
HSSM:一种流数据分层次模最大化方法
2016-08-31 04:36:11张奋翔陈华辉钱江波董一鸿
计算机研究与发展 2016年8期
张奋翔 陈华辉 钱江波 董一鸿
(宁波大学信息科学与工程学院 浙江宁波 315211)
HSSM:一种流数据分层次模最大化方法
张奋翔陈华辉钱江波董一鸿
(宁波大学信息科学与工程学院浙江宁波315211)
(zhang_fenxiang@163.com)
从大规模数据中“摘要”出最能满足效用函数收益的有限个数据对象,可以被归纳为次模函数最大化问题.并行过滤算法在满足流数据访问次数限制与实时响应的条件下,通过分布式筛选的方式实现次规模最大化,但在提升摘要速率时效用函数收益损失较大.提出一种流数据分层次模最大化算法HSSM,在仅访问一次数据集的条件下,采用流水并行的分布式处理框架得到接近于标准贪心算法的次模函数收益,同时改进HSSM通过累积摘要的压缩存储、分层过滤低增益对象提升摘要速率.该方法在数据摘要问题的相关领域具有广泛的应用性,如文档集中代表性文章的选取、数据集中心点选取等.实验结果显示,分布式算法Spark-HSSM+对比于传统的算法在运行速率上达到与摘要规模k成k2正比例关系的提升.而相对于其他分布式算法,其实验效用收益与理论最差收益都更接近于贪心算法.
流次模最大化;分层模型;流水并行;数据摘要;Spark分布式平台
在信息飞速增长的时代,经常需要从海量数据或仅能访问一次的流数据中“摘要”出一个较小的且具有代表性的数据集[1-2],例如,热点文章及热门微博推荐[3-4]、文档中概要语句提取[5]、数据集中心点选取[6]、数据集中噪声的查找[7]和社交网络中最大影响力节点的选取[8]等.摘要方法通常使用某种效用函数或称收益函数(utility function)来评价所选子集的“代表性”是否达到目的.数据对象在摘要过程中往往具有收益递减的所谓次模特性[9].次模最大化即研究如何利用该次模特性摘要出一个小规模对象集合,实现对原始数据集的主要特征概括.
围绕次模最大化问题已有不少的相关研究.最先由Nemhauser等人[9]提出使用标准贪心算法在有限次访问数据集的条件下,得到具有最低收益保证的摘要结果;Mirzasoleiman等人[10]设计出适用于处理静态大规模数据集的主从分布式摘要算法,在运行效率上对标准贪心算法做出改进;Gomes等人[11]针对无法二次访问的动态流数据,提出了通过有效维护一个指定大小的对象集合完成近似最大化收益摘要,但存在流数据实时响应速率慢的不足;Badanidiyuru等人[12]使用离散化预估最优收益的方法设计有限数量的过滤器,通过并行筛选的思想提升流数据实时摘要速率.
Badanidiyuru等人虽然在摘要的实时性方面提出改进,但存在摘要结果收益降低的缺陷.针对该问题,本文提出一种流数据分层次模最大化摘要算法(hierarchical streaming submodular maximization, HSSM),采用分层流水并行和逐层摘要的策略实现分布式运算与次模收益最大化.该方法仅需要访问一遍数据集,即可得到规模为k且效用收益至少满足1(2-1k)倍最优解的摘要结果.对每批数据量为v的流数据摘要,仅需要O(v+k)的时间开销即可完成更新.该方法摘要的理论与实验收益优于其他并行算法而略低于贪心算法,但在运行效率上较贪心算法有很大的提高.实验证明:本文算法可以有效地解决流数据的次模函数最大化问题.
1 流次模最大化问题
1.1次模函数最大化
从规模为n的数据集合O中选取大小为k的对象集合S作为摘要.效用函数f(S)用于表示摘要结果S对数据集O的效用收益,不同应用场合可有不同的效用函数.如1.2节的例子分别使用基于覆盖率与距离损失函数的效用函数,由以下定义得知,该效用函数均为次模函数.
定义1. 次模函数.有限集合O和定义在其幂集2O→上的单调实函数f,称f为次模函数当且仅当O的任意2个子集A,B及元素e,A⊆B⊆O,e∈OB,满足:
f(A∪{e})-f(A)≥f(B∪{e})-f(B).
(1)
用Δf(e|A)=f(A∪{e})-f(A)表示元素e对集合A的效用增益(marginal gain),式(1)说明次模函数的收益递减性质:若其他元素被先于元素e添加至集合A,将导致元素e的效用增益降低,即Δf(e|B)≤Δf(e|A).
定义2. 次模函数收益最大化(简称次模最大化).从数据集O中萃取出有限规模为k的代表性子集S,通过次模函数的收益递减特性选取近似最优解,使得S满足效用收益f(S)最大化,该过程称为次模最大化:
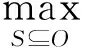
(2)
贪心算法是次模最大化的代表,其通过k轮迭代添加效用增益最大元素e∈OA至集合A,使得规模为k的集合A效用收益尽可能最大化,并通过次模最大化特性证明其在最差情况下的收益保证.
定义3. 摘要.基于效用评价函数从集合O中选取一个规模较小且具有高效用收益的子集S,则称子集S为集合O的摘要.
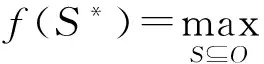
1.2次模最大化的典型问题
本文主要关心持续不断到来的流数据或仅能访问一遍的大规模数据摘要问题,下面是2个典型例子.
1.2.1 基于覆盖率的摘要问题
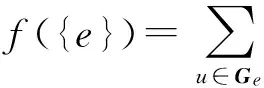
(3)
摘要集合应尽可能覆盖数据集的总信息收益f(O),以覆盖率(式(3))表示摘要S包含数据集O的信息收益比例[1,13].在逐个选取摘要对象的过程中,覆盖率函数满足ΔCov(e|Si-1)≥ΔCov(e|Si)的次模特性,故该问题是次模最大化问题.
1.2.2基于距离损失函数的中心点选取问题
求解k-medoid(k-中心点)问题是典型的数据挖掘应用[14-15],通过最小距离损失选取若干个对象为数据集中心点(如聚类中心等).其评价标准是最小化中心点与其他对象的距离之和,对于一个数据集O,使用距离函数(如欧氏距离公式:d(x,x′)=‖x-x′‖)表示集合O中对象间距离:O×O→.该问题的摘要损失函数L被定义如下[11]:
(4)
通过辅助对象e0=0,即可将L转换为具有次模特性的距离损失函数:
f(S)=L({e0})-L(S∪{e0}).
(5)
1.3次模最大化问题的相关算法
1.3.1 标准次模最大化算法
Nemhauser等人[9]提出的Standard-Greedy算法(及与次模相关的标准贪心算法[16-17])在解决次模最大化问题中给出近似最优解方案.该算法每次迭代访问数据集时,将满足最大化边际收益的对象添加到摘要集合中:
Si=Si-1∪{arg max Δf(e|Si-1)}.
(6)
文献[9]证明了在最坏情况下,该算法依然可以给出效用收益满足大于(1-1e)倍的最优解收益,并且没有其他方法能在同样访问量级上保证更优的最差解收益.
1.3.2流次模最大化算法
与静态数据处理不同,流数据具有动态增长的特点(搜索引擎Bing每10 min就产生超过1 TB的数据[18]).流数据摘要算法的提出是为了解决静态摘要方法在多次访问数据集方面的不足.
流数据的摘要算法是在有限的时间及内存空间开销条件下得到近似最优收益的解决方案,主要包含以下3个难点:
1) 摘要算法访问数据集的总次数,即非特定条件下流数据不能被二次访问.
2) 算法完成摘要的运行时间.流数据处理要求极高的实时性,因此摘要完成的运行时间是评价流算法符合需要的重要指标之一.
3) 算法最差解的摘要收益.流算法通常由于条件限制而给出近似解,故必须保证算法在最差情况下解收益的可接受性.
Gomes等人提出的Stream-Greedy算法[11]通过对比替换的方式,维持摘要S的效用收益最大化:若存在新对象oi替换b∈Sk,使得摘要S的效用收益增加,则替换Sk=Sk∪{oi}{b}.该方法在解决流次模摘要问题的同时仍存在2方面缺陷:1)在数据增益非均匀的情况下,该算法的摘要收益仅为1k最优解;2)该算法对于分批规模为v的流数据更新时间复杂度为Ω(kv),因此无法在短时间完成对大规模摘要(k很大)的更新.
1.3.3分布式次模最大化算法
为了解决流算法更新时间开销大的难题,相应的分布式解决方案被提出.Mirzasoleiman等人[10]与Kumar等人[19]分别提出解决次模函数最大化问题的分布式算法.其中,文献[19]的Greedy-Scaling算法要求已知单对象最大增益值 (即摘要至少访问2次数据集)且未给出具体实现,故本文未对其进行对比.
