
应用在线随机森林投票的动作识别
2016-10-10 01:24王世刚鲁奉军赵文婷赵晓琳
光学精密工程 2016年8期
王世刚,鲁奉军,赵文婷,赵晓琳,卢 洋
(吉林大学 通信工程学院,吉林 长春 130012)
应用在线随机森林投票的动作识别
王世刚,鲁奉军*,赵文婷,赵晓琳,卢洋
(吉林大学 通信工程学院,吉林 长春 130012)
提出了基于在线随机森林投票识别人物动作类别的方法。建立了在线随机森林投票模型。通过在线训练和在线检测两部分进行了算法研究, 提高了检测人物动作类别的准确率。基于人物动作在时间和空间上有重要信息,该方法首先通过提取图像立体块的lab色彩空间值、一阶差分、二阶差分以及大位移光流特征值在线训练随机森林;训练结束后,形成强分类器,利用分类器对检测图像进行投票,生成动作空间图;最后,在动作空间图中寻求最大值,判断检测图像的动作类别。验证结果表明在低分辨的视频图像中,本方法能够确定人物的动作类别,对Weizmann数据库和KTH数据库的识别率分别为97.3%和89.5%,对UCF sports数据库的识别率为79.2%,动作识别准确率有所提高。该方法增加了光流能量场特征表述,将原始投票理论拓展至三维空间,并且采用向下采样的方式更新结点信息,能够判断人物动作类别,为智能视频技术提供了有效的补充信息。
动作识别;随机森林投票;大位移光流;动作空间图;智能视频
*Correspondingauthor,E-mail:lufengjun2012@sina.com
1 引 言
人物的动作识别是计算机视觉的重要组成部分,通过分析视频图像中的人物特征判断动作类别,建立起特征数据与高层语义行为之间的关系人物动作通常利用摄像机拍摄获得。动作识别系统在智能视频、人机交互技术,体育竞技场景分析等方面有着广泛的应用。
动作识别系统将人物动作视为带有标记的特定视频图像序列,其主要包括视频图像预处理、人物特征提取、动作类别建模和分类器训练等多方面技术。其主要可分为时空特征方法和视频序列方法。早期的人物动作识别方法主要是针对单一静态背景视频序列的方法[1],其主要将视频图像作为连续的观察序列,计算人物产生某种动作的特征似然度,并判断检测序列的后验概率,从而确定人物动作行为。
最近时空特征方法已成为主流研究方法[2],其主要将兴趣点检测器和BOW(bag-of-words)的方法相结合,以增强人物动作的时空信息整合。视频图像在时间和空间方向上变化剧烈的特征点通常称为时空兴趣点,然后,通过聚类方法将特征向量形成时空单词集合,其经过训练得到时空单词模型,检测序列通过模型判断人物动作类别[3-5]。但是对于低分辨率、运动模糊和镜头移动的视频序列,这些方法识别人物动作比较困难。而且,系统还需要克服低分辨率视频图像的影响,适应人物动作的突变性和复杂性,提高抗干扰能力的特点。
随机森林分类器由于在训练和检测阶段中分类效率比较高,处理速度快,在行为识别领域受到了高度关注[6]。其分类方式主要在特征空间进行划分,在特定条件下对每个节点进行特征划分,这种方法的分类准确率取决于叶结点中数据类别的纯净度。
传统方法大多是基于人物的形态轮廓进行识别[7],对于复杂人体运动的分析描述并不准确。针对这问题,本文提出一种新颖的在线随机森林投票方法来确定人物的动作类别。本文引入了大位移光流能量场[8]特征信息,从而可以明显地区分人物动作的外在客观条件及内在姿态复杂性。
光流算法是通过计算区域像素的变化来捕获物体运动信息的[9],故可降低高层行为理解的复杂度,单像素的光流值计算较为困难,本文通过选取区域光流能量场作为特征提取的有用信息,以降低计算量。本文特征量值的优点如下:特征提取算法难度不高,可利用像素的底层信息作为特征的直接表述,与传统的基于轮廓外形特征的方法有明显区别,克服了传统特征表述信息表述不全面的缺点。随机森林能处理大量的高维数据,而且不会带来过度拟合问题,目前已经被广泛地应用到图像领域中[10-11]。其在目标检测中[12-13]已经成为一种重要的方法[14],但是在人物动作识别中的应用较少,这主要因为其难以提取能够表述人物运动的特征信息。在目标检测领域,随机森林将目标色彩信息、区域像素点一阶差分及二阶差分和目标方向梯度直方图作为训练特征信息。本文通过增加了光流能量场特征表述,将原始投票理论拓展至三维空间,并且采用向下采样的方式更新结点信息。最后,通过实验验证了算法性能。
2 算法结构
动作识别过程主要分为在线训练部分和在线检测部分。在线训练部分主要通过提取图像立体块的lab色彩空间信息、差分以及大位移光流特征值训练随机森林,训练结束后,形成强分类器;在线检测部分首先遍历测试样本图立体块,再利用随机森林分类器对测试样本图立体块进行分类,叶子结点为所在立体块进行投票,在动作空间图中寻找最大值,判断人物动作类别。算法流程图如图1所示。

