
基于HBase的小文件高效存储方法
2016-06-29 09:35熊安萍熊风波
重庆邮电大学学报(自然科学版) 2016年1期
熊安萍,熊风波
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
基于HBase的小文件高效存储方法
熊安萍,熊风波
(重庆邮电大学 计算机科学与技术学院,重庆 400065)
摘要:基于Hadoop平台的相关系统得到了广泛应用。Hadoop分布式文件系统(Hadoop distributed file system,HDFS)通过分布式的工作方式,负责处理海量文件数据。对HDFS而言,海量数据中的小文件存储问题制约着系统高效工作的能力。针对海量数据中小文件读写效率低的情况,提出一种基于HBase(Hadoop database)的海量小文件高效存储方法,利用HBase的存储优势,将小文件直接存储于HBase,从而有效减少元数据节点服务器(NameNode)的负载,并对上层应用系统提供透明的访问接口。实验结果表明,该方法可以实现海量小文件的高效存储,提高HDFS环境下小文件的读写效率。
关键词:Hadoop分布式文件系统(HDFS);海量数据;HBase;小文件存储;读写性能
0引言
随着互联网的不断发展,数字信息正在呈爆炸式增长,如何高效地处理和存储海量数据成为一个亟待解决的问题[1]。凭借其开源、易用的特点,Hadoop分布式平台已成为管理和处理海量数据的首选方案。以Hadoop分布式文件系统(Hadoop distributed file system,HDFS)为基本存储,并通过Map-Reduce计算框架提供各种服务,使得用户可以在低廉硬件环境下搭建Hadoop集群,利用HBase等组件完成海量数据的处理和分析任务[2],从而为超大数据集的处理及应用提供了一种低成本的分布式存储解决方案,因此,近年来得到了广泛的应用。
HDFS的主要工作对象是大文件,对于存储海量小文件并不合适。小文件指的是那些size比HDFS 的block size(默认64 MByte)小得多的文件。HDFS在存储小文件时存在以下具体问题。
1) 海量的小文件势必造成元数据的庞大,耗费元数据服务器的内存。这是由于HDFS采用了元数据节点与数据存储节点分离的存储架构,对于文件的访问往往都通过其元数据节点服务器(NameNode),而NameNode把元数据放置在内存中,所以,NameNode的内存大小成了分布式文件系统容纳文件数目的瓶颈。一般来说,每一个文件或Block的元数据需要占据150 Byte左右的空间,因此,如果有100万个文件,至少需要300 MByte内存。每个小文件作为一个块存储,当存在海量小文件时,NameNode节点内存将无法支撑。