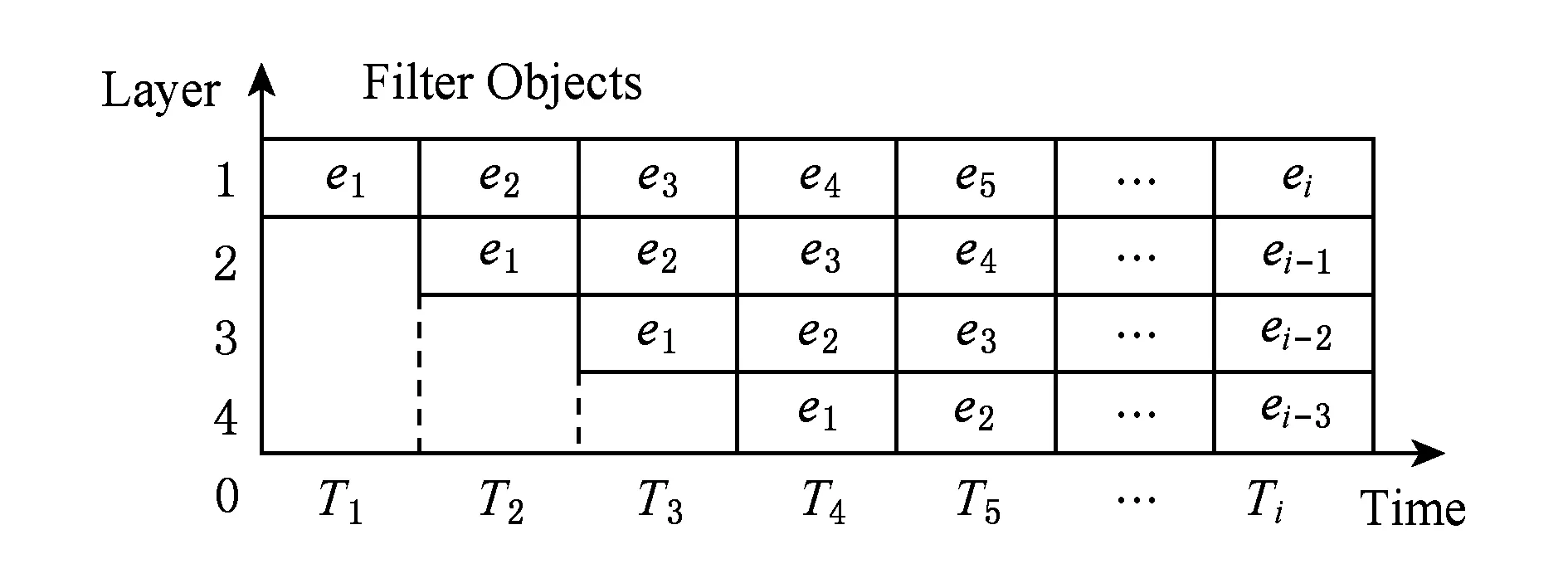
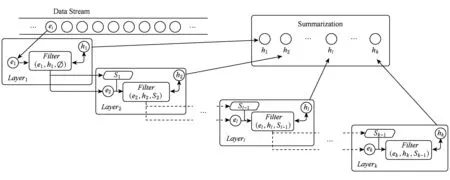
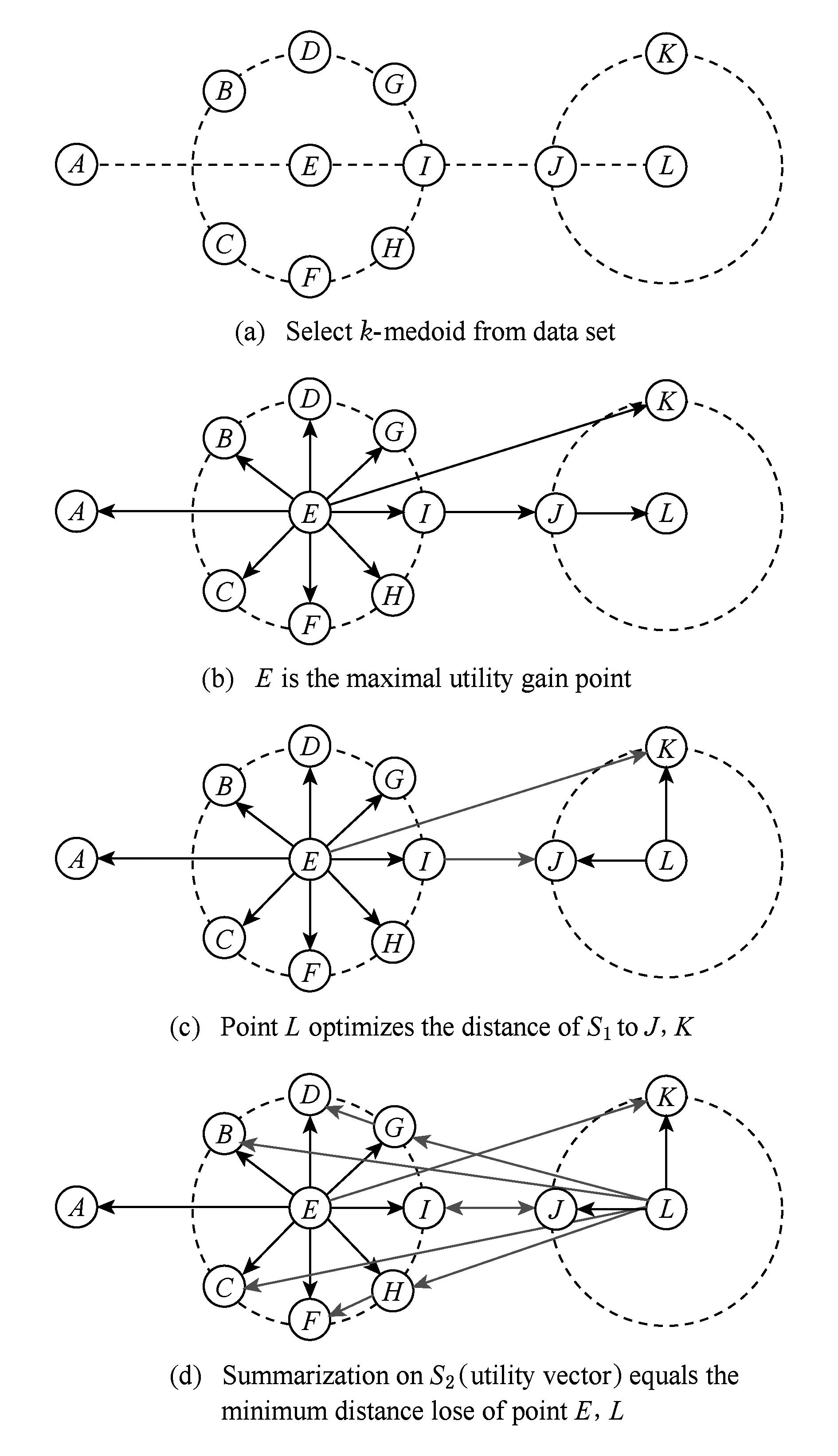
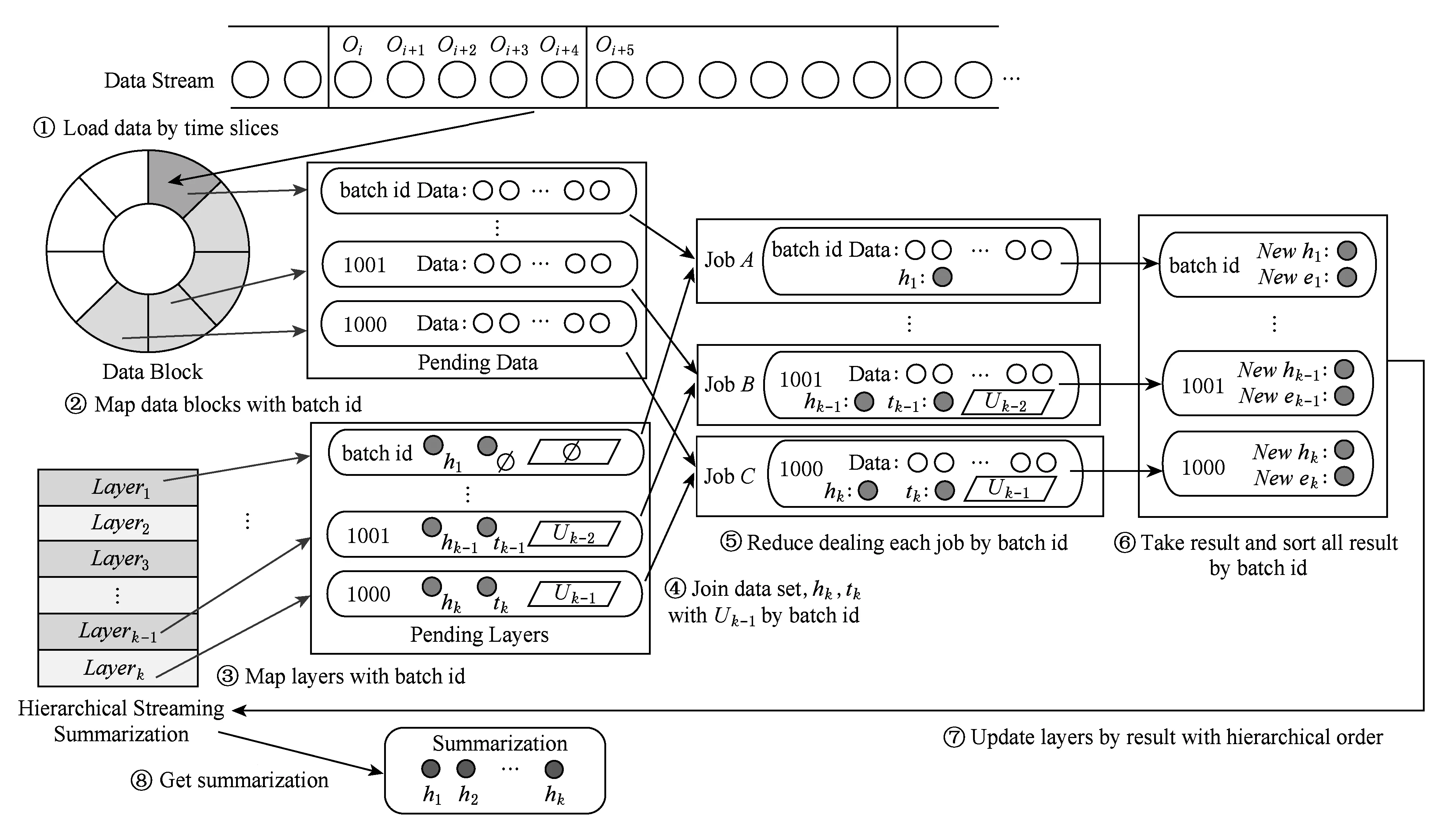
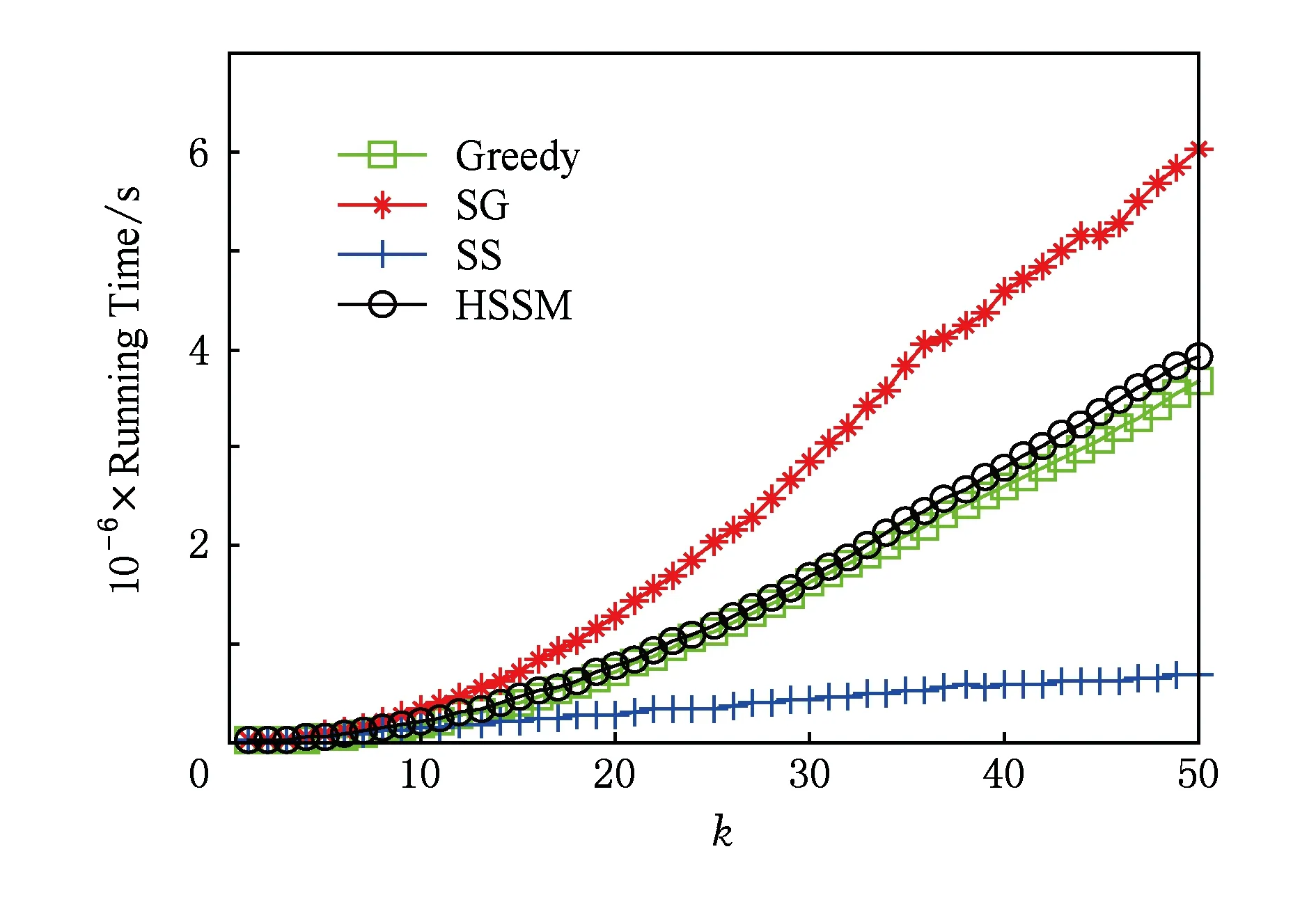
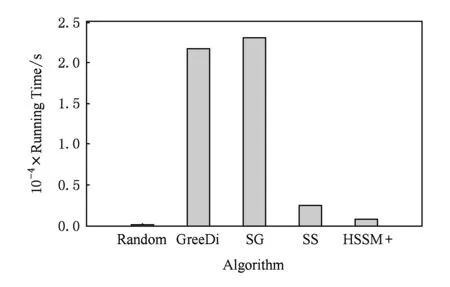
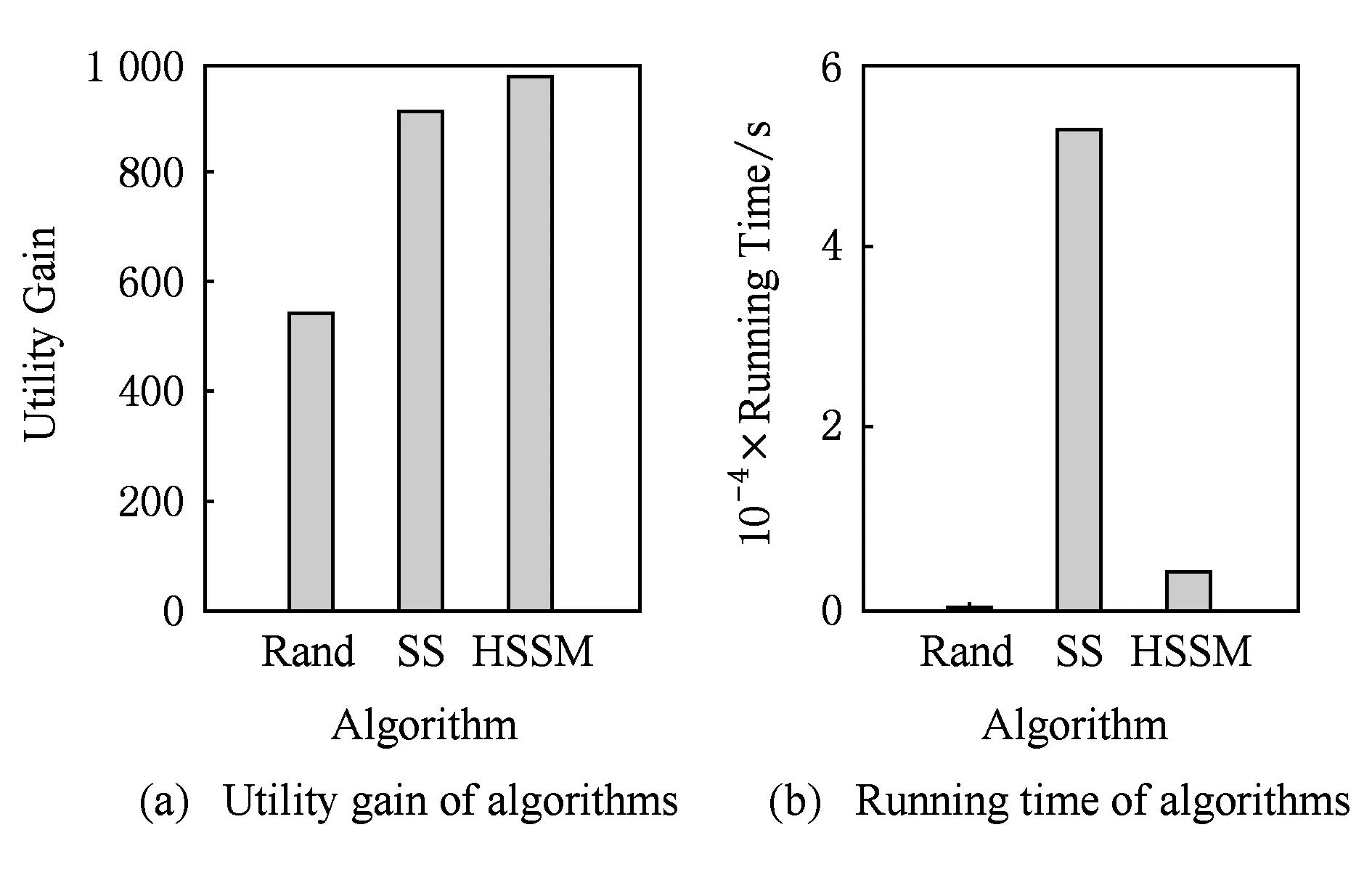
Badanidiyuru等人[12]提出具有最差收益保证的快速分布式次模摘要方法(Sieve-Stream),实现以当前单个对象的最大收益值m及离散系数ε预估出最优解集合T={(1+ε)i|m≤(1+ε)i≤k×m}.对于新数据e,通过i个以ti∈T作为目标收益的过滤器并行筛选:当摘要规模|S| 文献[12]是具有最低收益保证且满足分布式快速摘要的次模最大化算法,但该算法在流数据筛选过程中缺陷.一方面,若指定摘要规模为k,由于流数据具有增益不确定性(因此需要最差解保证),使得大多数过滤器通常处于非饱和状态,故摘要并没有达到收益最大化;另一方面,对于因单对象最大收益增大而新产生的过滤器,由于该过滤器无法访问已处理数据(流数据在非特定情况下只能访问一次),将导致许多高收益的对象被忽略处理.实验表明,该算法在实际摘要问题中的确存在效用收益明显低于大部分次模摘要算法的现象.因此,本文旨在提出新的分布式次模最大化算法,同时满足尽可能高的效用收益. 由于传统次模最大化问题的研究无法解决流数据摘要问题;同时,现存的流算法在提高摘要效率的同时存在降低摘要收益或最低收益保证过低的问题.因此,本文提出基于次模最大化的分层流摘要算法旨在解决3个难点:1)算法可以适用于解决流数据摘要问题;2)通过次模特性使得摘要获得尽可能高的收益及满足最低收益保证;3)设计分布式处理框架旨在提高摘要速率. 2.1分层次模最大化 本节设计一种新的并行处理框架用于解决流数据摘要在分布式处理方面的难题.由流水线并行(pipeline)[20]处理技术启发,通过分割次模增益的方法提出分层次模最大化算法HSSM. 根据1.1节给出的定义,为使摘要获得尽可能高的收益,次模最大化方法通过k轮迭代添加最大增益对象组成摘要集合S.由于分批到来的流数据不能够一次性全部访问,因此通过分层保留已访问数据的逐轮次优摘要对象hi来替代全局的最高增益对象.新数据对次优累积摘要的效用增益为:Δf(ei|Sj)=f(Sj∪{ei})-f(Sj),Sj={h1,h2,…,hj}.若数据ei的增益高于某轮最大增益对象hj时,替换hj与ei,进而实现流数据的摘要过程满足次模最大化. 由于同一时刻的数据增益筛选过程相互独立(即数据对象ei对于不同的累积摘要Sj需被计算k次),进而通过如图1所示的流水并行模式分层进行数据增益对比.其中,时刻Ti的数据在顶层V(累积摘要为空时)完成增益对比;与此同时,其余层也分别基于不同的累积摘要Sj对数据ei-j+1进行的增益筛选. Fig. 1 Data processing in pipeline mode.图1 流水并行模式处理数据 总体来说,传统的迭代算法使得规模为n的数据集被访问k轮后完成摘要筛选工作,其时间复杂度为Ω(nk).而流水并行的方法通过在连续的个时间单位比较待处理数据,进而实现基于不同累积摘要的多次增益筛选,使得总处理时间减少为Ω(n+k),一般而言v≫k,故摘要的总时间复杂度约为Ω(n). 结合流水并行模式的分层摘要算法HSSM如图2所示,其对单个数据对象处理的主要步骤如下: 1) 算法从流数据中逐一获取待处理数据ei,并将该数据作为输入传入首层. 2) 构建分层(图1中Layerl)数据结构:el表示第l层的待处理对象;Sl-1表示第l层之上的累积摘要结果:初始化S0对象为空,逐层完成增益筛选后,更新Sl=Sl-1∪{hl}并传递给l+1层完成增益累积;摘要维持对象hl是自身与待处理对象el基于累积摘要Sl-1对比后的高收益者: (7) 3) 通过自顶(第1层)向下的方式,逐层完成数据el与维持对象hl的筛选.根据增益比较结果输出 4) 算法在处理完所有数据后,通过合并各Layerl中摘要维持对象组成规模为k的摘要结果S={h1,h2,…,hk}. 算法1完成了分层模型中Layerl的数据筛选工作,行①②为摘要维持对象与待处理数据的增益计算,其中f为任意的效用函数;行③~⑨首先将待处理数据与摘要维持对象进行增益对比,对比的结果决定是否更新摘要维持对象,同时返回下层待处理数据与累积摘要. Fig. 2 The processing of per object in HSSM.图2 流数据对象在HSSM算法中的顺序处理流程 算法1. 增益筛选算法Filter(ei,hl,Sl-1). 输入:待处理数据ei、摘要维持对象hl、累积摘要Sl-1; 输出:下层待处理对象ei+1、本层摘要维持对象hl、下层累积摘要Sl. ① 计算维持对象hl增益:g_h=Δf(hl|Sl-1); ② 计算待处理对象ei增益:g_e=Δf(ei|Sl-1); ③ ifg_e>g_h ⑤tmp=hll,hl=ei; ⑥ return [tmp,hl,Sl-1∪{hl}]; ⑦ else ⑨ return [ei,hl,Sl-1∪{hl}]. 综上所述,HSSM算法通过流水线并行的方式分层解决流数据次模最大化摘要问题,同时该算法通过指定分层数量k确定摘要结果规模. 2.2HSSM算法的收益分析 HSSM算法与其他次模最大化方法都无法保证摘要结果在所有情况下都达到最优解收益.本节旨在分析该算法在最差情况下的摘要效用收益保证. 定理1. 在摘要维持对象(h1,h2,…,hk)未改变的情况下(即被过滤对象ek=ei=e1),过滤对象ek满足Δf(ek|Sk-1)≤f(Sk)k. 证明. 在HSSM算法中,设hi是第i层的摘要维持对象,i=1,2,…,k,满足收益递减特性: Δf(h1|S0)≥Δf(h2|S1)≥…≥Δf(hk|Sk-1). (8) 被第i层过滤的数据对象ei,其增益小等于该层摘要维持对象:Δf(ei|Si-1)≤Δf(hi|Si-1).特别地,当该对象被所有层过滤时,其增益小于式(8)中最小增益维持对象:Δf(ei|Sk-1)≤Δf(hk|Sk-1). 由式(8)同时得出,第i层摘要维持对象hi的收益小于等于本层累积摘要的平均收益:Δf(hi|Si-1)≤f(Si)i,且平均累积收益同时满足逐层递减特性:f(S1)1≥f(S2)2≥…≥f(Sk)k.故推出被过滤对象ek在所有层被过滤时,满足增益小等于累积摘要集合的最小平均收益: Δf(ek|Sk-1)≤Δf(hk|Sk-1)≤f(Sk)k. 证毕. 证毕. 定理3. HSSM算法的摘要收益f(Sk)对比最优解S*的收益f(S*),满足f(Sk)≥1(2-1k)×f(S*). 证明. 