
基于Dpark的数据分析方法的性能研究*
2016-08-11 07:04:14马燕龙
计算机与数字工程 2016年4期
关键词:数据预处理
马燕龙 吴 云
(贵州大学计算机科学与技术学院 贵阳 550025)
基于Dpark的数据分析方法的性能研究*
马燕龙吴云
(贵州大学计算机科学与技术学院贵阳550025)
摘要随着大数据时代的来临,以Hadoop和Spark为首的开源分布式计算框架主导着相关行业的事实标准。然而,无论是使用Java编写的Hadoop,还是使用Scala编写的Spark,使用及对其进行二次开发的难度都比较大,而使用Python编写的分布式计算框架Dpark,具有继承自Spark的内存计算和惰性求值机制,结合Python的简洁语法,同时又配合分布式文件系统MooseFS、分布式数据库Beansdb和分布式资源调度框架Mesos,可以极大提高数据分析的工作效率。文章主要对比了传统Python程序和基于Dpark的Python程序在完成数据预处理工作上的运行效率,得出后者的性能和可扩展性至少优于前者数十倍的结论。
关键词Dpark框架; 集群部署; 数据预处理
Class NumberTP311.5
1 引言
随着信息技术的飞速发展,云计算已经成为当前计算机相关行业热议的话题,“互联网+”也成为国家从上到下大力研究的课题。
云计算涉及的技术非常广泛,基本来说,数据的存储需要用到分布式文件系统和分布式数据库,资源的管理调度需要用到分布式资源调度系统,数据的计算需要用到分布式计算框架,文章重点研究由北京豆网科技有限公司开发并开源的分布式计算框架——Dpark[1],在Dpark之外,文章部署的云计算平台采用了分布式文件系统MooseFS[2]、分布式数据库Beansdb[3]和分布式资源调度系统Mesos[4]。
2 Dpark概述
毋庸置疑,由Apache基金会开发的分布式计算框架Hadoop[5]已经成为大数据处理事实上的工业标准,同时它也是最著名的MapReduce[6]开源框架。但相比Dpark来说,Hadoop的用户友好性不足,基于Hadoop的分布式计算需要采用Java编写严格意义上的Map函数和Reduce函数,设计难度大,开发的代码量也比较大,而大量的代码就意味着大量的维护,商业系统的开发和维护需要比较高的人力成本。而Dpark采用Python编写,提供了Python的原生接口,更是加入函数式编程的思想,极大简化了分布式计算的编码难度,降低了工作量,不管对于商业系统,还是科研系统来说,都可以极大提高工作效率。
从另一个角度看,由UC Berkeley AMP Lab开发并开源的分布式计算框架Spark[7]已经在挑战Hadoop的霸主地位。和Hadoop相比,Spark将内存计算的方法引入分布式计算领域,同时利用RDD(Resilient Distributed Dataset)[8]的内存抽象技术,实现惰性求值。此举不仅突破了Hadoop的MapReduce固定框架,同时对于实际应用中非常常见的迭代计算有了更好的支持,由于采用内存计算、惰性求值,Spark的性能远高于Hadoop。因而Spark正在向下一代分布式计算平台的事实工业标准迈进。
