
基于情感词典与机器学习的旅游网络评价情感分析研究*
2016-08-11 07:04:08王新宇
计算机与数字工程 2016年4期
王新宇
(南京旅游职业学院 南京 211100)
基于情感词典与机器学习的旅游网络评价情感分析研究*
王新宇
(南京旅游职业学院南京211100)
摘要针对旅游网络评价使用的旅游情感词汇量不多的特点,提出一种基于旅游情感词典和机器学习相结合的方法,用于旅游网络点评的情感倾向性分析研究。采用向量空间模型表示旅游评价文本,使用旅游情感词典对特征空间进行降维,采用TF-IDF特征权重法计算权重,利用SVM机器学习模型对评价进行分类,实验结果表明,该方法能够有效地进行旅游网络评价分类。
关键词机器学习; 情感词典; 情感分析
Class NumberTP391.1
1 引言
随着互联网的普及和不断发展,互联网日益成为企业和个人检索信息和发布信息的主要渠道,一条网络评论产生的影响不容忽视,特别是对某种产品的舆情评价信息,对购物者的导向作用愈来愈重要,当购物者通过电商网站选购商品,一般先浏览该商品的评价,特别注重负面评价,如果有少量负面评价,购物者往往会犹豫,如果负面评价过多,购物者一定会放弃在该网站购物。旅游产品作为一种特殊的商品,它完全要通过游客的身临其境的体验,才能完成产品的消费,潜在的顾客对旅游产品的网络评价特别注重,由于网络评论的时效性强,对于意见类诉求若不及时响应,往往对企业形象造成负面影响。所以在旅游领域,旅游电商企业、旅行社、酒店等十分重视旅游网络评价的主动引导,例如:同程旅游网已经具有处理游客评价的能力,游客在酒店住宿或在景区游玩后,除了进行一段点评,还可以选择对旅游企业的服务进行“好评”、“中评”和“差评”的归类评价,从表面上看,通过这种简单分类的办法,顾客对旅游企业的服务评价一目了然,简单直观,非常实用,但实际上,这种方法往往达不到期望的效果,这是因为一些游客出于某种原因不得不选择了好评,但点评文字表达中却又出现牢骚满腹的文字,表现出了不满情绪,可见,实际上这些顾客还是对旅游企业的服务是不满意的。如果仅仅使用简单套用表面上“好评”分类,不去分析顾客的点评文字,势必会影响结果,对客人的不满和投诉的解决也起不到作用。因此,需要一种更为有效的方法,直接对每一条顾客对服务的点评进行分析,从点评中挖掘顾客实际的评价情感倾向,帮助旅游企业发现旅游线路设计、景区服务管理、酒店客房管理中存在的不足,及时采取相应的补救措施,从而可以提高顾客忠诚度,产生更大的经济效益。
2 相关研究
情感分析(亦称评论挖掘),通常是指对一段带有主观性情感的文本进行分析的过程。情感分析有很强的实用价值,例如,通过对某酒店服务评论的情感分析,可以发现顾客对该酒店软硬件设施和服务的褒贬态度和意见,从而改进设施并改善服务,赢得竞争优势;通过对游客对某条旅游线路的评论情感分析,旅行社可以了解游客对该线路的态度倾向分布,从而优化路线,提高服务品质,从竞争中脱颖而出。通过情感分析技术,可以帮助企业从互联网上海量的产品评论中获取对产品综合、全面的评价信息。因此,许多企业都对应用情感分析技术分析客人的网络评价,有着迫切的需要,许多专家学者也对此开展了研究工作[1~5]。目前网络评价情感分析的研究工作主要着重于理论研究或微博的评论的情感分析,但重点对旅游网络评价,进行情感分析的文献和研究工作很少。因此,如何从旅游网络评价中获取游客的情感倾向,并更好地服务于游客,是一个非常有实用价值的研究方向。
目前研究文本情感倾向,主要使用两种方法,分别是:基于机器学习的方法和基于语义的方法。基于机器学习的方法是利用分类技术来处理文本,分类技术一般是使用某种学习算法来确定分类模型,该模型不但很好地拟合输入数据中的类标号与属性集之间的关系,还能够正确地预测未知样本的类标号中类标号,我们需要为它提供一个人工标注的训练集,通过上述的学习算法,训练并建立分类模型,然后可以将这个模型运用于检验集,从而检验类标号未知情感文本记录。唐慧丰等以中心向量法、KNN和支持向量机作为分类算法,分别进行了分类实验,实验表明,采用支持向量机进行情感分类,可以取得较好的效果[6]。徐军等将朴素贝叶斯和最大熵方法应用于新闻文本的情感分类,取得不错的分类性能,最高准确率能达到90%[7]。基于语义的方法,一般是先获得情感倾向词,把表示情感的词语划分成正面词语和负面词语,同时构造一个专用的情感词典,然后利用这个词典,使用线性代数和统计分析的方法,来统计文本中的正面和负面情感词语的相对数量,从而确定文本的情感倾向。罗景等将概率潜在语义模型用于中文信息检索,并通过实验证明,该模型能够明显地提高中文信息检索的精度[8];宋晓雷等利用概率潜在语义分析,给出了两种用于判别词汇情感倾向的方法,这两种方法可以在没有外部资源的条件下,实现词汇情感倾向的判别[9]。