易得知:最优解S*与摘要Sk的收益交集不大于Sk的效用收益;同时摘要Sk中所有不被包含的效用收益至多为定理1中被HSSM算法过滤的增益;进而通过定理2中第k层过滤对象的增益损失上界,推导出摘要Sk的最低效用收益. 证毕. 定理1表明被过滤的对象其增益不大于所选摘要S的平均增益;定理2表明,即使摘要S改变,已被过滤的对象增益也不会超过新摘要S′的平均增益;定理3得知,基于分层思想的次模最大化方法,在最坏情况下仍可以得到大于1(2-1k)最优解的收益. 2.3HSSM算法的改进 进一步分析HSSM算法,存在3点可改进之处: 1) HSSM算法中的分层模型存在收益递减特性,使得底层出现大量满足Δf(ei|Si-1)<σ的低增益对象,存在重复计算效用收益的问题; 2) HSSM算法通过式(7)进行数据增益对比的过程中,当累积摘要集合规模 (即|Si-1|≤k)较大时,将导致效用收益计算f(Si-1)的时间开销过大; 3) 摘要规模(k)较大时可能导致分层数量过多. 本节对这3方面不足提出进一步改进的做法. 2.3.1通过阈值过滤低增益对象 针对效用函数收益计算的时间开销问题,HSSM算法提出基于次模函数最大化收益递减特性的最低增益阈值过滤方法,使得各层不再将增益小于σ的待处理对象ei传输至下一层,进而减少了低增益对象的增益计算开销. σ=min(μ,Δf(hk|Sk-1)). 2.3.2效用向量替代累积摘要 围绕次模最大化方法中存在效用函数增益计算问题,大多数算法通过遍历累积摘要集合Si与新增数据e的方法得到效用函数收益差值:Δf(e|Si)=f(Si∪{e})-f(Si).其中,计算效用收益f(Si)的集合遍历开销与摘要规模|Si|成正比例关系,为了进一步减少该计算开销,本文提出一种使用效用向量替换累积摘要Si的信息压缩方法. Fig. 3 k-medoid select problem with utility vector.图3 效用向量在中心点选取问题中的应用 以图3的中心点选取问题为例,式(4)为该问题的次模效用函数.从图3(a)的12个数据点中选取3个中心点,使得各点到中心点的距离之和最小;初始化摘要集合为空;图3(b)首先选取到各点距离损失最小的点E添加至摘要S;图3(c)选取基于累积摘要S1的第2轮最大收益对象点L;第3轮中,累积摘要S2的效用收益为图3(d)中点E与点L到其余各点的最近距离(同样的,对规模为i的累积摘要Si,也需要遍历i个数据获取最优值作为效用收益). 次模最大化问题通常满足累积摘要在某一维度的收益单调增特性(如图3(c)实际是优化了摘要到点J,K的距离),因此,该类问题中摘要添加最高增益对象hi与直接优化摘要的某一维度的最优效用值是等价的.本文提出对具有以下特性的效用函数进行累积摘要集合Si的信息压缩,引入效用向量(utility vector)概念. Uk i=max{Uk i,gi({e})}, (9) 其中,Uk i表示第k层向量的第i维度效用值.效用向量Uk仅在新增摘要维持对象时完成更新,因此时间复杂度满足Ω(f({Uk}))=1k×Ω(f(Sk)),而效用向量的收益f({Uk})则满足f({Uk})=f(Sk). 综上,对于未压缩的累积摘要增益计算Δf(S),其开销为Ω(|S|×|f({hi})|×2).而通过效用向量的增益计算与更新开销为Ω(|f({Ui})|+|f({Ui})|×2),其中|f({Ui})|=|f({hi})|,|S|=k.因此相对于原算法,效用向量在时间复杂度上到达23×k倍的提升. 2.3.3可变的分层摘要维持对象数量 HSSM算法中每层的增益筛选过程仅保留单个摘要维持对象hi,故具有最低收益保证的优势.但考虑到某些场景中可能遇到需求摘要规模k过大,导致流水并行模式延迟过大(规模为v的数据摘要其时间开销为Ω(v+k))及层数过多导致存储空间增大等问题.本文提出分层模型中每层摘要维持数量是可变的(即Layerl可以保留li个摘要维持对象{hi 1,hi 2,….,hi l}).该方法将摘要S不规则地分配在i层中,使得层数是可控的,但会导致并行度降低,从而减慢摘要时间. 2.3.4HSSM+算法 改进的HSSM算法的实现如算法2所示. 算法2. HSSM+:改进的流次模最大化分层算法. 输入:数据集O、摘要规模k、过滤阈值σ; 输出:摘要结果S. h是摘要维持对象的集合; ② fori=1 tondo { ③e=Oi;*载入新数据* ④ forl=1 tokdo {*在每一层中筛选该数据* ⑤ if (Δf(e|Ul-1)<σ) ⑧ [e,hl,Ul]=Filter(e,hl,Ul-1);}} ⑨S∅;*初始化摘要结果* ⑩ forl=1 tokdo 根据第2.1节分析可知,HSSM+算法在不同层中数据增益对比具有可并行的特点,通过分布式处理框架实现不同分层的数据同时进行筛选,可达到提高摘要速率的目标.本节主要介绍HSSM+算法的分布式实现. 3.1分布式HSSM+算法 HSSM+算法构建流水并行模式(图1)使得某一时刻各层可同时进行数据增益对比Δf操作,进一步提出Spark-HSSM+算法.相对于单对象处理模式,分布式流数据框架需解决3个问题: 1) 对于实时到来的流数据,以单一对象作为分布式任务(Job)存在资源分配与任务调度(调度中心将任务分配给空闲的Worker并等待其返回运行结果)的时间开销问题. 2) 在建立分布式任务时,解决待处理数据与分层信息结合的问题. 3) 每轮摘要任务完成后,如何实现动态更新分层信息. 针对分布式系统中以单个对象(或少量数据)为数据处理单元(如Spark中的RDD)将导致频繁的启动任务,整个摘要过程的调度总开销甚至远大于摘要过程中效用收益的计算与对比的问题.分布式HSSM+算法将待处理数据按时间间隔t或数据量(最小数据规模阈值θ)进行分批处理,该方法确保每一次任务处理的数据量尽可能满足负载均衡与流数据处理的任务实时性. 为保证所有待处理数据O逐一被所有层过滤或保留.本文通过递增的方式给每批新数据添加批次号(i),同时建立一个有限大小的循环队列用于存储批数据 (图4步骤①):首先,将新数据存储于队列的指定单元(i%k);其次,Spark-HSSM+算法以时间片为单元,完成待处理批数据vi的摘要任务(即vi在对应层Layerl的增益筛选操作);最后,在下一时间片开始阶段,读入新数据vi+1并将(i+1)%k位置的原数据vi+1-k替代为该数据.该方法实现批数据vi-k在k个时间单位内被有规律的存储,并通过算法3实现批次号i与各批次数据vi及分层信息的映射. Fig. 4 Spark-HSSM+ algorithm in Spark.图4 Spark框架实现Spark-HSSM+算法 算法3.BatchMap:基于批次号i获取循环队列数据与分层信息的映射关系. 