
基于前景置信的人体行为识别
2016-11-08 08:43孟朝晖
计算机应用与软件 2016年10期
闵 军 孟朝晖
(河海大学计算机与信息学院 江苏 南京 211100)
基于前景置信的人体行为识别
闵军孟朝晖
(河海大学计算机与信息学院江苏 南京 211100)
为减少背景特征对行为识别的影响,提出一种基于前景置信的人体行为识别方法。该方法在基于稠密时空兴趣点的行为识别基础上,结合像素前景置信估计对特征描述器进行加权分类,再利用词袋模型判别行为。融合运动、外观及视觉显著性的像素前景置信的引入,提高了算法处理复杂背景视频的能力。该方法在UCF50和HMDB51视频库中进行训练和测试,平均识别率为66.4%。
行为识别前景置信加权分类词袋模型复杂背景
0 引 言
最近的十多年里,行为识别是计算机视觉研究的热点问题之一,在虚拟现实、人机交互及智能监控等领域有着广泛应用,受到越来越多研究人员的关注。
当前很多方法主要是通过提取视频中兴趣点的局部特征来对行为进行描述和识别。如 Harris3D 时空兴趣点检测算法[1]、Dollar时空兴趣点检测算法[2]、 Bregonzio时空兴趣点检测算法[3]和Laptev稠密时空兴趣点检测算法[4]。上述方法都在KTH 视频库上做过实验,得到了比较理想的结果。
然而,这种局部的特征描述器过分依赖训练视频库和测试视频库固有的特征,不区别对待背景特征和前景特征,也就是说不能突出视频中运动人体的特征。这就导致以上方法能够在特定的视频库中取得很好的结果,但对跨视频库或者实际生活中的视频进行测试时结果不理想。由此,本文提出一种融合人体运动、外观以及视觉显著性的前景置信行为识别方法。该方法不依赖前景和背景分离,而是根据以上特征对视频帧的每个像素进行前景估计,再结合兴趣点检测对行为进行识别。
1 背景在行为识别中的影响力
行为识别视频数据库原则上代表人类的视觉世界,因此应当尽可能多样化。背景的多样化是视频多样化最简单也是最常见的情况,背景特征应当对行为识别结果有尽可能小的影响。如果影响过大,这将广义化识别模型,最终导致在不同背景的视频库中识别准确率低的情况。除了背景的不同,同一个行为,不同人的动作的视角、姿势、速度以及关节的运动也是有所差异,这些都是影响识别结果的重要因素。
文献[5]在单独背景、单独前景和全局的情况下基于稠密时空兴趣点分别对UCF Sports和UCF Youtube 两个视频库进行行为识别,以此来说明背景或前景对行为识别结果的影响力,结果如表1所示。
