
基于Zookeeper框架实现MySQL分布式数据库集群*
2016-10-26 05:17张旭刚李东辉朱广新
计算机与数字工程 2016年9期
张旭刚 李东辉 俞 俊 朱广新 郑 磊
(南京南瑞集团公司信息系统集成分公司 南京 210000)
基于Zookeeper框架实现MySQL分布式数据库集群*
张旭刚李东辉俞俊朱广新郑磊
(南京南瑞集团公司信息系统集成分公司南京210000)
在MySQL数据库集群间数据一致性通常是基于日志复制,主数据库接收到来自从库的io_thread请求后,读取日志指定位置之后的日志信息,返回给从库的io_thread,io_thread将日志内容添加到relay-log,再由sql_thread解析relay-log并执行。这种基于日志复制数据库集群,缺少统一的框架对MySQL集群实现自动化管理,经常需要人工干预集群的维护,如数据一致性监控、主从切换、灾难恢复后加入集群等。为实现MySQL集群的自动化管理,论文提出基于Zookeeper的管理框架,监控和管理集群的状态、资源、数据一致性和主从切换等。
MySQL Zookeeper; 主从切换; 自动化管理
Class NumberTP391
1 引言
MySQL只提供了一种基于日志的同步模式,但在MySQL集群实际应用中,还需要解决一系列的问题,主要包括数据一致性监控、主从切换、灾难恢复后加入集群、状态和资源监控等,这些都是集群管理的基本问题。基于Zookeeper,实现MySQL集群的资源、配置的统一管理和调度,基本思想是在MySQL服务器上部署agent,由agent实时上报MySQL实例的可用性、复制的一致性、服务器负载等,Zookeeper根据这些动态信息进行资源调度和协调。
2 Zookeeper框架
2.1Zookeeper介绍
Zookeeper是一个分布式的协调服务,为分布式应用提供统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等,由2n+1(n≥1)服务器节点组成,这些节点中有一个主节点(leader),leader是通过leader selection自动地从服务器节点中选举出来,其他节点角色为follower或observer。Zookeeper提供了一个类似于标准文件系统目录结构的层次化的命名空间(hierarchal namespace)。如图1所示,hierarchal namespace中的每一个节点都被称为Znode。Znode是组成hierarchal namespace的基本单位。在源码中对应于类DataNode,其维护着节点用户数据、父节点和子节点集合,以及本节点状态,用户可以在hierarchal namespace中创建Znode,将数据保存在Znode中,并监听Znode的状态变化,Zookeeper会保证client对Znode的操作是顺序一致性。
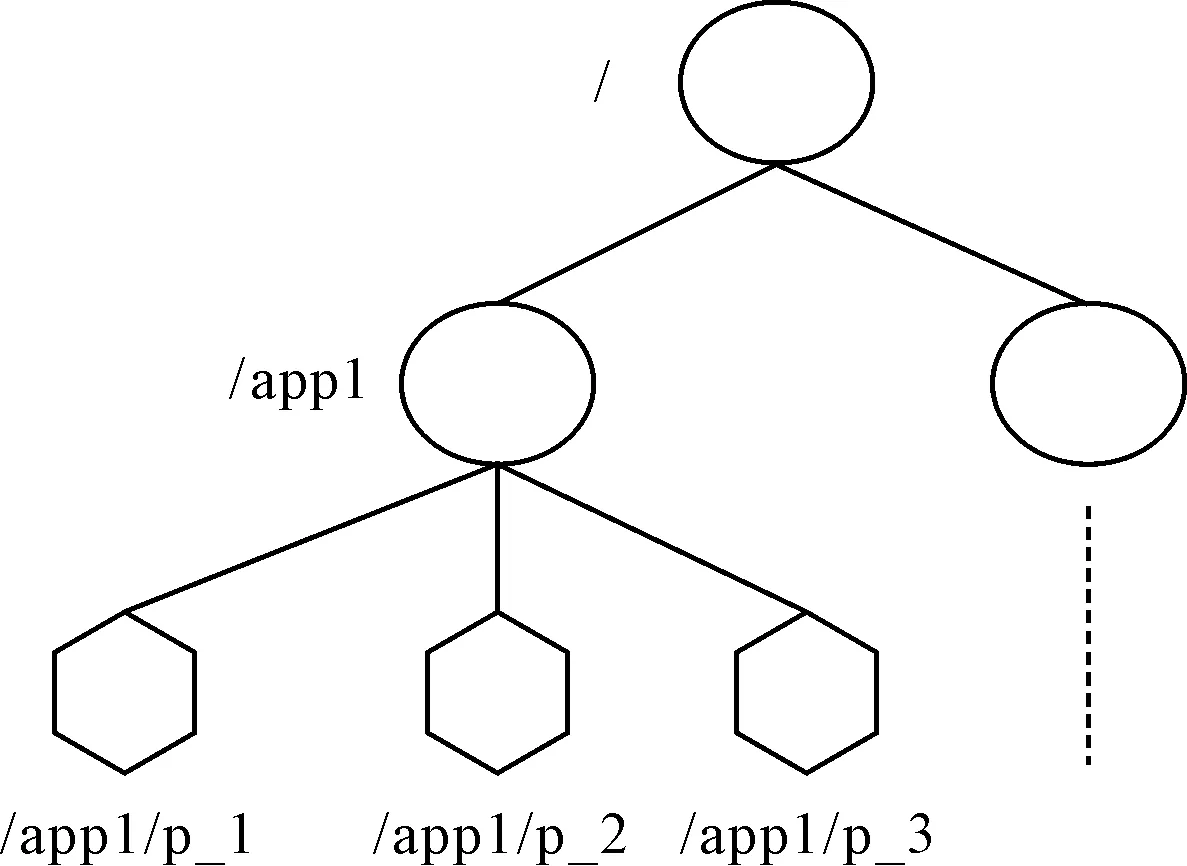
图1 层次化的命名空间
2.2Zookeeper框架
Zookeeper服务器节点的实现可以分成两部分:一部分是处理与客户端交互,实现客户端对zookeeper的hierachal namespace的各种操作;另一部分是作为zab算法(paxos算法的Zookeeper实现)的参与者(leader、follower、observer三种角色的其中一种),实现具体的算法逻辑。
Zookeeper服务器的hierachal namespace、Znode、客户端与服务器连接以及客户端可以监听服务器的Znode状态的watch机制之间的元数据关系如图2所示。

图2 Zookeeper 组件关系图
