
社会机会网络中基于节点相似性的信任转发算法
2016-11-09 01:17:52袁江涛张振宇杨文忠
计算机应用与软件 2016年9期
袁江涛 张振宇 杨文忠
(新疆大学信息科学与工程学院 新疆 乌鲁木齐 830046)
社会机会网络中基于节点相似性的信任转发算法
袁江涛张振宇*杨文忠
(新疆大学信息科学与工程学院新疆 乌鲁木齐 830046)
针对社会机会网络中存在的自私节点,提出一种基于节点相似性的信任转发算法。该算法首先计算了节点的路径相似性和社交相似性;然后根据相似性强度确定节点间的信任关系,并将其量化为具体的信任值;最后引入消费心理学思想,选取稳定性较高的信任节点作为转发节点。实验表明,与经典转发算法对比,该算法在含有自私节点的网络环境中能保证数据可靠传递。
社会机会网络节点相似度信任关系数据转发自私节点
0 引 言
近年来,随着智能手机、穿戴设备、平板电脑等短距离无线移动设备的普及,使得以人为载体的移动设备利用相遇机会进行通信成为可能,这种通过人类移动进行机会式通信的网络一般称为社会机会网络[1]。由于真实网络环境中,节点设备的移动规律和活动区域会受到人类行为的影响,节点经常表现出“小世界”现象[2],同时网络中节点内存、能量、带宽等资源有限,所以节点基于自身利益可能会拒绝转发数据而表现出自私行为[3],严重影响网络性能的可靠性。
机会网络中已有的信任转发算法主要通过节点的相关信息评价节点信任,从而找出信任节点作为可靠转发节点。文献[4]在不同的中间节点寻找不同转发节点的共同兴趣和朋友,以此衡量信任关系,但是在大规模的机会网络会造成较高延迟时间。文献[5]引入社会网络的朋友关系,依据节点间共同朋友数量、Prophet预测转发能力、节点流行度算法综合评价节点信任度,有效提高了数据转发效率,但该方法需要较长的准备时间建立节点间的朋友关系。文献[6]通过目的节点发送给源节点的反馈数据包数量衡量节点信任度,并利用反馈数据包识别自私节点,但有时大量的反馈数据包会造成网络局部拥堵的情况。