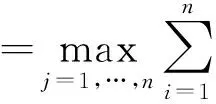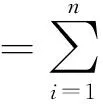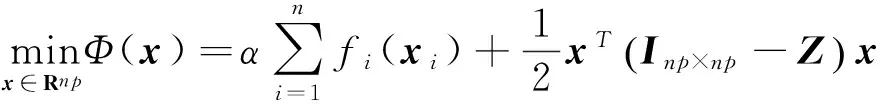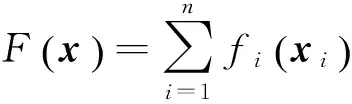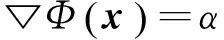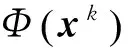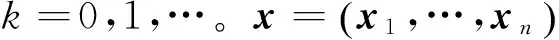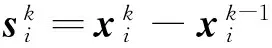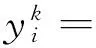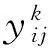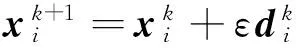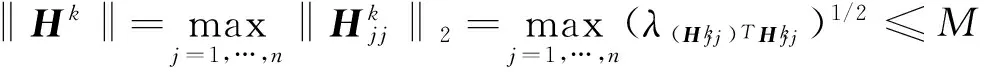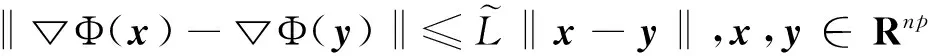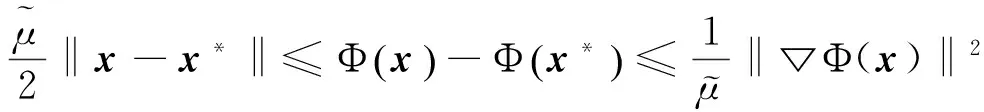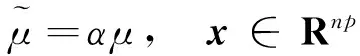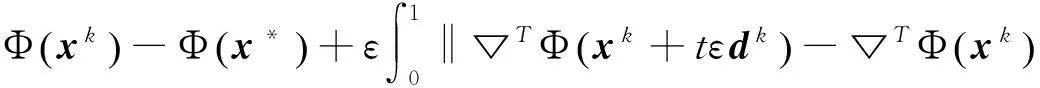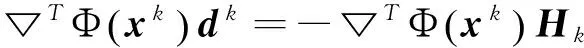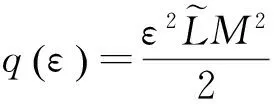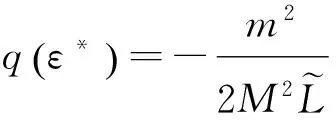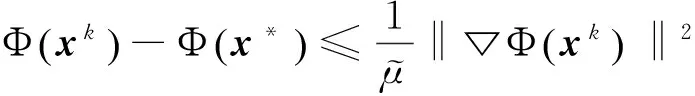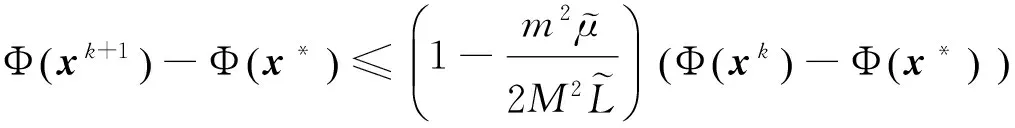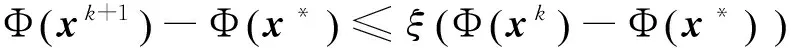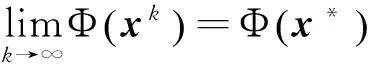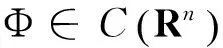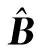求解无约束一致性优化问题的分布式拟牛顿算法
2016-06-24 10:25:16于慧慧王永丽陈勇勇周秀娟
山东科技大学学报(自然科学版) 2016年3期
于慧慧,王永丽,陈勇勇,周秀娟
(1.山东科技大学 数学与系统科学学院,山东 青岛 266590;2.山东科技大学 信息科学与工程学院,山东 青岛 266590)
求解无约束一致性优化问题的分布式拟牛顿算法
于慧慧1,王永丽1,陈勇勇1,周秀娟2
(1.山东科技大学 数学与系统科学学院,山东 青岛 266590;2.山东科技大学 信息科学与工程学院,山东 青岛 266590)
摘要:本文主要针对网络中各个节点相互协作,最大限度地使本地费用函数的总和最小的无约束一致性优化问题,提出了一类分布式拟牛顿算法。算法仅利用了目标函数的一阶导数信息,每步通过选取一个满足拟牛顿方程的正定对角矩阵来作为费用函数Hesse矩阵逆的校正矩阵,克服了校正矩阵的非稀疏性对算法分布式实现造成的困难,减少了计算量和存储空间。在适当条件下,证明了分布式拟牛顿算法的全局收敛性及局部线性收敛速度,并通过数值实验验证了算法的优越性。
关键词:无约束; 一致性优化; 分布式拟牛顿算法; 全局收敛; 线性收敛
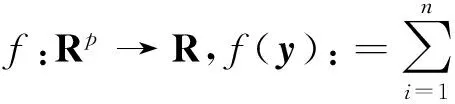
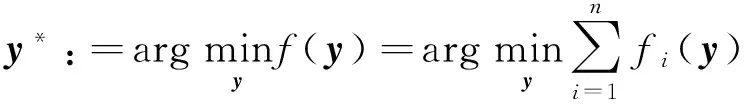
(1)
其中y*表示问题(1)的最优解。在现实生活中,这种形式的问题有很多,例如,大数据分析[1],分布式传感器网络[ 2-5 ]和分布式控制[6]等。
