
3D-HEVC深度图像帧内编码单元划分快速算法
2016-10-29 06:31:06张洪彬伏长虹苏卫民陈锐霖萧允治
电子与信息学报 2016年10期
张洪彬 伏长虹 苏卫民 陈锐霖 萧允治
3D-HEVC深度图像帧内编码单元划分快速算法
张洪彬①②伏长虹*①苏卫民①陈锐霖②萧允治②
①(南京理工大学电子工程与光电技术学院 南京 210094)②(香港理工大学电子资讯工程学系 香港 999077)
针对3维高性能视频编码(3D-HEVC)中深度图像帧内编码单元(Coding Unit, CU)划分复杂度高的问题,该文提出一种基于角点和彩色图像的自适应快速CU划分算法。首先利用角点算子,并根据量化参数选取一定数目的角点,以此进行CU的预划分;然后联合彩色图像的CU划分对预划分的CU深度级进行调整;最后依据调整后的CU深度级,缩小当前CU的深度级范围。实验结果表明,与原始3D-HEVC的算法相比,该文所提算法平均减少了约63%的编码时间;与只基于彩色图像的算法相比,该文的算法减少了约13%的编码时间,同时降低了约3%的平均比特率,有效地提高了编码效率。
3维高性能视频编码;深度图像;帧内编码;编码单元;角点检测;
1 引言
多视点加深度[1](Multi-view Video plus Depth, MVD)包含若干个视点的彩色和深度视频。MVD能够利用基于深度图像渲染技术在低码率下实现自由视点视频,近年来成为3D视频的研究热点[2,3]。联合视频专家组在高性能视频编码(High Efficient Video Coding, HEVC)的基础上,增加了深度图像编码技术,形成了3维高性能视频编码标准3D-HEVC[4]。3D-HEVC引入的深度帧内编码新技术[4],虽然提高了压缩效率,但编码复杂度也随之急剧增加,因此提高深度图像帧内编码速度成为MVD的研究重点。深度图像帧内编码复杂度高有以下两个原因:帧内模式数目多,包括HEVC帧内模式、帧内跳过模式和深度模型模式(Depth Modelling Mode, DMM);沿用了HEVC四叉树编码结构[5],编码单元(Coding Unit, CU)数目多。因此,现有的算法都基于减少候选帧内模式数目或者减少候选CU数目。
对于减少候选帧内模式数目的算法,文献[6]通过在双像素域上粗略地搜索DMM,有效地减少了候选DMM的数目;文献[7]发现DMM并不适用于深度图的平滑区域,在此基础上,文献[8]发现DMM也不适用包含水平和垂直边界的CU,因此他们各自提出了相应的DMM跳过算法。由于以上方法仍需要遍历计算所有CU的率失真(Rate-Distortion, RD)代价,所以这些方法对编码速度的提高十分有限。
在3D-HEVC中,CU是基本编码和处理单元,其大小范围为64×64到8×8,对应的划分深度为0到3。首先,待编码帧划分为许多最大编码单元 (Largest Coding Unit, LCU);然后,3D-HEVC测试模型(3D-HEVC Test Model, HTM) 按照递归的方式将每级CU划分为4个子CU,直至最小的CU (Smallest Coding Unit, SCU)。LCU的划分过程需要计算85次CU的RD代价,且每级CU要计算几十到几百次的RD代价来决定最优帧内模式。
