
基于Spark的OS-ELM并行化算法
2016-07-06 01:50:18邓万宇杨丽霞
西安邮电大学学报 2016年2期
邓万宇,杨丽霞
(西安邮电大学 计算机学院,陕西 西安 710121)
基于Spark的OS-ELM并行化算法
邓万宇,杨丽霞
(西安邮电大学 计算机学院,陕西 西安 710121)
摘要:针对Spark平台的弹性分布式数据集并行计算框架机制,提出一种在线连续极限学习机并行处理的改进算法。利用分离在线连续极限学习机矩阵之间的依赖关系,将大规模数据中的高度复杂的矩阵分布到Spark集群中并行化计算, 并行计算多个增量数据块的隐藏层输出矩阵,实现OS-ELM对矩阵的加速求解。实验结果表明,该算法在保持精度的同时可有效缩短学习时间,改善了大数据的扩展能力。
关键词:在线连续极限学习机;大数据;Spark;并行计算
在线连续极限学习机[1](onlinesequentialextremelearningmachine,OS-ELM)是极限学习机(extremelearningmachine,ELM)有效支持在线连续学习的改进算法之一,已广泛应用在数据拟合、分类预测、动态噪声控制等领域[2]。
OS-ELM算法受制于庞大的数据量、机器配置(如CPU、内存、磁盘)等资源,为提高集成在线顺序极限学习机的分类准确率提出一种集成方法[3];通过调整网络结构给出了一种改进的在线序列ELM算法[4]。这些方法都是在单机串行环境下运行,不仅耗时而且也不能很好地执行分类和回归分析任务。在并行环境下,OS-ELM只少量在MapReduce分布式框架[5]运行,但MapReduce中的大量磁盘I/O操作导致其响应延迟加剧,尤其在面对OS-ELM运算密集的机器学习算法时更需要用户具备非常专业的程序优化能力和深度优化并行调度策略。
本文拟通过Spa-rk平台的弹性分布式数据集(ResilientDistributedDatasets,RDD)并行计算框架[6-7],对OS-ELM进行并行化设计,以期改善OS-ELM算法对数据规模增大的适应性。
1OS-ELM算法描述
OS-ELM是针对动态数据应用研制的在线增量式快速学习算法[2]。假设输入样本N个,第j个样本设定的训练集
Ω={(xj,tj)|xj=(xj1,…,xjn)T∈Rn,
tj=(tj1,…,tjm)∈Rm,j=1,2,…,N}
其中xj=(xj1,…,xjn)T为输入数据,tj=(tj1,…,tjm)T为期望输出数据,n为输入样本数,m为样本类别。
神经网络模型为
(j=1,2,…,N)。
(1)
隐含层节点数为L,随机生成输入层与隐藏层的连接权值ai和隐含层阈值bi,βi为第i个隐藏层节点到输出节点的输出权值。当运用增加型隐藏层节点时对第j个样本,第i个隐藏层结点来说,隐藏层输出为G(ai,bi,xj)=g(ai·xj+bi)。OS-ELM算法包括初始化阶段和在线连续学习阶段两个阶段[8-9]。
