
Mapreduce下改进Skyline的高效算法*
2016-11-04 09:11刘建邦刘旭敏
传感器与微系统 2016年11期
刘建邦,刘旭敏
(首都师范大学 信息工程学院,北京 100048)
计算与测试
Mapreduce下改进Skyline的高效算法*
刘建邦,刘旭敏
(首都师范大学 信息工程学院,北京 100048)
目前基于MapReduce的Skyline算法随着维度增大会陷入维度灾难,不能高效地解决大数据条件下的计算问题。提出高效算法MRBPS,利用数据间的互不支配特性,通过一个优化轴点对数据集建立区域标识,在Map和Reduce阶段优先比较每个点的区域标识,将多维比较简化为一维比较,提高了计算效率,通过系统实验证明:此算法在大数据量时能够明显提高计算效率,与现有算法相比具有高效性和可靠性。
Skyline查询;MapReduce;大数据
0 引 言
Skyline查询又称Pareto查询,主要目的是找出数据集中所有不被其他点支配的数据点集,广泛应用于多目标决策和数据挖掘等领域,是数据库领域的一个研究热点,同时,随着大数据时代的到来,人们开始关注并行Skyline计算,Mapreduce隐藏了并行计算的细节,如数据的分布式存储,任务的调度,机器间通信和容错处理,具有良好的容错性和可靠性,非常适用于大数据的处理。目前MapReduce下的Skyline算法有MR-BNL算法,MR-SFS算法,MR-Bitmap算法等。
但是这些算法都有一个缺点,即随着维度增加,都会出现维度灾难的现象,通过研究,维度灾难是因为多维度比较导致时间开销急剧增大所致,本文提出MRBPS算法,通过优化轴点对数据集增加一个位串的方法,在计算时将多维比较简化为一维比较,减少比较次数,提高计算效率,实验证明:本文提出的算法与MR-BNL算法和MR-SFS算法相比具有高效性和可靠性。
1 Skyline算法
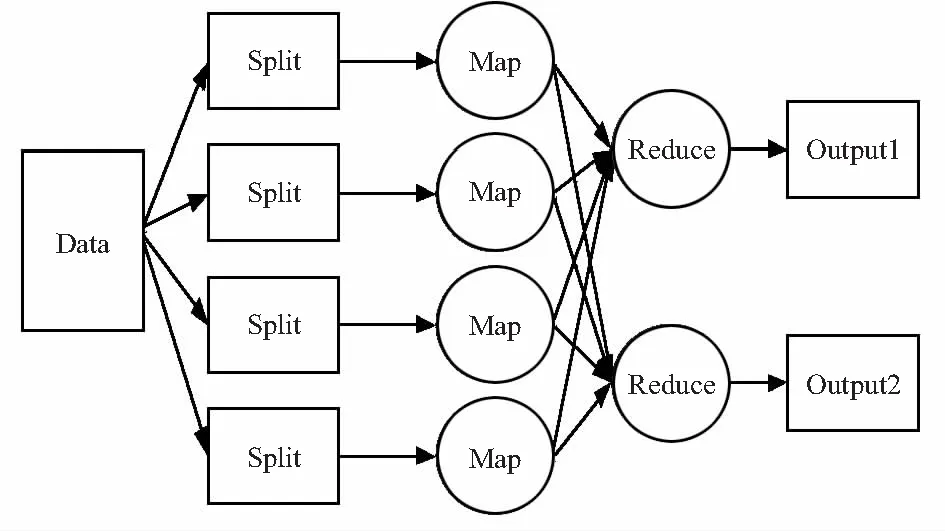
定义1 支配。数据集中的两个点p和q,当任意i∈(1,d),pi≤qi,且至少存在一个i,使得pi 定义2 Skyline集。若p点不被数据集中任何点支配,就说p点是Skyline点,所有这样的点构成Skyline集,在这个集合中,所有的点都是互相不支配的。 传统的Skyline算法都是集中式算法,如块嵌套循环(block-nested-loops,BNL)算法[1],分治(divide and conquer,D&C)算法[1],排序过滤(sort-filter-skyline,SFS)算法[2],最近邻(nearest-neighbor,NN)算法[3],分支界限(branch and bound skyline,BBS)算法[4],排序限定算法(sort and limit skyline algorithm,SaLSA)[5]等。其中BBS算法在维数较低(小于六维)时,是效率最高的算法。 由于数据量的增大以及数据存储的物理源相距较远时,传统集中式算法不能满足计算要求,并行Skyline计算成为人们关注的热点。Balke等人提出了Web信息系统上的分布式Skyline计算[6],通过对每一维数据排序,优先比较可能性较大的点,节约了开销,效率较高。文献[7]提出了基于数据划分的并行分布式Skyline算法,对划分的各组进行并行计算。 MapReduce[8]最早由谷歌公司于2004年提出,是一种并行编程框架,简单来说就是“任务的分解与结果的汇总”,它将任务在Map阶段分为一个个子任务,然后用多台机器并行处理键值对(key,value)形式的数据,最后再将结果在Reduce阶段合并,从而得出最终结果。图1是MapReduce的工作示意图。 图1 MapReduce工作示意图Fig 1 MapReduce framework 目前在MapReduce框架下对Skyline计算的研究比较有限,主要有MR-BNL算法[9,10],MR-SFS算法[9,10]和MR-Bitmap算法[9,10]。MR-BNL算法通过对数据分块,首先计算出部分数据集的Skyline结果,然后在对部分Skyline结果进行合并计算,得出最终Skyline集合。MR-SFS算法对数据增加了一个预排序环节,可以看做MR-BNL算法的改进。MR-Bitmap算法首先对每一个数据建立Bitmap,第二阶段再进行Skyline计算,当Bitmap较小时算法效率较高,但当Bitmap太大无法放入内存时,算法性能下降显著,因此MR-Bitmap算法应用较少。随着维度增大,MR-BNL算法和MR-SFS算法会陷入维度灾难的陷阱中,开销较高。 3.1 算法基本思想 MR-BNL算法和MR-SFS算法在大数据情况下,随着维度增加,点和点之间的比较次数增加太快,需要花费很多开销,导致两种算法效果并不好。目前的改进算法都是采用过滤的方法排除部分非Skyline点,如文献[11]和文献[12]。