文献[7]利用机会网络网络拓扑结构、跳数距离、交互时间、交互频率建立节点间的信任关系,通过该关系进一步确定节点的真实身份,从而有效抵抗“女巫”攻击,但是在节点松散的网络环境中,网络的转发效率较低。文献[8]在Spray-and-Wait基础上,每个节点通过历史交互次数评价相遇节点的信任等级,利用信任级别避开向自私节点转发数据。但是在自私节点数量较多时,其信任评价的准确性较差。社会机会网络作为一种特殊的机会网络,目前针对该网络的信任转发算法相对较少,如何确保数据转发在社会机会网络中不受自私节点干扰是一个重要问题。
本文从社会学的角度出发,提出一种基于社会节点相似性的信任转发算法。通过对网络整体区域的划分,对比不同节点间的移动轨迹和不同区域内节点的社交情况,计算节点间的路径相似性和社交相似性,从而量化节点间的信任度;同时依据消费心理学思想计算信任稳定性,选择稳定性较强的节点作为数据的转发节点,降低自私节点对数据转发的影响。
1 基于节点相似性的信任转发算法
1.1计算路径相似性和社交相似性
结合现实社会环境与社会成员的生活经验,经常在相同区域内活动的不同社会成员可以得到较多的交互机会,可逐渐建立起较为熟悉的关系[9],例如学生在上课时间段内会聚集在学校、喜爱电影的人经常会在休闲时间段内聚集在电影院、消费者在市场的正常营业时间段内聚集在市场等。根据活动场合的性质和类型,不同的社会成员会聚集成不同的团体,使得不同社会成员间活动范围经常重叠在一起。
通过分析社会网络中同一区域内具有相同移动路径的社会成员关系,以及社会成员在不同区域内的关系,了解到社会成员间的关系与其活动的场合密切相关,经常在相同区域内活动的不同社会成员可以得到较多的交互机会,逐渐建立起较为熟悉的关系。因此,社会机会网络节点通过模仿上述关系的建立过程,根据节点的路径相似性和社交相似性,共同构建节点的信任关系,抵抗节点自私行为对数据转发的影响。
1.1.1路径相似性
在社会机会网络中,节点的移动速度、方向、线路等都是由社会成员控制的,社会成员利用社会活动建立社会关系的同时,也给节点之间带来了建立关系的机会,例如经常在同一条路径上相遇的社会成员更容易建立一定的社会关系。因此,可以对比不同节点的路径相似性,从而确定节点间的信任关系。