输入:当前批次号i、数据总批数b、摘要大小k; 输出:起始循环数据块索引f_start、起始层次号l_start、对应使用的数据块及层次数目length. ① 初始化:f_start=0,l_start=0,length=0; ② ifi>(k-2) &&i ③f_start=i%k,l_start=0,length=k; ④ else ifi<(k-1)*循环队列未满* ⑤f_start=i,l_start=0,length=i+1; ⑦f_start=(b-1)%k,l_start=i-b+1, length=k-i+b-1; ⑧ return [f_start,l_start,length]. 为达到分层次模最大化算法的最差解收益保证,要求每轮摘要任务结束时,各层的累积摘要(或效用向量U)更新为上层累积摘要与本层筛选的最高增益对象hi.通过分布式任务可完成批数据vi的最优增益对象hi的选取,然而该方法无法实现自顶向下的累积摘要(或效用向量)更新,本文通过对各分布式任务的结果进行集中汇总更新的方式解决该难题.由于分布式摘要结果是无序的,故更新前还需对摘要结果进行排序,以保证累积摘要是自顶向下添加实现分层次模最大化摘要. 3.2Spark平台实现Spark-HSSM+算法 Spark[21]是基于Hadoop[22]文件存储系统HDFS与MapReduce处理模式的分布式处理平台,使用共享内存的弹性分布式数据集(RDD)技术与DAG(有向无环图)任务结构改进了Hadoop框架在迭代任务开始与结束阶段因数据频繁进行磁盘读写操作产生开销的缺陷. Spark-HSSM+算法通过建立如图4所示的分布式处理流程,利用Spark的Streaming流数据处理框架的fileStream()方法将流数据通过时间间隔(例如,1 s)分批读入;并以循环队列的形式实现3.1节中替换存储数据至分布式内存(RDD)中. 步骤②向分布式内存申请k个单元存储待处理数据块(DataBlocki),步骤③读取图4中Hierarchy Streaming Summarization的分层摘信息,通过map()方法完成摘要维持对象hi,上层待处理数据ti及效用向量Ui-1的数据映射操作,最终形成具有关联批次号(batchid)的分布式待处理数据与分层信息. 图4中步骤④通过按批次号连接(Spark中Join()方法)各分布式任务数据(包括DataBlocki,hi,ti及Ui-1)组成分布式任务(Job). 由于分层增益对比满足数据间的独立性,将所有任务(JobAB…)通过Spark的reduceByKey()方法分布在若干个节点上并行完成,使得所有数据分别执行增益计算,并对batchid相同的数据(在同一节点上)进行两两增益对比,最终仅返回最高增益对象为该层新摘要维持对象i (如图4步骤⑤),若发生摘要维持对象的替换时,需返回原摘要维持对象ei+1,使其在下层摘要筛选过程中被访问. 步骤⑧通过实时访问分层模型合并各层摘要维持对象(h1,h2,…,hk),最终得到规模为k的摘要结果Sk. 算法4.Spark-HSSM+:Spark实现HSSM+算法. 输入:分批数据集O、数据总批数b、摘要规模k; 输出:摘要结果S. ②fori=1to(b+k-1)do{*处理所有数据获取该批次号映射的层次信息* ③ [f_start,l_start,length]=BatchMap(i, b,k); ④ifi ⑤ 将oi存入DataBlockf_start数据块; ⑦forc=0tolengthdo{*所有数据合并同层待处理数据与维持对象* ⑧ tmpBlcokj=DataBlockj∪{hl}∪{tl}; ⑨ 基于映射关系连接DataBlockj与Ul-1; 将本文算法与常见的次模最大化算法进行分析,分别通过访问数据集次数、最低(最差解)收益保证、时间复杂度及流数据更新的时间与空间开销方面作出对比,各算法主要性能如表1所示: Table 1 Comparison Between the Existing Submodular Maximization Methods表1 常见次模最大化算法性能对比 首先对比各算法的数据集访问次数.除标准贪心算法(Standard-Greedy)需进行k轮迭代访问外,其余算法均可满足流数据仅一次访问数据集的限制. 在最差解收益保证方面,Standard-Greedy拥有最高的收益保证;Stream-Greedy算法需多次访问数据集以维持其最差解下界,即仅访问一次数据集时,其最差解收益的下界为1k×f(S*),而在多次访问数据集的条件下,其上界也不大于12*最优解收益;Sieve-Streaming算法的最差解保证则与其离散度参数ε相关;本文提出的HSSM+算法在2.2小节中证明摘要至少达到1(2-1k)的最优解收益. 对比各算法处理规模为n的数据集,其时间复杂度量级都不低于Ω(n×k2×Δf).但本文通过2.3.2节中提出效用向量压缩方法使得计算每个数据对象增益的时间开销由Ω(k2×Δf)降为32×k×Δf. 证明. 证毕. 对于流数据(仅通过访问增量数据v更新摘要S)的摘要问题,GreeDi算法在处理已知数据规模的情况下(不符合一般流数据使用条件),可基于不同的数据规模划分提高摘要速率;分布式Sieve-Stream与Spark-HSSM+算法适用解决所有流数据摘要问题,且较其余非分布式算法具有约k倍的提高.其中,Spark-HSSM+算法因流水并行结构对实时的摘要结果产生k个时间单位的延迟,但摘要过程的处理时间仍为Ω(v). 在空间开销方面,GreeDi算法与Stream-Greedy算法仅保存规模为k的摘要结果与当前处理的批数据v即可;Sieve-Stream算法根据其离散参数ε的不同,共保存logkε个过滤器,并分别为这些过滤器保存待处理数据v;Spark-HSSM+算法将批数据v需保存k个时间单位故产生k倍于批数据大小的额外内存开销. 从上述理论分析中得出,本文提出的流数据分层次模最大化摘要算法Spark-HSSM+,应用流水并行结构完成其在Spark分布式平台的实现,通过效用向量U使得次模效用函数的计算开销减少为原本的3(2k),并以分布式任务的方式使得摘要速率比串行算法上具有k倍的提升,最终实现较贪心算法具有23×k2倍的速率优化. 本节分别在单机环境及分布式集群上完成基于覆盖率的摘要问题与基于距离损失函数的中心点选取问题的次模最大化算法对比实验: 随机采样(Random):对数据集O随机选取k个对象作为摘要. Standard-Greedy(Greedy):通过标准贪心算法[9]遍历k次数据集选取k个对象作为摘要结果. Stream-Greedy(SG):基于1.3.2节中描述的流贪心算法[11],维护规模为k个对象的结果作为摘要. GreeDi:通过1.3.3节中描述的算法[10],将数据集用分布式标准贪心算法进行m次分割进行摘要. Sieve-Streaming(SS):通过流数据过滤算法[12]选取指定的离散参数ε实现分布式过滤数据集并选取最优解作为输出. Spark-HSSM+算法通过Scala2.11.6开发完成.所有单机对比实验运行于具有8GB内存、双核2.4GHz处理器的PC机上,Java环境为JRE1.8.