Zookeeper使用Trie树来实现了hierachal namespace,由PathTrie这个类来完成。为了实现从路径到Znode的映射,Zookeeper在内存中维护了一个Znode的hashmap,key为Znode在hierachal namespace上的路径,value为Znode对象,Znode在Zookeeper源码中由DataNode这个类实现。为了实现client监听Znode的状态变化,Zookeeper将与客户端的连接和hierachal namespace的节点路径进行映射,WatchManager这个类就是用于维护这个映射关系的,其中NIOServerCnxn是Zookeeper服务器与client的一个socket连接;为了监听Znode的目录结构的变化和数据变化,Zookeeper使用了两个WatchManager,分别用来监听namespace的目录结构和数据的变化。
在paxos算法中有三种角色,分别是提案者,接受者和学习者,与在zookeeper中的三种节点类型对应,即leader、follower和observer三种类型的节点,其中observer节点只能学习已经批准的提案,而不会参与到提案的投票过程中,这个角色的设定是为了保证提案选举的性能不会随着Zookeeper集群规模扩大而降低。角色间的信令交互如图3所示。

图3 角色交互图
3 Zookeeper设计与实现
在MySQL集群中,Zookeeper架构主要由Zookeeper、DBagent和MySQL等组件组成,Zookeeper作为系统的协调器,监控和管理系统资源,DBagent部署在MySQL上,负责向Zookeeper上报MySQL实例的状态,包括实例的可用性、复制的一致性、服务器负载等,由mysqlreport和mysqltransfer两个模块构成,mysqltransfer用于自动扩容,mysqlreport用于上报心跳信息、资源信息。总体结构如图4所示。
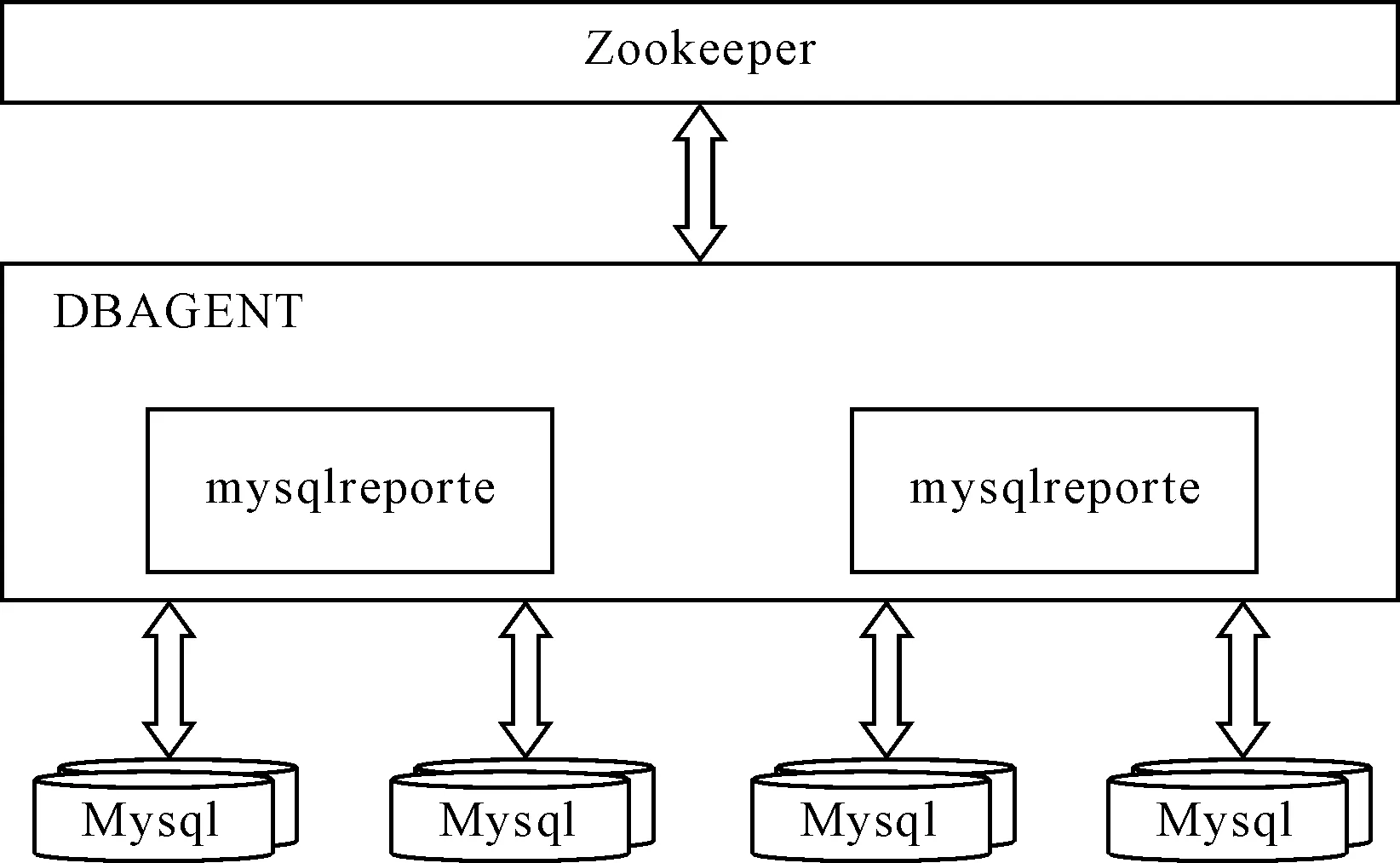
图4 系统结构图
3.1Zookeeper结构设计
主要有如下信息点:
1) 实时主从的状态信息setrun@set_1
{"master":{"alive":"0","city":"default","idc":"default","name":"172.16.17.20_3309","weight":"1","zone":"default"},"set":"set_1","slave":[{"alive":"0","city":"default","idc":"default","name":"172.16.17.11_3309","weight":"1","zone":"default"}]}
包括主从库的状态、分布的地理位置、IP地址及端口号等信息。
2) 读取控制主、从切换的参数cfg@recovery
{"consist":"on","maxdelay":"100","maxlosthbtime":"10"}
"maxdelay":"100" 100 代表主备延迟为 100 秒。
"maxlosthbtime":"10" 代表主机宕机10秒后,发起主备切换流程。
"consist":"on" 代表一致性容灾,off代表非一致性容灾,则不会按照一致性容灾的流程进行主备切换,而是暴力的替换主备机位置。
3) DBAgent上传DB 服务器上的磁盘信息、SQL统计信息 rsinfo
{"cpuoccupy":"0","deletecount":"","diskinfo":[{"avail":"185875","dev":"data_dir","fs":"/data/ea/dbdata/easycluster/db/data","total":"201586","usage":"7","used":"15711"},{"avail":"185875","dev":"binlog_dir","fs":"/data/ea/dbdata/easycluster/db/dblogs/bin","total":"201586","usage":"7","used":"15711"}],"insertcount":"","selectcount":"","server_id":"33091","slowquerycount":"","sqlasyn":"","updatecount":"","usable":"0","ver":"1.0"}