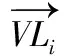
(1)
另外,随着节点不断移动,每个节点的移动路径也在不断变化,对于一定时间内不再访问的区域,需要对移动路径进行更新,以保证最近时间内经过的区域为当前移动路径。所以,每个节点记录了前一次进入某一子区域的时间tin、前一次移出某一子区域的时间tout和当前时间tnow,对位置矩阵进行更新的计算方法如下式所示:
(2)
式中round()为取整函数,LUpdate(tin,tout,tnow)表示某一子区域的更新值,只有更新值低于阈值φ,才将位置矩阵中该区域的标记位重置为0,反之,则维持标记位的原状态。
1.1.2社交相似性
一般情况下,不同社会成员的共同朋友数量可以在一定意义上说明成员间的关系强度[11],共同朋友的数量越多,两者之间的关系越紧密,例如同一个班的学生往往认识全班的所有同学,彼此之间能建立良好的信任关系。所以,在社会机会网络中可以对比节点间的社交相似性,反映节点间的信任关系。
首先,节点需要用邻接链表记录各子区域内的交互节点数量,邻接链表的头结点由子区域名称的数据域和指向链表第一个节点的指针组成,表节点是由邻节点域、记录交互节点名称的数据域、指向链表下一个节点的指针组成。如果节点i在1区域分别与节点b和节点u交互,则将节点b和节点u按照相遇顺序添加到1区域后面,表示节点i在1区域有两次交互记录。
(3)
Deci,j(tlast,tnow)=e-round(tnow-tlast)
(4)
1.1.3信任计算
在社会机会网络中,对比不同节点的路径相似性和社交相似性即可确定节点间的信任关系。采用加权求和的方法结合节点间的路径相似性和社交相似性,即可得到节点间的信任度Ti,j,如式(5)和式(6)所示:
Simi,j=α·LSim(Li,Lj)+β·FSim(Fi,Fj)
(5)
Ti,j=Simi,j
(6)
