
基于KII算法的公务卡用户分类模式研究
2016-10-31 23:55吴素云
中国总会计师 2016年7期
关键词:公务卡
吴素云
摘要:本文根据行政企事业单位工作人员办公的特点,借鉴相关银行系统理论与实践,对聚类方法中的经典K-means算法进行了改进,并应用到公务卡用户分类模式中,实现对公务卡用户的价值及行为特征的分类。对KII算法进行了仿真,实验结果表明该算法的准确率等方面较经典K-means算法有所提升。本文阐述了公务卡用户分类时如何选择分类变量、如何进行数据的预处理的全过程,也为银行进行公务卡用户分类提供了方法上的指导。
关键词:KII算法 公务卡 用户分类
借鉴国内外相关的理论研究,基于数据挖掘技术的公务卡用户分类研究很多都是基于经典K-means算法进行的,这主要是因为相对大部分聚类算法而言,K-means算法的时空复杂度相对较小,性能相对较好,同时很多挖掘工具都提供了内置的K-means聚类模型,如SPSS Clementine,DB Miner等,可直接使用,非常方便。但由于经典K-means算法本身存在的一些固有缺陷(如参数人为指定,初始聚类中心随机生成等),会影响公务卡用户分类结果的可靠性。因此本文将克服了K-means四大缺陷的算法——启发式初始化的改进K-means算法(KII算法)应用到公务卡用户分类研究中,建立基于KII算法的公务卡用户分类模式。
一、公务卡用户分类的维度分析
(一)维度分析的依据
维度是人们观察事物的角度,是有关于目标问题的属性的集合。在不同的应用背景和应用目的下,维度的选择和构成也不同。在公务卡用户分类问题中,银行分类的主要目的是识别用户的行为特征,尤其是用户中高价值用户的特征,以便对具有相似行为特征的高价值用户群开展集中的针对性营销和服务,因此用户的价值特征以及行为特征对银行而言都是非常感兴趣的模式,都可以作为公务卡用户分类的维度。对于用户的基本特征以及账户特征,由于它们能够对公务卡用户的价值及行为特征产生影响,因而银行对这类特征也很关心,所以它们也应该列为公务卡用户分类的维度。因此下文将从个人基本特征、用户持卡行为、用户价值、用户账户特征四个维度进行综合分析,建立一个完整的用户分类指标体系,以提供用户分类变量的选取范围。当分类指标体系确定后,可根据挖掘目标的需要,选取合适的分类变量。
(二)公务卡用户分类指标体系构建
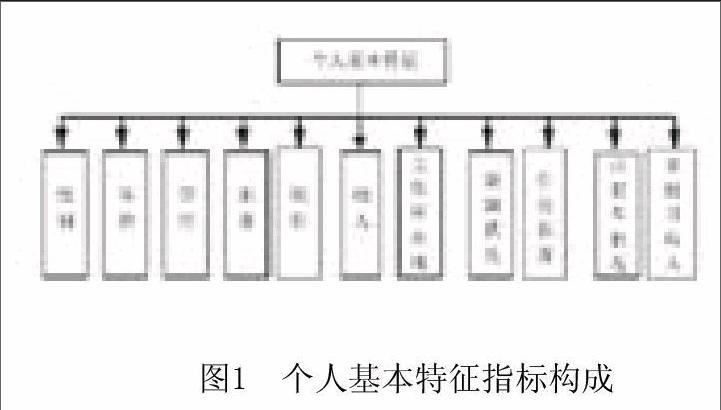
1.个人基本特征指标
公务卡用户个人基本特征会对行为和价值产生影响,在对用户进行分类时应该加入这类信息。本文从人口统计特征和社会特征两个方面提取指标,其中包括用户的性别、年龄、学历、职业、职位、所在地都市化程度、婚姻状况、住房状况、自有车状况、个人月收入、供养人口数、家庭月收入等指标。如图1所示。
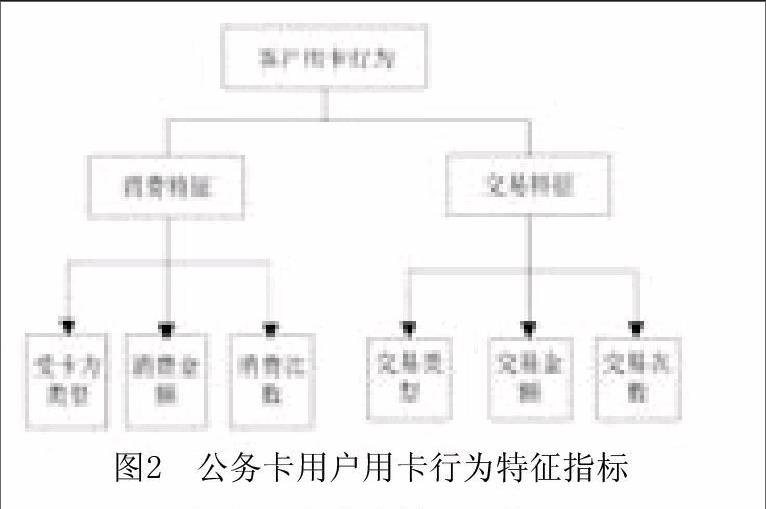
2.用户用卡行为特征指标
用户用卡行为主要由购买、还款、取现等行为组成,可以从消费特征、交易特征两个角度分析提取指标。消费特征反映用户对特定商品类型的偏爱,包含的指标有受卡方类型、受卡方消费金额、受卡方对应消费次数,交易特征包括交易类型、交易金额、交易次数等指标。如图2所示。
部分指标说明为,第一,受卡方类型:银行分配给特别商户的代码一般进行分类,本文为了方便在宏观上发现用户的消费特征,将受卡方按消费类别分为五类,分别为①商场、超市等零售业,②餐饮酒店类,③住宿类,④交通类,⑤网上消费。第二,交易类型:指消费、取现、透支、还款等交易代码。