从上述研究可以看出,这两种方法各有长处和不足,本文提出了一种基于词典和机器学习相结合的方法,并将这个方法应用于旅游网络评价的情感分析研究。
3 基于机器学习分类的方法
机器学习作为人类智力的延伸,作为人工智能的重要研究方向之一,它试图从模拟人类的学习能力出发,运用一些最基本的统计方法,去探索客观世界,获得各种知识和技能,在计算机技术的帮助下建立相关的学习模型,最终可以让计算机系统获得某些学习能力。
常用的机器学习分类法有:最大熵、朴素贝叶斯文本算法、支持向量机模型。
支持向量机(Support Vector Machine,SVM)是由Vapnik于1995年根据统计学习理论,提出的一种新的机器学习方法,它以结构风险化最小原则为基础,其主要思想是建立一个分类超平面作为决策曲面,使得正例和反例之间的隔离边缘最大化。它在许多诸如车牌识别、文本分类等实际应用中体现了其大有可为之处。另外,支持向量机还有一个特点,就是可以很好地应用于高维数据,避免了“维数灾难”问题。Pang等利用支持向量机、朴素贝叶斯、最大熵这三种机器学习方法,对观众的电影评论进行了情感分类,根据他们的研究,这三种机器学习方法均优于纯人工分类,并且发现支持向量机比其它两种机器学习方法更好。
4 数据的采集和预处理
4.1旅游点评数据采集
通过使用一个自行编写的评价提取工具(C#开发)从同程旅游网上抓取了部分景区的旅游点评,为了使数据更有广泛性,抓取的景区数据共有15个景区,其中:北方景区5个,南方景区7个,华东景区3个,共计提取4500条点评信息存入数据库(采用SQL Server express版)。
每个景区介绍页面中包含的标签和内容非常多,大部分信息是与游客点评无关的,程序需要仔细分析页面,从大量的“噪声”信息中找到游客的评价内容,我使用正则表达式可以轻松、高效、准确地获取到游客对景区的点评信息,并将其存储于数据库中。
以下代码简单描述了如何提取某景区的点评,并保存至数据库中。
void test(string str,string jqn){
string pstr = "〈DIV class=dpwords〉(?〈title〉.*?)〈/DIV〉";
string temp = "",sql = "";
MatchCollection mc = Regex.Matches(str,pstr);
int count = mc.Count;
int i=0;
string dpstr = "";
SqlConnection conn = dbbaseop.SqlCon();
SqlCommand cmd;
conn.Open();
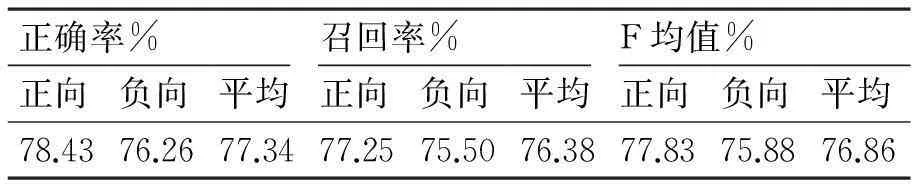
while(i temp = mc[i].Groups["title"].Value; dpstr = temp.Replace("'", ""); sql = "insert into tb_dpinfo values('"+jdn+"','" + dpstr+ "')"; cmd = new SqlCommand(sql, conn); cmd.ExecuteNonQuery(); i++; cmd.Dispose(); } conn.Dispose(); } 4.2分词系统 将游客对景区的评价信息从网页中提取出来以后,需要对评论内容进行预处理,第一步需要进行中文分词,将由汉字序列组成的评价语句,通过一定的方法分割成若干个有着单独意义的汉语词条,这一步比较关键,同时这也是中文文本挖掘的重点和难点。分词方法一般有3种方法:机械匹配的方法、最大概率的方法、语义理解的方法。机械匹配的方法是最常用的方法,在借助一个词典的帮助下,它主要利用正向或者反向最大匹配的原则来分词,清华大学CSEG系统就是这种方法实现的。最大概率是根据一个事先建立的常用词语的概率表,依据这张概率表,对汉字字符串可能存在的多种分词结果进行统计分析,将其中概率最大的那个结果,作为该汉字字符串的分词结果,代表系统有中科院计算所ICTCLAS系统;基于语义理解的方法,这种方法可以实现新词识别功能,亦称为人工智能分词方法,山西大学ABWS系统是其代表。 