集群为基于Hadoopyarn2.2.0资源调度管理的Spark1.2.0分布式框架,包括15个拥有8GB内存及4核2.4GHz处理器的普通PC节点.而所有分布式算法的集群运行参数统一设置:driver-memory为6GB,executor-memory为6GB,num-executors为10个,executor-cores为4个.在本文的实验中,为保证所有摘要结果都能够达到1(2-1k)的最优解收益下限,因此每层的摘要维持对象数目均为1. Spark框架通过DAG的任务结构,使得所有数据在未执行前,不进行实际的数据分配,进而使得所有被访问的数据尽可能的存储在同一台机器上,减少不同机器间的任务开销. 摘要集合的效用收益随着摘要规模k的扩大而提高,本文通过增量k值的方法对数据集进行摘要收益对比,当效用函数值增长率低于γ(本文选取γ=10-5)时停止扩展摘要规模.算法的性能对比主要基于2个指标:1)指定规模的条件下,各算法的摘要效用收益;2)指定规模的条件下,各算法完成摘要的总时间.相较于其他流摘要算法,随机选取策略仅访问一遍数据集且无需计算效用收益,故其时间开销是忽略不计的.对于无法在流数据或大规模数据集上完成摘要的Standard-Greedy算法,本文通过一个较小的数据集实现所有算法与该算法的对比. 5.1非分布式环境下的性能对比 本文首先对包含50 000个涉及1 000维特征(即每个对象包含一个或多个特征)的合成数据集进行基于最大覆盖率(式(3))的摘要实验.该数据集规模较小,能够进行包括静态算法(Standard-Greedy)及非分布式算法在覆盖率与运行时间的对比.实验中Sieve-Streaming算法选取ε=0.1对最优解进行离散.图5、图6分别为各算法对该数据集在不同摘要规模k的效用收益(覆盖率)及运行时间对比. Fig. 5 The coverage of algorithms in different k.图5 不同规模下各算法覆盖率对比 Fig. 6 The running time of algorithms in different k.图6 不同规模下各算法完整摘要时间对比 从图5中可以看出,在规模不断增加的过程中,Stream-Greedy(SG),Standard-Greedy(Greedy),Sieve-Stream(SS)及HSSM算法的收益都有次模特性,摘要的收益基本保持单调增长特性,但Sieve-Stream由于规模改变导致每次选取的摘要可能不同,有可能出现规模增大摘要收益反而降低的现象.总体来说,Stream-Greedy算法与HSSM算法在覆盖率收益方面都更接近于标准贪心算法Standard-Greedy的收益,而Sieve-Stream算法虽优于随机采样方法(Random),但相比于其他算法仍有10个百分比左右的差距. 图6表明,对于同一数据集,摘要时间随规模k呈指数型增长.而Stream-Greedy(SG)算法在仅访问一遍数据集的情况下需依次计算新数据e的增益Δf(e|Sk{hi})与原摘要维持对象hi的增益Δf(hi|Sk{hi}),即二次访问累积摘要集合,故比标准贪心算法多近一倍的开销时间.同时,未优化的HSSM算法与标准贪心算法时间开销接近;而Sieve-Stream运行时间则主要受限于过滤器数目及过滤器中摘要数量,本实验中k=50时过滤器数目为27个,其时间开销约为标准贪心算法的16. 通过2.3节中引入最优效用向量及最低增益过滤(σ=5)改进后的HSSM+算法在覆盖率收益与时间开销如表2、表3所示.通过对比结果发现,仅当k较大(k=45与k=50)的情况下,HSSM+算法的收益较原算法略有降低,但仍与Stream-Greedy算法收益接近.而在算法的运行时间开销方面,对比k=50的摘要规模,HSSM+比未改进的HSSM算法提升了约39倍,比Stream-Greedy算法要高约60倍,对比不同的摘要规模,HSSM+算法也能较原算法达到接近于理论(23×k倍)的速率提升. Table2ComparisonofHSSM,HSSM+ &Stream-Greedy(SG)inCoverage 表2改进的HSSM算法(HSSM+)与朴素算法(HSSM)及流贪心算法(SG)的覆盖率对比% Algorithmk5101520253035404550SG61.2073.3777.0770.9881.0981.7482.3983.3783.8084.13HSSM59.8972.2876.3079.1380.6581.8582.5083.0483.5984.13HSSM+59.8972.2876.3079.1380.6581.8582.5083.0483.3783.59 Table 3 Comparison of HSSM, HSSM+ & Stream-Greedy(SG) in Running Time表3 改进的HSSM算法(HSSM+)与朴素算法(HSSM)及流贪心算法(SG)的运行时间对比 s 5.2基于距离损失函数的分布式中心点选取 通过对CensS1990数据集[23]采用基于距离损失式(5)的效用函数进行中心点选取实验,该数据集生成包含2 458 285个68维特征的|O|×|O|距离矩阵数据,非流算法对于该数据集的多次访问需数天时间才能得到选取结果,已不符合一般问题的解决时效条件.文献[10]中证明该问题的摘要方法是增量可分的(additivelydecomposable),故实验使用从原数据集中采样|W|=1100|O|进行流算法的对比实验.由于文件大小的限制,本实验将该数据集以500个对象为一批次进行分割,而该数据量过小使得Spark-HSSM+算法不能够达到分布式最高运行效率(分布式任务调度开销过大),但我们仍进行对比以证明优化后的Spark-HSSM+算法在分布式环境下运行效率得到提升.本实验设置过滤阈值μ=20,Sieve-Stream算法选取ε=0.1离散化最优解,分布式中共包含72个过滤器.GreeDi不适合处理流数据,故仅用其作增量式(每批数据保存贪心摘要结果用于下一批次比较)贪心算法对比. Fig. 7 The utility of different algorithms in k=50.图7 k=50时效用函数值对比 图7显示在规模k=50的情况下,GreeDi,Stream-Greedy与Spark-HSSM+算法的效用收益相差不大,而Sieve-Stream算法则遇到过滤器最优解估计不适的情况,其效用收益值甚至低于随机采样. 图8表明Sieve-Stream算法与Spark-HSSM+算法的运行速率要明显优于Stream-Greedy与GreeDi算法,因此更适合处理需要更高效响应的流数据,其中,Spark-HSSM+算法较Stream-Greedy算法仅提高了29倍,未达到理论值提升的主要原因是数据规模过小不适合分布式任务且包含任务调度与资源分配同时产生额外开销,故该算法在处理小批量数据时,优化效果不明显. Fig. 8 The running time of different algorithms in k=50.