
基于感知哈希的作业相似度检测*
2016-10-20 13:25干丽萍楼宋江
台州学院学报 2016年3期
干丽萍,许 易,楼宋江,陈 盈
(台州学院 数学与信息工程学院,浙江 临海 317000)
基于感知哈希的作业相似度检测*
干丽萍,许易,楼宋江,陈盈*
(台州学院数学与信息工程学院,浙江临海317000)
现有抄袭检测多以文本的字符串匹配实现,无法检测图片作业,有一定局限性。提出一种将文本作业转化为图片,应用感知哈希算法获取图片特征值并计算图片相似度的方法,实现作业的抄袭检测。实验表明,该方法在一定的检测速度下,能保证低误判率和查准率。
抄袭检测;感知哈希;图像特征
0 引言
学习是人生中不可缺少的一部分,于学生而言更是如此。然而很多学生不是很明确学习的意义,在学习上总是得过且过,不求甚解,作业常常敷衍了事,或者直接抄袭。抄袭之风屡禁不止,甚至愈演愈烈,不仅仅是因为惰性,更是因为没有行之有效的检测方法。
长期以来,抄袭检测主要是依靠教师人工实现。然而受限于教师的精力与时间,抄袭检测有一定的难度。抄袭行为不但助长了学生的惰性,还会破坏教学秩序。教师难以从作业中得知学生对新知识的掌握情况。此外,教师在无法确定作业是否抄袭时只能根据作业的质量来进行打分,这就可能导致投机取巧的学生会有一个相对于认真完成作业的学生更好的成绩,容易伤害学生学习积极性。要从源头上遏制抄袭行为,就要让学生认识到抄袭要付出的代价,因此对于作业的相似度检测是非常重要的,实现抄袭检测的自动化更是必要的。
现有的学生作业抄袭检测系统主要借助字符串匹配算法和词频统计[1],是基于作业中的文本信息来进行对比检测的。这种方法准确性高,但在检测有大量文字的作业时运算量较大,且无法对图片作业进行检测。而通过将作业转化为图片,检测图片相似度以判断是否抄袭的方法则没有这种局限。由于作业易转化成图片,且不会改变作业的视觉信息,因此这种方法具有较高的可行性。
1 算法介绍
目前图片相似度检索的实现主要是应用“感知哈希算法”[2],该算法是基于人类感知模型,将图片唯一单向地映射为简短的数字摘要[3]。这种算法起源于数字水印技术,融合了多媒体中的认证、传统密码学中的哈希等理论与概念[4],将原本数据量较大的图片表示为简短的二值序列,在大量图像数据的检索中,不但降低了数据的存储成本,更缩短了检索时间。
衡量感知哈希算法性能的指标主要有抗碰撞能力、鲁棒性等[5]。抗碰撞能力强表现为感知内容不同的图片不会被映射为相同摘要,而鲁棒性则是取决于在经历图片格式、大小等不改变图片感知内容的变化后,图片是否仍映射为同一摘要。
自感知哈希被提出并有效地实现了可重复图像的检测后,研究者提出了众多优秀的算法,这些算法基于不同特征和编码,但其生成方案基本相同,如图1所示,分为特征提取、量化编码等步骤[6-7]。

图1 感知哈希序列生成流程图
图像是由像素点构成的,包含了大量细节信息,因此在进行特征提取前需要对图片进行一定处理,如统一图片规格、将图片转化成灰度图,以减少后续运算复杂度。
图像特征的提取是检测过程中的关键步骤[8],其图像表达能力将直接决定检测效果。早期感知哈希的特征提取大多是基于全局统计特征的[9],如颜色统计特征,这种方法的特点是简单易实现,但抗碰撞能力较差,不同的图像可能生成相同的特征值。后来研究者们不断对此进行改良研究,针对不同的应用领域提出了许多具有抗碰撞能力与鲁棒性的特征提取方法,如基于DCT变换的感知哈希[10]、基于图像特征点的感知哈希[11]等。
针对学生作业的特点,我们选择差异哈希来实现作业图片相似度的检测。该算法是在对图片进行预处理后比较相邻像素的亮度差,是基于渐变实现的,具有较好的图像表达能力,实现流程如下。


上一步提取出的特征值往往具有一定的冗余,为了便于存储与运算,需要对特征值进行量化与编码以得到尽可能短的哈希序列,以便于后续的应用。
由于学生在抄袭作业中鲜少有完全照搬的现象,而是或多或少地会做一些简单的小改动,因此不能只判断图像特征是否相同,还需要计算出作业图像的相似度。计算图片相似度可以通过计算哈希序列的汉明距离来获得:
其中,L为序列长度,H1和H2为两个哈希序列,⊕为异或运算。汉明距离越小说明两张图片越相似,抄袭嫌疑越大。
2 实验
2.1实验准备
共收集了100份《计算机网络实验》课的实验报告作为样本,其中10份实验报告已被验证为是抄袭作业,5份实验报告被认为具有抄袭嫌疑。该课程每个学期会安排6-8个实验,实验内容相对固定。在实验结束后学生需要上交PDF格式的实验报告,实验报告要求填写实验步骤、粘贴实验过程截图以及实验结果截图。由于实验报告填写比较繁琐,且实验步骤以及实验截图比较类似,有相当一部分同学选择直接复制粘贴他人作业以应付老师。