为了减少工作量,提高实验精度和效率,本文采用中国科学院计算技术研究所研制的汉语词法分析系统(ICTCLAS),该系统对非商业用途完全免费,除了提供一个简易的使用界面外,还提供了相关编程接口,可以使用C/C++、C#、Java等语言调用系统提供的函数,进行二次开发,将分词功能直接嵌入到自行开发的软件中,接口调用方法非常方便。我们利用ICTCLAS提供的接口,使用C#编程,实现了对旅游评价信息的分词,以下代码简单演示如何调用接口函数,获取分词字符串。 private string fc(string str){//str为待分词中文字符串 CFc.NLPIR_Init("", 0, "");//初始化接口 //调用接口函数,切分参数str传递的字符串,并将结果保存为IntPtr类型 IntPtrintPtr = CFc.NLPIR_ParagraphProcess(str, 1); //将切分结果转换为字符串 stringrstr = Marshal.PtrToStringAnsi(intPtr); CFc.NLPIR_Exit();//退出接口 returnrstr; } 输入字符串:“扬州瘦西湖,一直是闻其名,果然是美景怡人,门票稍贵了点,不过也算值得,在湖上荡舟,别有风味。就是四月的扬州人太多了些。” 得到分词后的结果:“扬州/ns 瘦西湖/ns ,/wd 一直/d 是/vshi 闻/v 其/rz 名/ng ,/wd 果然/d 是/vshi 美景/n 怡/vg 人/n ,/wd 门票/n 稍/d 贵/a 了/ule 点/qt ,/wd 不过/c 也/d 算/v 值得/v ,/wd 在/p 湖/n 上/f 荡/v 舟/n ,/wd 别有风味/vl 。/wj 就/d 是/vshi 四月/t 的/ude1 扬州/ns 人/n 太/d 多/a 了/ule 些/q 。/wj”。 4.3旅游情感词典的建立 基于词典的旅游情感分析,需要建立一个旅游情感词典。目前中文文本的情感分析处于研究阶段,已经有少量通用情感词典库可以利用,但由于很少有旅游情感分析的研究,所以目前尚没有专门的旅游情感词典库。我们通过以下方法来完成旅游情感词典的构建: 1) 以大连理工大学信息检索研究室整理和标注的一个中文感情词典资源库为本体库,该词典将情感共分为7大类21小类,每个词在每一类情感下都对应了“中性”、“褒义”、“贬义”、“褒贬两性”4种极性中的1种,并列出了每个词汇的词性种类、情感分类和情感强度[10],设该词典为集合D。 2) 利用分词系统提供的编程接口,编写了相关程序,对4.1节中的点评信息进行分词处理,将得到的词汇集合PW。将D与PW进行交集操作,可以得到旅游情感词典ED,可表示为ED=D∩PW。根据以上步骤编制程序,可以得到一个包含1989个情感词汇的旅游情感词汇词典。表1为最终得到的旅游情感词汇示例。 表1 网络点评常用旅游情感词汇示例 4.4文本表示 因为现代计算机无法智能地识别人类的自然语言,也无法直接处理文本这类非结构化数据,所以经过预处理的文本数据需要转化成某种结构化的形式,才能让计算机“读懂”,进而可以进行识别和处理,这个转化过程就是文本形式化表示。单字、词组、短语等都是常用的文本形式,常见的文本的形式表示模型有布尔模型、概率模型和向量空间模型(Vector Space Model,VSM)。其中,向量空间模型的文本表示效果较好,也是经常使用的一种文本表示方法,向量空间模型可以描述为,给定集合T{t1,t2,…,tn}是文本中出现的m个特征,设wi表示第i个特征在文本D中的权重,可以把D表示为D={t1,w1;t2,w2;…,tn,wn}。其中,权重可以通过使用布尔权重法、词频权重法或TFIDF权重法来计算。 4.5特征选取 游客的旅游点评文本转化为向量空间模型后,可以得到一个稀疏矩阵,通常是一个高维的空间,在机器学习的过程中,过高的特征空间维度,有造成“维数灾难”的可能。虽然理论和实践证明了采用支持向量机可以很好地应用于高维数据,避免了“维数灾难”问题,但如果考虑算法的时间复杂度,最好还是把特征的个数控制在一个合理的范围内。这就要求采用某种特征选择算法对特征空间进行筛选,从而达到降低维数的目的。已经研究出多种方法可以进行特征选择,最常用的两种方法是:文档频率(DF)和卡方(CHI)统计。文档频率是一种简单的,但有较好性能的特征选择方法,该方法通过将文档频率设置在某个范围来进行特征的选取。