
一种面向情报服务的交互式主题扩展方法
2016-08-15 01:27:41于福超卢廷钧王裴岩张桂平
沈阳航空航天大学学报 2016年2期
关键词:情报服务
于福超,卢廷钧,王裴岩,张桂平
(1.沈阳航空航天大学 人机智能研究中心,沈阳 110136; 2.中航工业昌河飞机工业(集团)有限责任公司 型号指挥部,江西 景德镇 333000)
一种面向情报服务的交互式主题扩展方法
于福超1,卢廷钧2,王裴岩1,张桂平1
(1.沈阳航空航天大学 人机智能研究中心,沈阳 110136; 2.中航工业昌河飞机工业(集团)有限责任公司 型号指挥部,江西 景德镇 333000)
摘要:情报服务中的主题扩展是指对客户的情报需求主题进行扩展,将扩展主题词作为原主题的补充和解释,是保证情报获取全面性的关键技术之一。面向情报服务中的主题扩展问题,提出了一种交互式扩展方法。该方法通过计算候选扩展词与相关词及不相关词间的相似度差异,利用相似度差异过滤候选扩展词,通过用户对推荐词的确认,更新相关词集和不相关词集。其中,相似度计算采用线性组合的方法融合了文档共现相似度与语义相似度。实验表明该方法具有较好的主题扩展效果。
关键词:情报服务;主题扩展;交互式方法;线性组合
在信息化快速发展的今天,情报服务[1]也不再局限于单纯以人力搜集情报为主的模式,如何将情报服务与互联网信息相结合,已经成为情报服务模式发展的转折点。海量信息为情报服务的发展带来便捷的同时,也使信息过载问题变得日趋严重,企业需要消耗大量的人力物力以获取自己所需要的信息。为辅助人工进行情报服务,降低其时间耗损,提高情报服务的准确性和全面性,主题扩展研究由此产生。 在面向情报服务的主题扩展中,将被扩展主题词的文档共现词[2-3]或语义相似词[4]作为扩展,以提高情报服务的信息准确度,这是常用的辅助扩展方法。但是这类辅助扩展方法的缺陷在于:没有利用用户对推荐词的确认反馈来改进推荐效果,不能够使推荐结果逐渐趋近用户需求。因此,本文提出用交互式扩展的方法以弥补上述辅助扩展方法的不足,该方法能够利用用户反馈,通过用户对被扩展主题词的相关词和不相关词的确认,不断更新相关词集和不相关词集。然后以此为基础,利用候选扩展词与相关词及不相关词间的相似度差异过滤候选扩展词。其中,相似度计算采用线性组合的方法融合了文档共现相似度与语义相似度,从而更加全面地对客户主题进行扩展,充分保证用户真正信息需求的获取。该方法对本文服务场景中的人工扩展流程进行了模拟,使其更加贴近本文的服务场景,从而提高人工情报服务的工作效率。
1 相关研究
主题扩展作为一种辅助人工扩展的技术手段,通常使用的方法有以下2种:(1)关键词匹配;(2)相似性计算。其中,基于关键字匹配[5]的搜索方式仅关注于返回包含关键字的文档,而忽略了对用户真正信息需求的识别与匹配。对于复杂信息的需求,返回的搜索结果中包含较多不符合用户需要的噪声文档,无法充分满足用户需要。
基于词语的相似度计算主要可分为基于语义词典的方法[6]和基于语料库的方法。前者通常根据人工构建的语义词典(如WordNet与知网等),以词语间的距离代表词语相似度。这种方法的缺点在于:一是构建WordNet这样的词典是一个浩大的语言工程,耗时耗力;二是词典构建后,对于新词和新义的增加问题,即维护该词典也需要很大的成本。
查询扩展是一种与主题扩展的思想类似的技术手段,是指将与查询用词关联程度高的词及词组加入原查询以生成新的查询,从而达到扩展优化的目的[7]。从用户参与角度看,查询扩展[8-9]可分为用户相关反馈[10]和伪相关反馈方法[11-12]。HF Wang[13]等研究中的实验表明,用户的参与和反馈对于查询精度有较好的改善。Kurland[14]等提出了一种迭代的伪反馈技术,取消用户交互的过程,只是重复性地进行查询词的扩展,直至达到满意的效果。这种反复迭代的方法容易加剧查询主题的漂移,虽然文中给出了解决此问题的方法,但同时也增加了算法的复杂度。
