
基于改进Hadoop云平台的海量文本数据挖掘
2016-08-31 02:21陈炎龙段红玉
湖南师范大学自然科学学报 2016年3期
陈炎龙,段红玉
(河南牧业经济学院信息工程系,中国 郑州 450011)
基于改进Hadoop云平台的海量文本数据挖掘
陈炎龙*,段红玉
(河南牧业经济学院信息工程系,中国 郑州450011)
针对常用的文本数据挖掘系统在处理海量文本数据时时间效率较低的问题,论文提出了一种基于改进Hadoop云平台的海量文本数据挖掘方法.该方法首先将传统Hadoop云平台进行改进以适应海量文本数据挖掘的需要,然后将海量文本数据集和挖掘任务分解到该改进平台上的多台计算机上并行处理,从而实现了一个基于改进Hadoop云平台的海量文本数据挖掘平台,并通过对10 000篇新闻材料组成的实验数据集进行挖掘验证了该平台的有效性和高效性.
文本挖掘;Hadoop;云计算;文本数据
随着计算机技术与信息技术的飞速发展,国民经济各行业所获得的数据呈爆炸式增长,TB级甚至PB级海量数据无处不在[1].由于数据主要来自于互联网,例如电子商务、微博等,这些数据主要以文本形式存储,十分繁杂但又极具价值.它们产生的速度远远超过了人们收集信息、利用信息的速度,使得人们无法快速有效地查找到自己真正感兴趣的信息,从而造成了时间、资金和精力的巨大浪费,导致“数据资源”变成“数据灾难”[2].因此,如何有效地从这类海量数据中获取信息或规律已成为当今信息科学技术领域所面临的基本科学问题之一.
然而, 在传统计算框架下,海量文本数据的处理一般需要借助高性能机或者是更大规模的计算设备来完成[3].这虽然能够在一定程度上解决海量数据的处理问题,但是其具有成本昂贵、随着时间推移容错性能差、可扩展性差等缺点,从而导致其很难普及[4].
Hadoop云平台作为一种专门处理海量数据的新式计算模型于2005年被提出,2011年1.0.0版本释出,标志着Hadoop已经初具生产规模,它将现代计算机的高性能与人的高智能相结合,是当今处理海量数据最有效、最核心的手段与途径[5].论文将传统Hadoop云平台进行改进以适应海量文本数据挖掘的需要,然后将海量文本数据集和挖掘任务分解到该改进平台上的多台计算机上并行处理,从而实现了一个基于改进Hadoop云平台的海量文本数据挖掘平台,并通过对10 000篇新闻材料组成的实验数据集进行挖掘验验证了平台的有效性和高效性.
1 Hadoop云平台简介
Hadoop云平台[6]是由Apache基金会开发的一个能够对大量数据进行分布式处理的软件框架,是一个能够让用户轻松架构和使用的分布式计算平台.通过该框架,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力高速运算和存储.Hadoop框架由HDFS[7]和MapReduce[8]组成,其中,Hadoop分布式文件系统(HDFS)[3]在最开始是作为Apache Nutch搜索引擎项目的基础架构而开发的,目前已经是Apache Hadoop Core项目的一部分.HDFS被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时,它和其他的分布式文件系统的区别也很明显[9].HDFS是一个高度容错性的系统,适合部署在廉价的机器上;能提供高吞吐量的数据访问,非常适合大规模数据集上的应用[10].MapReduce[11]是谷歌开发的一种分布式程序设计框架,基于它编写的应用程序能够运行在由上千台计算机组成的大型集群上,并且以一种可靠容错的方式对海量数据进行并行处理.Hadoop能够实现对多种类型文件的处理,比如文本、图像、视频等.我们可以根据自己的需要编写特定的应用程序来完成任务目标[12].
2 传统基于Hadoop云平台的文本数据挖掘
在传统基于Hadoop云平台的文本挖掘系统中,节点主要分为主节点(Master)和从节点(Slave)这两类.整个系统仅有一个Master节点,由NameNode、文本数据集、JobTracker、文本挖掘算法库组成.在系统中可有多个Slave节点,它由DataNode、TaskTracker组成,主要负责系统的存储和计算任务.系统的整体架构如图1所示.
