峰,等.基于改进的凝聚性和分离性的层次聚类算法[J].计算机研究与发展,2008,S1:202-206.
[12]Christopher D,Manning,Prabhakar Raghavan,Hinrich Schutze,Introduction to Information Retrieval[M].Cambridge University Press,2008.
[13]夏红科,郑雪峰,胡祥.多策略概念相似度计算方法LMS[J].计算机工程与应用,2010,46(20):32-39.
[14]杨文忠.基于近似网页聚类算法的Web文本数据挖掘技术的研究与应用[D].长沙:湖南大学,2005.
[15]严桂夺.基于主题聚类的网页目录结构构建方法研究[D].广州:华南理工大学,2010.
An effective clustering approach for W eb services
MA Chuan-bin,ZHAIShe-ping,MA Meng-yu,GUO Lin
(School of Computer Science and Technology,Xi'an University of Posts and Telecommunications,Xi'an 710121,China)
EstablishingWeb services into function similarity cluster is an efficientmethod of service discovery.The key of the clustering is the calculation of the semantic similarity between Web services.Mainstream use keywords,information retrieval or ontology-basedmethod to compute the similarity in home and abroad.Furthermore,Thesemethods exist such problems as lack of semantic information.Further,current clusteringmethods only take into account the processing of simple data type. The approach is proposed to calculate the service similarity not only contains simple data types but contains complex data types.Thus,use ontology learning and information retrievalmethod toWeb service clustering.This approach used in project willsignificantly improveWeb services discovery.
semantic Web;Web service;ontology learning;Web service discovery
TP391
A
1674-6236(2016)19-0011-04
2016-01-29稿件编号:201601282
陕西省教育厅科研项目(12JK0733);陕西省自然基金项目(2012JM8044);西安邮电大学研究生创新基金项目(114-602080049)
马传宾(1989—),男,山东菏泽人,硕士研究生。研究方向:语义Web。
猜你喜欢
哈哈画报(2021年10期)2021-02-28
数码世界(2020年5期)2020-06-23
制造业自动化(2017年2期)2017-03-20
计算机时代(2017年2期)2017-03-06
时代金融(2016年27期)2016-11-25
电脑知识与技术(2016年13期)2016-06-29
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
中国科技术语(2012年3期)2012-03-20
中国科技术语(2012年3期)2012-03-20
