
几种文本分类算法性能比较与分析
2016-10-22 00:43杨娟王未央
现代计算机 2016年25期
杨娟,王未央
(上海海事大学信息工程学院,上海201306)
几种文本分类算法性能比较与分析
杨娟,王未央
(上海海事大学信息工程学院,上海201306)
针对常用的文本分类算法,给定五种文本类型的数据集,通过使用典型的文本分类算法进行实验分析,通过精确率、召回率和测试值的精度来评估这些文本分类器的性能,并给出分析结果和改进的组合训练方法。结果表明:将半监督学习训练和监督学习相结合能达到更好的分类效果。为了提高文本推荐速度,前期工作就是要选择合适的分类算法方法,组合选择算法,提高准确度和效率。
文本分类;监督学习;组合选择;推荐
0 引言
随着互联网信息技术的发展,各种文本类型的信息海量产生,在面对网络社交化的时代,需要对文本信息进行分类处理,从而进行个性化推荐给相关度高的用户。于是,各种文本分类算法被提出。文本分类[2]就是把某文档归属于哪一个类别。当需要处理大量文本信息分类的时候,必须按照一定的模型标准,建立合适的分类器模型,把大量文本划分为预先设定好的几个类别中,实现自动文本分类。于是基于机器学习的文本挖掘技术被相应的提出来,自动化文本分类也得以实现。国内外学者研究提出来的许多分类方法,有支持向量机(SVM)算法[9],朴素贝叶斯(NB)算法[6],K最近邻(KNN)算法[7]等。本文主要针对基于机器学习的几种算法,选择有监督和半监督学习训练方法,对已知五种类型进行分类实验,通过分析结果精确度和分类结果的稳定性,提出文本推荐的时候该怎样选择合适的算法进行建模。
在文献[8]提到了在机器学习的过程中,先将样本数据分成三个集合:训练集、验证集、测试集。验证集用来对模型参数进行调整,训练集的目的是用来估计模型结构,测试集是用来验证模型的分类效果如何。训练集一般用在有指导的监督学习中,监督学习是指在有标记的样本集合中训练数据,建立学习模型,然后去预测大量的没有标记的样本。与监督学习相比,半监督学习则不需要人工的操作,且在处理只有少量标注样本和不均匀数据集时,能够利用大量未标记样本进行学习。这更好地避免了在标记文本时候代价大,以及主观判断所带来的缺陷。本文也通过实验,在同一数据集上对样本进行监督训练和半监督训练,又通过期望最大化算法(EM)对贝叶斯分类器(监督学习)训练,对比其他算法更好地实现了分类效果。
先给出文本分类的一般算法流程和半监督学习的文本分类流程图如下:
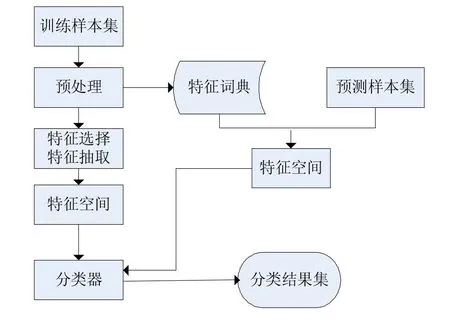
图1 文本分类的一般流程

