
基于本体的教育资源推理查询原型系统设计与实现
2016-11-08 08:33冯锡炜
计算机应用与软件 2016年10期
冯 瑶 冯锡炜
(辽宁石油化工大学计算机与通信工程学院 辽宁 抚顺 113001)
基于本体的教育资源推理查询原型系统设计与实现
冯瑶冯锡炜
(辽宁石油化工大学计算机与通信工程学院辽宁 抚顺 113001)
针对当前教育资源库存在的通用性差和缺乏语义查询等缺陷,将语义Web的重要基础本体及其推理和查询技术应用到教育资源领域,实现一个基于本体的教育资源推理查询原型系统。利用本体构建方法及建模工具protégé,以数据结构课程为例,构建一个基于元数据标准的教育资源领域本体;制定教育资源领域本体知识点推理规则,提出改进的语义相似度算法;设计并实现基于本体的教育资源推理查询原型系统。通过实验验证,该系统的查全率与查准率均高于基于关键字的查询。
教育资源本体本体推理本体查询原型系统
0 引 言
近年来E-Learning正被广泛关注,E-Learning的基础和核心是建立专业教育资源库。但当前Web上的各种教育资源缺乏一致的标准,无法通用和共享;同时,资源的知识组织缺乏语义关联,无法进行智能检索等服务。本体是实现语义Web的重要基础和技术,广泛应用于知识表示、知识共享与重用、逻辑推理等领域。本体是使用特定词汇来描述具有明确观点的实体、类、属性和相关函数的形式化概念模型。本体可以从已知有限的语义关系中推理出更丰富更深层的语义关系,从而增强了本体的表达性。近十年来,很多机构和组织都致力于对本体的研究并把其应用到各种实际领域中来。文献[1]对本体建模进行深入研究,构建了一个地理领域本体,并在推理机制和语义检索技术的基础上设计了一个应用地理领域本体的旅行检索和推荐的原型系统。文献[2]在医疗本体的基础上,利用语义查询扩展技术,提出了一个基于本体的医疗领域语义查询系统。文献[3]构建了玉米种植领域本体,并应用语义标注和查询扩展等技术实现了一个语义检索系统。文献[4]在专利领域本体的基础上,通过本体推理和查询等关键技术,使用语义Web框架Jena实现了专利本体的语义推理和查询系统。
本文将本体技术应用到教育资源领域,构建层次划分清晰、语义关系丰富的教育资源本体库,可以优化知识表示,同时为教育资源的语义查询和个性化自主学习做好准备。本文首先结合教育资源元数据标准,以“数据结构”课程为例构建了一个教育资源领域本体;其次结合SPARQL查询语言和查询扩展技术,针对教育资源本体制定了推理规则,并提出了改进的相似度算法;最后将本文的推理查询方法与Java EE 架构相关技术结合,实现了一个基于本体的教育资源推理查询原型系统。通过实验与基于关键字的查询作了比较,并验证了系统的可行性。
1 教育资源领域本体建模
1.1教育资源元数据标准
