
基于Petri网的模型偏差域识别与模型修正
2016-08-31 03:49:38杜玉越孙亚男
计算机研究与发展 2016年8期
杜玉越 孙亚男 刘 伟
(山东科技大学山东省智慧矿山信息技术重点省级实验室 山东青岛 266590)
基于Petri网的模型偏差域识别与模型修正
杜玉越孙亚男刘伟
(山东科技大学山东省智慧矿山信息技术重点省级实验室山东青岛266590)
(yydu001@163.com)
过程挖掘技术能够通过事件日志建立过程模型,一致性检测技术能够发现过程模型和观察行为间的偏差.然而,现有的过程挖掘技术着重于发现偏差,不易于修正偏差.因此,利用一致性检测技术和工作流网模型的动态特性,提出一种基于Petri网的模型偏差域识别方法和模型修正技术(静态模型修正和动态模型修正).通过跟踪token流向,有效地识别模型偏差域,并对其进行修正,特别是能够正确修正具有循环结构、选择结构的复杂实际流程.最后,通过与其他方法的对比实验和分析,验证了本文方法的有效性和正确性.
一致性检测;模型修正;偏差域;工作流网;token
随着传统生产流程理论、业务流程再造理论、工作流技术和管理技术的发展,业务过程管理在各企业和组织中都得到了相应的应用.但是,随着企业和组织业务的增长、企业和组织之间合作程度的加强以及企业外部环境的变化,企业已有业务过程难以与企业和组织的发展相适应.因此,增强企业业务过程以提高企业和组织的竞争能力势在必行.
过程挖掘通过从现代信息系统普遍可见的事件日志中提取知识,发现、监测和改进实际过程.过程挖掘主要包括3个部分:过程发现[1-6]、一致性检测[7-8]和过程增强.
过程发现是从事件日志出发,构造出可以描述事件日志的模型.一致性检测是指对发现的过程模型与事件日志比较,即将每条迹在模型中进行“重演”,分析模型行为与日志行为的一致性程度,是评价模型质量的重要标准.现有的一致性检测方法有令牌重演、足迹对比、校准等.一致性检测的目的是进行过程改善.有的研究以偏差检测为基础,对过程模型进行修正或扩展,如根据观察到的行为与模型行为之间的偏差,提出常见的偏差模式,并给出能够识别每一种偏差模式的Petri网片断,或通过子过程扩展模型,使之和观察到的行为有较高的拟合度.有的研究对不合理过程模型进行纠错,从结构距离[9]、行为距离[10]和方案弊端[11]3个维度考虑,用模拟退火算法使之最小化,进而达到修正模型的目的.
现有模型偏差识别方法不能很好地识别存在偏差的模型区域,例如,利用校准识别偏差只能模糊地判断可能存在偏差的区域,不能准确识别出每一个存在偏差的区域,所以修正结果也不理想.为使现有工作流网模型符合实际流程,根据实际流程产生的日志对工作流网模型修正.修正的前提是发现模型与实际流程间的偏差,对偏差区域修正.产生偏差最根本的原因是应该发生的活动没有在模型中触发,或者不应该发生的活动却在模型中触发了.在工作流网模型中,触发模型变迁的因素是token,故token是一个网系统动态特性的直观体现.因此,本文研究如何准确识别偏差和简单有效地修正模型,基于工作流网中token的动态性,在一致性检测(重演)的基础上,提出一种基于token的模型偏差域识别方法和基于token的模型修正技术,提高了修正结果的拟合度和简洁度.
1 有关概念
本节简要介绍Petri网[12-16]、工作流网[17-19]、合理性[20]等的基本定义及有关符号表示.Petri网可用于分布式并发系统的建模与分析,并能够直观地将流程运行展现出来.它既能描述系统的结构又能模拟系统的运行.+表示一个正整数集合.
定义1. 多重集.S是一个集合,集合S上的多重集D是一个映射D:S→+.B(S)表示集合S上的所有多重集的集合.
例如,D=[a3,b,c2]是集合S上的一个多重集,其中a,b,c∈S,D(a)=3,D(b)=1,D(c)=2.
[1],σ
[2],…,σ[n]是一个序列,表示尖括号内元素的列表.A是一个集合,A*表示A上有限序列的集合.
|σ|=n表示σ的长度.对于∀a∈A,σ(a)代表σ中a元素的个数,例如,σ(a)=|{σ[i]=a,1≤i≤|σ|}|.
定义3. 迹、事件日志. 设A是所有活动的集合,A⊆A.若活动序列σ∈A*,则称σ是一条迹.若∃L∈B(A*)是迹的一个多重集,称L为一个事件日志.用&(σ)表示由迹σ中所有活动构成的集合.
例如,活动集合A={a,b,c,d},σ=b,c,a,d即为一条迹,&(σ)={b,c,a,d}.
定义4. 前集、后集. 设N=(P,T;F)为一个网.其中,P为有限库所的集合,T为有限变迁的集合,F是网N的流关系集合.对于x∈P∪T,记
•x={y|y∈P∪T∧(y,x)∈F},
x•={y|y∈P∪T∧(x,y)∈F},
称•x为x的前集或输入集,x•为x的后集或输出集,称•x∪x•为元素x的外延.
定义5. Petri网. 四元组Σ=(P,T;F,M)称为一个Petri网,当且仅当
1)N=(P,T;F)为一个网;
2)M:P→+,M称为网N的一个标识;
3) 变迁发生规则:
① 对变迁t∈T,如果∀p∈•t:M(p)≥1,则称变迁t在标识M下使能,记为M[t>.
② 若M[t>,则在标识M下,变迁t可以发生,从标识M引发变迁t得到一个新的标识M′,记为M[t>M′,且对∀p∈P,有:
从M可达的一切标识的集合记为R(M),约定M∈R(M).
下面给出工作流网(workflow net)的概念.
定义6. 工作流网.Petri网Σ=(P,T;F,M)称为一个工作流网,当且仅当
1) 存在一个开始库所i∈P,并且•i=∅;
2) 存在一个结束库所o∈P,并且o•=∅;
3) 对于∀x∈P∪T,x均位于从i到o的一条路径上.
工作流网也记作WFN=(P,T;F,M,i,o).
在Petri网中,token可用来表示任务的前置和后置条件.因此,本文使用token代表工作流过程中的资源.
定义7. 子网. 网N=(P,T;F),如果
1)P′∈P,T′∈T;
2)F′=((P′×T′)∪(T′×P′))∩F;
则称N′=(P′,T′;F′)为网N的一个子网.
定义8. 死变迁.Σ=(P,T;F,M)是一个Petri网,t∈T,M0为初始标识,若∀M∈R(M0):M[t>,则称变迁t为死变迁.
定义9. 合理性(Soundness).WFN=(P,T;F,M,i,o)是一个工作流网,i为开始库所,o为结束库所.WFN是合理的当且仅当
1) 对从i可达的任意标识M,存在变迁序列可到达终止标识;
2) 开始状态可达终止状态,终止标识是满足o中至少包含一个token的标识;
3) 不存在死变迁.
2 模型偏差域识别
现实中流程不是既定不变的,流程往往会随着实际情况的改变而变化,以便更好地适应不断改变的环境.因此,需要根据实际流程产生的日志,对原有模型进行监测,判断原有模型是否存在与实际流程不相符之处,如果存在,就要进行模型修正.本节提出一种模型偏差域识别方法,基于强制重演技术确定模型中存在偏差的区域.下面先介绍强制重演.
2.1强制重演
在工作流网中,利用token描述系统的行为,能够有效实时地反映系统的动态变化,而且通过事件日志重演,能够发现模型存在的偏差.
事件日志的重演[12-13]是指以一个事件日志和一个过程模型作为输入,事件日志在过程模型上重新被执行一遍,记为Replay(Model,L).若迹与模型完全拟合,意味着迹会完全按照模型执行动作序列发生;若迹与模型不完全拟合,则当重演至迹与模型不符的动作时,将停止重演.然而,有些迹可能只有部分动作与模型不符,重演停止后无法再对后面的迹进行分析.为了使重演不终止,利用token的变化找到重演停止的原因,继而发现模型与日志不相符的区域,下面提出强制重演的定义.
定义10. 强制重演. 事件日志在工作流网上重演时,若迹与事件日志不完全拟合,则跳过模型上与事件日志不匹配或不存在的变迁继续重演.这种重演称为事件日志的强制重演,记为Force_Replay(WFN,L),其中WFN为工作流网,L为事件日志.
定义11. 日志活动与模型变迁的映射. 对于∀σ∈L,若活动a∈&(σ),并且在模型中存在变迁t与活动a对应,则称Map(a,t)是一个日志活动与模型变迁的映射.
由于强制重演的引入,必须改变工作流网的引发规则,才能实施强制重演.
定义12. 强制重演中WFN引发规则. 在强制重演Force_Replay(WFN,L)中,规定开始环境给开始库所一个token,其余库所token数为0,强制重演结束后,环境再消耗结束库所里的一个token.工作流网WFN=(P,T;F,M,i,o)变迁引发规则:
1) 迹σ对应变迁发生序列σt=t1,t2,…,tn,变迁t1在初始标识下引发,其余变迁t∈{t2,t3,…,tn}均可在前一变迁引发后得到的标识M下使能,即M[t>.
2) 若M[t>,从标识M引发变迁t得到一个新的标识M′(记为M[t>M′),对∀p∈P,
强制重演在模型中按照迹对应的变迁发生序列强制依次引发变迁,使得工作流网中变迁的使能引发规则改变.强制重演记录变迁引发后,相应库所p可能缺失token(M(p)<0)或者剩余token(M(p)>0),token的变化反映了强制重演中变迁的引发过程.强制重演结束后,若M(p)<0,表示强制重演过程中库所p缺失token,且一定有变迁在不满足通常使能条件下执行;若M(p)>0,表示强制重演过程中库所p有剩余的token,且一定有变迁在通常使能条件下没有被执行.因此,通过结束标识中token数量,能够清楚地判定找到现有模型与实际流程存在偏差的区域.下面给出强制重演算法.
算法1. 强制重演算法.
输入:工作流网WFN=(P,T;F,M,i,o)、事件日志L∈B(σ*);
输出:标识M.
Step1.TL←∅;*TL为日志活动对应模型变迁集,初始化TL*
Step2.M(i)=1,M(P-{i})=0;*初始状态环境给开始库所一个token,其余库所token数量为0*
Step3. FOR EACHσ∈LDO*对日志中的每条迹进行以下操作*
Step3.1. FOR (aj∈σ;j=1;j++) DO*对迹中的每个活动依次进行以下操作*
Step3.1.1.Map(aj,tj);*将活动映射为模型中的变迁*
Step3.1.2.TL←TL∪{tj};*更新集合TL*
Step3.2. FOR (tj∈TL,j=1;j++) DO*对集合TL中的元素依次进行以下操作*
Step3.2.1. FOR EACHp∈PDO
Step3.2.1.1. IFp∈•t∈t•THENM(p)←M(p)-1;
Step3.2.1.2. IFp∈t•-•tTHENM(p)←M(p)+1;
Step3.2.1.3. ELSEM(p)←M(p);
Step3.3.M(o)←M(o)-1;*最终环境消耗结束库所中的一个token*
Step4. RETURNM.*返回结束标识*
2.2模型偏差域识别方法
实际流程发生变化,要么变换活动的先后顺序,要么原有的活动代价太高不去执行,要么添加一个新的活动增加流程效率.因此,本文针对日志原有的活动顺序改变或者有部分活动未被执行的情况展开模型偏差域识别方法进行介绍.
将token理解为系统消耗资源(系统资源分为消耗资源和非消耗资源,如工具等),迹的重演可以理解为一种消耗资源使用行为.在一个正确有效的工作流网系统,消耗资源使用行为发生以后,系统中的消耗资源应该完全被消耗掉,不应该有剩余(剩余代表消耗资源浪费),也不应该有缺失(消耗资源缺失代表前期工作准备不足).所以,迹在一个正确的工作流网上重演后,各个库所中token数量应为0.不存在未使能却引发的变迁,也不存在使能却未引发的变迁.而当重演后,某些库所中重演数量不为0时,那么该工作流网系统必定存在与实际流程不相符的区域.
