
大数据处理技术在安全审计系统中的应用
2016-09-03 08:30李明桂丁文超
通信技术 2016年3期
许 杰,冷 冰,李明桂,丁文超
(中国电子科技集团公司第三十研究所,四川 成都 610041)
大数据处理技术在安全审计系统中的应用
许杰,冷冰,李明桂,丁文超
(中国电子科技集团公司第三十研究所,四川 成都 610041)
随着大数据时代的到来,数据出现了爆炸式的增长。这些海量数据的出现,影响了很多现有数据存储、处理和分析系统,其中就包括在网络安全中发挥着重要作用的审计系统。目前的审计系统中使用关系数据库对数据进行存储和处理,由于关系数据库的局限性,使得审计系统无法存储和处理大数据。针对该问题,提出了一种兼容现有系统的大数据存储方法,能够有效的解决大数据存储问题。同时,为了解决大数据(HBase)检索效率低下的问题,提出了一种使用Solr建立二级索引的方法,大大的提高了检索效率,满足了审计系统存储和处理大数据的需求。
大数据;审计系统;HBase;Solr
0 引 言
计算机网络安全审计(简称为安全审计)是指按照一定的安全策略,利用记录、系统活动和用户活动等信息,检查、审查和检验操作事件的环境和活动,从而发现系统漏洞、入侵行为或改善系统性能的过程。审计系统从审计内容上来看主要包括三方面:系统审计、应用审计和用户审计。
系统审计:主要针对系统的登录情况、用户ID、登录尝试日期时间、退出日期时间、所使用设备、运行程序等时间进行审查;
应用审计:主要针对应用程序的活动信息,如运行成功或失败,打开或关闭数据库或数据文件,读取、编辑、删除记录等特定操作,以及打印等行为;
用户审计:主要审计用户的操作活动,如用户直接启动命令,用户所有的认证操作,用户所访问的文件和资源等信息。
随着网络的繁荣发展及日益普及,各种具有网络功能的设备越来越多,审计系统开始从内网向外网扩展,从有线网络向无线网络覆盖。由于这种数据从单一到多渠道的变化使得数据量出现了指数级的增长,这就对现有的审计系统提出了新的应用需求,并促使审计系统向具备大数据存储、处理和分析能力方向发展。
大数据处理的数据包括结构化、半结构化和非结构化数据。半结构化、非结构化数据是相对于结构化数据而言,不方便用数据库二维逻辑表来表现的数据,如:办公文档、文本、图片、XML、图像和音频/视频等。现有的审计系统中存储的数据主要是从各类终端设备上采集的结构化数据,目前并不涉及半结构化、非结构化数据。随着数据量的海量增长,审计系统中的关系数据库已不能有效的存储、检索和处理这些结构化大数据。这就需要使用大数据技术来解决审计系统对大数据存储能力不足、检索效率低下等问题。
本文针对审计系统中大数据存储能力问题提出了一种有效的存储方法,同时为了提高大数据的检索效率,提出了一种建立二级索引的方法。
1 大数据相关技术
