
一种基于奇偶并行译码架构的高吞吐量译码器设计
2016-09-03 08:32云飞龙朱宏鹏吕晶
通信技术 2016年3期
云飞龙,朱宏鹏,吕晶,杜 锋
(中国人民解放军理工大学,江苏 南京 210001)
一种基于奇偶并行译码架构的高吞吐量译码器设计
云飞龙,朱宏鹏,吕晶,杜锋
(中国人民解放军理工大学,江苏 南京 210001)
针对具有准循环结构的LDPC码,设计了一种高吞吐量译码器。该译码器利用并行分层迭代译码算法,通过校验矩阵同一列循环因子对应的变量节点之间的数据传递更新,实现迭代译码,不仅有效降低了译码时间,同时也省去了变量节点处理单元,另外为了进一步提高吞吐量,针对同一列循环因子都为奇数或偶数的基础矩阵,提出了一种奇偶并行译码架构,该架构一次可同时并行处理2个奇偶变量节点的值,有效节省了一半的译码时间,可将吞吐量提高一倍左右。最后基于Xilinx公司Virtex6系列的xc6vsx475t芯片实现了上述译码器设计,码字采用(3200,1600)LDPC码,经ISE软件环境下布局布线后,结果表明,当迭代次数为15时,译码器吞吐量可达300 Mbps,该研究成果具有重要的实用价值。
并行分层;高吞吐量;QC-LDPC;奇偶并行译码
0 引 言
LDPC码(Low-Density Parity-Check Code)[1]是一类具有稀疏校验矩阵的线性分组码,不仅有逼近Shannon极限的良好性能,而且具有译码复杂度低、结构灵活、易于在FPGA上实现等特点,另外,其译码算法在理论上可实现全并行架构,具有高速译码的潜能,因此成为近年来编码界的研究热点。
在高速译码领域,由于全并行架构[2]资源消耗巨大,在实际设计中,往往采用部分并行架构[3]。Zhang K[4]等人提出了一种并行分层译码算法(PLDA),该算法不仅省去了变量节点处理单元(VNU),减少资源消耗,而且可减少译码时间,能有效地提高译码吞吐量。本文基于PLDA算法,对文献[4]中的架构进行改进,提出了一种奇偶并行译码架构,该架构可同时处理奇偶2个变量节点,能将译码时间缩短一半,可进一步提高译码吞吐量,同时本文也给出了实现该架构矩阵需满足的条件,最后在FPGA上实现,验证了其架构的可行性,表明其吞吐量可达300Mb/s。
1 准循环LDPC码及其译码算法
1.1准循环LDPC码
准循环LDPC码[5]是结构化LDPC码的重要分类,由于其校验矩阵有规律可循,因此编译码比一般的LDPC码相对简便。
给定两个常数c和t,且c≤t,准循环LDPC码的奇偶校验矩阵由c×t的大小均为z×z的循环矩阵阵列组成,校验矩阵一般形式为:
(1)
式中,Pc,t是z×z的循环移位矩阵或者0矩阵。当Pc,t重量为1或0时,称为I型准循环LDPC码,否则称为II型准循环LDPC码。本文所指的矩阵是I型准循环LDPC码。
针对I型准循环LDPC,定义mb×nb的基础矩阵H′,c=mb×z,t=nb×z,矩阵形式如下式所示,其中,smb,nb为-1~(z-1)之间的整数,称为循环移位因子。
(2)
校验矩阵H可由mb×nb的基础矩阵H′扩展得到。基础矩阵中对应的元素值为-1时,将其扩展为z×z的全0矩阵,若为其它值s,则将其扩展为z×z的单位阵循环右移s次。
1.2译码算法
算法采用修正的最小和译码算法[6],它是由BP算法[7-8]演化而来,由于其易于硬件实现,因此被广泛采用,算法如下:
(2)校验节点更新:更新校验节点Cm向变量节点Vn,n∈B(m)传输的信息,B(m)表示与校验节点Cm相连接的变量节点集合;
(3)


(4)
(5)
(6)
(5)通过校验矩阵H和序列Wk的模2相乘可以得到第k次迭代的校验子序列Sk,如果有Sk=θ(θ为全0序列),则终止迭代,最后的输出序列W=Wk;
Sk=WkHTmod2
(7)
若校验式(7)不能完全满足,同时迭代次数k达到最大迭代次数限制,则终止迭代,译码失败,否则继续迭代处理,k=k+1,跳转到第2步。
2 奇偶并行译码架构设计
2.1并行分层迭代算法
假设一个QC-LDPC码校验矩阵HQC-LDPC,同一列有2,5,8三个移位循环因子,则并行分层迭代算法(PLDA)如图1所示。