2) 小文件存储和读取效率不佳。因为HDFS设计初衷是便于存储超大文件,具有较大的数据吞吐量,以一定延时为代价。实验表明,HDFS集群存储10 GByte大文件的速度比存储10 GByte小文件的速度要快得多。同时,无法对海量小文件实现有效管理,加上内存容量的限制,海量小文件的访问效率严重下降。
然而,在实际应用中,小文件比比皆是,如个人应用中产生的日常文件及web应用中产生的小文件[3]等。当海量的小文件在HDFS文件系统中进行存储时,这些小文件的元数据信息将会占用 NameNode节点中的大量内存空间,对NameNode节点造成极大负载[4]。同时,每次访问小文件时,都要通过 NameNode 节点获取路径等信息,因此,大量小文件的并发访问势必造成NameNode 节点瓶颈,也会对整个 HDFS文件系统的性能造成严重的影响[5]。
此外, MapReduce 处理中的map 任务通常和数据块(data block)是对应的,当系统处理海量小文件时, 进行操作的map任务的数量巨大,而每一个map任务都会消耗一定量的系统资源[6], MapReduce[7]框架进行任务调度时,Map操作及Reduce操作的处理时间及消耗资源均会成倍增长,这也将导致系统的性能大幅下降。
针对HDFS中小文件存储问题,目前已有一些方法来进行解决。例如,HAR(Hadoop archive)[8]方法把一批小文件归档到一个大文件中进行存储。这种方法的问题是向归档文件中新增或者删除一个小文件时,需要对文件重新进行归档,效率很低。还有采用序列化文件方式,即通过生成 SequenceFile[9]文件而合并大量的小文件。SequenceFile 是由Hadoop API提供的一种文件支持,它可以通过将多个小文件组织起来统一存储为一系列的二进制 key/value,在这种技术中,将小文件名存入key,文件内容存入value,将小文件保存为键/值对。 但是,由于SequenceFile 结构没有建立相应的小文件到大文件的映射关系,查询小文件时就需要遍历整个 SequenceFile的目录文件,检索效率低,从而也降低了文件读取效率。
CombineFi1eInputFormat[10]是一种新的小文件合并方式,用于将多个文件合并成一个单独的split,并且,该方法在合并文件时也会考虑其存储位置。但是用户在使用这个方案时必须根据自己的需要进行编程实现。
有方案试图从系统层面上改变HDFS架构,以提高HDFS存储海量小文件时的存储速度。基本思想是将大量的小文件存储到一个数据块中,并且使用该数据块所在DataNode的内存空间存储这些小文件的元数据信息[11]。还有文献[12]提出了一种基于Hadoop海量小文件[13]的处理方法。首先对小文件进行合并,为方便小文件的管理和査询,生产以小文件名为关键字的索引文件。由于小文件的数量庞大,将索引文件存储在DataNode中缓解NameNode内存不足的压力。
