
基于视觉词典和位置敏感哈希的图像检索方法
2016-09-23 07:56:18孙晓峰彭天强
河南工程学院学报(自然科学版) 2016年3期
孙晓峰 ,彭天强
(1.河南工程学院 国际教育学院,河南 郑州 451191; 2.河南工程学院 计算机学院,河南 郑州 451191)
基于视觉词典和位置敏感哈希的图像检索方法
孙晓峰1,彭天强2
(1.河南工程学院 国际教育学院,河南 郑州 451191; 2.河南工程学院 计算机学院,河南 郑州 451191)
当前视觉词袋(Bag of Visual Word,BoVW)模型中的视觉词典均由k-means及其改进算法在原始局部特征描述子上聚类生成,但随着图像数据的迅速增长,在原始局部特征空间中进行聚类存在着运行时间较长和占用内存较大的问题.针对着这些问题,提出了一种基于视觉词典和位置敏感哈希的图像检索方法.首先,选择合适的生成二进制哈希码的哈希算法,将局部特征点保持相似性地映射为二进制哈希码.然后,在二进制哈希码上进行k-means,生成视觉词为二进制码的视觉词典.最后,用视觉单词的词频向量表示图像内容,根据词频向量对图像进行检索.在SIFT-1M和Caltech-256数据集上的实验结果表明,本方法可以缩短视觉词典生成的时间,占用更少的存储空间,与传统的基于k-means的视觉词典算法相比,图像检索性能基本不变.
二进制哈希码;视觉词袋模型;局部特征;二进制视觉词典;图像检索
随着大数据时代的到来,互联网图像资源迅猛增长,如何对大规模图像资源进行快速有效检索的问题亟待解决.图像检索技术由早期的基于文本的图像检索(Text-based Image Retrieval,TBIR)逐渐发展为基于内容的图像检索(Content-based Image Retrieval,CBIR),CBIR通过提取图像的视觉底层特征来实现图像内容的表达.视觉底层特征包括基于梯度的图像局部特征描述子,如SIFT[1](Scale-Invariant Feature Transform)、HOG[2](Histogram of Orientated Gradients)等.局部特征能够表征图像的底层视觉特征,被大量用于图像内容的分析.在基于局部特征的图像检索中,视觉词袋法(BoVW)[3]是主流的图像内容表示方法.BoVW的主要流程:①局部特征提取,一般提取SIFT特征;②视觉词典生成,采用聚类算法对局部特征进行聚类得出;③量化,将单幅图像的各局部特征量化为视觉单词;④创建直方图,根据视觉词典创建各图像视觉单词频向量,得到的词频向量用于表示图像,作为图像的特征进行图像的检索和识别等.
在上述视觉词袋法的流程中,关键在于第二步——视觉词典的生成,而第二步一般采用k-means聚类算法及其相关的改进算法[4]直接对图像的局部特征进行聚类,聚类得出中心构成视觉词典.k-means聚类算法需要对数据集中所有局部特征点进行多次迭代运算,而且每次迭代都需要将特征点分配到与之最近的聚类中心.在数据集规模较大时,聚类时间和内存消耗会急剧增加(其时间复杂度为O(nk),k是聚类数目,n为特征点数目).为了加快视觉词典的构建速度,Mu等[5]提出了基于位置敏感哈希[6](Locality Sensitive Hashing,LSH)构建视觉词典,该算法不需要聚类,利用LSH生成视觉词典.类似地,赵永威等[7]采用精确欧式位置敏感哈希(Exact Euclidean Locality Sensitive Hashing,E2LSH)对局部特征点进行聚类,生成多个视觉词典并加以融合.以上两种方法虽然避免了使用聚类方法生成视觉词典,但是采用了随机的哈希方法生成视觉词典,导致生成的视觉词典随机性太强,需要生成多个视觉词典组并加以融合才能达到不错的效果.
