
DSP芯片中的高能效FFT加速器
2016-08-01 06:18雷元武陈小文彭元喜
计算机研究与发展 2016年7期
雷元武 陈小文 彭元喜
(国防科学技术大学计算机学院 长沙 410073)
DSP芯片中的高能效FFT加速器
雷元武陈小文彭元喜
(国防科学技术大学计算机学院长沙410073)
(leiyuanwu@163.com)
摘要快速傅里叶变换(fast Fourier transform, FFT)是数字信号处理(digital signal processing, DSP)领域中最耗时的核心算法,该算法的计算性能和计算效率将影响整个应用的执行效率.因此,在DSP芯片上设计实现了一个基于矩阵转置操作的高能效可变长度FFT加速器,采用多种并行策略开发批量小规模FFT算法与大规模Cooley-Tukey FFT算法中指令级和任务级并行.设计“乒乓”多体数据存储器,重叠数据搬移和FFT计算之间的开销,提高FFT加速器计算效率.并基于此存储器,提出基于基本块的快速矩阵转置算法,从而避免对数据矩阵的列访问;提出混合旋转因子产生策略,结合查表和基于CORDIC算法在线计算方式,最大限度降低旋转因子产生的硬件开销.实验结果表明:FFT加速器原型的峰值能效为146 GFLOPsW,相比Intel Xeon CPU上的多线程FFTW实现,取得2个数量级的能效提升.
关键词快速傅里叶变换;加速器;高能效;矩阵转置;数字信号处理
随着半导体技术的发展,单芯片晶体管数量和性能持续以摩尔定律方式增加,当前单芯片已经能够集成几十亿个晶体管,计算能力达到TFLOPS量级.然而,由于晶体管的物理结构和特征没有发生本质变化,单个晶体管的能耗并未随工艺进步而大幅降低,使得功耗成为处理器性能提升的瓶颈.Hadi等人认为:由于能耗的限制,未来芯片上的功能单元不可能同时持续处于峰值运行状态,这导致实际运行时往往无法将芯片所有的性能完全发挥出来,即所谓“暗场硅晶”现象[1].
针对特定应用定制加速器是提升计算效率、缓解功耗问题的一种有效的方法.针对特定应用设计相应的硬件结构,使得计算和存储资源最佳匹配应用的并行特征和存储模式获得最高能效.目前,多种新型高效能芯片采用通用处理核和加速计算核相结合的异构多核体系结构,如OpensPlySER[2],QuicklA[3].
快速傅里叶变换(fast Fourier transform, FFT)是数字信号处理(digital signal processing, DSP)领域中的基本操作,广泛应用于声纳、图像、雷达、电信和无线信号处理等领域.通常,在这些应用中,FFT算法的计算开销所占比重较大.FFT算法的计算效率将直接影响整个应用的执行效率.然而,在不同的平台上,FFT算法的执行效率相差很大.在通用处理平台,如CPU,GPU等处理芯片[4-5],FFT算法的执行效率较低,达不到峰值性能的10%[4].这是因为FFT计算过程中需要以2的幂次方为步长交叉访问数据,这与通用处理器的组相联Cache、组相联地址映射和DDR存储器的突发访问机制不匹配,从而无法充分发挥芯片的计算性能,尤其对于大规模FFT计算,不能将整行数据存储到Cache或者片上存储器中,需要频繁访问片外存储器,存储带宽利用率较低.
针对FFT算法的计算特征和存储特征定制的FFT加速器能够获得高性能、低功耗和高能效.Chung等人预测:相比GPU和CPU,定制FFT加速器能够获得100倍和1 000倍的性能加速、2个数量级的效能提升[6].学者们提出了不同流水和并行FFT体系结构,如阵列并行结构[7-8]、单通路延时转换结构(SDC)[9]、单通路延时反馈结构(SDF)[10]、多通路延时转换结构(MDC)[11]、多通路延时反馈结构(MDF)[12]等.但是上述FFT处理器都是针对通信应用设计的,如OFDM,LTE和WiMax等,支持的最大规模通常小于2048点,这很难满足雷达等大规模FFT应用.
目前,部分DSP芯片内部集成了FFT加速器,如TI C55X系列DSP芯片包含一个紧耦合FFT加速器(称为HWAFFT)[13],通过使用加速器指令实现HWAFFT与DSP内核协同工作.然而,HWAFFT仅支持32位定点格式、规模不超过1024点的FFT计算,这限制了HWAFFT的应用范围.
对于不同DSP应用,FFT运算规模差别较大,例如在数字和无线电通信应用中,FFT规模通常为K量级(103),而对于雷达、声纳等应用,FFT规模能够可达兆(M)量级(106).因此,需要为可变规模FFT算法提供高性能和高能效支持,以满足实时信号处理领域中不同应用需求.我们先前工作[14]在DSP芯片上设计了一个支持可变规模无转置操作的FFT加速器,利用DSP芯片上SRAM存储器的随机访问特性来避免大规模Cooley-Tukey FFT计算过程中对DDR进行矩阵列访问[15].然而,该方法需要增加2次SRAM和DDR之间的搬移步骤(文献[14]图1(B)中的Step1和Step4或图1(C)中的Step1和Step5),同时,DSP芯片上的数据网络宽度通常为128 b(或256 b),在文献[14] 图1(B)和图1(C)中的Step2-1和Step2-2矩阵列读和列写过程中,每个时钟周期同时读出2列(或4列)数据,导致数据读写和FFT计算无法重叠,从而降低FFT计算效率.
本文在先前工作[14]的基础上进行优化,主要贡献如下:
1) 设计了“乒乓”多体数据存储器(multi-bank data memory, MBDM),重叠数据搬移和FFT计算之间的开销,提高FFT加速器计算效率.