与查询扩展相比,主题扩展的方向性更强,对信息的准确度要求更高。查询扩展以信息查全为目的,常包含大量无关文档。主题扩展需要将噪声信息的数量降至最低,甚至没有噪声信息,即以信息准确为第一准则。
2 情报服务场景
根据客户所需信息类别的不同,本文服务场景中的情报服务大致分为技术、市场、专利、情报等4类。其中情报类服务主要是通过对客户的需求分析和总结,在对大量网络数据进行挖掘分析的基础上,为客户提供契合其需求的精准的信息服务,让企业实时掌握竞争企业的动态,便于企业做出更准确的决策。 例如:客户情报需求:东北各个行业的发展趋势。 东北已有行业大致包括“汽车”、“飞机”、“机器人”、“燃气轮机”、“位置服务”、“机械”等行业;发展趋势大致在4个方面得以体现,分别为“发展前景”、“全国资讯”、“国家政策”、“商务合作”。因此,可构成“汽车行业发展前景”、“汽车行业全国资讯”、“汽车行业国家政策”等多个客户主题。
以“汽车行业全国资讯”主题扩展为例,人工扩展为“tittle:(汽车)andtittle:(人民日报新华网)”,意为检索到的信息标题中需要同时包含“汽车”、“人民日报”或“汽车”、“新华网”。其中“汽车”、“人民日报”和“新华网”为主题词,主题由主题词描述。人工主题扩展的方法多依靠个人经验,而且基于现有数据和客户需求,很难准确地将客户的情报需求主题扩展完整,本文的主题扩展方法正是解决这个问题的关键方法。
本文情报类服务的主题词大致分为5类,分别为:日期、地名、机构名、机械设备名(机械部件名)和其他。其中日期、地名、机构名有较为固定的词集合可以参考,也可以参考百度、谷歌等搜索引擎的检索信息。经过对人工主题扩展模式和特点的总结发现:机械设备名(机械部件名)通常不予以扩展,原因在于这类主题词专业性强,对其扩展容易造成对客户需求的偏差,比如“沥青混合料搅拌设备、伺服电机”等。其他类主题词不仅所占数量比例大,而且是人工扩展的难点所在,这类主题词其实是由若干相同或者不同词性的词组合在一起,例如:“市场(名词)+营销(动词)”、“飞机(名词)+容量(名词)”等,该类主题词是本文主题扩展方法的主要应用对象。
3 交互式扩展的实现
本文提出的交互式扩展方法从文档共现词和语义相似词2个角度,分别构建主题扩展方法,并对2种扩展方法的候选扩展词进行线性加权。然后通过用户对推荐词的确认反馈,更新相关词集和不相关词集,并计算候选扩展词与相关词及不相关词间的相似度差异,利用相似度差异过滤候选扩展词。
3.1基于文档共现的主题扩展方法
通常在相同文档中共现的词具有较高的相关性。在主题扩展时,可将与被扩展主题词经常共现的词加入到被扩展主题中。 首先采用TF-IDF[15]方法计算词在各个文档中的权重,以此为基础构成词的向量表示,其形式如下:
w=[TF-IDFd1,TF-IDFd2,TF-IDFd3,…,TF-IDFdn]
然后利用余弦公式计算向量间的相似度,两向量间的相似度反映两词在文档集中的分布的相似性,选择与被扩展主题词较大的词推荐给用户,进而实现基于文档共现的主题扩展方法。TF-IDF计算公式如式(1)所示:
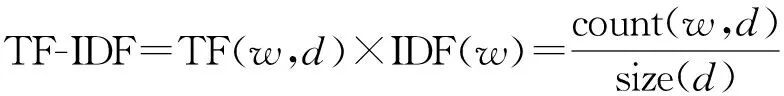
(1)
