
Git版本库全文检索系统的设计与实现
2016-09-20 08:14高毅任洪敏
现代计算机 2016年21期
高毅,任洪敏
(上海海事大学信息工程学院,上海 201306)
Git版本库全文检索系统的设计与实现
高毅,任洪敏
(上海海事大学信息工程学院,上海 201306)
随着Git版本控制系统应用的日益广泛,Git版本库中的文档资料也越来越多。基于Lucene的Git版本库搜索引擎针对Git版本库中的文件建立索引并进行搜索。该搜索系统通过Git的钩子机制异步地建立索引,在检索时使用了基于J2EE的架构。首先对Lucene、jGit等相关工具包进行研究,然后对索引模块、检索模块等进行设计,最后编程实现和测试分析。系统实现的Git版本库中文件的全文检索,为Git版本库提供Web化的检索方式,同时也是对Lucene应用领域的探索。
Git;Lucene;全文检索;搜索引擎
0 引言
Git是Linus开发的一个用于Linux内核代码管理的分布式版本控制工具[1]。基于Git的客户端管理工具如Git bash能用命令的形式对版本库中文件进行查找,但这种方式使用不方便、也不直观。为版本库提供一种Web化的检索方式,将提升用户检索的体验。
针对版本库中文件数据的特征,全文检索技术是管理这些数据的有效方式,它能根据文件的内容进行处理和定位。Lucene是实现全文检索的工具包,为实现Git版本库的检索提供了可能[2]。
本文通过研究Lucene在各个领域的应用,结合开源框架Spring和Spring MVC[3],设计了Java EE架构的全文检索系统。改进了Lucene的分词器,更好地支持中文分词;使用开源的文本抽取工具Tika为文本内容抽取提供了统一的编程接口;将Git钩子和Java异步编程结合,实现了异步索引;设计并实现了针对Git版本库中的海量数据的全文检索系统。
1 系统结构与功能分析
1.1 系统结构
全文检索是一种将文件中的所有文本与检索项匹配的文字资料检索方法[4]。一般包括索引程序根据文件内容建立索引、检索程序根据用户的搜索关键字对已建立的索引进行查找并反馈查找结果等步骤。
本系统按照全文检索理论针对Git版本库为用户提供全文检索服务。在系统结构上有索引数据库数据搜集、处理查询及展示结果集等全文检索核心功能。Git仓库及访问、索引引擎、查询引擎、文本分析引擎及Web相关功能构成了整个系统。本系统结构如图1所示。
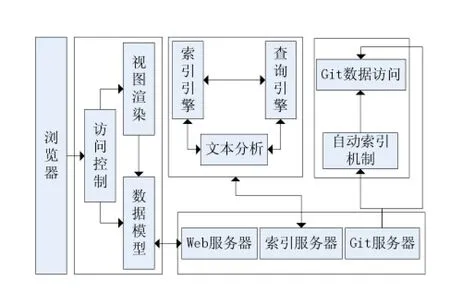
图1 系统结构
1.2 功能分析
本系统主要实现了Git仓库的异步索引和检索两大主要功能。其中,异步索引功能是针对用户的提交操作触发Git钩子,由钩子脚本调用索引模块完成Git仓库的索引的创建。在异步索引的过程中,要经过数据提取与转换模块、文本分析模块才能建立索引。这是由于在Git仓库中可能包含多种格式的文件,如txt、html、word、excel、pdf等,而Lucene的索引机制只能对文本文件建立索引[5],所以在做索引之前必须做数据转换,即提取各种格式文件的文本信息,这一功能由数据提取与转换模块完成。在提取文本数据之后,要由分词器对文本信息做分词处理,该功能由文本分析模块完成。