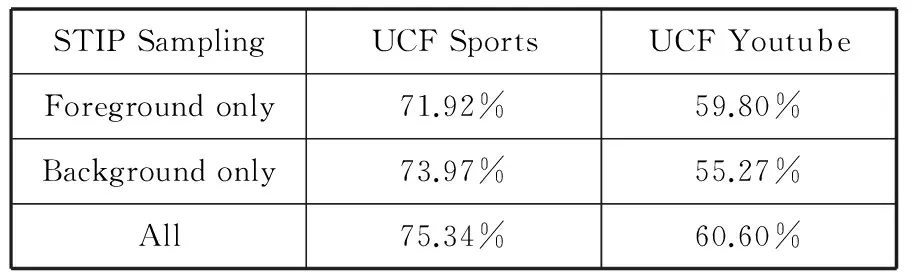
表1 基于稠密时空兴趣点识别结果
由结果可以看出,单独的背景特征检测并没有使识别的准确率有很大的下降。也就是说,在传统的全局特征提取中,背景特征和前景运动人体特征对识别结果的影响基本是等同的,甚至在UCF Sports视频库中背景的作用超过了前景,这就是在与训练库不同背景的视频库中进行测试结果不理想的主要原因。另一方面,由于视频背景复杂、相机的突然抖动等因素给前景提取带来了很大的干扰,基于单独前景特征行为识别的结果也不理想。依据特征对行为识别结果贡献度的不同,本文提出一种基于前景置信的人体行为识别方法。
2 基于前景置信的人体行为识别
2.1前景置信
所谓前景置信,就是估计视频帧中的每个像素作为前景区域的概率。本文主要从运动特征、外观特征、视觉显著性三方面考虑。
2.1.1运动特征
运动特征主要指的是视频中移动的部分,特别是运动的人体,可以针对这一特征给该像素较高的前景置信度。然而现实生活中很多视频在拍摄的过程中摄像头是移动的,如果使用简单的光流法,那些作为背景的非运动人体同样可以得到很高的置信度。为了避免这一问题,采用光流梯度[6]的 F-范数来体现运动特征。光流梯度不仅能够减少移动摄像头带来的背景影响,而且能给运动目标的运动关节带来很高的置信度。基于运动特征的前景置信度fm(x,y)定义为:
(1)
式中u和v为t时刻图像平面上坐标为(x,y)的像素点在水平和竖直方向的瞬时速度分量,g是指定方差的二维高斯滤波器。图1(a)是视频中骑车的原图,图1(b)为该帧进行运动特征检测后的视觉效果图,运动的人体和车有很高的前景置信度,背景的前景置信度则较低。

图1 运动特征
2.1.2外观特征
在大多数视频中,人体本身的颜色和背景颜色有着明显的差异,在室外有蓝色天空的地方尤为明显。本文的外观特征主要从颜色方面考虑,同时以颜色梯度作为第二个计算前景置信度的因素。在LAB颜色空间[7]中使用F-范数来计算,基于颜色梯度的前景置信度fc(x,y)定义为:
(2)
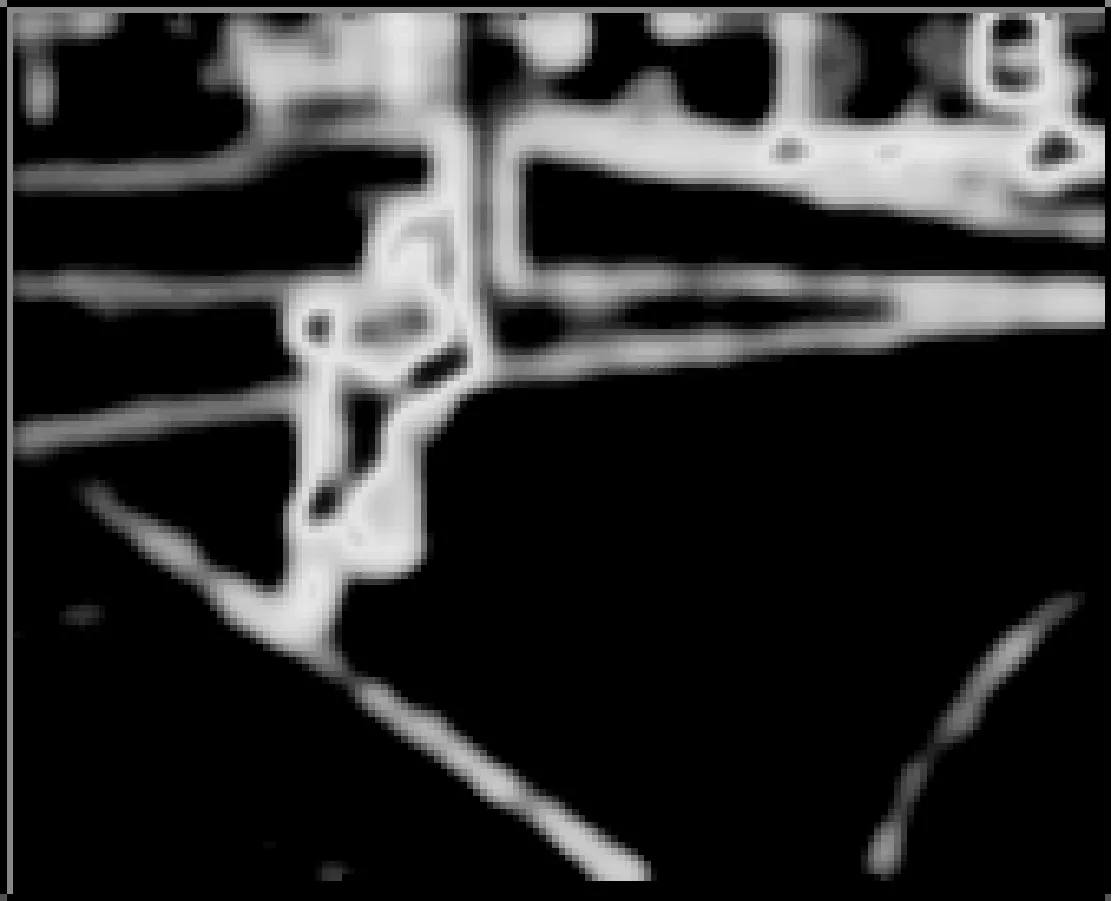
图2 外观特征
式中(Lx,ax,bx)、(Ly,ay,by)分别为水平和竖直方向的梯度向量,g是指定方差的二维高斯滤波器。外观特征检测后的定性效果如图2所示。由效果图可以看出,与背景颜色存在差异的人体、自行车及背景边缘有较高的前景置信度,颜色差异不大的区域前景置信度较小。