其中TF(Term Frequency)为词w在文档d中的频率,即词w在文档d中出现频次count(w,d)和文档d中总词数size(d)的比值。IDF(Inverse Document Frequency)为词w在整个文档集合中的逆向文档频率,即文档总数n与词w所出现文档数docs(w,D)加1的比值的对数,分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。
3.2基于语义相似的主题扩展方法
与被扩展主题词语义相似的词是扩展主题的另一有效途径。语义相似的词表现为在相同或相近上下文环境内可替换的词[16],文献[17]提出Word Embedding是基于词上下文环境将词进行向量表达的一种方法,以Word Embedding间的相似度能够表示词间的语义相似度。 本文利用Mikolov T[18]等人提出的Skip-gram模型训练Word Embedding,采用余弦公式找到与被扩展主题词语义相似的词,然后选择相似度较大的词推荐给用户,从而实现基于语义相似的主题扩展方法,Skip-gram是在已知词的前提下,求其上下文的概率。其模型的示意图如图1所示:
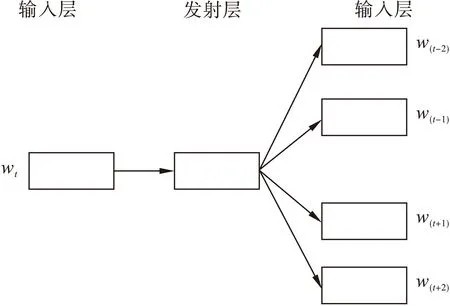
图1 Skip-gram模型
Skip-gram模型的训练目标就是使下式的值最大,如式(2)所示:
(2)
其中,c是窗口的大小,T是文档集大小,Skip-gram 模型计算的条件概率如式(3)所示:
(3)
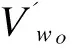
3.3两种主题扩展方法的融合
从文档共现和语义相似的两个角度分析,两种扩展方法的候选扩展词具有一定的互补性。如表1所示,客户的情报需求是“东北各个行业的发展趋势”,客户没有对行业的类别和方向做出明确要求。以被扩展主题词“发展前景”为例:基于文档共现的主题扩展方法可以基于现有数据,辅助人工获得被扩展主题词的文档共现词,如“气动工具”、“五金”、“塑料管道”等行业名称,提高人工扩展的效率和全面性;基于语义相似的主题扩展方法可以得到“市场前景”、“市场趋势”、“发展潜力”等被扩展主题词的语义相似词,辅助人工扩展得到更多契合客户需求的相关文档,提高情报服务的准确性。
这两种扩展方法是从不同却又互补的两个角度去提高人工扩展的效率以及全面性和准确性。 因此,采用线性加权的方法融合上述两种主题扩展方法,实现从文档共现相似性与语义相似性两个方面对被扩展主题词进行扩展,以期得到更全面的推荐结果。

表1 基于文档共现、语义相似的主题扩展方法的候选扩展词示例
线性加权是指把两种扩展方法得到的被扩展主题词w和候选扩展词的相似度进行线性融合,进而得到w与w′的融合相似度Sim(w,w),然后选取Sim(w,w)较大的候选扩展词推荐给用户,Sim(w,w′)的计算方法如式(4)所示:
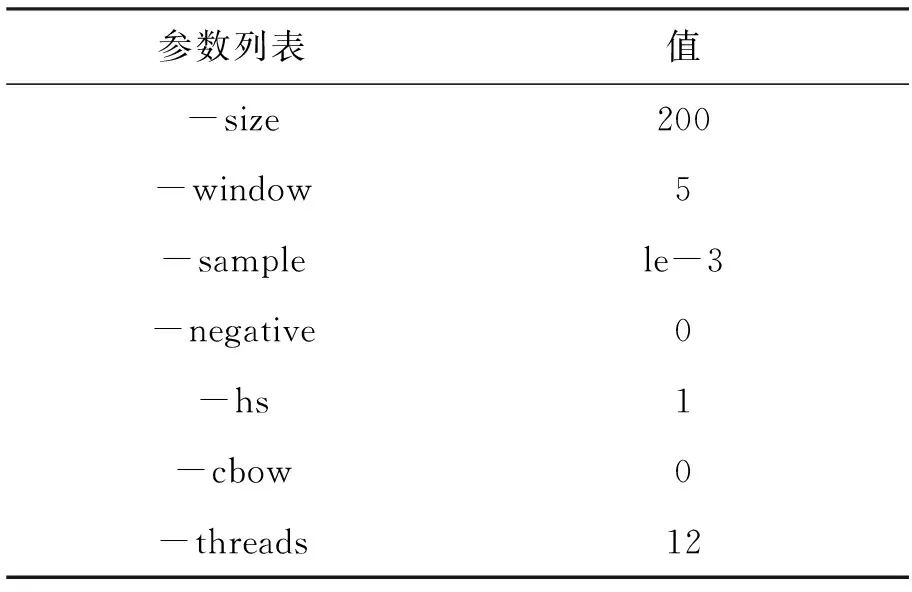
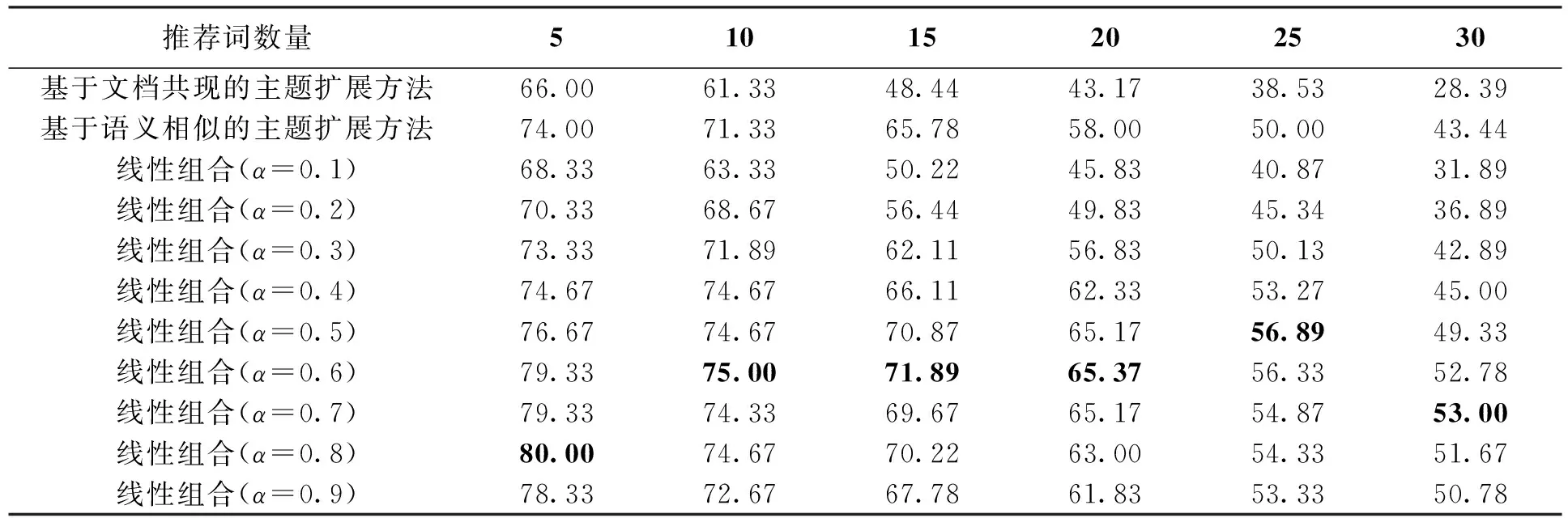
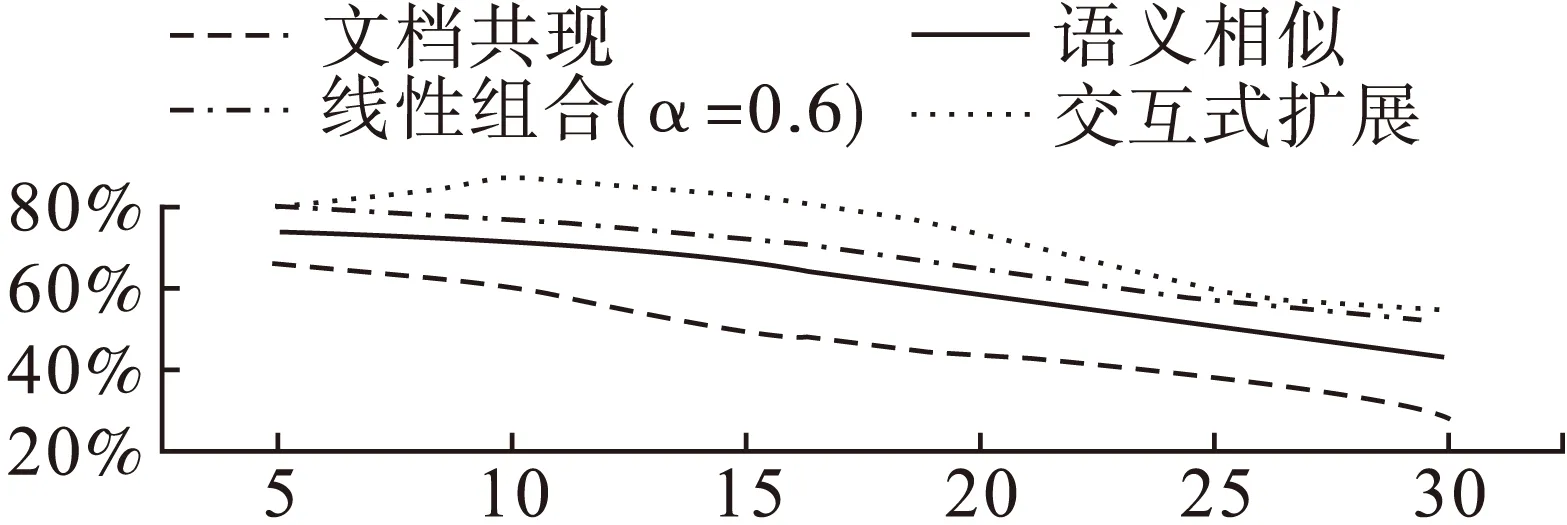
Sim(w,w′)=(1-a)*Simk1(w,w′)+a*Simk2(w,w′),0 (4) 其中,Simk1是从文档共现的角度,利用TF-IDF方法构造w和的向量表示,然后采用余弦公式得到的w和w′间的文档共现相似度;Simk2是从语义相似的角度,通过利用Skip-gram模型训练得到w和w′的Word Embedding,然后同样采用余弦公式得到的w和w′间的语义相似度。 3.4交互式主题扩展方法 为了能够对推荐词的用户反馈进行处理,并在此基础上进行再次推荐,本文提出一种交互式主题扩展方法。该方法通过用户对推荐词的确认反馈,更新相关词集和不相关词集。