衡量图片重复检测性能的指标有许多,在作业检测中比较重要的是查全率 (Recall)、查准率(Precision)以及误判率(False Positive Rate)。部分学生为了避免抄袭行为被发现会拼接多份实验报告作为自己的作业,而查全率是检索出的图像占相似图像的比例。查准率描述了所有被检测出的图片中符合要求的图片所占比例,误判率则代表着不相似作业被判定为相似的概率。计算公式如下:
Recall=(检测出的相似图像)/(特征库中相似图像数量)*100%
Precision=(检测出相似图像数量)/(检测到的图像数量)*100%
FPR=(检测出的不相似图像数量)/(检测到的图像数量)*100%
2.2实验过程
在实验开始前需要设定两个阈值,一是确定抄袭的阈值,二是有涉嫌抄袭的阈值。在本次实验中我们设置确定抄袭的阈值为5,即汉明距离小于6的作业被认定为抄袭作业,而涉嫌抄袭的阈值为10,即汉明距离小于11且大于5的图作业被认为有抄袭嫌疑,需要教师进一步确认。
首先需要对样本图像进行预处理,将所有图片转化成相同大小的灰度图,并通过差异哈希函数生成哈希序列;其次需要计算出样本图像与特征库中哈希值的汉明距离,得出样本图像与所有特征库中图片的相似度。
若特征库中无大于相似度阈值的图片,则将该哈希序列加入特征库中,再重复上述步骤直至样本检测完成;若特征库中有相似度高于涉嫌抄袭阈值且低于确定抄袭阈值的图片,则需要将样本图片与相似图片输出,由教师人工进行判断,以确保误判率尽可能地低;若相似度高于确定抄袭阈值,则无需教师再进行判断,以减少教师工作量。实验流程如图2所示。

图2 抄袭检测流程图
以学生上交的“实验三服务器的构建与应用”实验报告中无抄袭嫌疑的文档A、文档B为例进行测验。首先将两份文档分别按页转化为7张、8张图片,利用差异哈希得出每张图片的哈希值并计算汉明距离,如表1所示。
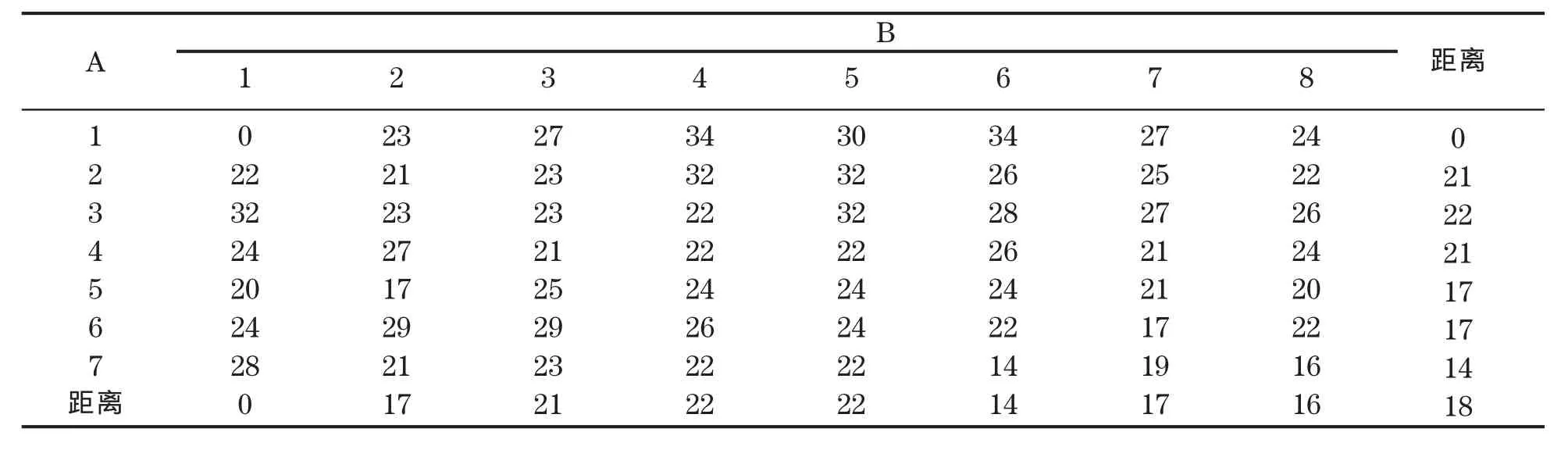
表1 文档A和B的汉明距离
表1中最右一列与最后一行是该行或该列中的最小值,表示在该页与另一份文档最大相似度。从表中数据可以看出两份文档的首页汉明距离为0,是相当相似的。这是由于实验报告的格式是固定的,文档首页内容相似,结构相同,因此在进行判定时可以忽略首页的汉明距离。表中剩余的几张图片汉明距离均大于10,相似度较低。
类似于文档A、B的检测过程,样本库中的文档图片将会与特征库中现有特征进行两两对比,检测出其平均相似程度,无抄袭嫌疑的图像特征值会逐渐加入特征库,形成一个不断更新的特征库,能够应用于后续的作业检测中。最终实验结果如表2所示。

表2 实验结果
2.3实验结果分析
表1中结构相同、内容略有不同的图片应用感知哈希得出的图片特征值相同,说明其具有一定的鲁棒性。而其余文档结构不同的图片计算出的汉明距离较大,说明算法的抗碰撞能力较好。
从表2可以看出,感知哈希算法的误判率较低,但查全率不是很理想。这是因为考虑到误判的危害以及教师的工作量而调整了涉嫌抄袭阈值,导致许多拼接作业难以被发现且难以查找出所有相似图片。另外,为了降低运算复杂度未对图像进行进一步的处理,导致有部分作业由于改变了页面布局而获得了较低的相似度。
综合考虑检测速度与有效性,差异哈希能够在保证较低误判率的情况下实现较理想的查找效果,比较适用于学生作业的抄袭检测。
3 结束语
通过比较作业图片的相似程度以进行作业检测,能够有效地解决传统作业检测方法无法检测包含图片作业的局限。本文将感知哈希应用于作业检测中,基于人类感知系统提取出作业图片的特征,将图像单向地映射为简短的二值序列,并通过比较哈希值进行检测。实验结果表明该方法的准确度较为理想,且计算复杂度低,存储量小,具有较好的应用价值。
但由于该方法考虑到计算复杂度而抛弃了大量细节信息,影响了检测效果。且差异哈希是基于渐变实现的,作业图片的布局可能会因为微小的变化而有较大变化,容易导致最后得出的哈希序列变化大,难以检测出真正与之相似的作业。今后将会继续优化感知哈希在作业检测中的应用,提高图像特征的表达能力,以获得更好的检测效果。
[1]陈荣钦,胡永良,应建健,等.在线评测系统中的源码相似度检测研究与实现[J].实验技术与管理,2014,31(4):109-111.