图1 基于随机森林投票的动作识别算法流程图Fig.1 Flowchart of action recognition based on random forest voting algorithm
2.1在线训练过程
2.1.1图像处理
训练样本可分为正样本和负样本,正样本为已经标记边界框的人物的动作类别,如图2所示,图2(a)被标记为滑板动作,图2(b)被标记为跳水动作;负样本为无目标图像,如图3所示,图3(a)和图3(b)分别表示街道1和街道2。

(a)滑板动作 (b)跳水动作 (a)Skateboard (b)Diving 图2 正样本Fig.2 Positive samples

(a)街道1 (b)街道2(a)Street 1 (b)Street 2图3 负样本Fig.3 Negative samples

图4 立体块特征信息Fig.4 Feature information of cuboids
人物动作在时间和空间中均含有信息,将图像中的连续动作采用时空立体块表示,立体块的大小为16×16×5,它们分别表示立体块长和宽的像素长度以及图像帧数。如图4所示。
2.1.2目标区域大位移光流特征值
光流法能够描述运动物体的特征信息,以图像像素点的变化表述物体的运动信息,在目标运动图像表达中有着重要的作用[15]。大位移光流[8]是由Thomas Brox等首先提出的,其主要用于描述图像像素点实时变化。文中提出了基于亮度、空间梯度和平滑区域能量变化最小的光流模型,而且又增加了平移不变的特征变换(Scale Invariant Feature Transform,SIFT)和颜色描述子匹配的内容,其能量模型公式如下:
E=Ecolor+γEgradient+αEsmooth+βEmatch+Edesc.
(1)
模型的最终目标是寻找式(1)中两帧图像最小能量值变化值,其中,Ecolor表示相邻两帧图像亮度变化值,受光照影响,Ecolor表达的信息有限,因此,增加了空间梯度能量最小值Egradient。然而,Ecolor和Egradient较少表达描述性特征,单一估算这两部分的能量值并不能完善地表述光流场的特性,故又增加了平滑区域能量值Esmooth来避免光流场误算的问题。为了增加描述子特征的信息,将SIFT和色彩描述子作为匹配对象,能量的表达形式为Ematch和Edesc,可变参数α,β和γ用以适应不同帧图像的运动剧烈程度。图5表示光流场强度,5(a)和5(b)为两帧相邻图像,由图可知,两帧图像的人物运动变化较大,5(c)和5(d)分别表示在x、y方向的光流场强度值,由图5可知大位移光流特征值对于运动物体的信息表述更为准确。
2.1.3训练


(a) 当前图像 (b) 相邻帧图像(a) Current image (b) Adjacent frame of (a)

