
应用Web日志挖据构建阿勒泰电大网络个性化教育
2016-07-25 09:32荣新疆阿勒泰广播电视大学阿勒泰836500
电大理工 2016年2期
陈 荣新疆阿勒泰广播电视大学 (阿勒泰 836500)
应用Web日志挖据构建阿勒泰电大网络个性化教育
陈 荣
新疆阿勒泰广播电视大学 (阿勒泰 836500)
摘 要以阿勒泰电大网络为研究对象,对网络教育用户在学习过程中形成的日志信息进行挖掘,探讨 Web日志挖掘的概念及其形成过程, 就如何满足不同类型学习用户的需求,实现网络教育的个性化。
关键词阿勒泰电大;WEB日志挖掘;网络教育;个性化
Web日志挖掘是在 Web环境下通过数据挖掘技术,从 Web日志文件中抽取非平凡模式与隐性数据,这些被挖掘的信息数据是未知且具有潜在应用价值的。Web日志挖掘也是一门综合技术,它是Web技术、数据挖掘技术、信息科学等多领域交叉而成的。Web日志挖掘的意义在于:可分类页面内容;2可得出有关用户的访问行为、方式信息;可根据挖掘出用户信息为络课程设计者和教师改进网络课程提供意见,从而满足学习需求。基本的 Web日志挖掘流程分源数据收集、数据预处理、模式发现、模式分析四个阶段。
1 Web日志挖掘在个性化网络教育中的源数据收集
以阿勒泰电大网络远程教育网站为例,用户访问留下诸多数据信息,包括IP地址、服务器名、访问时间、用户名、出错信息等,它们所形成的日志文件主要由以下类型:
(1)q Server log:
(2)Error log:
指存取请求失败的数据,如连接丢失,授权失败,超时等。
(3)Cookie
一种客户端持有的 Web server产生的标记,表示用户间会话,可自动标记和跟踪站点访问者。
2 Web日志挖掘在个性化网络教育中的数据预处理
通过图 2阿勒泰电大远程教育网结构图和表 1的访问序列可直观阐述数据如何预处理。
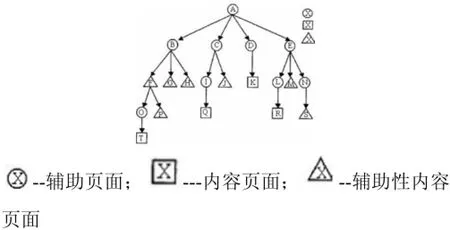
图2 阿勒泰电大远程教育网结构图
2.1 用户识别
(1)可根据用户浏览器或操作系统来识别
(2)可根据用户请求的引用与站点的网页拓扑关系来识别用户
(3)可根据学用户的登陆 ID号来识别。
2.2 会话识别
识别出同一用户的全部访问后,接下来需要划分出不同会话。如时间跨度很大的记录,可能是用户多次访问站点的结果。 如何将用户的访问记录划分成单个会话需要依靠会话识别。 时间窗方式是最简单的方法,如果不同访问间的时差超过某个值,可推出用户开启开其他会话。 仍以图 2和表 1为例,日志中用户 1的时间窗界定为使用时间30分钟,在前两个的 1小时之后最后两个引用发生,因此可识别为两个会话。4个会话分别是 A-B-F-O-G, A-D,A-B-C-G, L-R。
2.3 路径修补
重要的访问信息是否被遗漏是事务识别的另一问题,称为路径修补。如果某被请求页面,无法连接到前一个,但前一个页面却被列在历史请求中,可以认定用户通过向后援引缓存页面实现了要连接的页面。 同样以图 2和表 1为例,页面 G无法直接连接页面 O,日志分析时,可假设通过 B,G被访问,这说明用户返回到 B, 再到 G。 所以用户1的 会话中包含页面F和B 。通过路径修补可以得出, 用户1的会话有A-B-F-O-F-B-G, A-D,A-B-A-C-J, L-R。
2.4 事务识别
用户的事务文件被划分成多个有意义的用户访问序列片断就是事务识别。常见识别方法如下:
(1)引用时长(Reference Length)
用户在页面上的使用时间与该页面的辅助页面或内容页面呈相关性。试验得知,通常在辅助页面上使用的时间越短,内容页面耗费时间越长。使用大可能估计算法,辅助页面在日志中所占的比例的估计值,可通过划分辅助页面和内容页面的划分时间来得出。划分时间一旦确定,对照划分时间,页面可划分为内容或辅助两类,不同事务可被划分而出。
(2)最大前向指引(Maximal Forward Reference)
一组页面的访问可定义为一个事务,可从用户的初次引用到向后回溯为止。