在此基础上利用相似度差异Score(w)过滤候选扩展词,然后推荐给用户。Score(w′)的值越大代表该候选扩展词与客户需求越契合,Score(w′)的计算方法如式(5)所示: Score(w′)= (5) 其中,w是被扩展主题词,w′是候选扩展词,Sim(w,w′)是w与w′的融合相似度,T1和T2分别是相关词集和不相关词集。具体描述如下: 初始化: 相关词集T1={w}; 不相关词集T2=ø; 词集W={w1,w2,…,wm};Step1:基于公式(4)给用户推荐n个候选扩展词C={w1,w2,…,wn};Step2:用户对C进行确认,基于用户反馈更新T1与T2;Step3:对于W中的每个词,基于公式(5),计算Score值;Step4:选取Score较大的前n个候选扩展词C={w1,w2,…,wn}推荐给用户;Step5:返回Step2; 4.1实验数据及预处理 本文数据采用从网络抓取的新闻信息,每条数据包括标题、内容、时间、发布者、网址等。主题扩展研究主要针对4 000万条新闻标题,其包括时政、科教、经济、社会、军事等多个类别。预处理主要是将4 000万条新闻标题进行分词、去停用词、去低频高频词等操作,得到大小为248 355的词表。Word2vec是一款利用Skip-gram模型将词转化为词向量的高效工具,本文采用该工具生成每个词的Word Embedding。Word2vec所设定的对应参数如表2所示: 4.2评价方法 根据客户主题的种类与领域,选取了具有代表性的100个客户情报需求主题,并为每个客户情报需求主题的主题词推荐30个候选扩展词。由于本文服务场景的限制,首先分别将基于文档共现和语义相似两种扩展方法得的候选扩展词推荐给用户,由用户确认相关词和不相关词,然后将其作为评价线性组合、交互式扩展2种方法的实验效果的依据。本文以推荐词的利用率来判断评价主题扩展方法的实用效果,公式如式(6)所示: 利用率=相关词数/推荐词数 (6) 利用率高代表该扩展方法实用效果好,适合本文的情报服务场景。 表2 Word2vec参数设定 表3是用户对基于语义相似的主题扩展方法为被扩展主题词“发展前景”所提供的候选扩展词的相关性确认的示例。 表3 基于语义相似的主题扩展方法的候选扩展词示例 4.3实验分析 下表是基于文档共现、语义相似及线性组合3种扩展方法针对不同推荐词数量时的候选扩展词的平均利用率,其中线性组合的参数α取值是从0到1以步长0.1进行变化,如表4所示: 表4 基于文档共现、语义相似及线性组合3种扩展方法的平均利用率对比 % 表4显示,当推荐词数量为5、10、15、20、25、30时,线性组合扩展方法在参数α分别为0.8、0.6、0.6、0.6、0.5、0.7取得其平均利用率最高值,分别是:80.00%、75.00%、71.89%、65.37%、56.89%、53.00%,比基于文档共现和语义相似2种扩展方法的平均利用率要高。利用T检验方法对基于文档共现、语义相似及线性组合3种扩展方法进行差异显著性检测,发现线性组合方法与其余2种方法的显著性检测值均小于0.05,存在显著性差异。 从表4可以看出,当线性组合的参数α=0.6时,分别在推荐词数量为10、15、20时取得其平均利用率最高值。在推荐词数量为5、25、30时,线性组合的平均利用率最高值与α为0.6的平均利用率的差值不超过1%。当推荐词数量为5、10、15、20、25、30时,利用T检验方法对α=0.6与线性组合的平均利用率最高值进行差异显著性检测,发现不存在显著性差异,所以综合考虑,本文选择线性组合权重α=0.6。 表5 线性组合、交互式扩展平均利用率对比 % 交互式扩展每次推荐5个候选扩展词,连续推荐6次。