(c) x方向上的光流 (d) y方向上的光流(c) Optical flow in x direction (d) Optical flow in y direction图5 光流场强度Fig.5 Magnitude of optical flow field
其次,对提取的特征值进行分类,本文主要通过二值测试实现,具体过程如下:比较位置p∈R3和q∈R3中通道f上特征值的大小。在结点B的二值测试定义如下:
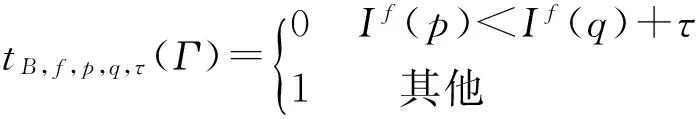
(2)
If(p)表示在特征通道f中位置p的特征值;tB,f,p,q,τ(Γ)表示在立体块中位置p和q特征值的比较值,τ为设定阈值。在同一特征通道f下,比较不同位置处的特征值将立体块分为两大类,每一类继续通过二值测试进行二分类,构成了二值测试集合{tk},其中k表示集合的数量。
对二值测试集合中的立体块需要进行最佳分类,通过随机森林分类器进行分类,随机森林F由决策树{T1,T2,…,TN}构成,N表示决策树的数目,每一棵决策树的函数形式为f(x;Θ):X→Y,Θ表示在树的分裂结点中定义参数,x∈X⊆Rd表示特征值。
在训练过程中,训练样本集合表示为{xi,yi}∈{X,Y},其中yk∈{1,2,…,K},K表示动作类别的数目。随机森林的构建是一个递归过程,对于树中的每个结点,通过计算信息增益ΔH或者立体块中心偏移值ΔD寻求最佳分裂函数ζ(·),其中ΔH表示为:

(3)

立体块中心偏移值用ΔD表示,其数学表达式为:
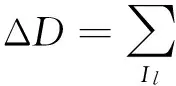
(4)

图6 向下取样流程图Fig.6 Flowchart of subsamples


2.2在线检测过程
2.2.1随机森林投票理论
在目标检测方面,随机森林投票方法应用较为广泛,其主要思想是,通过有监督学习方法,将二维图像块特征信息和随机森林投票建立映射联系,利用叶子结点判断目标类别。本文通过对其进行扩展,将随机森林的投票表决方法与三维图像立体块信息相结合进行描述。
以位置x∈R3为中心的立体块表示为p(x)=(I(x),c(x),d(c(x),x))。其中:I(x)表示立体块特征,c(x)表示立体块的未知动作类别,d(c(x),x)表示立体块中心到未知动作中心矢量。Qc(y)表示图像中任意一点y∈R3处具有动作类别c的事件。根据贝叶斯公式推导出的条件概率p(Qc(y)|I(x))表示如下:
c,I(x))p(c(x)=c|I(x))=p(d(c,x)|c(x)=c,I(x))p(c(x)=c|I(x)).
(5)

p(Qc(y)|I(x),T)=

(6)
其中G(·)表示三维高斯窗函数。
对整个随机森林T投票平均处理,得到(7)式:

(7)
2.2.2动作空间图


图7 动作空间图Fig.7 Spatial graph of different actions
图7(彩图见期刊电子版)表示UCF sports数据库的动作空间图,红色虚线表示鞍马运动连续帧图像的检测结果,红色小矩形框表示随机森林对鞍马运动其中一帧投票的结果。动作空间图能够准确判断此动作为鞍马运动。
3 实验结果及分析
本文实验的硬件运行环境为Intel Pentium(R) Dual-Core CPU、物理内存2G的PC机;软件的运行环境为Ubuntu系统,借助Opencv2.0开源计算机视觉库训练随机森林分类器。
实验中从国际标准人物动作数据库中选用3组测试样本,其中包括单人静态背景下的Weizmann数据库和KTH数据库,以及单人动态背景下UCF sports数据库。
3.1Weizmann数据库、KTH数据库和UCF sports数据库
Weizmann数据库[17]中含有10种不同的动作类别,其中每组动作由9个不同的表演者分别实现。本实验将每组动作中的8个视频序列作为训练序列,第9个视频序列作为检测序列,每次实验重复9次,保证每个表演者都被检测,最后将检测结果取平均值作为最终判断结果。Weizmann数据库的检测结果如图8所示。

