
面向以太网的网络故障自动实时发现与定位方法
2016-11-09 01:21赵灿明纪诗厚
计算机应用与软件 2016年9期
赵灿明 纪诗厚 石 滚 田 野
1(国网安徽省电力公司芜湖供电公司信通公司 安徽 芜湖 241000)2(中国科学技术大学计算机科学与技术学院 安徽 合肥 230027)
面向以太网的网络故障自动实时发现与定位方法
赵灿明1纪诗厚1石滚2田野2
1(国网安徽省电力公司芜湖供电公司信通公司安徽 芜湖 241000)2(中国科学技术大学计算机科学与技术学院安徽 合肥 230027)
在网络应用已完全融入日常生产生活的今天,人们需要稳定、可靠的计算机网络,高效、准确地发现和定位网络故障,是提高网络可靠性的重要手段。现有的网络故障自动发现方法往往需要修改节点代码、控制节点行为来实现故障检测,而交换机等以太网设备通常并不具有可修改性。针对以太网故障的自动发现与定位问题,基于目前标准化交换机支持的简单网络管理协议SNMP(Simple Network Management Protocol)协议和管理信息库MIB-2(Management Information Base)提出了“设备状态一致性检测算法”、“设备拥塞异常检测算法”等针对不同故障的检测算法。实验结果表明该故障检测算法对发现和定位以太网故障具有较高的效率和准确率。基于所提出的故障检测算法,该设计实现了一个故障发现与定位系统,并成功地在芜湖市国家电网计算机网络中部署运用。
网络故障故障定位与检测管理信息库(MIB)
0 引 言
随着越来越多的互联网应用融入人们的日常生活,人们对网络的用户体验要求越来越高。使网络保持实时畅通是保证用户体验的前提,因此必须及时地检测并排除网络故障,网络故障的检测与排除是网络管理工作中很重要的一部分。如何高效准确地检测网络故障成为近年来网络故障研究中的一个热点和难点。
目前,关于网络故障检测算法的研究已有较多成果。Katzela等[1]提出了基于网络中通信实体间的网络依赖图进行网络故障检测和定位。Kandula等[2]提出了基于系统和程序产生的日志信息,模块依赖图和历史诊断结果来定位和诊断企业网络故障,并研发出一个称为NetMedic的故障检测系统。McCann[3]提出通过依赖图诊断网络系统故障,主要包括网络协议栈故障诊断和网络流故障诊断。虽然依赖图对故障的定位和检测具有较高的准确率,但是建立一个系统或网络的依赖图要求对该系统或网络很熟悉才能建立比较准确的依赖图,且随着网络拓扑的变化,网络依赖图也需要变化,但是保持网络依赖图的实时性也较难。Steinder等[4]提出了一种概率事件驱动故障定位技术,该技术使用概率症状故障地图作为故障传播模型,通过更新症状-解释变量,来确定可能出现该症状的集合。同时Steinder等[5]提出了通过贝叶斯推理技术以及系统的结构状态信息来定位网络故障。上述两个故障定位算法虽然模拟实验结果表明具有较高的准确率,但是算法比较复杂,工程实现具有一定的难度。蒋康明等[6]提出了基于主动探测的故障检测探测选择(PSFD)算法和故障定位探测选择(IFL)算法。其中的PSFD算法是在已有的贪婪算法上做了改进,IFL算法将现有的2种故障定位探测选择算法相结合,但算法的工程实用性难以保证。
同时对网络故障管理系统研发的相关研究也较多。马秀丽等[7]将开源规则引擎Drools应用于网络故障管理系统中。该系统采用数据挖掘的方法获取相关性规则,并分类存储在规则库中,然后通过规则引擎提供的API创建规则引擎对象,并加载规则库,自动实现对告警实例的相关性分析处理。王伟等[8]提出了一种基于专家系统的网络故障管理系统结构。把事件关联和数据挖掘应用于网络故障管理,设计出了一个完整的基于规则的网络故障管理系统模型,它能够同时支持对关联规则和序列模式的推理[9]。结合专家系统的知识库和推理机,设计故障过滤和故障诊断模型[10]。Kompella等[11]提出基于风险模型和故障排除系统来定位网络故障。Zhang等[12]提出基于加权二分图的模型来定位网络故障。Feng等[13]将概率模型用于网络故障定位。然而,基于数据挖掘和概率模型研发的系统其准确率较难保证,且需要积累海量的网络设备日志进行分析,还有不同的厂商生产的网络设备的日志内容、格式不一样,有些网络设备甚至不产生日志。因此如果网络中新增加了不同厂商不同类型的网络设备,该设备的故障检测的实时性较难保证,同时不产生日志的网络设备的故障较难检测。