2) 提出基于基本块的快速矩阵转置算法,复用MBDM,避免对数据矩阵的列访问.
3) 在DSP芯片上设计实现了基于此快速矩阵转置算法的可变规模FFT加速器,增加3次快速矩阵转置来避免文献[14]中的存储问题.
4) 提出混合旋转因子产生策略,结合查表和基于CORDIC算法在线计算方式,最大限度降低旋转因子产生的硬件开销.
1Cooley-Tukey FFT算法
FFT加速器中,至少需要将一行数据存储到加速器内部数据存储器中,因此,FFT加速器所需存储容量随FFT规模的增大而线性增加.存储器容量将成为大规模FFT加速器设计的主要限制.
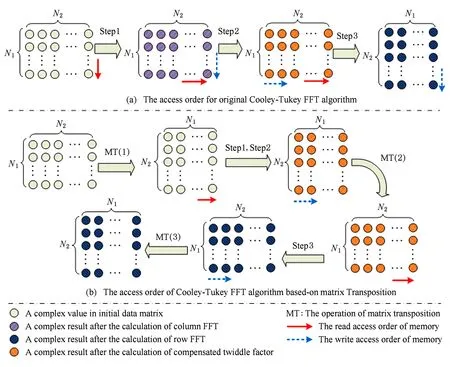
本文采用Cooley-Tukey FFT算法来实现大规模FFT.该算法采用分而治之的思想,使用规模较小的二维FFT模拟实现规模较大的一维FFT.对于NF=N1×N2点的FFT可以用N2个N1点和N1个N2点的FFT算法来实现,迭代公式为
X[k1N2+k2]=
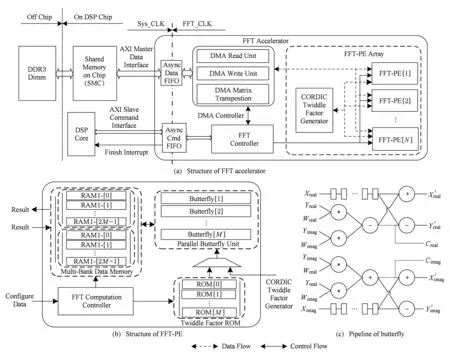
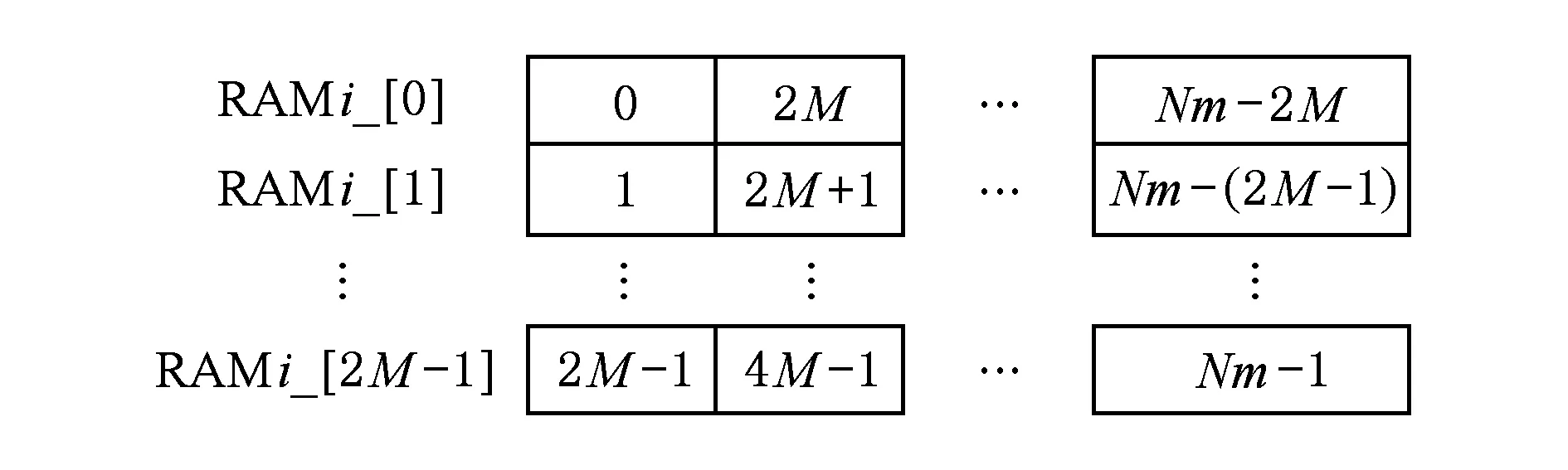
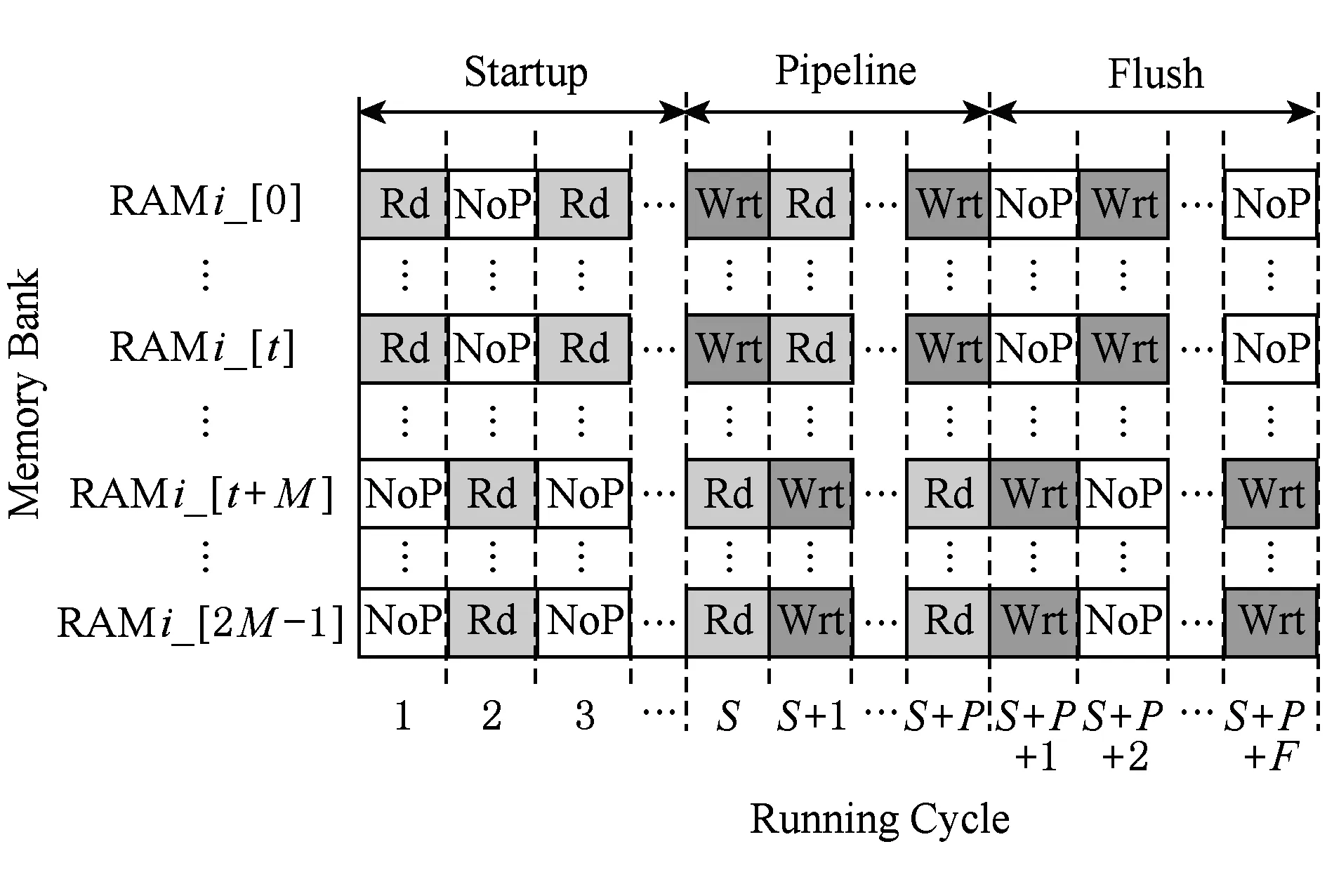
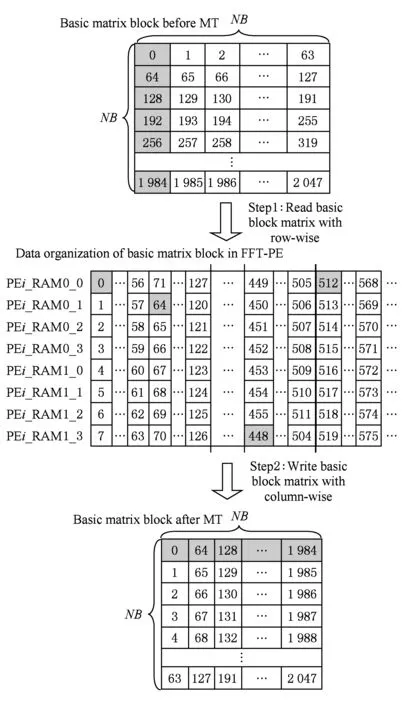
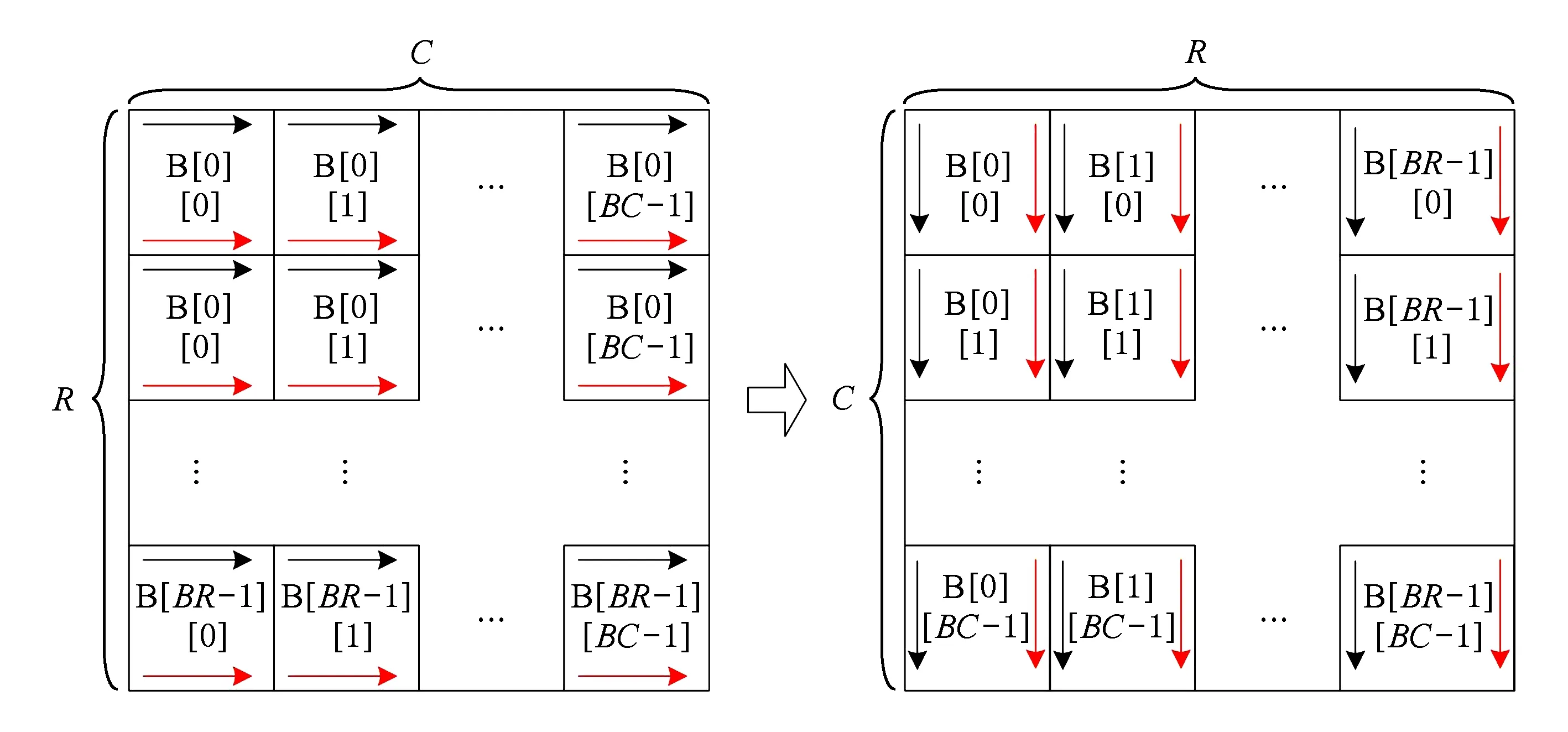
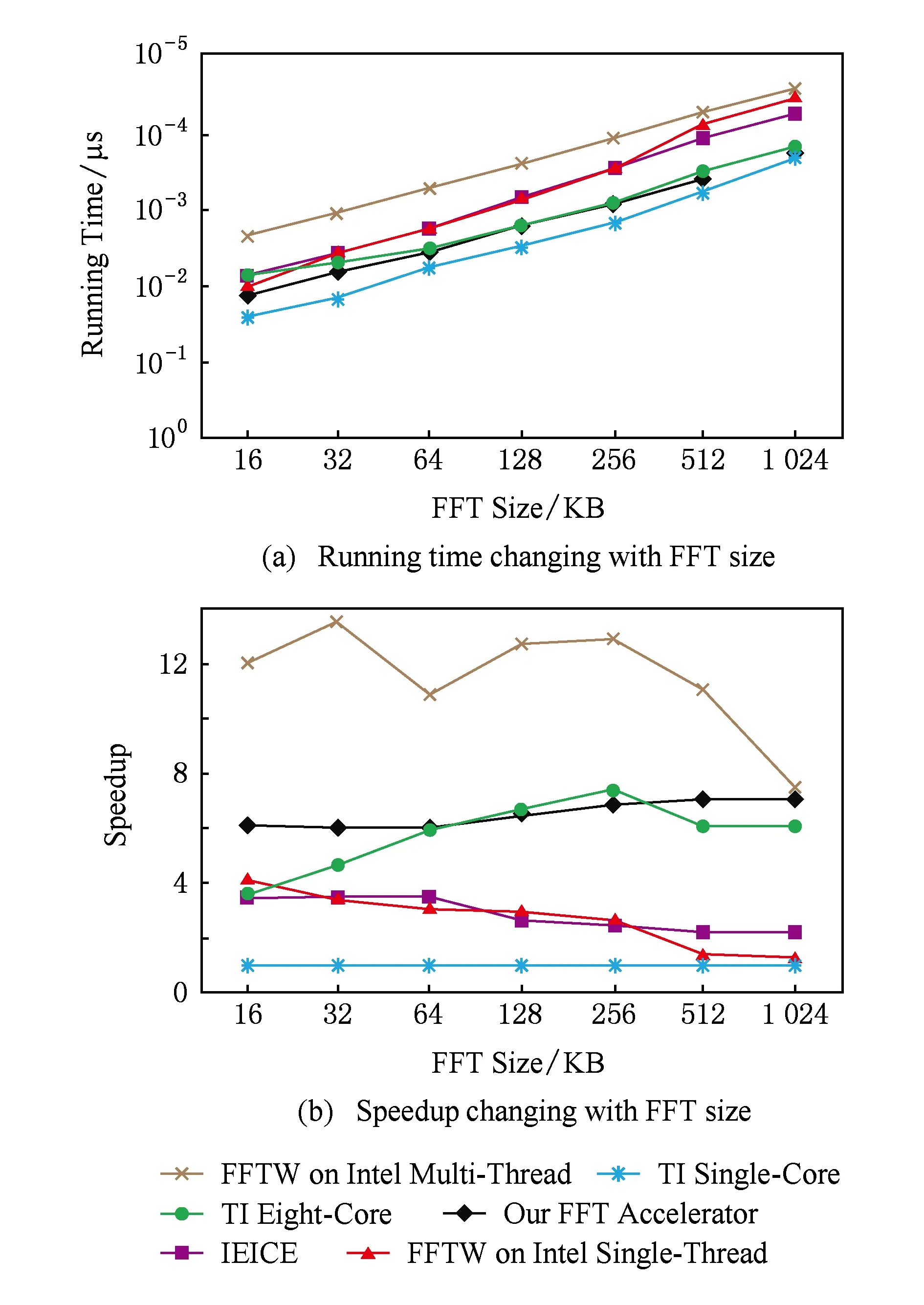
其中,0≤k1 从上述公式和图1(a)可以看出,将初始数据从逻辑上看成按行存储为N1×N2的矩阵,Cooley-Tukey FFT算法可以分为3个步骤: 步骤1. 列方向FFT计算.进行N2次的N1点FFT运算,即执行N2次公式: 步骤3. 行方向FFT计算.在步骤2的基础上进行N1次N2点FFT运算,即执行N1次公式: Fig. 1 The access order of Cooley-Tukey FFT algorithm.图1 Cooley-Tukey FFT算法中数据访问顺序 2FFT加速器的实现 2.1总体结构 如图2所示,全定制并行FFT加速器挂载于DSP芯片上的高速数据网络中、是数据网络中的一个主机,通过AXI主机数据接口访问到DSP芯片内部存储器(DSP内核中的Cache、共享存储器SMC等)和芯片外部存储器(如DDR3存储器等).同时,FFT加速器通过AXI从机命令通路完成DSP内核与FFT加速器之间的命令交互.FFT加速器接收来自DSP内核的启动命令及参数配置,然后从SMC或DDR3中读取数据进行指定规模的FFT运算,并将结果写入到指定位置,最后通过AXI从机命令通路查询方式或者中断方式将完成信号及完成情况返回给DSP内核. Fig. 2 The position of FFT accelerator on DSP chip.图2 DSP芯片上FFT加速器的位置 Fig. 3 Structure of FFT accelerator.图3 FFT加速器结构 如图3(a)所示,FFT加速器主要由FFT控制器、DMA控制器、FFT-PE阵列和异步数据命令FIFO组成.异步数据命令FIFO用于隔离FFT加速器时钟域(FFT_CLK)和DSP芯片时钟域(SYS_CLK),使得FFT加速器频率不再受DSP系统频率限制,可通过单独调节FFT_CLK来匹配FFT-PE阵列计算带宽和AXI数据网络带宽,从而获得最佳能效. FFT控制器控制着整个FFT加速器的运行,将批量FFT计算或大规模FFT计算分解为若干子操作序列,如DMA读、DMA写、DMA矩阵转置和小规模FFT计算,并将这些子操作分配到各个执行单元,在保证数据相关前提下尽可能通过重叠来隐藏延时,提高FFT加速器性能. DMA控制器负责完成数据在SMC,DDR和FFT数据存储器之间搬移,该模块将DMA读、DMA写、DMA矩阵转置等子操作转换为一系列AXI总线事务,再以突发方式访问片上SMC或者片外DDR存储器. FFT计算阵列完成所有计算任务,由N个单存储器结构的FFT-PE和CORDIC补偿旋转因子产生逻辑组成,并行执行多行小规模FFT运算.如图3(b)所示,FFT-PE由M个并行的蝶形运算单元、FFT-PE计算控制器、“乒乓”多体结构数据存储器、旋转因子存储器等组成,每个FFT-PE能够完成一行小规模FFT计算,直接支持最大规模为Nm.