大数据是指在所能容忍的处理时间范围内,数据规模超过常规数据库工具获取、存储、管理和分析能力的数据集。大数据具有5V1C的特征:数据量巨大(Volume)、数据类型繁多(Variety)、生成速度快(Velocity)、数据易变化(Variability)、数据真实性(Veracity)、数据复杂性(Complexity)[1-2]。
目前,围绕着大数据的获取、存储、管理和分析等已经建立了以Hadoop为核心的大数据生态系统,包括Ambari、Avro、Cassandra、Chukwa、HBase、Hive、Mahout、Pig、Spark、Tez、ZooKeeper等[3-5]。这些开源系统被国内外各大厂商和公司使用,或直接使用,或根据业务需要进行修改后使用。由于大数据技术较多,因此仅对本文中使用的相关大数据技术进行介绍:
(1)Hadoop是一个跨计算机集群可以使用简单编程模式进行大规模数据存储和分析处理的分布式软件框架,是专为离线和大规模数据分析而设计的。Hadoop=HDFS+MapReduce,HDFS是文件系统,提供海量数据存储能力;MapReduce提供数据处理和计算能力。
(2)HBase[6]是一个高可靠性、搞性能、面向列、可伸缩的分布式存储系统,利用HBase技术可以在廉价的PC Server上搭建起大规模结构化存储集群。它构建在Hadoop基础设施之上,依托于Hadoop的迅猛发展,HBase在大数据领域应用越来越广泛,成为目前NoSQL数据库中表现最耀眼,呼声最高的产品之一。
(3)ZooKeeper是一个分布式的,开放源码的分布式应用程序协调器,是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、名字服务、分布是同步、组服务等,是Hadoop和HBase的重要组件。
2 审计大数据存储
现有的审计系统基本上都采用关系数据库(MySQL,Oracle,SQL Server等)进行数据存储,而且系统的数据获取,数据存储和数据分析整体架构较成熟,如果直接将关系数据库存储部分替换成HBase存储,不但会对相关的模块产生影响,而且也会造成系统整体运行不稳定的情况,风险较大。因此,我们采用现有存储系统与大数据存储并存的方法,改进现有审计系统无法存储海量数据的问题。整体架构如图1所示。

图1 审计大数据系统整体架构1
从图1中可以看出,数据存储部分是关系数据库和HBase共存的模式,在该模式下可以有两种策略:
(1)系统从终端接收上报数据后,可以将数据同时存入关系数据库MySQL和HBase,等整体系统稳定后在慢慢过渡到数据存储全部由HBase接管,最终放弃关系数据库。
(2)将数据根据时间段进行分别存储。实时接收的数据包括近期(三个月或半年)的数据存入关系数据库, 历史数据存入HBase,系统根据需要读取不同存储系统数据进行分析和处理。
