
基于RS并行约简算法的配电网故障诊断方法
2016-09-08 01:35王小红
电子设计工程 2016年1期
王小红
(陕西省委党校 陕西 西安 710061)
基于RS并行约简算法的配电网故障诊断方法
王小红
(陕西省委党校 陕西 西安710061)
随着电力系统对系统故障诊断智能化的要求越来越高,为了解决传统专家系统对不完整知识处理的局限性以及减少误判、漏判的情况,本文提出一种基于RS并行约简算法,将约简算法中计算相对正域的过程和计算核值的过程实现了并行化处理。实验结果显示,本方法提高了粗糙集中决策表属性约简的准确性,同时降低了属性约简的时间。本方法对配电网故障诊断的决策规则的自动化生成、实时故障信息进行分类判断和识别具有重要意义。
配电网;故障诊断;并行计算;粗糙集
配电网故障诊断主要是对各级各类保护装置产生的报警信息,断路器的状态变化信息以及电压、电流等电气量测量的特征进行分析,根据保护动作的逻辑和运行人员的经验来推断可能的故障位置和故障类型。为了应对电力系统快速增长的各种海量信息,研究人员引入了许多方法和技术,并且取得了一定的成功,例如,基于贝叶斯网络[7]、遗传算法[8]、进化技术、Petri网络等的智能故障定位诊断。
以上这些方法虽然都取得了较为满意的结果,但都存在诊断所依据的实时信息不完备或信息受畸变时产生错误的诊断 结论的情况。而粗糙集理论作为一种处理不精确、不一致、不完整等各种不完备的信息有效的工具,其较强的容错能力使得它在电力系统中的应用发展[1,2]很快。基于粗糙集的应用研究[3-6]主要集中在属性约简、规则获取、基于粗糙集的计算智能算法研究等方面。由于属性约简是一个NP难问题,许多学者都进行了系统的研究。王国胤等人[6]从信息论的观点出发对粗糙集理论的基本概念和运算进行分析,并基于此给出了基于条件信息熵对决策表进行属性约简的两个算法——CEBARKNC和CEBARKCC,前者以所有条件属性集为起点,自顶向下逐步去掉不必要的属性,后者则是以决策表核属性集为起点,自底向上逐步增加属性。由于约简算法普遍低效,特别是对于大规模数据集,因而开始有学者试图运用粒计算的划分模型[9]来进行属性约简算法的研究。
然而,传统的粗糙集约简方法都是基于单机进行的。考虑到属性约简具有很高得计算复杂度,传统的基于单机的属性约简方法已经不能满足大规模数据的属性约简的需要[10]。幸运的是,当前基于MapReduce的并行计算平台为大规模数据的智能化处理提供了一种可行的解决方案。Hadoop作为MapReduce的一个实现框架,基于分布式文件系统(HDFS),通过利用map和reduce函数可以将现有的集中式处理任务并行化地部署在多台计算机节点上进行处理,可以大大提高计算效率。文中将基于Hadoop平台,提出了一种并行属性约简算法和并行值约简算法方法。通过一个具体算例,根据收集的故障信息所建立的决策表进行约简,得到诊断决策规则,并将其作为实时故障诊断的依据,从而实现配电网的故障诊断和定位。
1 并行约简的故障诊断方法总体流程
由于粗糙集理论可以很好地处理因保护装置和断路器误动作、信号传输误码而造成的错误或不完整的故障信号,形成鲁棒性较强的电网故障诊断专家知识库,所以将粗糙集应用于配电网故障诊断。通过决策表约简提取出决策规则,依据决策规则能够快速地根据故障区域判断产生故障的元件,调度员及时做出决策消除故障,便于检修和事故后的快速恢复,确保电力系统安全稳定运行。本文设计的并行约简的故障诊断(Parallel Reduction for Fault Diagnosis,简称为PRFD)。该诊断过程可分为 3个模块,故障信息决策表(Fault Decision Table,简称FDT)的建立模块,FDT约简模块,抽取诊断规则(Diagnosis Rules,简称DR)模块以及故障诊断模块[11]。