2.1.3视觉显著性
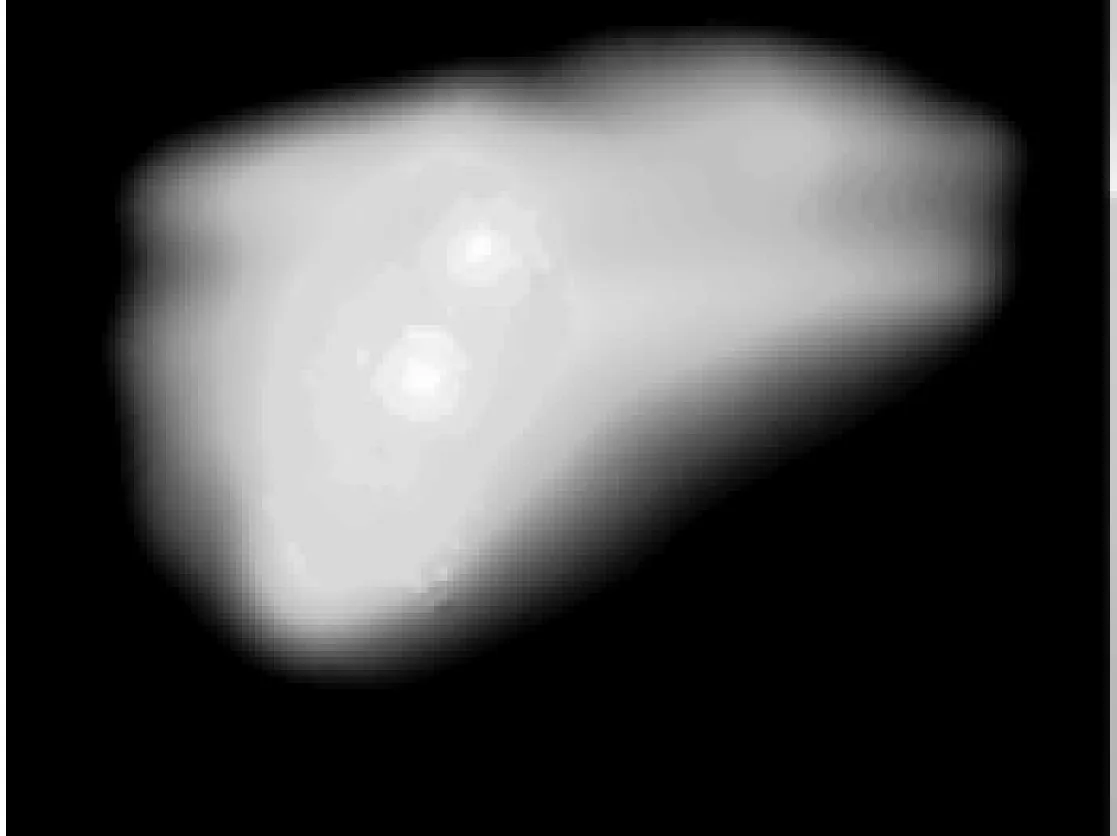
图3 视觉显著性
视觉显著性标识了一个场景中能够吸引视觉注意力的位置,Ttti及Koch在多篇文献中阐述了视觉显著性的作用机制和原理。相比于Ttti模型,Harel等[6]提出的基于图的视觉显著性模型GBVS(Graph-Based Visual Saliency),其基本思想是通过马尔科夫随机链的遍历分布来模拟视觉在扫描场景中的视觉分配特性,故在视觉注意力分配方面建模更加成功。本文以视觉显著性作为第三个影响前景置信度的因素,基于图的视觉显著性模型计算结果效果如图3所示,具体步骤如下:
Step1获取图像多尺度的亮度信息。对输入的每一帧图像转化为灰度图像,再使用高斯金字塔低通滤波器对其进行滤波,得到不同尺度下的滤波结果,表示亮度通道。
Step3求不同尺度和不同特征图的马尔科夫平衡分布。对上述每个通道内每个尺度的滤波结果,根据其像素间的差异和欧氏距离建立各自的马尔科夫链,然后求其马尔科夫平衡分布。
Step4计算视觉显著图。将所有组、所有尺度的滤波结果依次计算出平衡分布后,将结果按照通道叠加起来并归一化,得到大小与原始图像一致的综合显著图fs(x,y)。
2.1.4前景置信度融合
鉴于对数函数处理统计数据具有优势,本文以log(fm(fc+fs)+1)来融合每一个像素的前景置信度,并利用该帧中最大值对其进行归一化,得到的结果定义为该像素初始前景置信度fa。外观和视觉显著性的计算仅依赖当前帧,也就是仅用到了像素的空间信息。本文利用时空相邻点的相关性,按照式(3)对像素的前景置信度进行修正。
fa(p)=ω1fa(p)+ω2∑q∈NTpfa(q)+ω3∑q∈NSpfa(q)
(3)

图4 前景置信度
式中fa(p)为p点的前景置信度,NTp指时间上和p关联的点的集合,即前一帧和后一帧中和该点坐标相同的点的集合,NSp指空间上和p关联的点的集合,即该帧中p点周围的四个点的集合。本文中ω1=0.5,ω2=0.1,ω3=0.75,计算得到该帧最终的前景置信度fa(x,y)。加权后的前景置信度不仅提高了时间维度上的比重,而且能够防止局部点异常的情况,增加了算法的鲁棒性,最终的前景置信度定性效果如图4所示。
2.2前景置信词汇表构造和分布直方图生成