教育资源元数据能够对资源进行形式上以及内容上的描述,为教育资源标注提供了统一的标准。国外对其标准的研究开始于20世纪90年代,其中影响较大的有:IEEE LOM、ADL SCORM、Dublin DC。我国在2000年11月成立了全国信息技术标准化技术委员会教育分技术委员会CELTSC(Chinese E-Learing Technology Standardization Committee),制定了符合我国国情的教育资源元数据标准《CELTS-31学习对象元数据规范》[5]和《CELTS-41教育资源建设技术规范》[6]。本文参考ACM(Association for Computing Machinery)的CC2005(Computing Curricula 2005)[7]确定学科知识层次划分,以CELTS-31和CELTS-41两个教育资源元数据标准为蓝本,将元数据进行知识关联;利用本体技术,以“数据结构”课程为例,构建教育资源领域本体。教育资源领域本体提供了描述资源的组织框架。通过这个框架来对资源进行标注,并将学科知识中所有的概念划分,形成分类层次结构,为通过概念间的语义关联实现对资源的查询和检索做准备。
1.2教育资源本体的具体建模——以数据结构课程为例
本文参考7步法,结合CELTS元数据标准及CC2005,以“数据结构”为例,构建了一个教育资源领域本体。
(1) 确定了本体的领域和范围。教育资源库学科众多、分类复杂。本文将本体的领域范围限定在计算机领域,力图今后可以供其他学科的教育资源本体复用所参考。
(2) 复用现有本体。由于目前比较成熟的本体集中在医学、生物、地理等领域,我们所要涉及的领域并没有可以复用的本体。所以本文通过对元数据项及其与教育资源间的关系进行分析和抽象,找出语义关联性,定义类及类的属性,建立教育资源领域本体。
(3) 确定本体的类和层级。教育资源领域本体参考CC2005和CELTS-41确定类和层级,将计算机学科的教育资源本体划分为学科(Discipline)、资源(Resource)和课程知识点(Concept)三大子类。
本文参考CC2005对学科类进行划分;采用CELTS-41标准对资源类进行细分;将课程类划分为具体知识点集并对其进行语义关联,通过知识点间的语义关联可以实现对资源的推理和查询。课程知识点的组织结构参考CC2005,由上至下分为知识域(KnowledgeArea)、知识单元(KnowledgeUnit)和知识主题(KnowledgeTopic)。
参考国内多本数据结构教材以及网络课程,按照上文所述的知识点组织结构,将数据结构课程的核心知识点划分为5个知识域,15个知识单元,100多个知识主题,基本覆盖整个数据结构课程的核心知识内容。本文使用protégé 4.0构建教育资源本体。在protégé 4.0中建分类和层次,如图1所示。

图1 protégé类图
