
档案元数据核心集内部要素及关系研究*
2016-09-19 06:06任天琪天津城建大学综合档案室天津300384
档案与建设 2016年8期
任天琪(天津城建大学综合档案室,天津,300384)
档案元数据核心集内部要素及关系研究*
任天琪
(天津城建大学综合档案室,天津,300384)
现代档案管理工作趋向全数字化管理,数字技术为档案发挥历史记录功能创造了绝佳条件。但时至今日,各种档案管理系统的实现效果欠佳。文章借助“关联数据”分析找出档案元数据核心集的内部要素,建立起要素之间的“关联关系”,并利用这些关系建立起一个可以呈现真实历史面貌的档案管理系统。
档案元数据核心集关联数据关联关系档案资源整合档案管理系统
1 建立档案数据间关联关系的必要性
现代档案管理逐渐趋向档案的资源知识管理,档案管理者也正在向知识管理者转型[1]。各种类型的档案资源都在依靠现代化技术和设备进行数字化,并加以利用。但即便如此,在很大程度上档案利用效果还是难以达到人们的期望。当前,档案著录基本上还是沿袭传统思路,以档案内容特征和形式特征为主,这种著录方式可以较好地解决档案实体查询与检索利用,但是并没有将档案记录历史的功能很好地展现出来。造成这一结果的主要原因之一是,在档案管理系统中,各种档案元数据只是简单地著录,“单摆浮搁”在系统中,没有建立起数据间的关联关系。
因为每份档案不是孤立存在的个体,我们不能认为档案是单一的知识点。档案之间存在着一定的有机关系,是一个连续的生命体。如要有效地管理档案资源,最大限度地揭示并整合档案间的有机联系,使档案能够更真实地展现历史全貌,就要根据档案历史联系与历史的“同构性”规律,建立起档案元数据核心集,找出核心集的关键要素,并给各个要素之间建立起相应的历史联系。借助关键要素和要素之间的历史联系,可以建立一个呈现出历史原貌的档案管系统。这个关键要素和要素之间的历史联系即为档案元数据核心集的内部要素,可以分别用“关联数据”和“关联关系”来表示。
2 档案元数据核心集内部要素分析
2.1“关联数据”的选择
“关联数据”是一种在网络中发布、分享、互相联接结构化数据的方法,采用RDF(资源描述框架)数据模型,利用URI(统一资源标识符)命名数据实体,在网络上发布和部署实例数据和类数据,从而可以通过HTTP(超文本传输协议)揭示并获取这些数据,同时强调数据的相互关联、相互联系以及有益于人和计算机所能理解的语境信息[2]。用关联数据表示档案元数据,旨在建立有效且格式统一的档案元数据,在档案元数据之间建立起各种联系,有助于档案资源被智能搜索引擎发现。
利用关联数据对档案元数据进行描述时,要注意关联数据的选取。档案元数据浩如烟海,并不是所有元数据都需要用关联数据进行描述。我们只需要选择关键的档案元数据作为关联数据,这样既可以增强关联数据的可用性和可操作性,又可以节省资源和时间。