这2种方法从HDFS系统层面上实现了小文件的合并问题,并减少了NameNode内存空间的浪费,但是使用DataNode的内存空间存储元数据或索引文件,对以后大量小文件的读取或检索速度造成了影响。
本文的指导思想是利用分布式列式数据库HBase直接存储小文件,减少HDFS负担。将大、小文件分别处理,如果系统判别为小文件,则直接存储于HBase数据库中,HDFS只处理其擅长的大文件。
1基于HBase的小文件高效存储方法
HBase是一个面向列的、版本化的、可伸缩的、以键值对形式来存储数据的分布式列式数据库系统[14],HBase是Hadoop平台下的一个分布式、面向列的开源数据库组件。本文方法设计了基于HBase的小文件存储逻辑架构,并设计实现了逻辑架构中的接入层。
1.1小文件存储逻辑架构
本文基于HBase的小文件存储方法采用的存储逻辑架构如图1所示。
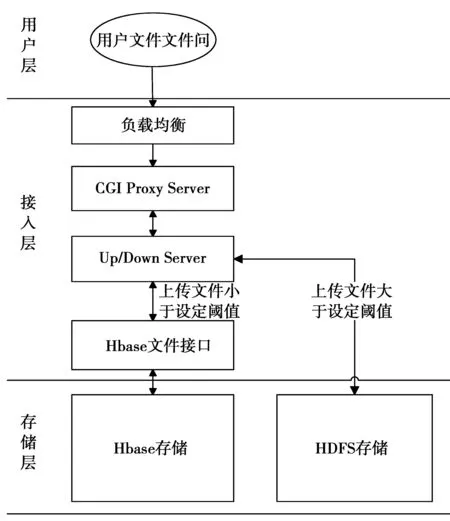
图1 小文件存储逻辑架构Fig.1 Small file storage logic architecture
该架构从上至下主要包括3层:用户层、接入层、存储层。下层为上一层提供相应服务,用户层采用HTTP协议或HTTPS协议与接入层进行交互,而接入层通过文件接口来调用对外封装好的类VFS,并与HBase存储层进行交互。在存储层中提供的文件接口为上一层提供服务,而HBase存储则实现对文件信息和文件内容的存储。
基于图1的逻辑架构,本文基于HBase的小文件存储核心在于将大、小文件分别进行处理,服务器接收到文件上传请求后,如果是大文件,则按照传统HDFS方法进行操作;而对于小文件,接入层的Up/Down Server接口将通过存储层的统一文件操作接口,将用户“标识符_文件”上传路径作为row_key,其他文件信息作为内容存储到HBase数据库表中。当有用户下载文件时,通过Up/Down Server端接收文件读取请求,从而获取用户“标识符_文件”路径信息,接入层的Up/Down Server接口通过该信息与HBase交互并读取文件内容并返回给用户。
1.2接入层设计
接入层主要负责接收用户的文件操作请求,并将请求转发给相应服务器,与存储层交互进行文件读写。接入层主要涉及Up/Down Server和CGI Proxy Server两类服务和HBase文件接口。Up/Down Server主要负责处理用户端对文件的第一类操作,即上传、下载操作,并与HBase文件接口、存储层进行文件交互,此外,也会和底层的HDFS存储层进行数据读、写交互。CGI Proxy Server主要负责处理用户端对文件的第二类操作,包括遍历文件目录、创建目录、删除目录、拷贝文件、删除文件、重命名文件等操作;并与HBase文件接口进行交互。HBase文件接口主要与存储层进行读、写交互。