对于减少候选CU数目的快速算法,文献[9-12]根据时空相关性,提出了基于HEVC的CU划分快速算法,但是这些算法并不适用于深度图像的CU划分;文献[13]通过判断帧内跳过模式的RD代价和编码块的方差值跳过子编码单元,然而该算法很难自适应地选择合适的阈值,造成该算法的自适应性差,对编码速度的提高有限;文献[14]依据深度图像和彩色图像存在信息冗余,利用彩色图像的CU划分缩小深度图像CU划分的深度范围,该方法没有考虑深度图像和彩色图像的失配问题,从而导致深度图像丢失部分细节,严重降低了虚拟视角的图像质量。
针对文献[13,14]存在自适应能力差、重建虚拟视角图像质量差以及编码效率低等方面的不足,本文将深度图像的空间特性和彩色图像的CU划分相结合,提出了一种基于角点和彩色图像的深度图像帧内编码单元划分的快速算法。该方法利用深度图像具有特殊的空间特性,提出利用角点特征对编码块进行预分类,同时考虑深度和彩色的相关性,利色彩图像的块划分对预分类结果进行修正,最终依据分类结果选择不同的CU深度级。此外,本文还定量地分析了不同角点算子对编码性能和效率的影响,并提出了一种自适应选择角点的方法来提高算法自适应性。
2 基于角点和彩色图像的深度图像CU快速划分算法
3D-HEVC包含两类帧内模式,分别为:单一方向型模式,包括DMM和角度模式(Angular);平滑型帧内模式,包含Planar, DC和帧内跳过模式。前者用于预测单一的纹理方向,而后者用于预测平滑区域。在HTM的CU划分过程中,如果最优帧内模式可以很好地预测CU,意味着更小尺寸的CU并不能提高当前块的重建质量,反而会增加模式编码的比特开销,所以该CU不必进一步地划分。文献[21]提出的方差等特征并不能可靠地预测CU的尺寸,例如当编码块包含单一纹理或多纹理时,其方差值都很大;然而单一方向型帧内模式可以准确地预测单一纹理编码块,无需划分为更小的CU尺寸。对于包含多纹理方向的CU,单一方向型的预测模式并不能很好地对CU划分进行预测,因此本文提出利用多方向的角点特征来预测CU的尺寸。角点指的是具有两个主方向的兴趣点,该特征可以区分单一纹理方向和多纹理编码块。
2.1基于角点的CU预划分
图1(a)为序列Balloons的角点分布图,其中白色圆点表示角点。由图1可知,深度图像的角点大多分布在不规则的边缘,其邻域有不止一个方向上的变化。对于包含角点的CU,两类帧内模式都不适用于预测多方向信息,导致深度边缘的失真。因此,包含角点的CU一般采用较小的CU尺寸编码,每个子CU可以采用不同的帧内模式,以增强对多方向的预测效果;相反没有包含角点的CU,其像素信息单一,所有尺寸CU的预测效果都很好,采用较大的CU尺寸可以减少CU编码的比特开销。因此,本文利用角点对深度CU进行预划分。划分原则为:如果CU包含一个或多个角点,则该CU进一步划分为4个子CU,逐级向下,直至SCU。CU按预划分深度分为4类:I-0(64×64), II-1(32×32), III-2(16×16)和IV-3(8×8)。图2为预划分的示例图,对于图2(a)中仅含有一个角点的LCU,按上述预划分原则得到预划分深度级,并按如图2(b)所示,以8×8为单元存储预划分深度级。