
基于宽松下近似的模糊决策树归纳算法
2016-11-09 06:58:22张群峰
河北大学学报(自然科学版) 2016年3期
张群峰
(河北大学数学与信息科学学院,河北保定 071002)
基于宽松下近似的模糊决策树归纳算法
张群峰
(河北大学数学与信息科学学院,河北保定071002)
利用模糊相似关系对连续型决策表进行模糊化,进而运用宽松下近似定义启发式作为选择扩展属性的标准,从模糊决策表学习模糊决策树.
连续型决策表;宽松下近似;模糊决策树
MSC 2010:68T37
如何从连续型决策表归纳出模糊决策树,是机器学习研究的重要问题.所谓连续型决策表是指用实数值条件属性和决策属性刻画的样例集合.一个有n个条件属性值和1个决策属性值的样例可记为e=(a1,a2,…,ai,d),其中ai,d∈R,i=1,2,…,n(R为实数集合).
模糊决策树是一种由模糊属性作节点、模糊属性值即模糊集作边的树形图.当一个用模糊属性值描述的样例出现时,可利用模糊决策树对其进行分类:从根节点开始,用节点属性对样例进行测试,将样例沿隶属度最大的边分类到子节点,如此递归地对样例进行测试和分类,直至将样例分类到模糊决策树的某个叶子节点,此时叶子节点的模糊集就是该样例的类标.
常用的从连续型决策表归纳模糊决策树的几种方法都是先将连续属性用三角形或梯形模糊集模糊化,从而使连续型决策表成为模糊决策表,再利用某种启发式作为选择节点属性的标准,产生节点和分支从而产生模糊决策树,这些方法的不同之处主要在于启发式信息的构造方法.
本文主要运用模糊粗糙集中宽松下近似概念提出一种连续型决策表的模糊决策树构建方法,这种方法的主要优点是能充分挖掘样例的信息.
1 预备知识
1.1模糊相似关系
设U={e1,e2,…,ei}为一个有限论域,其中ei(i=1,2,…,n)为样例.笛卡尔积U×U上的模糊集R:U×U→[0,1]称为U上的一个模糊关系.如果模糊关系进一步满足:
1)自反性:∀x∈U,R(x,x)=1;2)对称性:∀x,y∈U,R(x,y)=R(y,x),则称R为U上的一个模糊相似关系.
1.2模糊集的宽松下近似
设U为给定的论域,R为U上的模糊相似关系,用F(U)表示U上的全体模糊集合,则对于任意A∈F(U),A的宽松下近似定义为
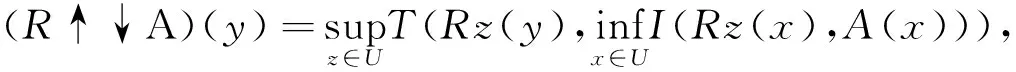
(1)
通常的下近似定义为
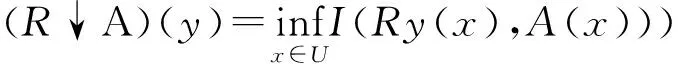
(2)
其中T为模糊t-模而I为模糊蕴含算子.
一般地有R↓A⊆R↑↓A⊆A,而且下例说明第1个包含关系中的等号可能不成立.
例设U=[0,1],A∈F(U)定义为A(x)=x,∀x∈U,U上的模糊相似关系定义为
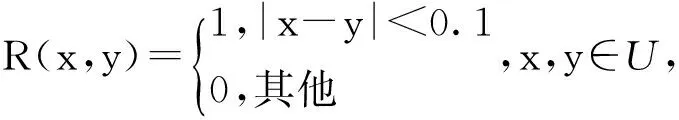
2 基于宽松下近似的模糊决策树归纳
2.1连续型决策表的属性模糊化
通常的模糊化方法是事先人为指定模糊集的个数,再将连续型属性模糊成若干三角形或梯形模糊集合,这种方法无论对什么属性做法都一样,忽视了各属性的特点.本文受宽松下近似的启发,对于给定的连续型决策表,针对每个属性的特点,选用一个合适的模糊相似关系以刻画样例间的相似性.进而对每一个属性建立一个相似矩阵.再通过合成的方法计算该模糊相似关系的传递闭包,依据该闭包对样例进行聚类.进一步确定每一类的聚类中心得出模糊集.
选定模糊相似关系后,产生模糊决策表的算法描述如下.
算法1连续型属性模糊化.输入:连续型属性的值向量.输出:连续型属性对应的模糊集.
第1步:计算属性对应的模糊相似矩阵; 第2步:计算模糊相似矩阵的传递闭包;第3步:根据适当的阈值取截集对样例聚类;第4步:对每个类计算其元素的平均相似度,将平均相似度最高的元素作为聚类中心,并以与其的相似度作为其他元素的隶属度.
