
基于加权有限状态机的电话号码规范解析
2016-07-19 02:07林家骏
计算机应用与软件 2016年6期
黄 明 林家骏 方 楠
1(华东理工大学信息科学与工程学院 上海 200237)2(上海104研究所 上海 200032)
基于加权有限状态机的电话号码规范解析
黄明1,2林家骏1方楠2
1(华东理工大学信息科学与工程学院上海 200237)2(上海104研究所上海 200032)
摘要针对社会数据处理中,电话号码数据写法多样,难以有效分析利用的问题,提出一种基于竞争性有限状态机的电话号码解析与规范化方法,并提出相应的基于负反馈的训练算法。经过实际应用检验,该规范化方法的处理速度和正确率都能够满足应用要求,有效解决了在存在输入差异性的场景下,对电话号码进行解析与规范化的问题,具有较好的工程实用性。
关键词有限状态机电话号码文本解析规范化负反馈训练
0引言
随着社会步入大数据时代,涉及联络通信的邮政、电信和物流等行业都积累了大量的社会数据有待分析。在人们的社会行为数据中,电话(手机)号码正扮演着越来越重要的角色,它已成为个人身份的一种重要识别码,起着标识人员、串联行为的作用,在社会人员活动轨迹描绘、行为分析中具有重要意义。
在邮政、海关和快递企业的业务数据中存在大量跨省、跨境的电话号码,这些号码写法多样、歧义性强,给数据比对分析工作带来了很大挑战。当前国内多采用正则表达式对电话号码的进行规范化处理,在号码种类多、格式差异大的情况下极易产生误差。本文提出了一种基于竞争性有限状态机和统计知识库的电话号码规范化算法,并提出了相应的基于负反馈的参数训练方法,有效解决了包含国际/国内区号的电话号码规范化问题,并应用在了实际生产环境中,经历了实践检验,取得了较好的效果。
1问题综述
目前,对电话号码的规范处理在国内依然是一个难题,在大数据处理中尤为突出,即使公安、邮政等民生部门也难以有效分析利用手头的电话号码数据资源。现实中,社会机构获取的电话号码数据普遍存在以下问题:
(1) 号码串格式写法多样化
由于个人写法习惯和单位录入标准不同,同一电话号码依据是否分节和分节方式存在多种写法。如手机号就存在不分节、“3-4-4”和“4-4-3”几种常见写法。
(2) 国内城市区号解析
国内电话号码的前几位或中间几位可能是国内城市区号,需要与主号部分区别提取出来。城市区号长度为2位或3位,与主号部分可能分隔也可能连在一起,有些数据还会在区号前加0。
(3) 国际区号解析
海关、邮政等部门的业务数据中包含大量国际电话号码,这些号码多以国际区号开头,各国的国际区号长度从1位到3位不等,与后续号码部分可能分隔也可能连在一起,一些国家(如美国)的数据习惯在国际区号前加“+”号或“00”。
(4) 分机号解析
许多国内电话号码中都含有分机号,即超过当地固定电话长度的末尾部分。大部分情况下,分机号都会通过分隔符与主机号分隔开来。
因此,电话号码解析是一项精细复杂的任务,既要从前端解析可能存在的国际区号和国内区号,又要在后端解析可能存在的分机号,再加上要识别固定电话、手机号、国内/国际长途号码的各种写法格式,往往一条号码就存在多条解析路线,需要结合匹配程度和出现概率挑选出最佳解析路线。