实现对CPU、SQL、磁盘等资源的监控。
3.2主从一致性监控
主从数据库的一致性监控通常是在从库上执行语句show slave statusG获取Seconds_Behind_Master参数的值来判断,但这个值通常不能反映主从数据库一致性的真实情况。Seconds_Behind_Master是通过比较sql_thread执行的event的timestamp和io_thread复制的 event的timestamp进行比较得到的一个差值。当主库I/O负载很大或是网络阻塞,io_thread复制binlog的速度会非常慢或停滞,此时sql_thread一直都能及时应用 io_thread的复制, Seconds_Behind_Master的值是0,表示是没有无延时的,实际主从数据一致性延迟非常严重。
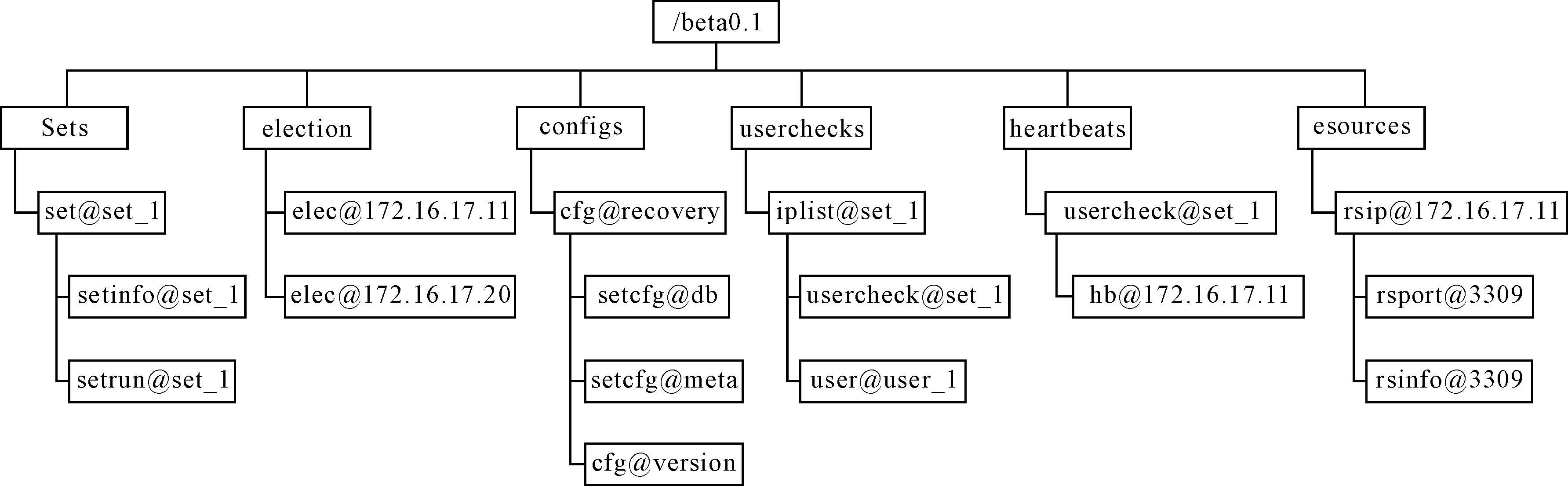
图5 Zookeeper结构设计图
为解决以上问题,本文通过在主从数据库上创建一张表SysDB.StatusTable,dbagent将当前时间戳、ip、端口通过replace into方式写入SysDB.StatusTable表,mysqlreport默认3s连接一次MySQL,并对sysdb.statustable表进行读操作,根据master同步过来的时间、slave写入的时间进行相减,计算出时间差值作为延迟的时间,将以上获取的数据库信息写入Zookeeper的hb@IP地址_端口号位置上,写入信息:{"agentbindport":"57086","autorebuildms":"1","conn_err":"0","conn_info":"","delay":"0","gtiddelay":"","read_err":"0","read_info":"","repl":"0","svrtype":"master","ver":"1.0","write_err":"0","write_info":""},其中delay值代表主从数据复制的延迟,单位为s,0表示无延迟,结构图如图6所示。

图6 复制一致性设计图
通过以上方式,能准确获取主从数据库的一致性延迟,如果延迟超过设置的阈值,则在主库宕机从库承担读写角色时,从库只能读不能写。
3.3资源监控

图7 系统资源监控设计图
在MySQL分布式集群系统中,有多种系统资源需要监控,并根据结果做出反应,主要的监控资源有CPU的使用率、磁盘使用率、磁盘IO、MySQL数据库状态信息等,放到Zookeeper的相关目录下,进行统一管理,并通过界面查看各资源信息,进行优化。
实际步骤是mysqlreport根据MySQL的my.cnf文件,找到数据文件日志和日志目录, mysqlreport调用C语言的statfs函数分析MySQL的数据文件、binlog文件在磁盘使用情况,mysqlreport获取只是统计数据文件及binlog的根目录大小,同时mysqlreport连接到MySQL通过show global statusG命令获取Com_select、Com_update、Com_insert、Slow_queries等信息,Mysqlreport默认5s一次将收集到的数据上传到Zookpeeper的rsinfo@IP_端口号目录下。
通过获取以上信息,当数据库的资源使用率超过设置阈值时,调用策略应对,如当CPU使用率超过95%时,进行主从切换,防止数据库宕机。
3.4主从切换管理

图8 主从切换流程
在该架构设计中,当主库宕机或者DBAgent上报心跳超时会进行切换,切换流程如下:
1) 当zookeeper 中主机的状态信息发生变化后,立刻能感知到主DB 的状态变化。
2) zookeeper进程将主机路由标记为不可达。
修改路径:
/beta0.1/sets/set@set_1/setrun@set_1