但由于Spark本身使用小众编程语言Scala开发,基于Spark的二次开发比较困难,而作为仍不成熟的计算框架,完全等着开发者去改进和完善是不现实的,对此,国内的北京豆网科技有限公司,即豆瓣网的开发运营商,采用Python语言将Spark进行了重写并开源,这样对于国内用户来说,根据需求进行分布式计算框架的二次开发十分方便,因此,研究Dpark已存在极大且必要的需求。
3 部署方法
常规的Dpark部署分为四个部分,即分布式文件系统MooseFS、分布式数据库Beansdb、分布式资源调度系统Mesos、分布式计算框架Dpark。其中MooseFS主要存储数据源文件,常见的是日志文件、逗号分隔符文件等文本文件,也可以是图片文件;Beansdb是一种分布式Key-Value数据库,主要用于存储中间计算结果,可以看成集群上各个节点共同使用的大字典;Mesos是一种资源调度系统,主要用于集群的任务分配,通过Web界面可以浏览任务完成情况。换句话说,MooseFS、Beansdb和Mesos将集群抽象成了一个机器,使得在集群上运用Dpark就如同在本地编写普通的Python程序,极大简化了程序编写的复杂度,降低了数据分析的工作量,提高了数据分析的效率。
部署了4台物理机器,含虚拟机在内共14个计算节点,1个内存节点,3个存储节点。相关硬件配置如表1所示。
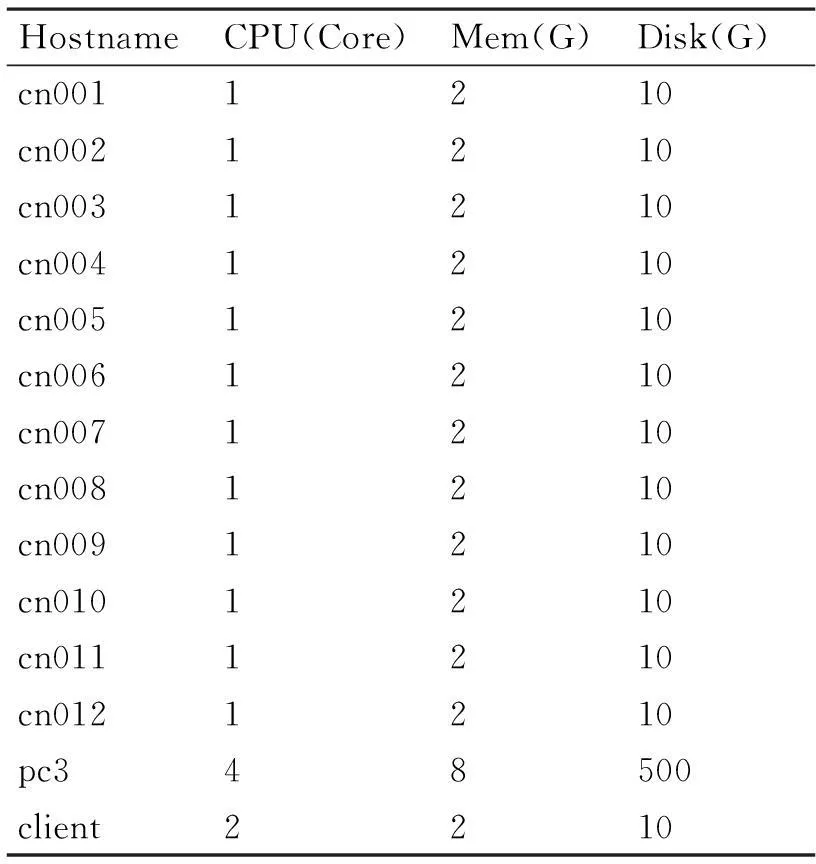
表1 集群相关硬件配置
4 实验与结果分析
通过经典的基于物品的协同过滤算法[9]中的数据预处理工作对比了传统Python程序和基于Dpark的Python程序的性能差异。实验中采用了MovieLens开放数据集[10]。
4.1源数据格式
论文使用了源数据中ratings.dat文件,数据格式和数据行数如图1所示,其中,数据行包含如下内容:用户编号、电影编号、评分值、时间戳(采用unix计时方式)。
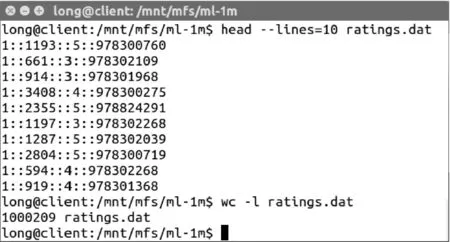
图1 数据集部分数据和数据行数
4.2数据预处理的性能对比
首先对比两种方法进行数据预处理的性能。由于将全部数据预处理结果打印到屏幕是不现实的,打印部分结果进行展示,同时分别统计程序运行时间。本例从源数据获取“用户-电影映射”和“电影-用户映射”这两个字典。
分别用传统算法和基于Dpark的算法进行了处理。
1) 传统算法采用的流程如下:
(1)打开并读取文件;
(2)用strip()函数去除行首和行尾空格;
(3)使用split()函数,依照“::”划分每行记录,放到一个嵌套列表中;
(4)使用嵌套列表推导计算映射结果。
2) 基于Dpark的算法采用的是如下流程:
(1)使用Dpark加载分布式文件系统中的目标文件;
(2)利用map()函数,结合strip()函数和split()函数,将数据集转换成嵌套列表;
(3)利用map()函数,结合groupByKey()函数,进行分组合并,得出映射结果。
两种方法的主体思路是一样的,但计算结果差距很大。

图2 两种方法的输出结果对比
图2是两种方法的运行结果对比,差距让人惊讶,提取同样结构的数据处理结果,传统方法花费了852.557s,而基于Dpark的方法只用了0.159s,相差5362倍,这主要得益于Dpark的惰性求值机制。实质上,Dpark并未真正求出结果数据集。但是传统方法不具有惰性求值的机制,故而计算的是提取了全部统计结果的时间耗费。对此,论文进行了进一步实验。但这里需要注意的是,即便基于Dpark的方法没有获取全部数据集,但可以在后续计算中,高效读取需要的数据。