图1(b)为基于图1(a)中角点的预划分结果。图1(d)为HTM方法获得的CU划分图。对比图1(b)和图1(d)可知,对于含有角点的区域,基于角点的预划分和HTM的划分都采用了较小尺寸的CU,而对于不包含角点的区域,两种方法都选择较大的CU。表1为序列Balloons序列的最优分割深度级和预划分深度级的分布表。表1证实了上述假设,大部分的I-0和II-1的编码块会选择深度级0和1的CU,而III-2和IV-3的编码块大多采用较大深度级。然而,图1(b)的CU划分和最优的CU划分并不相同,因此需要对基于角点的预划分结果进行修正。

图1 角点的分布图以及CU的划分示意图
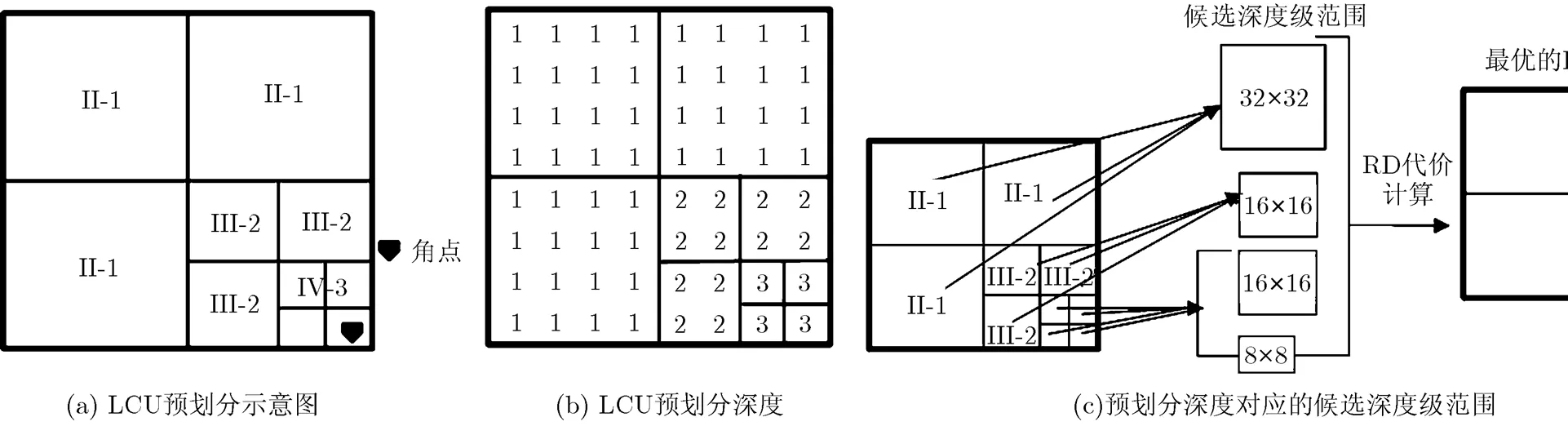
图2 LCU的预划分及对应的候选深度级示例图
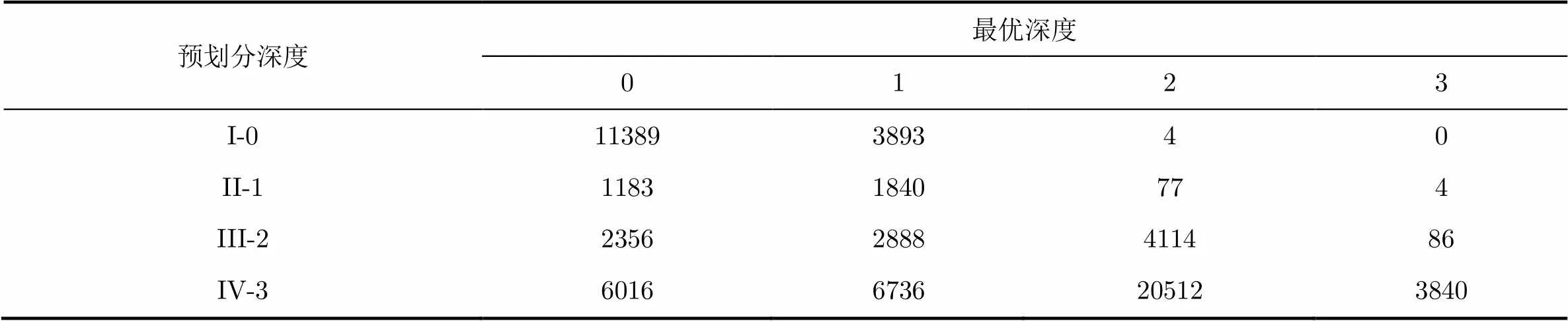
表1最优深度级和预划分深度级的分布表
2.2 基于彩色图像对预划分修正
深度图像的失真评价由合成视角和自身失真两部分组成,而合成视角失真和彩色图像的失真有很大关系[15]。具体表现为:彩色图像变化小的区域对深度的失真不敏感,即深图像失真对合成视角的图像质量影响较小;反之亦然。图1(c)为彩色图像的最优CU划分,在像素值变化小的区域,彩色图像选择较大的CU,反之亦然。文献[14]对彩色和深度视频的CU划分深度进行了详细的分析,并得到彩色图像和深度图像的CU划分相关性强的结论,感兴趣的读者可参考文献[14]。因此,本文利用彩色图像的CU划分的深度对预划分的深度进行调整,具体如表2所示。
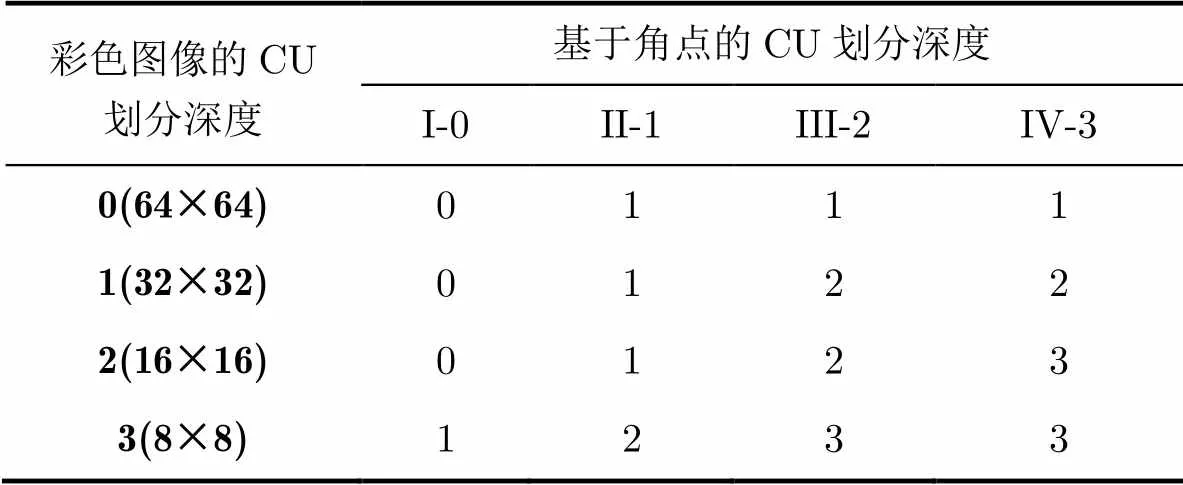
表2预划分CU深度级的调整方案
当彩色图像采用较大的CU时,减小预划分深度级,例如表2中第3行彩色图像的CU深度级为0,则III-2和IV-3的划分深度调整为1;当彩色图像采用较小的CU时,增大预划分深度级,例如表2第6行彩色图像的CU的划分深度为3,将I-0,II-1和III-2的划分深度分别调整为1, 2和3。值得注意的是,如果当前深度图像CU的所有像素值都相同,则不会依据表2中的方案增大CU划分深度。
2.3 基于预划分深度级的CU选择方法
为了探究调整后的预划分深度和最优深度之间的关系,本文选取了7个标准测试序列,并将量化参数(Quantization Parameter, QP)设置为34,对每个序列的前20帧进行测试,获得了最优深度级和预划分深度级之间的分布概率,具体如表3所示。对于I-0类型的编码块,97.23%的CU选择深度级0,采用其他尺寸CU(32×32, 16×16和8×8)的概率非常低,仅为2.77%;对于II-1块,87.76%的CU选深度为1;对于III-2块,75.32%的CU采用了16×16大小的CU;而IV-3的CU块,89.58%的CU选择了深度级为2和3。由于每种类型CU的最优划分深度概率呈不均匀分布,所以可以依据预划分深度级选择不同的CU深度级范围,以提高编码效率。表3同时列出了预划分深度的遍历深度范围。