式(5)中Simi,j表示节点j和i的总体相似度,α和β分别表示路径相似性和社交相似性在总体相似度中所占的权重系数,α,β∈(0,1)且α+β=1,由于α和β的权重控制要依据节点评价信任的环境来确定,同时要体现信任评价的主观性和动态性[12],所以权重分配方法如式(7)和式(8)所示:
(7)
(8)
1.2信任转发过程
从消费心理学[13]可知,社会成员在商场购买商品时,更倾向于选择质量具有稳定性保障的商品。本算法在选择信任节点作为转发节点时,可以根据节点的历史评价信任值考察节点信任的稳定性,在信任节点中选择稳定性最佳的节点作为数据转发的下一跳节点,进一步描述信任评价的准确性,保证数据转发的可靠性。
假设节点i对节点j的历史信任值序列为T1 i,j,T2 i,j,T3 i,j,…,Th i,j,h表示节点i对节点j的第h次信任评价,其信任稳定性的计算方法如式(9)和式(10)所示:
(9)
(10)

信任转发的具体过程可分为如下几步:
1.3算法复杂度分析
算法的时间复杂度主要取决于交互节点的数量和网络划分的规模。假设场景中节点数量m,网络划分的规模为n×n,算法最坏的情况为某一节点与其他n-1个节点相遇,此时算法的复杂度为O(mn2),最好的情况为某个节点只与单个节点相遇,此时算法的计算复杂度为O(n2)。考虑到现实网络中的情况介于最坏的情况与最好的情况之间,该算法的计算复杂度介于O(n2)和O(mn2)之间。另外,由于整个评价算法的存储数据和输入输出数据中包含二维表和一维数组等,所以该评价算法的空间复杂度为O(n)。
2 实验仿真
本文使用仿真工具ONE 1.4.1[14]对提出的信任转发算法进行评估,先将城市街道地图划分为若干200 m×200 m的放行区域,同时设置200个节点,每个节点采用蓝牙通信方式,通信半径为10 m,节点移动速度为1~3 km/h,数据传输速率为200 Kbps,环境参数具体设置如表1所示。
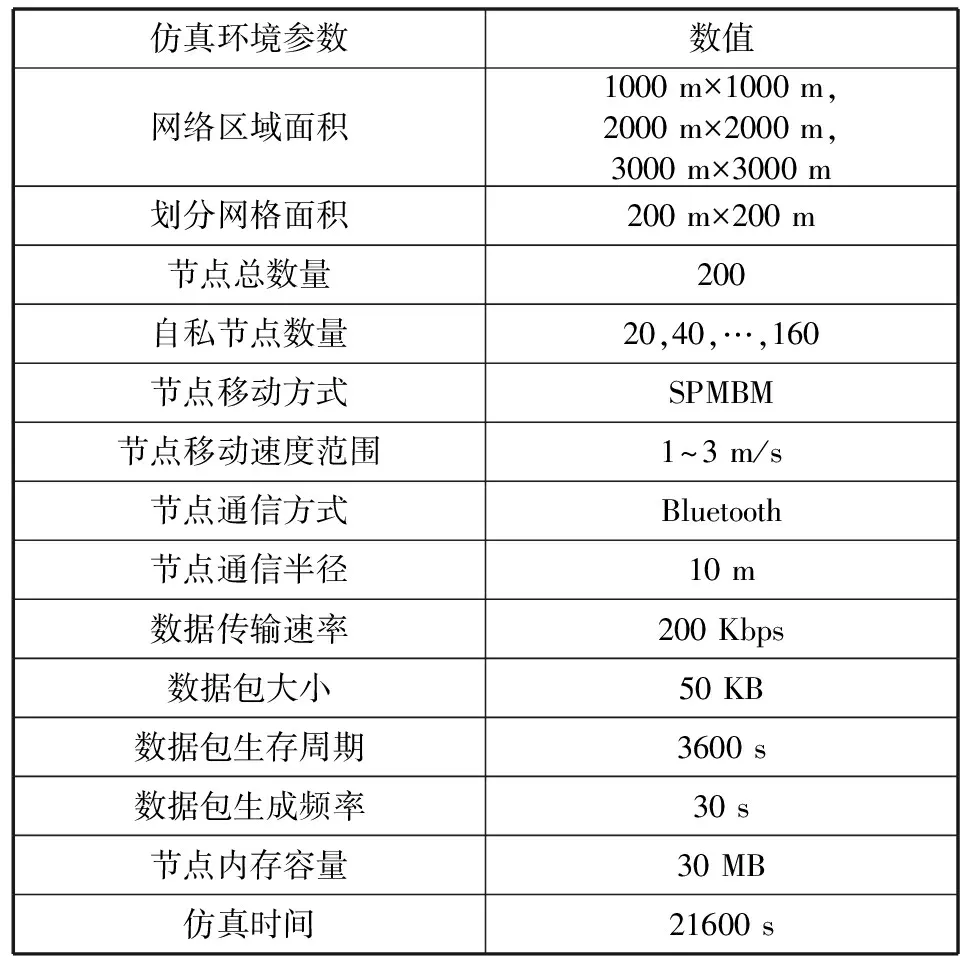
表1 仿真环境参数设置