2.2基于宽松下近似的属性重要度
设U={e1,e2,…,en}为样例构成的论域,C和D分别为连续型决策表的条件属性集合与决策属性,A⊂C为条件属性子集.若记RAj为对应于条件属性Aj∈A的模糊相似关系,则根据定义式(1),任意模糊决策类Ds(1≤s≤p)(这里p为决策类的总数)的RA-宽松下近似为
(3)
进而定义决策属性D相对于条件属性子集A的正域为
(4)
下面定义决策属性D相对于条件属性子集A的依赖度
(5)
设A⊂C为条件属性子集,Aj∈C为条件属性.若Aj∈A,则Aj相对于A的内部重要度定义为
(6)
若Aj∈C-A,则Aj相对于A的外部重要度定义为
(7)
选择决策树根节点的扩展属性时,需要计算各个条件属性相对于C的内部重要度;在选择子节点的扩展属性时,需要计算各候选属性相对于该节点所在路径上的父节点上扩展属性集的外部重要度.
算法2计算条件属性的重要度.输入:条件属性子集A,条件属性Aj,决策属性集合D.输出:条件属性Aj的重要度Ij.
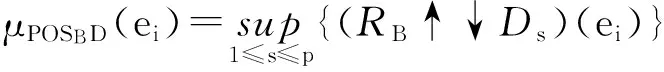
2.3模糊决策树的归纳算法
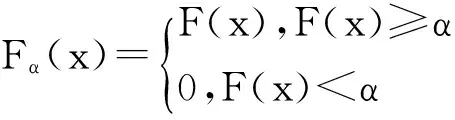
算法3模糊决策树归纳.输入:模糊决策表.输出:模糊决策树.
第1步:对所有条件属性计算其相对于条件属性集C的余集的正域,选择余集具有最小正域的条件属性作为根节点的测试属性.
第2步:按根节点测试属性的每一个模糊值术语产生一个分支.按照给定的α可能会产生该模糊值的截集为空集的情况,即所有样例对该模糊集的隶属度都在α以下,这时该分支称为空分支.删除所有的空分支.对于每一个非空分支,计算该分支相对于各个决策类的真值.如果存在真值大于β的决策类,则产生一个以该决策类为标签的叶子节点.否则,看是否有其他的条件属性能产生新的非空分支.若有,则选择相对于该路径属性集具有最大正域的属性作为扩展属性进一步产生新的分支.否则,产生新的叶子节点,其类标为具有最大真值的决策类.
第3步:对所有新的非叶子节点,重复第2步,直至树的生长结束.
下面的表1为一连续型决策表.选定如下模糊相似关系(其中σAj为属性Aj的属性值的均方差),对表1运用前述算法可得到如图1所示的模糊决策树.
(8)
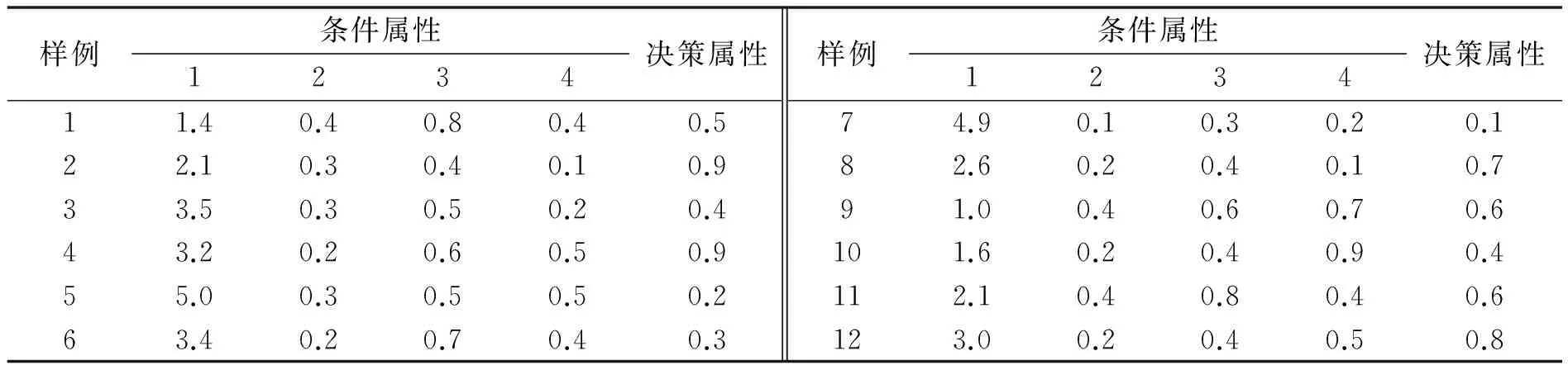
表1 连续型决策表的例子Tab.1 Examples of continuous decision table
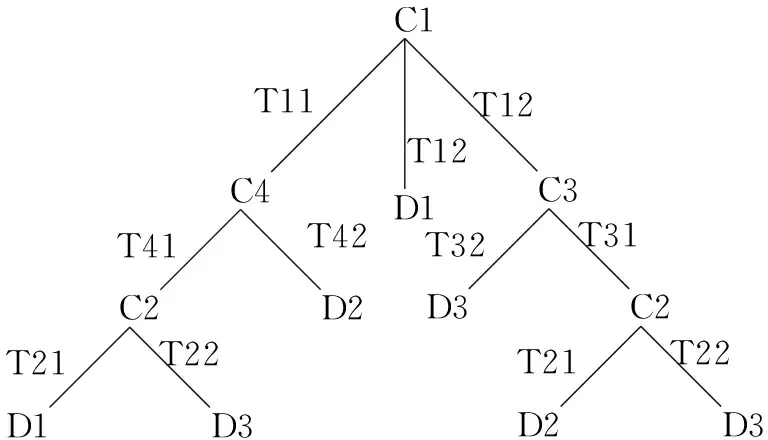
图1模糊决策树
Fig.1Fuzzydecisiontree
3 结论
在模糊粗糙集理论中,宽松下近似比其他形式的下近似概念能更准确地逼近目标概念.在从连续型决策表学习模糊决策树时,运用宽松下近似构造启发式并将其作为选择扩展属性的标准,能充分利用数据信息.而且,根据不同属性选择不同的模糊相似关系对连续值属性模糊化,可以反映属性的特点,避免通常模糊化方法的机械性.