当前常用的电话号码解析技术有全文检索文本分析器[1]和正则表达式[2],前者可用于提取号码片段和检索比对,但是无法将号码串转化为规范化的数据结构。后者则一来对于存在的多种可能解析方案的电话号码,难以进行有效的评价和取舍;二来在数据质量不高的情况下要穷举各种可能情况,会造成正则表达式过于复杂。
加权的有限状态机[3~5]能够较好地解决字符串识别中的多义性问题。特别是基于马尔可夫链[6,7]的概率统计有限状态机[8]已成为当今自然语言处理的主流技术。然而该技术主要根据前后字词出现的条件概率来选取解析路径,而电话号码中大部分位置上的数字都是平均分布的,难以直接套用。因此,基于加权有限状态机的技术思路,本人提出了竞争性的有限状态机,对可能的解析方案进行整体的比较和推选,从而较好地解决了电话号码的识别与解析问题。
2解决方案
我们的目的是设计一种高效、可行的算法机制,对大量现实数据中的电话号码进行识别处理,提取出原始号码中的国际区号、国内城市区号、本机号和分机号等属性,将原始号码转换为规范化的数据结构,以便于后续的分析利用。
竞争性有限状态机的构想是在解析输入串时,若遇到分歧路线,则递归或并行地按照分歧路线分别行进,独立计算分值,最终比较分值,选取分值最高的一条路径作为输入串的最优解析方案。
应用有限状态机对电话号码进行解析时,先设置一个初始适宜系数p0,解析中若满足了特定匹配或筛选条件,通过了对应解析路段(例如匹配出以中国国际区号86开头),则认为获取了额外的信息,需对当前解析路径上的适宜系数进行加权。设当前路径上的适宜系数为p,加权路段ek上的加权值为pk,则加权后的适宜系数为p+pk。
在电话号码解析中,最终能否识别出一个合理的手机或座机号是衡量一条解析路径是否正确的重要依据。因此,我们针对不同的终结状态(是否识别出有效号码)设定不同的基准分值,当一条解析路径达到终结状态时,设当前适宜系数为p,终结状态基准分值为a,则路径得分为:
S=pa
需要注意的是在国际/国内区号解析路段,由于各区号分布不均匀,在确定适宜系数的加权值时应考虑匹配区号的出现概率。设区号解析路段ek的基础加权值为pk,匹配区号的出现概率为pc,则加权值为pkpc。我们通过统计国际/国内区号在真实数据中的出现概率准备了两张区号概率表,例如,经统计出现最多的几个境外国际区号是1(美国,占25%)、81(日本,占15%)和82(韩国,占12%)。基于概率表,区号解析过程实际上可以分解为包含多分路的两步解析过程,如图1所示。

图1 区号解析
设有限状态机中的一条解析路径为Γ,计算适宜系数加权值涉及到匹配项出现概率的解析路段构成路段集W,一般解析路段构成路段集T。初始适宜系数为p0,路径上一段解析路段的ek的适宜系数加权值为pk。终结状态f对应一个基准分值af。设S(Γ)为路径的最终得分,则有:
设输入电话号码可能的解析路径集为P,通过竞争性有限状态机找到的最优解析路径Γm应满足:
S(Γm)=Max(S(Γ))Γ∈P
在实际应用中,我们构造如图2所示的竞争性有限状态机,输入电话号码在经过替换非数字字符、缩并空格等预处理后进入有限状态机进行解析,解析完成后输出规范化的数据结构。

图2 电话号码解析状态机
关于该有限状态机有以下几点说明:
1) 在状态0根据输入号码是否分节分为两条完全不同的解析路径。这是因为电话号码的分节本身就包含一定的辨识信息,从分节中提取出的号码部分可信度更高。