为了考察提出算法优劣,本文以传输成功率和平均延迟时间两个指标进行衡量。实验分为两组,分别对比在不同自私节点情况下,Epidemic[15]、Prophet[16]、Spray-and-Waits[17]三种转发方式,在没有使用信任算法和使用信任算法情况下的传输成功率和平均延迟时间,同时给出仿真结果,并分析其原因。
2.1传输成功率
如图1、图2、图3所示,分别在1000 m×1000 m、2000 m×2000 m、3000 m×3000 m的区域内,不同自私节点比例下,对比没有使用信任算法的Epidemic、Prophet、Spray-and-Wait和在使用信任算法的T-Epidemic、T-Prophet、T-Spray-and-Wait传输成功率。
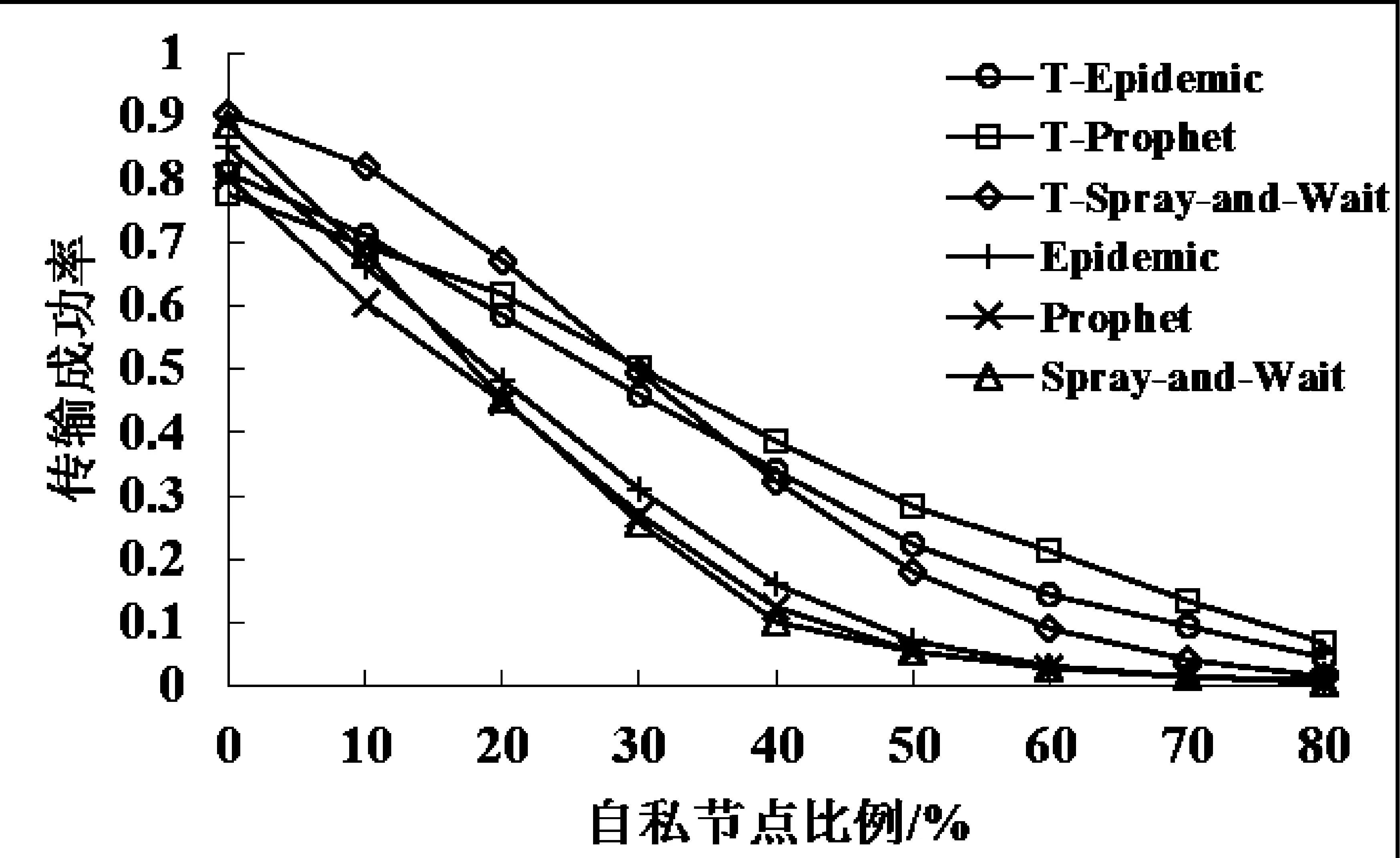
图1 1000 m×1000 m区域内的传输成功率
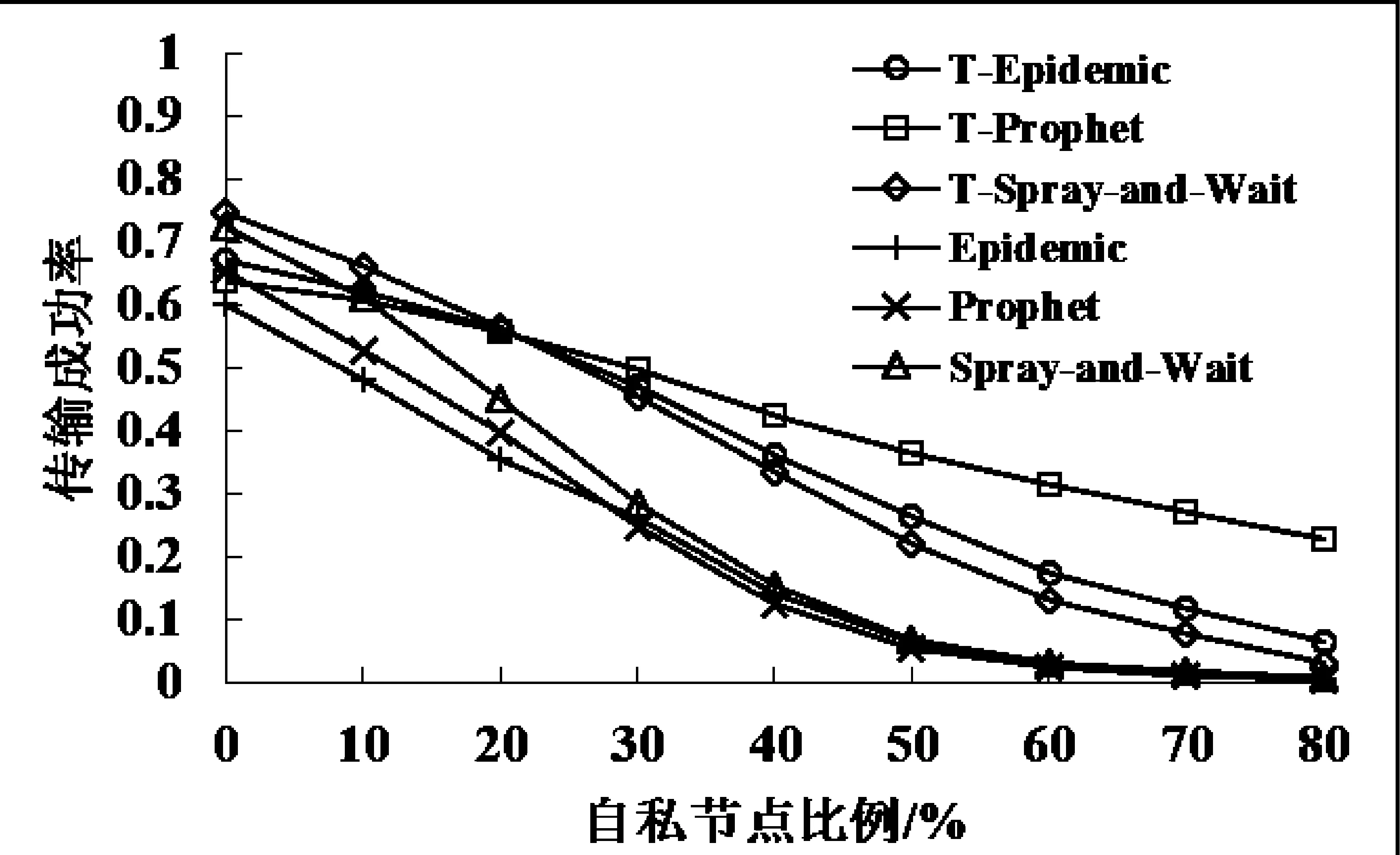
图2 2000 m×2000 m区域内的传输成功率
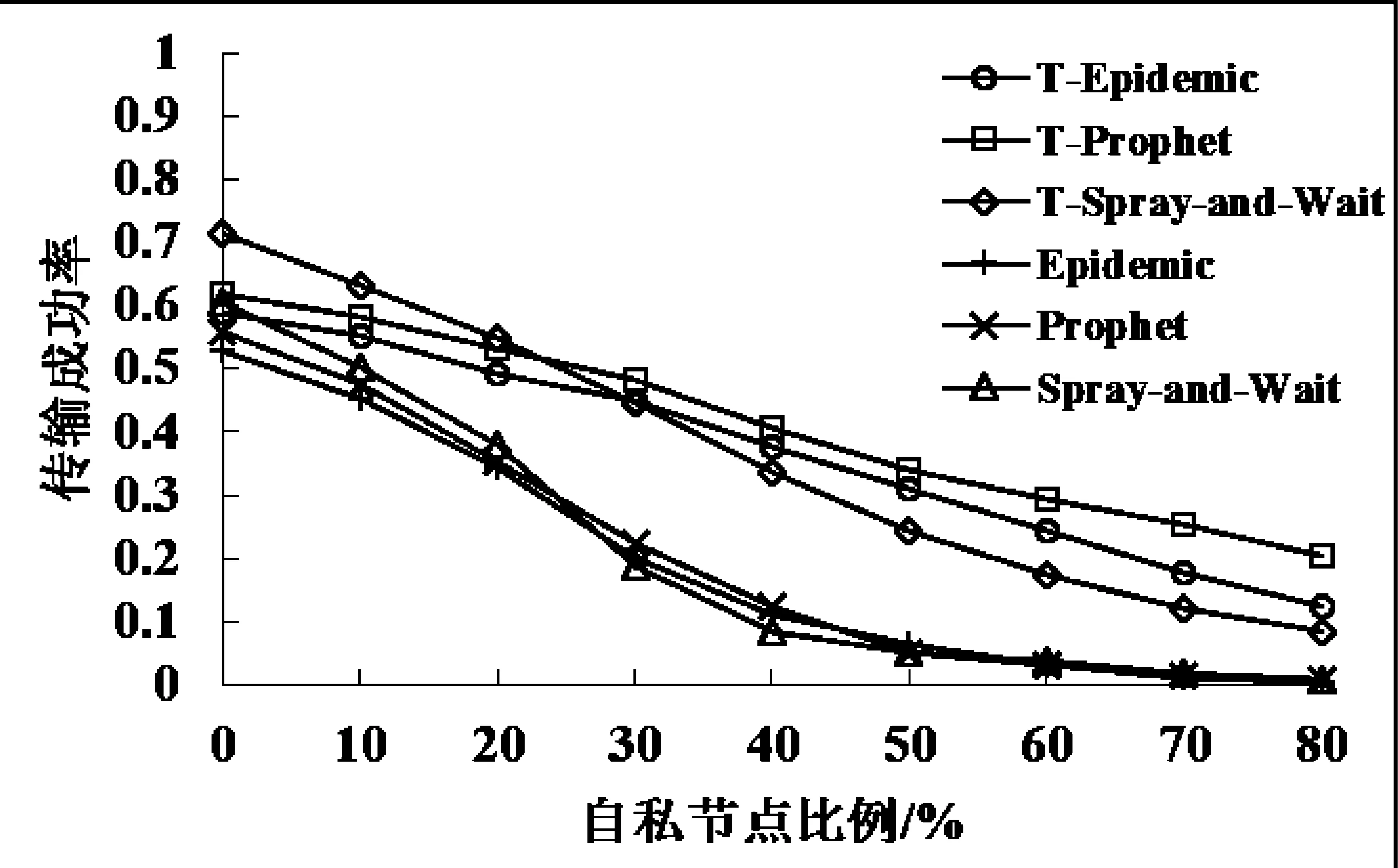
图3 3000 m×3000 m区域内的传输成功率
从图1-图3可知,3种转发方式在没有使用信任算法的情况下,随着网络区域面积的增大,传输成功率逐渐降低,总体趋势都是随着自私节点比例的增加而降低。当自私节点比例增长到50%或60%时,三种路由的传输成功率基本为0,只有极少量的数据可以传输成功,网络已基本处于崩溃状态。在使用信任算法的情况下,虽然传输成功率的趋势是随着自私节点比例的增高而降低,然而通过建立的信任关系,有效保证了数据转发的可靠性,降低了自私节点对数据转发过程的影响。
另外,通过对比同一网络区域面积内三种转发方式的传输成功率,Epidemic在自私节点比例较低时,其传输成功率比其他两种路由模式的传输成功率较高; Prophet在自私节点比例较高时,其传输成功率较高;Spray-and-Wait的传输成功率总体表现较为一般。这种情况可能是由于Epidemic在自私节点影响较小的情况下,其洪泛转发机制提高了数据的传输成功率,但是在自私节点影响较大的情况下,Epidemic的大量数据包被自私节点劫持,只有少量的数据在部分信任度较高的节点之间传递,使其传输成功率急速下降。