检索功能是本系统的核心功能。用户通过检索页面输入检索关键字提交检索请求后,经过文本分析模块、查询模块后将匹配结果集返回。各模块流程如图2所示。
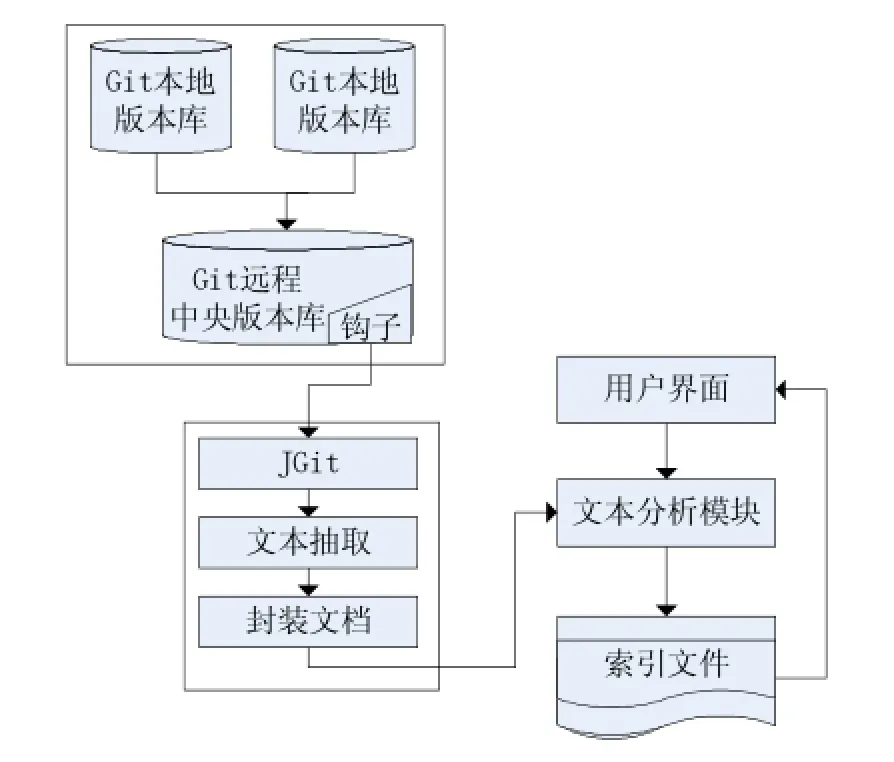
图2 模块流程图
2 系统设计
2.1 Git钩子和异步索引机制【6】
在Git版本库的版本库目录下有一个hooks目录,该目录是Git版本库的钩子脚本目录,也是实现所有与钩子相关功能的关键。这些钩子脚本能在特定的条件下被触发,从而可以利用该机制设计基于钩子的异步索引。在共享版本库中我们使用的是“update”脚本,要使该脚本生效只要去掉其文件的扩展名.sample即可。
在本系统中在共享版本库中设置该钩子,在本地的版本库向其推送时触发脚本,执行索引程序。工作流程如图3所示。
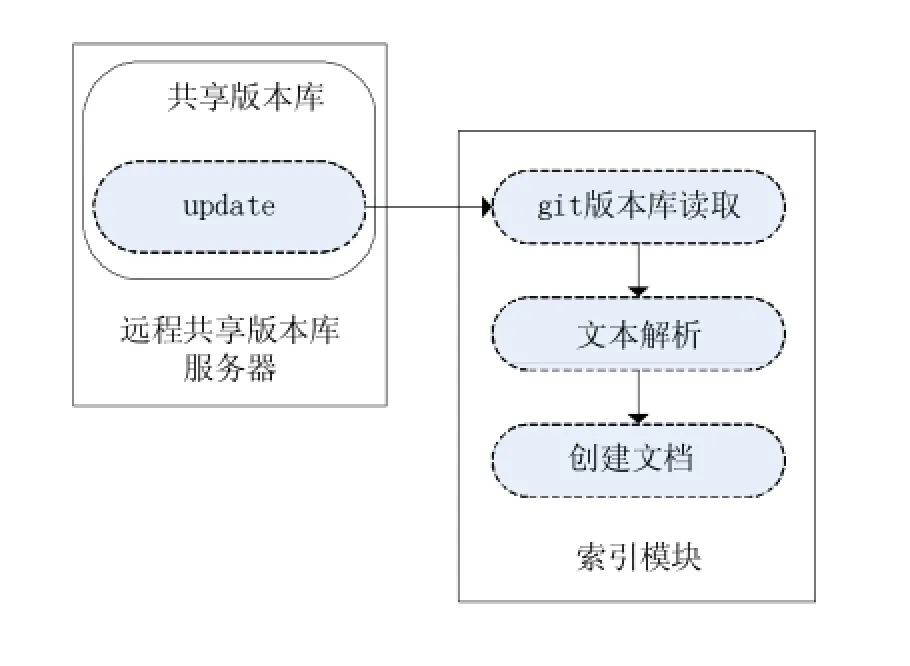
图3 基于钩子的异步索引机制
2.2 增量化索引
在Lucene中增量索引是指每次有新的数据源要索引时只对新增的数据做索引而不需改变原来的索引数据。根据Git版本库的特点,本系统采用增量索引的方式做索引。在一次提交中可能包含若干发生变化的文件,采用增量索引,只对这些发生变化的文件做索引。这种索引方式不仅提高了索引的效率,对于检索的查全率也有重要影响[7]。
做增量索引时,首先要获取在一次提交中发生变化的文档的集合,然后遍历该集合,删除与每一个文档相关联的对象块。下一步又分为两种情况,若发生变化的文档的变化类型是被删除的,则不做任何索引处理;若是其他变化类型,如修改,则对该文档重新建立索引。总之索引数据库中保存的总是文档的最新修改状态的数据形式。逻辑流程如图4所示。
2.3 文档解析模块设计
文档解析是指通过相关的工具对各种格式的文档进行转换并解析出文本内容。文档解析模块的意义在于为索引文档提供统一的数据格式。在Git版本库中可能存在有各种格式的文档如word、excel、pdf及普通的txt文档,使用jGit工具读取Git版本库中的数据后,可以得到字节数组形式的数据。Lucene内部只能对纯文本格式的数据建立文档,而对于其他类型的文档,不能建立索引,这也是做文档解析的必要性所在。故在做索引前必须将各种类型的文档转换成文本文档。通过分析Lucene的API发现其提供了文档类型的描述类Document类和关于域信息的描述类 Field类,其中Document代表被索引的一个文档,Field代表文档的一个域信息,如文档内容等。也就是说在实际使用时我们不必将各种格式的文档转换为文本文档,只需提取出各类型文档的文本内容即可。文档解析模块是索引的前提和基础,如果不能顺利提取文本内容索引也将无法建立。
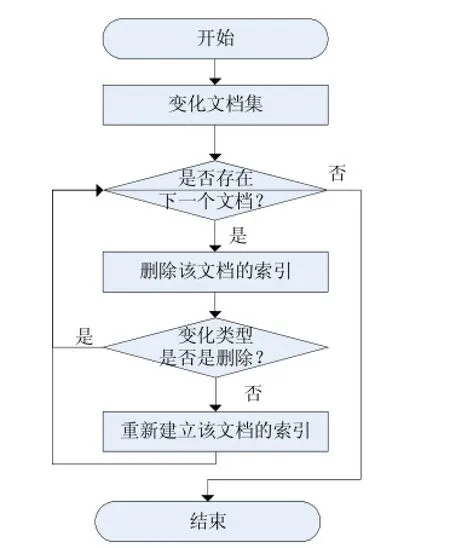
图4 增量索引逻辑流程图
文档解析的实现逻辑[8]:
文档解析模块使用解析框架Tika,Tika是使用Java语言实现的并且是Apache下的开源项目。它能探测并从各种常见的文件中提取包括文本和元信息在内的数据。多文档解析的示意图如图5所示。
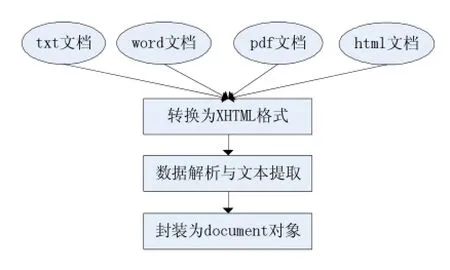
图5 文档解析流程
3 系统实现
3.1 异步索引的实现
“update”脚本在整个推送过程完成后运行。修改该脚本后大致内容如下:
#!/bin/sh
refname="$1"
cd$GIT_DIR/tool
uname=$(git config--get user.name)
java-Duser=$uname -Dbranch=$refname -Dfile. encoding=utf-8-jar index.jar
该脚本能在本地仓库向远程仓库推送完成后执行,执行过程中首先接收参数refname,其代表推送的分支。然后调用索引模块index.jar完成索引的构建。
在索引时使用了Java线程池和FutureTask类:
ExecutorService executorService = Executors.new-FixedThreadPool(5);
Task task=new Task();
FutureTask<Integer>futureTask=new FutureTask<>(task);
executorService.submit(futureTask);executorService.shutdown();
3.2 增量索引的实现
通过分析增量索引的逻辑流程,可知要实现增量索引首先要获取在一次提交中发生变化的文档集,获取文档集的核心代码如下:
//the list of files changed in a commit
List<PathChangeModel>list=new ArrayList<PathChange-Model>();
......
List<DiffEntry>diffs=df.scan(parent.getTree(),commit. getTree();
for(DiffEntry diff:diffs){
//create the path change model
PathChangeModel pcm=PathChangeModel.from(diff,commit.getName();
if(calculateDiffStat){
//update file diffstats
df.format(diff);
PathChangeModel pathStat=df.getDiffStat(). getPath(pcm.path);if(pathStat!=null){
pcm.insertions=pathStat.insertions;pcm.deletions=pathStat.deletions;}
}
list.add(pcm);
}
然后遍历该文档集,删除每个文档对应的索引:
//delete the indexed blob
deleteBlob(repositoryName,branch,path.name){
......