图1 PLDA算法示意
图1中,带框的8,2,5表示循环因子对应的循环子矩阵,CNU表示一个校验节点处理单元。8对应的循环子矩阵数据经CNU模块处理完后,传递更新给5对应的循环子矩阵,5对应的循环子矩阵数据处理完后,传递更新给2对应的循环子矩阵,2对应的循环子矩阵数据处理完后,又传递更新给8对应的循环子矩阵。而在时序上,3个循环子矩阵是并列处理的。
上述可概括为:每一行变量节点处理完后传递更新给循环因子较小的行,而循环因子最小的一行传递更新给最大的一行,即8→5→2→8。该算法不仅省去了变量节点处理模块(VNU),且减少了一半译码时间,同时由于采用分层译码算法原理,在相同迭代次数条件下,与上文的最小和译码算法相比,能达到更低的误码率,换句话说,可减少迭代次数。
需注意的是,为了实现该算法,校验矩阵同一列循环因子每2个的差值必须大于每行处理的时钟周期数,不然无法完成一次完整的迭代。文献[4]通过对循环因子添加一个偏移量有效的解决了该问题。
2.2奇偶并行译码架构
假设上述矩阵HQC-LDPC每一个循环因子对应一个10×10阶单位循环矩阵,则PLDA算法具体表示如图2所示。