Prophet由于本身带有目的节点预测能力,再配合信任策略建立节点间的信任关系,使其在随着自私节点比例增高的情况下,传输成功率下降速度较慢。Spray-and-Wait是在Epidemic基础上改进的转发算法,其性能介于Prophet和Epidemic之间。
2.2平均延迟时间
如图4、图5、图6所示,分别在1000 m×1000 m、2000 m×2000 m、3000 m×3000 m的区域内,不同自私节点比例下,对比没有使用信任算法的Epidemic、Prophet、Spray-and-Wait和在使用信任算法的T-Epidemic、T-Prophet、T-Spray-and-Wait平均延迟时间。
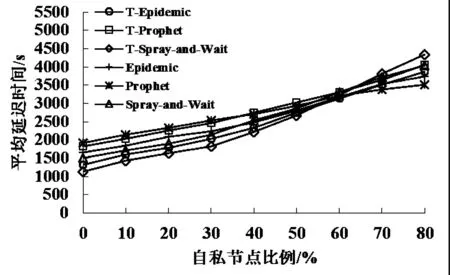
图4 1000 m×1000 m的区域内的平均延迟时间

图5 2000 m×2000 m的区域内的平均延迟时间

图6 3000 m×3000 m的区域内的平均延迟时间
从图4-图6可知,随着网络区域面积的增大,数据传输的平均延迟时间逐渐增长。3种转发方式在没有使用信任算法的情况下,数据转发的平均延迟时间是随着自私节点比例的增加而快速增长;在使用信任算法的情况下,随着自私节点比例的增高,数据传输的延迟时间得到了有效降低,减缓了平均延迟时间的增长趋势。
通过对比观察同一网络区域面积内三种转发方式的平均延迟时间,当自私节点比例低于50%或60%时,Spray-and-Wait的平均延迟时间低于Prophet和Epidemic的平均延迟时间, Prophet由于其转发数据包相对较少,在自私节点的影响下,其平均延迟时间比Epidemic和Spray-and-Wait都高。当自私节点比例低于50%或60%时,Prophet通过自身预测转发并配合信任算法,在自私比例相对较高时,平均延迟时间要低于Epidemic和Spray-and-Wait。
3 结 语