在FFT计算过程中,同一级的蝶形运算不存在数据相关,可以并行执行.因此,每个FFT-PE设置M个蝶形运算并行完成同一级FFT计算,同时每个蝶形运算单元采用全流水技术提高计算吞吐率.如图3(c)所示,蝶形运算单元由6个单精度浮点乘法和4个单精度浮点加法组成,采用复数乘法与蝶形运算的复用结构,能够以流水方式完成蝶形运算或复数乘法,减少中间计算结果的规格化操作,降低硬件开销,减少计算延时. FFT加速器支持的运算规模NF为2的幂次方,根据规模NF的大小,将FFT分为: 1) 小规模FFT算法.规模NF不超过Nm的FFT运算,通过DMA方式从DDR存储器或SRAM中读取数据,FFT-PE直接完成一维FFT运算,结果写回到存储器指定位置. 2) 大规模FFT算法.规模NF满足Nm 2.2混合旋转因子产生策略 旋转因子可以通过查表或者在线计算这2种方式得到.查表方式可以快速获得旋转因子,然而查找表的存储需求随FFT规模NF而线性增加,为4×NF字节,对于大规模FFT算法,在芯片内部存储所有旋转因子的硬件开销巨大.在线计算方式通常采用数字迭代算法,如CORDIC算法[16],计算相应角度正弦值和余弦值,这种方法能够计算出任意规模FFT的旋转因子.然而,以全流水方式实现正弦和余弦在线计算的硬件开销较大.本文提出混合旋转因子产生策略,结合查表和在线计算方式,满足Cooley-Tukey FFT算法需求,最大限度降低硬件开销. 从Cooley-Tukey FFT算法可以看出,步骤1列方向FFT计算和步骤3行方向FFT计算可视为批量小规模FFT计算在N个FFT-PE上执行,FFT规模不超过Nm.在每个FFT-PE中,M个蝶形计算单元为了获得流水吞吐率,每个时钟周期需要提供M个旋转因子,因此,在FFT-PE内部设置基于查表方式的多体旋转因子ROM(M个单端口(Nm2)×64的ROM,如图3(b)所示),为M个蝶形计算单元提供旋转因子数据. Cooley-Tukey FFT算法步骤2补偿旋转因子计算过程中,需要NF个补偿旋转因子(对于FFT加速器支持最大规模为Nm2),采用查表方式的存储需求将达到M量级,硬件开销较大.然而,在整个Cooley-Tukey FFT计算过程中,每个补偿旋转因子只使用一次.我们设计了基于CORDIC算法的补偿旋转因子计算引擎,采用41级全流水方式实现.由于步骤2补偿旋转因子计算与步骤1和步骤3批量FFT计算存在数据相关性,需要串行执行,将步骤1和步骤2相结合,步骤2视为一级FFT计算,以减少数据搬移,如图1(b)中Step1和Step2.同时,相对于步骤1和步骤3,步骤2所需时钟周期较少,多个FFT-PE可以共享同一个CORDIC补偿旋转因子计算引擎,进一步提高硬件资源利用率. 2.3“乒乓”多体数据存储器(MBDM) 每组多体数据存储器的数据以体低位地址交叉方式进行组织,如图4所示,最大限度将同时访问的数据存储在不同存储体中.FFT加速器运算是原位运算,即参与蝶形运算数据的原始位置和结果位置相同,对于第i级FFT运算,同一蝶形操作的2个数据间隔为2i-1,针对多体存储器,采用如下访问策略: Fig. 4 Organization of data in MBDM.图4 多体数据存储器的数据组织方式 1) 第i级FFT计算,其中2i-1≤M.蝶形运算2个数据间隔不超过M,即这2个数据存储在不同的存储体中.每个存储体的2个端口设置为一个读端口和一个写端口,同时从2个不同存储体中的读端口中读取数据,蝶形运算结果通过写端口写入各自存储体中. 2) 第i级FFT计算,其中2i-1>M.蝶形运算2个数据存储在同一存储体中.因此,只能通过该存储体的2个端口同时读才能获得蝶形运算的2个数据;对于结果,需要将存储体的2个端口设置为写端口,同时完成写操作.然而,2M个存储体中,每个时钟周期最多M个存储体进行读操作和M个存储体进行写操作.因此,可以采用存储体交叉方式流水读取数据,然后,再以交叉方式将数据写入,避免存储体的读写端口冲突,如图5所示: NoP refers to no operation in this cycle Fig. 5 The space-time graph of “Ping-Pong” access mode of MBDM.图5 多体数据存储器乒乓访问方式时空图 3基于基本块的矩阵转置算法 FFT加速器通过AXI主机数据接口以突发方式访问数据,需尽量避免对数据矩阵的列方式访问.