定义13. 模型偏差域. 设WFN=(P,T;F,M,i,o)是一个工作流网,WFN′=(P′,T′;F′,M′,i,o)是挖掘事件日志L得到的工作流网,若F中存在与F′中元素不匹配的元素(p,t)或(t,p),记为不匹配流关系,模型偏差域是由不匹配流关系组成的最小子网,用2端库所表示,记为(pn,pm).
根据定义13,模型偏差域是指原有模型与实际流程相比存在偏差的区域.利用提出的强制重演,得到结束标识M,根据M所记录的token数量判定模型偏差域.剩余token的库所与缺失token的库所之间存在与实际流程不相符的行为.为了方便模型修正,在判定模型偏差域时,应当遵循偏差域越集中约好,模型偏差域越小越好.
符号#(A)表示集合A中元素的个数.Mend为结束标识.
定理1. 设WFN=(P,T;F,M,i,o)是一个工作流网,L是事件日志,对于σ∈L,∀a∈σ,若∃Map(a,t),则∑#(•t)=∑#(t•)当且仅当强制重演结束后,对∀p∈P,∑Mend(p)=0.
证明. 充分性.根据强制重演算法,开始环境会产生1个token到开始库所,最终环境还要从结束库所中消耗1个token,两者相互抵消.∑#(•t)是所有变迁前集元素的数量,变迁引发需要消耗前集的token,∑#(•t)也就代表所有变迁消耗token的数量.∑#(t•)是所有变迁后集元素的数量,同样变迁引发会向后集中产生token,∑#(•t)也就代表所有变迁产生token的数量.因为,∑#(•t)=∑#(t•),变迁引发消耗的token和产生的token又相互抵消,即∑Mend(p)=0.
必要性.由于∑M(p)=0,可得没有变迁引发token为0,或者引发变迁消耗token的数量等于产生token的数量.所以,∑#(•t)=∑#(t•).
证毕.
在模型偏差域识别过程中,定理1验证模型偏差域2端库所的个数.例如,结束标识和为0,则所有的模型偏差域2端库所个数相等,如果不为0,则存在2端库所个数不相等的偏差域.
定理2. 迹是完全拟合的当且仅当强制重演结束后,对∀p∈P,Mend(p)=0.
证明. 充分性.因为迹是拟合的,所以所有变迁都是满足使能的条件下触发,因此不存在缺失token的库所,也不存在使能却不触发的变迁,因此也不存在含有token的库所,所以强制重演结束后,对∀p∈P,Mend(p)=0.
必要性.强制重演结束后,对∀p∈P,Mend(p)=0,所以既没有缺失token也没有剩余token,因此迹是完全拟合的.
证毕.
定理2用来判定重演迹的拟合性,从而判定工作流网模型是否存在偏差,同时验证偏差域的准确性.例如,结束标识中若存在库所中的token不为0,则表示该工作流网模型存在偏差.
下面给出基于token的模型偏差域的识别算法.
算法2. 基于token的模型偏差域识别算法.
输入:工作流网WFN=(P,T;F,M,i,o)、事件日志L∈B(σ*);
输出:模型偏差域(pn,pm).
Step1. 调用算法1强制重演算法;
Step2. IF(M(p)<0) RETURNt;*强制重演中,M(p)←M(p)-1后就开始判断,判断前不进行强制重演的后续行为*
Step3.pm←•t;
Step4.pn←顺着流关系向前寻找含有token的库所(规定开始库所的前一个库所是结束库所);
Step5. IF(pn不存在) THEN*如果沿着流关系没有找到含有token的库所,就返回上一次出现负数token的标识M,重新执行t*
Step5.1.M←上一次出现负数token的标识M;
Step5.2. RETURN上一次出现负数token的模型偏差域(A,B);
Step5.3.pn←A;
Step5.4.pm←B∩pm;
Step5.5. RETURN(pn,pm);
Step5.6.M(pm)←M(pm)+1;
Step5.7.M(pn)←M(pn)-1;*更新M的值,继续强制重演的后续行为*
Step6. ELSE RETURN(pn,pm);
Step7.M(pm)←M(pm)+1;
Step8.M(pn)←M(pn)-1.*更新M的值,继续强制重演的后续行为*
算法2调用算法1,出现含有负数token的库所时,以该库所为起点沿着流关系向前寻找含有token的库所,是为了在后续的修复工作中尽量使用简单结构修正模型,向前寻找含有token的库所能保证优先发现顺序结构等简单结构修正模型.如果寻找到开始库所还是没发现含有token的库所,则按照规定开始库所的前一个库所是结束库所,继续寻找含有token的库所.
例1. 工作流网模型WFN1如图1所示,日志L={a,c,c,e,d}.在WFN1上,对σ=a,c,c,e,d进行模型偏差域识别.表1给出了强制重演时库所token变化情况.
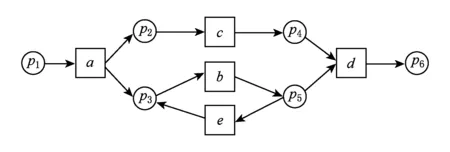
Fig. 1 Workflow net model WFN1.图1 工作流网模型WFN1
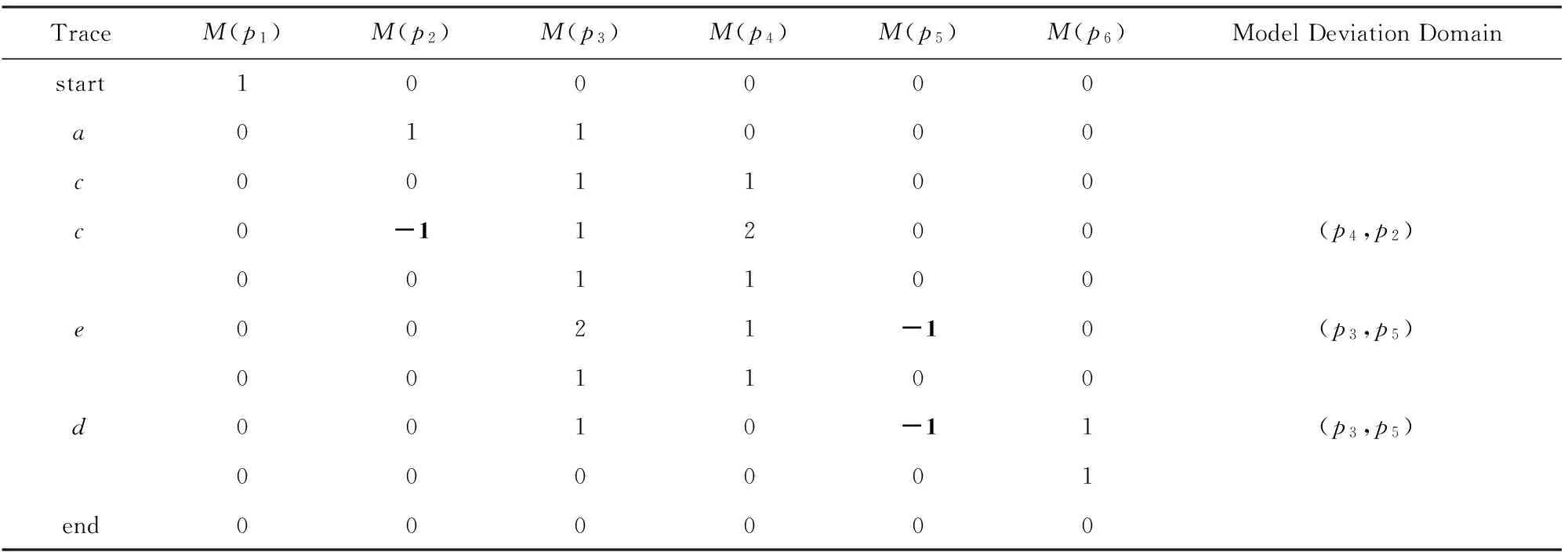
TraceM(p1)M(p2)M(p3)M(p4)M(p5)M(p6)ModelDeviationDomainstart100000a011000c001100c0-11200(p4,p2)001100e0021-10(p3,p5)001100d0010-11(p3,p5)000001end000000
由表1,初始状态环境为开始库所p1产生1个token,其余库所里的token数量为0,M[1,0,0,0,0,0].重演σ=a,c,c,e,d,首先触发变迁a,p1∈•a-a•,M(p1)=M(p1)-1;p2∈a•-•a,p3∈a•-•a,M(p2)=M(p2)+1,M(p3)=M(p3)+1;其余库所token不变,更新M[0,1,1,0,0,0].然后触发c,p2∈•c-c•,M(p2)=M(p2)-1;p4∈c•-•c,M(p4)=M(p4)+1;其余库所token不变,更新M[0,0,1,1,0,0].触发c,p2∈•c-c•,M(p2)=M(p2)-1<0,因为M(p4)=1>0,所以偏差域(p4,p2),更新M(p2)=M(p2)+1=0,M(p4)=M(p4)-1=0,由于只执行了触发c时前集库所里的token数量减1,继续执行后集库所里token数量加1,p4∈c•-•c,M(p4)=M(p4)+1=1,M[0,0,1,1,0,0].触发e,p5∈•e-e•,M(p5)=M(p5)-1<0,因为M(p3)=1>0,所以偏差域(p3,p5),更新M(p5)=M(p5)+1=0,M(p3)=M(p3)-1=0,由于只执行了触发e时前集库所里的token数量减1,继续执行后集库所里的token数量加1,p3∈e•-•e,M(p3)=M(p3)+1=1,M[0,0,1,1,0,0].触发d,p4∈•d-d•,M(p4)=M(p4)-1,p5∈•d-d•,M(p5)=M(p5)-1<0,因为M(p3)=1>0,所以偏差域(p3,p5),更新M(p5)=M(p5)+1=0,M(p3)=M(p3)-1=0,由于只执行了触发d时前集库所里的token数量减1,继续执行后集库所的token数量加1,p6∈d•-•d,M(p6)=M(p6)+1=1,M[0,0,0,0,0,1].根据算法最终结束库所标识M(o)-1,得到结束标识M[0,0,0,0,0,0].偏差域识别后,根据定理2迹与模型是拟合的,因此识别的偏差域是正确的.
模型偏差域的发现是为了模型修正.例1的模型偏差域为(p4,p2)和(p3,p5).库所p2缺失一个token,库所p4剩余1个token,也就是说变迁c在没有使能的情况下被强制执行了.所以,模型中(p4,p2)区域存在偏差,区域(p4,p2)为一个偏差域.区域(p3,p5)被发现2次,一次是由于e未使能却强制执行,另一次是由于b使能但未执行,所以模型中(p3,p5)区域存在偏差,区域(p3,p5)为一个偏差域.最终得到偏差域为(p4,p2)和(p3,p5),如图2所示:
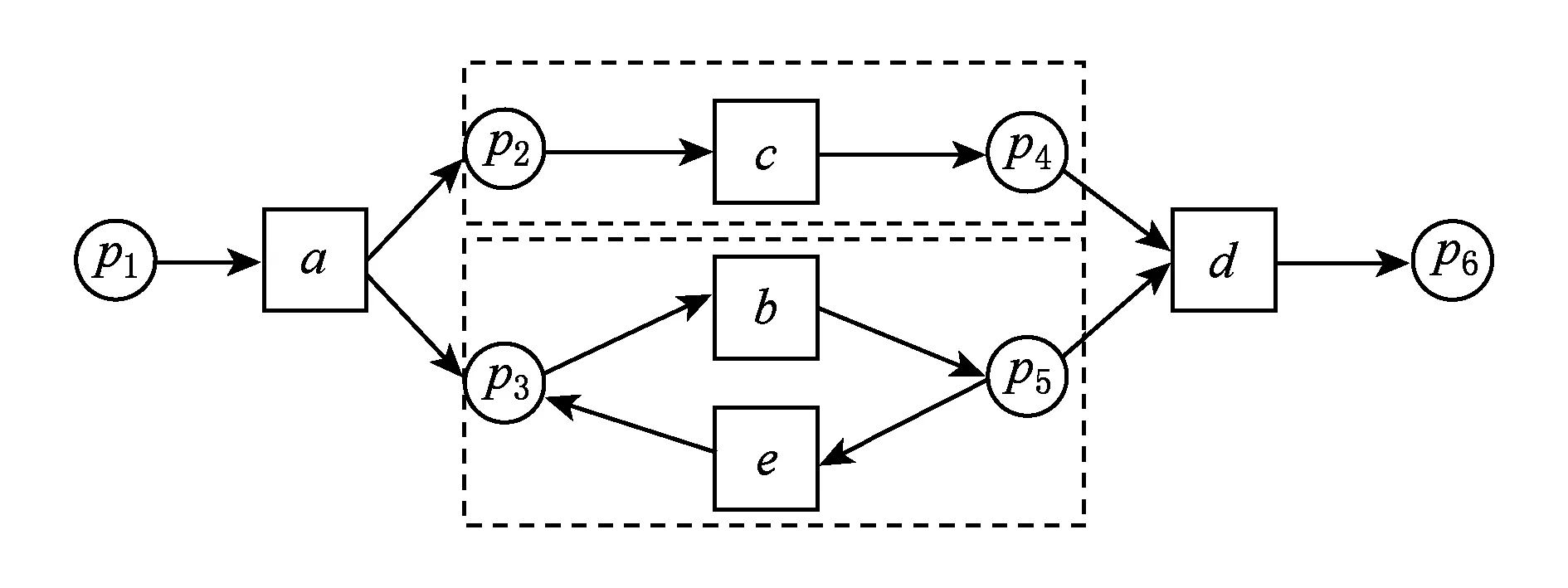
Fig. 2 Deviation domains of WFN1.图2 WFN1偏差区域
下面给出一个更复杂的模型偏差域识别示例.