图8 k=50时各算法完整摘要时间对比 5.3分布式环境下基于覆盖率的数据摘要 由于5.2节中实验未体现大规模流数据摘要的特点(每批次数据量过少),因此,本节选取Yahoo!提供的28 041 015条用户首页访问日志数据集[24]以280 000条数据进行分批,同样以基于最大覆盖率的效用函数进行实验. Fig. 9 Comparison of utility & running time on Yahoo! dataset.图9 Yahoo!数据集的效用收益与运行时间对比 该数据集包含126维用于描述用户访问时的行为特征,根据文献[1]中提出的关联规则对其中最频繁的50维特征的频繁二项集进行最大覆盖率摘要实验.实验选取k=30,Spark-HSSM+算法选取过滤阈值上界μ=20,Sieve-Stream算法设置离散系数ε=0.01(该离散值使其效用收益更加接近于Spark-HSSM+算法).图9为随机采样、SS算法及Spark-HSSM+算法的摘要时间及其效用收益对比. 图9表明Spark-HSSM+算法在可接受响应时间内,较Sieve-Stream算法与随机选取得到更优的效用收益.同时其在运行速率方面也较Sieve-Stream算法有10倍左右的提升.除上述3个算法外,其余算法均无法在24h内给出响应结果,对于流摘要的代表算法Stream-Greedy,本文通过其完成1%的数据处理量耗时预估出其时间开销约为本文算法的500倍(理论值为23×k2=600倍,但应除去分布式任务的启动与资源调度的时间开销).故大规模流数据摘要算法Spark-HSSM+,在具有高效用收益的同时,其速率提升也是显著的. 本文提出了基于次模最大化的流数据分层摘要算法.该算法在分布式环境下仅一次访问数据集即可完成选取大小为k的摘要集合,其摘要的效用函数收益至少能达到1(2-1k)的最优解.实验表明Spark-HSSM+算法在处理大规模数据集时能够在达到近似于标准贪心算法收益(次模最大化问题中最好的解决方案)的同时,相比于其他算法在实时性上具有优势,其速率在理论较标准贪心算法提升约为23×k2倍.本文的贡献旨在对大规模数据及流数据集在次模最大化收益问题及运行效率方面得到改进. [1]XuJ,KalashnikovDV,MehrotraS.Efficientsummarizationframeworkformulti-attributeuncertaindata[C] //Procofthe33rdACMSIGMODIntConfonManagementofData.NewYork:ACM, 2014: 421-432 [2]WangZhenhua,ShouLidan,ChenKe,etal.Onsummarizationandtimelinegenerationforevolutionarytweetstreams[J].IEEETransonKnowledgeandDataEngineering, 2014, 27(5): 1301-1315 [3]SiposR,SwaminathanA,ShivaswamyP,etal.Temporalcorpussummarizationusingsubmodularwordcoverage[C] //Procofthe21stACMIntConfonInformationandKnowledgeManagement.NewYork:ACM, 2012: 754-763 [4]ShouL,WangZ,ChenK,etal.Sumblr:Continuoussummarizationofevolvingtweetstreams[C] //Procofthe36thIntACMSIGIRConfonResearchandDevelopmentinInformationRetrieval.NewYork:ACM, 2013: 533-542 [5]BarzilayR,MckeownKR.Sentencefusionformultidocumentnewssummarization[J].ComputationalLinguistics, 2005, 31(3): 297-328 [6]ShiL,OlaS.Approximatingk-medianviapseudo-approximation[C] //Procofthe45thAnnualACMSymponTheoryofComputing.NewYork:ACM, 2013: 901-910 [7]El-AriniK,VedaG,ShahafD,etal.Turningdownthenoiseintheblogosphere[C] //Procofthe15thACMSIGKDDIntConfonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2009: 289-298 [8]ChenHao,WangYitong.Threshold-basedheuristicalgorithmforinfluencemaximization[J].JournalofComputerResearchandDevelopment, 2012, 49(10): 2181-2188 (inChinese) (陈浩, 王轶彤. 基于阈值的社交网络影响力最大化算法[J]. 计算机研究与发展, 2012, 49(10): 2181-2188) [9]NemhauserGLWolseyLA,FisherML.Ananalysisofapproximationsformaximizingsubmodularsetfunctions—I[J].MathematicalProgramming, 1978, 14(1): 265-294 [10]MirzasoleimanB,KarbasiA,SarkarR,etal.Distributedsubmodularmaximization:Identifyingrepresentativeelementsinmassivedata[J].AdvancesInNeuralInformationProcessingSystems, 2013, 87(1): 382-384 [11]GomesR,KrauseA.Budgetednonparametriclearningfromdatastreams[C] //ProcoftheIntConfonMachineLearning.Haifa:ICML, 2010: 391-398 [12]BadanidiyuruA,MirzasoleimanB,KarbasiA,etal.Streamingsubmodularmaximization:Massivedatasummarizationonthefly[C] //Procofthe20thACMSIGKDDIntConfonKnowledgeDiscoveryandDataMining.NewYork:ACM, 