传统的词袋模型直接对特征描述器集合X={xi},通过K-means进行聚类,得到k个聚类中心(码字)。这k个聚类中心就形成了相应的视觉词汇表,再利用最小距离法计算该视频的特征描述器集合在各个码字中出现的频率,统计形成直方图分布,就形成了利用直方图来对视频中的人体动作进行表征的方法[9]。该模型把所有特征描述器放在了同等的地位,不能够突出运动人体特征的重要性,故识别结果不会很好。本文在此基础上,利用像素的前景置信度构造加权前景视觉词汇表并生成相应的加权分布直方图。具体构造过程如下:
Step1对输入视频每一帧进行前景置信度计算,并进行稠密时空兴趣点检测[4],生成特征描述器集合X={xi}。
Step2计算像素点平均前景置信度。利用像素点的时空性,由式(4)计算像素点平均前景置信度ωi,其中Pi指在时空框架中同描述器xi相关联的点的集合,即空间相邻的四个像素点和时间相邻的两个像素点的集合。
ωi=∑(x,y)∈Pifa(x,y)/|Pi|
(4)
Step3构造视觉词汇表。依据最小能量函数(式(5)),利用特征加权K-means对特征描述器集合进行聚类,得到聚类中心集合Z={zj},即为加权视觉词汇表。其中C为|X|×K维的矩阵,这样的聚类方式使得聚类中心Z离高前景置信度的特征描述器近,离低前景置信度的特征描述器较远。

(5)
Step4生成加权分布直方图。利用最小距离法判别每个描述器xi属于哪个码字zj,并以属于该码字的所有描述器的前景置信度之和作为该码字出现的频率,形成对应的加权分布直方图。
2.3人体行为识别
上文中的视频分析都是针对单个视频的,然而不同的人在进行同一行为,动作上也是存在差异的,提取出来的特征描述器集合是不同的。这直接影响到加权直方图的分布,故对行为识别的结果影响很大。产生差异的主要原因是人的升高、衣服的颜色、动作的幅度、速度以及背景的差异。为了解决这一问题,需要构造每种行为的标准加权直方图。以Biking为例,识别原理如图5所示,具体构造如下:
Step1利用前面提到的方法,分别计算n个Biking视频的特征描述器子集合Gi(1≤i≤n)和像素的平均前景置信度ωi,对这些子集合进行合并得到代表Biking的特征描述器总集合ΩG。
ΩG=G1∪G2∪…∪Gn
(6)
Step2对特征描述器总集合进行聚类,得到标准码本。再利用最小距离法对总集合ΩG中所有特征描述器进行分类,以每个描述器的平均前景置信度之和作为该码字的频率,形成标准加权分布直方图。
Step3对测试视频按照2.2节的方法,得到加权分布直方图。再和Biking的标准分布直方图进行相识度匹配,从而判别该行为类型。

图5 识别原理图
3 实验结果及分析