}
接下来判断变化文件的变化类型,若是删除则什么也不做;若不是则重建索引。
//re-index the blob
if(!ChangeType.DELETE.equals(path.changeType){
//the file deleted is not indexed
result.blobCount++;
Document doc=new Document();
doc.add(new Field(FIELD_OBJECT_TYPE,SearchObjectType.blob.name(),StringField.TYPE_STORED);
......
//file name
doc.add(new Field(FIELD_NAME,path.name,TextField. TYPE_STORED);
//determine extension to compare to the extension //blacklist
String ext=null;
String name=path.name.toLowerCase();if(name.indexOf('.')>-1){
ext=name.substring(name.lastIndexOf('.')+1);}
if(StringUtils.isEmpty(ext)||!excludedExtensions.contains(ext){
//read the blob content
Stringstr= JGitUtils.getStringContent(repository,commit.getTree(),path.path,encodings);
if(str!=null){doc.add (new Field (FIELD_CONTENT,str,TextField.TYPE_STORED);writer.addDocument(doc);}
}
}
3.3 文档解析的实现
通过在设计章节对文档解析模块的分析,本系统使用开源的文本提取工具Tika提取各种格式文档的文本数据,它为文本抽取提供了统一的编程接口。实现文本抽取的核心代码如下:
①ByteArrayInputStream in=new ByteArrayInput-Stream(content);
②ContentHandler contentHandler=new BodyContentHandler();
③Metadata metadata=new Metadata();
④Parser parser=new AutoDetectParser();
①中是读取被解析的文件保存在字节数组content中,这时在程序内部会建立XHTML形式的数据结构,然后②中创建一个ContentHandler的子类的实例,本系统使用的是BodyContentHandler类,它能读取<body></ body>标签之间的文本内容并保存在 contentHandler中。③中是创建了一个默认设置的元信息对象。④中创建了一个自动探测解析类型的解析器,它会探测文档的类型然后调用相应的解析器。
3.4 索引的实现
在实现时具体的过程如下:
(1)搜集用户输入的查询关键词及过滤条件,并作初步的客户端验证。
(2)创建查询解析器QueryParser对象以解析用户输入,在创建对象时传入解析器作为构造的参数。
(3)创建BooleanQuery对象以封装多个子查询。(4)创建IndexSearcher对象和TopScoreDocCollector容器对象,并执行查询方法,将结果集写入容器。
(5)以分页显示的方式从容器中取得本页数据,并放入ScoreDoc类型的数组中。
(6)遍历数组,返回结果集。
检索功能的核心代码如下:
//result set
Set<SearchResult> results= new LinkedHashSet<SearchResult>();
IKAnalyzer analyzer=new IKAnalyzer();try{
BooleanQuery query=new BooleanQuery();
QueryParser qp;
if(StringUtils.isEmpty(fname){
//search by content
//default search checks content qp=new QueryParser(LUCENE_VERSION,FIELD_CONTENT,analyzer);
qp.setAllowLeadingWildcard(true);
query.add(qp.parse(text),Occur.SHOULD);}else if(StringUtils.isEmpty(text){
//search by filename…………}else{
//search by filename and content…………}
//searcher
IndexSearcher searcher=getIndexSearcher(repositories[0]);
Query rewrittenQuery=searcher.rewrite(query);
TopScoreDocCollector collector=TopScoreDocCol lector. create(5000,true);
searcher.search(rewrittenQuery,collector);
int offset=Math.max(0,(page-1)*pageSize);
ScoreDoc[]hits=collector.topDocs(offset,pageSize).score-Docs;
int totalHits=collector.getTotalHits();for(int i=0;i<hits.length;i++){
int docId=hits[i].doc;
Document doc=searcher.doc(docId);
//search result