(4) 本体的类及层次确定以后,要确定本体类之间的属性关系。本体的属性分为数据属性(DataProperty)和对象属性(ObjectProperty)两部分。数据属性的定义域是本体的类,值域是数据类型,例如int型、string型等。对象属性(ObjectProperty)是表示所有个体之间关系的属性。
① 数据属性。为了使网络上分散的教育资源库有统一的语义标注标准,我们对CELTS-31的每一个子元数据项进行分析,抽取出数据属性,如表1所示。
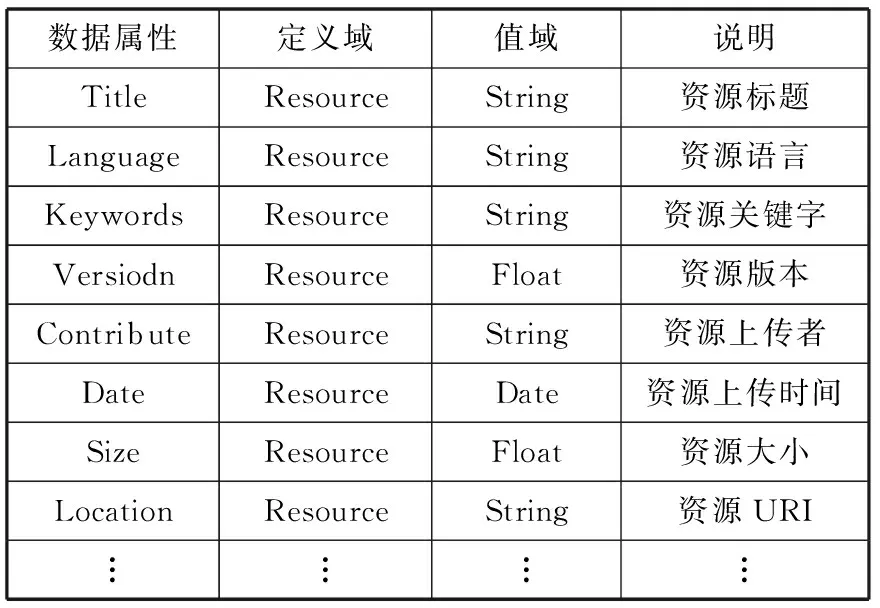
表1 教育资源本体的数据属性
② 对象属性。本文构建的教育资源领域本体的主要对象属性是知识点类的对象属性。由于课程知识点之间具有丰富的语义关系,从而可以通过这些语义关系建立本体属性,并利用这些属性进行本体推理和查询,作为教育资源语义搜索的基础。为了确定知识点类的属性关系,根据课程特点,对知识点间关系进行分析抽象得到如表2所示的对象属性。

表2 教育资源本体的对象属性
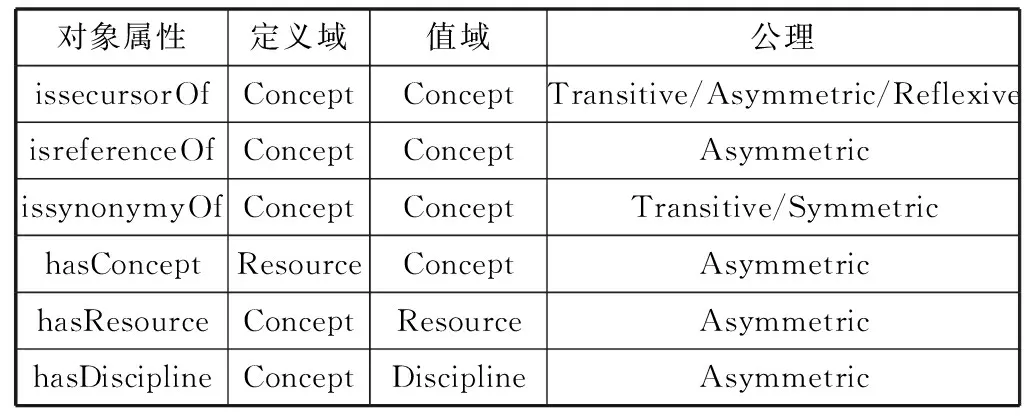
续表2
(5) 属性约束。OWL使用属性约束来描述那些特定类的属性条件,属性的基数约束举例如表3所示。

表3 属性的基数约束
(6) 实例。类和属性建立之后,用实例对本体进行填充。定义本体的类和属性相当于建立描述逻辑知识库中TBox的过程,定义实例相当于建立描述逻辑知识库中的ABox的过程。在protégé中构建实例,如图2所示。

图2 本体实例图(部分)
2 教育资源本体的语义查询推理框架
本文在第1节构建的教育资源领域本体的基础上构建了教育资源领域本体的推理和查询原型系统,系统架构如图3所示。
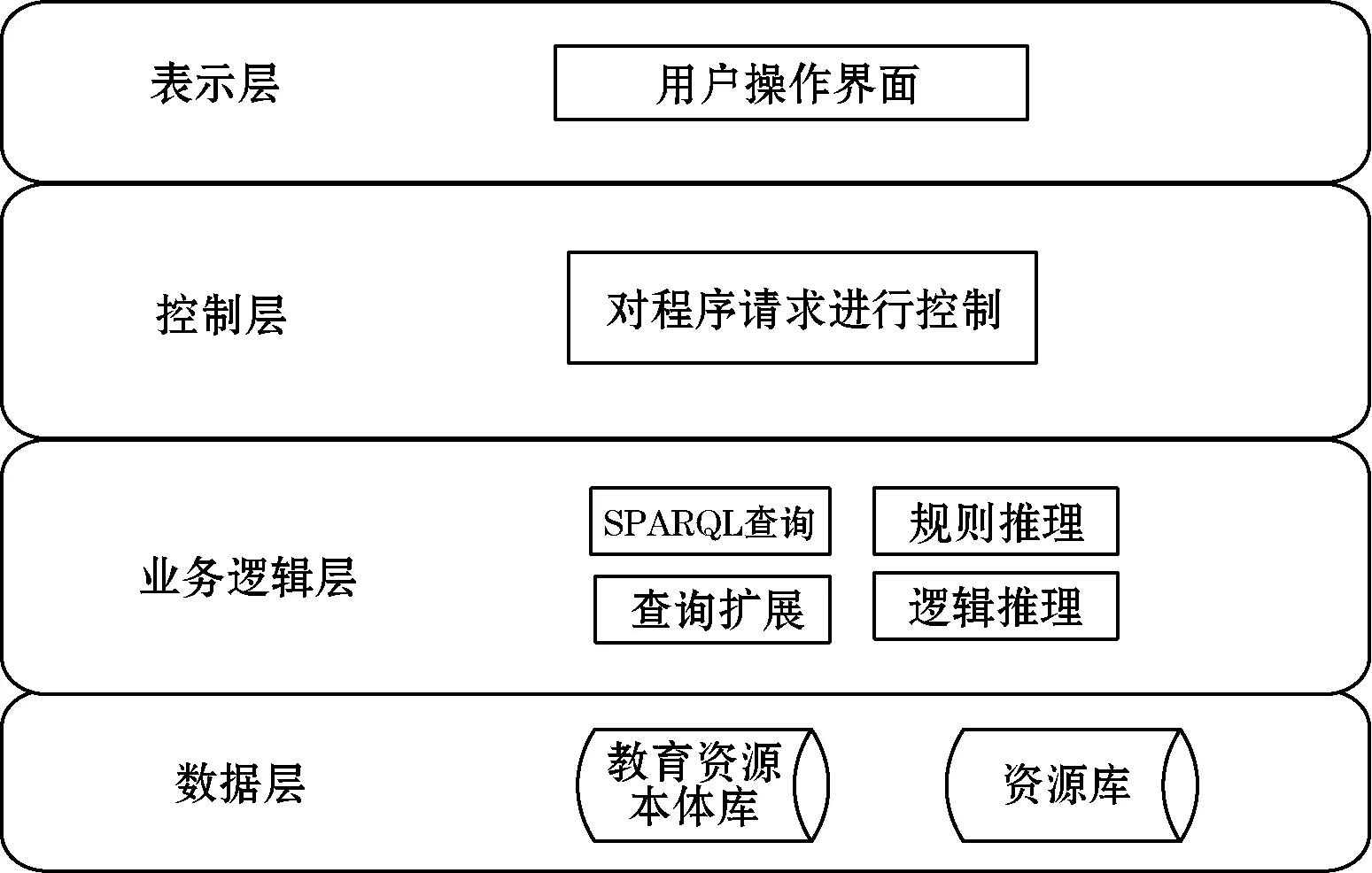
图3 教育资源推理查询系统架构图
数据层是教育资源本体库和资源数据库。业务逻辑层是系统的核心,主要实现的功能有本体逻辑检测、本体规则推理、查询预处理和扩展、本体查询。通过本体逻辑检测模块确定了本体逻辑正确、分类合理、没有冲突,可以进一步提高推理的效率。规则推理模块负责对本体的自定义推理,因为该系统资源的查询是通过查询知识点实现的,所以该系统主要是对知识点类进行推理。根据知识点之间的对象属性可以指定丰富的自定义推理规则,经过推理可以得到查询知识点的相关知识点集作为查询词汇集。推理得到的词汇集里面可能有些与查询知识点关联不大,需要通过查询扩展模块进一步筛选。查询扩展通过把查询知识点与推理得到的词汇集里的知识点经过语义相似度算法计算,再与设定的阈值比较,来确定与知识点关联的查询扩展词汇集,然后可以通过SPARQL查询得到相关的资源。控制层来做用户和业务逻辑层的桥梁,当接到来自表示层的用户请求时,决定由业务逻辑层的哪一个功能模块来完成工作。表示层将返回的结果显示给用户。
2.1逻辑推理模块