计算初始隐藏层输出矩阵
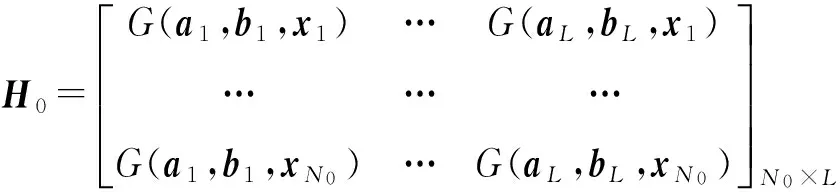
(2)
已知目标输出
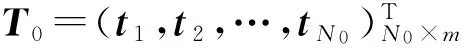
(3)
计算初始输出权值β0也就是计算‖H0β-T0‖最小值问题[10]。由式(1)可以转写为矩阵形式
HB=T[10],
又由β=H†T,H†=(HTH)-1HT得出
(4)
其中

(2)在线连续学习阶段:Mk+1,βk+1的运算都需要计算中间变量Hk+1。当输入第k+1个样本数据,计算隐含层的输出矩阵Hk+1,则输出权值βk+1可表示为
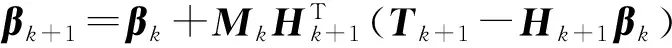
(5)

(6)
其中I为单位矩阵。
2OS-ELM并行化设计及实现
2.1基本原理
根据OS-ELM算法矩阵之间的依赖关系,在线阶段每次新到来的增量训练数据集的输出向量都要依赖于前一个数据集的输出进行更新。对计算每个增量训练数据集的隐藏层输出矩阵之间互不影响,对其可进行并行化处理。
OS-ELM算法利用增量块来选取训练样本,即从分布式文件系统(HighDensityFixedServices,HDFS)接收k个数据样本,每个数据块按Hadoop平台所设块的大小进行分块,对数据进行RDD封装,形成多个RDD。每个RDD都分成不同分片,每个分片中的每条记录都需要进行一次Map操作,当数据的记录量过多时会加消耗,使用MapPartition来代替Map对每个分片进行计算 。计算该数据集的隐含层输出矩阵Hk,然后将每一组增量数据
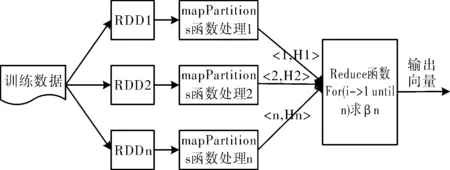
图1 基于Spark的OS-ELM算法框架
2.2基于Spark的OS-ELM算法设计
为了实现对增量训练数据块隐藏层输出矩阵并行化设计,对OS-ELM算法进行改进。该改进算法命名为基于Spark在线连续极限学习机并行算法(SPOS-ELM)。
SPOS-ELM算法如下。
输入:训练数据集
Ω={(xj,tj)|xj=(xj1,…,xjn)T∈Rn,
tj=(tj1,…,tjm)T∈Rm,j=1,2,…,N}
隐藏层节点个数L,训练数据块k+1。
输出:k+1块训练数据集的输出向量βk+1。
步骤1初始化阶段,随机生成的隐藏层输入权值ai,隐藏层阈值bi。
步骤2根据式(2)计算初始隐藏层输出矩阵H0。
步骤3根据式(4)计算初始输出权值β0。
步骤4在线学习阶段,并行计算增量k+1个数据块的隐藏层输出矩阵(H1,…,Hk+1)。将中间变量隐藏层输出矩阵的分布式求解得出的Hk+1进行缓存,并用Spark RDD形式对训练完成的中间变量Hk+1进行封装。