然而,如图1(a)所示,在原始Cooley-Tukey FFT算法需要对数据矩阵进行3次列访问(步骤1的读矩阵、步骤1的写矩阵和步骤3的写矩阵). 本文利用FFT加速器内部数据存储器(MBDM)来实现快速矩阵转置,从而避免对数据矩阵的列方式访问.本文提出基于基本块的矩阵转置策略: 1) 将原始N1×N2矩阵分解若干基本块NB×NB(方阵,NB为2的幂次方),通过一次按行读和按列写操作完成基本块转置; 2) 以基本块为元素,对基本块矩阵进行转置,实现整个矩阵的转置,基本块矩阵转置通过控制基本块转置的读、写地址完成; 3) 充分利用AXI数据通路的读通路与写通路完全分开,可以重叠读操作和写操作的特征,设计“乒乓”结构重叠不同基本块的读操作和写操作. 3.1基本块转置算法 Fig. 6 The organization of basic block matrix in MBDM.图6 多体数据存储器中的基本块组织 步骤1. 以行的顺序连续读取一个基本块的数据,并以体交叉方式存储到一组FFT-PE的数据存储器中.基本块中相邻行列号相同的数据存储到不同存储体内,这样保证按列读取时能同时取出相邻行相同位置的数据.对于基本块中任意数据E[i][j](0≤i,j 步骤2. 以列顺序连续将数据从FFT-PE的数据存储器MBDM中读出,并以突发方式写入到SMC或DDR. 3.2块矩阵转置算法 块矩阵转置如图7所示,对于规模为NF的FFT计算(NF>1024),NF点的一维数据可视为二维矩阵(NB×R)×(NB×C),其中R>0,C>0.假定初始数据矩阵起始地址为A_I,转换后数据矩阵起始地址为A_R,则矩阵中任意一个数据(序号为i,j),则行列位置: NC=i%(NB×C). 基本块的行列位置: 基本块内的行列位置: NEC=NC%NB=(i%(NB×C))%NB. 矩阵转置后对应的地址位置: Addr_Trans[i]=A_R+NER+NB×NBR+ NB×C×(NB×NBC+NEC). Fig. 7 The transposition of basic block matrix.图7 基本块矩阵转置 块矩阵转置采用“乒乓”方式重叠读、写时间开销,首先以行块的顺序读取基本块,以列块顺序写入到目标地址中,除第1个基本块的读和最后一个基本块的写不能重叠外,其余的都能重叠,最大化利用读、写通路的数据带宽. 4实验及结果 4.1原型系统 在DSP芯片上设计实现了上述FFT加速器原型.该DSP芯片的片上共享存储器SMC的容量为4 MB,系统时钟频率为500 MHz,峰值IO带宽为8 GBps.FFT加速器原型包含2个FFT-PE,每个FFT-PE包含2个全流水蝶形运算单元,FFT-PE直接支持FFT的最大规模为1 024,即N=2,M=2,Nm=1024.FFT-PE内部的“乒乓”结构多体数据存储器由8个子存储体组成,每个子存储体为一个256×64双端口RAM. 在45 nm工艺库下,对FFT加速器原型进行综合,关键路径延时为0.91 ns、面积为1.22 mm2、功耗为273 mW.FFT-PE计算阵列负责完成FFT算法中所有的计算工作,所占面积较大,约占86.3%.FFT加速器工作在1 GHz下,能够取得单精度浮点峰值性能和能效分别为40 GFLOPs和146 GFLOPsW. 4.2性能比较与分析 表1对比了3个不同平台执行上小规模FFT的性能,这些平台分别为TI TMS320C55X DSP芯片上的FFT加速器HWAFFT[13]、我们先前工作[14]——基于SRAM的无转置可变规模FFT加速器和Intel Xeon X5675 CPU平台上的FFTW函数库.Intel CPU为6核12线程处理器,运行频率为3.07 GHz,在此处理器上运行最快FFT函数库——FFTW-3.3-DDL64[17],该函数库利用Intel处理器SSE4 SIMD指令对FFT算法进行自动向量化,加速FFT执行.相对于Intel Xeon CPU平台上的单线程FFTW,我们能够取得1.14~1.65倍的性能提升,同时取得2个数量级的能效提升(124 GFLOPSW比0.14 GFLOPSW).相比于TI DSP芯片上的紧耦合FFT加速器HWAFFT,本文的设计能够取得2.65~4.22倍的性能提升.相比于我们先前工作[14],本文在数据存储方式、并行任务调度和同步等方面进行优化,性能略有提升. Fig. 8 Performance comparison among different platforms for big size FFT.