{"master":{"alive":"-1","city":"default","idc":"default","name":"172.16.17.20_3309","weight":"1","zone":"default"},"set":"set_1","slave":[{"alive":"0","city":"default","idc":"default","name":"172.16.17.11_3309","weight":"1","zone":"default"}]}
3) Zookeeper调度进程查看是否有可用的从机,从机必须存在且正常工作(且主从数据是一致的)。
(1)查看路径:
/beta0.1/sets/set@set_1/setrun@set_1
{"master":{"alive":"-1","city":"default","idc":"default","name":"172.16.17.20_3309","weight":"1","zone":"default"},"set":"set_1","slave":[{"alive":"0","city":"default","idc":"default","name":"172.16.17.11_3309","weight":"1","zone":"default"}]}
(2)查看从机数据延迟情况
/beta0.1/heartbeats/hb@172.16.17.11_3309
{"agentbindport":"56056","autorebuildms":"1","conn_err":"0","conn_info":"","delay":"6","gtiddelay":"0","read_err":"0","read_info":"","repl":"0","svrtype":"slave","ver":"1.0","write_err":"0","write_info":""}
(3)查看切换配置限制
/beta0.1/configs/cfg@recovery
{"consist":"on","maxdelay":"100","maxlosthbtime":"10"}
切换必须满足条件 slave 状态必须为alive ,主备延迟必须小于maxdelay 即delay 4) Zookeeper调度进程下发切换命令(写入Zookeeper )至从数据库,由从DBAgent从Zookeeper中读取相关命令,执行切换,提升从数据库为主用数据库。 写入信息到路径: /beta0.1/resources/rsip@172.16.17.20/rsport@3309/swjobs@172.16.17.20_3309_00000000+degrade 其中:0000000000 为任务ID数字尾缀 degrade 为任务类型,这里是降级任务 DBAgent 接收到降级任务后,需返回确认信息。将信息写入zookeeper /beta0.1/resources/rsip@172.16.17.20/rsport@3309/swjobs@172.16.17.20_3309_00000000+degrade Zookeeper 接收到DBAgent应答后,下发命令至从数据库,让从数据库加载relaylog。 /beta0.1/resources/rsip@172.16.17.11/rsport@3309/swjobs@172.16.17.11_3309/swjob@172.16.17.20_3309_00000000+applychange 从数据库加载relay log 完成后,返回确认信息,将信息写入Zookeeper /beta0.1/resources/rsip@172.16.17.11/rsport@3309/swjobs@172.16.17.11_3309/swjob@172.16.17.20_3309_00000000+applychange 5) 步骤4完成后,DBagent更新Zookeeper中自己的角色信息,由Slave 修改为Master。 