实验的主要目的是证明基于前景置信的行为识别方法比传统稠密特征点识别方法有更高识别率。为了验证本文提出的人体行为识别方法的性能,在UCF50和HMDB51这两个视频库上进行实验。
UCF50视频库[10]有50种行为类别,虽然大多视频不是日常生活中的,而是专门的表演拍摄,拍摄时会或多或少偏向该行为,但这其中不乏有很多业余拍摄风格。比如一些杂乱的背景或者突然的摄像机运动等情况拍摄而成的视频。HMDB51视频库[11]中的视频大多来自电影,也就是说HMDB51取材于比较真实的场景,更加接近现实生活。考虑到两个视频库中篮球、骑自行车、引体向上、高尔夫球摆动及骑马的视觉相似度较高,本文对这五种行为进行实验验证。
以UCF50视频库中这五种行为的各100个视频为训练样本,对HMDB51视频库中同种行为的各100个视频进行测试,测试结果如表2所示。

表2 HMDB51测试的混淆矩阵
为保证实验的公平性,对2个视频库进行交叉实验。分别从2个视频库中取每种运动的100个视频,按照60∶40的比例分开,60个用来训练,另外的40个用来测试。测试结果如表3所示,实验结果可以看出,在同一个视频库里进行训练和测试仅仅提高了3%左右的准确率,但在跨视频库的训练和测试上有10%以上的提高,说明该算法具有处理复杂背景视频的能力。

表3 测试结果
4 结 语
本文简单分析了传统时空特征点方法的不足,提出了一种复杂场景下的人体行为识别方法。该方法依据像素的运动特征、颜色特征、视觉显著性特征,引入了像素前景置信度的概念,并利用它先对特征描述器进行加权分类,再判别行为类型。实验结果表明,该方法比传统未加权的时空兴趣点检测行为识别方法有更高的识别率,在不同的视频库上进行训练和测试的时效果更加明显。
[1] Laptev I.On Space-Time Interest Points[J].International Journal of Computer Vision,2005,64(2-3):107-123.[2] Dollar P,Rabaud V,Cottrell G,et al.Behavior recognition via sparse spatio-temporal features[C]//Visual Surveillance and Performance Evaluation of Tracking and Surveillance,IEEE International Workshop on.IEEE,2005:65-72.