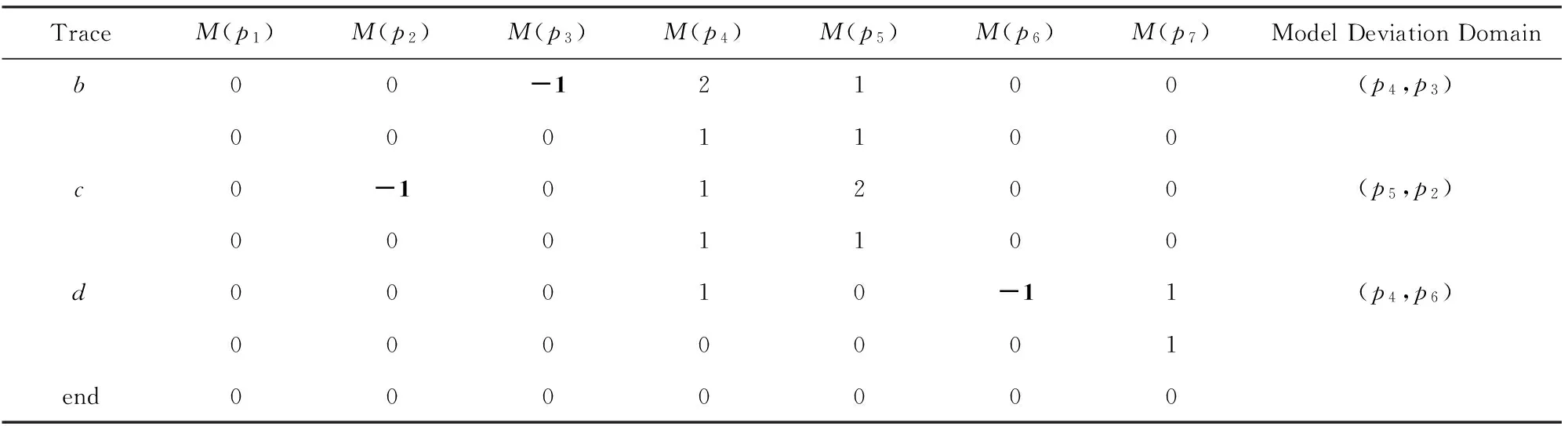
例2. 工作流网模型WFN2如图3所示,日志L={a,b,c,d,b,c,b,c,d}.根据算法2,库所token变化如表2所示.
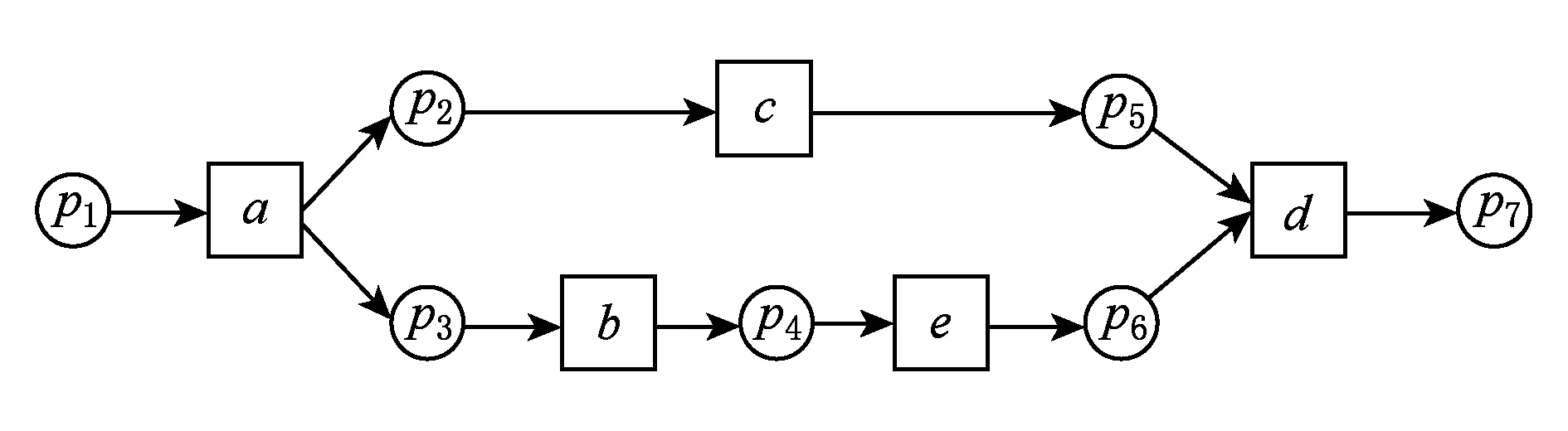
Fig. 3 Workflow net model WFN2.图3 工作流网模型WFN2
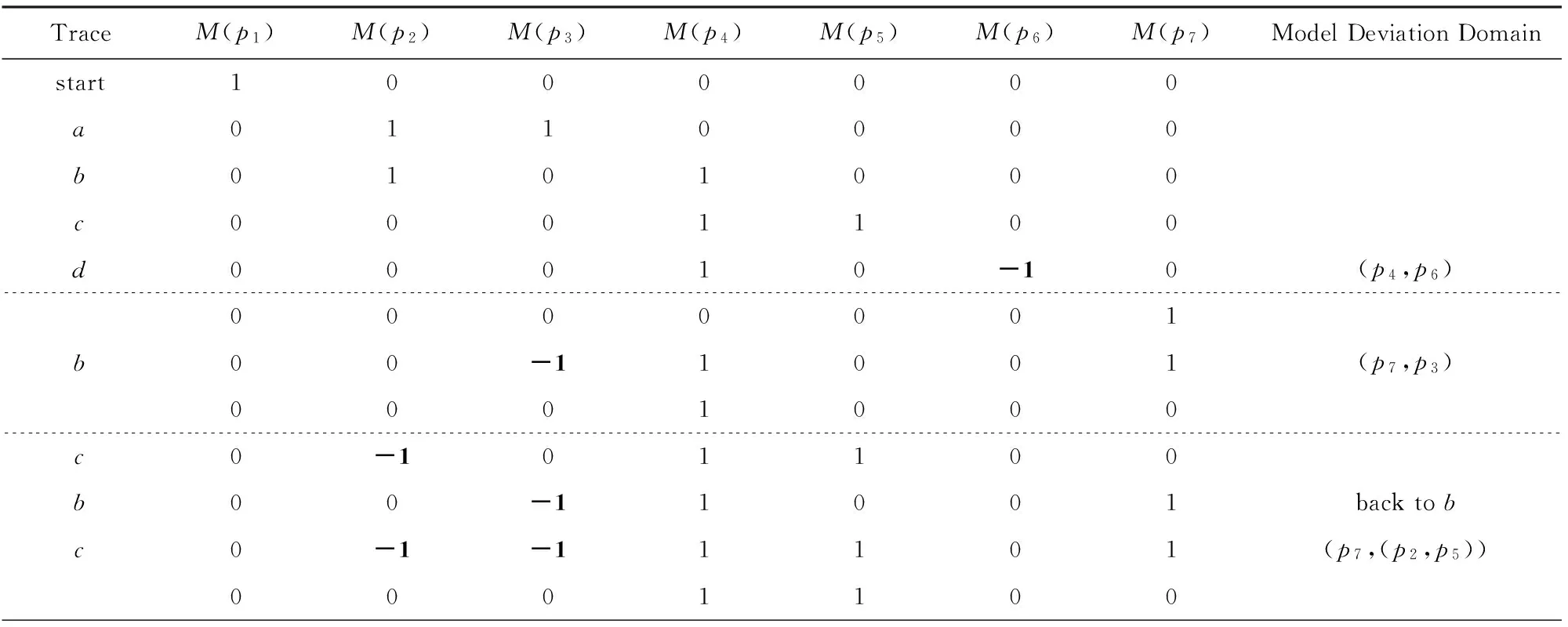
TraceM(p1)M(p2)M(p3)M(p4)M(p5)M(p6)M(p7)ModelDeviationDomainstart1000000a0110000b0101000c0001100d00010-10(p4,p6)0000001b00-11001(p7,p3)0001000c0-101100b00-11001backtobc0-1-11101(p7,(p2,p5))0001100
Continued (Table 2)
表2中token的变化原理同表1,这里不再赘述,不同的地方是虚线框里的部分,由于第2次触发c时,库所p2中token为负数,而触发变迁c之前,其后集库所p5也没有token,所以沿着流关系向前寻找含有token的库所.p1,p7,p5中都没有token,返回上一次出现负数token的操作,也就是触发b后的标识[0,0,-1,1,0,0,1].此时,重新触发c,库所p2,p3中token数均为负数.把(p2,p3)看成一个整体,而p5和p4中没有同时含有token,所以沿着流关系向前寻找含有token的库所,p7中含有token,且偏差域为(p7,(p2,p3)).最后,得到模型的偏差域为(p4,p6),(p7,(p2,p3)),(p4,p3),(p5,p2),(p4,p6).根据定理1,由于强制重演结束标识和不为0,所以存在2端库所数量不相等的偏差域.根据定理2,识别的偏差域是正确的.模型WFN2偏差区域如图4所示:
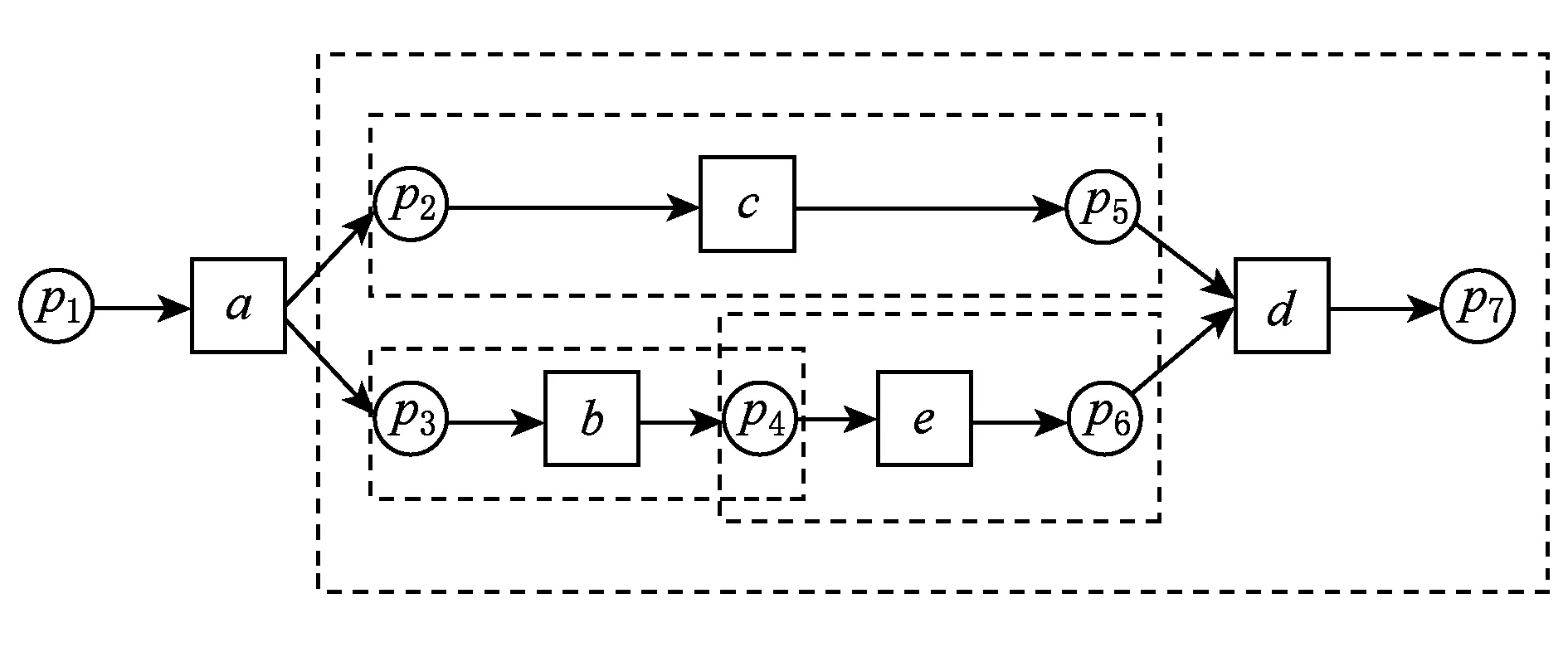
Fig. 4 Deviation domains of e.g.2.图4 例2偏差区域
3 基于token的模型修正
修正与实际流程相差不大的模型有很重要的意义,小规模的修正比重新挖掘要简单方便省时,而且有利于企业更好地管理业务流程.本文所涉及的模型修正有3种:单个分支上的活动循环(新日志中增加了部分旧活动的执行次数)、部分活动跳过(新日志中没有执行某些活动)和复杂结构体循环(新日志中增加了循环执行的多个活动).对于其他情况,例如增加了大规模的新活动、原有活动执行顺序大部分改变等,其修正的代价要比重新挖掘的代价大得多,一般没有修正的意义了.强制重演时环境给予工作流网模型1个token,新日志在修正后的模型上重演,最后环境再消耗1个token,此时的工作流网模型理应不含token.本节基于工作流网中token的缺失与剩余,给出一种模型修正的方法,利用不可见变迁改变token的流向,达到修正模型的目的.