图8 不同平台上大规模FFT性能对比 图8对比了3个不同平台上执行大规模FFT的性能,在Intel Xeon CPU上分别使用单线程和多线程(12线程)版本的FFTW函数库的性能进行比较,而在TI TMS320C6678 DSP芯片上采用优化后的单核和8核程序[18]的执行性能进行比较.图8(b)中的加速比以TI TMS320C6678 DSP上单核性能来评估.由于Intel Xeon CPU的L2 Cache容量为256 KB,能够存储32×103点FFT的数据,多核上执行多线程Cooley-Tukey FFT通过L2 Cache进行数据交互.对于FFT规模超过32×103点,多线程FFTW必须通过L3 Cache或外部存储器进行数据交互,性能会有所降低.因此,CPU上的多核程序执行32×103点FFT运算时取得最高计算性能.相对于Intel CPU上的多线程FFTW,本文提出的FFT加速器性能略低,但是Intel CPU的功耗为FFT加速器的350倍以上(95 W比0.27 W),FFT加速器能够取得2个数量级的能效提升.对于1×106点FFT算法,本文的FFT加速器与多线程FFTW的性能相当. TI TMS320C6678 DSP芯片的共享L2存储器的容量为4 MB,能够存储256×103点FFT的数据,8核FFT程序通过L2存储器进行数据交互.因此,多核DSP版本的FFT程序在256×103点时的性能最高.与单核DSP和多核DSP相比,本文的FFT加速器能够获得6.6倍和1.2倍的平均性能提升. 与我们先前工作[14]相比,本文基于FFT加速器内部多体数据存储器实现快速矩阵转置,并设计了基于矩阵转置操作的Cooley-Tukey FFT算法,避免文献[14]中的矩阵列访问时FFT加速器中计算单元利用率不高、数据搬移开销与FFT计算开销无法有效重叠的问题.相比于文献[14],对于大规模FFT加速器,本文的FFT加速器能够获得2.3倍的平均性能提升. 5结论 在DSP芯片上设计实现了一个基于矩阵转置操作的高能效FFT加速器,采用多种并行策略、混合旋转因子产生策略和“乒乓”结构多体数据存储器来提升FFT加速器性能和计算效能,并基于FFT加速器内部多体数据存储器,提出基于基本块的快速矩阵转置算法,避免对矩阵的列访问,进一步提升FFT加速器能效. 参考文献 [1]Hadi E, Emily B, Remnee S A, et al. Dark silicon and the end of multicore scaling[C]Proc of the 38th Annual Int Symp on Computer Architecture. Piscataway, NJ: IEEE, 2011: 365-376 [2]Jesse B, Ryan C, Chris F, et al. Design, integration and implementation of the DySER hardware accelerator into OpenSPARC[C]Proc of the 18th IEEE Int Symp on High performance Computer Architecture. Piscataway, NJ: IEEE, 2012 [3]Nagabhushan C, Ganapati S, Scott H, et al. QuicklA: Exploring heterogeneous architectures on real prototypes[C]Proc of the 18th IEEE Int Symp on High performance Computer Architecture. Piscataway, NJ: IEEE, 2012 [4]James R G, Sharon M S. A transpose-free in-place SIMD optimized FFT[J]. ACM Trans on Architecture and Code Optimization, 2012, 9(3): 23:1-23:21 [5]Li Y, Zhang Y, Jia H, et al. Automatic FFT performance tuning on OpenCI GPUs[C]Proc of the 7th IEEE Int Conf on Parallel and Distributed Systems. Piscataway, NJ: IEEE, 2011: 228-235 [6]Chung E S, Milder P A, Hoe J C, et al. Single-chip heterogeneous computing—Does the future include custom logic, FPGAs, and GPU?