图8 Weizmann数据库混淆矩阵Fig.8 Confusion matrices for Weizmann dataset
KTH数据库[18]中含有6个不同的动作类别,这6个动作由25个表演者在4个不同的场景下拍摄所得。本文将同一人在4个不同场景下的同类动作视为动作完整图像序列,并将20个表演者的完整图像序列作为训练序列,剩下的5个用于检测,以每5组一轮换的方式进行训练和检测,最后将检测结果取平均值作为最终判断结果。KTH数据库的检测结果如图9所示。

图9 KTH数据库混淆矩阵Fig.9 Confusion matrices for KTH dataset
UCF sports数据库[19]含有10组不同的动作类别,每组动作由15个不同的视频序列组成。本文在每类动作中依次选取5大组,大组轮换次数为15;每大组中又包括5个小组,其中4个小组作为训练序列,剩下1组作为检测序列,小组轮换次数为5,最后计算检测结果的平均值。UCF sports数据库的检测结果如图10所示。

图10 UCF sports数据库混淆矩阵Fig.10 Confusion matrices for UCF sports dataset
3.2动作分类比较结果
BOW算法把已提取的人体局部轮廓作为特征信息,通过K均值聚类算法将特征分为K类;则在视频中的每帧图像形成长度为K的特征向量。本文主要与随机森林在词袋模型BOW中应用的方法进行对比。词袋中的特征向量通过随机森林(Random Forest,RF)和支持向量机(Support Vector Machine,SVM)进行分类识别,文中将这两种方法分别称为BOW+RF和BOW+SVM。根据词袋外数据误差进行分析,又可形成RF-1方法[7]。考虑到提取轮廓特征信息的维数比较大,RF-1算法应用PCA(Principal Component Analysis)算法对特征信息进行降维,其在随机森林中使用决策树的数目为500。另外,还选用文献[5]基于时空兴趣点的人体动作识别方法进行对比。