3.1静态模型修正
第2节已经介绍了模型偏差域的识别方法,找到原始模型与实际流程的偏差区域,下一步就要对原始模型修正,使之更加接近实际流程.
模型偏差域识别算法中已经确定了偏差区域,静态模型修正就是将偏差域2端库所,用不可见变迁连接起来,流关系是从偏差域2端中含有token的库所到缺少token的库所.
下面给出静态模型修正的算法,τ表示不可见变迁.
算法3. 静态模型修正算法.
输入:工作流网WFN=(P,T;F,M,i,o)、事件日志L∈B(σ*);
输出:修正后的工作流网WFN′=(P′,T′;F′,M,i,o).
Step1. 调用算法2得到模型的所有偏差域(pn,pm);
Step2.T′←T∪τ;
Step3.P′←P;
Step4.F′←F∪(pn,τ)∪(τ,pm);
Step5. RETURNWFN′=(P′,T′;F′,M,i,o).
例3. 对图1中的工作流网模型WFN1,日志L={a,c,c,e,d},迹σ=a,c,c,e,d的模型修正结果如图5所示:
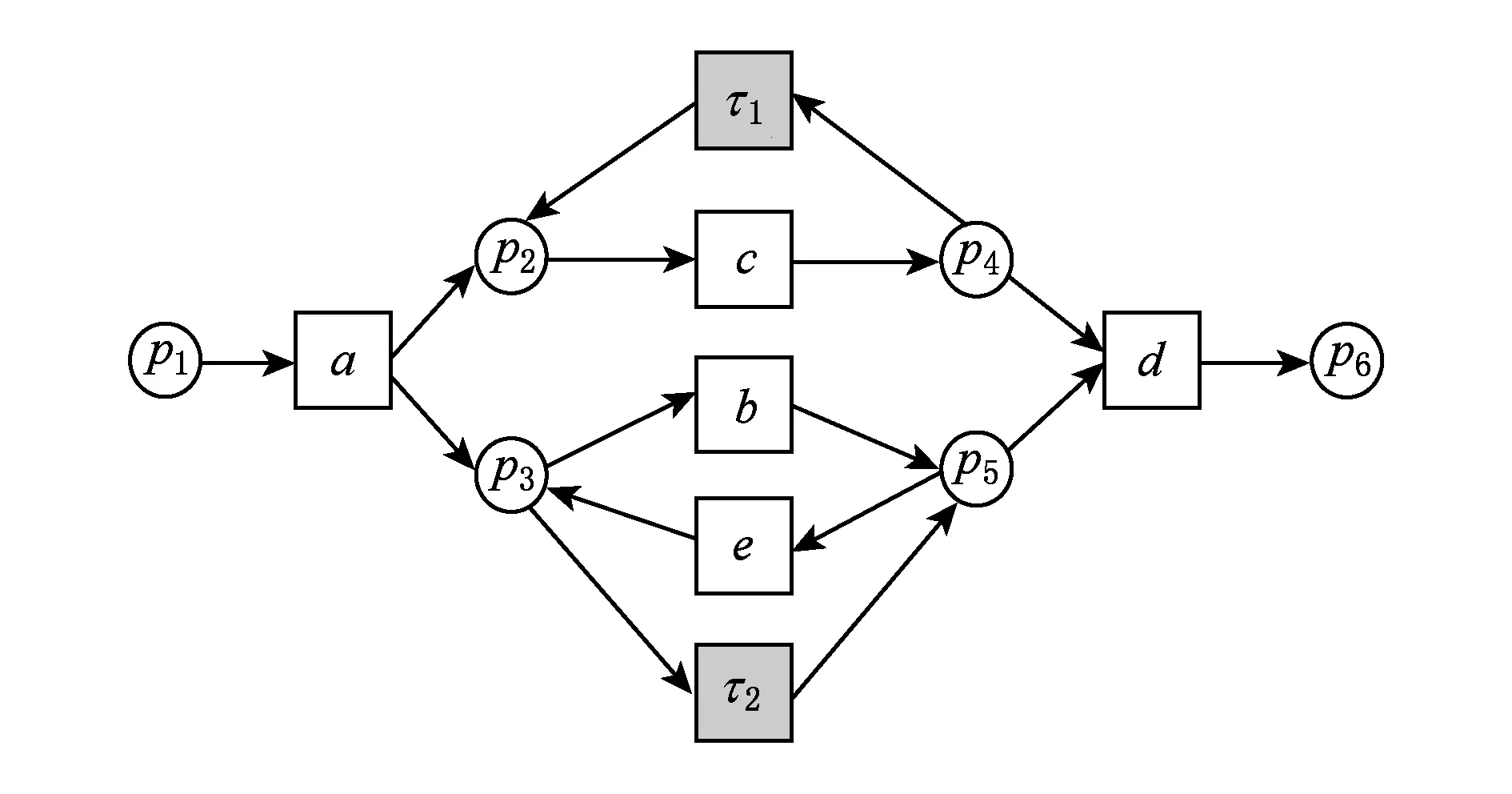
Fig. 5 Repaired model of WFN1.图5 WFN1的修正模型
由图5可知,当第3个活动c触发时,库所p2中缺少1个token,在p2和p4之间添加1个不可见变迁τ1,使token从p4流向p2,这样就可以解决p2中缺少token的问题,使活动c使能.活动e触发时,库所p5缺少1个token,在p5和p3之间添加1个不可见变迁τ2,使token从p3流向p5,这样就可以解决p5中缺少token的问题,使活动e使能.触发活动d时,库所p5缺少1个token.添加了从库所p3到库所p5的不可见变迁和流关系后,通过此不可见变迁库所p5可以获得token,使d使能.
例4. 对于图3中的工作流网模型WFN2,日志L={a,b,c,d,b,c,b,c,d},根据识别的模型偏差域,可以修正模型,且修正结果如图6所示:
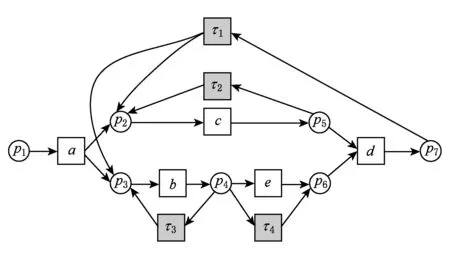
Fig. 6 Repaired model of WFN2.图6 WFN2修正模型
WFN2修正是一个相对复杂的修正例子,涉及到了复杂结构体循环修正和循环结构内部修正.一共增加了4个不可见变迁,第1次触发d时,库所p6中缺少1个token,在p4和p6之间添加1个不可见变迁τ4,使token从p4流向p6,使变迁d使能.变迁b和c是并发的,第2次触发b和c时,2个库所同时都缺少1个token,在p7与p2和p3之间添加1个不可见变迁τ1,使token从p7流向p2和p3,使并发变迁b和c都使能.第3次触发b时,库所p3中缺少1个token,在p4和p3之间添加1个不可见变迁τ3,使token从p4流向p3,使变迁b使能.第3次触发c时,库所p2缺少1个token,在p5和p2之间添加1个token,使token从p5流向p2,使变迁c使能.最后触发d,库所p6缺少1个token.在p4和p6之间有1个不可见变迁,token可以从p4流向p6,使d使能.由此可得到如图6所示的WFN2的模型修正图.
3.2动态模型修正
静态模型修正依赖于识别出来的模型偏差域,模型偏差域识别算法只有在偏差域识别出来时才考虑,后续的识别过程中如果直接或间接涉及到该偏差域时,算法都默认该偏差域是不存在的,这就会导致偏差重复识别并且忽略偏差对整体的影响.因此对于复杂结构修正(例如WFN2的修正),静态模型修正无法整体把握模型的偏差,会使修正结果复杂条理不清晰.针对复杂结构修复,提出一种动态模型修正方法,使修正结果更加简单清晰.
动态模型修正在进行模型偏差域识别的过程中,一旦识别出偏差域立即修正模型,并更新原有模型,在新模型的基础上继续进行强制重演直到结束.下面给出动态模型修正算法,τ表示不可见变迁.
算法4. 动态模型修正算法.
输入:工作流网WFN=(P,T;F,M,i,o)、事件日志L∈B(σ*);
输出:修正后的工作流网WFN′=(P′,T′;F′,M,i,o).
Step1.S←∅;*S用来存放以pm为标记的偏差域(pn,pm),若pm为多个库所,则分别以每一个库所为标记存放在S中*
Step2. 调用基于token的模型偏差域识别算法(算法2);
Step3. IF (there is (pn,pm)) THEN
Step3.1. IF (pm未在S中出现) THEN
Step3.1.1.S←〈pm,(pn,pm)〉∪S;
Step3.1.2.T′←T∪τ;
Step3.1.3.F′←F∪(pn,τ)∪(τ,pm);
Step3.1.4.P′←P;
Step3.1.5. RETURNWFN′=(P′,T′;F′,M,i,o);
Step3.2. ELSE
Step3.2.1. 在S中以pm为索引得到;*此处为之前识别过的偏差域可能与pn相同也可能不同*
返回算法2对库所内出现负数token的操作;
Step3.2.3. RETURNWFN′←WFN.