从表5可以看出,在推荐词数量为10、15、20的时候,交互式扩展的平均利用率相对于线性组合方法都有7%以上的显著提高,在推荐词数量为25、30的时候,其平均利用率的提高也在2%左右,没有显著提高,这是因为与被扩展主题词相关的词已经基本全部被涵盖。这也说明,交互式方法能够在较少的推荐次数下,获得更多的与被扩展主题词相关的词。由此可以看出在每次推荐词数量为5的情况下,相比于线性组合方法,交互式主题扩展方法利用用户对推荐词的确认反馈信息,得到更好的推荐效果。 图2 平均利用率对比 图2显示出,在推荐词数量分别为10、15、20、25、30时,交互式主题扩展方法推荐的候选扩展词的平均利用率均高于基于文档共现、语义相似及线性组合3种扩展方法,并且在推荐词数量为10、15、20的时候,实验结果有明显提高。 本文提出了一种交互式的主题扩展方法。首先从文档共现和语义相似2个角度,分别构建了主题扩展方法,利用线性组合的方法融合2种扩展方法得到被扩展主题词与候选扩展词间的相似度。然后在此基础上利用用户对候选扩展词的确认反馈,更新相关词和不相关词的集合,并利用相似度差异过滤候选扩展词,交互式为用户进行推荐,实验表明该方法具有较好的应用效果。在本文的工作中并没有考虑相关词集与不相关词集中每个词的各自权重,在未来工作中,考虑引入词的权重,使在计算Score值时,不同的词起到的作用不同。 参考文献(References): [1]许真玉,王文佳,杨晓玉.企业竞争情报研究与图书馆情报服务[J].现代情报,2006,26(11):185-186. [2]Morita K,Atlam E S,Fuketra M,et al.Word classification and hierarchy using co-occurrence word information[J].Information Processing & Management,2004,40(6):957-972. [3]唐守忠,齐建东.一种结合关键词与共现词对的向量空间模型[J].计算机工程与科学,2014,36(5):971-976. [4]吴健,吴朝晖,李莹,等.基于本体论和词汇语义相似度的Web服务发现[J].计算机学报,2005,28(4):595-602. [5]胡昊,王君伟,常橙,等.XML数据上支持查询扩展的关键词检索系统[J].计算机研究与发展,2013,50(S1):421-425. [6]江敏,肖诗斌,王弘蔚,等.一种改进的基于《知网》的词语语义相似度计算[J].中文信息学报,2008,22(5):84-89. [7]崔航,文继荣,李敏强.基于用户日志的查询扩展统计模型[J].软件学报,2003(9):1593-1599. [8]Huang M,Yan X,Zhang S,et al.Review and perspective of query expansion techniques[J].Computer Applications & Software,2007. [9]Chirita P A,Firan C S,Nejdl W.Personalized query expansion for the web.[J].Proceedings of Sigir’,2007:7-14. [10]Biao L,Jiabei Z,Ming Y,et al.3D object retrieval with multitopic model combining relevance feedback and LDA model.[J].IEEE Transactions on Image Processing,2015,24(1):94-105. [11]黄名选,严小卫,张师超.