[C]Proc of the 43rd Annual IEEEACM Int Symp on Microarchiecture. Piscataway, NJ: IEEE, 2010: 225-236 [7]Palmer J, Nelson B. A parallel FFT architecture for FPGAs[C]Proc of the 14th Int Conf on Field Programmable Logic and Application. Piscataway, NJ: IEEE, 2004: 948-953 [8]Dou Y, Zhou J, Lei Y, et al. FPGA SAR processor with window memory accesses[C]Proc of the 18th IEEE Int Conf on Application-Specific Systems, Architectures and Processors. Piscataway, NJ: IEEE, 2007: 95-100 [9]Cho T, Lee H. High-speed low-complexity modified radix-25 FFT processor for high rate WPAN applications[J]. IEEE Trans on Very Large Scale Integration Systems, 2013, 21(1): 187-191 [10]Yu C, Yen M H. Area-efficient 128- to 20481536-point pipeline FFT processor for LTE and mobile WiMAX systems[J]. IEEE Trans on Very Large Scale Integration Systems, 2015, 23(9): 1793-1800 [11]Tang S N, Liao C H, Chang T Y. An area-and energy-efficient multimode FFT processor for WPANWLANWMAN systems[J]. IEEE Journal of Solid-State Circuits, 2012, 47(6): 1419-1435 [12]Ayinala M, Brown M, Parhi K K. Pipelined parallel FFT architectures via folding transformation[J]. IEEE Trans on Very Large Scale Integration Systems, 2012, 20(6): 1068-1081 [13]Mckeown M. FFT implementation on the TMS320VC5505, TMS320C5505, and TMS320C5515 DSPs, SPRABB6B[R]. Dallas, Texas: Texas Instruments, 2013 [14]Guo L, Tang Y, Dou Y, et al. Transpose-free variable size FFT accelerator based on-chip SRAM[J]. IEICE Electron Express, 2014, 11(15): 1-8 [15]Guo L, Tang Y, Dou Y, et al. Window memory layout scheme for alternate row-wisecolumn-wise matrix access[J]. IEICE Trans on Information and