例5. 运用动态模型修正算法重新修正图3中的工作流网模型WFN2,L={a,b,c,d,b,c,b,c,d},修正结果如图7所示:
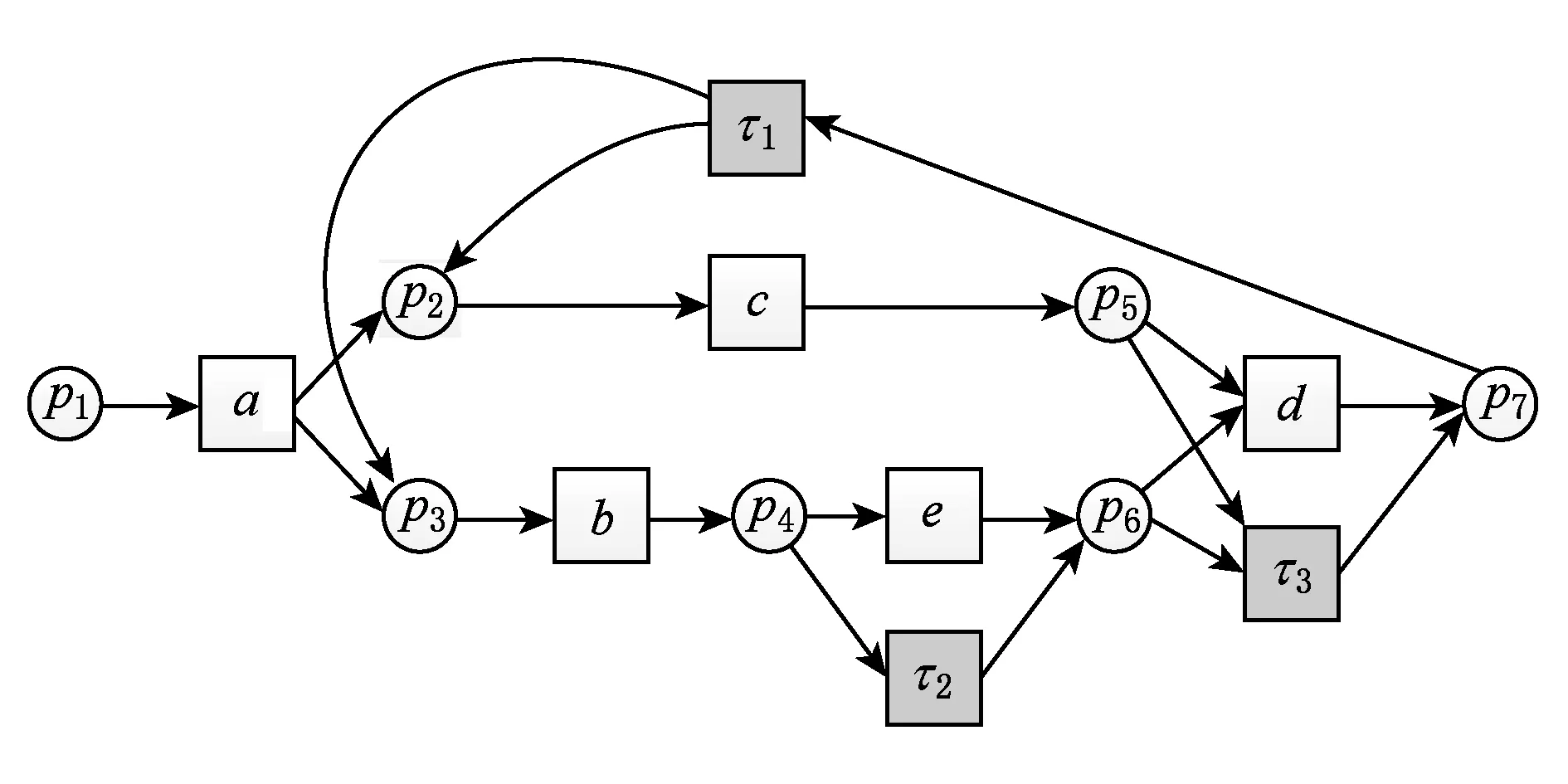
Fig. 7 Dynamically repaired model of WFN2.图7 WFN2动态修正模型
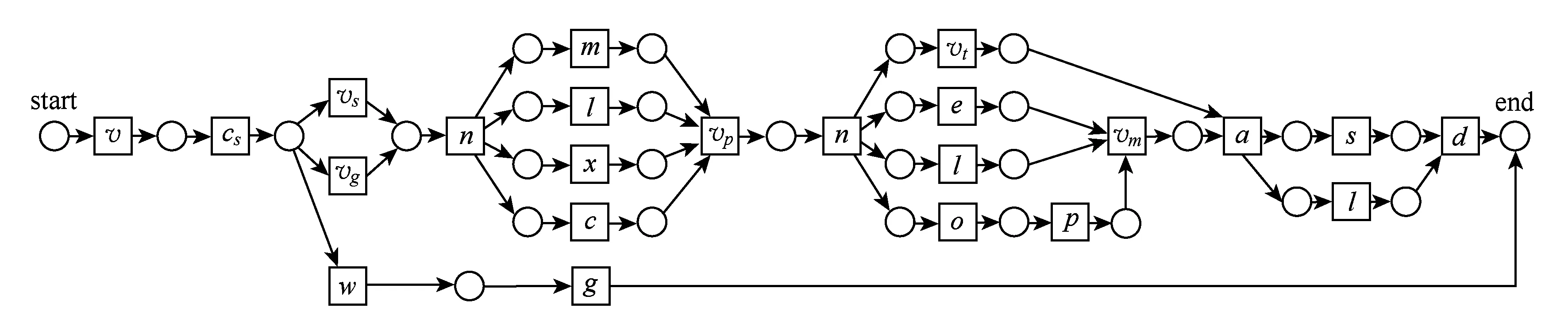
Fig. 8 The process model for diagnosing and performing surgery on patients with colonopathy.图8 结肠病患者就诊流程模型
与静态模型修正不同的是:第3次触发b时,返回模型偏差域(p4,p3)进行判断,由于标记p3在S中出现,因此之前的工作已经将此偏差修正,不必对(p4,p3)区域修正.得到S中以p3为标记的元素p3,(p7,(p2,p3)),继续判断库所p7中是否有token,结果在第3次触发d之前库所p7中是没有token的,因此顺着流关系寻找存在token的库所,发现偏差域((p5,p6),p7),只有p5中有token,p6中没有,然后再顺着流关系向前寻找含有token的库所,发现偏差域(p4,p6),而标记p6在S中出现,因此不用修正偏差域(p4,p6),只需修正偏差域((p5,p6),p7).
对比图6和图7,动态模型修正的修正结果只添加了3个不可见变迁和8条流关系就完成和修正,而静态模型修正的修正结果却添加了4个不可见变迁和9条流关系.随着模型和日志的复杂程度增加,这种修正结果的对比会更加明显.可见,动态模型修正方法对于复杂结构的修正更为简单准确,而且结构清晰.
4 仿真实验
本文提出的模型修正技术已经在过程挖掘工具ProM6中实现.本节将对提出的技术进行仿真实验与比较分析,进一步验证本文方法的正确性和有效性.
4.1实验模型与数据
实验所使用的过程模型和事件日志来源于某三甲医院.图8展示了结肠病患者的诊断和手术过程.此过程开始于患者访问就诊部门(变迁v),结束访问后去做结肠镜检查(cs),检查完毕后直接去手术门诊(vs)或者让肠胃病主任查看检查结果(vg)或者没有结肠疾病(w)离开结肠门诊(g).如果患者有结肠疾病,需去结肠护理门诊(n)制定一系列诊断检查计划.主要有化验检测(l),CT扫描(c),核磁共振(m)和X射线扫描(x).做完这些检查后,患者需要再次去就诊部门(vp)制定治疗计划.然后,患者再次去结肠护理门诊(n)准备手术过程.依次进行确认手术(o),术前评估(p),同时进行心电图(e)和化验检测(l),且到膳食部门制定相应的饮食计划(vt).同外科医生商议(vm)后,患者住院(a)并进行手术(s)以及化验检测(l).最后,患者病愈出院(d).其工作流网模型如图8所示.
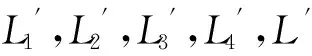
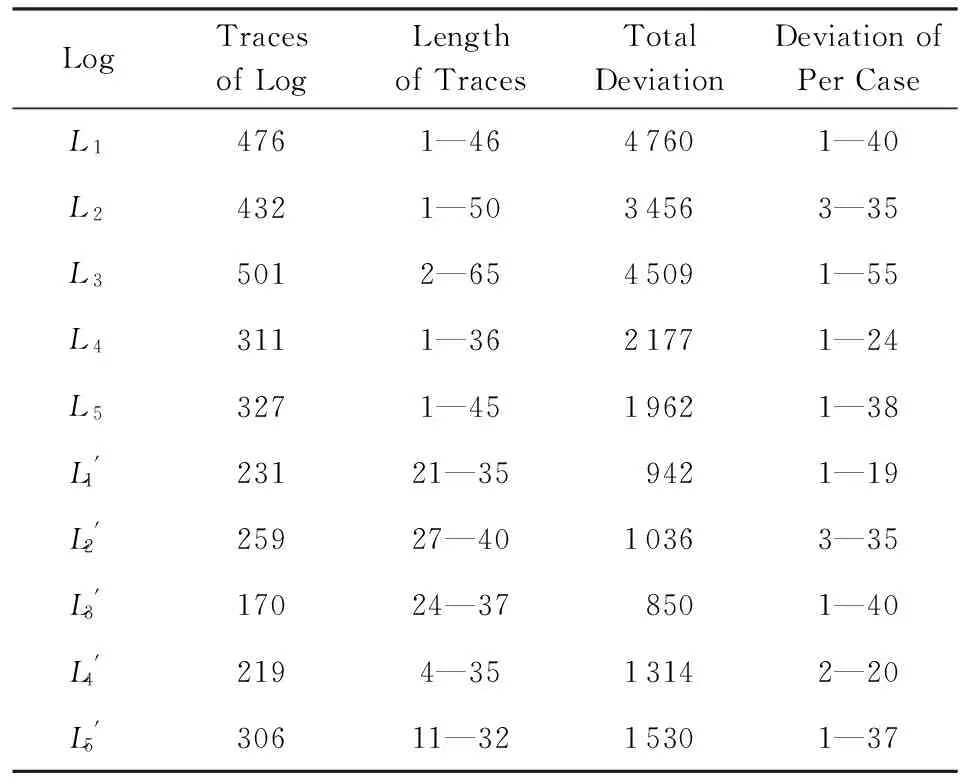
Table 3 Detailed Information of Logs表3 详细日志信息
4.2基于子迹的模型修正实验
本文以基于子迹的模型修正技术为代表[21]进行实验对比与分析,该技术是普通修正技术的改进,其主要思想是,通过校准找到模型的偏差区域,对于模型动作通过添加不可见变迁跳过执行,将相邻的日志动作作为子日志,通过子日志挖掘子模型,将子模型添加到原模型中.这种修正方法耗时长,涉及的算法过多,既要利用合适的校准找到偏差区域,又要利用模型挖掘算法挖掘子模型,因此与本文所提模型修正技术相比过于复杂.