还有一些企业同时也开发了商用网络故障管理系统。如ManageEngine的OpManager系统[14],这是一款端到端的综合网络管理软件,可对企业网络内的网络设备、服务器、主机、WAN链路、应用及服务等IT基础设施实现全方位、可视化、统一集中监控和管理。IBM的Netcool Network Management系统[15]是一款具有拓扑发现、检测网络故障、配置网络等功能的系统。惠普的OpenView系统[16]是一款具有拓扑发现和故障管理等功能的系统。
本文基于目前标准化交换机支持的SNMP和MIB-2,提出了以太网故障检测方法。该方法通过查询MIB-2中的相关变量和简单计算即可检测与定位以太网的一般性故障:链路拥塞、设备异常、设备状态不一致等,且实验结果表明该方法具有较高的效率和准确率。然后基于本文的故障检测方法设计和实现了以太网故障检测系统,并成功部署到芜湖市国家电网计算机网络中。
1 以太网故障发现与定位方法
1.1MIB变量说明
SNMP是一个用于IP网络设备管理标准的互联网协议。目前支持SNMP的网络设备包括:路由器、交换机、服务器、工作站、调制解调器、打印机等[23]。SNMP作为一个网络设备管理协议并没有定义哪些信息是网络设备应提供用于管理的,而MIB说明了设备管理的数据结构,使用对象标识符OID(Object Identifier)来唯一标识每个变量,这些变量可以通过SNMP协议来读取和赋值。本文使用的MIB变量如表1所示。

表1 MIB变量说明
1.2以太网故障发现与发现方法
首先形式化描述由以太网拓扑发现子系统获得的目标网络拓扑结构(以太网拓扑发现系统是基于文献[17]中的算法研发的)。对于发现的目标网络拓扑结构,用图G=(V,E)表示,其中u∈V表示图中的一个节点,代表拓扑上的一台交换机,ui表示交换机u的第i个端口。e=(ui,vj)∈E表示图中的一条边,代表拓扑中连接交换机u的ui端口和交换机v的vj端口的一条链路。所有的交换机和链路构成目标网络链路层拓扑G=(V,E)。
1.2.1 设备状态一致性检测算法
以太网交换机状态一致性检测算法如算法1所示。目标网络中交换机状态一致性检测主要包括:
• 交换机端口状态检测:对目标网络中的所有交换机,对该交换机出现在拓扑中的所有端口,查询其ifOperStatus值为1,表明端口正在工作;否则,报警。
• 交换机STP协议版本一致性检测:对目标网络中的所有交换机,查询其dot1dStpProtocolSpecification取值应一致;否则,报警。
• 交换机工作方式一致性检测:对目标网络中的所有交换机,获取其dot1dTpPortTable全为空,或者其dot1dSrPortTable全为空;否则,报警。
• 交换机源路由协议版本一致性检测:如果网络中所有交换机工作于源路由模式,则查询所有交换机的dot1dSrBridgeLfMode取值应一致;否则,报警。

算法1 状态一致性检测算法Input:switchsetdetectedbyEthernetTopologyDiscoverySystem(ETDS)SDefine:flag=false1. foreachswitchsinSandeachportpofs:2. ifp.ifOperStatus==1:continue//检测交换机端口状态3. else:producewarning//交换机端口不工作,报警4. flag=checkwhetherallswitches’dot1dStpProtocolSpecificationinSissame//检测交换机STP协议版本5. ifflag==false:producewarning//交换机STP协议版本不一致,报警 //交换机工作方式//一致性检测6. flag=checkwhetherallswitches’dot1dTpPortTableordot1dSrPortTableinSisempty7. ifflag==false:producewarning//交换机工作方式不一致,报警 //如果交换机工作于源路由模式检测源路由协议是否一致8. flag=checkwhetherallswitches’dot1dSrBridgeLfModeinSissame9. ifflag==false:producewarning//交换机源路由协议不一致,报警
1.2.2 设备拥塞异常检测算法