表1 各方法在Weizmann、KTH和UCF sports 数据库的比较结果
本文不需要对特征维数进行降维,构造的决策树数目为15棵,将本文算法与其他算法的实验结果进行比较,如表1所示。由表1可知,本文方法在Weizmann数据库的识别率达97.3%,KTH数据库识别率达89.5%,较为复杂的UCF sports数据库识别率达72%。结果表明,本文算法识别效果高于其他算法。
4 结 论
针对人物动作识别的问题,本文提出了一种应用在线随机森林的动作识别方法,重点介绍了大位移光流特征的提取方法,并构建了随机森林和在线检测方法。实验结果表明:在低分辨率的视频图像中,本文方法对简单动作数据库Weizmann和KTH的识别率分别为97.3%和89.5%,对复杂动作数据库UCF sports的识别率为79.2%。该方法能够判断人物动作类别,将为智能视频技术提供了有效的补充信息。
[1]SCHULDT C, APTEV I, CAPUTO B. Recognizing human actions: a local SVM approach[C].IEEE,Proceedingsofthe17thInternationalConferenceonPatternRecognition,Cambridge,theUnitedKingdom,2004:32-36.
[2]DOLLAR P, ABAUD V R, COTTRELL G,etal.. Behavior recognition via sparse spatio-temporal features [C].VisualSurveillanceandPerformanceEvaluationofTrackingandSurveillance,Beijing,P.R.China. 2005:65-72.
[3]付朝霞,王黎明. 基于时空兴趣点的人体行为识别[J]. 微电子学与计算机, 2013,30(8): 28-35.
FU ZH X, WANG L M. Human action recognition based on space-time interest point [J].Microelectronics&Computer, 2013,30(8):28-35. (in Chinese)
[4]王博,李燕. 视频序列中的时空兴趣点检测及其自适应分析[J]. 计算机技术与发展, 2014,24(4): 49-56.
WANG B, LI Y. Space-time interest points detection in video sequence and its adaptive analysis [J].ComputerTechnologyandDevelopment, 2014, 24(4):49-56. (in Chinese)
[5]王世刚,孙爱朦,赵文婷,等. 基于时空兴趣点的单人行为及交互行为识别[J].吉林大学学报(工学版),2015,45(1): 304-308.
WANG SH G, SUN A M, ZHAO W T,etal.. Single and interactive human behavior recognition algorithm based on spatio-temporal interest point [J].JournalofJilinUniversity(EngineeringandTechnologyEdition), 2015, 45(1): 304-308. (in Chinese)
[6]鲍一丹,陈纳,何勇,等. 近红外高光谱成像技术快速鉴别国产咖啡豆品种[J].光学 精密工程, 2015, 23(2): 349-355.
BO Y D, CHEN N, HE Y,etal.. Rapid identification of coffee bean variety by near infrared hyperspectral imaging technology [J].Opt.PrecisionEng., 2015, 23(2): 349-355. (in Chinese)
[7]蔡加欣,冯国灿,汤 鑫,等. 基于局部轮廓和随机森林的人体行为识别[J]. 光学学报, 2014, 34(10): 1015006(1-10).
CAI J X, TANG G C, TANG X,etal.. Human action recognition based on local image contour and random forest[J].ActaOptocaSinica, 2014, 34(10): 1015006(1-10).(in Chinese)
[8]BROX T,MALIK J. Large displacement optical flow: descriptor matching in variational motion estimation [J].IEEE,TransactonsonPatternAnalysisandMachineIntelligence, 2011, 33(3): 500-513.
[9]徐富元, 顾国华, 陈钱, 等. 转动红外探测器下地面远距离运动目标检测方法[J]. 红外与激光工程, 2014, 43(4): 1080-1086.
XU F Y, GU G H, CHEN Q,etal.. Ground target detection method on rotating infrared detector[J].InfraredandLaserEngineering, 2014, 43(4): 1080-1086. (in Chinese)
[10]向涛, 李涛,李旭东,等. 基于随机森林的层次行人检测算法[J]. 计算机应用研究,2015,32(7): 2196-2199.
XIANG T, LI T, LI X D,etal.. Random forests for hierarchical pedestrian detection [J].ApplicationResearchofComputers, 2015, 32(7): 2196-2199. (in Chinese)
[11]屠大维,江济良. 改进的光流运动图像分析方法及其应用 [J].光学 精密工程, 2011,19(5):1159-1164.
TU D W, JIANG J L. Improved algorithm for motion image analysis based on optical flow and its application [J].Opt.PrecisionEng, 2011,19(5):1159-1164. (in Chinese)
[12]刘翔, 杨鑫, 王蕾. 改进的基于码本模型目标检测算法[J]. 液晶与显示, 2014,29(6): 999-1002.
LI X, YANG X, WANG L. Object detection algorithm based on improved codebook model [J].ChineseJournalofLiquidCrystalsandDisplays, 2014,29(6): 999-1002. (in Chinese)
[13]林培杰, 郑柏春, 陈志聪, 等. 面向多区域视频监控的运动目标检测系统[J]. 液晶与显示, 2015,30(3): 484-491.
LI P J, ZHENG B CH, CHEN ZH C,etal.. System of multi-regions moving object detection in video surveillance [J].ChineseJournalofLiquidCrystalsandDisplays, 2015,30(3): 484-491. (in Chinese)
[14]胡梦婕,魏振忠,张广军. 基于对象性测度估计和霍夫森林的目标检测方法[J]. 红外与激光工程, 2015, 44(6): 1936-1941.
HU M J, WEI ZH ZH, ZHANG G J. Object detection method based on objectness estimation and Hough forest[J].InfraredandLaserEngineering, 2015, 44(6): 1936-1941. (in Chinese)
[15]赵海,陈星池,王家亮,等. 基于四轴飞行器的单目视觉避障算法[J].光学 精密工程, 2014,22(8): 2232-2241.
ZHAO H, CHEN X CH, WANG J L,etal.. Obstacle avoidance algorithm based on monocular vision for quad-rotor helicopter [J].Opt.PrecisionEng., 2014 22(8): 2232-2241 . (in Chinese)
[16]JUERGEN G, VICTOR L. Class-specific Hough forests for object detection [C].IEEETransactionsonComputerVisionandPatternRecognition,Miami,theUnitedStates2009:1022-1029.
[17]BLANK M, GORELICK L, SHECHTMAN E,etal.. Actions as space-time shapes[C].IEEEInternationalConferenceonComputerVision,Beijing,China, 2005.
[18]SCHULDT C, LAPTEV I, CAPUTO B. Recognizing human actions: a local SVM approach[C].Proceedingsofthe17thInternationalConferenceonPatternRecognition,Cambridge,UK, 2004.
[19]RODRIGUEZ M, AHMED J, SHAH M. Action mach-a spatio-temporal maximum average correlation height filter for action recognition[C]. 2008IEEEConferenceonComputerVisionandPatternRecognition,Anchorage,AK, 2008.