3 HBase二级索引
通过使用大数据存储技术可以有效的解决审计系统海量数据存储的问题。这是由于HBase是一个面向列存储的分布式存储系统,它的优点在于可以实现高性能的并发读写操作,同时HBase还会对数据进行透明的切分,这样就使得存储本身具有了水平伸缩性。但HBase也有缺点,它不支持复杂条件查询,这与它的数据组织方式有着密切的关系,在逻辑上,HBase的表数据按RowKey进行字典排序,RowKey实际上数据表的一级索引(Primary Index),由于HBase本身没有二级索引(Secondary Index)机制[4],基于索引检索数据只能单纯依靠RowKey,为了解决该问题,一种常用的方法是将可能作为查询条件的字段拼接到RowKey中,但无论如何设计,单一RowKey固有的局限性决定了它不可能有效的支持多条件查询。因此,我们提出使用一种高效的索引工具Solr[7]来解决HBase二级索引的问题。Solr是一个高性能全文搜索引擎,它提供丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,可实现高效的检索。使用Solr后的整体架构如图2所示。
使用Solr提供的API接口可以简单方便的为HBase建立二级索引,提高检索效率并支持多条件查询。但由于Solr并不是专为优化HBase而开发的系统,对于HBase的增量更新,Solr是无法感知的,这就会造成数据和索引之间出现不一致的现象。
HBase在0.92版本后引入了一种协处理器(coprocesser)机制[8],该协处理器可以实现建立二级索引、复杂过滤器以及访问控制等。coprocesser机制建立了一个框架,它为用户提供类库和运行时环境,使得用户的代码能够在HBase region server和master上处理。coprocesser分两种类型:系统协处理器可以全局导入region server上的所有数据表;表协处理器是用户可以指定一张表使用协处理器。协处理器框架为了更好支持其行为的灵活性,提供了两个不同方面的插件,一个是观察者(observer),类似于关系数据库的触发器;另一个是终端(endpoint),动态的终端类似存储过程。
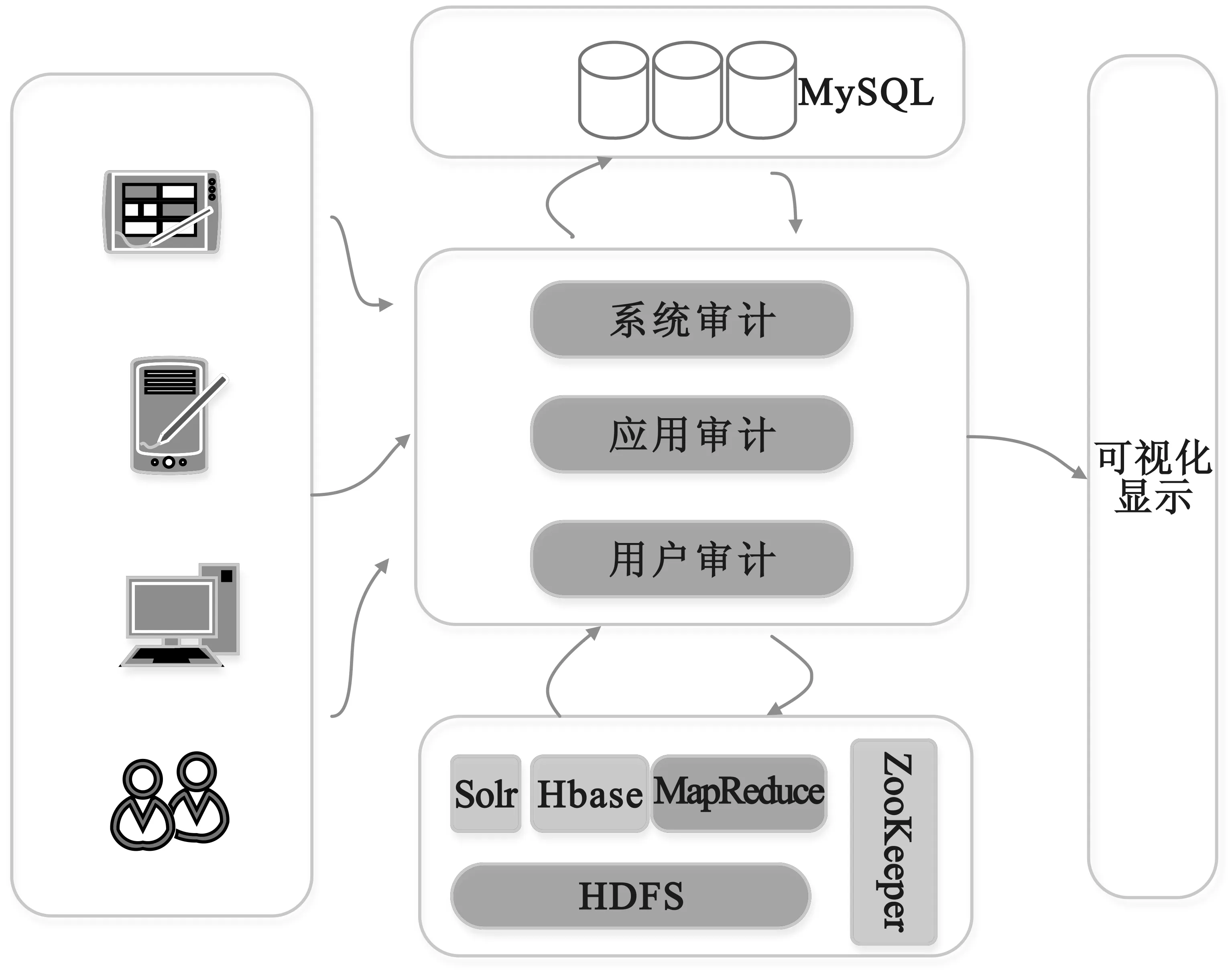
图2 审计大数据系统整体架构2
(1)观察者(observer)允许用户通过插入代码来重载协处理器框架的upcall方法,具体事件触发的callback方法有HBase的核心代码来执行。协处理器框架处理所有的callback调用细节,协处理器本身只需要插入添加或改变的功能。其工作流程如图3如所示。
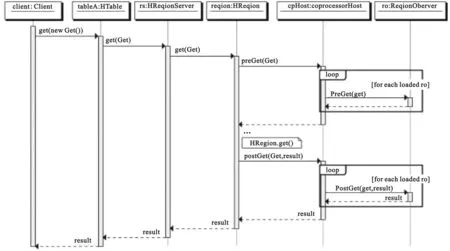
图3 Region Observer工作流程