求解问题(1)的分布式方法分为两类,一类是基于费用函数一阶信息的方法,该类方法中研究较多的是分布式梯度法[7-10],分布式交替方向乘子法[11-13]和分布式对偶平均法[14-15]。虽然这些算法之间存在着很大的差异,但基本思想都可以归结为先进行本地下降步,然后与相邻节点进行变量交换和信息整合。由于该类计算仅涉及到一阶信息,导致了对下降方向曲率估计的不准确性,便得收敛速度较慢。另一类分布式方法是基于费用函数二阶信息的方法,即分布式牛顿类算法,主要的文献有[16-17]等。目前,对分布式牛顿类算法的研究较少,这主要是因为牛顿法的分布式实现比较困难且计算目标函数的二阶信息计算量较大。但考虑到牛顿类算法比大多数一阶方法具有更快的收敛速度,越来越多的学者开始了对该类算法的研究。
本文研究分布式求解问题(1)的拟牛顿方法,只需计算目标函数的一阶信息,通过选取一个满足拟牛顿方程的正定对角矩阵来作为费用函数Hesse矩阵逆的校正矩阵,来克服校正矩阵的非稀疏性对算法分布式实现造成的困难,从而实现拟牛顿法的分布式计算,减少计算量和存储空间。同时,在适当条件下证明分布式拟牛顿算法的收敛性,并通过数值试验验证算法的有效性。应当指出的是,这里的分布式是指每个节点仅知道其本地费用函数,且只能够与相邻节点进行信息交换。
1预备知识
首先给出关于问题(1)的一些预备知识。
假设1假设函数fi:Rp→R是系数为μ>0的强凸函数,即
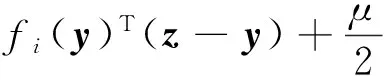
(2)
并且具有常数为L的Lipschitz连续梯度,即
‖▽fi(y)-▽fi(z)‖≤L‖y-z‖。
(3)
假设3矩阵W=WT∈Rn×n是元素为wij的随机矩阵, 其中wij的定义如下:
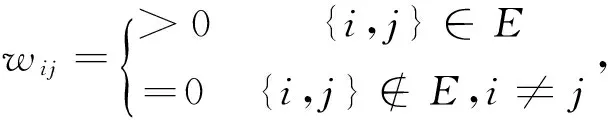
且存在常数wmin,wmax使得
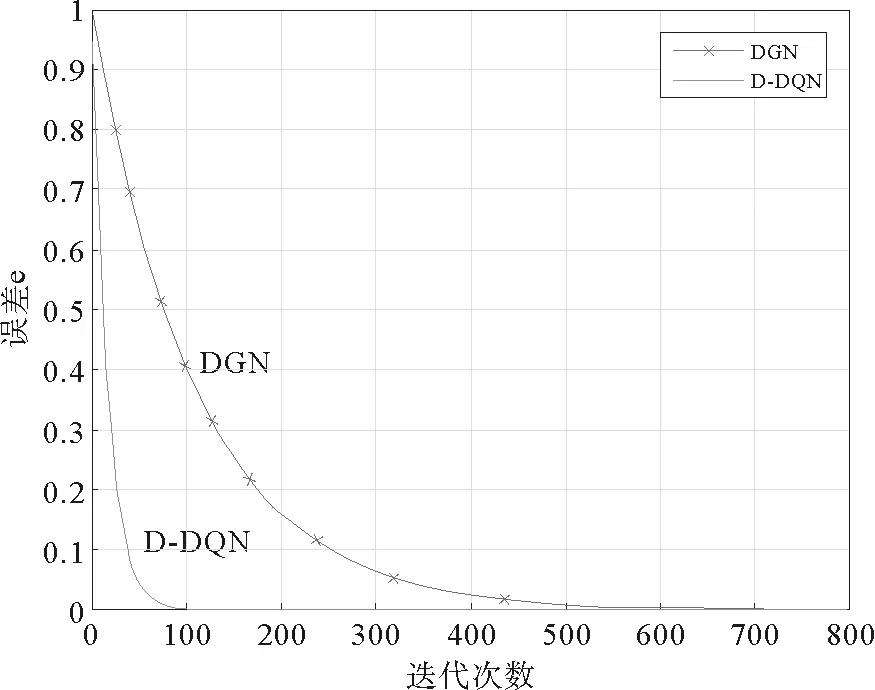
0 定义1[16]对于矩阵M=(Mij)∈Rnp×np,其中Mij∈Rp×p,定义M的范数如下: 类似的,对向量x∈Rnp,xi∈Rp,定义: 其中‖·‖2为欧式范数。 2分布式拟牛顿法 牛顿法的基本思想是利用目标函数的二次Taylor展开来逼近目标函数,但在实际问题中,尤其是大规模的高维问题中,如果所基于的网络是稀疏的,则目标函数的二阶导也可能是稀疏的,从而使得所求解的问题具有特殊结构。但遗憾的是,即使目标函数的Hesse矩阵是稀疏的,但其逆却是稠密的。为了减少计算量,避免Hesse矩阵逆的计算,我们利用目标函数及其一阶导数信息来近似Hesse矩阵的逆矩阵,通过构造特殊的拟牛顿矩阵,实现拟牛顿矩阵的分布式计算。 2.1问题的等价变形 引入辅助函数Φ:Rnp→R,令x=(x1,…,xn)∈Rnp,并记Z∈Rnp×np为W和单位矩阵I∈Rp×p的Kronecker积:Z=W⊗I,则由文献[18]可知问题(1)等价于如下问题: (4) 其中α>0 为罚参数,Inp×np表示np×np的单位矩阵。 (5) 2.2算法框架 求解问题(4)的拟牛顿法的基本迭代格式为:xk+1=xk+εdk。 (6) (7) Hk是目标函数Hesse矩阵逆矩阵的近似,满足正定性和如下拟牛顿条件: Hkyk=sk。 (8) (9) 其中hij表示对角矩阵hi的第j个对角元,yij表示子向量yi中第j个分量,sij表示子向量si的第j个分量。 (10) (11) 于是,由(7)式可以写出在每个节点i处的下降方向: (12) (13) 由上述讨论可得分布式拟牛顿算法(Distributed-DiagonalQuasi-Newton,D-DQN)的框架如下: 分布式拟牛顿算法 对每个节点i,给定α,ε>0。步1.初始化:对每个节点i,令k=0,给定初始点x0i,x1i∈Rp。步2.对每个节点i,将其迭代点xki传递给其相邻节点j∈Oi,并从相邻节点接收xkj.步3.对每个节点i,计算搜索方向:dki=-hkiα▽fixki()+∑j∈Oiwijxki-xkj()[]步4.对每个节点i,更新其近似解:xk+1i=xki+εdki步5.由(10)式、(11)式计算hk+1i的元素,令k=k+1,返回步2. 注:注意到拟牛顿方法每步迭代都涉及到当前节点及其相邻节点前两步的变量信息,因此在给定初始条件时,每个节点需要给出两个初始值。在算法的第2步,每个节点需要与其相邻节点进行信息交换。 第3步中计算搜索方向时涉及到了参数α,这一参数的取值在文献[18]中已有研究,本文在数值实验时取α为固定值。算法第4步,本文采用一个固定步长ε,显然变量的迭代只涉及到自身的函数信息和相邻节点的信息,实现了问题(1)的分布式计算。 