什么样的档案元数据是关键的元数据呢?经研究,我们可以依据档案领域特有的元数据,即元数据核心集。档案元数据核心集对档案历史联系要素(来源、事由和年代)的本体特征及要素之间的关系进行结构化描述。它是一种在档案自身形成过程中对“历史联系”的完整描述信息。
如图1[3]所示,历史与档案的历史联系具有同构性,即主体与来源、客体与事由、时间与年代表现为一一对应的关系,而档案元数据核心集是通过档案历史联系的三个要素(来源、事由、年代)来确立的。由此可见,档案元数据核心集应包括来源元数据、事由元数据和年代元数据。因此,我们要选取的关联数据是档案的“来源关联数据”“事由关联数据”和“年代关联数据”。
2.2“关联关系”的建立
要想发挥关联数据的作用,就需要充分利用现有数据之间的关联关系,以及根据实际需要建立新的关联关系,因为关联关系是资源发现和资源扩展的重要基础[4],也是建立“后检索时代”档案服务模式的关键所在。从利用角度看,用户关心的首要问题是能否在档案的海洋中找到所需的有效资源。这个“有效资源”一方面指与用户查找的档案完全契合的;另一方面是用户未提出的利用需求,但与所寻档案相关的,或者是用户感兴趣的。利用关联关系向用户进行档案信息的主动推送,可以提高档案查询的准确率,也大大提高了档案的利用率。
从档案自身角度看,档案之间的关联关系紧密且复杂。如何选择关键的关联关系,向用户提供“有效资源”呢?如前所述,档案元数据核心集由来源元数据、事由元数据和年代元数据组成。比如,每份文件都有拟稿单位、发文单位、执行单位等,还有文件的形成时间、发文时间、收文时间等,还有相关的社会活动。根据这些信息,我们可以著录出来源、事由、时间方面的元数据,然后建立起档案文件之间的关联关系。所以,与档案元数据核心集相对应,我们可以建立“来源关联关系”“事由关联关系”和“年代关联关系”。通过这些关联关系,建成一张张相互联系的知识网络[5]。
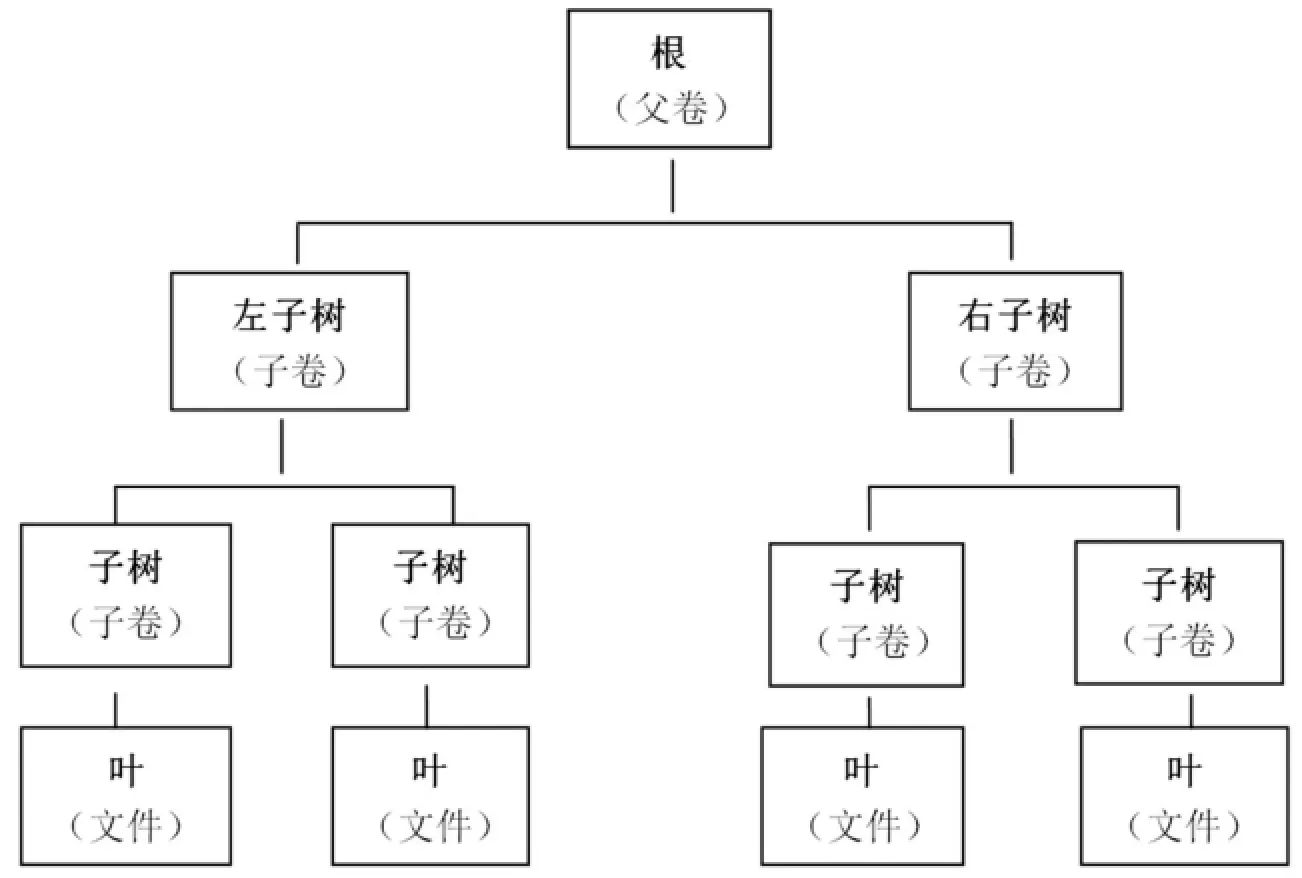
图1 档案元数据核心集构建机理示意图
3 档案元数据核心集子模型的建立
每种关联数据及关联关系组成了档案元数据核心集的元数据子模型。模型由点和线构成一个三维网络结构。“点”表示档案的来源,或者特征事件,或者特定年代;“线”代表来源间、事件间、年代间的关系。每个元数据子模型不但可以完整地描述点(事件、来源、年代)的本体特征信息,而且还可以将节点(事件、来源、年代)间的关联信息准确地揭示出来。根据上面的分析,我们可以建立起“来源元数据子模型”“事由元数据子模型”和“年代元数据子模型”。
3.1来源元数据子模型的建立
来源元数据子模型由关联数据和来源关联关系组成,侧重于描述档案来源或档案形成机构之间的关系,对应着档案历史联系中的来源联系。它客观真实地记录下档案来源的具体信息,利用来源关联数据来描述隐藏在档案来源之间的内在联系。依据档案的来源,分为个人来源、机构来源、国家来源三个层次。