以太网中交换机拥塞异常检测算法如算法2所示。以太网故障检测系统周期地对网络中所有交换机的每个端口,计算由于拥塞导致的报文丢弃率。本文仅考虑交换机工作于透明网桥模式下(交换机工作于源路由网桥模式下的算法类似)。在某个时刻t,查询交换机每个端口的dot1dTpPortOutFrames(本文以下使用TpPOF表示)变量和交换机的dot1dBasePortDelay
ExceededDiscards(本文以下使用BPDED表示)变量。计算(t,t+1)时段,交换机传输和丢弃的报文帧数。如果在连续K段时段中,有L段时段discard(t,t+1)/transport(t,t+1)大于某个阈值delta,则报警。传输和丢弃帧数的计算公式如下:



算法2 设备拥塞异常检测算法Input:switchsetdetectedbyEthernetTopologyDiscoverySystem(ETDS)S,K,L,t,deltaDefine:transport(t,t+1)=0,discard(t,t+1)=0,count=0,i=01. foreachswitchsinS:2. count=0,i=03. whilei
1.2.3链路丢包异常检测与定位算法
以太网中链路丢包异常检测与定位算法如算法3所示。以太网故障检测系统周期性地对拓扑中每一条链路(ui,vj),计算链路在两个方向的丢包率。本文以下仅考虑交换机工作于透明网桥模式下(交换机工作于源路由网桥模式下的算法类似)。在时刻t,查询端口ui和vj的TpPOF和dot1dTpPortInFrames[21](本文以下使用TpPIF表示)变量。分别计算(t,t+1)时段,链路(ui,vj)不同方向的丢包率。如果在连续K段时段中,有L段时段lossu(v(t,t+1)或lossv(u(t,t+1)大于某个阈值delta,则报警。丢包率的计算公式如下:
u→v方向上的丢包率lossu(v(t,t+1)
v→u方向上的丢包率lossv(u(t,t+1)

算法3 链路丢包异常检测与定位算法Input:topologydetectedbyEthernetTopologyDiscoverySystem(ETDS)topo,K,L,t,deltaDefine:lossu(v(t,t+1)=0.0,lossv(u(t,t+1)=0.0,count1=0,count2=0,i=0,switchportui,vj1. foreachedge(ui,vj)intopo:2. count1=0,count2=0,i=03. whilei
1.2.4DoS攻击检测算法
以太网上常见的DoS攻击是攻击者通过构造伪装源MAC地址不同的以太帧,使得交换机在其转发表中存储大量的无意义地址转发条目,并换出真正有用的地址转发条目,从而达到瘫痪网络的目的。以太网故障检测系统周期性地,对网络中每台交换机,计算其换出的地址转发条目。在时刻t,查询交换机的dot1dTpLearnedEntryDiscards变量。计算(t,t+1)时段,换出的转发条目数量。如果在连续K段时段中,有L段时段discardentry(t,t+1)>0,则报警。换出的地址转发表条目计算公式如下:
discardentry(t,t+1)=dot1dTpLearnedEntryDiscardst+1-
dot1dTpLearnedEntryDiscardst
1.2.5地址转发表正确性检测算法
随机选取一个MAC地址s,s未绑定在网络中任何设备上。构造以s为源地址,以网络中待检测设备u为目的地址的以太网帧,在网络中传输。若交换机v位于从检测系统到待检测设备u的路径上,则以s查询v的dot1dTpFdbTable转发表变量,应存在条目(s,vi,learned)条目,其中vi是v接收探测报文的端口,表明v已经学习了s的转发条目;否则,报警。
1.3ns-3 模拟实验
本文使用ns-3[22]进行模拟实验,模拟网络中包括45台交换机和60台主机。交换机状态一致性错误模拟是通过给每台交换机定义一组变量且这组变量的初始值都相同,然后随机选择一组交换机不定时改变这组交换机的初始值,实验过程中本文将时间间隔设为1~15秒。同时每隔interval1秒检测所有交换机的这组变量,实验中将interval1设为5秒,如果发现某台交换机异常则报警。表2展示的是模拟4种交换机状态一致性错误各500次,程序检测的结果,实验结果表明算法2检测交换机状态一致性错误具有较高的准确率。