步骤5根据式(5)和式(6)循环迭代训练计算出(M1,M2,…,Mk+1)
步骤6根据式(5)依次计算(β1,β2,…,βk+1),输出最后β值。
2.3基于Spark的OS-ELM算法实现
OS-ELM算法在Spark上的并行实现主要分为隐藏层输出矩阵的分布式求解过程和隐藏层输出矩阵的Reduce过程。
(1)隐藏层输出矩阵的分布式求解过程
当数据集合Ω的RDD分成若干分片,为了避免大量不必要的通信开销,选择将主节点参数复制到各从节点上,而不是传递给各分片。广播变量[10]是一种缓存于所有从节点的只读型变量,应用于所有从节点的数据分片。
输入:Spark集群主节点构造隐藏层权值ai,隐藏层阈值bi,i=1,…,k,隐藏层节点L个,激励函数g(xi),并将ai,bi,g(xi),以广播变量的形式分发到各个从节点。
输出:隐藏层输出矩阵Hi,目标输出Ti。
各个从节点计算每个增量样本的隐藏层输出矩阵Hi,并汇总各个从节点的结果给主节点。
(2)隐藏层输出矩阵的Reduce过程
输入:(key,value)key是每个增量块的序号,value是每个增量块序号所对应的隐藏层输出矩阵和目标输出向量Hi和Ti。
输出:k+1块数据集输出权值βk+1。
步骤1通过各从节点给主节点的结果进行迭代计算输出向量βk+1。
步骤2根据式(5)和式(6)循环计算出(M1,M1,…,Mk+1)。
步骤3根据式(5)依次计算(β1,β2,…,βk+1),输出最后β值。
3实验结果与分析
3.1实验设置
实验采用一台PC作为主节点和服务器,5台PC作为计算节点即从节点。软硬件配置为4核XeonE5440(2.83G)CPU; 16GBytes内存;Ubuntu14.04操作系统;IDEA开发工具;scala开发语言[12];Hadoop2.5.0;Java1.7.0_74;Spark1.3.1。
对基于Spark平台的OS-ELM并行算法分别在精度、训练时间和加速比等3个方面进行测试比较。所使用数据集均为LIBSVM数据[13-14]。从LIVSVM数据中选定Shuttle、Ijcnn、Covtype3种真实的分类数据集以及CaliforniaHousing、Servo、Bank、Delta-Ailerons4种回归数据集对该并行算法性能进行验证。数据信息分别如表1和表2所示。
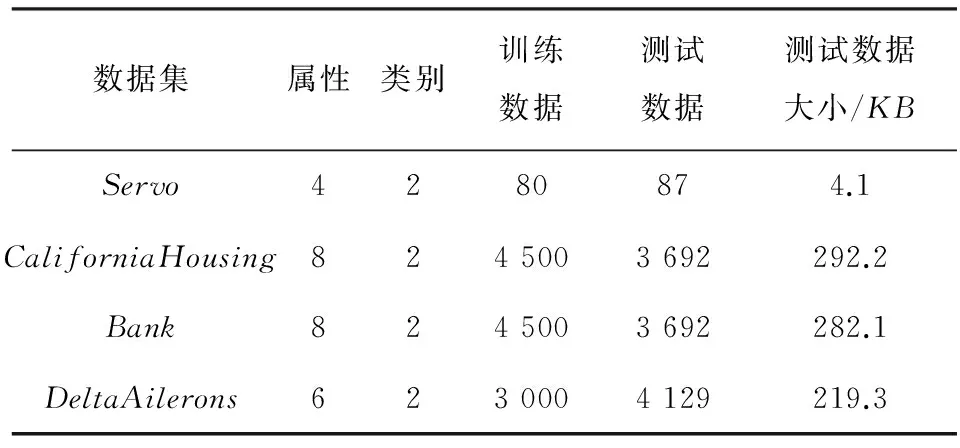
表1 回归数据集信息
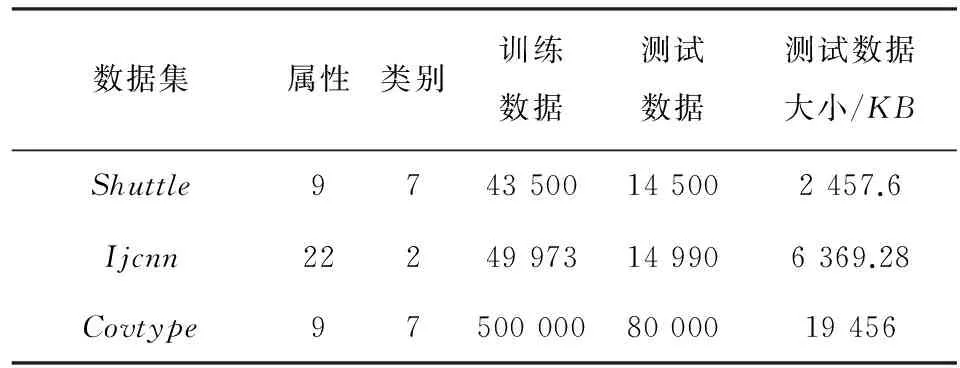
表2 分类数据集信息
3.2评估结果
3.2.1真实数据的精确度测试
利用表1和表2的数据集在Spark集群通过并行OS-ELM算法程序对各个数据集进行测试。表3和表4的结果分别为回归和分类数据集在程序中的测试结果。
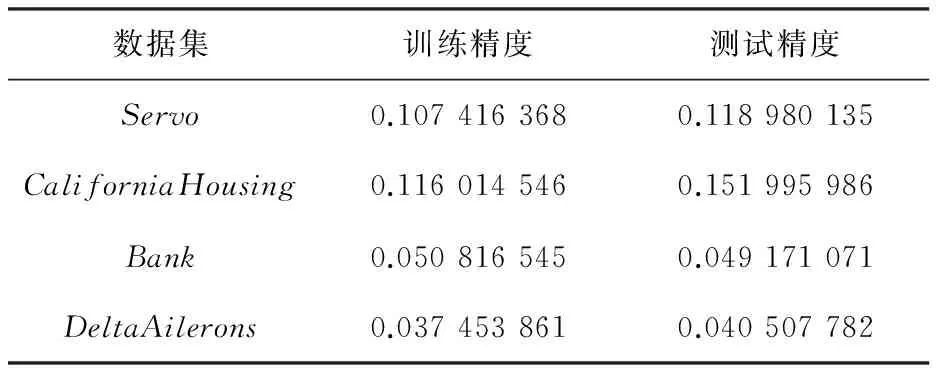
