
针对JavaScript攻击的恶意PDF文档检测技术研究
2016-09-23 06:00:32胡江周安民
现代计算机 2016年1期
胡江,周安民
(四川大学电子信息学院,成都 610065)
针对JavaScript攻击的恶意PDF文档检测技术研究
胡江,周安民
(四川大学电子信息学院,成都 610065)
恶意PDF文档;JavaScript代码;静态检测;特征提取
0 引言
PDF(Portable Document Format)是便携式文档格式的简称,是由Adobe公司所开发的一种独特的跨平台的文件格式,在Windows、Unix或者Mac OS中,PDF文件都是通用的。然而,正是由于PDF文档的可移植性、兼容性、封装性和免费性,它成为了互联网上攻击者传播恶意代码的主要载体[1]。最常用的方式就是利用电子邮件,通过社会工程学,让用户主动打开恶意PDF附件,从而感染受害者电脑。PDF文档常被攻击者利用的另一个重要原因是它拥有自己的JavaScript引擎,并允许在PDF文档中嵌入JavaScript代码,此功能意味着PDF能够执行复杂的任务如形式验证和计算。然而,它也使攻击者拥有了运行任意代码的途径,攻击者可以利用恶意的JavaScript代码发起攻击。塞门铁克的一份安全报告表明,通过PDF文档来执行恶意功能时,90%都使用了JavaScript代码,因此在检测恶意PDF文档中,能否准确识别JavaScript代码尤为重要,大部分嵌入的JavaScript代码在一定程度上进行了混淆编码,这样,不但增加了人工分析的复杂度,而且连防病毒软件也难以检测出来。现阶段的检测技术主要有以下几种方法:
(1)对PDF文档的物理结构[2]进行解析,并根据数据流对象进行解压缩操作,通过解压后的数据,进行全局匹配,例如匹配/JS、/OpenAction等关键字段,然后通过确定规则判断是否为恶意文档。
(2)JScan模型[3],这是一种动态检测模型,该模型是将异常JavaScript代码检测和仿真结合起来,异常检测通常是基于对特定函数的监控,例如eval,从而达到对恶意代码的自动识别的目的。
由于上述方法(1)中,很多恶意样本是混淆或者加密过的,所以单单进行解压缩后可能还是一些密文,造成检测效率很低。而且很多正常PDF文档也会有JavaScript代码,所有这样检测很容易造成较高的误报率。方法(2)由于使用了大量的仿真技术,所以该检测系统会造成大量的资源消耗,所以通用性不强。本文通过对PDF文档格式进行深入解析,对PDF文档中流对象的压缩算法与加密算法进行自动判断,以及对解密后JavaScript代码进行完整的预处理,形成有效的特征向量集,并在此基础上建立规则特征库,最后综合判断是否为恶意PDF文档。
1 PDF文档检测模型
1.1PDF文档格式解析
PDF文档是一种文本和二进制混排的格式,它的文件结构主要是由文件头(header)、文件体(body)、交叉引用表(cross-reference)和文件尾(tailer)组成。
(1)文件头
文件头是用来标识PDF文档的版本,它出现在PDF文件的第一行。如%PDF-1.6表示该文件格式符合PDF 1.6规范。
(2)文件体
文件体主要包含了PDF文档的主题内容,各部分之间是由对象方式(obj)呈现,这些对象构成了PDF文档的具体内容如字体、页面、图像等。基本格式如下所示:
70 obj
〈〈/Kids[5 0 R]/Type/Pages/Count 1〉〉
endobj
其中7 0 obj中的7是对象序号,是用来唯一标记一个对象;0是生成号,是和对象序号一起标记其是原始对象还是修改后的对象。其中obj和endobj是对象的定义范围。而对象obj的类型有很多种,例如根对象(Catalog)、页集合(Page)、图片对象(Xobject)、字体对象(Font)、流对象(stream)。