2014: 671-680 [13]VeeE,SrivastavaU,ShanmugasundaramJ,etal.Efficientcomputationofdiversequeryresults[C]//Procofthe24thIEEEIntConfonDataEngineering.Piscataway,NJ:IEEE, 2008: 228-236 [14]MishraD,HiranwalS.Analysis&implementationofitembasedcollaborationfilteringusingK-Medoid[C] //Procof2014IntConfonAdvancesinEngineeringandTechnologyResearch(ICAETR).Piscataway,NJ:IEEE, 2014: 1-5 [15]CarvalhoF,MeloF,LechevallierY.Amulti-viewrelationalfuzzyc-medoidvectorsclusteringalgorithm[J].Neurocomputing, 2015, 163(c): 115-123 [16]MinouxM.Acceleratedgreedyalgorithmsformaximizingsubmodularsetfunctions[J].LectureNotesinControlandInformationSciences, 1978, (7): 234-243 [17]LiuYong,GaoHong,LiJianzhong.Top-Kgraphpatternsminingbasedonsomejointsignificancemeasure[J]. //ChineseJournalofComputers, 2010, 33(2): 215-230 (inChinese) (刘勇, 高宏, 李建中. 基于联合意义度量的Top-K图模式挖掘[J]. 计算机学报, 2010, 33(2): 215-230) [18]YanY,ZhangJ,HuangB,etal.Distributedoutlierdetectionusingcompressivesensing[C] //Procofthe2015ACMSIGMODIntConfonManagementofData.NewYork:ACM, 2015: 3-16 [19]KumarR,MoseleyB,VassilvitskiiS,etal.FastgreedyalgorithmsinMapReduceandstreaming[J].ACMTransonParallelComputing, 2015, 2(3): 14:1-14:22 [20]BeltrameG,BrandoleseC,FornaciariW,etal.Anassembly-levelexecution-timemodelforpipelinedarchitectures[C] //Procofthe2001IEEE//ACMIntConfonComputer-AidedDesign.Piscataway,NJ:IEEE, 2001: 195-200 [21]ZahariaM,ChowdhuryM,DasT,etal.Resilientdistributeddatasets:Afault-tolerantabstractionforin-memoryclustercomputing[C] //Procofthe9thUSENIXConfonNetworkedSystemsDesignandImplementation.Berkeley,CA:USENIXAssociation, 2012: 141-146 [22]Apache.Hadoop[OL]. [2009-03-06].http://hadoop.apache.org [23]ChristopherM,BoT,DavidH.Thelearning-curvesamplingmethodappliedtomodel-basedclustering[J].TheJournalofMachineLearningResearch, 2002, 2(3): 397-418 [24]LiLihong,ChuWei,LangfordJ,etal.Unbiasedofflineevaluationofcontextual-bandit-basednewsarticlerecommendationalgorithms[C] //Procofthe4thACMIntConfonWebSearchandDataMining(WSDM’11).NewYork:ACM, 2011: 297-306 ZhangFenxiang,bornin1989.MastercandidateintheFacultyofElectricalEngineeringandComputerScience,NingboUniversity.Hismainresearchinterestsincludestreamdataprocessingandcloudcomputing. ChenHuahui,bornin1964.PhD,professor.MemberofChinaComputerFederation.Hismainresearchinterestsareintheareasofdatastreamsandmassivedataprocessing(chenhuahui@nbu.edu.cn). QianJiangbo,bornin1974.PhD,professor.MemberofChinaComputerFederation.Hismainresearchinterestsincludedatabasemanagement,streamingdataprocessing,multidimensionalindexing,andqueryoptimization(qianjb@163.com). DongYihong,bornin1969.PhD,professorandmasterinstructorintheFacultyofElectricalEngineeringandComputerScience,NingboUniversity.Hismainresearchinterestsincludebigdata,dataminingandartificialintelligence(dongyihong@nbu.edu.cn). HSSM: A Hierarchical Method for Streaming Submodular Maximization Zhang Fenxiang, Chen Huahui, Qian Jiangbo, and Dong Yihong (FacultyofElectricalEngineeringandComputerScience,NingboUniversity,Ningbo,Zhejiang315211) How