根据不同的深度范围,本文提出的CU划分算法,具体如下:如果CU属于I-0类,则只考虑深度级0,跳过深度级为1, 2和3的RD代价计算;如果CU属于II-1类,则只考虑深度级1,跳过其他深度级。如果当前块属于III-2类,则仅计算深度级2的RD代价。对于IV-3类的CU,将计算深度级为2和3的RD 代价。图2(c)为基于预划分深度级的CU划分示意图,列出了LCU的预划分深度级、对应候选深度级范围和最优的LCU划分。虽然对于II-1, III-2和IV-3的块,有10%~20%的编码块选择较大尺寸的CU,意味着本文所提的CU选择方法的准确率仅为80%到90%,但是这对最终的合成视角的RD性能的影响较小。其原因在于:HTM采用视角合成优化(View Synthesis Optimization, VSO)用来评价深度图像的RD性能,然而VSO并非合成完整的虚拟视角,存在失准问题,对II-1, III-2和IV-3块进行精细的划分,将提高最终合成虚拟视角的图像质量;与彩色视频相比,深度图像的比特数约占总比特数的10%,所以精细的深度图划分所需要的比特数对总RD性能影响较小。

表3 HTM划分深度级和调整后的预划分深度级的分布概率以及预划分深度级对应的遍历深度级范围
2.4 角点的计算方法和自适应选择角点数目
本文的基于角点和彩色图像的CU划分算法需要利用角点对每个LCU进行预划分,因此其编码性能依赖于角点的选择,所以自适应地根据不同的编码内容和编码参数选取角点数目成为本文算法的重要环节。角点的检测方法有很多,例如FAST[16], Shi-Tomasi[17]以及Harris[18]算子等。角点算子根据图像局部相关性原理,利用像素邻域的梯度变化来检测特征点。FAST算子通过中心像素点与离散圆上的像素点进行比较,进行角点检测。Harris算子的角点响应值依据Harris矩阵计算,如式(1)。
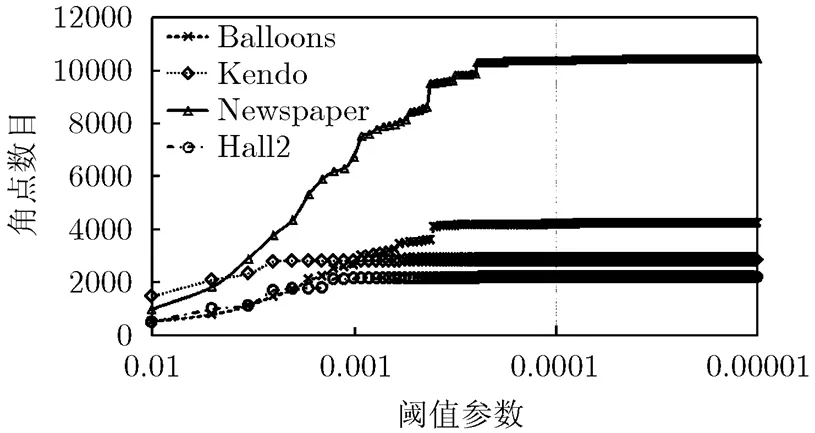
图3 不同阈值参数T检测到的角点数目
2.5 本文算法流程
对于整体算法流程,如图4所示。首先针对每个深度视频帧,根据角点算子和获得角点,然后对每个LCU进行预划分,再依据彩色图像的CU划分对预划分进行调整,得到各LCU最终预划分,并按8×8为单位存储。对于每个LCU的划分过程,根据预划分的深度选择不同的遍历深度范围。整体算法的具体步骤如下:

图4 本文算法的流程图
(2)利用角点对每一个LCU,得到预划分的深度。
(3)利用彩色图像LCU的划分,对步骤(2)中的预划分深度按表2进行调整,并以8×8的像素块为单元存储。
(4)对于每个LCU,按原始的递归顺序进行CU编码,如果当前CU对应的所有预划分深度级为0,则计算深度级为0的 RD代价并且终止CU的划分。否则,执行步骤(5)。
(5)如果当前CU对应的所有预划分深度级都为1,则计算深度级为1的RD代价并且终止CU的划分,否则执行步骤(6)。
(6)如果当前CU对应的所有预划分深度级为2或是3,则计算深度级为2的RD代价。若所有的预划分深度级都为2则终止CU的划分,否则执行步骤(7)。
(7)计算深度级为3的RD代价,并按自底向上的顺序返回步骤(4),重复执行步骤(4)-步骤(7),直至遍历结束,获得最优的LCU划分。