针对以上问题,提出了一种基于视觉词典和位置敏感哈希的图像检索方法,基本思想是利用保持相似性的二进制哈希码代替原空间的特征进行聚类算法生成视觉词典,即将原始特征变换到Hamming空间中,在Hamming空间再做一次聚类操作,生成视觉词典.这样,既利用了二进制哈希码在计算速度和存储空间上的优越性,又找到了一种原特征点与二进制视觉词之间的变换方法,降低了视觉词典的随机性.
1 位置敏感哈希
位置敏感哈希按照其应用可以分为两类[8]:一类是以一个有效的方式对原始数据进行排序以加快搜索速度,这种类型的哈希算法称为二进制哈希(Original LSH);另一类是将高维数据嵌入Hamming空间,进行按位操作以找到相似的对象,这种类型的哈希算法称为“Binary Hashing” .二进制哈希可以为每一个对象产生二进制编码,通过二进制码的Hamming距离来度量两个对象的相似性和距离,Hamming距离还可以保持原始对象间的欧氏距离.
二进制哈希方法可以分为无监督的哈希算法、半监督的哈希算法和监督的哈希算法.无监督的哈希方法不考虑数据的标签信息,包括Isotropic Hashing[9](PCAH)、谱哈希[10](Spetral Hashing,SH)、PCA-ITQ[11]等;半监督的哈希方法考虑部分相似性信息,包括半监督哈希方法[12](Semi-Supervised Hashing,SSH) ;监督的哈希方法利用数据集的标签信息或者相似性点对信息作为监督信息,包括BRE[13](Binary Reconstructive Embedding)、监督的核哈希[14](Kernel-Based Supervised Hashing,KSH)等.这些二进制哈希算法的目标均是寻找能够较好地保持特征在原空间中的相似性信息且能够生成紧致二进制码的哈希函数.由于半监督和监督的哈希方法需要数据的类别标签信息,适用性具有一定的限制,所以考虑使用无监督的哈希方法,而在无监督的哈希方法中PCA-ITQ的性能最优.所以,本研究利用PCA-ITQ方法学习哈希函数.
2 基于视觉词典和哈希方法的图像检索
2.1多索引哈希技术
多索引哈希技术[15](Multi-Index Hashing,MIH)通过为二进制码建立索引结构,在Hamming空间中可以快速进行精确的r邻域搜索.它的基本思想是将维度为q的二进制哈希码h划分成m个不相交的子串h(1),…,h(m),分别为每个子集建立哈希结构.搜索与Hamming距离小于r的近邻域g,g需要满足在m中的某个子串中,h和g之间的Hamming距离不超过r′,其中r′=⎣r/m⎤.将在高维Hamming空间中r邻域的搜索问题转化为在较低维度空间中进行半径更小的r′邻域问题,在较低维空间中进行较小半径的邻域搜索,速度更快.
2.2基于二进制哈希码的k-means算法
Gong等[16]提出了一种基于二进制哈希码的聚类算法,用于大量图像的分类.它的主要流程为首先利用深度学习算法为每张图像提取特征,然后利用保持相似性的哈希算法将高维的深度特征映射为二进制哈希码,并用二进制编码作为图像的特征表示进行聚类.
基于二进制哈希码的k-means算法的目标函数为

(1)
该目标函数类似于k-means算法的目标函数,只是聚类中心和样本均为离散的二进制值,该优化可以利用EM算法来求解.首先,需要将每个二进制哈希码分配到与之最近的聚类中心,对当前二进制编码的情形可以通过多索引哈希技术(MIH)加快该处理过程.然后,更新二进制聚类中心,可以通过求解问题(1)的最优解得到其计算公式.