更新路径: /beta0.1/sets/set@set_1/setrun@set_1 {"master":{"alive":"0","city":"default","idc":"default","name":"172.16.17.11_3309","weight":"1","zone":"default"},"set":"set_1","slave":[{"alive":"0","city":"default","idc":"default","name":"172.16.17.20_3309","weight":"1","zone":"default"}]} 基于zookeeper的MySQL分布式数据库集群,解决了MySQL数据库集群中存在的数据一致性难监控、主从切换需要人工操作、日志自动追平等问题,在统一的架构下实现了MySQL分布式数据库集群的自动化管理,维护简单,易于管理,横向扩展,已在国家电网的企协内部管理信息系统、统一数据保护与监控平台、安全基线合规系统等应用,取得良好效果。 [1] Flavio Junqueira,Benjamin Reed.ZooKeeper: Distributed Process Coordination[M].O′Reilly Media,2013.12:210-333. [2] 曾大聃,周傲英.Hadoop权威指南(第二版-中文版)[M].北京:清华大学出版社,2011:88-89. ZENG DaDan, ZHOU AoYing. Hadoop:the Definitive Guide(2rd Edition-Chinese)[M]. Beijing: Tsinghua University press,2011:88-89. [3] 邓鹏,李枚毅,何诚.Namenode 单点故障解决方案研究[J].计算机工程,2012,38(21):25-44. DENG Peng, LI MeiYi, HE Bin. Research on Namenode Single Point of Fault Solution[J]. Computer Engineering,2012,38(21):25-44. [4] Patrick Hunt,Mahadev Konar,Flavio PJunqueira,Benjamin Reed,ZooKeeper:Wait-freecoordinationforIntemet — scalesystems[C]//USENIX Annual Technology Conference,2011:2-3. [5] 叶谦.Zookeeper初步调研报告[J].计算机技术与发展,2011,7(7):15-25. YE Qian. Zookeeper Initial Research Report[J].Computer Technology And Development,2011,7(7):15-25. [6] 倪超.从Paxos到Zookeeper[M].北京:电子工业出版社,2015:43-61. NIE Chao.From Paxos to Zookeeper[M].Beijing:Electronic Industry Press,2015:43-61. [7] Marco Aiello.leader_election[M].Distributed system,2011:5-9. [8] 雷明.fast paxos算法与Zookeeper leader选举源代码分析[J].计算机技术与发展,2015,3(4):3-20. LEI Ming. Source Code Analysis on Fast Paxos and Leader Election of Zookeeper[J]. Computer Technology and Development,2015,3(4):3-20. [9] ZooKeeper: Because Coordinating Distributed Systems is a Zoo[J/OL].Science,[2014-3-14](http://zookeeper.apache.org/doc/r3.4.6/ /). [10] ZooKeeper Administrator’s