3 实验结果以及分析
本文在3D-HEVC的测试平台HTM-13.0[19]上实现了该算法,并与文献[13,14]及原始HTM的CU划分的算法进行比较。使用全帧内配置模式,对7个标准序列进行了编码,编码帧数为100。编码性能使用平均比特率(Bjøntegaard Delta Bit Rate, BDBR),它是由彩色和深度视频的总比特率以及虚拟视角的峰值信噪比(PSNR),按文献[20]所述方法计算得到。计算复杂度用编码时间来度量。为了便于说明,本文所提的CU划分方法记做JCUD方法。
表4为本文所提JCUD算法与文献[13]和文献[14]的编码性能和计算复杂度的比较结果。由表4可知,与HTM-13.0相比算法JCUD节省编码时间平均为63%。对于Fly和Hall2序列,JCUD其编码时间节省了70%,这是因为这两个序列中含有的物体较少,检测到的角点数目少,故大部分LCU仅需计算0, 1,或是2,一个深度级的RD代价。文献[14]只考虑了彩色图像,忽略了深度图像和彩色图像的失配问题,导致了平均码率增加了3.96%。尤其对于通过深度估计算法得到的序列Kendo, Balloons 和Newspaper, BDBR增加了2.78%~14.85%。文献[13]利用方差等特征提前终止CU的划分,但是方差只是反映了像素的变化信息,并不能够提供方向信息,因此该方法只用于像素几乎不变的平滑区域,平均码率增加了0.18%,但是节省的编码时间仅为30%。图5为Newspaper序列分别在HTM,文献[14]和本文所提JCUD方法的CU划分结果,文献[14]的方法对一些边缘区域选择了较大尺寸的CU,导致了合成视角的图像质量下降;而本文算法与HTM算法的CU划分基本一致,且在物体的边缘区域采用了更加精细的划分。
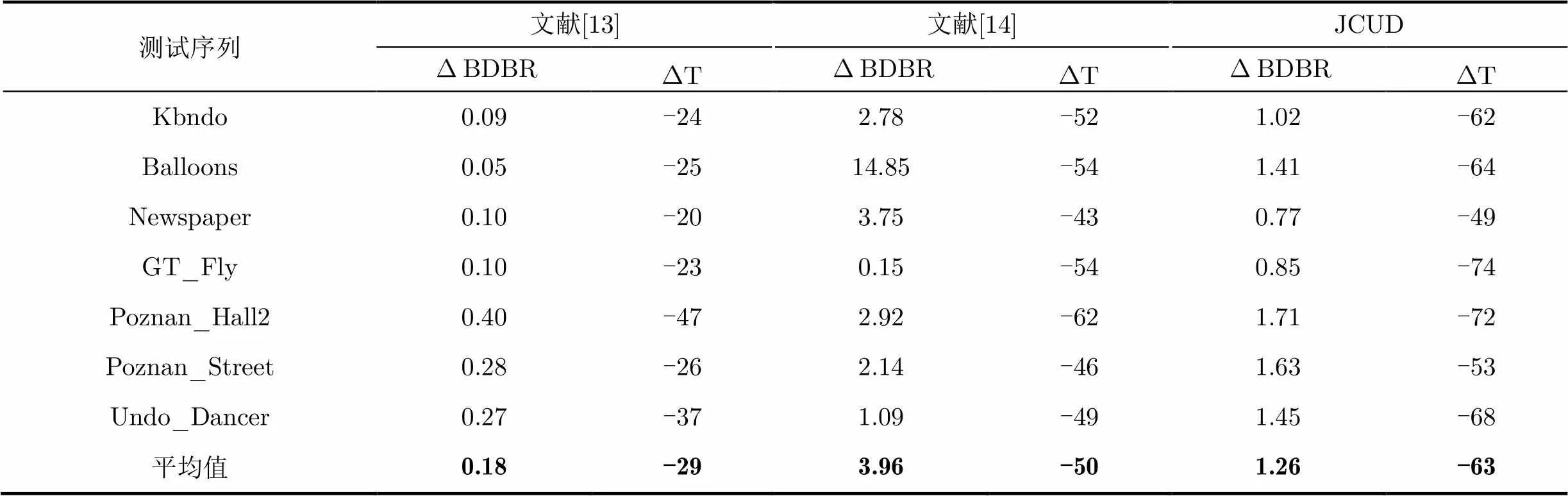
表4 本文提出方法与文献[13]和文献[14]方法的编码性能的比较(%)

图5 序列Newspaper在QP=39时的CU划分结果
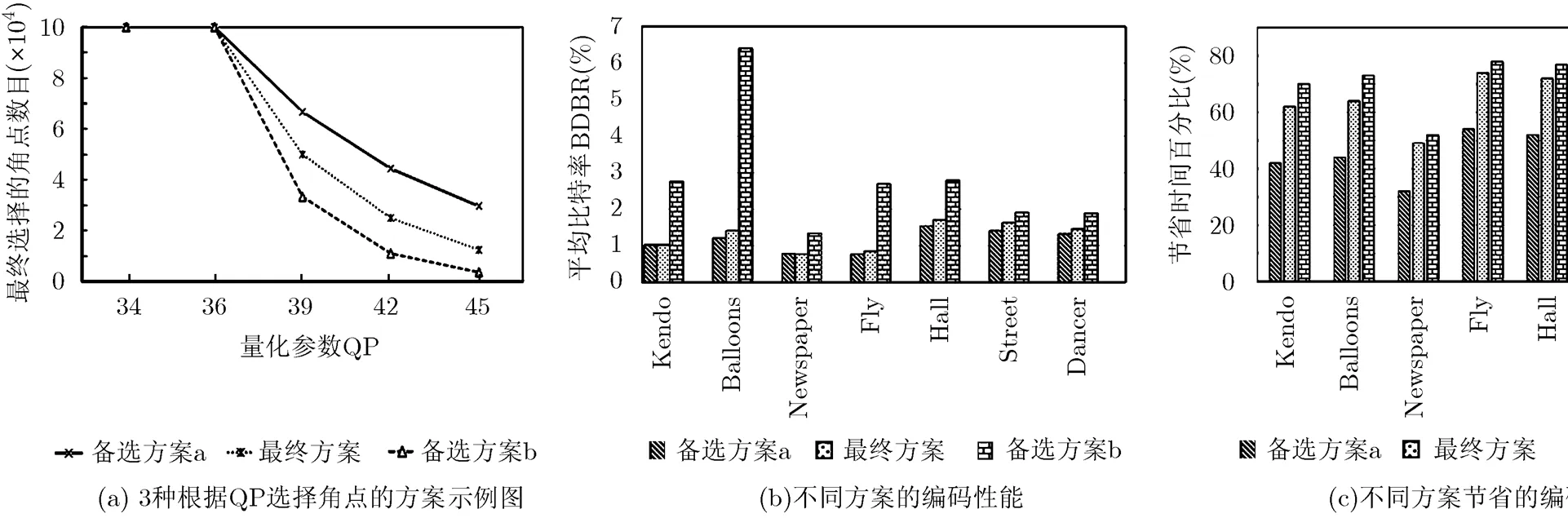
图6 3种根据QP选择角点的方案及对所提算法编码性能和效率的影响
表5列出了采用Harris, Shi-Tomasi以及FAST角点算子的实验结果。由表5可知,不同的角点算子对编码性能影响很小,说明本文算法有很好的推广性。另外,基于FAST算子的CU划分算法节省的时间最少,约为55%,其原因在于FAST容易将边界点误检为角点特征,导致预分配过程产生较多的IV-3的块,而IV-3块需要计算深度级2和3的RD代价。同时表6列出了各角点算子的计算时间占所提算法的百分比。因为3种算子的计算时间仅占总编码时间0.02%~0.60%,所以单纯计算角点的时间对所提算法的编码效率影响很小。
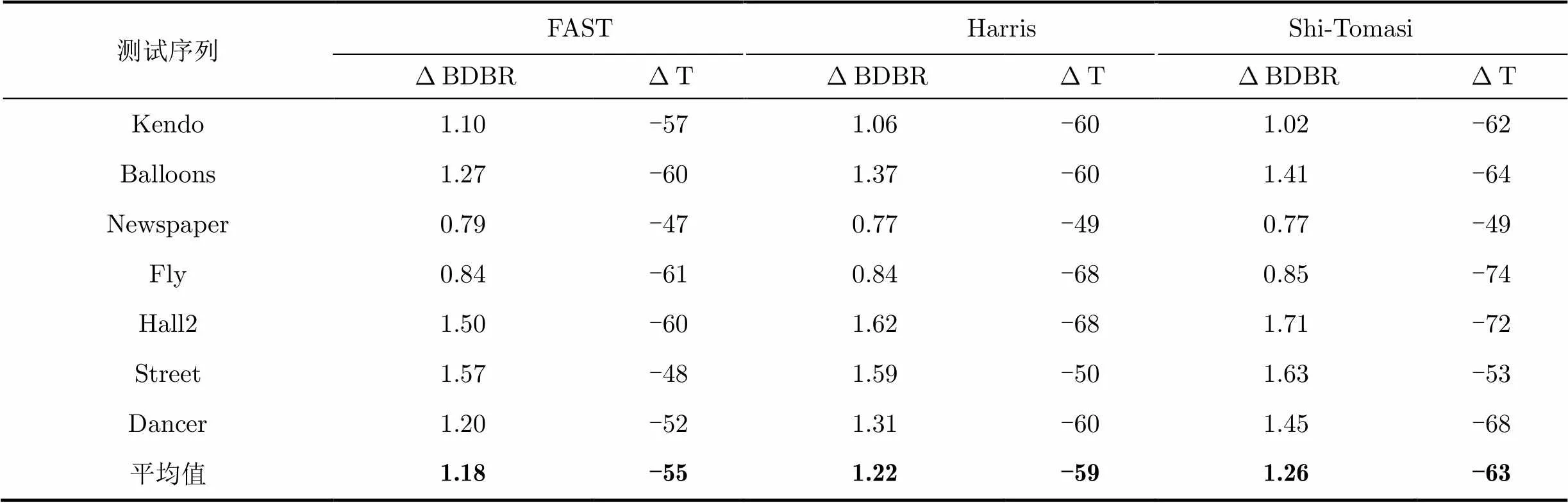
表5 FAST, Harris以及Shi-Tomasi角点算子对编码性能的影响(%)

表6 FAST, Harris以及Shi-Tomasi的计算时间及占总编码时间的百分比