CGI Proxy Server。该服务通过Http或者Https协议,接收Client端的相关文件操作请求,然后内部调用HBase文件接口API实现这些操作,其处理流程如图2所示。
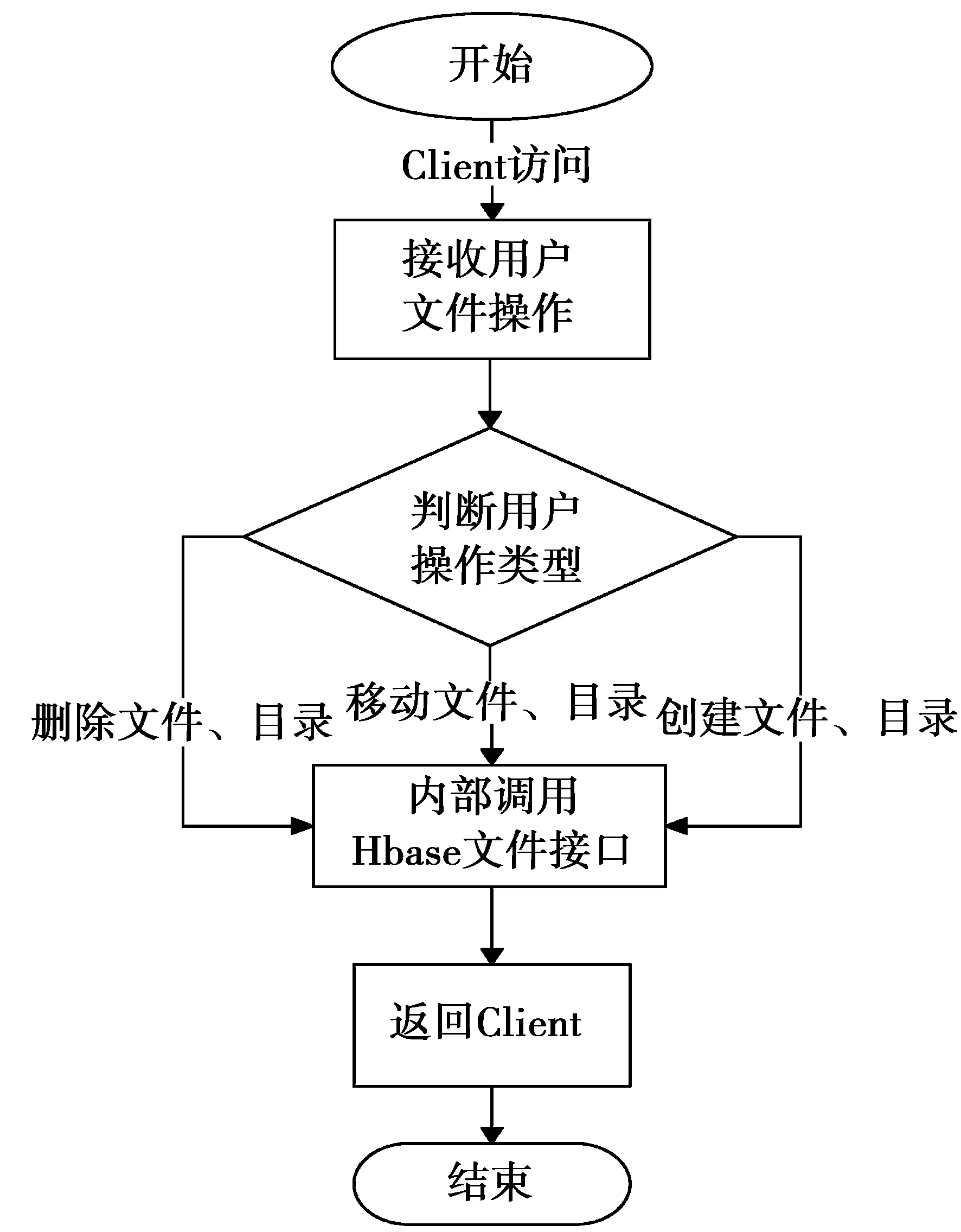
图2 CGI Proxy Server服务流程Fig.2 CGI Proxy Server service process
Up/Down Server。该服务对接收到的上传文件请求,先判断文件大小是否大于设定阈值,如果上传文件被判定为大文件,则调用HDFS文件写入API上传文件到HDFS;如果是小文件则内部调用HBase文件接口实现文件上传,其处理流程如图3所示。
HBase文件接口。主要用于将HBase关于文件和目录操作的接口封装成类似VFS的mkdir,rm接口函数。当底层文件操作系统发生变化时,不会导致上层调用接口的改变。该接口接收来自Up/Down Server和CGI Proxy Server的文件操作请求,进行必要的预处理,例如收集文件信息等,再调用相应的HBase文件读写API,将文件信息和文件内容写入HBase或者读取文件内容返回给上层服务。写入文件接口伪代码如下。
public boolean insertData(String tableName, String rowKey,String[] cols, String[] values) {
HTablePool pool = new HTablePool(configuration, 1000);
HTable table = (HTable) pool.getTable(tableName);
Put put = new Put(rowKey.getBytes());
for (int i = 0; i < cols.length; i++) {
put.add(cols[i].getBytes(),null, values[i].getBytes());
}
table.put(put);
return true;}
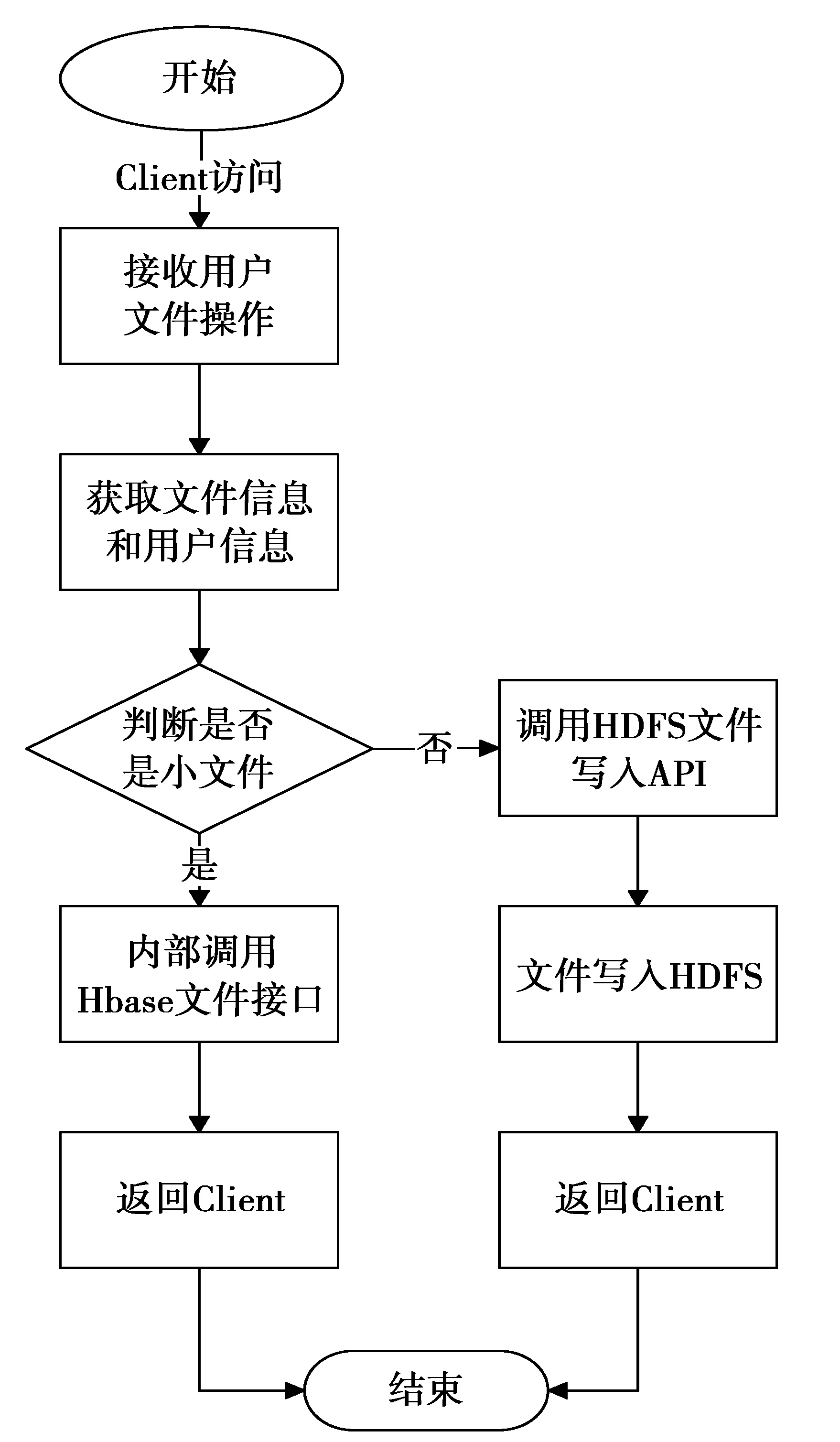
图3 Up/Down Server服务流程Fig.3 Up/Down Server service process
下载文件时,首先内部调用HBase文件接口读取文件,如果读取成功,直接返回文件内容给Client,如果读取失败,则调用HDFS文件读取API进行下载目标文件,处理流程如图4所示。
读取文件接口伪代码如下。
public HashMap
QueryByCondition1(String tableName, String rowkey) {