故障信息决策表(FDT)建立模块主要用于建立初始故障信息表。从故障信息库中提取故障记录,判断每条故障信息记录中是否含有状态缺失信息,若不含缺失信息,则将其加入故障信息库,否则加入不完备知识库。从故障信息库读取故障记录时,只将各个元件状态和故障发生位置属性加入初始故障信息表,其他的相关信息在该系统中不考虑。
诊断规则(DR)提取模块的主要功能是完成对初始故障信息表的约简以及故障规则的提取,其中约简部分又包括属性约简和值约简,利用属性约简可以去掉故障信息表中冗余的属性,而值约简则用于删除每条故障记录中的冗余属性值。诊断规则是从最终故障决策表中提取出来的,用于诊断实时故障。约简后的最终故障决策表中每行记录即为一条诊断规则,且每条诊断规则都不含冗余信息。
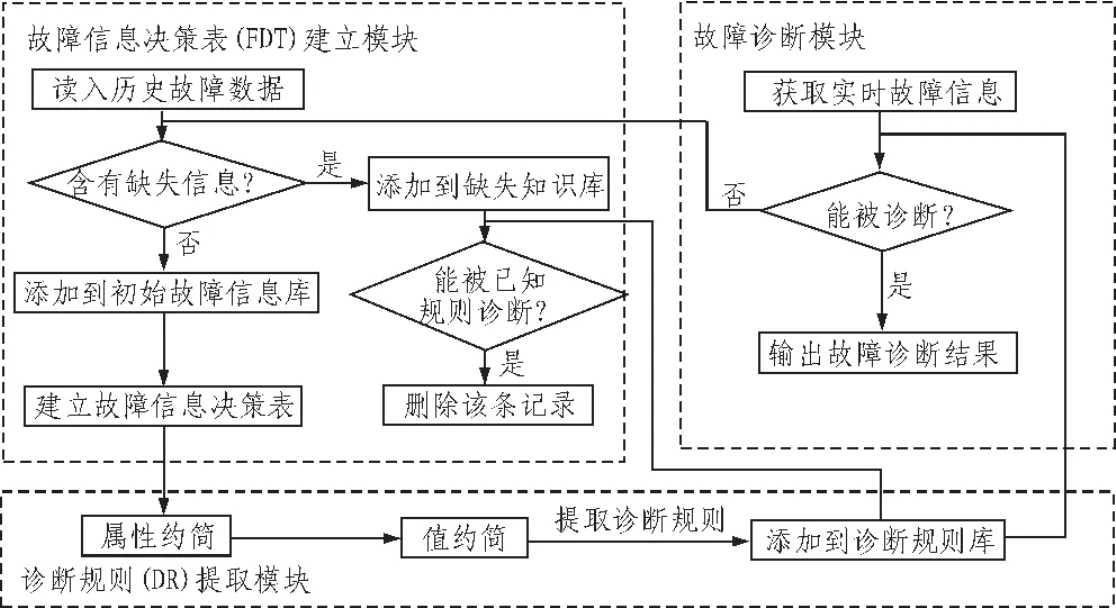
图1 基于PRFD方法的诊断过程Fig.1 Diagnosis procedure based on PRFD
故障诊断模块完成对实时故障进行故障定位和诊断。诊断规则库建立后,从实际配电网使用过程中出现的故障可以根据诊断规则判断哪些元件导致故障的发生。如若根据规则库中的诊断规则无法进行判断,此时将记录下该故障发生时各个元件的状态信息,并将该故障记录转入FDT建立模块进行处理。该条记录中若无缺失信息,则将其加入历史故障数据库,否则加入缺失信息库。对于缺失信息库中的记录,如果可以根据诊断规则进行判断,则将其删除。
2 并行属性约简
文中属性约简基于文献[4]的思想,将并行计算融入粗糙集[12-13]的决策表约简,具体并行属性约简的算法流程如图2和图3所示,其中假设参与计算的处理器的个数为K,并令第一个处理器P1为主处理器,故障属性约简集合记为R,待处理的属性集记为Attr_left=CR。该约简主要分为属性扩张和属性收缩两个部分。
在属性扩张阶段,首先在主进程中计算属性核CORED (C),令R的初始值为属性核。然后将剩余的属性Attr_left分为K组(S1,S2,…,SK)分配给K个进程同时处理,其中每组中的属性个数相差不大于1,接下来在每个处理进程中,根据相对正域中元素的个数选择出每个分组Si中必要的属性Cselect_i,并将Cselect_i和POS{R∪Cselect_i}(D)发送给主进程,主进程再根据相对正域中元素的个数在各分进程提交的属性中选择出必要属性Cselect,并更新R=R∪Cselect同时更新Attr_left,重复上述操作直至POSR(D)=POSC(D),然后进入属性收缩阶段。属性扩张如图2所示。

图2 属性扩张流程Fig.2 Procedure of attribute expansion