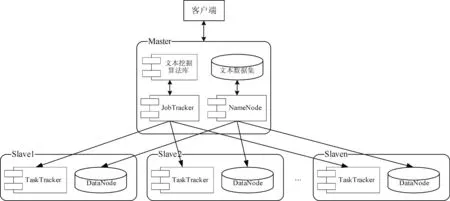
图1 基于Hadoop云平台的文本挖掘整体架构图Fig.1 Overall architecture diagram of text mining based on hadoop cloud platform
NameNode: 整个集群中只有一个,是整个系统的大脑,负责管理HDFS的目录树和相关的文件元数据信息以及监控各个DataNode的健康状态.NameNode主要职责是跟踪文件如何被分割成文件块、文件块又被哪些节点存储,以及分布式文件系统的整体运行状态是否正常等,如果NameNode节点停止运行的话将会导致数据节点无法通信,客户端无法读取和写入数据到HDFS,实际上这也将导致整个系统停止工作.通常情况下每个Slave节点安装一个DataNode,数据以若干个固定大小的block块的形式在其上存储,定期向NameNode汇报其上存储的数据信息.
文本挖掘算法库主要用于存储对数据进行挖掘所需的算法,这些算法都被存于Master节点中.通常算法都是串行的,为使它们能够在Hadoop云平台执行,在使用之前需要对它们按照Hadoop云平台的特点进行改造.在挖掘过程中,JobTracker会根据实际所需自动将其分发至各Slave节点,供TaskTracker使用.
在该系统中,Master周期性地ping每个Slave,如果在一个时间段内Slave没有返回信息,Master就会标注该Slave节点失效,此节点上所有任务将被重新初始空闲状态,并被分配给其他Slave执行.
从功能上划分,NameNode、DataNode、文本数据集形成了系统的存储部件,JobTracker、文本挖掘算法库、TaskTracker形成了系统的计算部件.
3 Hadoop云平台的改进
在海量文本数据挖掘中,网络通信性能制约了系统性能的提高,网络宽带资源比较重要.在“计算迁移总是比数据迁移代价低”[12]的思想指导下,本文将计算节点和存储节点配置在一起,在任务调度时尽量在保存相应输入文件块的设备上分配并执行任务,这种方法使得大部分并行任务都在本地机器上读取输入数据,有效的减少网络数据流量,从而减少了节点间的通讯消耗.
在Hadoop云平台工作过程中,节点间的数据传输消耗大量时间,如果能减少数据传输次数,就有可能提高系统整体时间性能.在传统的Hadoop云平台中,需要将具有相同键值Key/Value对的中间数据传送到同一个Reduce节点归约.如果相同类型的键值Key/Value对较多,即这类中间结果较多的话,那么节点间就必定存在大量中间结果的传送,这势必消耗大量宽带资源,平台的时间性能也就交差.为此,我们对传统Hadoop云平台作如下修改:在Map阶段增加一个CombineProcess模块,对同一Map阶段中具有相同键值Key/Value对的中间结果做一个初步合并,并过滤掉一些无用的中间结果.改进后的Hadoop云平台海量文本数据挖掘系统工作流程如图2所示.

图2 改进的基于Hadoop云平台的文本挖掘整体架构图Fig.2 Improved overall architecture diagram of text mining based on hadoop cloud platform
由于CombineProcess模块位于Map阶段,只在本地机上执行,并不存在节点间的数据传输,因此,该模块耗时较少.而在文本挖掘中,相同键值Key/Value对的中间结果以及无用的中间结果较多,经过CombineProcess模块的初步合并和过滤,能够减少很多中间结果,相应地也就较多地减少了节点间的数据传输,此较少的消耗时间要比CombineProcess模块在本地机上执行初步合并和过滤所消耗的时间要多得多,因此,改进后的Hadoop云平台系统在整体上能够减少耗时,执行效率能够有所提升.