Systems, 2013, E96-D(12): 874-885 [16]Jack E V. The CORDIC trigonometric computing technique[J]. IRE Trans on Electronic Computers, 1959, 8(3): 330-334 [17]Frigo M, Johnson S G. The design and implementation of FFTW3[J]. Proceeding of the IEEE, 2005, 93(2): 216-231 [18]Li X, Blinka E. Very large FFT for TMS320C6678 processors, spry277[R]. Dallas, Texas: Texas Instruments, 2015 Lei Yuanwu, born in 1982. Received his PhD degree in computer science and technology from National University of Defense Technology (NUDT) in 2012. Assistant researcher at the College of Computer, NUDT. His main research interests include high performance computer architecture, high-performance microprocessor and DSP design. Chen Xiaowen, born in 1983. Received his PhD degree in microelectronics from NUDT in 2011. Assistant researcher at the College of Computer, NUDT. His main research interests include VLSI design, computer architecture, microarchitecture, SOC, and NOC. Peng Yuanxi, born in 1966. Professor and PhD supervisor. Received his PhD degree in computer science from NUDT in 2001. His main research interests include high performance computing, on-chip networks, multi-core and many-core architectures. 收稿日期:2016-03-07;修回日期:2016-05-14 基金项目:国家自然科学基金项目(61402499,61502508);湖南省自然科学基金项目(2015JJ3017) 通信作者:陈小文(xwchen@nudt.edu.cn) 中图法分类号TP302 A High Energy Efficiency FFT Accelerator on DSP Chip Lei Yuanwu, Chen Xiaowen, and Peng Yuanxi (CollegeofComputer,NationalUniversityofDefenseTechnology,Changsha410073) AbstractFast Fourier transform (FFT) is a most time-consuming algorithm in the domain of digital signal processing (DSP). The performance and energy efficiency of FFT will make significant effect on different DSP applications. Thus, this paper presents a high energy efficiency variable-size FFT accelerator based on matrix transposition on DSP chip. Several parallel schemes are employed