图2 基于半监督学习的文本分类流程
1 常用文本分类方法思想
1.1类中心向量法
类中心向量算法源于向量空间模型理论,是情报检索领域经典的算法,基本思想是:在训练阶段计算训练样本集中各类的中心点,即已建立分类器;当测试文本D需要分类时,将其进行向量表示后,计算与各类中心向量的相似度,最后将D标定为相似度最大的那个类别。
1.2KNN近邻算法
KNN(K Nearest Neighbor)算法是一种基于实例统计的文本分类方法。该算法思想为:给定一个带标注的训练文本集,在对新文本进行分类时,从训练集的特征空间中找出与新文本最相似的K篇文本,这些K篇文本所属的类别是已经训练好的了,已经正确分类的了,那么目标新文本也划分到该类别中。
1.3朴素贝叶斯算法
朴素贝叶斯(Naive Bayes)算法是来自概率统计的贝叶斯决策理论。基本思想是:给出待分类项,在该项出现的条件下求解出各个类别出现的概率,选取最大的那一个,把待分类项分到那个类别。简单来说,就是利用关键词语在类中出现的概率,概率越大的,就推测给定文档属于该类。NB方法的朴素是因为它的特征属性单词独立性假设,即不同单词在给定类别下的条件概率是互相独立的(文档中的每个词都是相互独立出现的,且词的出现没有线性顺序关系)。
1.4自训练学习
自训练(Self-Training)算法是半监督学习中比较常见的方法之一,首先对已标作过标注的少量样本进行监督学习训练,再将没有标注过的样本添加到通过训练集所得的初始分类器中训练,进行预测,得出的数值越大代表分类取得的效果越好,将该分类得到数值大的文本和其分类标注一起添加到训练集合中,作为新的训练样本集进行又学习,迭代训练直到满足条件为止。
另外还有一种经典的被称作上帝的算法的是期望最大(Expectation-Maximization)方法,它与朴素贝叶斯方法都是来源于概率统计模型。期望最大化算法是一用来解决数据不完整的参数估计问题,需要循环迭代,最后收敛于最大似然参数的一种估计方法。定义一个最大化函数,收集一些训练数据集,就可以使用EM算法进行若干次迭代后即可得到所需模型,这是提出的最早的一种半监督学习方法,很好用,一般迭代三四次,所定义的目标函数就能收敛。
1.5基于生成模型的半监督分类
样本生成模型(Generative Models)是根据统计学的观点提出来的,需要把样本数据分为标记样本和未标记样本,该模型的参数一般先由标记样本计算确定,然后结合标记样本并利用当前模型训练出未标记样本后再进行共同调整。首先对模型的参数进行初始估计,采用上文提到的期望最大化算法(EM),再进行重复执行E步和M步,直至收敛。E步称为期望步,根据当前参数计算每个对象关于各个簇的隶属概率;M步称为最大化步,使用E步计算的概率来更新参数估计。
使用不同的生成式模型作为基分类器,会产生不一样的分类结果,例如混合高斯(Mixture of Gaussians)、混合专家(Mixture of Experts)、朴素贝叶斯等。生成式模型会让半监督学习更简单方便,预测结果比较直观,当标记样本非常稀少的时候,通过训练样本得到的生成式模型较其他模型具有更好的性能,如果假设模型不能准确地得出数据的分布,需要利用大量的未标记数据来估计模型参数,必定会大大降低训练出的模型的泛化能力。文本分类中另一个重要的考虑其实就是需要标记数据的可用性。数据标记是非常耗时的任务,因此,在许多情况下,它们在数量上有限。如果可能的话,我们想利用这个有限的标签信息,以及在我们的分类时将无标签的数据加入到训练集合中,一起构成训练样本,有了这个目标,我们采用了半监督和监督相结合的学习方法,利用这些标记和未标记的数据得出更适合的分类器模型。在实际进行数据建模的时候,怎样选择合适的半监督学习方法来训练分类器?本文来做一个实验对比下它们的分类精度,提出改进方法,让训练出来的分类器尽可能地提高正确分类的比例。
2 实验和分类评估指标
2.1实验数据集
实验数据集来源是搜狗实验室测试文本分类文章语料库(http://www.sogou.com/labs/dl/c.html),共有九类,为了便于实验,计算机自动抽取的524篇文章里,对有把握分类的488篇重新分为五类,实验分别在有监督学习和半监督学习下对数据集进行分类,有监督下分类分为训练数据集和测试数据集,如下表1:

表1 有监督训练数据集
半监督分类的测试数据与有监督分类相同,训练数据部分划分为两部分,一部分作为初始标记样本数据,另一部分作为训练数据,如下表2:

表2 半监督训练数据集
2.2分类评估指标
本实验采用准确率,召回率和F1的值(F1值越大分类效果越好)三个数据来评估文本分类器的性能,它们分别计算的公式如下:
精确率(pecision):

召回率(recall):

F1测试值:

3 实验分析
本实验环境是:联想B460笔记本上,处理器Intel i3,内存4GB,硬盘320G,操作系统:Windows 10,实验算法是在MATLAB7上进行的。有监督训练学习选择了类中心向量算法,KNN算法(先取K=5)和朴素贝叶斯算法。半监督学习训练采用类向量+自训练相组合算法:即对于标记样本的数采用类中心向量训练,再结合未标记样本,用自训练算法迭代循环训练得出最终分类器和分类结果。
有监督分类结果:

表3 类中心向量的有监督分类精度

表4 KNN(K=5)的有监督分类精度
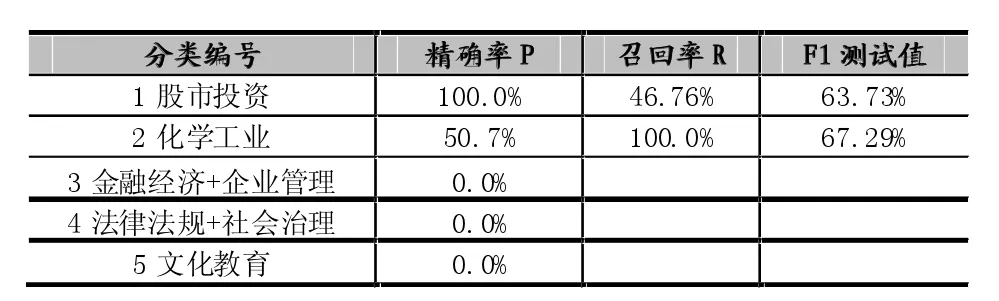
表5 贝叶斯的有监督分类精度
半监督分类结果——试验1:
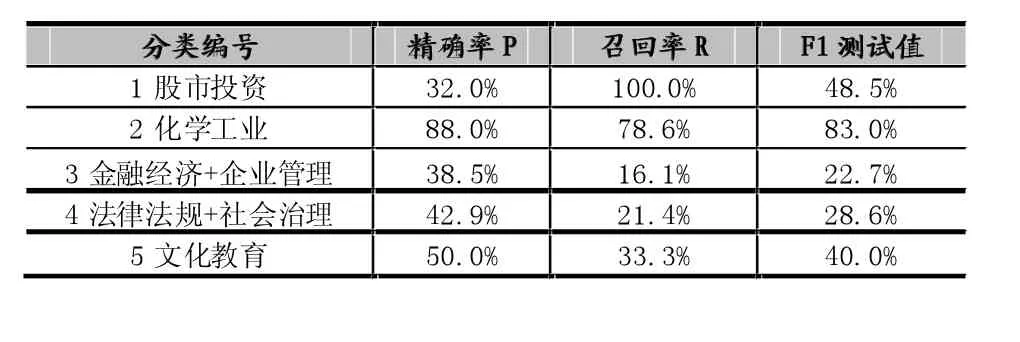
表6 类中心向量+自训练的半监督分类精度(训练数据)
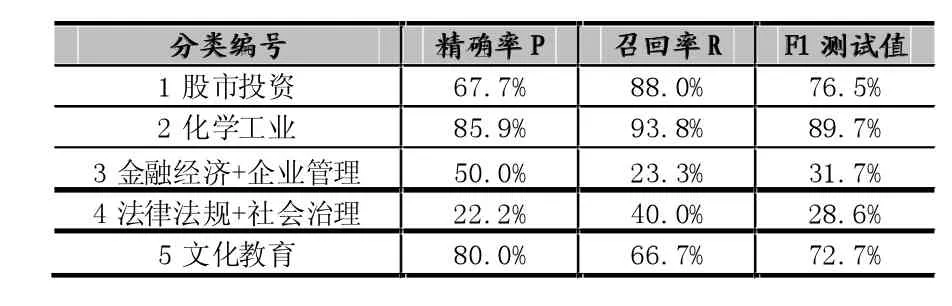
表7 类中心向量+自训练的半监督分类精度(测试数据)