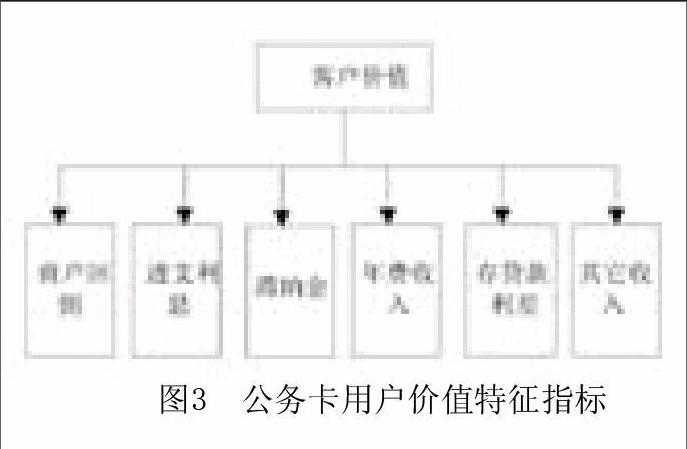
3.公务卡用户价值特征指标
针对公务卡用户的价值,有很多不同的定义和评价方法。其中比较有影响力的价值分类方法是将用户的价值分为当前价值和潜在价值。这虽然在理论上很完善,但实际操作却很难实现。因为用户的潜在价值量化非常困难,去银行搜集与之相关的数据也不容易得到,所以本文仅考虑用户的当前价值。当前价值是公务卡用户的行为所产生的,所以也可理解为行为价值。可以选取商户回佣、透支利息、滞纳金收益、年费收入、存贷款利差、其他收入等指标作为用户价值的主要指标。
从图3可以看到,商户回佣对应的是公务卡用户的购买行为,是用户购买活动所带来的价值,而滞纳金分别对应着逾期产生的罚金,透支利息是免息期外产生的费用,受透支时间和金额影响,存贷款利差是公务卡账面金额带来的收益。
4.公务卡用户账户特征指标
公务卡账户特征包括卡账户的基本特征和信用特征,卡账户基本特征包括持卡类型、开卡时间、账面余额、透支金额等指标,信用特征包括信用额度、信用等级、逾期等级、违约情况等指标。如图4所示。
5.用户分类指标体系构成
公务卡个人信息:性别、年龄、学历、婚姻状况、住房状况、职业、职位、个人月收入、供养人口数、家庭月收入。用卡特征:受卡方、受卡方对应消费金额、受卡方对应消费次数、月均刷卡次数、月均消费金额、月均取现次数、月均还款次数、月均取现额、月均还款额。价值特征:商户回佣、透支利息、滞纳金收益、存贷款利差、其他收入。账户特征:持卡类型、开卡时间、账面余额、信用额度、透支额度、信用等级、逾期等级、违约等级。
二、公务卡用户分类变量的选取
分类变量的选取范围是上节中介绍的用户分类指标体系,但具体选取时,主要是根据公务卡用户的分类目标来进行。以基于用户消费特征的用户分类为例,可选择分类变量表。详见表1。
由于人工或技术的问题,抽取出来的数据不可避免地存在着数据缺失、冗余、噪声以及不一致等问题,这些数据直接用于数据挖掘,可能导致挖掘过程十分低效,甚至结果有误。因此在进行数据挖掘前需要先进行数据预处理,以提高数据挖掘的精度和性能。数据预处理过程主要有以下几个步骤。
(一)缺失值处理
对于缺失问题,一般的处理方法有:忽略记录,人工填写缺失值,用属性的均值填补缺失值,用给定记录所属类的样本增值填补缺失值,用默认值填补缺失值,用最大可能性的值填补缺失值。具体可以采用以下方法进行处理:首先将缺失值在60%以上的指标删除,对于离散性指标用众数对数据项进行填充,连续型指标用均值对缺失项进行填充,然后采用标准差检验法甄别异常数据,并对异常数据进行剔除。
(二)噪声消除
数据录入过程中,人为的错误或是设备的故障等原因都会导致产生噪声数据。平滑噪声的方法很多,一般可采用分箱、聚类、回归或者是计算机与人工检查相结合等技术。
(三)数据不一致处理
来自数据仓库或数据集市的数据也可能会存在数据结构的不一致、标签的不一致、数据值的不一致等问题,需要进行纠正,使数据一致化,方便进行挖掘。
(四)属性转换
当指标中存在分类数据需要进行量化,将其转换成数值形式,方便进行统计和计算。
三、基于KII算法的用户分类
综上所述,用KII算法进行公务卡用户分类的处理过程见图5。