to extractkelements from a large data stream according to some utility functions can be reduced to maximizing a submodular set function. The traditional algorithms had already given some good solutions of summarizing a static data set by submodular method, well-known as standard greedy algorithm. Lastly researches also presented some new algorithms with corresponding distributed solutions to meet the streaming data access and the real-time response limits, but those algorithms are not good enough in maximizing the utility gain. In this paper, we propose a new algorithm called HSSM which runs as a pipelining distributed framework and requires only a single-pass access the data set. Finally, the utility gain of our solution is close to the option standard greedy solution. We also propose using utility vector to compress the set of summarization and filtering out the low gain objects to improve the original HSSM algorithm. Fortunately, this approach can get applications in many related fields such as representative articles selection,k-medoid select problem and so on. Experimental results show that the improved Spark-HSSM+ method can increase the summarization speed in direct proportion tok2in contrast to the traditional method. Compared with other distributed algorithms, the result of the Spark-HSSM+ method is the most close to the standard greedy solution. streaming submodular maximization; hierarchy model; pipelining parallelism; data summarization; Spark distribution platform 2016-03-11; 2016-05-31 国家自然科学基金项目(61572266,61472194) TP391 This work was supported by the National Natural Science Foundation of China (61572266,61472194).2 流数据分层次模最大化算法
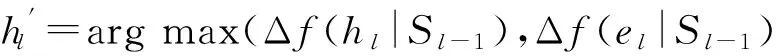
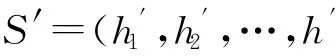
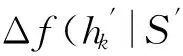
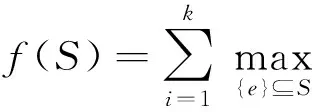
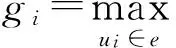
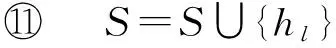

3 分布式分层次模最大化算法及实现
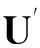





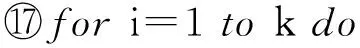


4 次模最大化相关算法的性能对比

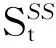
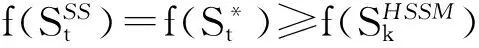
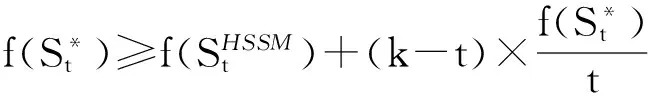
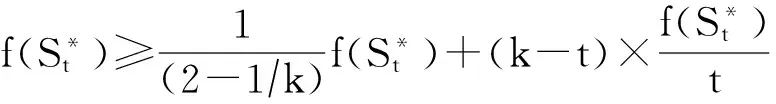
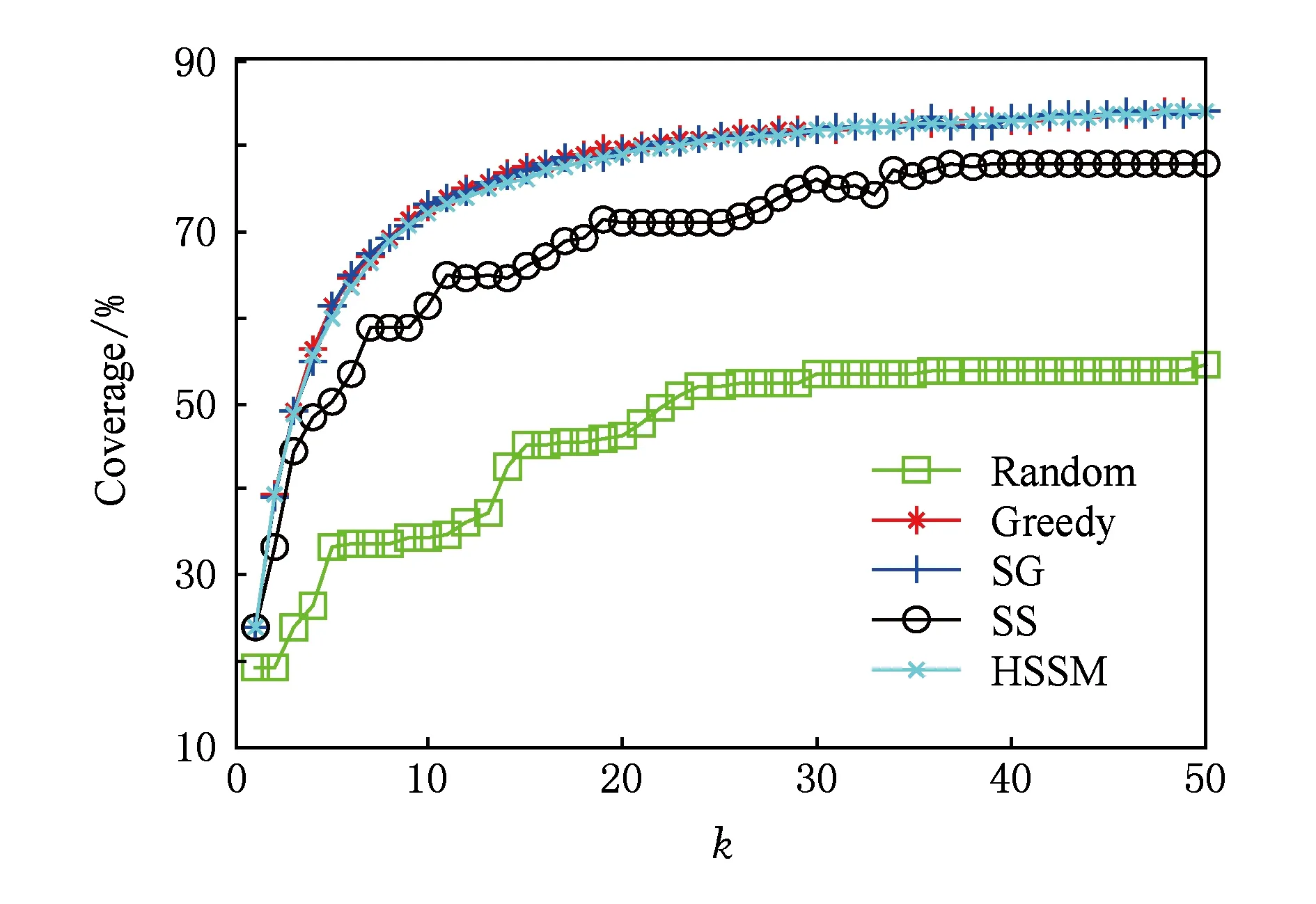
5 实验结果与分析



6 结 论



 猜你喜欢
当代陕西(2021年1期)2021-02-01 07:18:12农村财务会计(2020年9期)2020-09-21 10:25:56考试与评价·高二版(2020年3期)2020-09-10 13:04:38少儿美术(2019年7期)2019-12-14 08:06:22华人时刊(2019年15期)2019-11-26 00:55:44会计之友(2018年4期)2018-02-02 22:05:21金融经济(2017年14期)2017-12-23 14:52:09中国塑料(2016年9期)2016-06-13 03:18:48中国卫生(2015年8期)2015-11-12 13:15:34现代农业(2015年5期)2015-02-28 18:40:44
猜你喜欢
当代陕西(2021年1期)2021-02-01 07:18:12农村财务会计(2020年9期)2020-09-21 10:25:56考试与评价·高二版(2020年3期)2020-09-10 13:04:38少儿美术(2019年7期)2019-12-14 08:06:22华人时刊(2019年15期)2019-11-26 00:55:44会计之友(2018年4期)2018-02-02 22:05:21金融经济(2017年14期)2017-12-23 14:52:09中国塑料(2016年9期)2016-06-13 03:18:48中国卫生(2015年8期)2015-11-12 13:15:34现代农业(2015年5期)2015-02-28 18:40:44