图3 程序性能对比图
在进一步的实验中,修改了两个程序,普通方法用print()函数输出两组映射的元素个数,基于Dpark的方法用count()函数计算结果集的规模,再进一步对比两个程序的性能。限于篇幅,由于基于Dpark的方法程序输出时会有很多运算过程信息,所以无法截图,只好直接展示性能对比图,如图4所示。
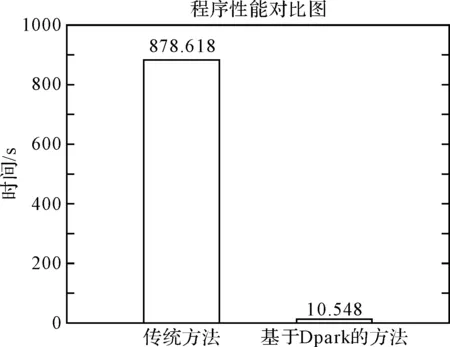
图4 进一步实验的程序性能对比图
两种方法统计的结果中,“用户-电影映射”共有6040个元素,“电影-用户映射”共有3706个元素。传统方法运行了878.618s,而基于Dpark的方法只用10.548s。注意传统方法在第一次实验中已经得到了整个集合,集合长度并不大,所以求元素个数没有耗费很多时间,和之前的代码运行结果相差不大,完全不是倍数关系。但基于Dpark的方法由于需要真实计算结果集合,并且还需要计算元素个数,因而和之前相差66倍之多。但即便如此,基于Dpark的方法完成相同需求所用时间,也是传统方法的1.2%左右。
4.3结果分析
综上,如果只需要提取结果集,并不明确获取结果集的全部元素,那么运用Dpark可以让程序运行效率提高几千倍;即便明确获取结果集的全部元素,运用Dpark也可以让程序运行效率提高60倍左右。这主要得益于Dpark继承自Spark的惰性求值机制,大大减少迭代计算时的工作量,简化了计算过程,提高了运行效率。
这里需要注意的是,基于Dpark的方法只是启用了三个计算节点参与了本次运算,也就是说,一百万行的计算量尚不足以发挥整个集群的运算能力。我们会在后续工作中使用更大的数据集进行测试。
5 结语
Dpark的运用对于提高数据分析效率具有重大意义,这对于拥有大量数据,同时有强烈数据分析需求的用户来说,无疑具备了强有力的武器。文章进行了数据预处理相关工作,基于Dpark的方法相对传统方法性能提高至少在数十倍左右,也就意味着数十天的工作量,使用Dpark可以在1天左右
完成。实际应用中可以根据任务量的大小分配虚拟机的数量,减少不必要的网络开销。同时,如果数据量非常庞大,也可以加入更多的虚拟机参与计算,随着计算节点的增加,集群的计算能力可以不断增大,而传统方法不具备这样的可扩展性。在合理的虚拟机数量下,计算效率还有很大的提升空间,而如何计算合理的虚拟机数量,是下一步的研究重点。
Dpark充分发挥了Python的简洁语法特性,大量工作都可以用简短的代码完成,工作效率得到大大提升。从文章可以看到提取某一个统计结果数据集仅需要一行简短的Python代码。这对于提高数据分析系统的开发效率、降低系统维护难度具有现实意义。
Dpark是分布式计算框架,计算能力可以随着集群的扩展而不断增强,具备良好的可扩展性。在处理大规模的数据时,单台主机已经无法在有效的时间范围内处理数据,这时只能依靠集群的并行计算能力处理数据,Dpark大有用武之地。
参 考 文 献
[1] 张杰.PyGel:基于DPark的分布式图计算引擎的研究与实现[D].广州:华南理工大学计算机科学与工程学院,2013:5-25.