4 仿真实验
在实验中,我们的Hadoop云平台由9台计算机组成(其中1台为Master,另8台为Slave),操作系统均为CentOS-6.4 64 bit,配置均为八核IntelCorei 7处理器,4 GB内存,1 TB硬盘,Hadoop版本为1.1.2,Java版本为1.7.25,每个节点通过100Mb/s的局域网连接.实验数据集,从新华网(http://forum.xinhuanet.com/)下载2010—2013年间新闻材料,共10 000篇,包括财经、法律、娱乐、体育、计算机等10大类.这些实验数据集经预处理后 (忽略所有的报头)进行挖掘实验,采用改进前后的Hadoop云平台海量文本挖掘系统,主要进行了以下3组不同的对比实验(注:所有时间结果都四舍五入取整):
实验1处理10 000篇新闻材料,文件复制数分别设为1和3,BlockSize设为10 M,系统执行时间如表1所示.
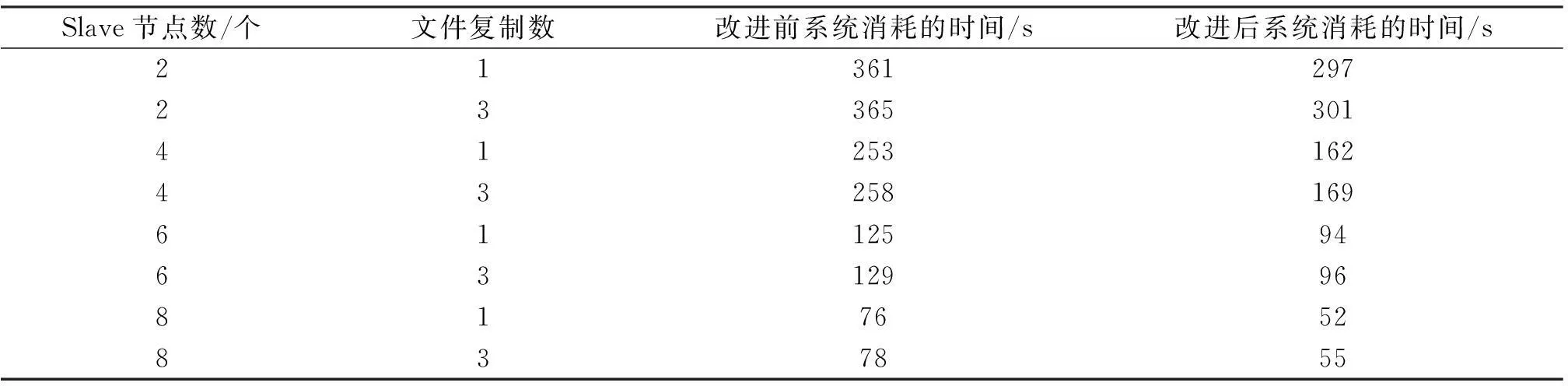
表1 实验1的执行时间对比结果
从表1可以看出:文件复制数的增多并没有提高整体挖掘的时间性能,同时,文件复制数增多,系统准备时间在一定程度上会增多.
实验2文件复制数设为1, Slave分别为2,4,6,8台,BlockSize设为10 M,处理10 000篇新闻材料,系统执行时间如表2所示.
实验1处理10 000篇新闻材料,文件复制数分别设为1和3,BlockSize设为10 M,系统执行时间如表1所示.
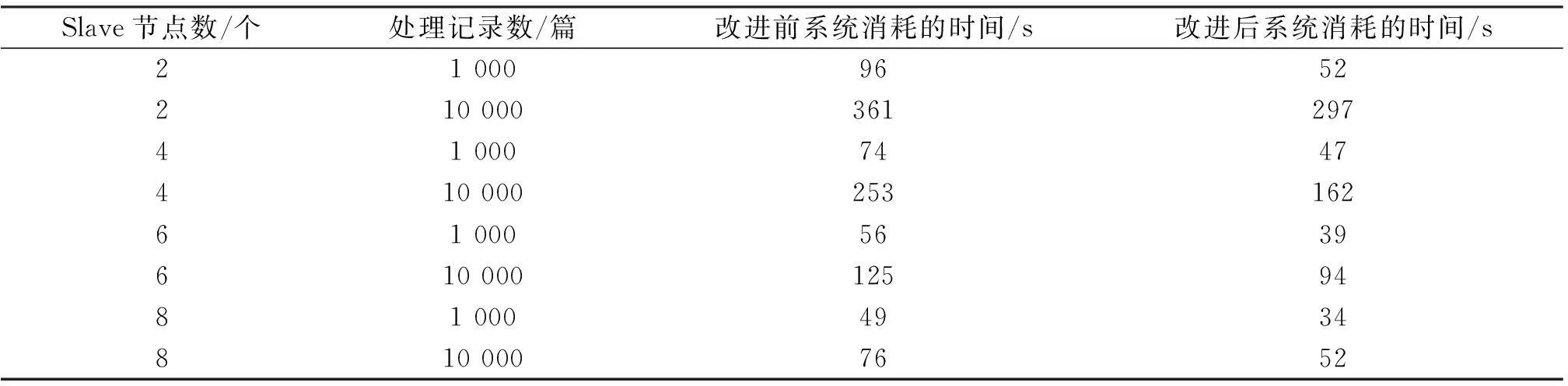
表2 实验2的执行时间结果
从表2可以看出:随着Slave数目的增多,系统整体时间性能有所增加,处理的数据量越大,系统表现得越优秀.