SearchResult result=createSearchResult(doc,hits[i]. score,docId,offset+i+1,totalHits);
result.repository=repositories[0];
String content=doc.get(FIELD_CONTENT);if(content.length()>50){
//the number of display
content=content.substring(0,50);
}
result.fragment=getHighlightedFragment(analyzer,query,content,result);
results.add(result);
}
系统实现的检索结果页面如图6所示。
图6 检索界面
4 系统测试分析
系统测试环境中CPU为Intel Core i3-3110M CPU @2.40GHz,内存为4GB。以txt、docx、pdf三种文档格式作测试,数据大小级别分别为10KB、100KB、1000KB。测试结果如表1所示。测试结果表明,文件类型和大小对索引的建立速度有直接的影响,而对检索速度影响不大。由于在实际环境中,更频繁的操作是检索,故能基本满足用户对Git仓库的检索需求。
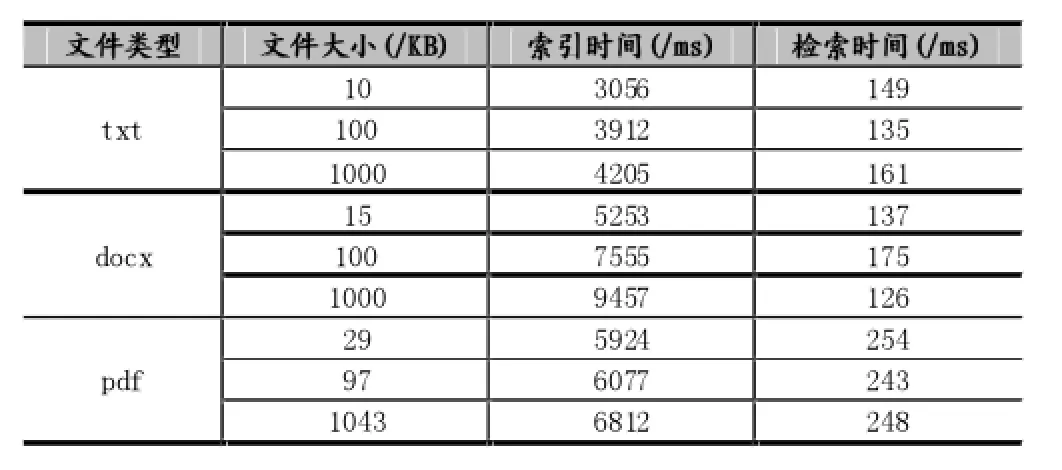
表1 系统测试结果
5 结语
本文在研究了Git的工作原理和开源检索框架Lucene的基础上,对多格式文档内容进行提取,设计并实现了一个基于Git仓库的全文检索系统。 系统能根据用户输入的关键字和文件名定位索引库中的文件。系统主要在两方面需要改进,其一对中文分词的进一步优化,提高分词精度;其二在面对海量数据检索时,检索的准确性和效率。
[1]蒋鑫.Git权威指南[M].北京:机械工业出版社,2011.
[2]Apache Software Foundation.Lucene Java Documentation[DB/OL].http://lucene.apache.org/core/3_0_3/index.html,2013-06-21.
[3]王福强.Spring揭秘[M].北京:人民邮电出版社,2009.438-580.
[4]周敬才.基于Lucene全文检索系统的设计与实现[J].计算机工程与科学,2015,37(2):2-3.
[5]牛长流.Lucene实战[M].北京:人民邮电出版社,2011.32-73.
[6]王文龙.分布式软件开发平台的设计与实施[D].北京邮电大学,2011.
[7]江毅铭.专业搜索引擎技术的研究与实现[D].北京化工大学,2005.
[8]Apache Software Foundation.Apache Tika Document[DB/OL].http://tika.apache.org/1.12/parser.html,2016.
[9]O'Reilly Taiwan公司译.Shell脚本学习指南[M].北京:机械工业出版社,2009.
Design and Implement of Git Repository Search Engine
GAO Yi,REN Hong-min
(College of Information Engineering,Shanghai Maritime University,Shanghai 201306)
With Git version control system applications increasingly widespread,Git repository documentation is also increasing.Lucene-based Git repository search engine indexing for Git repository file and search.The search system indexed by the hook mechanism Git asynchronously,when used in the retrieval based on J2EE architecture.First,Lucene,jGit kits and other related research,and then indexing module,searching module design,programming and final test analysis.System to achieve full-text search Git repository file with a Git repository provides a Web-based retrieval methods,but also the exploration of Lucene applications.
1007-1423(2016)21-0071-06
10.3969/j.issn.1007-1423.2016.21.017
高毅(1987-),男,山东青岛人,硕士研究生,研究方向为信息系统与电子商务任红敏(1969-),男,上海人,博士,副教授,研究方向为软件体系结构、构件技术、软件复用、过程工程、软件项目管理,基于社会计算、群体智能、人本计算、社会网络、舆情分析等技术的软件资产管理、船舶协同设计知识管理等
2016-05-06
2016-07-15
猜你喜欢
萍乡学院学报(2022年2期)2022-09-27
客联(2022年3期)2022-05-31
散文百家(2021年1期)2021-11-12
中国新闻周刊(2021年26期)2021-07-27
影像视觉(2020年5期)2020-06-30
科学与财富(2019年27期)2019-10-25
数码世界(2019年9期)2019-09-07
电子制作(2019年14期)2019-08-20
高中生·青春励志(2017年4期)2017-06-09
电脑爱好者(2017年7期)2017-05-06