2) 状态2、状态12表示成功解析出了国内手机号。包含国际区号的国外号码中只有美国号码以1开头,且总长度为10位;国内电话号码只有北京区号以1开头,总长度为10位。因此,以1开头,有效位数11位可以作为当前国内手机号的判别条件。
3) 从一个状态开始,以“/”为开始端的路径为排它路径,即当前状态如果满足该路径则跳过其它解析路径,以减少计算量。
4) 从一个状态开始,以“○”为开始端的路径构成一个互斥的分组,即当前状态如果满足分组中的一条路径则跳过组中其它路径,以减少计算量。但组外路径依然需要遍历。
3反馈训练
有限状态机的初始参数根据经验设定,为提升有限状态机解析规范电话号码的准确率,需根据应用反馈对系统参数进行校正,对自动机进行调优。在实际应用场景中,电话号码规范结果的正确与否最终只能依靠业务人员的知识经验来判断,需要耗费一定人工,因此大范围的收集应用反馈不现实。相比较而言,用户对于号码规范解析中出现的错误较为敏感,比较容易建立一套错误用例的收集、汇总机制。因此,我们设计了一种基于负反馈的有限状态机优化算法,通过对出现解析错误的用例进行分析学习,进而调节参数,提升性能[9,10]。
该算法的主要思想是:对于每个错误用例,算出其当前错误解析路径和正确解析路径间最终分值的差值。基于差值,提升正确解析路径上各个路段的适宜系数加权值,降低错误解析路径上各个路段的适宜系数加权值。由于采用基于负反馈的调优,我们假设除错误用例外的其他用例都得到了正确解析。因此,为了维持系统的稳定性,我们基于各路段的通过概率(易在系统运行中统计)对适宜系数加权值进行调节:通过概率高的认为是经过验证的普遍情形,适宜系数加权值调节幅度小;通过概率低的认为是作用于当前错例的特殊情形,适宜系数加权值调节幅度大。
以图3为例,算法具体描述如下:
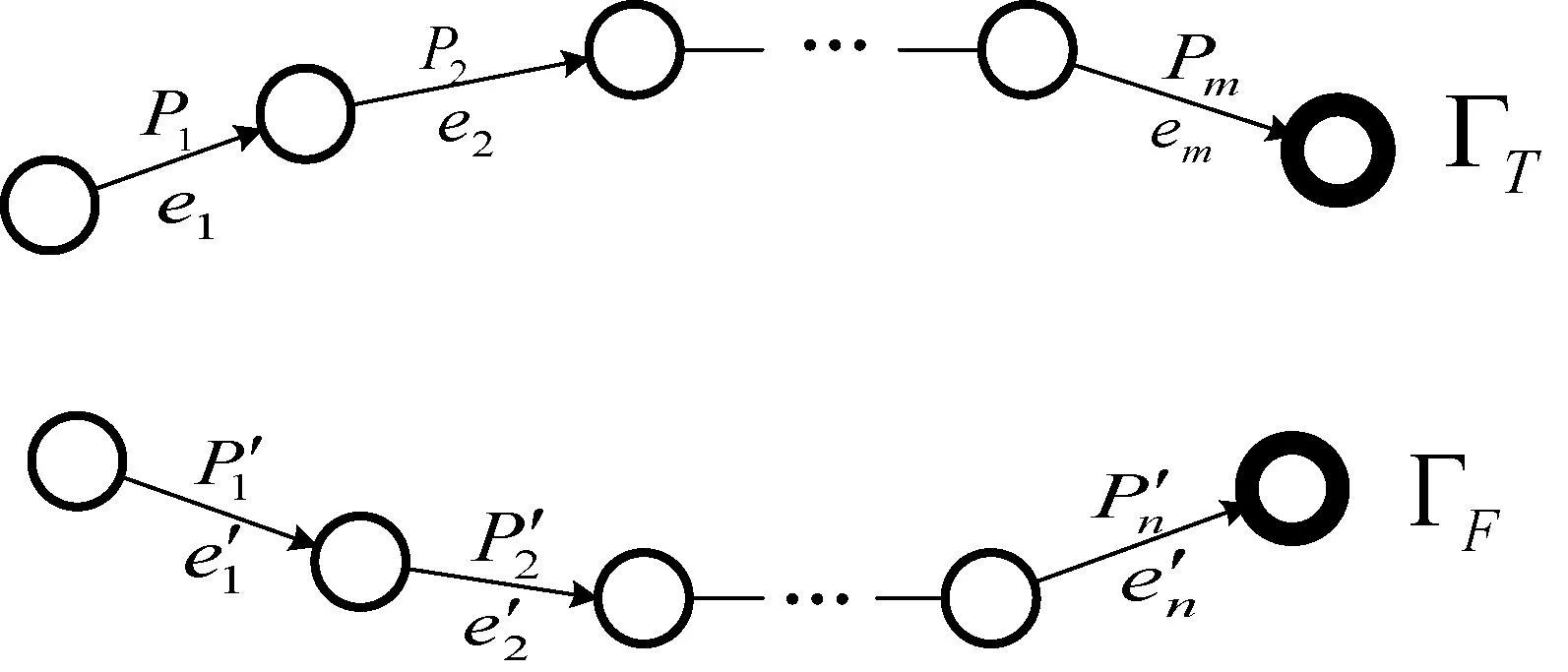
图3 反馈训练
错误路径的整体通过概率为:
对正确路径上每条路段的适宜系数加权值进行放大,设路段为ei,则放大增量为:

4实际测试
该技术应用于实际生产环境中,搭配200余条的国际区号概率知识库和300余条的国内区号概率知识库,配合曙光八核服务器,日均处理电话号码数据700多万条。经测试,单线程每秒可处理号码1.3万条,处理速度能够满足实际应用的需要。
如表1所示,应有本文所述的负反馈训练算法优化有限状态机,经过几轮训练后,电话号码规范解析的正确率显著提高,每日报告错例数大幅减少。在目前的实际应用中,解析正确率超过99.9%,被报告的错例基本上也都是在缺少辅助信息的情况下,人工也难以判别的输入号码。

表1 反馈效果表
以20万条国内电话号码,2万条国际电话号码作为测试数据,分别运用文本分析器、正则表达式和本文所述方法进行解析测试。测试结果如图4所示。显然,与文本分析器、正则表达式技术相比,本文所述的电话号码解析方法在正确率上具有明显优势,具有实用价值。

图4 测试对比
5结语
本文提出了一种基于竞争性有限状态机的电话号码解析与规范化方法,并提出了相应的基于负反馈的训练算法,有效解决了在存在输入差异性的场景下,对电话号码进行解析与规范化的问题。该规范化方法在实际生产环境中投入了应用,经过实践检验,取得了良好的效果,处理速度和正确率都达到了应用要求,充分证明了该方法具有工程实用性。
参考文献
[1] 义元鹏,陈启安.基于Lucene的中文分析器分词性能比较研究[J].计算机工程,2012(22):279-282.