表3 回归数据的评估结果
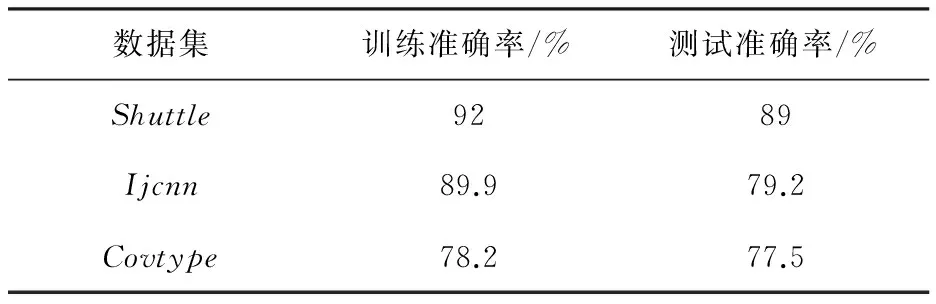
表4 分类数据的评估结果
可以看出SPOS-ELM的训练精度与原始OS-ELM没有多大区别,证明该改进算法的精度准确性和算法改进的正确性。
3.2.2检查训练速度与节点之间的关系
通过控制Spark集群节点数量从 1、2、3、4、5、6 来检查各个数据集在不同节点的训练速度。通过图2显示了不同数据集在各个节点6上的训练时间。
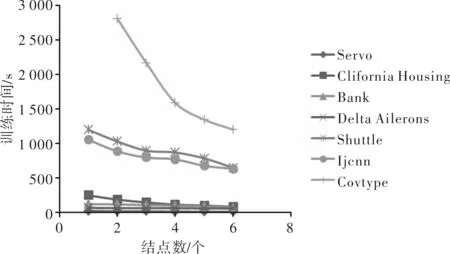
图2 各个数据集在不同节点的训练时间
由图2可以看出,随着节点数的增多,所有的数据集的训练速度加快,训练的时间缩短。如果数据集较小,随着节点数增多时间上并没有很明显的改变。然而,对于数据集越大的数据,数据集的训练速度进一步加快,说明SPOS-ELM算法并不适合数据集较小的数据。
3.2.3扩展性测试
对数据做可伸缩性测试,用于可伸缩性测试的参数如表5所示。训练样本的数量和属性扩展基于CaliforniaHousing以循环的方式复制原始数据。

表5 规范合成可伸缩性测试的数据
图3为可伸缩性数据CaliforniaHousing加速比与节点的数量的关系。训练数据对取值范围内大小为40k,320k和1 280k的加速比进行比较。
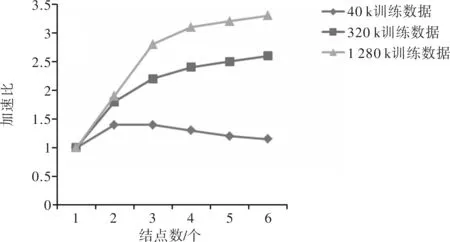
图3 可扩展性数据加速比与节点的关系
由图3可见,随训练数据增大,对于SPOS-ELM加速比更大。但是,随着节点数增多,多个节点和PC之间的协同操作的开销成本增加。越小的训练数据随着节点增多加速比反而变得较低,从而进一步证实SPOS-ELM适合大规模学习。
4结束语
基于Spark平台对OS-ELM算法进行并行化处理。通过利用分离在线连续极限学习机矩阵之间的依赖关系,进行矩阵分解。以在精度准确性、加速比、扩展性等指标从理论和实验结果两个方面对并行算法进行了评价。实验结果表明,该算法在保持精度的同时也成功实现算法效率的提升,比原始串行OS-ELM具有更好的可扩展能力,提高了算法的准确性。
参考文献
[1]HUANGGB,ZHUQY,SIEWCK.ExtremeLearni-ngMachine:TheoryandApplications[J].Neuroco-mputing,2006,70(1):489-501.
[2]LIANGNY,HUANGGB,SARATCHANDRANP,etal.Afastandaccurateonlinesequentiallearningalgorith-mforfeedforwardnetworks[J].IEEETransactiononNeuralNetworks, 2006, 17(6):1411-1423.
