
基于随机森林和多标记学习算法的慢性胃炎实证特征选择和证候分类识别研究
2016-08-01 07:47徐玮斐顾巍杰刘国萍刘晏颜建军钟涛
中国中医药信息杂志 2016年8期
徐玮斐 顾巍杰 刘国萍 刘晏 颜建军 钟涛

摘要:目的 对慢性胃炎实证证候的特征症状进行选择,并建立证候模型,为慢性胃炎证候量化诊断的建立提供方法学参考。方法 运用慢性胃炎中医问诊规范化量表采集临床症状和体征,并运用机器学习领域新提出的随机森林和多标记学习算法对慢性胃炎的实证症状进行选择和模型构建。结果 运用随机森林和信息增益算法,结合多标记学习算法对证候分别建模,随机森林算法挑选出15个特征症状,信息增益方法挑选出20个特征症状,二者的模型最高准确率分别为83%、82%。通过评价,随机森林算法选出的特征症状更加精简,提高了诊断模型的识别率。结论 随机森林结合多标记学习算法可实现慢性胃炎实证证候特征症状的选择,同时还可解决几个证候相兼问题,弥补传统学习算法的不足。
关键词:随机森林算法;多标记学习算法;慢性胃炎;特征选择;证候
DOI:10.3969/j.issn.1005-5304.2016.08.006
中图分类号:R259.733 文献标识码:A 文章编号:1005-5304(2016)08-0018-06
证候指人体生理病理的整体功能状态,临床上常指对个体整体功能状态的判断结果[1]。证候分类是对不同个体生理病理整体功能状态进行分类的一种方法,主观症状和体征(舌脉等)信息则是中医证候分类的主要依据。此外,症状和体征的出现在不同证候中有不同的规律,这种规律可以利用现代方法去寻找和不断完善,从而找到证候分类标准的制订和完善方法。刘渡舟教授大力提倡“抓主症”,并指出每一种病证都有其特异性的主症,可以是一个症状,也可能由若干个症状组成[2]。随着数理统计学和数据挖掘技术的发展,如何找出患者的主症,是提高临床辨证准确性的关键,也是中医步入“数字中医”时代的紧迫任务。特征选择旨在去除不相关特征和冗余特征,力求以最少的特征来表达原始信息,并达到最优的预测或分类精度。特征选择与寻找“主症”的目的相同。随机森林算法(random forest algorithm)是一种嵌入式的特征选择方法,充分利用了集成分类器构建过程所产生的分类模型。随机森林算法适合对高维、离散型数据进行建模仿真,当数据含噪声时也表现出良好的性能。
本课题组前期研究显示,临床实际中慢性胃炎证候往往不会单一出现、时常交织在一起,2个以上证候兼杂的情况占30%以上[3]。这属于典型的多标记问题。因此,我们运用课题组提出标记相关特征的多标记学习方法[4]和随机森林算法相结合,进行慢性胃炎症状和体征的选择和实证证候分类识别,为慢性胃炎的中医证候诊断规范化及客观化研究提供参考。
1 资料与方法
1.1 研究对象
2008年9月-2010年10月于上海中医药大学附属龙华医院、上海中医药大学附属曙光医院、上海交通大学医学院附属新华医院、上海市普陀区中心医院及上海市中医医院消化内科门诊、住院部、胃镜室进行病例采集,去除信息不完整及不符合慢性胃炎诊断的量表,共采集有效样本919例。其中男性354例(38.5%),平均年龄(44.61±14.54)岁;女性565例(61.5%),平均年龄(48.70±12.74)岁。本研究获得上海市医院伦理委员会批准,所有纳入病例患者均签署知情同意书。
1.2 诊断标准
1.2.1 西医诊断标准 参考中华医学会消化病学分会《中国慢性胃炎共识意见(2006年,上海)》[5],通过胃镜与病理组织学结果结合临床表现诊断筛选为慢性胃炎患者。