本体进行逻辑推理对领域本体的构建至关重要,它优化了本体质量,是本体评价和本体进化的重要手段;同时又是规则推理的重要基础,在逻辑推理之上通过本体公理和自定义规则推理扩充本体的语义关系,从而为实现语义查询和检索服务提供依据。本文采用Pellet推理机对本体进行逻辑推理。通过对教育资源领域本体进行一致性分析,发现了3个概念定义错误和7个实例归类错误,为下一步的规则推理做好了逻辑保证,提高了推理效率。
2.2SPARQL查询模块
Jena查询工厂类(QueryFactory)提供的一些方法可实现SPARQL查询。Query对象在调用create()方法后被返回,Query对象封装了解析RDF模型后的查询。对于简单的查询操作,可以使用提供的execSelect()方法,该方法将返回查询结果集 ResultSet类型数据。通过SPARQL查询可以得到与指定知识点相关的知识点集。
2.3规则推理模块
知识点之间的语义关系可以制定丰富的自定义推理规则,经过推理可以进一步扩展查询知识点集。若a、b表示知识点,p、q表示属性,p具有传递性,p和q互逆:
(1) 传递性规则
(?a p ?b)(?b p ?c)→(?a p ?c)
如果知识点a与b之间具有属性p,知识点b和c之间也具有属性p,由于属性p具有传递性,则可以推理得到知识点a与c之间也具有属性p。
(2) 互逆规则
(?a p ?b)→(?b q ?a)
如果知识点a与b之间具有属性p,由于属性p和q互逆,则可以推理得到知识点b和知识点a之间具有属性q。
本文根据对教育资源领域本体知识点类的属性特征和性质的分析,制定了如表4所示的推理规则。为了节省篇幅,用前缀lr表示http://www.semantic web.org/ontologies/learningres- ource.owl#。

表4 教育资源本体知识点推理规则
2.4查询扩展模块
通过规则推理可以扩展查询关键词的相关词汇,会得到查询知识点的所有相关(同义、蕴含、属于、依赖、兄弟、参考)知识点。但得到的词汇可能有的与查询知识点关系不大,所以在推理得到的结果集上可以采用语义相似度算法来做进一步筛选。用语义相似度公式来计算词汇之间的关联度,并设定阈值,确定查询词汇集。教育资源本体推理查询流程如图4所示。

图4 教育资源本体推理查询流程
Step 1输入查询语句;
Step 2分词处理得到关键知识点集;
Step 3对关键知识点集通过自定义的推理规则推理得到知识点扩展集合S1;
Step 4对S1中的每个知识点关键词,根据相似度计算公式,计算其相似度;
Step 5相似度计算结果与设定的阈值μ进行比较,如果大于阈值μ,就把知识点放到相关知识点集S2;
Step 6对S2中的每一个知识点概念,都对资源本体库进行查询,查询到的资源返回给用户。
3 基于改进相似度算法的语义查询