表2 交换机状态一致性错误检测模拟结果
基于上面的拓扑,本文选取拓扑中的25条链路(由30台交换机组成),将这25条链路分为5组,并将这5组链路的丢包率分别设为3%、5%、8%、12%、15%。然后主机间以一定的速率sendrate在覆盖这25条链路的路径上转发一定数目的报文。每台交换机的每个端口定义两个变量sh_rec_packets和ac_rec_packets分别用于统计应当接收和实际接收的报文数。实验中,本文定义报警阈值delta=0.1、L=1。同时每隔interval2秒检测这30台交换机的所有端口的sh_rec_packets和ac_rec_packets,并根据算法2和算法3检测交换机故障和端口故障。图1展示的是sendrate分别为10 packets/s和30 packets/s,interval2=2秒时,连续发送100秒,30台交换机丢包率超过delta的次数(交换机按sendrate=10 packets/s时产生的报警数排序)。实验结果表明,交换机转发流量越大,越容易丢包,这与实际情况是一致的。当sendrate=30 packets/s,25条链路两个端口产生的报警数如图2所示。从图2可以观察到有些链路两个端口的报警数相差较大,这是由于在实验过程中,我们故意增加一些交换机的负荷,使其处理报文的能力下降造成的。在实际情况下,如果两台直连交换机性能相同,但是一台交换机丢包率明显大于另外一台交换机,应该查询丢包率较大的交换机判断其是否出现了故障。

图1 链路流量与交换机报警次数的关系

图2 25条链路两端口报警次数比较
同样使用上面的拓扑,为模拟DoS攻击,每台交换机定义两个变量learn_table_size和discard_entry分别用于表示转发表的大小和因超过转发表的容量被丢弃的表项数,同时定时检测discard_entry。然后使拓扑中的主机以不同的速率发送源MAC地址不同的报文。表3展示的是当learn_table_size=500时,主机以不同速率连续发送60秒报文,10台边缘交换机(即与主机直连的交换机)平均丢弃的表项数。实验结果表明边缘交换机丢弃的转发表的表项数和该交换机每秒收到的源MAC地址不同的报文数目正相关。同时可以发现当主机的发送速率为60 packets/s时,边缘交换机丢弃的表项数与交换机应该接收到的源MAC地址不同的报文数目相差较大,这是因为在模拟拓扑中我们发现边缘交换机每秒能正确处理的报文数目大概为50个。
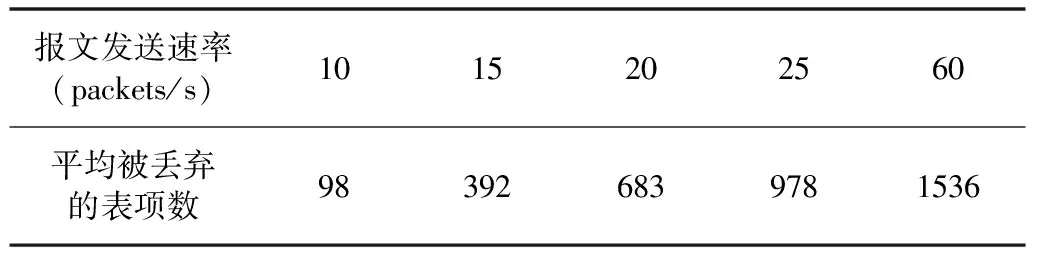
表3 交换机DoS攻击检测模拟结果
基于上面的拓扑,与模拟DoS攻击检测一样,在模拟交换机地址转发表正确性检测时,本文仍将转发表的大小learn_table_size设为500。然后使主机以不同的速率发送报文,以检测10台边缘交换机的转发表的正确性,实验结果如表4所示。实验结果表明当交换机超负荷时,转发表的准确率较低。
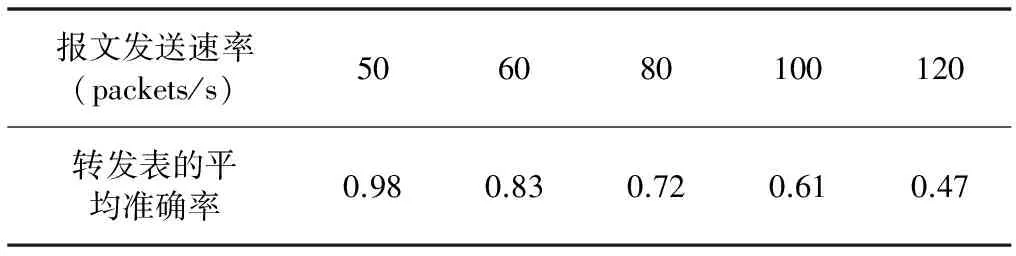
表4 交换机地址转发表正确性检测模拟结果
2 以太网故障检测系统的设计与实现
2.1系统概述
以太网故障检测子系统架构如图3所示。该系统依赖以太网拓扑发现子系统获取的目标网络拓扑结构,通过SNMP通信模块周期性地查询目标以太网络上交换机的MIB管理变量,执行相应的故障检测算法,发现目标网络中交换机与链路故障,生成日志,并向网络管理员发送报警信息。

图3 以太网故障检测子系统架构
以太网故障检测子系统包含5个关键模块:
• 状态一致性检测模块:检测目标网络中所有交换机及其端口的工作模式是否正确,网络链路两端的端口工作模式是否一致,发现异常时报警。
• 端口拥塞异常检测模块:周期性检测目标网络中交换机端口的拥塞情况,发现交换机拥塞异常时报警。
• 链路丢包异常检测模块:周期性检测目标网络中链路的丢包事件,发现链路丢包率异常时报警。
• DoS攻击检测模块:周期性检测目标网络中交换机地址转发表的溢出情况,发现地址转发表溢出异常时报警。
• 转发表正确性检测模块:检测目标网络中交换机能否正确构造地址转发表,发现地址转发表异常时报警。
这样的系统架构设计使得系统的各个模块的耦合度较低,具有较好的扩展性和可移植性。
2.2对实际运行网络的故障发现与定位