[2] 邓凯元,姜磊.正则表达式匹配引擎性能分析[J].计算机与现代化,2011(7):105-107.
[3]MehryarM,FernandoP,MichaelRiley.Weightedfinite-statetransducersinspeechrecognition[J].ComputerSpeechandLanguage,2002,16(1):69-88.
[4] 郭宇弘,黎塔,肖业鸣,等.基于加权有限状态机的动态匹配词图生成算法[J].电子与信息学报,2014,36(1):140-146.
[5] 张倩,郭嗣琮.基于有限状态机和Trie数的分级地址模型[J].计算机应用,2013,33(3):854-857.
[6]BaumLE,PetrieT.Statisticalinferenceofprobabilisticfunctionsoffinitestatemarkovchains[J].TheAnnalsofMathematicalStatistics,1966,37(6):1554-1563.
[7]BaumLE,EagonJA.AninequalitywithapplicationstostatisticalestimationforprobabilisticfunctionsofMarkovprocessesandtoamodelforecology[J].BulletinoftheAmericanMathematicalSociety,1967,73(3):360-363.
[8]JohnLafferty,AndrewMcCallum,FernandoPereira.Conditionalrandomfields:probabilisticmodelsforsegmentingandlabelingsequencedata[C]//ProcofICML,2001.
[9] 姚全珠,张杰.基于数据挖掘的搜索引擎技术[J].计算机应用研究,2006(11):29-30.
[10] 温锐,朱巧明,李培峰.HMM和负反馈模型在词性标注中的应用[J].苏州大学学报:自然科学版,2005(3):39-42.
STANDARDISATION AND ANALYSIS OF PHONE NUMBERS BASED ON WEIGHTED FSM
Huang Ming1,2Lin Jiajun1Fang Nan2
1(College of Information,East China University of Science and Technology,Shanghai 200237,China)2(Shanghai 104 Research Institute,Shanghai 200032,China)
AbstractWe proposed a competitive FSM-based phone numbers analysis and standardisation method in light of the problem that in social data processing the phone numbers data are written in various section formats and are difficult to analyse and utilise, and presented the corresponding negative feedback-based training algorithm as well. By verification with practical applications, this standardisation approach can meet the application requirements in both processing speed and accuracy, this effectively solves the problem of analysing and standardising phone numbers under the circumstance with input differences, and has preferable project applicability.
KeywordsFinite-state machine (FSM)Phone numberText analyseStandardisationNegative feedback training
收稿日期:2015-01-09。黄明,工程师,主研领域:数据挖掘。林家骏,教授。方楠,工程师。
中图分类号TP391
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.019
猜你喜欢
数学小灵通(1-2年级)(2021年5期)2021-07-21
小学生学习指导(低年级)(2020年6期)2020-07-25
故事会(蓝版)(2020年1期)2020-01-19
北京航空航天大学学报(2019年9期)2019-10-26
奥秘(创新大赛)(2019年10期)2019-10-24
小天使·一年级语数英综合(2017年9期)2017-10-20
数学小灵通·3-4年级(2017年9期)2017-10-13
广西科技大学学报(2015年4期)2015-02-27
小说月刊(2014年1期)2014-04-23
空间控制技术与应用(2010年5期)2010-12-23