实验3处理10 000篇新闻材料,文件复制数设为1,Slave分别为2,4,6,8台, BlockSize分别为10 M,50 M或100 M,系统执行时间如表3所示.
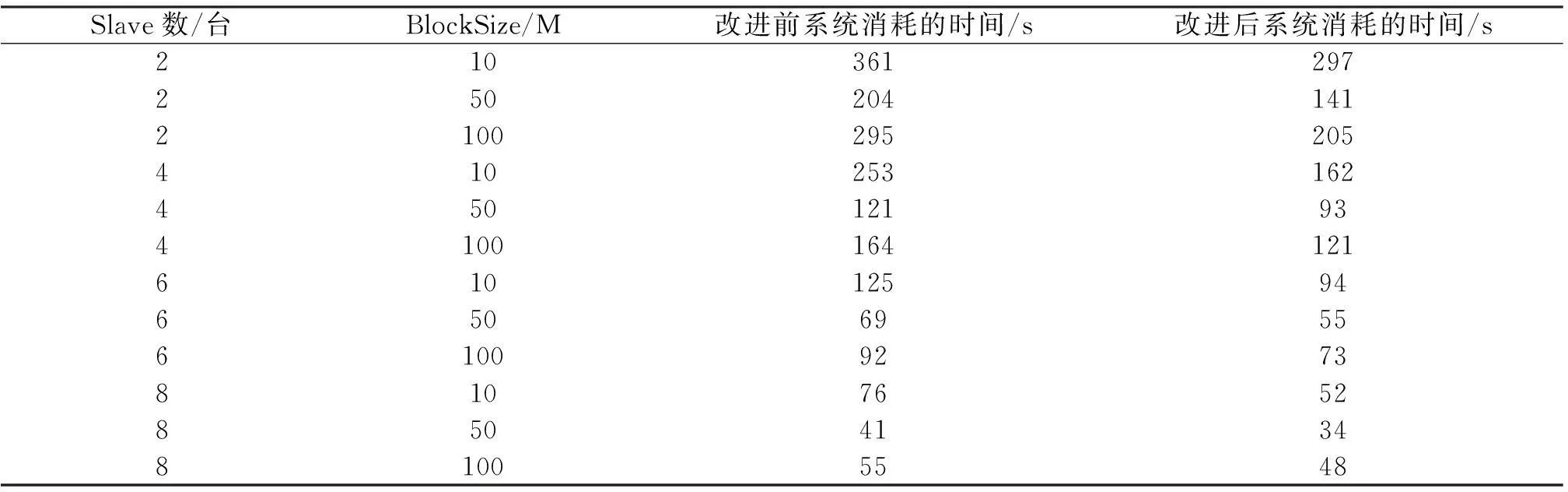
表3 实验3的执行时间结果
从表3可以看出:BlockSize分块大小对系统有很大影响.如果BlockBlockSize较小,那么Job数目增多,系统调度频繁,节点间通信开销大,性能降低;如果BlockBlockSize较大,虽节点间通信开销小,但是并行程度较低,节点内部计算时间较大.