图2 PLDA算法具体示意
图2中,循环因子8对应的10个变量节点处理完后,传递更新给循环因子5对应的10个变量节点,循环因子5对应的10个变量节点处理完后,传递更新给循环因子2对应的10个变量节点,循环因子2对应的10个变量节点处理完后,又传递更新给循环因子8对应的10个变量节点,重复上述步骤,直到迭代终止,实现一次完整的译码算法。
在文献[4]的PLDA算法中,一次读取一个数据,针对上述矩阵HQC-LDPC,一次迭代则需要10个时钟周期,为了提高吞吐量,我们对此进行改进,将上述结构拆分成奇偶两半,拆分后的PLDA算法示意图如图3所示。
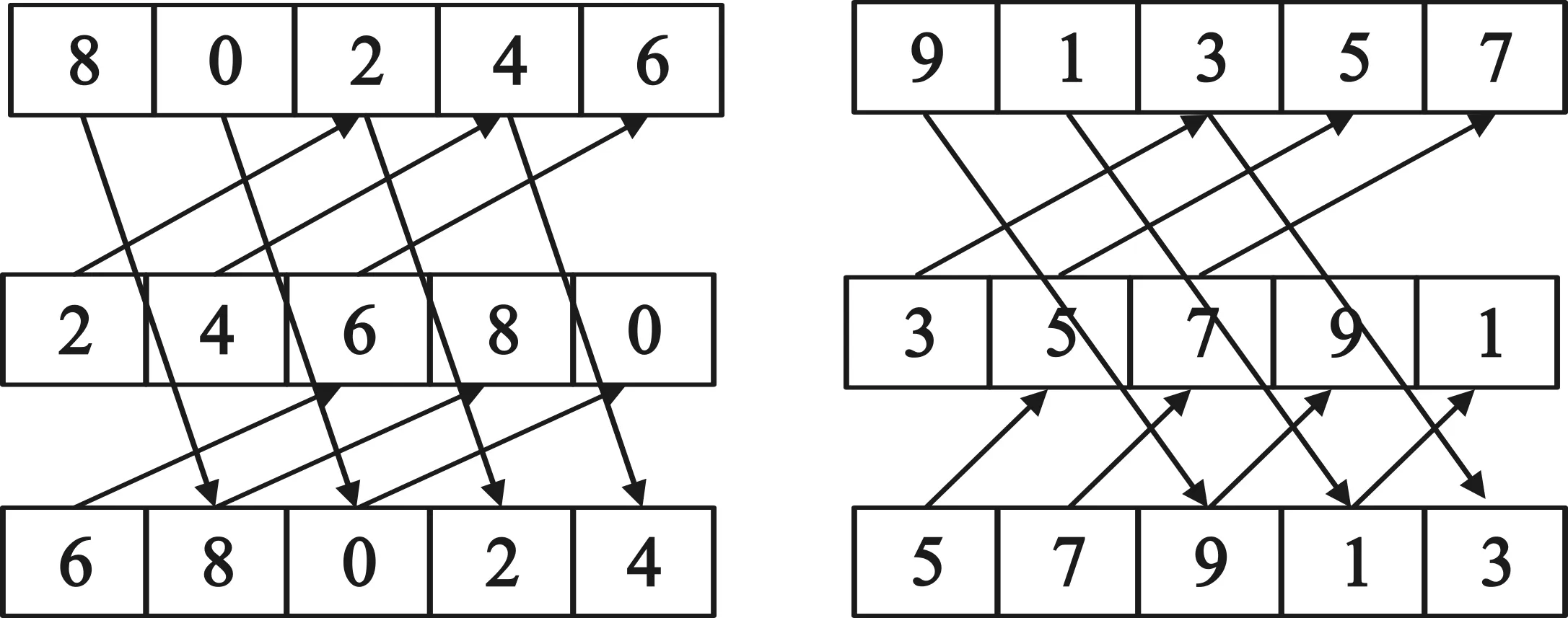
图3 改进后的PLDA算法示意
图3中,将原来的一个完整的10×10阶单位循环矩阵,拆分成2个奇偶数对应的5×5阶矩阵,2组奇偶数对应的矩阵分别各自独立的采用PLDA算法。就译码架构来说,在同一时刻译码器可同时并行处理2个变量节点,节省译码器一半的时间,有效提高了译码吞吐量,然而这种架构的缺点是,在存储器资源消耗上,原来一个循环因子对应一块RAM资源,现在一个循环子矩阵拆分成2个独立的奇偶数矩阵,此时相当于1个循环因子变成了2个循环因子,因此存储器RAM资源增加了一倍,这种架构是通过牺牲存储资源来换取高吞吐量。
为了节省RAM存储资源,同时又能在同一时刻译码器同时并行处理2个变量节点,可以将一个循环因子对应的变量节点的值存储到同一块RAM中,同一时刻读取连续的2个奇偶数,这样就可以实现上述架构的思想原理。以图2中变量节点8和9为例,我们可将循环因子8对应的变量节点的值全部存储到一块RAM中,读取位宽是2个变量节点的量化位宽,即一个地址读取2个数据,此时一次可同时读取变量节点8和9,送入CNU模块处理,处理完后的数据送给循环因子5对应的变量节点8和9,后面的处理操作亦是如此。然而这种架构存在的问题是,同一列循环因子如果既有奇数,也有偶数,那么就会使得地址访问不协调。如图2中,循环因子8是偶数,就存储器RAM来说,变量节点8和9位于同一地址,而循环因子5是奇数,变量节点8和9分别位于存储器RAM的2个地址内,同一个时钟周期无法全部读取,最终不能有效地完成译码。因此这种架构要求在矩阵设计的时候,同一列循环因子必须都为奇数或者偶数,这样才能保证并行处理的2个奇偶数据位于RAM的同一地址内,而不会造成地址访问不协调问题,同时为了奇偶对称,循环因子扩展矩阵的阶数z必须为偶数,如下面的矩阵H,该矩阵是一个16×32基础校验矩阵,每一列的循环因子或者为偶数,或者为奇数,该矩阵可实现上述奇偶并行译码架构。

3 译码器的FPGA实现
译码器系统框图如图4所示,主要包括输入控制模块、译码模块以及输出控制模块。译码器采用上述矩阵H,码字采用(3200,1600)LDPC码(阶数z为100,是偶数),接收到的译码信息采用6 bit量化,同时译码器迭代次数设为15次。

图4 译码器系统框
输入模块主要是对信道似然比信息(LLR)存储器进行初始化,初始化为接收到的量化译码信息,同时对外信息存储器也进行初始化操作,初始化数据为0。需注意的是,在输入控制模块中,对信道似然比信息存储器(RAMLLR)的写入顺序操作与循环因子大小有关,假设循环因子是8,则RAMLLR对应的初始化操作如图5所示,0地址存入的数据是循环因子8对应的变量节点的值,1地址存入的数据是第9个变量节点的值,2地址存入的数据是第10个变量节点的值……后面地址按顺序依次存入对应的数据,因此不同的循环因子对应不同的输入控制模块,总共有107个循环因子,则对应107块RAMLLR及其相应的输入控制模块,而外信息存储器(RAM外信息)的初始化与循环因子无关,因此只需一个输入控制模块即可对应107块RAM外信息。其中,对RAMLLR和RAM外信息的初始化操作在a端口完成。