个人来源中,最典型的是名人档案全宗,可以根据关键字进行检索,但是“姓名”会出现重名的问题。这需要我们对“姓名”进行元数据的注释,比如个人隶属的机构,或是就读的学校。这些注释就说明了个人与个人、个人与机构、个人与国家之间的关系。比如王某形成档案A,李某形成档案B,利用注释元数据来说明王某和李某的关系。若王某和李某是同学,那么两人的学籍档案会有些相似的课程设置和评分标准。这就是来源关系。
机构来源指档案来源于政府机关、法人单位、社会团体、党派等集体组织。来源于同一机构的档案,即档案的责任者相同,可以形成机构全宗,比如天津城建大学全宗。这是机构来源中机构与机构关系最简单的体现。机构与机构之间的关系可以架构起机构沿革,从而反映出一个机构的演变发展历程。机构与国家之间是从属关系。比如天津城建大学的全宗隶属于中国,而非从属于其他国家。
国家来源是指来源于国家的档案,是构成国家全宗群的重要条件,可以是来源于同一个国家的档案,比如中国国家档案全宗群。可以是来源于不同国家的档案,比如来源于不同国家的联合国档案。以上是国家与国家之间的关系。
3.2事由元数据子模型的建立
事由元数据子模型由事由关联数据和事由关联关系组成,侧重对档案中涉及的活动或事件的描述,它对应着档案历史联系中的事由联系,要通过事由关联数据,客观真实地记录一件事情,描述隐藏在事件与事件之间的内在联系。形式上,事件可表示为e,定义为一个六元组:e=<A,O,T,V,P,L>,其中A为动作要素,表示事件的变化过程及其特征,是对动作的程度、方式、方法等的描述;L为语言表现要素,表示事件的语言规律,包括核心词集、核心词表现、核心词搭配等[6]。我们根据事件的动作要素(A)和语言表现要素(L)来建立事件之间的联系,分为“分类关系”与“非分类关系”[7]。
分类关系,是指按照事物种类、等级或性质分别归类。根据分类的思想把无规律的事物,按照不同的特点划分,使事物更有规律性。在档案检索过程中,以关键词作为检索的关键信息,就是分类的体现。比如父子关系,即树形结构,是一种层次的嵌套结构,存在着“一对多”的数据结构。父子关系可以用树状图表示(如图2):一棵树可以简单地表示为根、左子树、右子树,左子树和右子树又有自己的子树,子树延伸到叶即结束。根和子树之间有相似的结构,每个子树又可以有自己的特性。在档案管理中,我们会根据重要事件组建专题卷,或者专题全宗。比如本科教学质量水平评估专题全宗,其中评估的通知、指标等文件可以组成父卷,即根。根据每个评估指标组成子卷,即子树。每个子卷又是相对独立的卷,有自己的内容,比如本科专业设置、本科教育经费等。每个子卷内的档案文件,即叶。
再比如上下位关系,也称类属关系,指反映的现象之间具有包含和被包含的关系。上位类更具有概括性,反映的现实现象众多;下位类更具丰富内涵属性,除了继承上位类的所有属性外,还有自己的属性。比如,国家颁布了一项法规,这项法规即上位类;相关的机构、单位就要根据这项法规出台相应的规定,就是下位类。