ZHANG Jie. PyGel: A Distributed Graph Computing Engine Based On Dpark[D]. Guangzhou: School of Computer Science & Engineering, South China University of Technology,2013:5-25.
[2] Chen Lixian, Xiao Tong. Research on Achieving Cloud Storage Based on Moose FS[C]//Proceedings of the 2012 Second International Conference on Electric Information and Control Engineering,2012(2):1266-1269.
[3] Deka Ganesh Chandra. BASE analysis of NoSQL database[J]. Future Generation Computer Systems. May.,2015(3):13-21.
[4] Benjamin Hindman, Andy Konwinski, et al. Mesos: a platform for fine-grained resource sharing in the data center[C]//Proceedings of the 8th USENIX conference on Networked systems design and implementation,2011:295-308.
[5] Mohd Rehan Ghazi, Durgaprasad Gangodkar. Hadoop, MapReduce and HDFS: A Developers Perspective[J]. Procedia Computer Science,2015(48):45-50.
[6] Jeffrey Dean, Sanjay Ghemawat. MapReduce: Simplified Data Processing on Large Clusters[J]. Communications of the ACM. Jan.,2008(51):107-113.
[7] Matei Zaharia, Mosharaf Chowdhury, et al. Spark: Cluster Computing with Working Sets[D]. Berkeley: Tech. Rep. UCB/EECS-2010-53, EECS Department, University of California,2010:1-6.
[8] Matei Zaharia, Mosharaf Chowdhury, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[D]. Berkeley: Tech. Rep. UCB/EECS-2011-82, EECS Department, University of California,2011:1-14.
[9] Greg Linden, Brent Smith, et al. Amazon.Com Recommendations: Item-to-Item Collaborative Filtering[J]. IEEE Internet Computing,2003,7(1):76-80.
[10] Herlocker, J., Konstan, J., et al. An Algorithmic Framework for Performing Collaborative Filtering[C]//Proceedings of the 1999 Conference on Research and Development in Information Retrieval. Aug,1999:230-237.
收稿日期:2015年10月14日,修回日期:2015年11月28日
基金项目:个性化推荐技术的研究与应用(编号:联科(合)20141101);贵州省科学技术基金项目(编号:黔科合J字[2010]2100号);贵州大学博士基金(编号:贵大人基合字(2009)029号)资助。
作者简介:马燕龙,男,硕士研究生,研究方向:分布式计算与推荐系统。吴云,男,博士,副教授,研究方向:云计算。
中图分类号TP311.5
DOI:10.3969/j.issn.1672-9722.2016.04.029
Performance of Data Analysis Method Based on Dpark
MA YanlongWU Yun
(College of Computer Science and Technology, Guizhou University, Guiyang550025)
AbstractDistributed computing has got extensive application with the coming of the big data era. Open source distributed computing frameworks headed by Hadoop and Spark lead the relevant industry standards. However, there are difficulties in using and second-round developing Hadoop and Spark, while the former is programmed with Java and the latter is programmed with Scala. But Dpark, a distributed computing framework programmed with Python, extremely improves work efficiency of data analysis, because it not only inherits the mechanism of memory calculation and lazy evaluation from Spark, but also combines with the concise syntax of Python. What’s more, it is able to cooperate with MooseFS, which is a distributed file system, Beansdb, which is a distributed database, and Mesos, which is a distributed resources scheduling framework, naturally. The work efficiency of traditional Python program and the Dpark-based program in data preprocessing are compared, while the performance and scalability of the latter is better than the former.
Key WordsDpark, cluster deployment, data preprocessing
猜你喜欢
中国经贸(2017年16期)2017-09-22 06:37:55
现代农业科技(2017年15期)2017-09-15 16:59:52
数字技术与应用(2017年7期)2017-09-09 06:57:54
电子技术与软件工程(2017年7期)2017-06-05 08:46:47
科技创新与应用(2017年15期)2017-05-31 06:36:17
湖北农业科学(2016年22期)2017-04-12 23:25:16
科技视界(2016年27期)2017-03-14 22:45:40
现代农业科技(2017年1期)2017-03-06 12:59:21
中国市场(2016年41期)2016-11-28 05:30:48
电脑知识与技术(2016年10期)2016-06-16 21:32:52