我们将所提出的故障检测方法应用到对芜湖市国家电网公司计算机网络中。芜湖市国家电网的内部以太网覆盖安徽省芜湖市的所有电网网点,骨干网络由40多台交换机组成,为整个城市的供电管理提供了通信基础设施。基于本文提出的以太网故障检测方法、系统架构和10个测量agent,我们开发了以太网故障检测子系统,并集成到公司的网络管理综合系统中。故障检测子系统的功能界面如图4所示。我们统计该模块连续运行50天检测到的各种故障结果。其中交换机状态一致性错误检测结果如表5所示。STP协议版本不一致错误检测到3次是由于在实验期间,公司由于业务需要,新增了3台交换机,这三台交换机的STP协议的版本均高于目前网络中交换机运行的STP协议版本。公司网络中所有交换机都工作于透明网桥模式下,表4中的交换机工作方式不一致错误以及交换机源路由协议版本不一致错误是我们人为修改交换机配置造成的。
图4 以太网故障检测子系统界面

错误类型端口不工作STP协议版本不一致工作方式不一致源路由协议版本不一致检测到的次数8332020
实验期间我们研发的系统检测到交换机拥塞异常10次,链路拥塞异常16次,DoS攻击100次(均是我们每天人为伪造2次DoS攻击的结果),我们人为发送100个MAC地址不同的报文,发现报文所经过链路上的交换机转发表均能正确学习到。同时我们统计所有故障发生到检测到的时间间隔,发现所有故障平均的检测时间位54秒。实验结果表明,我们研发的以太网故障检测系统能较快较准确地发现和定位以太网故障。
3 结 语
基于目前标准化交换机支持的SNMP和MIB-2,本文提出了以太网故障检测方法,并基于该方法研发了以太网故障检测系统。模拟实验结果和对实际运行网络的故障检测结果表明该方法能较高效、较准确地发现和定位以太网故障,因此该方法具有较好的适用性和较高的工程应用价值。
[1] Katzela I,Schwart M.Schemes for fault Identification in network communications [J].IEEE/ACM Transactions on Networking,1995,3(6):753-763.
[2] Kandula S,Mahajan R,Verkaik P,et al.Detailed diagnosis in enterprise networks [C]// Proc.of ACM International Conference on the applications,technologies,architectures,and protocols for computer communication’09,2009.
[3] McCann J N.Automating performance diagnosis in networked Systems [D].Prince George`s County,State of Maryland:School of Computer Science,University of Maryland,2010.
[4] Steinder M,Sethi A S.Probabilistic fault diagnosis in communication systems through incremental hypothesis updating [J].Computer Networks,2004,45(4):537-562.
[5] Steinder M,Sethi A S.Probabilistic fault localization in communication systems using belief networks [J].IEEE/ACM Transactions on Networking,2004,12(5):809-822.
[6] 蒋康明,林斌,乔焰.基于主动探测的高效故障检测与定位方法[J].北京邮电大学学报,2012,35(1):36-40.
[7] 马秀丽,王红霞,张凌云.Drools在网络故障管理系统中的应用[J].计算机工程与设计,2009,30(8):1859-1862.
[8] 王伟,芦东昕,唐英.基于专家系统的网络故障管理系统的设计[J].计算机工程与设计,2005,26(11):3031-3033.
[9] 岳海涛.基于事件关联和数据挖掘的网络故障管理技术的研究[D].长沙:中南大学计算机学院,2010.