基于矩阵加权关联规则挖掘的伪相关反馈查询扩展[J].软件学报,2009,20(7):1854-1865. [12]Cao G,Nie J Y,Gao J,et al.Selecting good expansion terms for pseudo-relevance feedback.[C].Sigir 08 International Acm Sigir Conference on Research & Developm.ACM,2008:243-250. [13]Wang H F,Lee K F,Yang Q.Search engine with natural language-based robust parsing for user query and relevance feedback learning:US,US6766320[P],2004. [14]Kurland O,Lee L,Domshlak C.Better than the real thing? Iterative pseudo-query processing using cluster-based language models[J].Acm Sigir Forum,2005:19-26. [15]黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864. [16]Lebret R,Collobert R.Rehabilitation of count-based models for word vector representations[M].Computational Linguistics and Intelligent Text Processing.Springer International Publishing,2015:417-429. [17]Lebret R,Collobert R.Word Embeddings through Hellinger PCA[C].Conference of the European Chapter of the Association for Computational Linguistics.Idiap,2013. [18]Mikolov T,Chen K,Corrado G,et al.Efficient estimation of word representations in vector space[J].arXiv preprint arXiv:1301.3781,2013. (责任编辑:刘划英文审校:王云雁) 收稿日期:2016-01-28 基金项目:国防基础科研项目资助(项目编号:A0520131003);辽宁省高校创新团队支持计划(项目编号:LT2014005) 作者简介:于福超(1990-),男,辽宁大连人,硕士研究生,主要研究方向:知识管理与人机智能交互,E-mail:94330101@163.com;张桂平(1962-),女,辽宁本溪人,教授,博士,主要研究方向:机器翻译、知识管理等,E-mail:zgp@ge-soft.com。 