本文将综合考虑影响语义相似度的3种因素(语义距离、节点密度、节点深度)和知识点间6种关系(同义关系、蕴含关系、依赖关系、参考关系、兄弟关系、平行关系),提出改进的语义相似度计算方法。
3.1语义距离
根据它们的本体层次计算节点的语义距离:距离越近,相似度越高。在节点中存在多条路径的情况下,考虑所有路径的最短路径。知识点c1和c2的基于语义距离的相似度如下:
(1)

3.2节点密度
本体树的密度越高,概念的划分越细,语义相似度越大。由此得到基于节点密度的相似度公式:
(2)
其中,lso(c1,c2)表示节点c1和c2的最近共同祖先节点,degree(lso(c1,c2))表示lso(c1,c2)的度,degree(Tree)表示本体树的度。
3.3节点深度
节点的位置越深,概念划分得越具体,节点表示的概念越相似。基于节点深度的语义相似度公式如下:
(3)
其中,depth(c1)表示概念c1的深度,depth(c2)表示概念c2的深度。depth(lso(c1,c2))表示c1和c2最近共同祖先节点的深度。
3.4关系类型
最常见的关系就是is-a关系,其他关系例如part-of关系、substance-of等关系,都与边的权值相关[8]。连接一个结点和它所有孩子结点的边的权值可能各不相等。在节点间距离相等的情况下,存在其他关系的节点间的相似度较大。基于关系的语义相似度计算公式如下:
Simtype(c1,c2)=type(c1,c2)
(4)
其中,type(c1,c2)表示c1和c2之间的不同关系的权值。通常权值的确定需要领域专家的意见,本文参考了所在学院多名数据结构课程教师意见。根据不同的关系强度,分配权值如下:

(5)
综合以上四个因素,得到语义相似度计算公式,如式(6)所示:
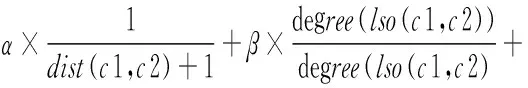
(6)其中,α、β、λ、γ为调节因子,分别表示距离、节点密度、节点深度、节点间不同关系的强度对相似度的影响。经过实验,公式的调节因子取α=0.2、β=0.05、γ=0.15、λ=0.6时效果较好。
4 教育资源推理查询原型系统的设计与实现
4.1系统实现
本文在构建的教育资源领域本体的基础上,使用逻辑推理、规则推理、查询扩展等本体推理及查询关键技术对教育资源领域本体进行推理和查询,最后遵循MVC模式的SSH2框架实现了教育资源领域本体的推理和查询原型系统。系统使用MyEclipse 10开发,本体构建工具采用Protégé 4.0,本体解析和推理工具采用Jena 2.6.4,描述逻辑推理机使用Pellet 2.2,数据库使用MySQL 5.6,Web服务器使用Tomcat 6.0,中文分词工具使用IKAnalyzer。
4.2运行结果分析
本文对网络上以及本地文件共200个不同类型的数据结构课程的教育资源进行语义标注后,形成了资源本体库。判断一个查询系统好坏的指标是查全率和查准率,查全率和查准率公式如式(7)和式(8)所示:

(7)

(8)
用本文介绍的查询方法与传统的关键字查询对200个文本、动画、试卷、课件、视频等资源从查全率和查准率两个方面作了比较,根据四个常用知识点进行查询,得到的查询结果对比如图5和图6所示。相似度计算的阈值分别取0.55、0.6和0.65。
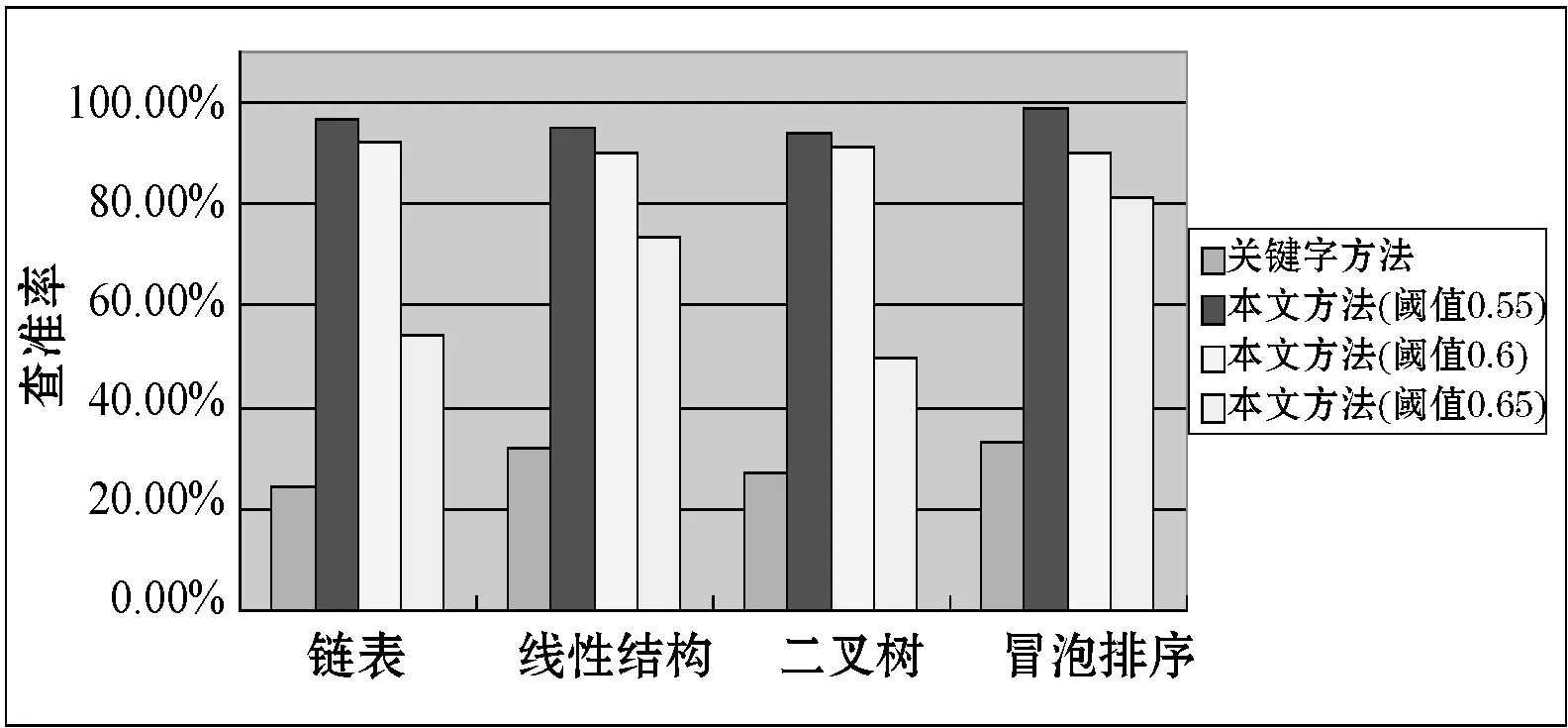
图5 查全率比较图

图6 查准率比较图
图5和图6更直观地表示查全率和查准率。通过查全率和查准率的数据图表可以看出:在查全率方面,使用本文方法查询要高出关键字查询方法很多。因为关键字的查询只是针对标题上是否包含所查询的知识点,没有任何语义关联;而本文的方法由于本体中包含丰富的知识点的各种关系,通过推理和查询扩展等技术就可以获得与查询知识点相关联知识点的资源。比如查询“链表”知识点,那么它的上下位、兄弟、依赖等知识点的资源都会被查询出来,可以方便用户自主学习。而本文方法的查全率和查准率主要取决于阈值μ的设定。当阈值μ设定为0.55的时候查全率是最高的,阈值μ设定为0.65的时候查全率较低。这是由于当阈值μ升高后查出的相关资源会减少。
在查准率方面,两种方法差别不大。本体模型在概念与概念之间的关系基础上进行查询,一些无关的分类信息不会被查询出来,从而提高了系统的查准率;而传统关键字查询的关键字也是资源的知识点,基本上也不会出现查询到的资源与知识点无关的情况。所以这两种方法在查准率方面都表现较好。但是就查询到的资源总量而言,关键字查询要远远低于本体查询。这是因为对于视频、图片、动画等标题上没有所查询知识点而实际内容又与知识点相关的资源,基于关键字的方法是查询不到的。本文在本体中已经对资源进行标注,查询时不是通过标题查询,而是通过对资源的属性,只要资源与包含的知识点做了标注就可以被查询出来。本文方法当阈值取μ为0.65时查准率最高。综合查全率和查准率两个方面分析,并且从实际用户角度出发,阈值取μ为0.6时查询效果较为理想。阈值μ=0.6时的系统运行如图7所示。

图7 系统页面截图
5 结 语
本文从教育资源元数据标准及数据结构课程的知识点中分析、提取语义关联,利用本体构建工具protégé构建了一个数据结构课程的教育资源领域本体。用Pellet对本体进行一致性检测,用Jena对本体进行规则推理,并根据教育资源领域本体知识点关系制定了推理规则,改进了基于语义距离的相似度算法。实现了一个基于本体的推理查询原型系统——数据结构课程教育资源推理查询原型系统,并通过实验比较了传统的关键字查询与本文的语义推理查询的查全率和查准率;同时对不同阈值的相似度算法做了实验,通过实验结果确定了查询阈值。下一步的研究:扩大本体库规模,实现自动标注。本体库规模越大,说明系统的性能越优越;由于基于本体的查询,需要一个庞大的本体库,手工标注信息已不能满足需要。对查询扩展增加用户兴趣模型,把用户真正想学习、感兴趣的知识点与资源的知识点结合起来,实现真正的个性化自主学习。