此外,虽然本文提出的方法是针对帧内编码(I帧),而在实际应用中帧间编码(P/B帧)的占比更大。需要指出的是,即使在帧间编码的帧中,同样包含了大量的帧内块。为了说明所提算法的应用范围,本文将分层编码结构[21]的帧分为4类:I帧,Inter- View(IV)帧,Inter-Temporal(IT)帧,以及Inter- View/Temporal(IVT)帧。表7中列出了后3种帧间编码帧的当中的帧内块的百分比分别为94.26%, 22.07%和16.19%。在这些帧内块当中,本文的算法已经可以发挥作用。另外,由于深度图像的帧间相关性低,且角点大多分布在物体边缘,如图1(a)所示,角点区域更容易受到运动的影响,往往需要采用较小的编码单元提供准确的预测,所以所提算法可以应用于非帧内块的CU划分,但仍需要进一步地研究。

表7分层编码结构中不同类型帧的帧内块的百分比(%)
4 结论
本文利用深度图像的空间结构和其与彩色图像存在冗余,提出了基于角点和彩色图像的帧内编码单元划分快速算法。实验结果表明,与HTM-13.0的方法相比,本文算法平均比特率在仅增加了约1.26%的情况下,节省了约63%的编码时间,与只基于彩色图像的方法比较,节省了约13%的编码时间,且平均比特率减少了约3%,有效地提高了编码效率。同时,本文所提算法可以根据不同的视频内容和编码参数,自适应地选择所需的角点数目,算法的自适应性强。由于角点大多分布在物体的边缘,所以本文算法还可以应用到基于Kinect的物体3维重建,3维定位等基于对象访问的远程系统中,以促进3维视频压缩技术在此类应用的进一步发展。
参考文献
[1] ISO&IEC and MPEG. Information technology-MPEG video technologies-Part 3: Representation of auxiliary video and supplemental information[R]. ISO/IEC/JTC1/SC29-23002-3, 2007.
[2] 张秋闻, 安平, 张艳, 等. 基于虚拟视点绘制失真估计的深度图帧内编码[J]. 电子与信息学报, 2011, 33(11): 2541-2546. doi: 10.3724/SP.J.1146.2011.00218.
ZHANG Qiuwen, AN Ping, ZHANG Yan,. Depth map intra moding based on virtual view rendering distortion estimation[J].&, 2011, 33(11): 2541-2546.doi: 10.3724/SP.J.1146. 2011.00218.
[3] 时琳, 刘荣科, 李君烨. 基于深度信息的立体视频错误隐藏方法[J]. 电子与信息学报, 2012, 34(4): 1678-1684. doi: 10.3724/ SP.J.1146.2011.01107.
SHI Lin, LIU Rongke, and LI Junye. Error concealment based on depth information for stereoscopic video coding[J].&, 2012, 34(4): 1678-1684. doi: 10.3724/SP.J.1146.2011.01107.