文章编号:2095-1248(2016)02-0059-06 中图分类号:TP391.3 文献标志码:A doi:10.3969/j.issn.2095-1248.2016.02.011 An interactive topic expansion technology for intelligence service YU Fu-chao1,LU Ting-jun2,WANG Pei-yan1,ZHANG Gui-ping1 (1.Human-Computer Intelligence Research Center,Shenyang Aerospace University,Shenyang 110136,China ;2.Type Command Department,AVIC Changhe Aircraft Industry(Group)Company Limited,Jingdezhen 333000,China) Abstract:The topic expansion of intelligence service is to expand the customer’s intelligence needs with the expanded topic words as a supplement and explanation of the original topic,which is one of the key technologies to ensure the comprehensive intelligence acquisition.In this paper,we propose an interactive expansion method for the topic expansion problem in intelligence service.The method computes the divergence between the similarity of candidate words with the related words and the unrelated words,filters the candidate words by the similarity divergence,and updates related words set and unrelated words set with the user’s confirmation on recommendation words.Among them,linear combination combines the document co-occurrence similarity and semantic similarity.Experiments show that the proposed method has a good effect on the topic expansion. Key words:intelligence service;topic expansion;interactive method;linear combination
4 实验设计及评价


5 结束
猜你喜欢
中国安全生产科学技术(2022年9期)2022-10-17 01:04:08
情报杂志(2022年2期)2022-03-07 08:00:54
图书馆理论与实践(2020年5期)2021-01-05 06:27:48
海峡科技与产业(2019年4期)2019-11-28 14:31:32
长江丛刊(2019年9期)2019-11-20 03:10:24
长江丛刊(2017年26期)2017-11-25 09:08:42
新西部·中旬刊(2017年1期)2017-05-19 07:36:49
罕少疾病杂志(2016年6期)2016-03-11 16:34:48
创新科技(2015年8期)2015-12-24 06:23:56
天津科技(2015年8期)2015-06-27 06:33:38