仅考虑某个聚类中心,问题(1)优化问题可转化为

(2)
由于式(4)中第一项和第二项均为常数值,问题(4)的最小化问题可以转化为等价的最大值问题:
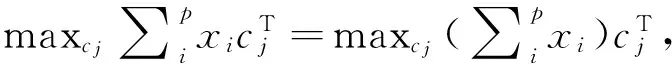
(3)
问题(3)有解析形式的最优解且其最优解为
(4)
2.3基于二进制视觉词典的图像检索
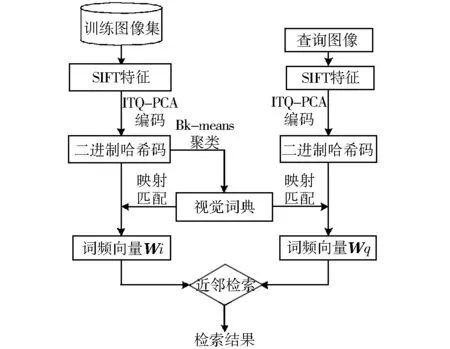
图1 基于二进制视觉词典的图像检索流程Fig.1 The flow chart of image retrieval for binary-based visual vocabulary
基于二进制视觉词典的图像检索流程见图1.基于二进制视觉词典的图像检索分为视觉词典生成和图像检索两个阶段,与传统的BoVW图像检索方法的区别在于,视觉词典是二进制哈希码及局部特征点需要变换到汉明空间转化为二进制哈希码.二进制视觉词典的生成过程如下:
(1)提取图像集中各图像的SIFT特征;
(2)从SIFT特征点集中选择样本点,训练生成PCA-ITQ哈希方法所需参数;
(3)根据(2)得到的参数,利用PCA-ITQ算法将SIFT特征集转化为二进制哈希码;
(4)根据2.2中基于二进制哈希码的聚类算法,将二进制哈希码聚成k类(k为事先指定的视觉词典的单词数目);
最后,得到的k个聚类中心构成了二进制视觉词典.
利用上述(2)中的参数将图像集各图像局部特征点转化为二进制哈希码,然后根据二进制视觉词典统计图像集各图像二进制哈希码的词频生成图像集的词频向量组.
图像检索过程,主要包括:①提取查询图像的SIFT特征;②利用PCA-ITQ哈希算法将SIFT特征点转化为二进制哈希码;③根据视觉词典统计二进制哈希码的词频,生成查询图像的词频向量组;④计算查询图像词频向量和图像集词频向量的相似度;⑤进行相似度排序,确定相似图像.
3 实验与性能评价
3.1实验
为验证本方法的有效性,在SIFT-1M[17]、Caltech-256[18]图像集上对本方法进行了评估.SIFT-1M包含1 000 000个128维的局部特征点;Caltech-256图像集是目标分类任务中常用数据集,包含256个类别共计30 608张图像,其中每个类别中至少包含80张图像.
实验用单机的硬件配置为3.4 GHz的双核CPU、16 G的内存.图像检索性能指标采用MAP(Mean Average Precision),它表示所有图像查准率的平均值.其中,查准率定义如下:

(5)
3.2实验性能分析
为验证基于二进制哈希码的聚类算法(Bk-means)的有效性,在SIFT-1M数据集上与传统的k-means算法进行比较.首先,在SIFT-1M数据集中随机选出10 000个样本,训练生成PCA-ITQ算法所需参数;其次,利用PCA-ITQ算法将SIFT-1M数据集转化为64 bit的二进制哈希码;然后,利用2.2中基于二进制哈希码的聚类算法进行聚类,测试它聚类所用的时间.在SIFT-1M数据集上测试在设置不同的聚类个数的情况下,Bk-means算法和k-means算法的所用时间,实验结果如表1所示.
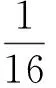
为验证基于二进制视觉词典的检索方法在图像检索中的有效性,在Caltech-256图像集上进行了实验.在特征点个数N不同的情况下,测试基于Bk-means的视觉词典生成算法和基于k-means的视觉词典生成算法,在视觉词典生成时间和检索结果MAP上作比较,结果见表2.