1.2.2 中医证候诊断标准 参考《中药新药临床研究指导原则(试行)》[6]及中华人民共和国国家标准《中医临床诊疗术语·证候部分》[7]制定脾胃湿热、湿浊中阻、脾胃气虚、脾胃虚寒、肝气郁滞、肝胃郁热、胃阴不足、胃络瘀血8个证候的辨证标准。
1.3 纳入标准
①符合慢性胃炎诊断标准和中医证候诊断标准;②对本调查知情同意者。
1.4 排除标准
①精神病患者及伴有其他系统重度疾病者;②语言表达能力较差,病情叙述有困难者;③未获得知情同意,拒绝配合者。
1.5 采集量表的制作方法
由上海市资深中西医结合消化系统临床专家、临床医生及研究者组成研究小组。参考以往量表制作的经验[8],通过文献检索,参考国内慢性胃炎证型与证候有关的症状频率的报道,初步制定出临床流行病学调查表。并经2轮专家咨询及相关的统计学检验,完善修改量表。确定的中医问诊量表包括寒热、汗、头身胸腹、二便、饮食口味、睡眠、情绪、妇女共8个维度,及既往史、望诊、切诊等内容,共113个变量。
1.6 调查方法
量表中对症状给以明确的定义,指出问诊时的具体操作方法和顺序。病例采集人员经统一培训。为保证在调查过程中的统一,小组成员定期集中,对典型病例的资料进行讨论,以尽可能保证所采集资料的一致性。
1.7 诊断方法
邀请3位临床经验丰富的高年资主任医师,参考课题组制定的辨证诊断标准,对信息完整的病例进行中医辨证诊断。选取2位专家诊断结果一致的数据进行录入;对于诊断不一致的数据,再与专家讨论,诊断结果达成一致后再录入。
1.8 数据输入及处理
采用Epidata3.1软件建立数据库。独立双遍录入,并对2份录入数据进行对比核查。再进行逻辑检查,修正调查表填写错误。
1.9 分析方法
1.9.1 症状(体征)特征选择方法 前期研究显示,信息学的特征提取方法中信息增益(information gain)的结果最优[4],因此,本研究运用随机森林和信息增益2种算法进行对照,分别对慢性胃炎临床常见证候进行特征选择,并运用REAL多标记学习算法对证候进行识别。采用matlab7.0进行分析。
1.9.1.1 信息增益 信息增益在机器学习领域被广泛应用。在信息论中,样本属性的信息增益越大,其包含的信息量也越大。它是通过计算一个特征能带来多少用于分类的信息,以衡量特征对应分类的重要度。在信息增益中,重要性的衡量标准就是看特征能够为分类系统带来多少信息,带来的信息越多,该特征越重要。
1.9.1.2 随机森林算法 本研究利用Abhishek Jaiantilal的R package randomForest工具包训练出中医慢性胃炎数据的分类模型以确定特征重要度。在不增加原样本集样本的情况下通过自举法(bootstrap)选择样本子集构建一组分量分类器,然后利用投票(voting)机制综合分量分类器的结果得到最终分类结果。在构建分量分类器时,未被选中的样本组成袋外(out-of-bag,OOB)数据集,用袋外数据进行测试得到袋外误差(out-of-bag error,OOB Err)。在森林每一颗树的构建过程中,记下OOB事例集,并记下分类投票正确的个数。随机改变OOB事例集中一个特征m,把这些事例训练成树。然后用之前未受改变特征m影响情况下正确分类投票数减去改变OOB事例集中特征m后的正确分类票数得到票数差,这个票数差客观反映了特征m对分类的影响程度。对每棵树做相同处理,然后每棵树结构得到的票数差取平均值称为特征m的重要度(raw importance)。取出重要度参向量importance=(ipt1,ipt2,…,iptn)。则权
1.9.2 多标记学习方法 为了更好地体现标记之间的关联性,本研究运用课题组提出的标记相关特征的多标记学习算法(REAL算法)进行证候模型的建立。