(2)终端(EndPiont)是动态RPC插件的接口,它的实现代码被安装在服务器端,从而能够通过HBase RPC唤醒。客户端类库提供了方便的方法来调用这些动态接口,它们可以在任意时候调用一个终端,其实现代码会被目标region远程执行,结果会返回给终端。其整体流程如图4所示。

图4 终端(EndPoint)工作流程
本文中需要解决的问题是当HBase中的表出现插入,添加,修改和删除数据的情况下,更新相应的Solr二级索引,从而达到增量更新的目的。因此,结合上述的HBase协处理器的功能,采用观察者的方法,将编写好的更新Solr二级索引代码加载到相应的HBase中的数据表上,当该表出现数据变化时,通过coprocesser机制将该变化更新到相应的Solr索引中。
4 效果评价及分析
4.1环境搭建
为验证本文方法的改善效果,采用一台服务器,8台虚拟机搭建大数据存储及二级索引试验环境,具体配置如表1所示。

表1 大数据试验环境配置
在安装和配置大数据环境的过程中,首先,有以下几点需要注意:
(1)关闭各机器的防火墙。
(2)时间同步。
(3)配置ssh无密钥访问。
其次,需要配置Hadoop的slaves、core-site.xml、hdfs-site.xml、mapre-site.xml和yarn-site.xml四个配置文件,配置完成后将Hadoop发布到各节点。其中,master为namenode,slave1~slave8为datanode。配置完成后的Hadoop的节点集群和datanode信息如图5和图6所示。

图5 Hadoop节点集群
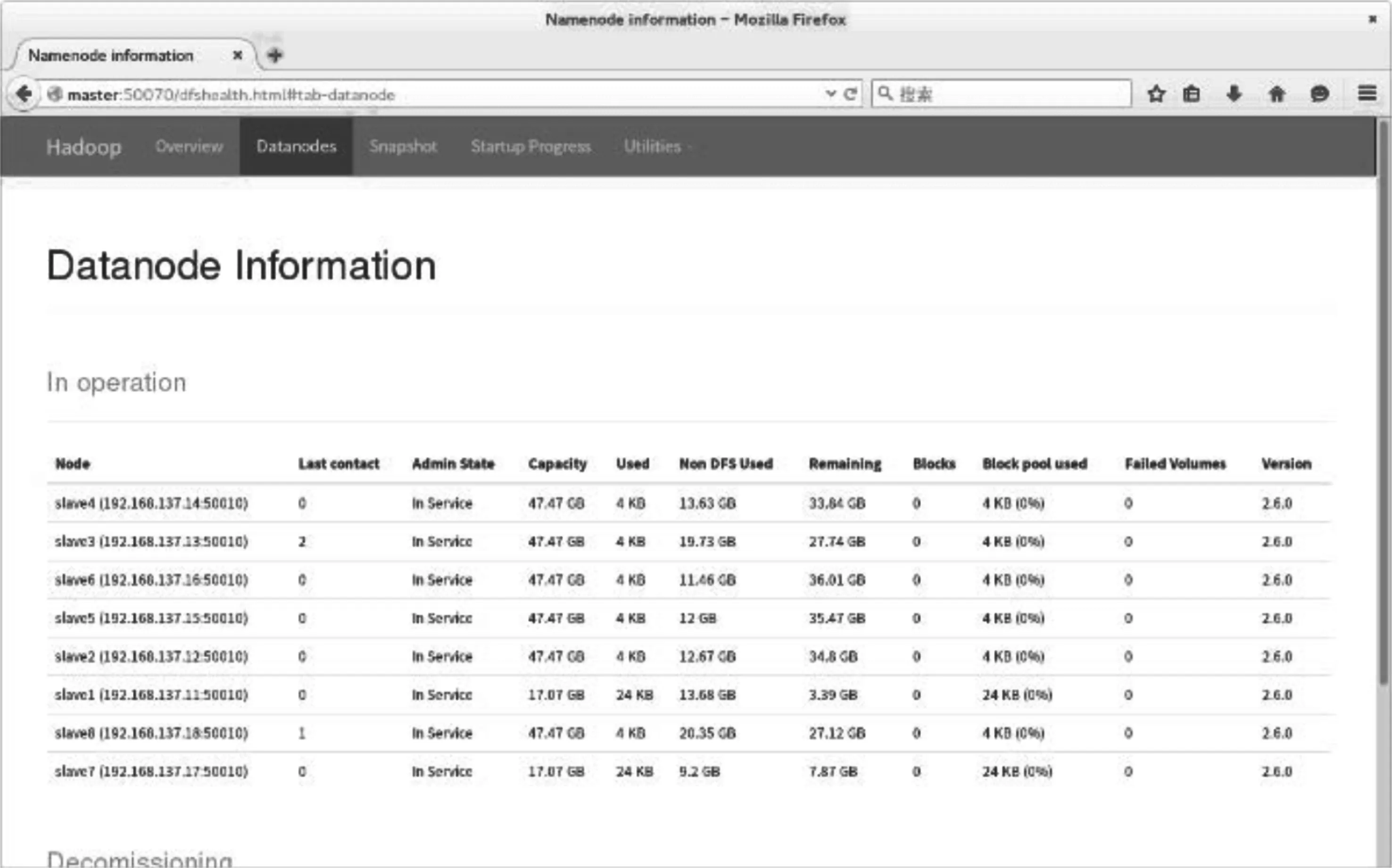
图6 数据节点(datanode) 信息
HBase集群的部署需要修改hbase-env.sh、regionservers和hbase-site.xml三个配置文件,配置完后发布至各节点,同时添加HBase环境变量。配置及发布完成后,通过地址http://master:16010/master-status可以在浏览器中查看master及各region server的情况。如图7所示。
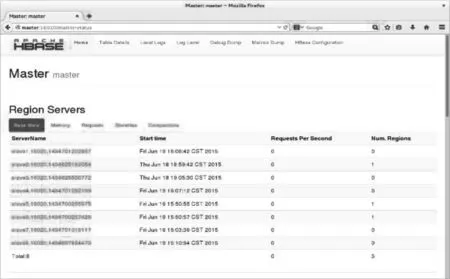
图7 HBase集群
ZooKeeper对于HBase和Solr来说是必不可少的组件,它提供了分布式系统的高效协调服务。HBase有内置的ZooKeeper,但不太稳定。因此在验证中采用独立安装模式进行配置。ZooKeeper的配置相对较简单,首先,在zoo.cfg文件中添加各机器节点信息,发布各机器节点;然后,根据zoo.cfg中的设置修改各机器节点上myid文件中的id号;修改完毕后,在各个机器节点启动ZooKeeper即可。