前向指引是指一个页面从未在事务集中出现,后向指引指是指一个页面已在前面事务中出现。一个前向指引出现标志着一个新的事务开始(前提:页面是最大前向指引页面,辅助页面是导向最大前向指引页面的页面)。
(3)时间窗(Time Window)
通过谈定访问间隔是否大于某特定参数来划分事务的方法可称为时间窗。
2.5 格式化
当获得一组事务集后,将处理结果表示成适合挖掘需要的形式就是格式化。如对于关联规则挖掘时间属性是无用的,而把它格式化成适于关联规则,元组中的时间属性是不可忽略的。
3 Web日志挖掘在个性化网络教育中的模式发现
继续依据阿勒泰电大网络信息,完成用户会话识别和事务识别后,就可进行模式发现,常用技术包括有:
3.1 路径分析
路径分析可判定在阿勒泰电大网络远程教育站点中最频繁访问的路径,其它路径的信息也可判定得出。 例 如 : 70%的 用户多是从/CBEcourse开始 , 经 过 /CBEcourse/SimpleDescription, / CBEcourse/chapter1,最后访问/CBEcourse/chapter2;65%的用户浏览 小于等于4个页面内容后就离开了。通过以上信息,可改进站点的设计结构。
3.2 关联规则
在 Web的访问事务中使用关联规则法,可以发现: 40% 的用户 访 问 页 面/CBEcourse/chapter1 时 , 也 访 问 了 /CBEcourse/chapter8; 30%的用户在 访 问 /CBEcourse/SimpleDescription时,也访问了/CBEcourse/reference。通过上述相关性,站点的Web空间可以更好的组织,教学策略也会被有效执行。
3.3 序列模式
有序的事务集中,“一些项跟随另一个项”的内部事务模式就属于序列模式。例如:的用户访问/ CBEcourse/chapter1中,在过去的一个星期里80%的人曾在 yahoo中用查询“计算机辅助教育”。 找到序列模式,可预测出用户的访问模式,对此可针对性的进行教学。
3.4 分类和聚类
分类用户可用到分类规则,可对某个特殊群体的公共属性给出识别性描述。如:学过/CBEcourse/ chapter2的用户中40%是 20-30的年轻教师。聚类分析是辨别出具有相似特性的用户的规则。在 Web事务日志中,聚类用户信息有利于开发设计新的教学模式和用户群。
4 模式分析
在Web日志挖掘中,模式分析是最后一项步骤,也是非常重要的。选择和观察后,可将现有发现的规则、模式与统计值转换为知识,在此基础上进行模式分析,即可得出有价值的模式,如某种具有吸引力的规则、模式,最后利用可视化技术,向用户提供图形界面方式的内容。
5 结语
在阿勒泰电大网络中,Web日志挖掘将Internet、WWW 和数据挖掘结合起来,是前沿研究领域,也是一种新技术。 我们发现,它在个性化网络教育中可广泛应用,在用户信息提取、教学内容设计、站点的分析和设计方面,其应用迁建也是很好的。
参考文献
[1]邢东山,沈钧毅,宋擒豹.从Web日志中挖掘用户浏览偏爱路径[J].计算机学报.2013(11)
[2]李燕,冯博琴,鲁晓锋.Web日志挖掘中的数据预处理技术[J].计算机工程.2009(11)
[3]李烈彪,张海鹏,周亚峰.Web日志挖掘中数据预处理方法的研究[J].计算机产技术与发展.2007(7).
(责任编辑:兴安)
中图分类号:G431
文献标识码:A
文章编号:1003-3319(2016)02-00022-02
猜你喜欢
文苑(2020年4期)2020-05-30
新闻传播(2018年12期)2018-09-19
汽车与新动力(2016年6期)2017-01-04
亚太教育(2016年31期)2016-12-12
科学与财富(2016年26期)2016-12-01
电脑知识与技术(2016年26期)2016-11-24
中国市场(2016年36期)2016-10-19
中国卫生(2015年1期)2015-01-22
语文知识(2014年4期)2014-02-28
语文教学与研究(2014年8期)2014-02-28