本文采用一种新颖的方法,利用数据之间的互不支配特性来提高MapReduce下Skyline计算的效率,用一维比较确定两个数据的互不支配关系,减少比较次数,从而提高计算效率。 文献[13]讨论了数据集中最大化互不支配对数的轴点的计算方法Slectpivotpoint算法,为了尽可能增加划分后数据的互不支配对数,本文采用效率较高的满足平衡条件(各维度值相差最小)的Skyline点作为区域划分的轴点。Slectpivotpoint算法步骤:初始化BP点为第一个点,cur=2,minscore=score(BP);While(cur≤n),如果BP支配S[cur],cur=cur+1;如果S[cur]支配BP,BP=S[cur],minscore=score(BP),cur=2;如果BP和S[cur]互不支配,curscore=score(S[cur]),当curscore 3.2 算法流程 MapReduce在Map阶段将数据划分成64 MB的小块,这样的数据可以直接放入内存中处理,本文第二阶段计算Skyline点时采用文献[18]提出的内存算法sskyline进行计算,比MR-BNL算法和MR-SFS算法所采用的外存算法效率要高。sskyline算法步骤如下: 1)head=1,tail=n,While(head 2)While(i≤tail),if S[head]支配S[i],S[i]=S[tail],tail=tail-1;if S[i]支配S[head],S[head]=S[i],S[i]=S[tail],tail=tail-1,i=head+1;如果S[head]和S[i]互相不支配,i=i+1; 3)内循环结束时,当head 4)外循环结束时,输出S[1,……,head],即为Skyline集。 MRBPS算法的步骤共分两个阶段的MapReduce计算,第一阶段先利用横向划分在第一阶段并行运行Slectpivotpoint算法得到部分localBP点,在MapReduce中是用(N,localBP)这样的键值对来处理的,N代表每一个子节点的编号。然后通过Reduce得到最终的BP点,存放在Distri-butedCache中等待第二阶段调用(算法1的第1~8行)。第二阶段利用BP点对每个点进行区域标识,为每个数据增加一个长度为d的位串D(算法1的第12行),具体实现方法为:数据集中每一个点p,i∈(1,d),若pi 算法1 MRBPS算法 Input:Dataset S Output:Skyline(S) Description: 1.Prepare Job 2.Map Task 3.compute localBP using Slectpivotpoint 4.output (N,localBP) 5. 6.Reduce Task 7.compute globalBP using Slectpivotpoint 8.output globalBP in Distributed Cache 9. 10.Processing Job 11.Map Task 12.compute regionID by BP 13.compute localSkyline with precompare using sskyline 14.output(N,localSkyline) 15. 16.Reduce Task 17.compute globalSkyline with precompare using sskyline 18.output(pj&BP,null) 4.1 实验环境 本文实验采用五台机器,配置相同:处理器Intel(R)Core(TM)i3-3220,CPU @3.3 GHz,4 GB内存,500 G硬盘;操作系统windows 7;Hadoop版本为0.20.2,在JDK1.7环境下编程实现。 实验数据集采用文献[1]的方法,每维值域在[0,1],数据集大小为200~1 000 K,默认为400 K。默认维度为4维。分为相关分布、独立分布、反相关分布三种。独立分布的数据每一维都是相互独立的,相关分布的数据在某一维度较好则其他维度也较好,反相关分布的数据在某一维度较好而其他维度较差。实验指标为不同维度下和不同数据量下算法的运行时间。图2显示了二维下100个点的相关分布、独立分布、反相关分布情况。 图2 三种数据集分布Fig 2 Distribution of three kinds of dataset 从图2可以看出,相关数据集Skyline点结果比较小,独立分布数据集次之,反相关数据集Skyline点结果最多。故只选取独立和反相关数据集进行实验比较。 4.2 实验结果与分析 4.2.1 Skyline查询性能随数据维度变化情况 图3显示了维度变化时,运行三种算法耗费的时间情况,从独立分布的结果可以看出,随着维度的增大,三种算法耗费的时间都有所增加,这是因为随着维度的增大,互不支配的点增多,运算时间也会增加,而MRBPS算法因为在互不支配点时节约了比较次数,时间效率上要优于前两种算法,从反相关分布的结果可以看出,当维度增大到四维以上时,MR-SFS算法和MR-BNL算法运行时间都出现急剧的增大,产生了“维度灾难”现象,而MRBPS算法因为需要较少的比较次数,“维度灾难”影响较小。 