[4] MULLER K, SCHWARZ H, MARPE D,. 3D high-efficiency video coding for multi-view video and depth data[J]., 2013, 22(9): 3366-3378. doi: 10.1109/TIP.2013.2264820.
[5] SULLIVAN G J, OHM J R, HAN W J,. Overview of the High Efficiency Video Coding(HEVC) standard[J]., 2012, 22(12): 1649-1668. doi: 10.1109/TCSVT.2012.2221191.
[6] MERKLE P, MULLER K, ZHAO X,. Simplified Wedgelet search for DMM modes 1 and 3--JCT3V-B0039[R]. ITU-T SG16 WP3 and ISO/IEC JTC1/SC29/WG11, 2012.
[7] GU Z Y, ZHENG J H, LING N,. Fast depth modeling mode selection for 3D HEVC depth intra coding[C]. IEEE International Conference on Multimedia & Expo Workshops, San Jose, CA, 2013: 1-4. doi: 10.1109/ICMEW.2013.6618267.
[8] PARK C. Edge-based intra mode selection for depth-map coding in 3D-HEVC[J]., 2015, 24(1): 155-162. doi: 10.1109/TIP.2014. 2375653.
[9] 李元, 何小海, 钟国韵, 等. 一种基于时域相关性的高性能视频编码快速帧间预测单元模式判决算法[J]. 电子与信息学报, 2013, 35(10): 2364-2370. doi: 10.3724/SP.J.1146.2013.00028.
LI Yuan, HE Xiaohai, ZHONG Guoyun,. A fast inter-frame prediction unit mode decision algorithm for high efficiency video coding based on temporal correlation[J].&, 2013, 35(10): 2364-2370. doi: 10.3724/SP.J.1146.2013.00028.
[10] 齐美彬, 陈秀丽, 杨艳芳, 等. 高效率视频编码帧内预测编码单元划分快速算法[J]. 电子与信息学报, 2014, 36(7): 1699-1705. doi: 10.3724/SP.J.1146.2013.01148.