在属性收缩阶段中,主要对加入到R中的非核属性进行处理,判断它们相对于故障位置属性是否是多余的。首先将R/CORED(C)中的各个属性分别分配到K个进程中进行处理,分配完成后若还存在剩余的属性,则等待下一批处理。在各个进程中判断其分配到的属性是否相对于故障位置属性是多余的,若是,则将其发送给主进程,否则记为-1后发送给主进程;主进程将收到的多余属性进行筛选,选出第一个多余属性Cdelete,若Cdelete≠箒1,则更新R=R/Cdelete,再次判断剩余的非核属性中是否存在多余属性;若Cdelete=箒1且所有非核属性均已判断,则R即为约简后的属性集;若Cdelete=箒1但尚存在未判断的属性,则将这些属性分配到K个进程中按上述步骤进行处理。属性收缩如图3所示。
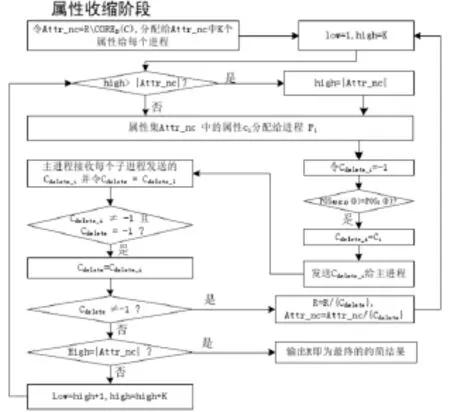
图3 属性收缩流程Fig.3 Procedure of attribute contraction
经过以上并行属性约简和并行值约简后得到的最终故障决策表中,所有属性值均为该表的值核,所有记录均为该故障信息表对应的诊断规则。本阶段只需将每条记录存储于诊断规则库中,作为对实时故障的诊断和定位的依据。此外,也要对诊断规则库进行定期的更新,保证该系统的正确诊断率。
3 实验仿真分析
为验证本文设计的PRFD系统的可用性和有效性,在该系统上运行UCI数据集进行测试,并与基于粗糙集传统约简算法的专家系统(RSES)进行比较。本文测试所用的标准测试数据集UCI是来自于加州大学欧文分校机器学习数据收集库(http://archive.ics.uci.edu/ml/),本文选择了其中的6个数据集作为实验数据,且测试的数据集的大小变化不等,以此测试系统在大数据集下的运行效率。某些数据集中可能含有缺失值,以此来测试该系统对不完整记录的处理情况,这些数据集的具体特征如表1所示。

表1 数据集及其特征Tab.1 Data sets and their characteristics
文中设计的系统PRFD与传统RSES系统的比较结果如下图4和图5所示。由图4可知,当数据集的记录个数小于1024时,得到最小约简时两个系统的运行时间相当,这是因为本文设计的PRFD系统中所使用的约简算法的通信时间只与条件属性个数有关,当数据量较小时,其通信时间在整个约简时间中所占的比例较大,然后当数据集中记录个数足够大时,该系统的优势越来越明显,运行时间相比传统的方法大大缩减,说明PRFD系统对大数据集仍具有一定的高效性。由图5可以看出,当数据集不大时,两个系统的准确率相当;且随着记录数目越来越大,系统的准确率都会有所下降,但相比RSES,PRFD系统的准确率较高,并且准确率下降的速度较缓,主要原因是在获取决策规则的过程中,PRFD系统是根据当前的约简结果来计算属性重要性,属于一种动态的贪心策略,能够得到最优或次优的约简结果,从而得到较为准确的诊断规则。
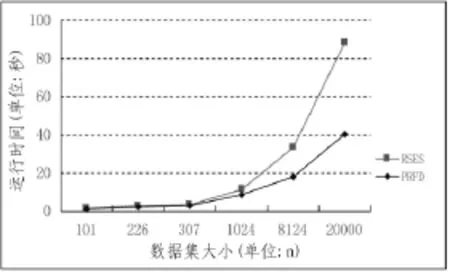
图4 PRFD系统和RSES系统运行时间对比曲线Fig.4 Comparison of system uptime between PRFD and RSES

图5 PRFD和RSES系统准确率对比曲线Fig.5 Comparison of system accuracy between PRFD and RSES
4 结 论
文中提出一种并行粗糙集约简算法,通过属性扩张和收缩,实现并行化处理。相关实验仿真显示,较传统方法比较而言本文方法降低了数据约简的执行时间,而且也提高了约简的准确率。文中方法复杂配电网络的故障诊断提供了一种可行的解决方案。
[1]束洪春,孙向飞,于继来.电力系统自动化粗糙集理论在电力系统中的应用[J].电力系统自动化,2004,28(3):90-95.