图3 不同维度下三种算法运行时间Fig 3 Runtime of three kinds of algorithms with different dimensions 4.2.2 Skyline查询性能随数据量变化情况 从图4可以看出,随着数据量的增大,三种算法运行时间都增加,MR-SFS算法和MR-BNL算法相差不多,这是因为MR-SFS算法可以看做是MR-BNL算法的改进,而前一种算法需要一个预排序过程,比较耗费时间。MRBPS算法比前两种算法都要快,这是因为使用轴点划分区域后,在Map和Reduce阶段将多维比较简化为一维比较,减少了比较次数,节约了运算时间。 图4 不同数据量下三种算法运行时间Fig 4 Runtime of three algorithms of different data quatities 本文对大量数据下,现有的基于MapReduce的Skyline算法随着维度增加陷入维度灾难,造成计算效率低的问题,提出MRBPS算法,利用轴点划分区域,在MapReduce计算时将多维比较简化为一维比较,减少比较次数,经过系统实验验证,本文提出的算法具有高效性和可靠性。 [1] Borzsonyi S,Kossmann D,Stocker K.The skyline operator[C]∥Proceedings of 2001 the 17th International Conference on Data Engineering(ICDE),Washington DC,USA:IEEE Computer Society,2001:421-430. [2] Chomicki J,Godfrey P,Gryz J,et al.Skyline with presor-ting[C]∥Proceedings of 2003 the 19th International Conference on Data Engineering(ICDE),Los Alamitos,CA,USA,Washington DC,USA:IEEE Computer Society,2003:717-719. [3] Kossmann D,Ramsak F,Rost S.Shooting stars in the sky:An online algorithm for Skyline queries[C]∥Proceedings of 2002 the 28th International Conference on Very Large Data Bases(VLDB),Hong Kong,China,San Francisco,CA,USA:Morgan Kaufmann,2002:275-286. [4] Papadias D,Tao Y,Fu G,et,al.Progressive computation in database systems[J].ACM Transactions on Database Systems,2005,30(1):41-28. [5] Bartolini I,Ciaccia P,Patella M.Efficient sort-based Skyline evaluation[J].ACM Transactions on Database Systems,2008,33(4):31-79. [6] Balke W T,Guntzer U,Zheng J X.Efficient distributed skylining for Web information systems[C]∥Proceedings of 2004 the 9th International Conference on Extending Data-base Technology(EDBT),Heraklion,Crete,Greece:Springer,2004:256-273. [7] Cui Bin,Lu Hua,Xu Quanqing,et al.Parallel distributed processing of constrained Skyline queries by filtering[C]∥Procee-dings of 2008 the 24th International Conference on Data Engineering,ICDE’08,Cancun,Mexico,Washington,DC,USA:IEEE Computer Society,2008:546-555. [8] Dean J,Ghemawat S.MapReduce:Simplified