3收敛性分析 引理1若假设1~3成立,则有‖dk‖≤M‖▽Φ(xk)‖。 证明因为Hk为块对角矩阵,由本文中范数的定义,可知: 因此,由dk的定义可得 (14) (15) (16) 证明由算法的迭代过程与题设可得 于是,由引理1可得 (17) (18) 4数值实验 本节通过数值实验来验证D-DQN算法求解问题(1)的有效性,并将本文提出的算法与分布式梯度法(DGN)在迭代次数和运行时间两方面进行比较。实验运行环境为Pentium(R)E5500 2.77GHz双核处理器,内存2.00GB。所有算法程序均用Matlab2015a编写。 实验生成节点个数为n的连通网络,考虑如下形式一致性问题 当全局变量维数p=3,图1、图2分别取不同网络节点数时,分布式梯度下降法(DGN)和分布式拟牛顿算法(D-DQN)迭代次数与误差的关系曲线。可以看出,分布式拟牛顿算法的收敛速度要快于分布式梯度下降方法,且在刚开始迭代时表现出非常快的下降速度,从而体现出分布式拟牛顿法在求解大规模稀疏一致性优化问题中的优越性。 图1 当n=100时,D-DQN算法与DGN算法的比较 图2 当n=200时,D-DQN算法与DGN算法的比较 5结论 本文针对无约束一致性优化问题(1),提出了一类新的分布式拟牛顿算法,算法通过选取一个近似满足拟牛顿方程的正定对角矩阵来近似费用函数Hesse矩阵的逆,实现了拟牛顿算法的分布式实现。在取固定步长的情况下,证明了算法的全局收敛性及局部线性收敛速度,并通过数值实验验证了算法的有效性。实验结果表明,分布式拟牛顿算法在求解大规模稀疏一致性优化问题方面具有较好的应用前景。 参考文献: [1]DANESHMAND A,FACCHINEI F,KUNGURTSEV V,et al. Hybrid random/deterministic parallel algorithms for nonconvex big data optimization[J].Journal of Inverstigative Medicine,2014,60(4):671-675. [2]SCHIZAS I D,RIBEIRO A,GIANNAKIS G B.Consensus in ad hoc WSNs with noisy links—Part I:Distributed estimation of deterministic signals[J].IEEE Transactions on Signal Processing,2008,56(1):350-364. [3]KAR S,MOURA J M F,RAMANAN K.Distributed parameter estimation in sensor networks:Nonlinear observation models and imperfect communication[J].IEEE Transactions on Information Theory,2012,58(6):3575-3605. [4]SAYED A H,LOPES C G.Adaptive Processing over distributed networks[J].Leice Transactions on Fundamentals of Electronics Communications and Computer Sciences,2007,E90-A(8):1504-1510. [5]CATTIVELLI F S,SAYED A H.Diffusion LMS strategies for distributed estimation[J].IEEE Transactions on Signal Processing,2010,58(3):1035-1048. [6]MOTA J F C,XAVIER J M F,AGUIAR P M Q,et al.Distributed optimization with local domains:Applications in MPC and network flows[J].IEEE Transactions on Automatic Control,2015,60(7):2004-2009. [8]JAKOVETIC D,XAVIER J,MOURA J M F.Fast distributed gradient methods[J].IEEE Transactions on Automatic Control,2014,59(5):1131-1146. [9]YUAN K,LING Q,YIN W.On the convergence of decentralized gradient descent[DB/OL].