Fig. 9 Repaired result of Fig.8 according to 2 by subprocess-based model repair.图9 基于2对图8的修正——基于子迹的模型修正
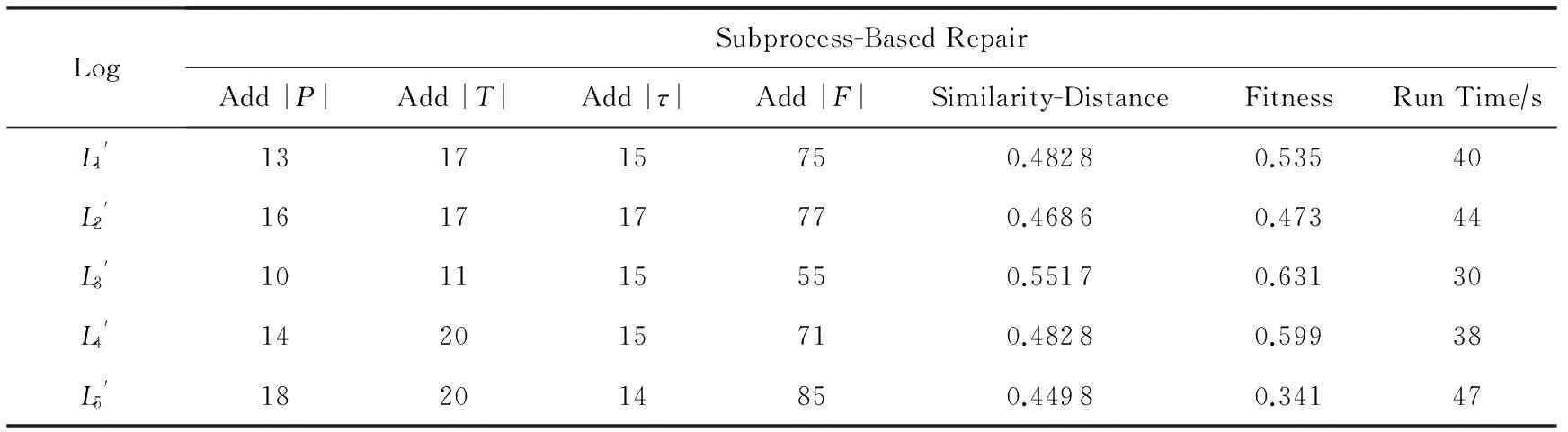
LogSubprocess-BasedRepairAdd|P|Add|T|Add|τ|Add|F|Similarity-DistanceFitnessRunTime∕sL'1131715750.48280.53540L'2161717770.46860.47344L'3101115550.55170.63130L'4142015710.48280.59938L'5182014850.44980.34147
4.3基于token的模型修正验证实验
4.3.1静态模型修正
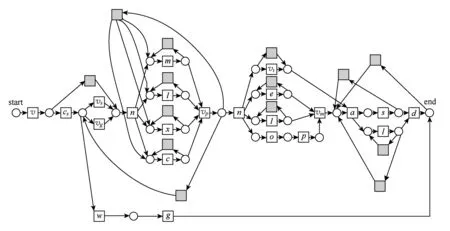
Fig. 10 Repaired result of Fig.8 according to 2 by static model repair.图10 基于2对图8的修正——静态模型修正
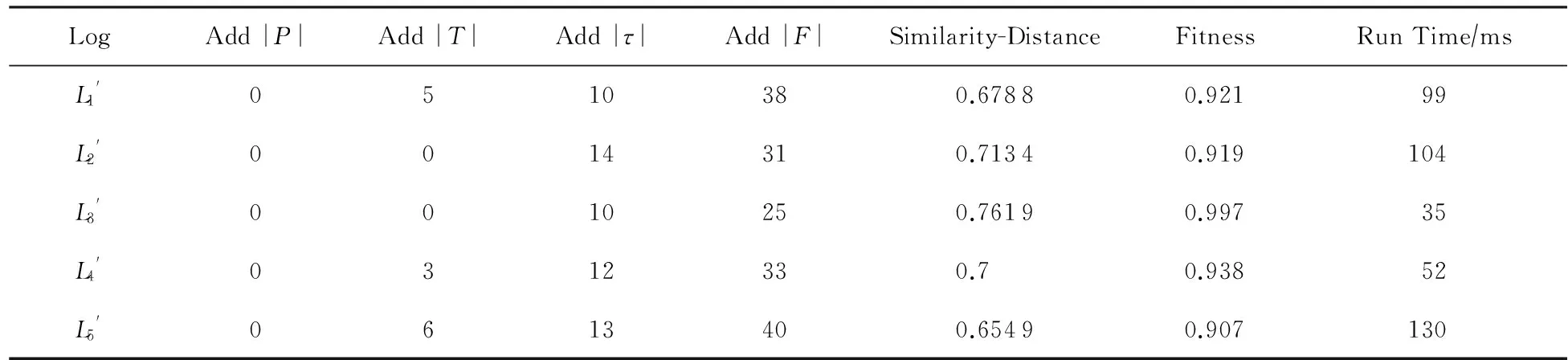
LogAdd|P|Add|T|Add|τ|Add|F|Similarity-DistanceFitnessRunTime∕msL'10510380.67880.92199L'20014310.71340.919104L'30010250.76190.99735L'40312330.70.93852L'50613400.65490.907130
4.3.2动态模型修正
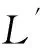
表6展示了动态修正结果,增加0个库所、13个不可见变迁、30条流关系、增加9个循环结构和4个选择结构.修正模型与原始模型的相似距离0.722 6,与日志的拟合度高达0.969.
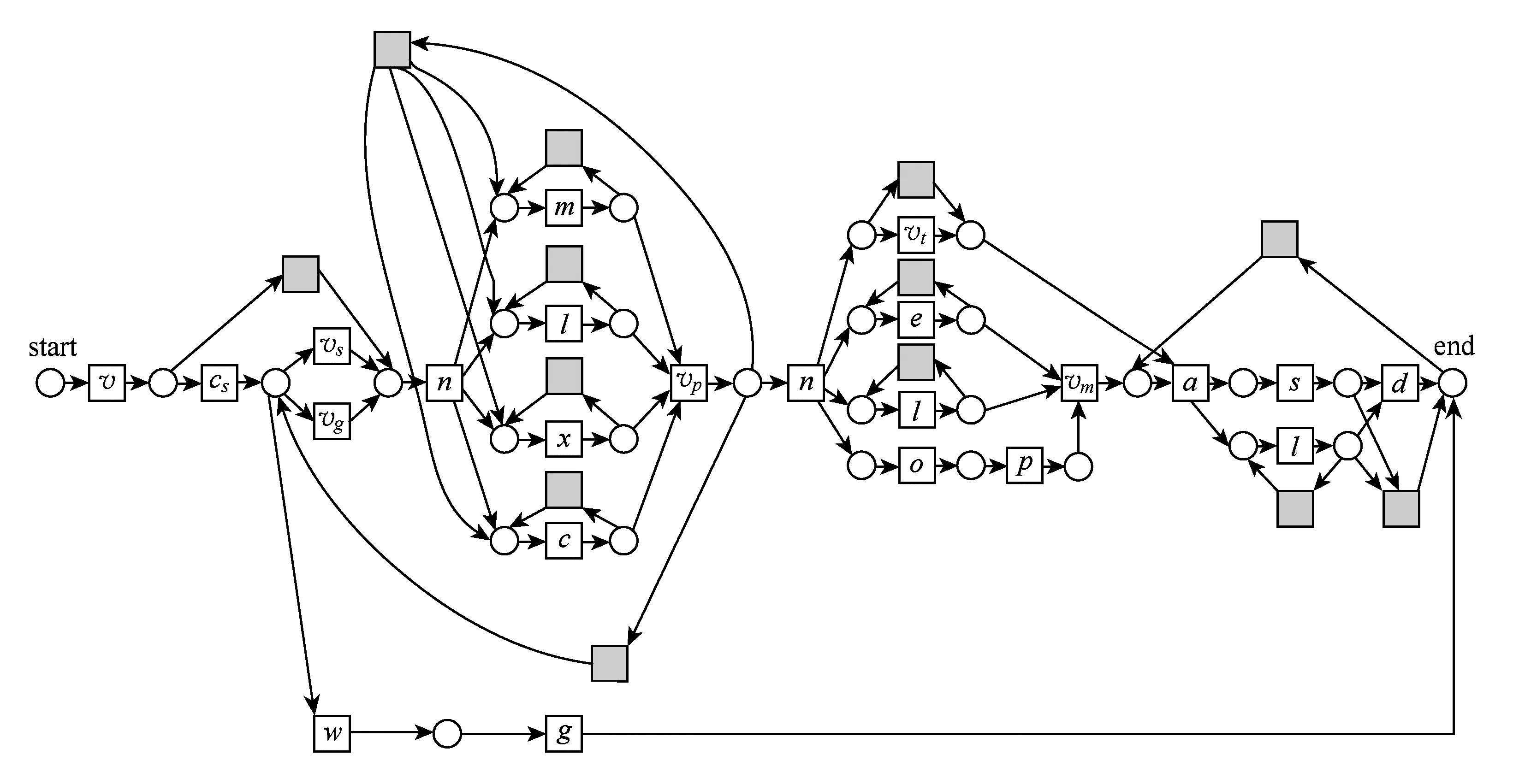
Fig. 11 Repaired result of Fig.8 according to 2 by dynamic model repair.图11 基于2对图8的修正——动态模型修正
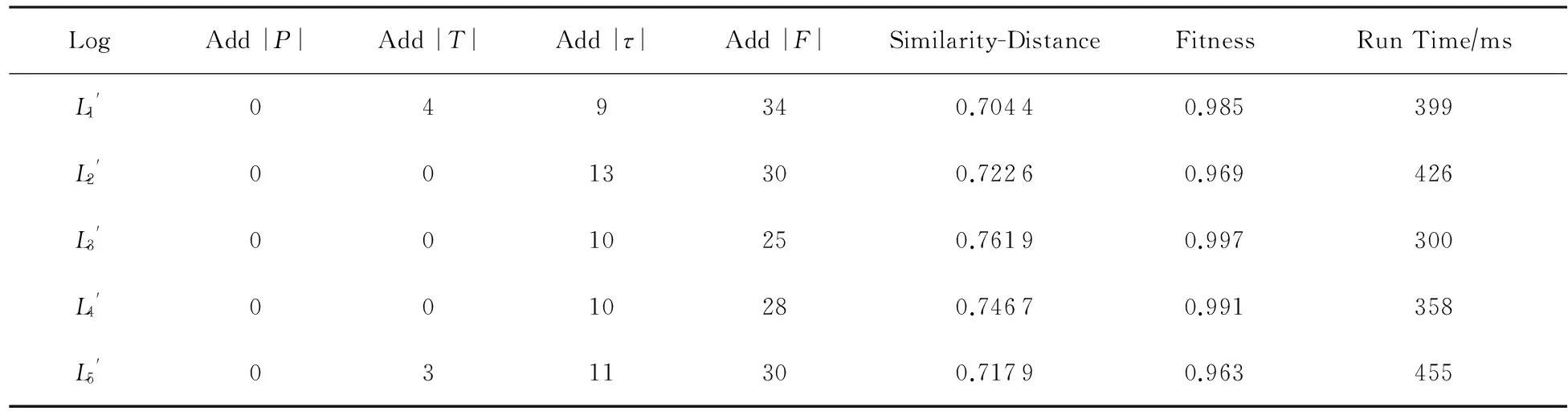
LogAdd|P|Add|T|Add|τ|Add|F|Similarity-DistanceFitnessRunTime∕msL'1049340.70440.985399L'20013300.72260.969426L'30010250.76190.997300L'40010280.74670.991358L'50311300.71790.963455
4.43种模型修正技术对比分析
本节对3种修正方法进行拟合度和时间复杂度方面的对比分析.