输入:训练特征集( 以及每个特征集对应的类标签集 );测试特征集( 以及每个特征集对应的类标签集 );近邻数(k);参数(s)。
输出:类向量( );真值向量( )。
算法流程如下:
Step1:通过特征选择算法挑选各个标记N个相关特征,将每个特征的标号分别放在1个数组中。
Step2:对原始数据集进行10倍交叉检验,划分训练集和测试集。
Step3:根据每个标记分别使用相关的特征子集进行训练。所属训练样本之间的距离→每个类的先验概率→由每个样本的距离选取最近的k个近邻→近邻的标签→累计每个样本的近邻确实是该类的个数→后验概率。
Step4:根据每个标记分别使用测试集中相关的特征子集进行测试,计算所属训练样本的特征子集和测试样本的特征子集之间的距离→测试样本的近邻→近邻的标签→通过先、后验概率得到每个值的最大后验概率值。
1.9.3 实验设置与评价 根据每个证型分别选取112、100、70、60、50、40、30、20、15、10、5个症状组成的证型相关的特征子集,再运用多标记学习方法对相应的特征子集建模。实验结果的评价采用5种在多标记学习用的比较常见的评价指标:汉明损失(Hamming loss)、首标记错误(One-error)、覆盖距离(Coverage)、排序损失(Ranking loss)、平均精度(Average precision)。
1.9.3.1 平均精度 表示预测标记集合中的标记排序等级比实际中的某个 的特定标记更高的统计概率。实际反映了预测标记的平均准确率,该值 越大分类性能越好。
1.9.3.2 覆盖距离 代表覆盖预测样本标记的平均距离,该值 越小分类性能越好。
1.9.3.3 汉明损失 评价示例-标签对错分的次数,该值 越小越好。也就是不属于某个事例的标记被预测为该事例了,或者属于某个事例的标记却没有被预测出来。
式中 表示2个事例-标记对相应位置上数值的区别。
1.9.3.4 首标记错误 计算预测的最高等级标记不在样本标记集合的次数,该值 越小越好。在单标记分类问题中,该评价准则被视作普通的分类错误。
1.9.3.5 排序损失 表示不相关标记比相关标记排序更高的次数,该值 越小分类性能越好。
其中 代表Y中Yi的补集。
2 结果
2.1 基于随机森林和信息增益的REAL算法不同特征数下平均准确率的变化
由于前期的研究显示,信息增益方法选取20个特征时的识别率最高,平均准确率达到最大值为82%[6]。因此,本研究主要利用随机森林算法分别选取不同的特征数运用REAL算法进行分析,分别选取112、100、70、60、50、40、30、20、15、10、5个症状组成的证型相关的特征子集,在这些症状(体征)子集上进行证候诊断模型的建模,研究症状(体征)选择对证候预测模型的影响。以挑选的特征数目为横坐标、预测的平均精度(最高为1)为纵坐标作图,具体结果见表1、图1。
从图1中可以看出,随着特征数的变化,平均准确率是不同的。在选择的特征数为15时,平均准确率达到最大值83%,之后随着特征数的增加,平均准确率逐渐下降。
图2是利用随机森林算法特征选择数目为15、信息增益特征选择数目为20时,REAL算法各项性能的对比。
从图2中可以看出,利用随机森林算法进行特征选择时平均精度、覆盖距离、汉明损失、首标记错误和排序损失分别达到0.830、0.157、0.137、0.265和0.114。而利用信息增益进行特征选择时,这5项指标分别为0.820、0.160、0.142、0.283和0.117。基于随机森林算法的REAL算法的各项性能要高于信息增益。
特征选择方法下REAL算法各项性能比较