[1]MOTOHIDEU,HIROTAKAO,ITSUOH.FuzzydecisiontreesbyfuzzyID3algorithmanditsapplicationtodiagnosissystems[C].ProceedingsoftheThirdIEEEConferenceonFuzzySystems,1994(3):2113-2118.DOI:10.1109/FUZZY.1994.343539.
[2]YUANY,SHAWMJ.Inductionoffuzzydecisiontrees[J].FuzzySetsSystem,1995,69(2):125-139.DOI:10.1016/0165-0114(94)00229-Z.
[3]WANGXZ,YEUNGDS,TSANGECC.Acomparativestudyonheuristicalgorithmsforgeneratingfuzzydecisiontrees[J].IEEEtransactionsonsystems,man,andcybernetics-partb:Cybernetics,2001,31(2):215-226.DOI:10.1109/3477.915344.
[4]TSANGECC,CHENDG,YEUNGDS,etal.Attributesreductionusingfuzzyroughsets[J].IEEETransFuzzySyst,2008,16(5):1130-1141.DOI:10.1109/TFUZZ.2006.889960.
[5]ZHAIJH.Fuzzydecisiontreebasedonfuzzy-roughtechnique[J].SoftComputing,2011,(15):1087-1096.DOI:10.1007/s00500-010-0584-0.
[6]RADZIKOWSKAAM,KERREEE.Acomparativestudyoffuzzyroughsets[J].FuzzySetsSystem,2002,126(2):137-155.DOI:10.1016/S0165-0114(01)00032-X.
[7]MARSALAC.Fuzzydecisiontreesfordynamicdata[EB/OL].(2013-04-15)[2015-03-12].http://webia.lip6.fr/~marsala/articles/2013-ssci.pdf.DOI:10.1109/EAIS.2013.6604100.
(责任编辑:王兰英)
A fuzzy decision tree induction algorithm based on loose lower approximation
ZHANG Qunfeng
(College of Mathematics and Information Science,Hebei University,Baoding 071002,China)
To induce a fuzzy decision tree from a continuous decision table,a method based on loose lower approximation in fuzzy rough set theory is proposed.First,a fuzzy decision table is generated by clustering fuzzy similarity relations.Second,based on loose lower approximation,a measure of the importance of a condition attribute is introduced.Finally,using this measure as a criterion for selecting the expanding attribute,a fuzzy decision tree induction algorithm is proposed and an illustrative example is provided.
continuous decision table;loose lower approximation;fuzzy decision tree
10.3969/j.issn.1000-1565.2016.03.001
2015-06-16
河北省自然科学基金资助项目(F2015201185);保定市科学技术研究与发展计划指导项目(12ZS005;12ZS006)
张群峰(1963-),男,河北邯郸人,河北大学副教授,主要从事机器学习及粗糙集理论研究.
E-mail:zhangqunfeng@hbu.cn
O235
A
1000-1565(2016)03-0225-04
猜你喜欢
苏州科技大学学报(社会科学版)(2023年4期)2023-03-03 05:37:43
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:07:36
心理学探新(2022年1期)2022-06-07 09:15:40
舰船电子工程(2022年4期)2022-05-11 09:34:32
广东教学报·教育综合(2020年15期)2020-03-23 05:58:29
华东师范大学学报(自然科学版)(2019年3期)2019-06-24 05:29:09
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:02
电测与仪表(2015年13期)2015-04-09 11:57:36
中央民族大学学报(自然科学版)(2014年2期)2014-06-09 08:28:14
中学教学参考·文综版(2014年1期)2014-03-11 09:19:00