非分类关系,指类目之间或检索词之间除等同关系和等级关系以外的其他各种关系,可以理解为事件之间的相关关系。我们可以选取逻辑关系和语义关系作为事件的非分类关系,建立事由之间的关联联系。逻辑关系即逻辑顺序,是按照事件的内部联系及人们认识事件的过程来安排说明事件的发生顺序,如因果关系、循环关系等。之前提到的为用户进行档案主动推送服务,就需要建立档案间的逻辑关系。比如请示和批复,说明了事件之间的因果联系;定期召开的会议档案,说明事件之间的循环关系。语义关系,或者说词义,即词语的含义。词义之间可以是同义词、近义词、反义词。也就是说语义关系可以分为语义相同、语义相近、语义相逆。比如我们在著录“任命”这个元数据时,同时给出注释,加入同义词“任职”,相近词“任免”,反义词“免职”。那么我们在以“任命”为关键词进行检索时,可以得到某个机构的人事变动的组织沿革。
3.3年代元数据模型的建立
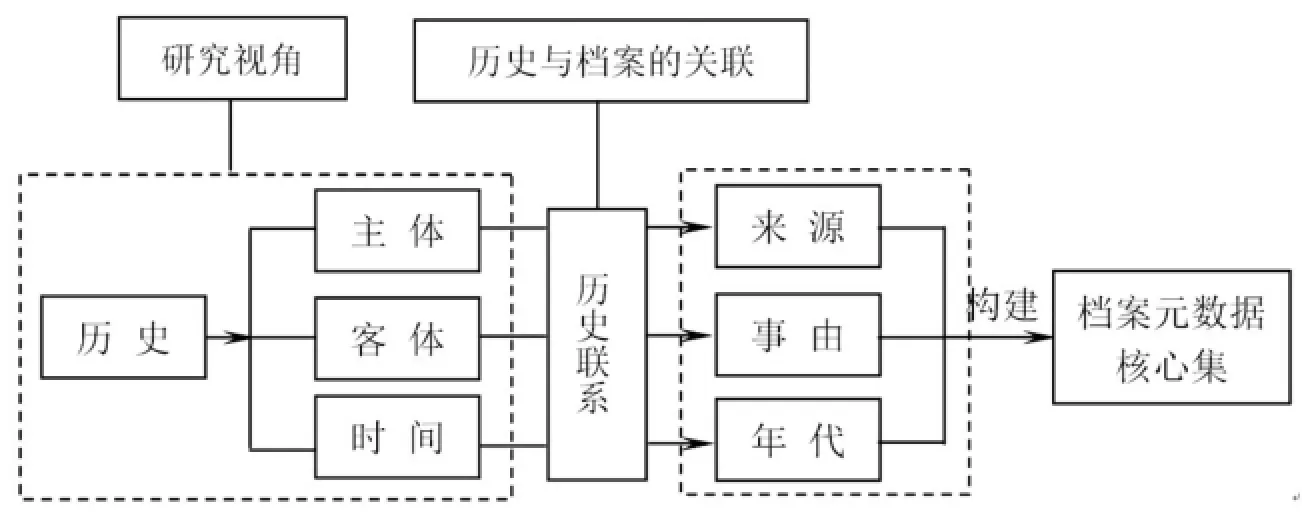
图2 事由元数据子模型父子关系图
年代元数据模型由年代关联数据和年代关联关系组成,侧重于对档案中涉及时间的描述,对应着档案历史联系中的年代联系。它利用年代关联元数据来描述隐藏在年代之间的内在联系。这里的年代即为时间,可大可小,可长可短。年代包括时间点、时间区间、时间跨度、时间集合[8]。
同一年代关系,指时间点相同的档案集合。时间点也称为时刻,是把时间看成一个个离散的点,这些离散化时间点的间隔大小适度时,就可以准确描述现实世界现象发生及变化的情况[9]。时间点相同可以根据时间粒度的精确程度来选取相同的区域,可以是同一年、同一月或者同一天。
不同年代关系可以有时间的先后关系、时间的包含关系。先后关系指在一个时间区间内,按照时间的先后顺序进行排序,这是档案实体中普遍存在的一种关系。包含关系指时间区间或者时间集合对时间点的包含。我们在查找文件时,要规定一个时间区间,或者某个时间集合(如{2000,2005,2010})。
4 结束语
档案是社会发展的记忆,是各种事实、经验和档案资源开发知识的重要载体[10]。准确找出档案元数据核心集的要素,并建立要素之间的关系,可以更准确地检索档案资源,满足用户的基本需求;为用户提供主动服务,更加生动地向用户展现真实的历史面貌;可以使可公开的档案资源很好地融入其他信息资源,提高档案资源的利用率,发挥档案资源的生产力作用。
*本文是2015年度教育部人文社会科学研究规划青年基金项目“‘魂系历史主义’的档案元数据核心集的构建研究”(项目编号:15YJC870007)阶段性研究成果。
[1][5][10]吕元智.数字档案资源知识“关联”组织研究[J].档案学研究,2012(6):44-47.
[2]石华.关联数据:档案行业的新机遇[A]//创新:档案与文化强国建设——2014年全国档案工作者年会优秀论文集[C].北京:中国文史出版社,2014:242.
[3]田伟,韩海涛.发挥档案元数据核心集作用推进“互联网+档案”建设[J].档案,2016(6):7.