Solr索引服务需要结合tomcat进行安装和配置。首先,安装tomcat;然后,修改solrcongif.xml配置文件。修改完后发布各节点,通过启动tomcat即可启动Solr服务,通过地址http://slave1:8080/solr/在浏览器中可查看Solr的相关配置信息及查询结果。如图8所示。

图8 Solr Web界面
在界面上可以通过选择相应的Core来查看索引,也可以通过Solr提供的API接口来查询。
4.2效果验证
验证使用现有审计系统中的关系数据库MySQL和大数据存储系统进行对比。效果从两方面进行验证:存储能力和数据检索能力。
4.2.1存储能力
系统将收集到的数据同时存入MySQL和HBase,收集数据包括字段有:ID、用户ID、登录时间、退出时间、登录类型、登录机器、行为类型、行为描述等。数据写入时间为48小时。
从表2中可以看出,MySQL的存储量为1亿条数据,而HBase是2亿条。实际上,在试验中随着存入数据量不断增大时,MySQL写入性能开始劣化,越来越慢。而HBase的写入性能没有任何影响,最终,在规定时间内写入了2亿条数据,是MySQL的两倍。

表2 数据存储量
从理论上来说,HBase的存储能力是无限大的,它的存储能力与集群的存储空间相关。当集群的存储空间不足时,可以通过简单的添加机器即可,而且是廉价的PC机。但如果MySQL出现存储能力不足时,就需要提高机器的整体存储能力和性能,无法通过简单的添加机器来实现,而且还存在数据迁移的问题,成本较高,难度较大。
4.2.2数据检索能力
HBase由于在检索时,仅依靠RowKey实现,而RowKey不支持二级索引,检索效率非常不理想。通过Solr建立二级索引后,检索效率得到了极大的提升。以1千万条数据建立的索引为例,提升后的效率与MySQL的对比结果如表3所示。

表3 检索效率
从表3可以看出HBase改善后的检索能力是MySQL的17~35倍左右。该检索效率是在单个检索条件下的测试结果,如果是多条件检索的情况下,MySQL会出现无法响应的情况。
从上述验证结果可以看出,本文提出的方法能够有效的解决现有审计系统处理大数据存储和检索问题。
5 结 语
随着大数据时代的到来,现有审计系统在存储和检索能力上都出现了不能满足应用需求的问题。针对这些问题,从大数据的角度出发,利用大数据技术,并结合现有审计系统的架构,提出了使用大数据系统对海量数据进行存储和处理的方法,有效的解决的审计大数据存储问题。同时,针对HBase检索效率低下的问题,提出了使用Solr建立二级索引的方法,使得检索效率得到了大大的提升。本文提出的方法在兼容现有系统的同时,有效的解决了审计系统在大数据存储和检索上的问题。
[1]Wikipedia. Big Data [EB/OL]. https://en.wikipedia.org/wiki/Big_data. 2016.01.31.