[3] Bregonzio M,Gong S G,Xiang T.Recognising action as clouds of space-time interest points[C]//IEEE Conference on Computer Vision & Pattern Recognition.IEEE,2009:1948-1955.
[4] Laptev I,Marszalek M,Schmid C,et al.Learning realistic human actions from movies[C]//Computer Vision and Pattern Recognition,IEEE Conference on.IEEE,2008:1-8.
[5] Sultani W,Saleemi I.Human Action Recognition across Datasets by Foreground-Weighted Histogram Decomposition[C]//Computer Vision and Pattern Recognition (CVPR),2014 IEEE Conference on.IEEE,2014:764-771.
[6] 郭利,曹江涛,李平,等.累积方向-数量级光流梯度直方图的人体动作识别[J].智能系统学报,2014,9(1):104-108.
[7] 庞晓敏,闵子建,阚江明.基于HSI和LAB颜色空间的彩色图像分割[J].广西大学学报:自然科学版,2011,36(6):976-980.
[8] Harel J,Koch C,Perona P.Graph-based visual saliency[C]//Advances in Neural Information Processing Systems,2006:545-552.
[9] 雷庆,陈锻生,李绍滋.复杂场景下的人体行为识别研究新进展[J].计算机科学,2014,41(12):1-7.
[10] Reddy K K,Shah M.Recognizing 50 human action categories of web videos[J].Machine Vision & Applications,2013,24(5):971-981.
[11] Kuehne H,Jhuang H,Garrote E,et al.HMDB:A large video database for human motion recognition[C]//Computer Vision (ICCV),2011 IEEE International Conference on,2011:2556-2563.
HUMAN BODY ACTION RECOGNITION BASED ON FOREGROUND CONFIDENCE
Min JunMeng Zhaohui
(CollegeofComputerandInformation,HohaiUniversity,Nanjing211100,Jiangsu,China)
In order to reduce the effect of background features on action recognition, this paper proposes a foreground confidence-based human body action recognition method. On the basis of dense spatiotemporal interest points-based action recognition, the method combines the pixels estimation with foreground confidence to carry out weighted classification on feature descriptors. Then it uses the bag-of-words model to discriminate actions. The introduction of foreground confidence of pixels fusing the motion, appearance and visual saliency improves the ability of algorithm in dealing with complex background video. To be trained and tested on UCF50 and HMDB51 video datasets, the method obtains the average recognition rate of 66.4%.
Action recognitionForeground confidenceWeighted classificationBag-of-words modelComplex background
2015-04-18。闵军,硕士生,主研领域:视频监控,行为识别。孟朝晖,副教授。
TP391
A
10.3969/j.issn.1000-386x.2016.10.042
猜你喜欢
舰船科学技术(2022年20期)2022-11-28
湘潭大学自然科学学报(2022年2期)2022-07-28
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
摄影之友(影像视觉)(2018年12期)2019-01-28
计算机应用(2018年5期)2018-07-25
自动化学报(2017年4期)2017-06-15
初中生世界·八年级(2017年3期)2017-03-24
国防科技大学学报(2016年6期)2017-01-07
潍坊学院学报(2016年6期)2016-04-18