Guide[J/OL]. Science, [2013-4-4](http://archive.cloudera.com/cdh/3/zookeeper/zookeeperAdmin.html) [11] Flavio Junqueira, Benjamin Reed. Zookeeper development programming[J]. O’Reilly Media,2013,12,4(03):8-12 Design and Implementation of Zookeeper in Distributed MySQL Database Cluster ZHANG XugangLI DonghuiYU JunZHU GuangxinZHENG Lei (Information System Integration Company, Nari Group Cooperation, Nanjing210000) Data consistency is always based on log replication among MySQL cluster. First, master database receives io_thread request from slave database, read log information of specified location and repsond the information to io_thread of slave database. Then, io_thread of slave databased appends the log information to relay-log, sql thread of slave database analyses relay-log and executes the sql statements. The MySQL cluster based on log replication lacks unified architecture to realize automated management and needs maintenace for monitoring data consistency, master-slave switchover and rejoining cluster after disaster recovery. To realize automated management for MySQL Cluster, the topic adopts zookeeper to monitor and manage state, resources, data consistency and switchover between master and slave databased. MySQL Zookeeper, master-slave switch, automated management 2016年3月6日, 2016年4月29日 张旭刚,助理工程师,研究方向:计算机应用技术。李东辉,高级工程师,研究方向:电力系统通信信息。俞俊,高级工程师,领域方向:电力系统通信信息。朱广新,工程师,研究方向:模式识别与智能系统。郑磊,助理工程师,研究方向:电力系统通信信息.。 TP391DOI:10.3969/j.issn.1672-9722.2016.09.0484 结语
猜你喜欢
公民与法治(2022年5期)2022-07-29
华人时刊(2021年13期)2021-11-27
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
心声歌刊(2020年4期)2020-09-07
制造技术与机床(2017年6期)2018-01-19
小学生(看图说画)(2017年6期)2017-11-06
电测与仪表(2016年24期)2016-04-12
燕山大学学报(2015年4期)2015-12-25
探测与控制学报(2015年4期)2015-12-15