鲁奉军(1991-),男,吉林德惠人,硕士研究生,2013年于吉林大学获得学士学位,主要从事数字图像处理、机器学习等方面的研究。E-mail: lufengjun2012@sina.com
(版权所有未经许可不得转载)
Action recognition based on on-line random forest voting
WANG Shi-gang, LU Feng-jun*, ZHAO Wen-ting, ZHAO Xiao-lin, LU Yang
(CollegeofCommunicationEngineering,JilinUniversity,Changchun130012,China)
An action recognition method for people is proposed based on on-line random forest voting to judge the action classification. The on-line random forest voting model is established and its algorithms are researched through the two parts consisting of on-line training and on-line detection to improve the precision of the action classfication. As people action shows important information in both space and time, the method firstly trains the random forests in line by extracting 3D image features containing a lab color space , the first order difference, the second order difference and displacement optical flow. After training, a strong classier is formed. Then, the classifier is used to vote for detection images to produce an action space map. Finally, by seeking the maximum in the map, the category of action in the detection images is complemented. Experimental results indicate that the method determines the category of people action in the low resolution video images. The accurate rates of the Weizmann data, the KTH data and the UCF sport data are 97.3%,89.5%,and 79.2%,respectively. These results show that the accuracy of action recognition is improved. Moreover, the model proposed adds the feature representation of light flow energy field, expands the traditional forest voting theory to a 3D space, and uses to update information. It improves the stability and the reliability and will be of potential application in the intelligent video surveillances.
action recognition; random forest voting; large displacement optical flow; action map; intelligent video
2015-11-09;
2015-12-14.
教育部博士学科点专项科研基金资助项目(No.20120061110091);吉林省科技发展计划资助项目(No.20150204006GX);长春市科技局资助项目( No.14KG007)
1004-924X(2016)08-2010-08
TP391.4
A
10.3788/OPE.20162408.2010

王世刚(1962-),男,吉林长春人,教授,博士生导师,1983年于东北大学获得学士学位,1997年于吉林工业大学获得硕士学位,2001年于吉林大学获得博士学位,研究方向为数字图象处理技术及应用。E-mail: wangshigang@vip.sina.com
猜你喜欢
导航定位学报(2022年5期)2022-10-13
民族古籍研究(2018年1期)2018-05-21
作文大王·笑话大王(2017年1期)2017-02-21
作文大王·笑话大王(2016年10期)2016-10-18
作文大王·笑话大王(2016年7期)2016-08-08
作文大王·笑话大王(2016年2期)2016-02-24
新校长(2016年8期)2016-01-10
浙江大学学报(工学版)(2015年1期)2015-03-01
中北大学学报(自然科学版)(2014年3期)2014-11-22
中国铁道科学(2014年6期)2014-06-21