HTablePool pool = new HTablePool(configuration, 1000);
HTable table = (HTable) pool.getTable(tableName);
HashMap
Get scan = new Get(rowkey.getBytes());
Result r = table.get(scan);
for ( KeyValue keyValue : r.raw() ) {
result.put(new String (keyValue.getFamily () ) ,
new String(keyValue.getValue()));
}
return result; }
1.3文件读写
1.3.1文件存储步骤
首先判断文件大小,对大小文件分别处理,当通过接入层后,大文件直接存储于HDFS中,小文件则存储于HBase数据表中。详细步骤如下。
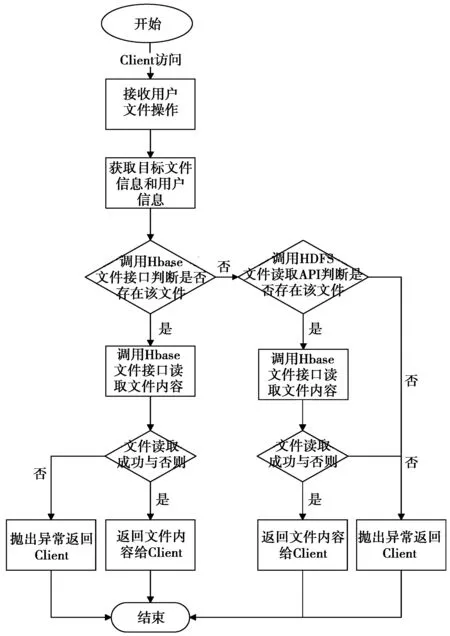
图4 Up/Down Server文件读取流程Fig.4 File read process of Up/Down Server
步骤1用户上传待存储的文件。
步骤2接入层Up/Down Server判断文件大小,当文件大小大于设定阈值,转步骤4;否则,转步骤3。
步骤3Up/Down Server端进一步对文件请求进行解析,从请求中获取用户标识符、文件上传路径等信息,利用用户“标识符_文件”(上传路径的标识信息)作为Row Key在存储层的HBase记录表中进行检索,如有记录存在,则表明目标上传路径中已上传有相同文件名的文件,此时,向用户层返回提示信息,提示用户端已上传文件。否则Up/Down Server端向HBase存储层发起创建相应文件记录和写入文件的请求。转步骤5。
步骤4Up/Down Server端直接调用HDFS文件写入接口进行操作。
步骤5将文件信息写入HBase相应表。
1.3.2文件读取步骤
根据用户“标识符_文件”路径与HBase文件存储记录表Row_key的比较来实现文件读取。
步骤1Up/Down Server端接收文件读取请求,获取用户“标识符_文件”的路径信息,转步骤2。
步骤2Up/Down Server端利用所获得的信息在HBase数据表中进行检索,如果定位到用户所请求读取文件的记录。转步骤3,否则转步骤4。
步骤3Up/Down Server端读取HBase文件记录中的列簇,由索引层直接返回“文件内容”列的数据给用户端,读取文件过程结束。
步骤4调用传统HDFS文件读取接口进行操作。
2实验
为了验证上文所提小文件存储方案的高效性,本文对传统HDFS、基于HBase小文件高效存储方法进行读写的对比实验。
2.1实验数据集