(2015-07-01)[2016-01-05].http://arXiv preprint arXiv:1310.7063. [10]SHI W,LING Q,WU G,et al.Extra:An exact first-order algorithm for decentralized consensus optimization[J].SIAM Journal on Optimization,2015,25(2):944-966. [11]LING Q,RIBEIRO A.Decentralized linearized alternating direction method of multipliers[C]//IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP),2014:5447-5451. [12]BOYD S,PARIKH N,CHU E,et al.Distributed optimization and statistical learning via the alternating direction method of multipliers[J].Foundations and Trends in Machine Learning,2011,3(1):1-122. [13]SHI W,LING Q,YUAN K,et al.On the linear convergence of the ADMM in decentralized consensus optimization[J].IEEE Transactions on Signal Processing,2014,62(7):1750-1761. [14]DUCHI J C,AGARWAL A,WAINWRIGHT M J.Dual averaging for distributed optimization:convergence analysis and network scaling[J].IEEE Transactions on Automatic control,2012,57(3):592-606. [15]TSIANOS K I,LAWLOR S,RABBAT M G.Push-sum distributed dual averaging for convex optimization[C]//IEEE 51st Annual Conference on Decision and Control (CDC),2012:5453-5458. [16]BAJOVIC D,JAKOVETIC D,KREJIC N,et al.Newton-like method with diagonal correction for distributed optimization[DB/OL](2015-09-05)[2016-01-05].http://arXiv preprint arXiv:1509.01703. [17]MOKHTARI A,LING Q,RIBEIRO A.An approximate Newton method for distributed optimization[C]//IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP), 2015. [18]JAKOVETIC D,MOURA J M F,XAVIER J.Distributed Nesterov-like gradient algorithms[C]//IEEE 51st Annual Conference on Decision and Control (CDC),2012:5459-5464. [19]时贞军,孙国.无约束优化问题的对角稀疏拟牛顿法[J].