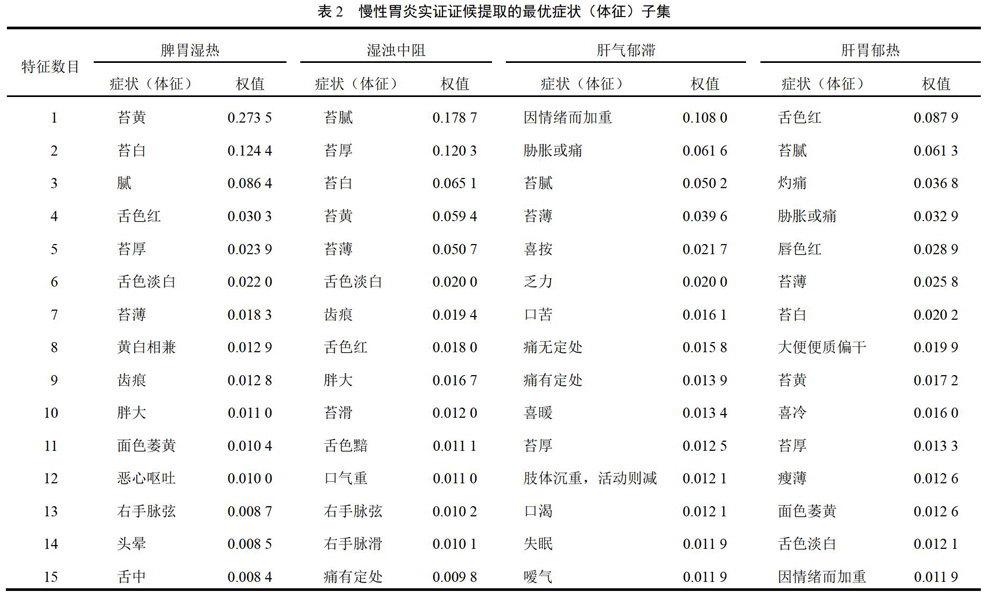
2.2 提取的最优症状(体征)子集
随机森林算法在选取15个症状特征时的识别率最高,平均准确率达到最大值83%;而信息增益方法选取20个特征时的识别率最高,平均准确率达到最大值82%。可见随进森林算法的结果更好,因此,我们得到慢性胃炎4个实证证候脾胃湿热、湿浊中阻、肝气郁滞、肝胃郁热的最优症状(体征)子集,并按照权值进行排序。
脾胃湿热证提取的症状(体征)有苔黄、苔白、苔腻等15个症状体征,湿浊中阻证提取的症状(体征)有苔腻、苔厚、苔白等15个症状体征,肝气郁滞证提取了因情绪而加重、胁肋胀或痛、苔腻等15个症状体征,肝胃郁热证提取了舌色红、苔腻、灼痛等15个症状体征,具体见表2。
3 讨论
特征选择不仅可以去除数据的冗余特征信息和无关特征信息从而提高原始数据的质量,而且还可以大大降低数据挖掘的成本。
3.1 特征选择
随机森林算法是一种机器学习方法,适合对高维、离散型数据进行建模仿真,当数据含噪声时也表现出良好的性能。它是Leo Breiman[9-10]于2001年提出的一个新的组合分类器算法,从而对数据进行挖掘和模式识别。该方法在许多领域得到了应用,例如天文学、微阵列、药物发现、癌细胞分析等[11]。其主要优点有:①较少的参数调整;②不必担心过度拟合;③适用于数据集中存在大量未知特征;④能够估计哪个特征在分类中更重要;⑤当数据集中存在大量的噪音时同样可以取得很好的预测性能。本研究充分考虑到中医数据的多标记特点,将随机森林算法和REAL多标记学习算法结合,挑选出慢性胃炎4个实证证候的症状和体征大部分与中医理论相符。如湿热内蕴,上泛舌面可见苔黄、苔腻、苔厚。根据中医理论,舌中部多反映中焦脾胃的病变,脾胃运化失常,多见舌中厚腻。寒湿困脾,湿浊上泛见舌苔白厚腻,苔滑、齿痕、胖大皆为寒湿停滞,脾失运化的表现。肝气郁滞可见胁肋胀痛,肝失条达则因情绪而加重,肝胃不和、胃气上逆可见嗳气等。肝胃郁热则见舌色红,热使脉道扩张、血行加速,气血沸涌,致使舌体脉络充盈而舌色红,灼痛、大便便质偏干、苔黄也皆是热证的典型表现。
但肝气郁滞证候中同时出现“痛有定处”和“痛无定处”2个症状,脾胃湿热证和湿浊中阻证中见脉弦,与中医理论不完全相符。可能有以下原因:①临床上肝气郁滞证多与血瘀等证候相兼出现,单独出现者较少,故而痛有定处和痛无定处同时出现。②弦脉临床主痛,肝胆病、痰饮、脾胃湿热及湿浊中阻证湿郁化饮也可见弦脉。虽然这几个症状(体征)可以用中医理论解释,但并非该证候的特异性症状(体征),考虑在今后研究中扩大样本量,进一步深入探讨。
3.2 证候模型构建
本研究是将随机森林算法和信息增益方法进行对比,前期研究显示信息增益方法选取20个特征数目时的识别率最高,平均准确率达到最大值。4个证候的特征子集分别为:脾胃湿热证共提取苔黄、苔腻、胸骨后烧灼感等症状(体征)20个;湿浊中阻证共提取苔白、舌胖大、苔腻等症状(体征)20个;肝气郁滞证共提取因情绪而加重、胁胀或痛、痛无定处等症状(体征)20个;肝胃郁热证共提取舌色红、灼痛、喜冷等症状(体征)20个。
而随机森林算法在选取15个症状特征时的识别率最高,平均准确率达到最大值为83%。通过比较发现,信息增益所得结果中包含的症状(体征)基本包含了随机森林算法选出的15个症状(体征),可见随机森林算法能够达到精简症状的目的,并且提高了证候的识别率。同时,随机森林算法能够计算单个特征重要性,能衡量各个特征对分类问题的重要性和贡献度,为证候诊断的客观化提供了直接的参考和依据,也为慢性胃炎证候的诊断标准建立提供了借鉴。
参考文献:
[1] 吕爱平,李梢,王永炎.从主观症状的客观规律探索中医证候分类的科学基础[J].中医杂志,2005,46(1):4-6.
[2] 傅延龄,刘渡舟.抓主症方法的认识与运用[J].中华中医药杂志, 1993,8(4):43-44.
[3] LIU G P, ZHEN R W, YAN S X. Association analysis and distribution of chronic Ggastritis syndromes based on associated density[C]// 2010 IEEE International Conference on Bioinformatics and Biomedicine Workshops(ITCM2010).Hong Kong,2010:790-794.
[4] LIU G P, YAN J J, WANG Y Q, Application of multi-label learning using the relevant feature for each label (REAL) algorithm in the diagnosis of chronic gastritis[J]. Evidence-Based Complementary and Alternative Medicine,2012 (2012),Article ID 135387.doi:10.1155/2012/135387.
[5] 中华医学会消化病学分会.中国慢性胃炎共识意见(2006年,上海)[J].中华消化内镜杂志,2007,24(1):58-63.
[6] 郑筱萸.中药新药临床研究指导原则(试行)[M].北京:中国医药科技出版社,2002:124-129.
[7] 国家技术监督局.中医临床诊疗术语:证候部分[M].北京:中国标准出版社,1997:17-20.
[8] 刘国萍,王忆勤,董英,等.中医心系问诊量表的研制及评价[J].中西医结合学报,2009,7(1):1222-1225.
[9] BREIMAN L. Random forests[J]. Machine leaning,2001,45(1):5-32.
[10] BREIMAN L. Manual on setting up, using, and understanding random forests v4.0[EB/OL].[2014-05-10].http://oz.Berkeley.edu/users/ breiman/Using-random-forests-V4.0.pdf.
[11] REMLINGER K. Introduction and application of random forest on high though put screening data from drug discovery[EB/OL].[2014- 05-10].http://www4.ncsu.edu/ksremlin.
猜你喜欢
世界科学技术-中医药现代化(2022年9期)2023-01-17
电子制作(2017年23期)2017-02-02
中国民族民间医药·上半月(2016年11期)2016-12-26
中国实用医药(2016年26期)2016-11-07
饮食与健康·下旬刊(2016年7期)2016-05-10
西北工业大学学报(2015年4期)2016-01-19
云南中医学院学报(2015年2期)2015-07-31
振动工程学报(2014年4期)2014-03-01
计算机工程(2014年6期)2014-02-28
中医研究(2013年1期)2013-03-11