本文选择了大量大小为1 kByte-16 kByte小文件作为实验测试数据集。其中,1 kByte,2 kByte,4 kByte,8 kByte,16 kByte各500万个。
2.2实验环境
本实验环境为4个节点的Hadoop集群,每个节点的配置为16核Intel Xeon CPU 2.4GHz,32 Gyte内存服务器。网络环境是千兆光纤。其中一台机器作为NameNode,其余3台机器全部作为DataNode和RegionSever。
HBase Master和HDFS namenode运作在同一个节点,zookeeper集群运行在除NameNod外的3台机器上。每台节点安装的操作系统为Cent OS5.4,Hadoop版本2.0,HBase版本HBase-0.96,JDK的版本1.6.0_35。
2.3实验结果分析
本文对HDFS,HBase的存储方法在小文件存取方面进行了实验分析,分析结果如图5,图6所示。
从图5的实验结果可以看出,基于HDFS的写入速度为20-33 MByte/s,基于HBase的高效存储方法的写入速度为60-80MByte/s,这是因为在写入小文件的时候,基于HBase储存方法是直接写入HBase数据表中,而基于HDFS还需要管理元数据和数据块等信息,所以,本文提出的方法在写入速度上有较大提升。
图6中,在小文件读取方面,基于HDFS读取速度为50-60 MByte/s,基于HBase的高效存储方法读取速度为111-120 MByte/s,HDFS需要先访问元数据,再与datanode交互进行读取,而HBase利用其自身索引机制,能够对数据表中信息进行快速读取。实验结果表明,在小文件读写方面,本文提出的基于HBase的小文件高效存储方法比HDFS平均读取速度有显著提高,写入速度提升也明显。
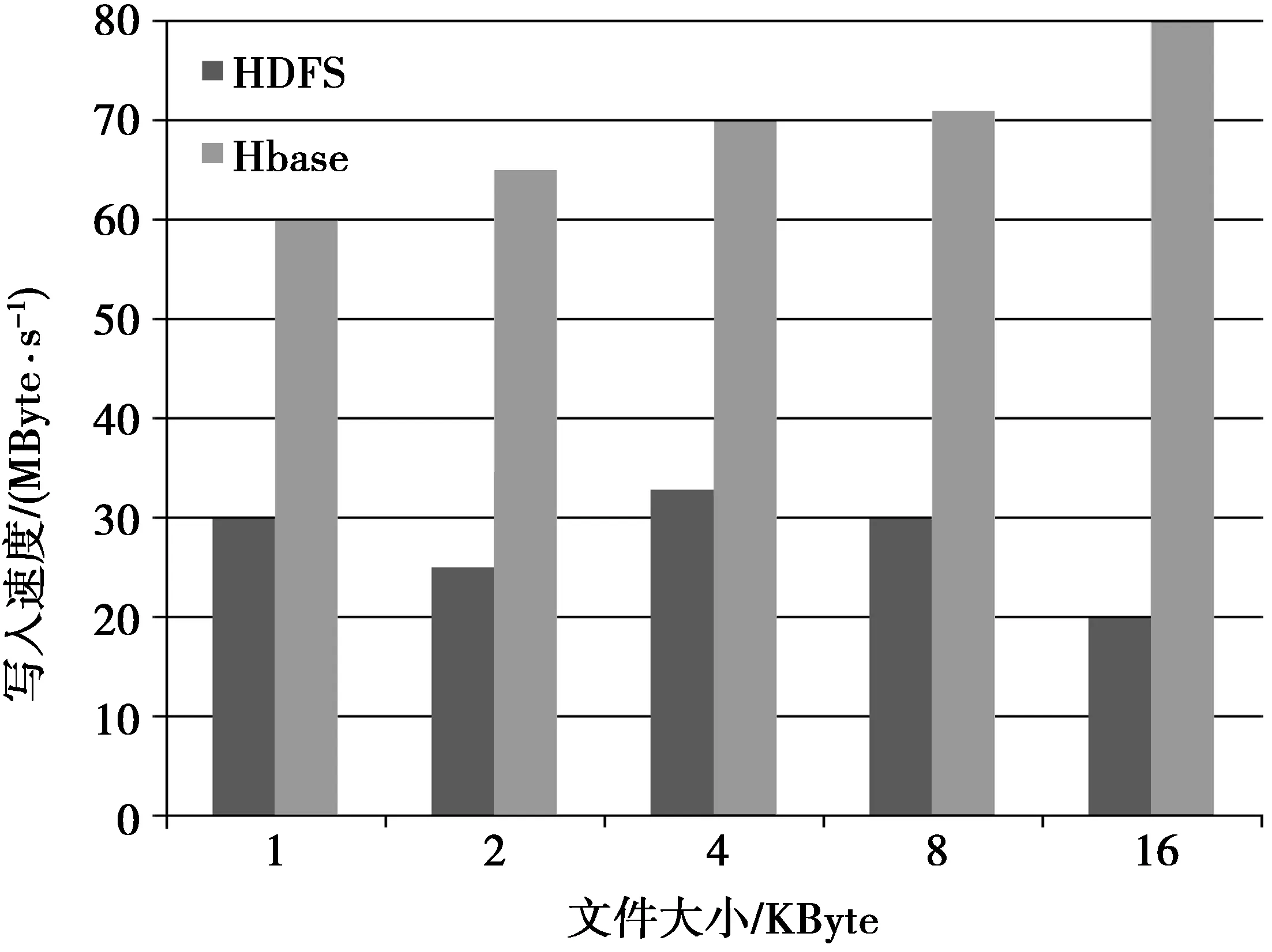
图5 小文件写入Fig.5 Small files written in HBase
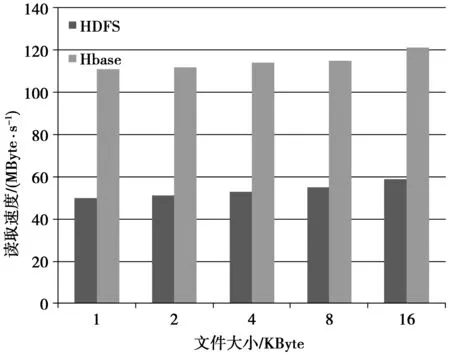
图6 小文件读取Fig.6 Small file read from HBase
3总结和未来工作
本文提出的基于HBase的小文件高效存储方法在文件写入的时候,将小文件直接存储于HBase表结构中,在读取的时候利用HBase自身索引机制实现高效读取,并且相对于HDFS而言,该方法减少了HDFS大量小文件的元数据信息管理的过程,综上所述,该方法用于海量小文件的读写是高效可行的。在下一步工作中,将继续研究海量数据中大、小文件的统一高效存储方案。
参考文献:
[1]胡继宽,汪维青.一种适宜于海里数据的快速分组排序算法[J].西南大学学报:自然科学版,2010,32(6):173-176.