其中流对象里面保存了所有的二进制内容,JavaScript很多也是加密混淆后放入流对象中,因此它是本文重点关注对象,图1说明了数据流在obj中的表现形式。

图1 stream在obj中的形式
其中Dictionary又包含了常用字段Length,该字段表示关键字组合stream和endstream之间字符串的长度,Filter字段表明stream中使用的编码算法,常用的算法有 Flate、JPEG、ASCIIHex、LZW、CCITTGroups,DecodeParms[4]表示一个参数字典,供Filter使用。例如:
10 obj
〈〈/Filter/FlateDecode/Length 336〉〉
stream
data
endstream
endobj
其中336表示流数据(data)的大小,FlateDecode表示数据流的解码算法,即著名的zip压缩算法。
(3)交叉引用表
交叉引用表是为了能对对象进行随机存取而设立的对象地址的索引表 ,主要目的是为了快速定位PDF文档中的各对象。
(4)文件尾部
文件尾部包含了交叉引用的摘要和交叉引用表的起始位置。例如startxref 1946%%EOF,其中1946就是交叉引用表的偏移地址,EOF为结束标志。
1.2基于JavaScript的攻击方式
嵌入PDF中的恶意JavaScript代码主要是通过PDF阅读器(例如Adobe Reader)的漏洞来将正常的执行控制流指向植入的恶意JavaScript代码中去的。这个控制过程一般可以通过Heap Spraying技术实现。使用JavaScript代码进行的另一恶意活动是从互联网下载可执行文件到受害者机器上来初始化一个攻击。此外,JavaScript代码也能打开一个恶意网站来对受害者机器进行一系列的恶意操作。然而攻击者在利用JavaScript进行攻击时,一般使用了代码混淆技术,以防止被基于特征关键字的检测器识别出来。因此,在检测时,需要进行代码还原。
1.3基于JavaScript的攻击特征向量集提取
在分析大量基于JavaScript攻击的PDF样本文件后,发现了一些共同的特征。
第一条,PDF对象中经常出现/JavaScript,/JS,/S等关键词或“JavaScript”字符串时,就表明该文件包含了JavaScript代码,此时,再结合/AA,/Type/Action,/Open-Action,/URL,/GOTO,/launch,/Acroform等关键词的行为就可以判定PDF文档的性质,当然一些正常的文件也可能会有JavaScript,因此建立规则应该排除一些正常的特征,减少误差。
第二条,这种攻击一般是利用了PDF阅读器的漏洞,并使用堆喷射技术,堆喷射技术一般会包含一些典型特征,例如0c0c,0a0a,%u,spray,crypt等字符串、一些通用函数 (fromCharCode,eval,unescape和replace)来混淆代码,以及一些常用的存在漏洞的典型函数(getIcon(),Collab()等)。
第三条,从恶意代码嵌有Shellcode过程中来分析特征,例如恶意代码中的单词“for”,“while”出现的次数一般是确定的;文件流中JavaScript代码一般通常拥有超过四十个单词的代码,这个长度值通常要在uneacape()函数中返回;并且使用堆分配的方式创建相同大小的内存块许多次,数据一般用NOP填充字段,shellcode功能主体组成。
通过上述对基于JavaScript攻击的PDF样本文件分析,提取出一个确定特征向量集的模型,该模型特征提取主要是通过对恶意PDF进行大量分析,其中包括解压缩与解密各个PDF文件流对象,定位并提取JavaScript代码,形成大量特征向量,最后借鉴恶意软件匹配利器YARA[5]创建规则,例如,检测字符串、正则表达式、常用shellcode中的API函数以及一些混淆函数等。
具体特征向量集模型如图2所示:
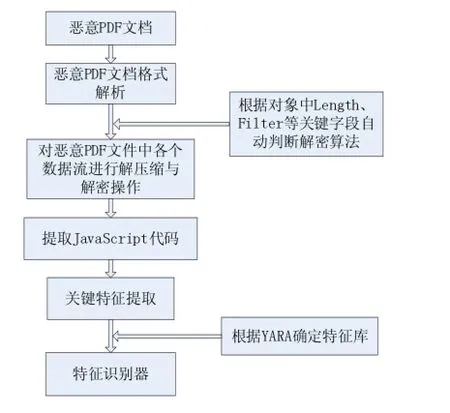
图2 特征向量集确定模型
1.4基于JavaScript攻击的PDF文档检测系统
基于上述研究结果,提出了基于 JavaScript攻击技术的PDF文件检测模型,其流程示意如图3所示。
该检测系统在对未知PDF文件检测时,首先对PDF二进制流映射到内存,对文档格式深入进行解析,主要是对各个流对象进行扫描,标识一些恶意PDF常用字符串,以及统计各个流对象的大小以及压缩算法,常用的有Flate、ASCLLHex,并对各个流对象数据进行自动解压缩与加密,在结合一些关键字段,如/Javascrip,/JS,/S,定位到 JavaScript,定位 JavaScript后自动判断是否有有编码,若有进行解码操作,其后判断是否有混淆,若有混淆,则进行去混淆操作,最后提取JavaScript代码中的特征向量集,与已有的特征识别器进行对比,判断出结果。
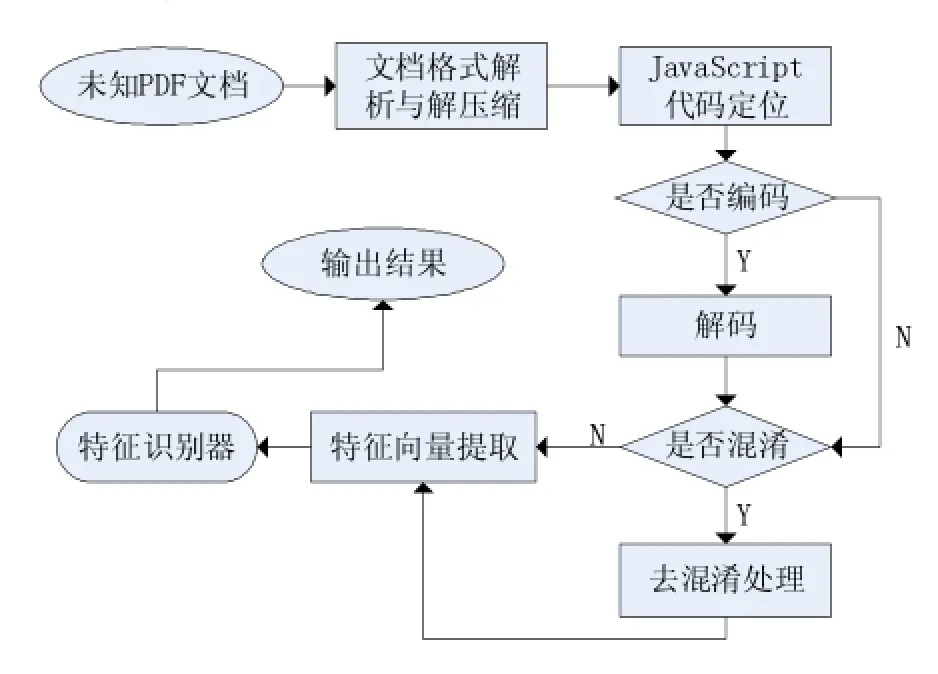
图3 PDF文件检测模型
2 系统有效性分析
为了验证系统的有效性,对多个PDF文件进行了测试验证,在测试中,共选取了100个PDF文件,其中恶意样本40个,来自metasploit、Virustotal[6]、secuelist[7],都是基于JavaScript攻击的样本,正常样本60个。并分为10组测试,每组10个。测试环境为Windows 7 64位。图4是第一组的样本文件。
通过PDF检测系统后,结果如表1所示。

表1 第一组样本分析结果

图4 其中一组的样本文件
表1中文件属性是指文档本身是否为恶意文档,M(Malicious)为恶意样本,N(Normal)为正常样本。因此如表1所示,第一组样本中有恶意样本3个,用检测系统测试后发现,第一组的恶意样本都能检测出来。
用同样的的方法测试了其他9组数据,现将数据结果(漏报个数,误报个数)用表2示意。
其根据表1、2所示,100个测试样本中,2个样本属于漏报,4个样本属于误报。因此其误报率与漏报率都在接受范围内,特别是对于恶意样本,检测效率很高。
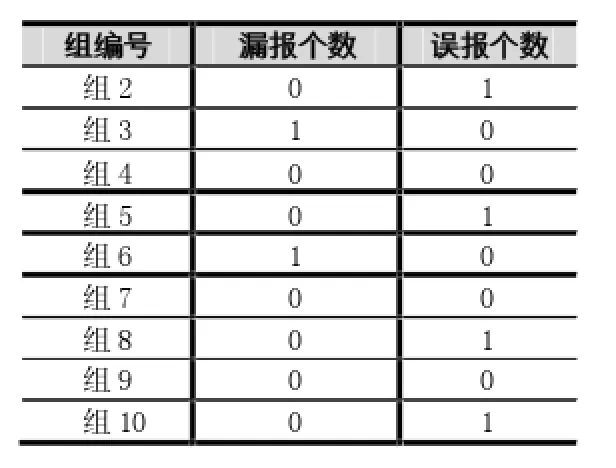
表2 其他9组测试数据结果
3 结语
实验表明该系统的检测结果与实际PDF文档属性相符合,并且检测时间很迅速,说明基于JavaScript攻击的样本检测系统的可行性,未来会在特征提取以及特征规则上进一步优化,以提高PDF检测效率。
[1]Lu Xun,Zhuge Jianwei,Wang Ruoyu,Cao Yinzhi,Yan Chen.De-Obfuscation and Detection of Malicious PDF Files with High Accuracy [J].System Science(HICSS),2013(1):1530-1605.
[2]Tzermias Z,Sykiotakis G,Polychronakis M,et al.Combining Static and Dynamic Analysis for the Detection of Malicious Documents Proceedings of the Fourth European Workshop on System Security.ACM,2011:4.
[3]Laskov P,rndi N.Static Detection of Malicious JavaScript-bearing PDF Documents Proceedings of the 27th Annual Computer Security Applications Conference.ACM,2011:373-382.
[4]丁晓煌.恶意PDF文档的静态检测模型技术研究.西安:西安电子科技大学,2014.