to exploit instruction level parallel and task level parallel of batch of small-size FFTs or big-size Cooley-Tukey FFT. A “Ping-Pong” structure of multi-bank data memory (MBDM) is presented to overlap the overhead of data move and FFT calculation. Moreover, based on MBDM, fast matrix transposition algorithm with basic block transposition is presented to avoid the matrix access with column-wise and improve the utilization of DDR bandwidth. Hybrid twiddle factor generating scheme, combining lookup table and on-line calculation with CORDIC, is presented to reduce the hardware for twiddle factor. Experimental results show that our FFT accelerator prototype with power efficiency of 146 GFLOPs�W, achieves energy efficiency improvement by about two orders of magnitude with multi-thread FFTW on Intel Xeon CPU. Key wordsfast Fourier transform (FFT); accelerator; high energy efficiency; matrix transposition; digital signal processing (DSP) This work was supported by the National Natural Science Foundation of China (61402499,61502508) and the Natural Science Foundation of Hunan Province of China (2015JJ3017).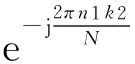

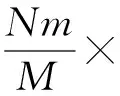
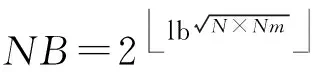
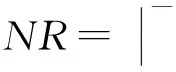
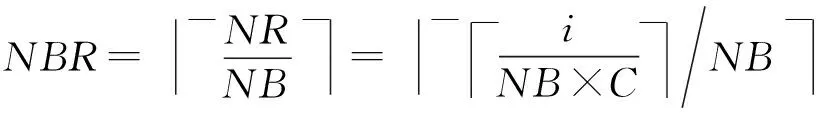

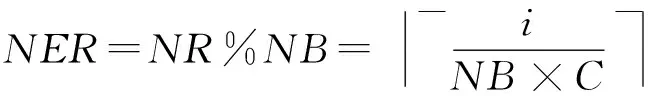


 猜你喜欢
现代装饰(2022年5期)2022-10-13小哥白尼(趣味科学)(2022年5期)2022-08-15少先队活动(2021年6期)2021-07-22中学生数理化(高中版.高二数学)(2017年1期)2017-04-16亚太教育(2016年34期)2016-12-26文理导航(2016年32期)2016-12-19大学教育(2016年6期)2016-07-06科技视界(2016年13期)2016-06-13科技视界(2016年12期)2016-05-25民主与科学(2014年5期)2014-02-28
猜你喜欢
现代装饰(2022年5期)2022-10-13小哥白尼(趣味科学)(2022年5期)2022-08-15少先队活动(2021年6期)2021-07-22中学生数理化(高中版.高二数学)(2017年1期)2017-04-16亚太教育(2016年34期)2016-12-26文理导航(2016年32期)2016-12-19大学教育(2016年6期)2016-07-06科技视界(2016年13期)2016-06-13科技视界(2016年12期)2016-05-25民主与科学(2014年5期)2014-02-28