从表1、表2和表3可以看出:在同样条件下,改进后的Hadoop云平台海量文本数据挖掘系统在时间消耗上都优于改进前的平台系统.这是因为改进后的平台系统能够借助CombineProcess模块来过滤掉一些无用的数据,且把计算节点和存储节点尽可能配置在一起,从而极大地减少了节点间的网络通讯,进而提高了系统的整体时间性能.
5 结束语
针对传统文本挖掘系统作用于海量文本数据时时间性能较低的问题,论文把Hadoop云平台引入其中并加以改进,在此基础上提出了一个基于改进Hadoop云平台的海量文本数据挖掘系统.以人民网上下载的10 000篇新闻材料作为实验数据集,分别进行了不同的3组对比实验,结果都显示改进后的平台系统在时间性能上有一定程度上的提高,这也表明了改进后的平台系统是有一定实用价值的.论文下一步的工作将是对平台系统改进前后的挖掘精度,以及应用于其他类型的海量数据,例如对海量植物叶片图像数据所涉及的关键技术做进一步研究.
[1]中国互联网络信息中心(CNNIC).第33次中国互联网络发展状况统计报告[R].北京:中国互联网络信息中心, 2014.
[2]王珊,王会举,覃雄派,等. 架构大数据:挑战、现状与展望[J].计算机学报, 2011,34(10):1741-1752.
[3]SEGALL R S, ZHANG Q Y. Web mining technologies for customer and marketing surveys [J].Int J Syst Cyber, 2009,38(6):925-949.
[4]THEUER H, LASS S. Engineering data management systeme/product data management systeme [J]. Productivity Manag, 2010,15(4):34-38.
[5]MARSTON S, LI Z, BANDYOPADHYAY S,etal. Cloud computing—the business perspective[J].Decision Supp Syst, 2011,51(1):176-189.
[6]ARMBRUST M, FOX A, GRIFFITH R,etal. A view of cloud computing[J]. Commun ACM, 2010,53(4):50-58.
[7]DEAN J, GHEMAWAT S. MapReduce: a flexible data processing tool[J]. Commun ACM, 2010,53(1):72-77.
[8]AFRATI F N, ULLMAN J D. Optimizing multiway joins in a map-reduce environment[J]. IEEE Trans Knowled Data Engi, 2011,23(9):1282-1298.
[9]覃雄派,王会举,杜小勇,等.大数据分析——RDBMS 与MapReduce 的竞争与共生[J].软件学报, 2012,23(1):32-45.
[10]李建江,崔健,王聃. MapReduce并行编程模型研究综述[J].电子学报, 2011,39(11):2635-2642.
[11]SRINIVASAN A, FARUQUIE T A, JOSHI S. Data and task parallelism in ILP using MapReduce [J]. Mach Lear, 2012,86(1):141-168.
[12]罗军舟,金嘉晖,宋爱波,等. 云计算:体系架构与关键技术[J].通信学报, 2011,32(7):13-21.
(编辑HWJ)
Mass Text Data Mining Based on Improved Hadoop Cloud Platform
CHEN Yan-long*, DUAN Hong-yu
(Department of Information Engineering, Henan University of Animal Husbandry and Economy, Zhengzhou 450011, China)
To overcome the problem of low time efficiency for commonly used text data mining system in the treatment of massive text data, an improved mass text data mining method was put forward based on the Hadoop cloud platform.This method firstly improved traditional Hadoop cloud framework to meet the needs of the massive text data mining, and then decomposed mass text data sets and mining task to multiple computers of the improved platform for parallel processing. By doing so, this method realizes the mass text data mining platform based on the improved Hadoop cloud platform. The effectiveness of this improved platform is verified by the mass experimental data set composed of 10 000 news materials.
text mining; Hadoop; cloud computing; text data;
10.7612/j.issn.1000-2537.2016.03.015
2015-09-21基金项目:河南省重大科技专项项目(121100111000)*通讯作者,E-mail:chenyanlong0330@163.com
TP301
A
1000-2537(2016)03-0084-05
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
机械工业标准化与质量(2022年6期)2022-08-12
大众投资指南(2021年35期)2021-02-16
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
当代陕西(2019年14期)2019-08-26
电力与能源(2017年6期)2017-05-14
中学数学杂志(初中版)(2016年5期)2016-11-01
信息通信技术(2015年6期)2015-12-26
中国卫生(2015年12期)2015-11-10