4.4.1拟合度
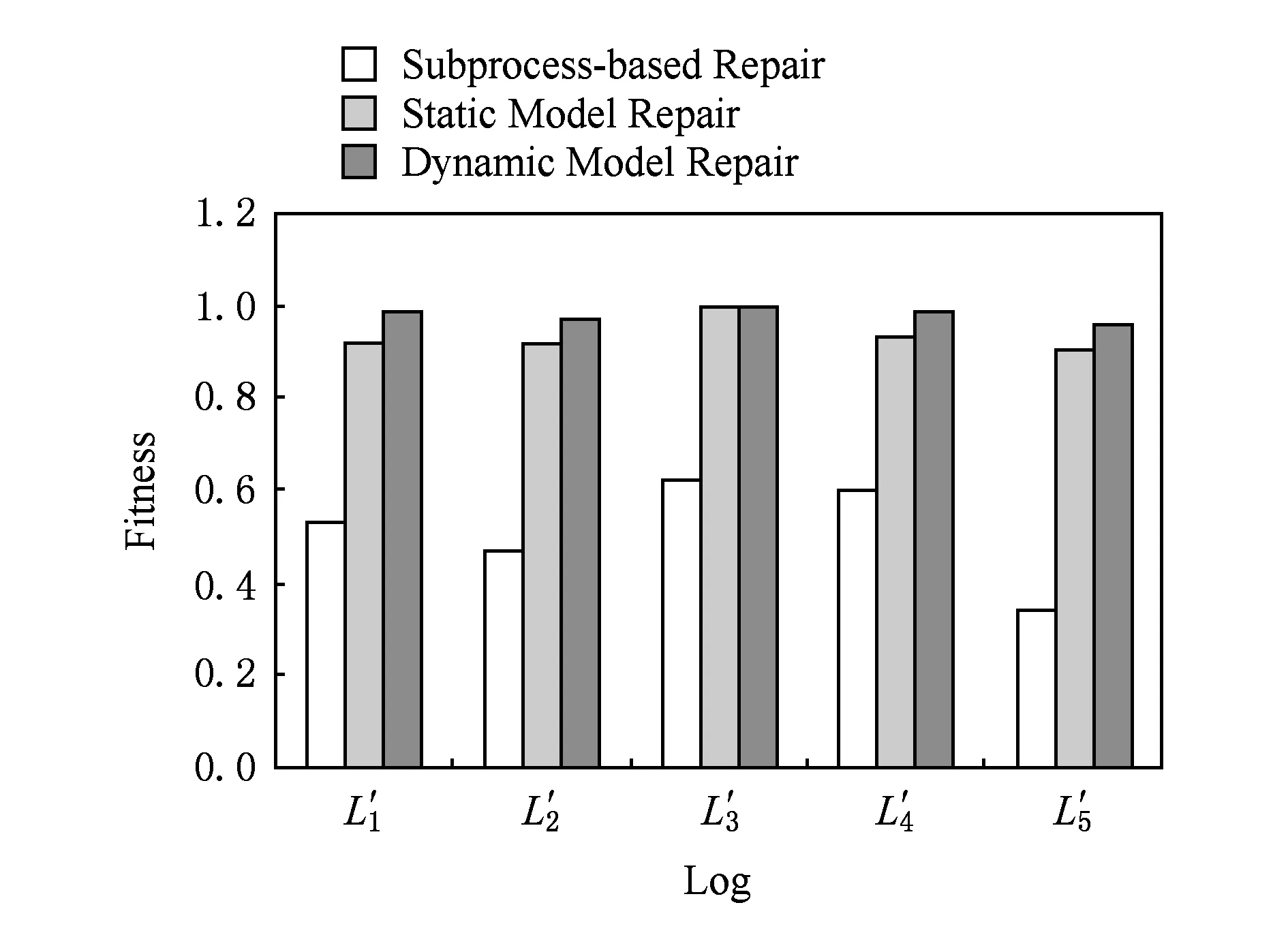
Fig. 12 Fitness of different model repair techniques.图12 不同修正技术的拟合度
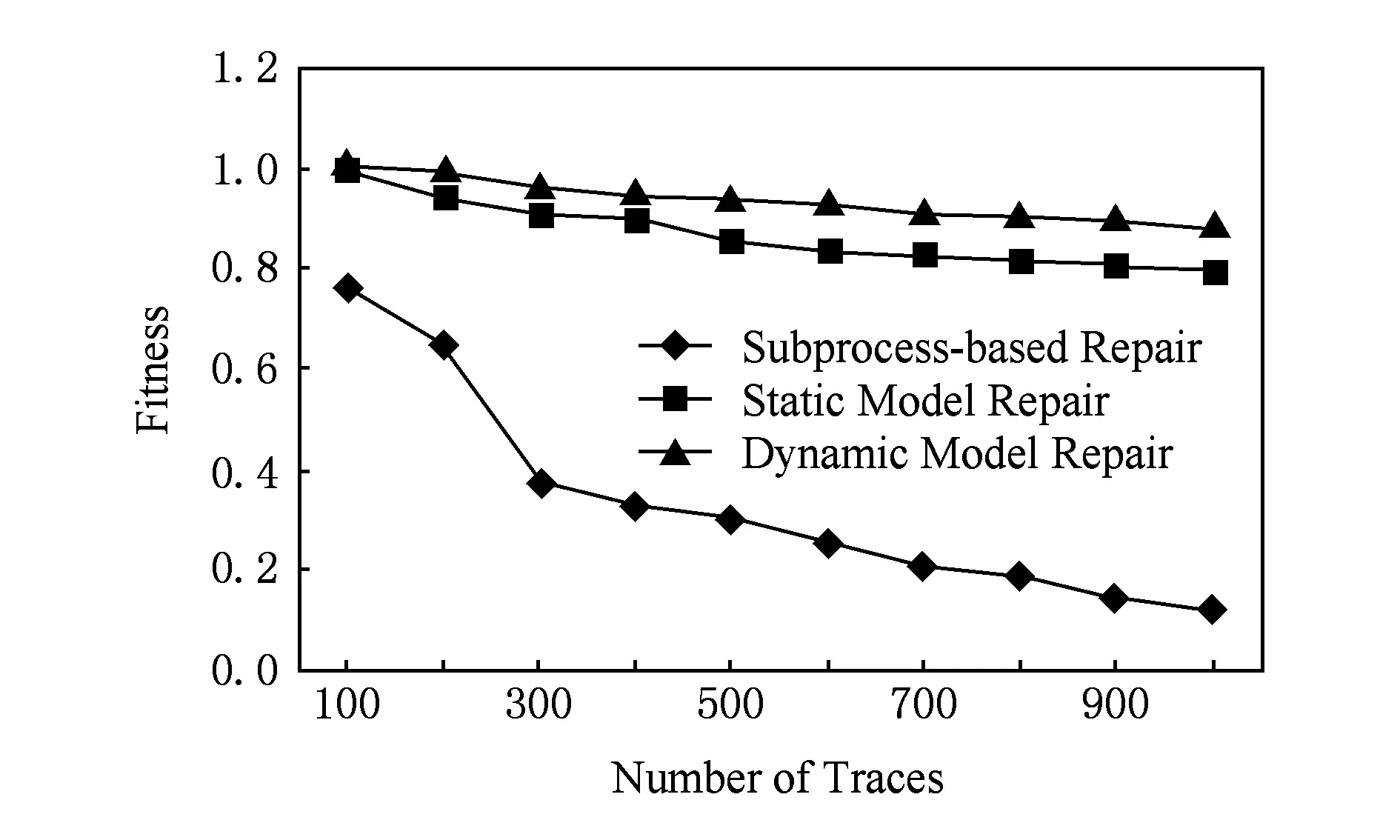
Fig. 13 Changing curves of fitness.图13 拟合度变化曲线
4.4.2时间复杂度
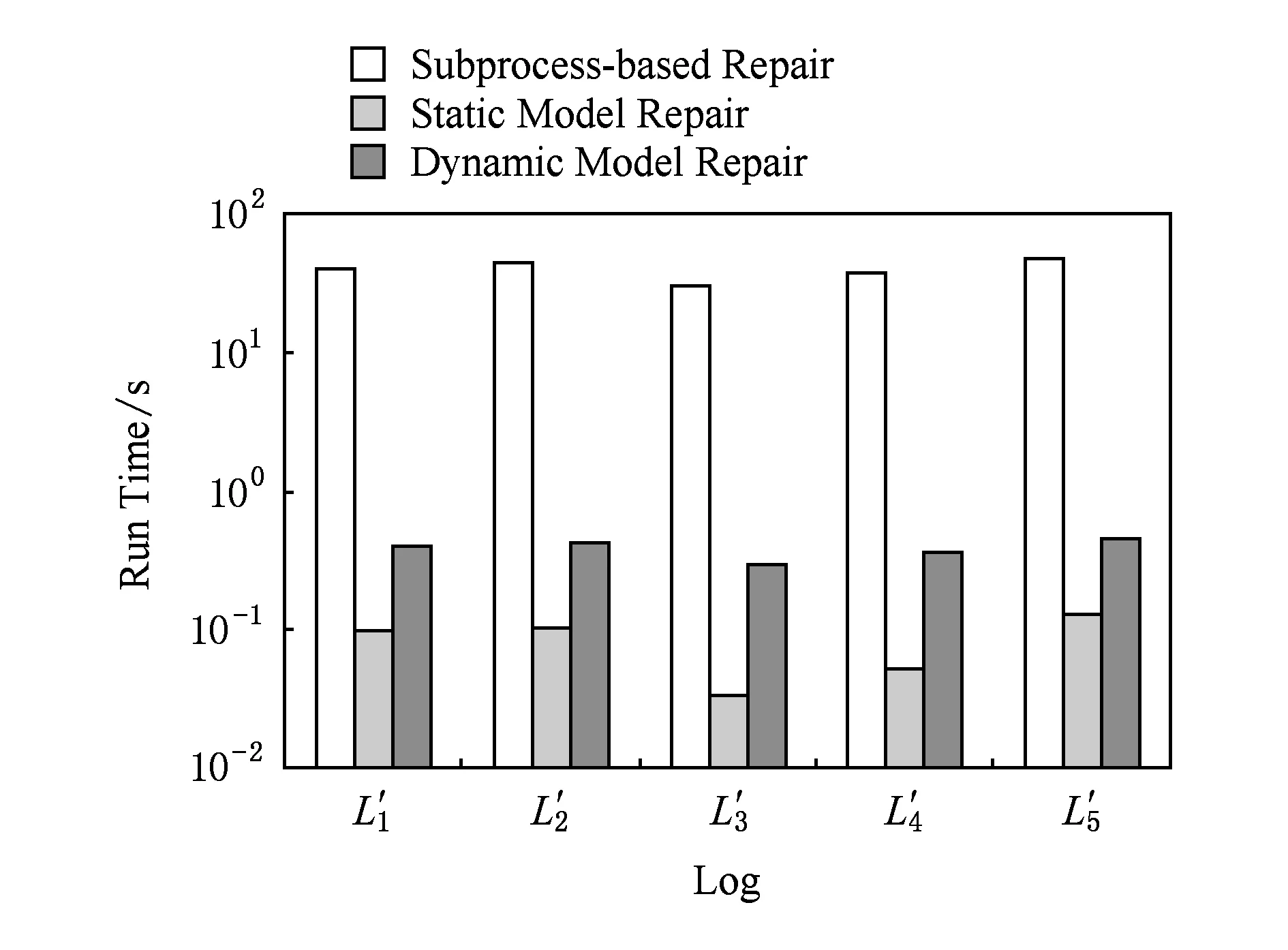
Fig. 14 Run time of different model repair techniques.图14 不同修正技术所需时间
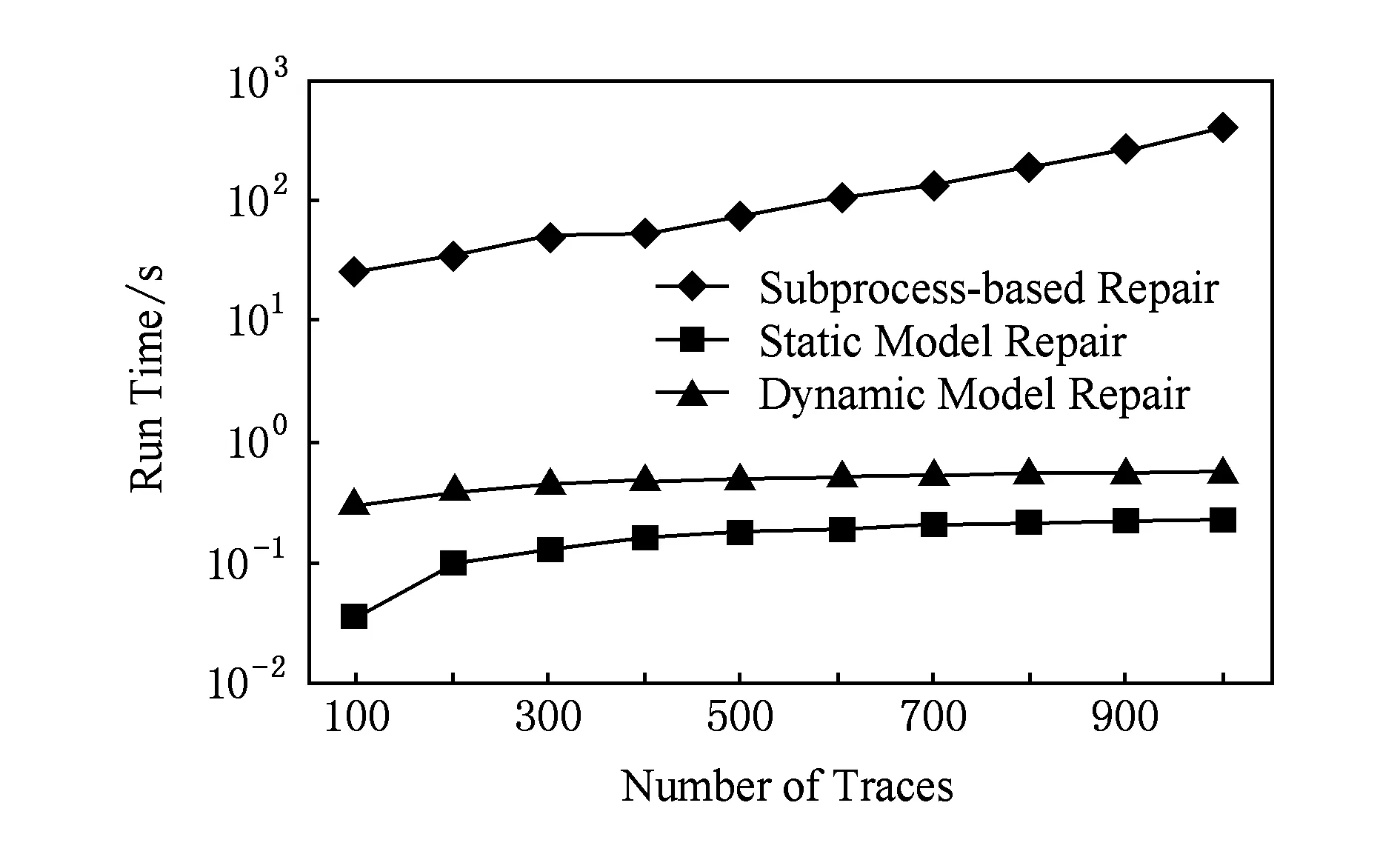
Fig. 15 Changing curves of run time.图15 时间变化曲线
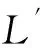
5 相关工作
现有的一致性检测技术主要目的是衡量拟合度,例如模型可以重演多少日志以及尽可能多地发现模型偏差[22].除了拟合度,还有其他度量标准[18](精确度、泛化度和简洁度)衡量模型质量.将模型和日志作为输入的迭代过程发现技术,主要有2种基本技术类型.1)从日志L中发现过程模型NL,然后合并N和NL成新模型N[23].2)提取日志L中事件间的关系RL和模型N中活动间的关系RN,将2种关系合并得到R′.通过R′就可以得到修改的过程模型N′.R′是RN被RL取代的关系[24].这2类技术都会产生一个复杂的模型.为了解决这个问题,一个新的模型修正技术基于子迹的模型修正技术[21]被提出.虽然该技术解决迭代过程发现技术的缺点,但是同样使用过程发现技术,不同的是迹的规模变小了.因此,时间复杂度是不变的,且修正得到的结果同样很复杂.另一种模型修正方法是强制修正模型与原始模型之间的相似度,将相似度形式化为编辑距离[25].基于编辑距离,多种模型修正技术被提出,例如原始模型的最优相似健全模型[26].但是这些方法都不考虑现实行为.还有一些技术利用执行时间调整模型.