[1] 韩冬梅,王雯,杭丽娜.基于语义Web的地理领域本体建模及推理研究[J].情报科学,2013,31(8):53-56,160.[2] 李鹏飞,黄冉,姚琴,等.面向医学信息交换的语义查询系统设计[J].中国数字医学,2012,7(12):24-27.
[3] 齐红,张亮亮,李昕.基于玉米本体的语义检索系统[J].计算机工程,2011,37(4),34-36,48.
[4] 许鑫,谷俊,袁丰平,等.面向专利本体的语义检索分析系统的设计与实现[J].图书情报工作,2014,58(9):96-104.
[5] 信息技术标准化技术委员会教育分技术委员会.CELTS-31学习对象元数据标准[EB/OL].http://www.celtsc.edu.cn/content/jxzyl/40288b88391ed5fd0139leddc93d0014.html.
[6] 信息技术标准化技术委员会教育分技术委员会.CELT-41教育资源建设技术规范[EB/OL].http://www.celtsc.edu.cn/content/jxzyl/40288b88391ed5fd01391edbb05d000e.html.
[7]ACM,AIS,IEEE-CS.Computingcurricula2005:Theoverviewreport[EB/OL].http://www.acm.org/education/curric_vols/CC2005-March06Final.pdf.
[8]EklundP,DucrouJ,DauF.ConceptSimilarityandRelatedCategoriesinInformationRetrievalUsingFormalConceptAnalysis[J].InternationalJournalofGeneralSystems,2012,41(8):826-846.
DESIGN AND IMPLEMENTATION OF ONTOLOGY-BASED PROTOTYPE SYSTEM OF EDUCATION RESOURCES REASONING AND QUERY
Feng YaoFeng Xiwei
(SchoolofComputerandCommunicationEngineering,LiaoningShihuaUniversity,Fushun113001,Liaoning,China)
In view of the defects such as poor universality and lack of semantic query in current education resource, we applied the important basic ontology and its reasoning and query technologies of semantic Web to education resources, and implemented an ontology-based prototype system of education resources reasoning and query. We made use of ontology construction method and modelling tools protégé, and took the course of data structure as an example to construct a metadata standard-based education resource domain ontology; We formulated the inference rules of knowledge points for education resources domain ontology, and put forward the modified semantic similarity algorithm; finally we designed and implemented an ontology-based prototype system of education resources reasoning and query. It is verified through experiment that the recall and precision of the system are both higher than the keyword-based query.
Education resource ontologyOntology reasoningOntology queryPrototype system
2015-08-01。辽宁省普通高等学校本科教育教学改革研究项目(UPRP20140914);辽宁省教育科学“十二五”规划立项课题(JG13DB077)。冯瑶,硕士,主研领域:人工智能,语义网。冯锡炜,教授。
TP391
A
10.3969/j.issn.1000-386x.2016.10.004
猜你喜欢
哈哈画报(2021年10期)2021-02-28
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机应用(2016年10期)2017-05-12
制造业自动化(2017年2期)2017-03-20
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
中国管理信息化(2009年10期)2009-06-19