系统科学与数学,2006,26(1):101-112. SHI Zhenjun,SUN Guo.A diagonal-sparse quasi-Newton method for unconstrained optimization problem[J].Journal of Systems Science and Mathematical Sciences,2006,26(1):101-112. (责任编辑:傅游) Distributed Quasi-Newton Algorithm for Solving Unconstrained Consensus Optimization YU Huihui1, WANG Yongli1, CHEN Yongyong1, ZHOU Xiujuan2 (1. College of Mathematics and Systems Science, Shandong University of Science and Technology, Qingdao Shandong 266590, China;2. College of Information Science and Engineering, Shandong University of Science and Technology,Qingdao, Shandong 266590, China) Abstract:A class of distributed quasi-Newton algorithm was proposed for solving the unconstrained consensus optimization, where the network nodes work collaboratively to minimize the sum of their locally known convex costs. The new algorithm used only the first-order derivative information of the cost function. By choosing a positive definite diagonal matrix as the quasi-Newton correction of the inverse of the Hesse matrix of the cost function at each iteration, the proposed algorithm successfully overcame the difficulty caused by the non-sparsity of the correction matrix in the implementation of distribution, and greatly decreased computation and storage pressure. Under suitable conditions, the proposed distributed quasi-Newton algorithm was proved to be globally convergent with local linear convergence rate and its superiority was verified by numerical simulations. Key words:unconstrained consensus optimization; distributed quasi-Newton algorithm; global convergence; linear convergence 收稿日期:2016-01-05 作者简介:于慧慧(1991—),女,山东菏泽人,硕士研究生,主要从事分布式优化算法的研究.E-mail:yxh622@163.com 王永丽(1977—),女,山东栖霞人,博士,副教授,主要从事非线性优化理论与算法、分布式优化算法、并行计算的研究,本文通信作者.E-mail:wangyongli@sdkd.net.cn 中图分类号:O224 文献标志码:A 文章编号:1672-3767(2016)03-0112-07