data processing on large cluster[C]∥Proceedings of 2004 the 6th Conference on Operating Systems Design &Implementation(OSDI),Berkeley,CA,USA:USENIX Association,2004:137-150. [9] Zhang Boliang,Zhou Shuigeng,Guan Jihong.Adapting Skyline computation to the MapReduce framework:Algorithms and experiments[C]∥Proceedings of DASFAA Workshops,Hong Kong,China:Springer,2011:403-414. [10] 张波良,周水庚,关佶红.Mapreduce框架下的Skyline计算[J].计算机科学与探索,2011,5(5):385-397. [11] 丁琳琳,信俊昌,王国仁,等.基于Map-Reduce的海量数据高效Skyline查询处理[J].计算机学报,2011,34(10):1785-1796. [12] 李文俊,张大方,李 玮.基于MapReduce的预处理高效Skyline算法[J].计算机应用与软件,2015,32(3):243-246. [13] Lee J,Hwang S.Scalable Skyline computation using a balanced pivot selection technique[J].Information Systems,2014,39(1)1-21. [14] Park S,Kim T,Park J,et al.Parallel Skyline on multicore architectures[C]∥Proceedings of 2009 the 25th International Con-ference on Data Engineering,ICDE’09,Shanghai:IEEE,2009:760-771. 刘建邦(1988-),山东潍坊人,硕士,主要研究方向为数据挖掘,大数据处理。 Improved efficient skyline algorithm based on Mapreduce* LIU Jian-bang,LIU Xu-min (College of Information Engineering,Capital Normal University,Beijing 100048,China) Existing Mapreduce-based Skyline algorithms is inefficient facing large scale database,to solve this problem,an MapReduce with balanced point skyline(MRBPS)algorithm is proposed,using incomparability of dataset,map points to different regions with a computed balanced point,simplified multi-dimensional comparison to one dimensional comparison,reduce number of tests in Map and Reduce Task.Systematic experiments prove that the algorithm is efficient in large scale database,and more efficient and reliable than existing algorithms. Skyline query;MapReduce;big data 10.13873/J.1000—9787(2016)11—0116—04 2016—01—22 国家自然科学基金资助项目(61272029) TP 311 A 1000—9787(2016)11—0116—042 Mapreduce下Skyline算法
3 MRBPS算法
4 实验评估



5 结束语
猜你喜欢
当代陕西(2022年4期)2022-04-19北京大学学报(自然科学版)(2021年3期)2021-07-16意林(2021年9期)2021-05-28东北师大学报(自然科学版)(2021年1期)2021-03-27电脑爱好者(2020年19期)2020-10-20电子制作(2019年13期)2020-01-14中华诗词(2019年7期)2019-11-25时代英语·高一(2019年1期)2019-03-13自动化学报(2017年2期)2017-04-04Coco薇(2016年8期)2016-10-09