首先进行数据的导入。数据导入主要指从数据仓库中或是原始数据库中获得的公务卡用户的相关数据,然后根据分类目标的需要,选择能够反映公务卡用户特征的分类变量,并抽取相应的数据,对它们进行数据预处理。将处理后的数据进行组合,得到一张宽表,该表中的记录就是聚类算法处理的数据对象。将预处理后的数据集分成两部分,一部分作为训练集,一部分作为测试集。将训练集作为参数,运用KII算法进行聚类分析,并对聚类的结果用Huberts 进行验证结果是否满足预先设定的阈值,如果不是,则调整分类变量,直到Huberts 结果满足要求为止。将获得的聚类中心用于对测试集进行划分,并输出聚类的结果。本文构建了一个公务卡用户的分类模式,详细介绍了用户分类指标的提取,数据的预处理,以及如何运用KII聚类方法进行用户分类的过程。
四、总结与展望
本文以国内某家商业银行公务卡业务的实际需求为研究背景,在研究数据挖掘发展相关理论和技术的基础上,提出一种基于数据挖掘技术的公务卡用户分类模式。本文在比较了数据挖掘中各种聚类算法后,最终决定采用K-means聚类方法作为模型的关键方法。由于K-means算法本身存在诸多缺陷,直接应用到模型中,会降低模型的准确性和有效性。因此,本文针对这些不足进行了改进,提出了一种启发式初始化的改进K-means算法,并将它应用到公务卡用户分类模式中,实现对用户的价值及行为特征的分类。本文对聚类方法中的经典K-means算法进行了改进。针对K-means算法对初始聚类中心的依赖性,提出一种具有启发式的选取初始化聚类中心的方法,在进行K-means前找到合适的初始中心,避免由于初始中心选取不当而导致K-means聚类错误的问题。对KII算法进行了仿真,实验结果表明该算法的准确率、鲁棒性等方面较经典K-means算法有所提升。提出一种基于KII算法的有关公务卡用户分类的应用模式,该模式说明了进行公务卡用户分类时如何选择分类变量、如何进行数据的预处理以及如何应用KII聚类算法的全过程,为银行进行公务卡用户分类提供了方法上的指导。
参考文献:
[1]娄洪.着力推进公务卡改革的深化与发展[J].中国金融,2009(20).
[2]陈建宁.预算单位推行公务卡结算制度的探析[J].会计之友(上旬刊),2009(9).
[3]谭明,申凤云.湖南省公务卡发展现状调查与对策建议[J].金融会计,2009(5).
[4]周静莉.关于预算单位推行公务卡结算的若干思考[J].当代经济,2009(8).
[5]陈建华.南京市公务卡应用情况调查与建议[J].金融电子化,2008(12).
[6]李项南.公务卡在财政国库管理制度改革中的应用[J].中外企业家,2008(11).
[7]朱久霞.积极推进公务卡的使用提高预算资金的使用效率[J].会计之友(下旬刊),2008(5).
[8]顾海英.推广公务卡制度引入国库集中支付的探讨[J].财会研究,2008(5).
[9]孙兴全,苗慧凯,赵兴罗.从公务卡制度看公务支出的监督[J].财政监督,2007(19).
[10]舒泰峰,徐艳.公务卡能否卡住腐败[J].浙江人大,2007(9).
(作者单位:广州市残疾人安养院)
猜你喜欢
魅力中国(2016年39期)2017-02-09
中国经贸(2016年22期)2017-01-16
中国经贸(2016年20期)2016-12-20
商业会计(2016年18期)2016-11-10
现代交际(2016年10期)2016-06-17
商业会计(2016年3期)2016-03-11