本文从社会学角度出发,在社会机会网络中,提出一种基于节点相似性的信任转发算法。利用节点的移动路径和社交情况描述节点间的相似性,从而反映出节点间的信任关系,一方面完善了社会机会网络节点的信任评价过程,另一方面有效解决了自私节点对数据转发的影响。仿真结果表明,与经典转发算法相比,该转发算法在含有自私节点的网络环境中能保证数据的高效传递。
[1] Boldrini C,Conti M,Passarelia A.Exploiting users’ social relations to forward data in opportunistic networks:The HiBOp solution[J].Pervasive and Mobile Computing,2008,4(5):633-657.
[2] Golbeck J,Hendler J.Inferring binary trust relationships in web-based social networks[J].ACM Transactions on Internet Technology (TOIT),2006,6(4):497-529.
[3] Mtibaaa,Harras K A.Social-Based Trust Mechanisms in Mobile Opportunistic Networks[J].Proc.IEEE SIMNA,2011,2011,5(3):34-39.
[4] Becker C,Schlinga S,Fischer S.Trustful Data Forwarding in Social Opportunistic Networks[C]//Ubiquitous Intelligence and Computing,2013 IEEE 10th International Conference on and 10th International Conference on Autonomic and Trusted Computing (UIC/ATC).IEEE,2013:430-437.