[2]Abraham A K,Haroon R P.An Improved Hashing Method for the Detection of Image Forgery[J].IOSR Journal of Computer Engineering,2014,6(5):13-19.
[3]牛夏牧,焦玉华.感知哈希综述[J].电子学报,2008,36(7):1406-1411.
[4]欧新宇,伍嘉,朱恒,等.基于深度自学习的图像哈希检索方法[J].计算机工程与科学,2015,37(12):2386-2392.
[5]潘辉,郑刚,胡晓惠,等.基于感知哈希的图像内容鉴别性能分析[J].计算机辅助设计与图形学学报,2012(07):925-931.
[6]唐坚刚,王泽兴.基于Hash值的重复图像检测算法[J].计算机工程,2009(01):183-185.
[7]周国强,田先桃,张卫丰,等.基于图像感知哈希技术的钓鱼网页检测[J].南京邮电大学学报(自然科学版),2012(04):59-63,69.
[8]翟俊海,赵文秀,王熙照.图像特征提取研究[J].河北大学学报(自然科学版),2009(01):106-112.
[9]宋宝林.基于图像特征的图像哈希算法及实现[D].济南:山东师范大学,2014.
[10]Ahmed F,Siyal M.A novel hashing scheme for image authentication[C].Proceedings of the 2006 Innovations in Information Technology,2006(11):1-5.
[11]崔得龙,左敬龙,彭志平.结合Harris角点检测和不变质心的稳健图像Hash算法[J].传感器与微系统,2011,30(5):30-33.
Perceptual Hashing Based Plagiarism Detection of Homework*
GAN Liping,XU Yi,LOU Songjiang,CHEN Ying*
(School of Mathematics and Information Engineering,Taizhou University,Linhai 317000,China)
Plagiarism detection system s are mainly detecting by matching the string w hich causes restrictions,for instance,image homework doesn't apply to these systems.This paper achieves the detection by using the perceptual hashing algorithm to get features of the images transformed from homew ork and calculating the sim ilarity of these features.The experiments show that the method keeps the detection speed while ensures precision rate and false positive rate.
Plagiarism detection;perceptual hashing;image feature
10.13853/j.cnki.issn.1672-3708.2016.03.003
(责任编辑:耿继祥)
2016-05-10;
2016-05-19
台州学院2015年度开放实验项目;台州学院2016年大学生创新创业训练计划项目(2016004)。
通读作者简介:陈盈(1981-),男,浙江诸暨人,讲师,硕士,主要从事智能信息处理方面的研究。
猜你喜欢
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
临床骨科杂志(2020年1期)2020-12-12
电脑爱好者(2020年20期)2020-10-22
郑州大学学报(理学版)(2020年3期)2020-08-25
制造技术与机床(2019年9期)2019-09-10
中国铁路文艺(2016年6期)2016-05-14
探测与控制学报(2015年4期)2015-12-15
电脑爱好者(2015年13期)2015-09-10
科技视界(2014年25期)2014-04-27