[2]孟小峰,慈祥.大数据管理:概念、技术与挑战 [J].计算机研究与发展,2013,50(01):146-169.
MENG Xiao-feng and CI Xiang. Big Data Management: Concepts, Techniques and Challenges [J]. Journal of Computer Research and Development, 2013, 50(01): 146-169.
[3]Apache Hadoop. Home Page [EB/OL]. https:// hadoop.apache.org/. 2016.01.25.
[4]张锋军.大数据技术研究综述 [J]. 通信技术,2014,47(11): 1240-1248. ZHANG Feng-jun.Overview on Big Data Technology[J]. Communications Technology,2014,47(11):1240-1248.
[5]李明桂,肖毅,陈剑锋等. 基于大数据的安全事件挖掘框架[J].通信技术,2015,48(03): 346-350.
LI Ming-gui, XIAO Yi, CHEN Jian feng,et al. Big Data-based Framework for Security Event Mining[J].Communications Technology, 2015, 48(03): 346-350.
[6]HBase RowKey Design. HBase Reference Guide [EB/OL]. http://abloz.com/hbase/book.html # rowkey. design. 2013.04.07.
[7]Solr. Solr Home Page [EB/OL]. http://lucene. apache.org/solr/. 2016.01.01.
[8]HBase Coprocesser Introduction. Apache HBase Blog [EB/OL]. https://blogs.apache.org/hbase/ entry/coprocessor_introduction. 2015.12.17.

许杰(1978—),男,博士,工程师,主要研究方向为信息安全与大数据;
冷冰(1976—),男,硕士,高级工程师,主要研究方向为通信网络与信息安全;
李明桂(1989—),男,硕士,主要研究方向为信息安全与大数据;
丁文超(1991—),男,硕士研究生,主要研究方向为信息安全与大数据。
Application of Big Data Processing Technology in Audit System
XU Jie, LENG Bing, LI Ming-gui, DING Wen-chao
(No.30 Institute of CETC, Chengdu Sichuan 610041, China)
With the advent of big data era, there is an explosive growth in data volume. The emergence of massive data directly affects storage, processing and analysis systems of the existing data, including audit system,which plays an important role in network security. The current audit system implements data storage and processing with relational databases. Due to the limitations of relational databases, the audit system is unable to store and process big data. To solve this problem, a big data storage method compatible with the existing system is proposed, thus to effectively solve the problem of big data storage. Meanwhile, in order to solve the low efficiency of HBase retrieval, the method using Solr to establish secondary index is presented,which could greatly raise the retrieval efficiency and satisfy the needs of audit system in storing and processing big data.
big data; audit system; HBase; Solr
10.3969/j.issn.1002-0802.2016.03.018
2015-10-15;
2016-01-26Received date:2015-10-15;Revised date:2016-01-26
TP309
A
1002-0802(2016)03-0346-06
猜你喜欢
山东冶金(2022年2期)2022-08-08
河北理科教学研究(2021年4期)2021-04-19
军民两用技术与产品(2021年2期)2021-04-13
计算机教育(2020年5期)2020-07-24
福建基础教育研究(2020年3期)2020-05-28
科学技术创新(2020年22期)2020-01-09
科学与财富(2019年27期)2019-10-25
电子制作(2019年14期)2019-08-20
青春岁月(2016年21期)2016-12-20
专利代理(2016年1期)2016-05-17