[5]武学峰.恶意PDF文档的分析.山东:山东大学,2012.
[6]Securelist,http://www.securelist.com/en/
[7]Virustotal,https://www.virustotal.com
Malicious PDF Documets;JavaScript Code;Static Detection;Feature Extraction
Research on Malicious PDF Documents Detection Technology Based on JavaScript Attack
HU Jiang1,ZHOU An-min2
(Department of Electronic Information,Sichuan University,Chendu 610065)
胡江(1991-),男,四川达州人,硕士研究生,研究方向为信息系统安全理论与技术
周安民(1963-),男,四川成都人,硕士生导师,研究方向为信息安全关键技术和核心产品工程2015-11-20
2015-12-20
当今社会,便携式文档(PDF)已经成为恶意代码传播的主要载体,而90%的恶意PDF样本都是基于JavaScript攻击的。因此针对JavaScript攻击的恶意样本检测是非常有必要的。介绍PDF的结构,以及常见的嵌入JavaScript的恶意PDF文档攻击手段,在此基础上,提出一种基于JavaScript攻击的恶意PDF文档检测方法,并实现基于该方法的检测系统,主要包括PDF文档格式深入解析模块、JavaScript代码定位与提取模块、恶意特征提取模块。实验表明该系统能有效检测PDF恶意文档。
In today's society,portable document(PDF)has become the main carrier of the spread of malicious code,while 90%of the malicious PDF sample are based on JavaScript attacks.So it is necessary to detect the malicious sample based on JavaScript attack.Introduces the structure of PDF files and attack method based on JavaScript code.Based on this research,proposes a malicious PDF document detection method based on JavaScript attack and realizes the detection system,which mainly includes the parsing module of PDF file format, JavaScript code location and extraction module,malicious feature extraction module.Experiments show that this system can effectively detect malicious PDF document.
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
自动化学报(2021年8期)2021-09-28 07:20:18
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
爱你(2018年16期)2018-06-21 03:28:44
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