卡方统计是通过分析特征和类别之间的依赖程度来进行特征的选取。 此外,还可以结合情感词典进行特征选择,建立一个情感词汇数量不多的情感词典,然后直接通过使用该情感词典作为特征选择的依据,在这种情况下,可以认为使用情感词典也是一种有效的降维方法,一些文献对这种方法进行了实验,证明这种方法是有效和可行的[11,12]。根据刘志明[12]的研究,当权重采用TF-IDF法时,在特征数为2000时,SVM的性能可以达到最优。4.3节中建立的旅游情感词典的词汇数量接近2000,所以本文把该旅游情感词典中所有的词汇均作为特征。 4.6特征加权 对于4.4节中的文本空间,其中的每个特征的重要性是不同的,需要对文本特征进行加权操作,这一步对于分类结果有着相当重要的作用。特征加权的过程,就是根据每个特征对分类结果的贡献大小,赋予不同权值的过程。经常使用的特征加权方法有:布尔权重法,词频权重法和TF-IDF权重法。 TF-IDF被是被广泛使用的特征权重计算方法,其主要思想是,对文档分类最有作用的特征词,应该是那些在一篇文档中出现频率高,而在其他文档中很少出现的词。其计算公式可表示如下: 其中,tf(i,j)为特征项ti在文本dj中出现的次数,ni为包含ti特征的文本数量,N为总文档数。 周杰通过实验证明,对于评论语句很短的语料,在进行情感倾向分析时,使用TF-IDF权重计算方法,可以获得较优准确率[13],所以本文使用TF-IDF权重法,利用C#语言编制相应的计算程序。 5.1实验数据及环境 实验数据使用的语料库为4.1节中建立的数据库,从中挑选了5个景区的1800点评信息为语料,人工对这些点评的情感倾向进行了标注。语料选择情况如表2所示。 表2 语料选择情况统计 实验环境为Visual Studio 2008、SQL Server 2005,实现SVM机器学习模型使用的是林智仁开发的LIBSVM工具箱。特征词选用了4.3节中建立的旅游情感词典中的全部1989个情感词汇,使用TF-IDF进行权重计算。 5.2评价指标 本次实验使用了正确率(precision)、召回率(recall)、F均值作用评价指标,来检验实验效果。 令Drighti为被正确的划分到Ci类别中的评价文本数量,Dwrongi为被误划分到Ci类别中的评价文本数量,为Ci类别中实际的评价文本数量。则: 5.3实验结果及分析 实验结果如表3所示。 表3 实验结果 研究表明,基于SVM模型的情感分类实验,其正确率可以高80%左右[12],从实验结果看,本文所设计的以旅游感情词典作为特征,采用TF-IDF进行特征权重计算,利用SVM机器学习模型进行情感倾向分类的方法,虽然正确率没有达到很高的值,但本方法算法简单,效率较高,容易实现,三大指标的数值还是较为满意的。 针对旅游点评内容很短、使用的旅游情感词汇数量不多、用语口语化等特点,本文提出一种基于旅游情感词典和机器学习相结合的方法,用于旅游网络点评的情感倾向性分析研究。采用向量空间模型表示旅游评价文本,使用旅游情感词典对特征空间进行降维,采用TF-IDF特征权重法计算权重,利用SVM机器学习模型将旅游网络评价的情感分为正向和负向两类,因为利用了旅游情感词典进行降维,减少了计算工作量并降低了计算复杂度,较为实用,从正确率、召回率、F均值三大指标来看,该方法的实验也取得了较为满意结果,从中我们可以看出这种方法在旅游网络评价情感倾向分析中,具有一定的优势。今后的研究工作主要着重两点:第一,将实验中所编制网络评价提取和相关算法的程序,进一步完善,实现实用化的软件产品;第二,加强对旅游网络评价词的聚类分析研究,找出游客评价中的共同点,为旅游企业改进产品和服务提供数据支持,实现“科技为旅游助力”。 参 考 文 献 [1] 张紫琼,叶强,李一军.互联网商品评论情感分析研究综述[J].管理科学学报,2010(6):84-96. ZHANG Ziqiong, YE Qiang, LI Yijun. Literaturereview on sentiment analysis of online product reviews[J]. Journal of Management Sciences in China,2010(6):84-96. [2] 叶强,张紫琼,罗振雄.面向互联网评论情感分析的中文主观性自动判别研究[J].