图5 RAMLLR初始化示意
输出模块主要将最后一次译码迭代数据的符号位送入寄存器,每一列循环因子对应一个位宽为100的寄存器,总共需要16个这样的寄存器,即对应校验矩阵的前16列信息位,最后通过并串转换模块将1600个信息位按比特依次输出。
图4中,中间虚线框的译码模块是译码器的核心部分。在译码过程中,对RAMLLR进行读取时,每次读取一个地址,2个数据,位宽为12,读取的数据送入2个并列的CNU模块,对RAM外信息读取操作与对RAMLLR的操作一样,读取的数据也送入2个并列的CNU模块。每一行的LLR值通过2个CNU模块处理完后,经数据交换网络,传递更新给其对应的另一行,而外信息处理完后,原路返回,更新上一次迭代的值。数据交换网络由并行分层译码算法的传递规则决定:每一行变量节点处理完后传递更新给循环因子较小的行,而循环因子最小的一行传递更新给最大的一行。其中,在译码时对RAMLLR和RAM外信息的读取和更新操作都在b端口完成。由于对RAMLLR的译码读取写入操作,循环因子对其的影响在初始化的时候已经消除,而RAM外信息完全不受循环因子的影响,因此可采用同一个模块对所有的RAMLLR和RAM外信息进行读取写入操作,有效降低了资源消耗。
整个译码器的译码过程概括如下:
(1)初始化:将接收到的3 200位编码信息进行6比特量化,并送入对应的RAMLLR,对其初始化,同时对RAM外信息也进行初始化,初始化数据为0,每块RAMLLR和RAM外信息的a端口深度为100,位宽为6。
(2)译码:初始化完成后,分别读取RAMLLR和RAM外信息对应的数据,进行译码迭代,一次读取2组数据,分别送入2个并列的CNU模块,CNU模块处理完后返回2组新的数据,新的外信息值直接原路返回,更新本行上一次迭代的值,而LLR值则通过数据交换网络传递更新给其对应的其他行,对RAMLLR和RAM外信息的译码读取写入操作在b端口完成,其深度为50,位宽为12。
(3)译码输出:当迭代次数达到15后,停止译码,将译码数据输出,基础校验矩阵的前16列,每一列对应一个位宽为100的寄存器,用于存放译码数据的符号位,寄存器再通过并串转换,将译码数据按比特输出。同时,由于译码数据位于16个寄存器中,因此可对RAMLLR里面的数据进行修改,此时可对下一帧数据进行初始化操作,而不用等上一帧数据完全译码输出,能有效减少译码等待时间。
4 仿真结果及其资源消耗
4.1性能仿真
针对本文上述矩阵H,图6给出了采用BPSK调制后的误码率性能。

图6 误码率性能仿真比较
从图6中可看出,相同迭代次数条件下,5 bit量化性能最差,而6 bit与7 bit性能比较接近,因此综合考虑性能和资源消耗,选择6 bit量化。
同时从图6中也看出,相同量化位宽条件下,15次迭代与20迭代性能相比,相差不大,但是15次迭代比20次迭代吞吐量更高,因此综合考虑后,选择迭代次数为15。
4.2资源消耗情况
在Xilinx公司的FPGA上实现了译码器设计,FPGA采用Virtex6系列xc6vsx475t芯片。资源消耗情况见表1。