[10] 赵永杰.基于事件机制的网络故障管理系统的研究[D].西安:西安电子科技大学计算机学院,2008.
[11] Kompella R R,Yates J,Greenberg A,et al.IP fault localization via risk modeling [C]// Proc.of Symposium on Network System Design and Implementation’05,2005.
[12] Zhang C,Liao J X,Li T H,et al.Probabilistic fault localization with sliding windows [J].China Science Information Science,2012,55(5):1186-1200.
[13] Feng M,Gupta R.Learning universal probabilistic models for fault localization [C]//Proc.of ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering’10,2010.
[14] ManageEngine OpManager System [EB/OL].[2014-04].http://www.manageengine.com/network-monitoring/network-fault-mana-gement.html.
[15] IBM Netcool Network Management System [EB/OL].[2011-07].http://www-03.ibm.com/software/products/en/netcool-network-management.
[16] HP OpenView System [EB/OL].[2013-08].http://h71000.www7.hp.com/.
[17] Breitbart Y,Garofalakis M,Jai B,et al.Topology discovery in heterogeneous IP networks:the NetInventory system [J].IEEE/ACM Transactions on Networking,2004,12(3):401-414.
[18] McCloghrie K,Rose M.Management Information Base for Network Management of TCP/IP-based internets.IETF RFC 1156 [EB/OL].[1990-05].https://www.ietf.org/rfc/rfc1156.txt.
[19] Decker E,Langille P,Rijsinghani A,et al.Management information base for network management of TCP/IP-based internets.IETF RFC 1286 [EB/OL].[1991-10].https://www.ietf.org/rfc/rfc1286.txt.
[20] Decker E,McCloghrie K,Langille P,et al.Definitions of managed objects for source routing bridges.IETF RFC 1525 [EB/OL].[1993-09].https://www.ietf.org/rfc/rfc1525.txt.
[21] Decker E,Langille P,Rijsinghani A,et al.Definitions of managed objects for bridges.IETF RFC 1493 [EB/OL].[1993-07].https://www.ietf.org/rfc/rfc1493.txt.
[22] ns-3 main page [EB/OL].[2011-08].http://www.nsnam.org/.
[23] SNMP wiki [EB/OL].[2015-4-28].http://en.wikipedia.org/wiki/Simple_Network_Management_Protocol#cite_note-ESNMP-1.
AN ETHERNET-ORIENTED METHOD FOR AUTOMATIC REAL-TIME NETWORK FAULTS DETECTION AND LOCALISATION
Zhao Canming1Ji Shihou1Shi Gun2Tian Ye2
1(Information and Telecommunication Branch,State Grid Wuhu Power Supply Company,Wuhu 241000,Anhui,China)2(SchoolofComputerScienceandTechnology,UniversityofScienceandTechnologyofChina,Hefei230027,Anhui,China)
Nowadays the network applications have been fully integrated into people’s daily life,the people require a stable and reliable computer network.To efficiently and accurately identify and locate network faults is the important means for improving networks reliability.However existing automatic network faults detection methods usually need to modify nodes code or control nodes behaviour to realise the faults detection,but the switches and other Ethernet devices are not modifiable typically.In this paper,in light of automatic Ethernet faults detection and localisation issue,we proposed based on SNMP and MIB-2 which supporting the standardised switches the “device status consistency detection algorithm”,“device congestion anomaly detection algorithm” and other detection algorithms aimed at different Ethernet faults.Experimental results indicate that these algorithms could identify and locate Ethernet faults with high efficiency and accuracy.Based on these proposed algorithms we design and implement a detection and localisation system for Ethernet faults,and it is successfully deployed in computer networks of State Grid in Wuhu Power Supply Company.
Network faultsFault localisation and detectionManagement information base (MIB)
2015-05-05。国家自然科学基金项目(61202405,61103228)。赵灿明,工程师,主研领域:计算机系统结构。纪诗厚,工程师。石滚,硕士生。田野,副教授。
TP393
A
10.3969/j.issn.1000-386x.2016.09.024
猜你喜欢
装备制造技术(2020年1期)2020-12-25
铁道通信信号(2019年12期)2019-05-21
铁道通信信号(2018年12期)2019-01-31
网络安全和信息化(2018年6期)2018-11-07
网络安全和信息化(2017年8期)2017-11-07
电子制作(2017年24期)2017-02-02
铁道通信信号(2016年10期)2016-06-01
电源技术(2015年7期)2015-08-22
中国交通信息化(2015年11期)2015-06-06
电子设计工程(2015年6期)2015-02-27