HU Jikuan, WANG Weiqing. A Quick Group-Sort Algorithm for a Great Deal of Data[J]. Journal of Southwest University: Natural Science Edition, 2010, 32(6):173-176.
[2]WHITE T,周敏奇,王晓玲,等.Hadoop权威指南[M].2版.北京:清华人学出版社,2011:73-80.
WHITE T,ZHOU Minqi,WANG Xiaolin, et al. Translate. The Definitive Guide of Hadoop[M]. 2nd ed.Beijing: Tsinghua University Press,2011:73-80.
[3]LIU X, HAN J, ZHONG Y. Implementing WebGIS on Hadoop: A case study of improving small file I/O performance on HDFS[C]//CLUSTER'09 IEEE International Conference on Cluster Computing and Workshops. Washington DC: IEEE Computer Society,2009:1-8.
[4]陆嘉恒.实战Hadoop[M].北京:机械工业出版社,2012:108-132.
LU Jiaheng.Hadoop in actual combat[M].Beijing: China Machine Press,2012:108-132.
[5]VORAPONGKITIPUN C, NUPAIROJ N.Improving performance of small-file accessing in Hadoop[C]//2014 11th International Joint Conference on IEEE Computer Science and Software Engineering (JCSSE). Washington DC:IEEE Computer Society,2014:200-205.
[6]AISHWARYA K, SREEVATSON M C, BABU C. Efficient prefetching technique for storage of heterogeneous small files in Hadoop Distributed File System Federation[C]//2013 Fifth International Conference on IEEE Advanced Computing (ICoAC). Washington DC:IEEE Computer Society, 2013: 523-530.