表1 译码器资源利用
在ISE环境下布局布线后,结果表明最高时钟频率可达169.112 MHz,迭代15次后,吞吐量可达300 Mb/s。
吞吐量计算公式如下:
(8)
在式(8)中,ninformation是LDPC编码帧包含的信息位,fmax是译码器能达到的最高时钟频率,nClk是译码器迭代一次消耗的主时钟周期数,nIter是译码器迭代的次数。
5 结 语
本文针对具有准循环结构的LDPC码,设计了一种奇偶并行译码架构,该架构利用并行分层迭代译码算法,有效地省去了变量节点处理单元,降低了硬件资源消耗,同时该架构并行处理奇偶2个变量节点,能省去一半的译码时间,可进一步提高吞吐量,最后通过性能仿真、分析以及硬件实现,表明在6 bit量化以及15次迭代的情况下,译码器性能优越,同时我们在FPGA硬件上进行了实现,结果表明其吞吐量可达300 Mb/s,该研究成果具有重要实用价值,可应用于高速数字通信领域。
[1]Gallager R G. Low-Density Parity-Check Codes[J]. Information Theory, IRE Transactions on,1962,8(1):21-28.
[2]Sivakumar S. VLSIImplementation of Encoder and Decoder for Low Density Parity Check Codes[D].Houston :Texas A&M University, 2001.
[3]Hocevar D E. A Reduced Complexity Decoder Architecture via Layered Decoding of LDPC Codes[C]//IEEE Workshop on Signal Processing Systems. USA, 2004,107-112.
[4]ZHANG K, HUANG X and WANG Z. High-Throughput Layered Decoder Implementation for Quasi-Cyclic LDPC Codes[J].Selected Areas in Communications, IEEE Journal on, 2009, 27(6):985-994.
[5]Fossorier M P C. Quasi-Cyclic Low-Density Parity-Check Codes from Circulant Permutation Matrices[J]. Information Theory, IEEE Transactions on. 2004, 50(8):1788-1793.
[6]姜明.低密度奇偶校验码译码算法及其应用研究[D]. 南京: 东南大学, 2006.
JIANG Ming. Decoding Algorithm and Applied Research of Low-Density Parity-Check Code[D] .Nanjing: Southeast University, 2006. (in China)
[7]CHEN J, Dholakia A, Eleftheriou E, et al .Reduced-Complexity Decoding of LDPC Codes[J]. Communications, IEEE Transactions on,2005,53(8):1288-1299.
[8]陈燕,蔡灿辉.LDPC码的译码算法研究[J].通信技术,2008,41(12):87-91.
CHEN Yan and CAI Can-hui. Research on the LDPC Decoding Algorithm [J].Communications Technology,2008,41(12):87-91.

云飞龙(1990—),男,硕士,主要研究方向为信道编码;
朱宏鹏(1982—),男,博士,主要研究方向为信道编码;
吕晶(1965—),男,教授,主要研究方向为卫星通信;
杜锋(1990—),男,硕士,主要研究方向为卫星通信。
A High-Throughput Decoder based on Architecture of Decoding Odd and Even in Parallel
YUN Fei-long,ZHU Hong-peng,LV Jing, DU Feng
(PLA University of Science and Technology,Nanjing Jiangsu 210001,China)
In connection with QC-LDPC, a high-throughput decoder is designed, which could, with parallel layered decoding algorithm, could enable the variable nodes of the same column circulating factors to correspondingly transmit and update data with each other and realize iterative decoding, thus reducing the decoding time and saving the variable-node disposing unit and the resource. In addition, a new architecture of decoding odd and even in parallel to increase the throughput is proposed and applied to the basic matrix where all of the same columns circulating factors are odd or even. This architecture could decode two variable nodes in parallel, thus to save half time and double the throughput. Finally, the decoder design is implemented on basis of Xilinx Virtex6 xc6vsx475t, and (3200, 1600) LDPC. After the ISE software layout and wiring, the experiment result indicates that the throughput could reach 300Mbps at 15 iterations. This achievement is of important practical value.
parallel layered; high-throughput; QC-LDPC; decoding odd and even in parallel
10.3969/j.issn.1002-0802.2016.03.003
2015-10-11;
2016-01-19Received date:2015-10-11;Revised date:2015-01-19
国家自然科学基金(No.91338201)
TN911.22
A
1002-0802(2016)03-0264-06
Foundation:National Natual Science Foundation of China(No.91338201)
猜你喜欢
沈阳工业大学学报(2021年6期)2021-11-29
现代电子技术(2021年7期)2021-04-08
中学生数理化·高一版(2021年1期)2021-03-19
现代计算机(2021年36期)2021-03-14
中学生数理化(高中版.高二数学)(2020年9期)2020-10-27
中学生数理化·高一版(2019年9期)2019-10-12
科技视界(2018年27期)2018-01-16
时代英语·高一(2017年5期)2017-11-14
科教导刊·电子版(2016年36期)2017-04-22
中国惯性技术学报(2015年1期)2015-12-19