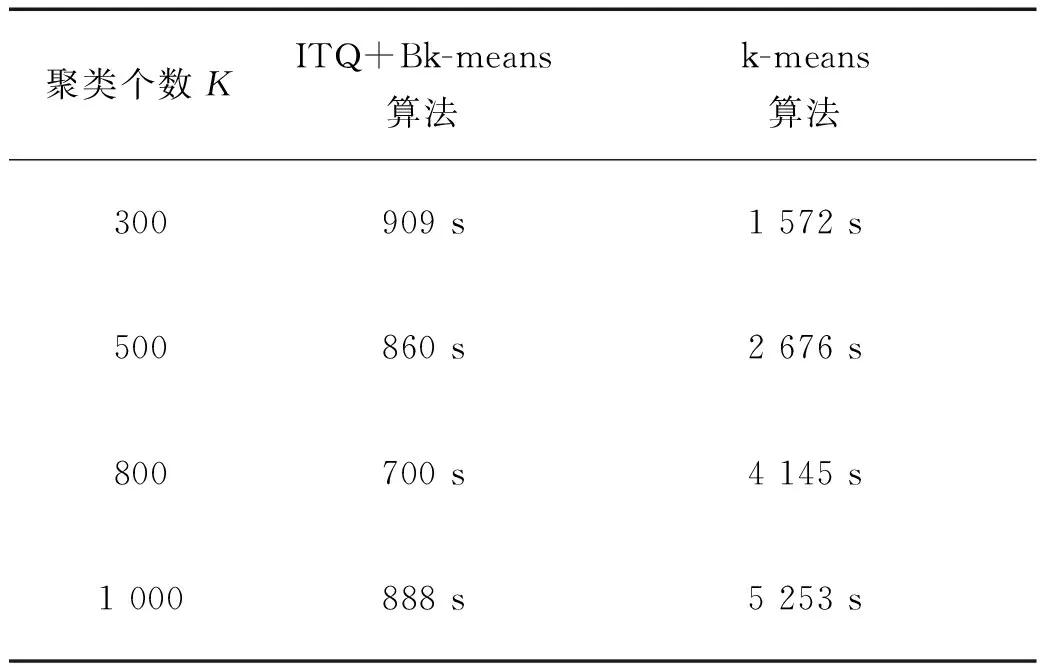
表1 在数据集SIFT-1M上聚类时间对比
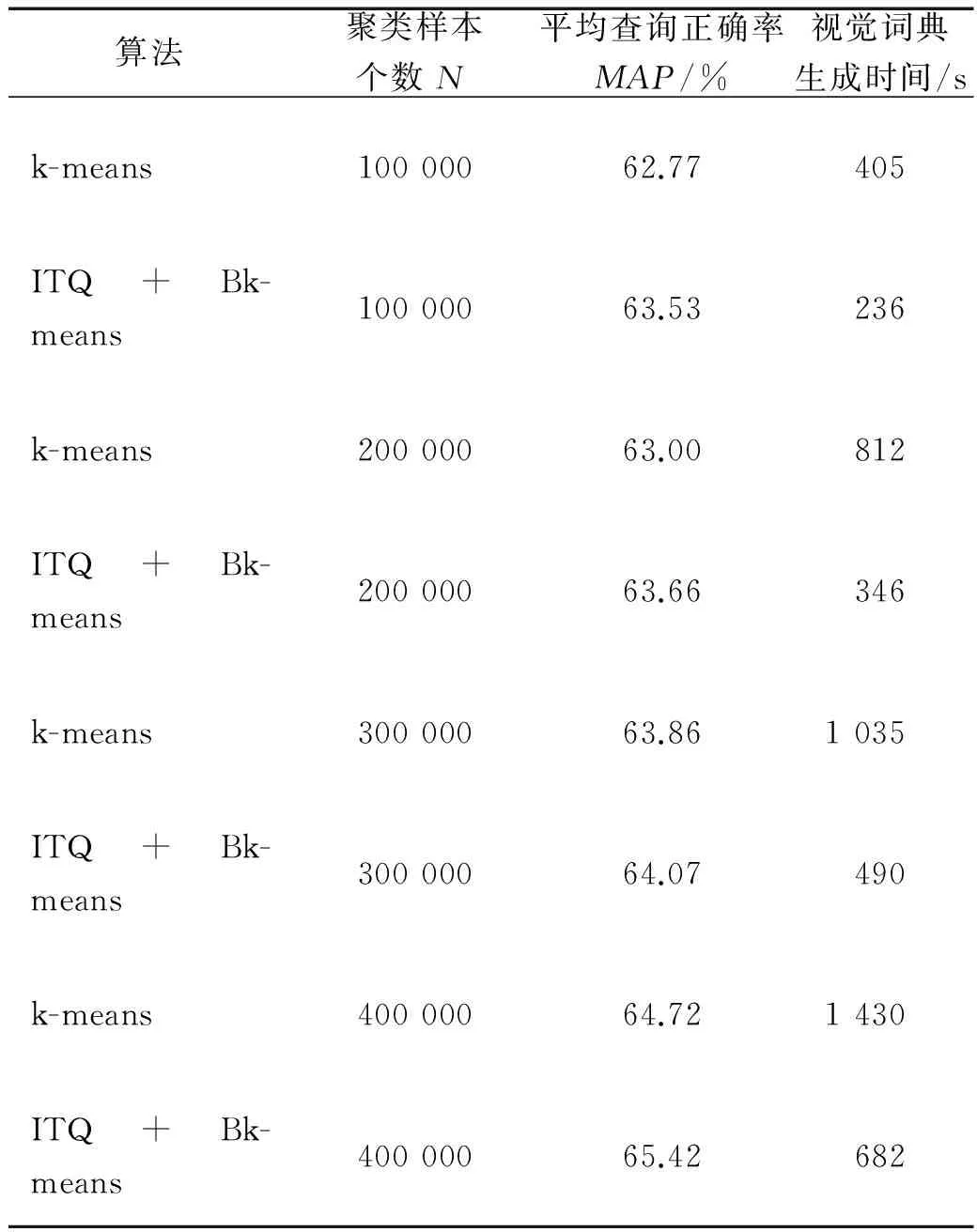
表2 不同特征点个数的图像检索MAP值和视觉词典生成时间对比
从表2中可以看出,在不同的特征点N的情况下,基于传统k-means算法生成视觉词典所用时间是基于二进制哈希码生成视觉词典所用时间的2倍.随着N的增加,基于传统k-means的视觉生成算法所用时间增加速度快于基于Bk-means的视觉词典生成算法.
4 结语
提出了一种基于视觉词典和局部敏感哈希的图像检索方法.首先,为了充分利用二进制哈希码在存储和计算速度上的优越性,选择无监督的PCA-ITQ算法将原始空间中的局部特征点保持相似性地映射为二进制哈希码.然后,在二进制哈希码上进行k-means,生成视觉词为二进制码的视觉词典.最后,用二进制视觉单词的词频向量表示图像,根据词频向量对图像进行检索,实验结果有效地验证了本方法的图像检索精度损失不大,但是在运行时间和存储空间上有较大的优势.
[1]DAVID G,LOWE.Distinctive image features from scale-invariant key points[J].International Journal of Computer Vision,2004,60(2): 91-110.
[2]DALAL N,TRIGGS B.Histograms of oriented gradients for human detection[C]∥Computer Vision and Pattern Recognition,San Diego,CA:IEEE,2005:886-893.
[3]SIVIC J,ZISSERMAN A.Video Google:a text retrieval approach to object matching in videos[C]∥Proceedings of 9th IEEE International Conference on Computer Vision,Nice:IEEE,2003:1470-1477.
[4]FRANK M,ERIC N,FREDERIC J.Randomized clustering forests for image classification[J].Pattern Analysis and Machine Intelligence,IEEE Transaction on Pattern Analysis and Machine Intelligence,2008,30(9):1632-1646.
[5]MU Y D,SUN J,TONY X,et al.Randomized locality sensitive vocabularies for bag-of-features model[C]∥European Conference on Computer Vision,Heraklion Crete:FORTH,2010:748-761.
[6]DATAR M,IMMORLICA N,INDYK P,et al.Locality sensitive hashing scheme based on p-stable distributions[C]∥Proceedings of the ACM Symposium on Computational Geometry,New York:ACM,2004:253-262.
[7]赵永威,李弼程,彭天强,等.一种基于随机化视觉词典组合查询扩展的目标检索方法[J].电子与信息学报,2012,34(5):1154-1161.