[5] Premaltha S,Mary Anita Rajam V.Reputation management for data forwarding in opportunistic networks[C]//Computer Communication and Informatics (ICCCI),2014 International Conference on.IEEE,2014:1-7.
[6] Trifunovic S,Legendre F,Anastasiades C.Social trust in opportunistic networks[C]//INFOCOM IEEE Conference on Computer Communications Workshops,2010.IEEE,2010:1-6.
[7] Al-hinal A,Zhang H,Chen Y,et al.TB-SnW:Trust-based Spray-and-Wait routing for delay-tolerant networks[J].The Journal of Supercomputing,2014,69(2):1-17.
[8] Dend S,Hhang L,Xu G.Social network-based service recommendation with trust enhancement[J].Expert Systems with Applications,2014,41(18):8075-8084.
[9] Gallos L K,Makse H A,Sigman M.A small world of weak ties provides optimal global integration of self-similar modules in functional brain networks[J].Proceedings of the National Academy of Sciences,2012,109(8):2825-2830.[10] Callahan E,Agarwal A,Cheever C,et al.Determining a trust level of a user in a social network environment:U.S.Patent 8,656,463[P].2014-2-18.
[11] Conti M,Giordano S,May M,et al.From opportunistic networks to opportunistic computing[J].Communications Magazine,IEEE,2010,48(9):126-139.
[13] Keranen A.Opportunistic network environment simulator[OL].[2008-5-29],http://www.netlab.tkk.fi/tutkimus/dtn/theone.
[14] Ramanathan R,Hansen R,Basu P,et al.Prioritized epidemic routing for opportunistic networks[C]//Proceedings of the 1st international MobiSys workshop on Mobile opportunistic networking.ACM,2007:62-66.
[15] Huang T K,Lee C K,Chen L J.Prophet+:An adaptive prophet-based routing protocol for opportunistic network[C]//Advanced Information Networking and Applications (AINA),2010 24th IEEE International Conference on.IEEE,2010:112-119.
[16] Huang W,Zhang S,Zhou W.Spray and wait routing based on position prediction in opportunistic networks[C]//Computer Research and Development (ICCRD),2011 3rd International Conference on.IEEE,2011,2:232-236.
TRUST FORWARDING ALGORITHM IN SOCIAL OPPORTUNISTIC NETWORKS BASED ON NODE SIMILARITY
Yuan JiangtaoZhang Zhenyu*Yang Wenzhong
(School of Information Science and Engineering,Xinjiang University,Urumqi 830046,Xinjiang,China)
To address the problem of existence of selfish nodes in social opportunistic networks,we propose a node similarity-based trust forwarding algorithm.First the algorithm calculates the node path similarity and social similarity; then it determines the trust relationships between nodes based on the similarity strength,and quantifies them to specific trust value; finally it introduces the consumer psychology idea,and chooses the trust nodes with higher stability as the forwarding nodes.It is demonstrated by experiment that comparing with traditional forwarding algorithm,this algorithm guarantees the reliable messages transmission in a network environment containing selfish nodes.
Social opportunistic networksNode similarityTrust relationshipData forwardingSelfish node
2015-04-05。国家自然科学基金项目(61262089,61262087);新疆教育厅高校教师科研计划重点项目(XJEDU2012I09)。袁江涛,硕士生,主研领域:机会网络。张振宇,副教授。杨文忠,副教授。
TP393
A
10.3969/j.issn.1000-386x.2016.09.023
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
当代水产(2022年6期)2022-06-29 01:12:02
煤气与热力(2021年3期)2021-06-09 06:16:22
中国生殖健康(2020年8期)2021-01-18 03:05:34
河北画报(2020年8期)2020-10-27 02:54:20
湖南邮电职业技术学院学报(2020年3期)2020-10-13 04:40:50
交通运输系统工程与信息(2020年1期)2020-02-28 02:56:28
中国生殖健康(2018年3期)2018-11-06 07:20:12
中国塑料(2016年8期)2016-06-27 06:35:02
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