[2]孙秋野,张化光,戴瓂.基于改进粗糙集约简算法的配电系统在线故障诊断[J].中国电机工程学报,2007,27(7):58-64.
[3]束洪春,孙向飞,司大军.基于粗糙集理论的配电网故障诊断研究[J].中国电机工程学报,2001,2l(10):73-78.
[4]肖大伟,王国胤,胡峰.一种基于粗糙集理论的快速并行属性约简算法[J].计算机科学,2009,36(3):208-211.
[5]CHEN De-gang,ZHAO Su-yun,ZHANG Lei,et al.Sample pair selection for attribute reduction with rough set[J].IEEE Transactions on Knowledge and Data Engineering,2012,24 (11):2080-2093.
[6]王国胤,于洪,杨大春.基于条件信息熵的决策表约简[J].计算机学报,2002,25(7):759-766.
[7]ZHU Yong-li,LU Jin-ling.Bayesian networks-based approach for power systems fault diagnosis[J].IEEE Transactions on Power Delivery,2006,21(2):634-639.
[8]LIN Xiang-ning,KE Shuo-hao.A fault diagnosis method of power systems based on improved objective function and genetic algorithm-tabu search[J].IEEE Transactions on Power Delivery,2010,25(3):1268-1274.
[9]刘清,刘群.粒及粒计算在逻辑推理中的应用[J].计算机研究与发展,2004,41(4):546-551.
[10]童晓阳,谢红涛,孙明蔚.计及时序信息检查的分层模糊Petri网电网故障诊断模型[J].电力系统自动化,2013,37 (6):63-68.
An RS parallel reduction based approach for distribution network fault diagnosis
WANG Xiao-hong
(Shaanxi Provincial Party School of the CPC,Xi’an 710061,China)
With the increasing demand of intelligent fault diagnosis of distribution network,an RS parallel reduction based approach is proposed in this paper in order to address the limitations of incomplete information processing in traditional expert systems.This approach computes relevant positive areas and core values of rough set in parallel.The experiment results show that our approach improves the accuracy of attributes reduction and reduces the performing time of executing reduction.Our approach has the significance to automatic generation of decision rules and classification and recognition of fault information.
distribution network;fault diagnosis;parallel reduction;rough set
TN302
A
1674-6236(2016)01-0181-03
2015-10-29稿件编号:201510219
国家自然科学基金项目(61372184)
王小红(1975—),女,陕西宝鸡人,讲师。研究方向:数据挖掘与知识工程。
猜你喜欢
舰船电子工程(2022年4期)2022-05-11
四川师范大学学报(自然科学版)(2021年6期)2021-11-15
科教导刊·电子版(2021年6期)2021-05-06
计算机工程与应用(2020年12期)2020-06-18
成都信息工程大学学报(2019年2期)2019-08-28
系统管理学报(2018年3期)2018-08-13
自动化学报(2018年2期)2018-04-12
智能系统学报(2017年3期)2017-08-01
计算机与数字工程(2016年11期)2016-12-13
厦门理工学院学报(2016年3期)2016-11-10