[3]付倩, 韩飞, 叶松林. 一种改进的集成在线顺序极限学习机[J]. 无线通信技术, 2013, 22(3):39-44.
[4]杨乐, 张瑞. 在线序列ELM算法及其发展[J]. 西北大学学报:自然科学版, 2012, 42(6):885-889.
[5]VERMAA,LLORAX,GOLDERGDE,etal.ScalingG-eneticAlgorithmsUsingMapReduce[C]//2009NinthInternationalConferenceonIntelligentSystemsDe-signandApplications.Washington,DC,USA:IEEEComputerSociety, 2010 16(45):13-18.DOI:10.1109/ISDA.2009.181
[6]戎翔, 李玲娟. 基于MapReduce的频繁项集挖掘方法[J]. 西安邮电大学学报, 2011,16(4):37-39.
[7]王家林.大数据Spark企业级实战[M].北京:电子工业出版社, 2014:20-24;431-458.
[8]WANGB,HUANGS,QIUJ,etal.ParallelonlinesequentialextremelearningmachinebasedonMapReduce[J/OL].Neurocomputing, 2015, 149:224[2015-9-30].http://www.sciencedirect.com/science/article/pii/S092523121401145X.DOI:10.1016/j.neucom.2014.03.076.
[9]刘瑜. 基于云平台的OLAP系统研究与实现[D]. 沈阳:东北大学, 2013:48-52.
[10]HUANGGB,ZHUQY,SIEWCK.Extremelearningmachine:Theoryandapplications[J].Neurocomputing, 2006, 70(s1/3):489-501.
[11]梁彦. 基于分布式平台Spark和YARN的数据挖掘算法的并行化研究[D].广州:中山大学, 2014:14-27.
[12]ODERSKYM,SPOONL,VENNERSB.ProgramminginScala[M].ArtimaInc, 2011:5-40;51-150.
[13]FANRE,CHANGKW,HSIENCJ,etal.LIBLIN-EAR:alibraryforlargelinearclassification[J].JournalofMachineLearningResearch, 2008, 9(12):1871-1874.
[14]CHANGCC,LINCJ.LIBSVM:alibraryforsupportvectormachines.ACMTransactionsonIntelligentSystemsandTechnology[EB/OL]. [2015-09-20].http://www.csie.ntu.edu.tw/~cjlin/libsvm.
[责任编辑:祝剑]
ParallelizationofOS-ELMbasedonSpark
DENGWanyu,YANGLixia
(SchoolofComputerScienceandTechnology,Xi’anUniversityofPostsandTelecommunications,Xi’an710121,China)
Abstract:A parallel processing algorithm of online sequential extreme learning machine is proposed for elastic distributed data set parallel computing framework based on Spark platform. By separating the dependence relationship among the matrix of online sequential extreme learning machine, the highly complex matrix of large scale data is distributed to the Spark cluster for parallel processing to figure out the hidden layer output matrix of the multiple incremental data block, and thus, the accelerated solution of the matrix by OS-ELM is implemented. Experimental results show that the algorithm can effectively shorten the learning time while maintaining the accuracy, and therefore improved the ability to expand massive data.
Keywords:online sequential extreme learning machine(OS-ELM), big data, Spark, parallel computing
doi:10.13682/j.issn.2095-6533.2016.02.020
收稿日期:2015-10-27
基金项目:国家自然科学基金资助项目(61572399);陕西省科技新星资助项目(2013KJXX-29)
作者简介:邓万宇(1979-),男,博士,副教授,从事数据挖掘、机器学习与知识服务研究。E-mail: 58028654@qq.com 杨丽霞(1988-),女,硕士研究生,研究方向为数据挖掘和机器学习。E-mail:498538730@qq.com
中图分类号:TP389.1
文献标识码:A
文章编号:2095-6533(2016)02-0101-05
猜你喜欢
计算机应用(2016年12期)2017-01-13 20:06:47
科学与财富(2016年15期)2016-11-24 13:30:27
大经贸(2016年9期)2016-11-16 16:25:33
中国新通信(2016年16期)2016-10-18 10:58:44
新闻世界(2016年10期)2016-10-11 20:13:53
科技视界(2016年20期)2016-09-29 10:53:22
中国记者(2016年6期)2016-08-26 12:36:20
电脑知识与技术(2016年14期)2016-06-30 20:33:39
科技视界(2016年11期)2016-05-23 08:13:35