[4]黄永文,岳笑,刘建华.关联数据应用的体系框架及构建关联数据应用的建议[J].现代图书情报技术,2011(9):7
[6][7]张旭洁.事件本体构建中几个关键问题的研究[D].上海大学,2012.13.
[8][9]徐真.面向对象的时空数据模型研究[D].山东科技大学,2007.13-15.
任天琪,女,天津城建大学办公室综合档案室主任,馆员,主要研究方向为档案管理。
Research on the Internal Elements and Relationships of Archives Metadata Core Set
Ren Tianqi
(Archives of Tianjin ChengJian University,Tianjin,300384)
Modern archives management work trend all digital management.Under this background,digital technology has created an excellent condition for the ultimate function of recording history.But today,a variety of file management system is not to achieve this purpose.In
Archives Metadata Core Set;Associated Data;Association Relation;Intergration of Archival Resources;Archives Management System
G270.7
? this paper,we use the"associated data"analysis to find out the internal elements of the archival metadata core set,and establish the relationship between the elements.Use these relations to establish a real history of the appearance of the file management system.
猜你喜欢
求是学刊(2022年5期)2022-11-08
学苑创造·A版(2022年5期)2022-05-19
新世纪智能(数学备考)(2021年9期)2021-11-24
仲裁研究(2019年1期)2019-09-25
当代陕西(2019年15期)2019-09-02
汉字汉语研究(2019年2期)2019-08-27
流行色(2018年11期)2018-03-23
学苑创造·A版(2018年11期)2018-02-01
河北经贸大学学报(综合版)(2017年2期)2017-02-23
读者(2017年5期)2017-02-15