已有修正技术可能会存在时间复杂度高、修正结果拟合度低或者修正结果相对复杂的情况.针对这些情况本文提出了基于token的模型偏差域识别方法和基于token的模型修正技术,从另一个角度分析网行为,更加细致准确地完成模型修正,并且修正结果简单拟合度高.
6 结 论
本文根据一致检测技术中的重演提出强制重演,主要使用拟合度和时间复杂度衡量模型修正的质量.对于与模型不拟合的迹重演不能顺利进行,而强制重演遇到不能触发的活动时,用标识记录token的变化情况,并继续重演.根据强制重演记录的标识,可以很容易地找到缺失token的库所和剩余token的库所.以token为线索,从微观的角度分析网系统的偏差,又在强制重演的基础上提出一种基于Petri网的模型偏差域识别方法以及模型修正技术.通过控制token流向,有效地实现了模型修正,该模型修正方法修正结果拟合度高.该技术使得系统资源合理利用,利用系统多余资源使缺少触发条件的变迁得以触发,该技术还可以从根本上发现模型偏差并对其做出修正.
通过与其他方法的对比实验和分析,验证了本文方法的有效性和正确性.下一步工作将考虑其他一致性度量标准和改进的一致性检测方法[27],例如泛化度和精确度.同时,对于日志的适用不仅局限于活动的执行顺序,还要考虑诸如时间戳和活动属性等信息.
[1]Medeiros A K A, Weijters A, van der Aalst W M P. Genetic process mining: An experimental evaluation [J]. Data Mining and Knowledge Discovery, 2007, 14(2): 245-304
[2]van der Aalst W M P, Weijters A, Maruster L. Workflow mining: Discovering process model form event logs [J]. IEEE Trans on Knowledge and Data Engineering, 2004, 16(9): 1128-1142
[3]Goedertier S, Martens D, Vanthienen J, et al. Robust process discovery with artificial negative events [J]. Journal of Machine Learning Research, 2009, 10: 1305-1340
[4]Medeiros A, Weijters A, van der Aalst W M P. Genetic process mining: An experimental evaluation [J]. Data Mining and Knowledge Discovery, 2007, 14(2): 245-304
[5]Wang Jianmin, Wen Lijie. Mining process knowledge from log data [J]. Communications of CCF, 2012, 8(6): 63-68 (in Chinese)
(王建民, 闻立杰. 从日志数据中挖掘过程知识[J].中国计算机学会通讯, 2012, 8(6): 63-68)
[6]van der Werf J, van Dongen B, Hurkens C, et al. Process discovery using integer linear programming [J]. Fundamenta Informaticae, 2010, 94: 387-412
[7]van der Aalst W M P, Adriansyah A, van Dongen B. Replaying history on process models for conformance checking and performance analysis [J]. WIREs Data Mining and Knowledge Discovery, 2012, 2(2): 182-192
[8]Rozinat A, van der Aalst W M P. Conformance checking of processes based on monitoring real behavior [J]. Information Systems, 2008, 33(1): 64-95
[9]Banerjee A. Structural distance and evolutionary relationship of networks[J]. Biosystems, 2012, 107(3): 186-196
[10]Cao Yongzhi, Wang Huaiqing, Sun Sherry Xiaoyun, et al. A behavioral distance for fuzzy-transition systems[J]. IEEE Trans on Fuzzy Systems, 2013, 21(4): 735-747
[11]Alpaydin E. Introduction to Machine Learing[M]. Cambridge, MA: MIT Press, 2010
[12]Murata T. Petri nets: Properties, analysis and applications [J]. Proceedings of the IEEE, 1989, 77(4): 541-580
[13]van der Aalst W M P. Process Mining: Discovery, Conformance and Enhancement of Business Processes[M]. Berlin: Springer, 2011
[14]Du Yuyue, Jiang Changjun, Zhou Mengchu. A Petri net-based model for verfication of obligations and accountability in cooperative systems [J]. IEEE Trans on Systems, Man, and Cybernetics—Part A: Systems and Humans, 2009, 39(2): 299-308
[15]Du Yuyue, Jiang Changjun, Zhou Mengchu. A Petri nets based correctness analysis of internet stock trading systems [J]. IEEE Trans on System, Man and Cybernetics-Part C: Applications and Reviews, 2008, 38(1): 93-99
[16]Lin Chuang, Yang Hongkun, Shan Zhiguang. Application of Petri nets to bioinformatics [J]. Chinese Journal of Computers, 2007, 30(11): 1889-1900 (in Chinese)
(林闯, 杨宏坤, 单志广. Petri网在生物信息学中的应用[J]. 计算机学报, 2007, 30(11): 1889-1900)
[17]Sun H C, Du Yuyue. Soundness analysis of inter-organizational workflows [J]. Information Technology Journal, 2008, 7(8): 1194-1199
[18]Du Yuyue, Jiang Changjun. Modeling real-time cooperative systems with workflow nets [J]. Chinese Journal of Computers, 2004, 27(4): 471-481 (in Chinese)
(杜玉越, 蒋昌俊. 基于工作流网的实时协同系统模拟技术[J]. 计算机学报, 2004, 27(4): 471-481)
[19]Lin Chuang, Tian Liqin, Wei Yaya. Performance equivalent analysis of workflow systems [J]. Journal of Software, 2002, 13(8): 1472-1480 (in Chinese)
(林闯, 田立勤, 魏丫丫. 工作流系统模型的性能等价分析[J]. 软件学报, 2002, 13(8): 1472-1480)
[20]van der Aalst W M P, van Hee K M, ter Hofstede A H M, et al. Soundness of workflow nets: Classification, decidability and analysis [J]. Formal Aspects of Computing, 2011, 23(3): 333-363
[21]Fahland D, van der Aalst W M P. Model repair: Aligning process models to reality [J]. Information Systems, 2015, 47: 220-243
[22]Rozinat A, van der Aalst W M P. Conformance checking of processes based on monitoring real behavior [J]. Information Systems, 2008, 33(1): 64-95
[23]Kindler E, Rubin V, Sch¨afer W. Incremental workflow mining based on document versioning information[G] //LNCS 3840: Proc of Int Software Process Workshop. Berlin: Springer, 2005: 287-301
[24]Li Jie, Wen Lijie, Wang Jianmin. Process model storage mechanism based on Petri net edit distance [J]. Computer Integrated Manufacturing Systems, 2013, 19(8): 1832-1841 (in Chinese)
(李婕, 闻立杰, 王建民. 基于Petri网编辑距离相似性的过程模型存储机制[J]. 计算机集成制造系统, 2013, 19(8): 1832-1841)
[25]Lohmann N. Correcting deadlocking service choreographies using a simulation-based graph edit distance[G] //LNCS 5240: Proc of the 6th Int Conf on BPM. Berlin: Springer, 2008: 132-147
[26]Gambini M, Rosa M L, Migliorini S, et al. Automated error correction of business process models[G] //LNCS 6896: Proc of the 9th Int Conf on BPM. Berlin: Springer, 2011: 148-165
[27]Tian Yinhua, Du Yuyue. A grouping algorithm of optimal alignments [J]. Journal of Shandong University of Science and Technology : Natural Science, 2015, 34(1): 29-34 (in Chinese)
(田银花, 杜玉越. 一种最优校准的分组算法[J]. 山东科技大学学报: 自然科学版, 2015, 34(1): 29-34)

Du Yuyue, born in 1960. Professor and PhD supervisor at Shandong University of Science and Technology. Senior member of China Computer Federation. His research interests include work flows, business process mining and Petri nets, etc.

Sun Yanan, born in 1991. Master candidate at Shandong University of Science and Technology. Her research interests include big data, process mining and Petri net, etc.

Liu Wei, born in 1977. Associate professor at Shandong University of Science and Technology. His research interests include Petri net and service computing (yanchunchun9896@163.com).
Petri Nets Based Recognition of Model Deviation Domains and Model Repair
Du Yuyue, Sun Ya’nan, and Liu Wei
(KeyLaboratoryforWisdomMineInformationTechnologyofShandongProvince,ShandongUniversityofScienceandTechnology,Qingdao,Shandong266590)
Process mining techniques can be used to discover process models from event logs. Event logs and process model can be contrasted by conformance checking techniques. And conformance checking techniques can be used to detect the deviations between observed behaviors and process model. However, existing techniques of process mining concern with discovering these deviations, but not support to repair the process model easily and make the process model more related to the real process. So in this paper we propose a token-based identification method of model deviation domains and a token-based technique of model repair (static model repair and dynamic model repair) through techniques of conformance checking and dynamic behaviors of workflow net. Model deviation domains can be identified effectively though the flow direction of token. We can repair process model according to model deviation domains. And we also can repair the real complex process accurately which has the structures of complicated circulation and choice. In this paper, the effectiveness and the correctness of techniques are illustrated through contrast experiment and analysis with other techniques.
conformance checking; model repair; deviation domains; workflow net; token
2016-03-01;
2016-05-30
国家自然科学基金项目(61170078,61472228);泰山学者建设工程专项;山东省自然科学基金项目(ZR2014FM009);山东省优秀中青年科学家科研奖励基金项目(BS2015DX010)
孙亚男(ynsun1006@163.com)
TP301.6
This work was supported by the National Natural Science Foundation of China (61170078,61472228), the Taishan Scholar Construction Project of Shandong Province, the Natural Science Foundation of Shandong Province (ZR2014FM009), and the Promotive Research Fund for Young and Middle-aged Scientists of Shandong Province (BS2015DX010).
猜你喜欢
高技术通讯(2022年8期)2022-11-06 06:06:14
电子器件(2021年1期)2021-03-23 09:24:02
科学与财富(2020年15期)2020-07-04 04:06:44
水利科技与经济(2017年4期)2017-04-22 02:38:02
城市轨道交通研究(2015年11期)2015-06-28 11:42:56
西南科技大学学报(哲学社会科学版)(2015年1期)2015-02-28 10:28:32
连环画报(2014年6期)2014-11-14 08:30:56
华侨大学学报(自然科学版)(2014年4期)2014-10-11 06:23:42
吉林大学学报(工学版)(2014年1期)2014-04-12 00:32:08
制造技术与机床(2012年3期)2012-09-26 09:31:46