信息系统学报,2007(1):79-91. YE Qiang, ZHANG Ziqiong & Law Rob. Automatically Measuring Subjectivity of Chinese Sentences for Sentiment Analysis to Reviews on the Internet[J]. China Journal of Information Systems,2007(1):79-91. [3] 陆文星,王燕飞.中文文本情感分析研究综述[J].计算机应用研究,2012(6):2014-2017. LU Wenxing, WANG Yanfei. Review of Chinese text sentiment analysis[J]. Application Research of Computers,2012(6):2014-2017. [4] 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848. ZHAO Yanyan, QIN Bing, LIU Ting. Sentiment Analysis[J]. Journal of Software,2010,21(8):1834-1848. [5] 周立柱,贺宇凯,王建勇.情感分析研究综述[J].计算机应用,2008(11):2725-2728. ZHOU Lizhu, HE Yukai, WANG Jianyong. Survey on research of sentiment analysis[J]. Computer Applications,2008(11):2725-2728. [6] 唐慧丰,谭松波,程学旗.基于监督学习的中文情感分类技术比较研究[J].中文信息学报,2007(11):88-108. TANG Huifeng, TAN Songbo, CHENG Xueqi. Research on Sentiment Classification of Chinese Reviews Based on Supervised Machine Learning Techniques[J]. Journal of Chinese Information Processing,2007(11):88-108. [7] 徐军,丁宇新,王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2007(11):95-100. XU Jun, DING Yuxin, WANG Xiaolong. Sentiment Classification for Chinese News Using Machine Learning Methods[J]. Journal of Chinese Information Processing,2007(11):95-100. [8] 罗景,涂新辉.基于概率潜在语义分析的中文信息检索[J].计算机工程,2008(1):199-201. LUO Jing, TU Xinhui. Chinese Information Retrieval Based on Probabilistic Latent Semantic Analysis[J]. Computer Engineering,2008(1):199-201. [9] 宋晓雷,王素格,李红霞,等.基于概率潜在语义分析的词汇情感倾向判别[J].中文信息学报,2011(6):89-93.SONG Xiaolei, WANG Suge, LI Hongxia, et al. Word Sentiment Orientation Discrimination Based on PLSA[J]. Journal of Chinese Information Processing,2011(6):89-93. [10] 徐琳宏,林鸿飞,赵晶.情感语料库的构建和分析[J].中文信息学报,2008(1):116-122. XU Linhong, LIN Hongfei, ZHAO Jing. Construction and Analysis of Emotional Corpus[J]. Journal of Chinese Information Processing,2008(1):116-122. [11] 杨鼎,阳爱民.一种基于情感词典和朴素贝叶斯的中文文本情感分类方法[J].