半监督分类结果——试验2:
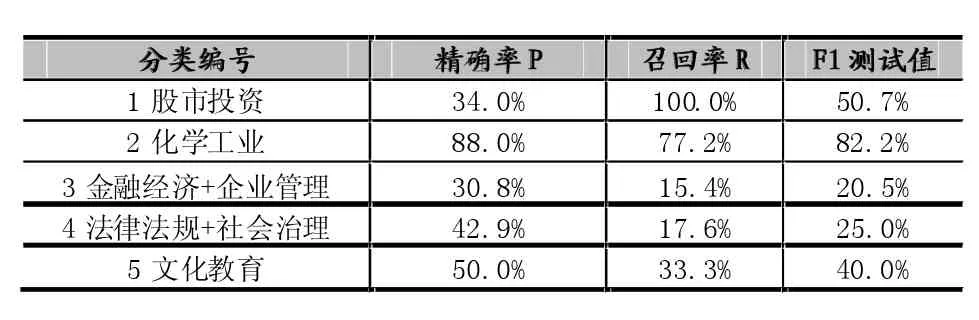
表8 类中心向量+自训练的半监督分类精度(训练数据)
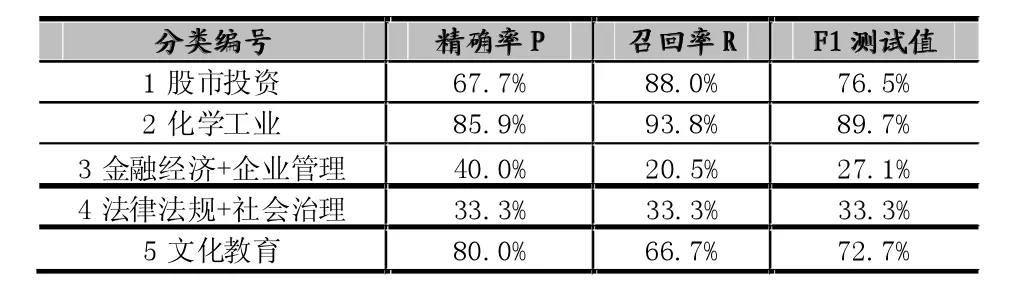
表9 类中心向量+自训练的半监督分类精度(测试数据)
为了保证试验的可比性,又取同样的数据进行了试验3,结果和试验2一样,用折线图来表示算法精确度对比情况:
为了更好地表示半监督分类算法的效果,本文又设计了一组半监督分类算法(贝叶斯+EM)试验,从表3可以看出朴素贝叶斯算法在对小样本数据集处理时表现出很差的分类效果,没有用平滑处理零概率文本,因此我们决定用期望最大化算法来训练贝叶斯分类器,期望通过这种组合,可以得出更好的分类效果。具体步骤如下:
1.仅采用标注集合L(部分训练数据)进行初始化训练,得到第一个中间分类器A0;
2.Estep:根据A0中的参数值计算所有类关于每个未标注样本(测试数据)的后验概率;
3.Mstep:利用包括了标注和未标注样本的训练集D以及P训练出新的中间分类器A1。
EM步骤一直迭代(迭代次数k=2或者3次),直到A1收敛,最终即可得到比较好的分类器。
还是使用相同的数据集,只不过这次单以测试数据作为建模对象,得出试验图4如下:

图3 半监督分类3次试验各测试值折线图

图4 贝叶斯+EM测试分类图
4 结语
通过观察半督分类结果可以发现,两次试验的测试精度有三类(分类编号为1,2,5)都达到了要求(F1测试值>70%),没有达到要求的两类都为数据样本稀少的小类(总共49篇、25篇,分类编号分别为3和4)。通过观察实验结果,还会发现上述几种方法在稀有类别上的准确性都较低,然而,KNN和类中心向量法对样本分布的稳定性要好于NB等方法。其中我们知道NB方法是基于假设一个特征单词在一个分类文档中的发生概率与该文档中的其他单词无关,从而使得计算复杂度简单,具有较高的效率。但是,该假设在现实中对于绝大多数文本都不能得到很好的保证,其中有的还出现了零概率的情况。故后来我们又采用了半监督的分类(贝叶斯+EM)的组合方法,通过试验对比,给出了相对较好的分类效果。
现实中,网络上大量的没有处理过的数据集在类别的分布上常常都是偏斜的,十分不均衡的,导致了分类效果很不理想。而实验环境下验证一个分类器效果好不好,用这种分类算法来训练分类器得到了改善,它们所选的数据集大都是均匀的,所以结论都得到很好的分类效果。如果在数据偏斜的情况下进行实验分类,分类器往往会忽视少量稀疏类的样本,因为样本无法准确反映整个空间的数据分布情况。通过查阅文献,得知Yang[9]研究的支持向量机(SVM)、NB及KNN等许多分类算法均控制了样本的分布,再做实验分析从理论上来对比分析分类效果与数据分布之间的关系,其结果大部分都表明:SVM和KNN对样本分布的鲁棒性要优于NB等方法,这也印证了SVM的泛化性能以及NB对类别先验概率的依赖性。这也是这些分类算法的缺陷,因为各种方法在稀有类别上的分类效果准确性均很低。本文就是在实验时,特意选择样本数据集有一部分是稀疏的做了实验,这一结论同样体现在我们的数据结果上。
[1]张俊丽.文本分类中关键技术研究.华中师范大学,2008.[4]孙丽华.中文文本自动分类的研究.哈尔滨工程大学,2002.
[2]张浩,汪楠.文本分类技术研究进展.计算机科学与技术.2007,23:95-96.
[3]卢苇,彭雅.几种常用文本分类算法性能比较与分析[J].湖南大学学报,2007.03.02.
[4]陈琳,王箭.三种中文文本自动分类算法的比较和研究[J].计算机与现代化,2011.06.15.
[5]汪传建,李晓光,王大玲,于戈.一种基于混合模型的文本分类器的设计与实现.计算机研究与发展增刊,2004,VoL41,96-100.
[6]DudaP E,Richard O.Hart,Pattern Classification and Scene Analysis[J].1973.
[7]李永平,程莉,叶卫国.基于隐含语义的KNN文本分类研究[J].计算机工程与应用.2004.
[8]Sebast,nai,.F,2002.Machine Learning Automated Text Categorization[J].ACM Computing Suvreys,34(1),1-47.
[9]Yang M H,Ahuja N.A Geometric Approach to Train Support Vector Machines[C].Proceedings of CVPR 2000.Hilton Head Island,2000:430-437.
Performance Comparison and Analysis of Several Text Classification Algorithms
YANG Juan,WANG Wei-yang
(College of Information Engineering,Shanghai Maritime Univeristy,Shanghai 201306)
Analyzes several typical text classification algorithms,gives five types of text data sets,the classic text categorization algorithm test comparison by precision,recall accuracy rate and test value to evaluate the performance of the text classifier,and gives the analysis result and the improved combination training method.The results show that the combination of semi supervised learning training and supervised learning can achieve better classification results.In order to improve the speed of text recommendation,the preliminary work is to choose the appropriate classification algorithm,combine selection algorithm to improve the accuracy and efficiency.
Text Categorization;Supervised Learning;Portfolio Selection;Recommendation
1007-1423(2016)25-0012-05DOI:10.3969/j.issn.1007-1423.2016.25.003
杨娟(1991-),女,安徽安庆人,硕士研究生,学生,研究方向为数据库开发与应用王未央(1963-),女,江苏常熟人,硕士研究生导师,副教授,研究方向为数据处理与挖掘
2016-04-19
2016-09-02
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
智富时代(2018年11期)2018-01-15
智富时代(2018年11期)2018-01-15
电子技术与软件工程(2017年14期)2017-09-08