[7]DEAN J, GHEMAWAT S.MapReduce: simplified data processing on large clusters[EB/OL]. (2005-08-05)[2015-03-01]. http://wenku.baidu.com/link?url=_mdOT_PQWOa1JlJHm4PG9VNF8VgtIdZhfjne1Eu6n6Z XenKuzZbkMI8xGgHpi2UIJEZmyQkTTmD6qUKPZeLGMkbbCPLEp9A73RdTVls9h1.
[8]范东来.Hadoop海量数据处理技术详解与项目实战[M]. 北京:人民邮电出版社,2015:20-21.
FAN Donglai. HadoopMass data processing technology explanation and the project of actual combat[M].Beijing: Posts & Telecom Press,2015:20-21.
[9]蔡斌,陈湘萍.Hadoop技术内幕:深入解析Hadoop Common和HDFS架构设计与实现原理[M].北京:机械工业出版社,2013:90-121.
CAI Bin, CHEN Xiangping. Hadoop technology insider:In-depth analysis the principle of Hadoop common and HDFS of the architecture design and implementation[M]. Beijing: China Machine Press, 2013:90-121.
[10] NARAYAN S, BAILEY S,DAGA A. Hadoop Acceleration in an OpenFlow-Based Cluster[C]// High Performance Computing, Networking, Storage and Analysis (SCC), 2012 SC Companion.Washington DC:IEEE Computer Society, 2012:535-536.
[11] JIANG L, LI B, SAONG M. THE optimization of HDFS based on small files[C]//2010 3rd IEEE International Conference on IEEE Broadband Network and Multimedia Technology (IC-BNMT).Washington DC:IEEE Computer Society,2010: 912-915.
[12] 泰冬梅.基于Hadoop的海量小文件处理方法的研究[D].辽宁:辽宁大学,2011:8-10.
TAI Dongmei.Research approach of massive small files Hadoop-based[D].Liaoning:Liaoning university, 2011:8-10.
[13] MACKEY G, SEHRISH S, WANG J. Improving metadata management for small files in HDFS[C]//International Conference on Cluster Computing and Workshops. Washington DC: IEEE Computer Society, 2009:1-4.
[14] 文艾,王磊.高可用性的HDFS:Hadoop分布式文件系统深度实践[M].北京:清华大学出版社,2012:250-267.
WEN Ai,WANG Lei.High availability of HDFS:The depth practice of distributed file system into Hadoop[M].Beijing:Tsinghua university press,2012: 250-267.
Efficient storage method of small-file based on HBase
XIONG Anping, XIONG Fengbo
(College of Computer Science and Technology, Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R. China)
Abstract:In recent years, related systems have been widely used based on Hadoop. Particularly, Hadoop distributed file system(HDFS) is responsible for handling big data files by distributed way of working. However, in terms of HDFS, the problem of small-file storage in Big data is restricted by the ability of HDFS to work effectively. In the view of the lower efficiency of reading and writing for small-file in big data, this paper proposes an efficient storage method of Small-File based on HBase. The storage advantage of HBase is used in this paper; small files are stored in HBase directly; it reduces the NameNode load and provides the transparent access interface to the upper-level application system. The experimental result shows that the method implements efficient storage for a lot of small files, in addition, the efficiency performance of reading and writing for small files in HDFS is improved by this method.
Keywords:Hadoop distributed file system(HDFS); big data; HBase; small-file storage; performance of reading and writing
DOI:10.3979/j.issn.1673-825X.2016.01.019
收稿日期:2015-02-03
修订日期:2015-10-20通讯作者:熊风波515377984@qq.com
中图分类号:TP393.0
文献标志码:A
文章编号:1673-825X(2016)01-0125-06
作者简介:

熊安萍(1971-),女,四川人,教授,硕士生导师,主要研究方向为软件体系结构、操作系统内核、高性能计算。E-mail: xiongqp@cqupt.edu.cn。

熊风波(1990-),男,重庆人,硕士研究生,主要研究方向为高性能计算。E-mail: 515377984@qq.com。
(编辑:刘勇)
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
机械工业标准化与质量(2022年6期)2022-08-12
装备制造技术(2020年2期)2020-12-14
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
商品与质量(2019年34期)2019-11-29
当代陕西(2019年14期)2019-08-26
测控技术(2018年5期)2018-12-09
信息安全研究(2016年4期)2016-12-01
中学数学杂志(初中版)(2016年5期)2016-11-01
中国卫生(2015年12期)2015-11-10