计算机应用研究,2010(10):3737-3739. YANG Ding, YANG Aimin. Classification approach of Chinese texts sentiment based on semantic lexicon and naive Bayesian[J]. Application Research of Computers,2010(10):3737-3739. [12] 刘志明,刘鲁.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1-4. LIU Zhiming, LIU Lu. Empirical study of sentiment classification for Chinese microblog based on machine learning[J]. Computer Engineering and Applications,2012,48(1):1-4. [13] 周杰,林琛,李弼程.基于机器学习的网络新闻评论情感分类研究[J].计算机应用,2010(4):1011-1014. ZHOU Jie, LIN Chen, LI Bicheng. Research of sentiment classification for net news comments by machine learning[J]. Journal of Computer Applications,2010(4):1011-1014. 收稿日期:2015年10月4日,修回日期:2015年11月26日 基金项目:南京旅游职业学院基金项目(2015YKT10),大数据时代旅游数据挖掘与应用研究资助。 作者简介:王新宇,男,硕士研究生,讲师,研究方向:旅游电子商务、软件工程。 中图分类号TP391.1 DOI:10.3969/j.issn.1672-9722.2016.04.004 Sentiment Analysis of Tourism Reviews Based on Semantic Lexicon and Machine Learning WANG Xinyu (Nanjing Institute of Tourism & Hospitality, Nanjing211100) AbstractThis paper provides an approach for sentiment analysis of tourism reviews through Internet service by combining semantic lexicon with machine learning. The approach expresses tourism reviews by adopting Vector Space Model(VSM). It reduces dimension of feature space by semantic lexicon. The weights are calculated by term frequency-inverse document frequency(TF-IDF). The tourism reviews are classified by Support Vector Machine(SVM). Experimental results show that the proposed approach can make sentiment classification for plenty of tourism reviews efficiently. Key Wordsmachine learning, semantic lexicon, sentiment analysis
5 实验及结果分析

6 结语
猜你喜欢
电脑知识与技术(2017年3期)2017-03-27 14:05:09
智能计算机与应用(2017年1期)2017-03-23 13:24:04
物联网技术(2016年11期)2017-01-12 19:41:22
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
预测(2016年5期)2016-12-26 17:16:57
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