QI Meibin, CHEN Xiuli, YANG Yanfang,. Fast coding unit splitting algorithm for high efficiency video coding intra prediction[J].&, 2014, 36(7): 1699-1705. doi: 10.3724/SP.J.1146. 2013.01148.
[11] SHEN Liquan, ZHANG Zhaoyang, and LIU Zhi. Effective CU size decision for HEVC intra coding[J]., 2014, 23(10): 4232-4241.doi: 10.1109/TIP.2014.2341927.
[12] SHEN Liquan, ZHANG Zhaoyang, and AN Ping. Fast CU size decision and mode decision algorithm for HEVC intra coding[J]., 2013, 59(1): 207-213. doi: 10.1109/TCE.2013.6490261.
[13] MIOK K, NAM L, and LI S. Fast single depth intra mode decision for depth map coding in 3D-HEVC[C]. IEEE International Conference on Multimedia & Expo Workshops, Turin, Italy, 2015:1-6. doi: 10.1109/ICMEW.2015.7169769.
[14] MORE E G, JUNG J, CAGNAZZO M,Initialization, limitation, and predictive coding of the depth and texture quadtree in 3D-HEVC[J]., 2014, 24(9): 1554-1565. doi: 10.1109/TCSVT.2013.2283110.
[15] LI W and LU Y. Rate-distortion optimization for depth map coding with distortion estimation of synthesized view[C]. IEEE International Symposium on Circuits and Systems, Beijing, China, 2013:17-20. doi:10.1109/ISCAS.2013.6571771.
[16] ROSTEN E and DRUMMOND T. Fusing points and lines for high performance tracking[C].IEEE International Conference on Computer Vision, Beijing, China, 2005: 1508-1515. doi: 10.1109/ICCV.2005.104.
[17] SHI J and TOMASI C. Good features to track[C]. IEEE International Conference on Computer Vision and Pattern Recognition, Seattle, WA, 1994: 593-600. doi: 10.1109/ CVPR.1994.323794.
[18] HARRIS C and STEPHENS M. A combined corner and edge detector[C]. Alvey Vision Conference, Manchester, UK, 1988: 147-151.
[19] MPEG 3D-HTM Software V13.0[OL]. https://hevc.hhi. fraunhofer.de/svn/svn 3DVCSoftware/tags/13.0, 2014.
[20] BJPMTEGAARD G. Calculation of average PSNR differences between RD curves[R]. ITU-T Video Coding Experts Group, 2002.
[21] MERKLE P, SMOLIC K, MULLER P,. Efficient prediction structures for Multi-view video coding[J]., 2007, 17(11): 1461-1473. doi: 10.1109/TCSVT.2007.903665.
Fast Coding Unit Decision Algorithm for Depth Intra Coding in 3D-HEVC
ZHANG Hongbin①②FU Changhong①SU Weimin①CHAN Yuilam②SIU Wanchi②
①(,,210094,)②(,,999077,)
An efficient Coding Unit (CU) decision algorithm is proposed for depth intra coding, in which the depth level of CU is predicted by Corner-Point (CP) and the co-located texture CU. More specially, firstly, the CPs are obtained by corner detector in junction with the quantization parameter, which are further used to pre-allocate the depth level. After that, the refinement of pre-allocation depth level is performed by considering the block partition of the co-located texture. Finally, different depth search range is selected based on the final pre-allocation depth levels. Simulation results show that the proposed algorithm can provide about 63% time saving with maintaining coding performance compared with the original 3D-HEVC method. On the other hand, it can achieve about 13% time saving while the BD-rate 3% decreased over the CU decision method that only considers the texture information.
3D-HEVC; Depth map; Intra coding; Coding unit; Corner Point (CP) detection
TP391
A
1009-5896(2016)10-2523-08
10.11999/JEIT151426
2015-12-17;改回日期:2016-06-22;网络出版:2016-08-26
伏长虹 enchfu@njust.edu.cn
国家自然科学基金(61301109),江苏省自然科学基金(BK2012395)
The National Natural Science Foundation of China (61301109), The Natural Science Foundation of Jiangsu Province (BK2012395)
张洪彬: 男,1988年生,博士生,研究方向为3D视频压缩和图像处理.
伏长虹: 男,1981年生,副教授,研究方向为视频压缩和处理.
苏卫民: 男,1960年生,教授,研究方向为雷达信号处理、图像处理和视频处理.
猜你喜欢
数学物理学报(2021年2期)2021-06-09 08:54:26
应用数学(2020年2期)2020-06-24 06:02:44
电子制作(2019年16期)2019-09-27 09:34:46
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:54
电子技术与软件工程(2018年10期)2018-07-16 12:04:18
自动化学报(2017年5期)2017-05-14 06:20:56
电子科技(2016年12期)2016-12-26 02:25:49
数学物理学报(2016年3期)2016-12-01 05:36:27
系统工程与电子技术(2016年4期)2016-08-24 07:46:28
东北电力大学学报(2015年1期)2015-11-13 05:20:36