[8]ZHANG L,ZHANG Y D,ZHANG D M,et al.Distribution-Aware Locality Sensitive Hashing[M].Berlin:Springer-Verlag Berlin Heidelberg,2013:395-406.
[9]KONG W H,LI W J.Isotropic hashing[C]∥Advances in neural information processing systems,Lake Tahoe:NIPS Foundation,2012:1646-1654.
[10]YAIR W,ANTONIO T,ROB F.Spectral Hashing[C]∥I Advances in neural information processing systems,Vomcouver,BC:NIPS Foundation,2009:1753-1760.
[11]MU Y D,LAZEBNIK S,GORDO A,et al.Iterative quantization:a procrustean approach to learning binary codes for large-scale image retrieval[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2012,35(12):2916-2929.
[12]WANG J,KUMAR S,CHANG S F.Semi-Supervised hashing for large scale search[J].IEEE Transaction on Pattern Analysis and Machine Intelligence,2012,34(12):2393-2406.
[13]KULIS B,DARRELL T.Learning to hash with binary reconstructive embeddings[C]∥Advances in neural information processing systems,Vomcouver,BC:NIPS Foundation,2009:1042-1052.
[14]LIU W,WANG J,JI R R,et al.Supervised hashing with kernels[C]∥Computer Vision and Pattern Recognition,Rhode Island:IEEE,2012:2074-2081.
[15]NOROUZI M,PUNJANI A,FLEET D J.Fast search in hamming space with multi-index hashing[C]∥Computer Vision and Pattern Recognition,Rhode Island:IEEE,2012:3108-3115.
[16]GONG Y,PAWLOWSKI M,YANG F,et al.Web scale photo hash clustering on a single machine[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,Boston:IEEE,2015:19-27.
[17]JEGOU H,DOUZE M,SCHMID C.Product quantization for nearest neighbor search[J].Pattern Analysis and Machine Intelligence,2011,33(1):117-128.
[18]FERGUS F F L R,PERONA P.Learning generative visual models from few training examples:an incremental Bayesian approach tested on 101 object categories[J].Computer Vision and Image Understanding,2007,106(1):59-70.
Image retrieval based on visual vocabulary and locality sensitive hashing
SUN Xiaofeng1, PENG Tianqiang2
(1.Department of International Education,Henan University of Engineering,Zhengzhou 451191,China;2.CollegeofComputer,HenanUniversityofEngineering,Zhengzhou451191,China)
Currently, visual vocabulary in the bag of visual word(BoVW) model is often generated either by the k-means algorithm or its improved algorithms based on original local features, but with the increasing amount of image data, clustering in the original local feature space have the problem of long running time and large memory occupation. For these problems, we propose an image retrieval method based on visual vocabulary and locality sensitive hashing. Firstly, we select an appropriate binary hashing algorithm, which map the similar local feature points onto similar binary hash codes. Second, we play k-means on the binary hash codes and generate the visual vocabulary with binary visual word. Finally, the image is represented with the word frequency vector of visual words, and image retrieval is achieved based on the word frequency vector. Experimental results on SIFT-1M and Caltech-256 data sets show that the proposed method can reduce the visual vocabulary generation time and take up less storage space. Compared with the traditional image retrieval based on k-means, the image retrieval performance is almost the same.
binary hashing code; bag of visual word model; local feature; binary visual vocabulary; image retrieval
2016-04-18
国家自然科学基金(61301232)
孙晓峰(1981-),女,黑龙江哈尔滨人,讲师,研究方向为图像检索.
TN391.4
A
1674-330X(2016)03-0064-05
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
中等数学(2021年8期)2021-11-22 07:53:38
数学大王·低年级(2019年10期)2019-11-25 08:23:26
中等数学(2019年4期)2019-08-30 03:51:44
工业设计(2016年8期)2016-04-16 02:43:34
计算机工程(2015年8期)2015-07-03 12:20:04
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
图书馆论坛(2014年8期)2014-03-11 18:47:59
计算机工程(2014年6期)2014-02-28 01:25:40
