
基于网络流量分析的二进制协议逆向方法
2016-06-08 06:48陈佳莹
现代计算机 2016年13期
陈佳莹
(西南交通大学电气工程学院,成都 610031)
基于网络流量分析的二进制协议逆向方法
陈佳莹
(西南交通大学电气工程学院,成都610031)
摘要:
关键词:
0 引言
随着以通信网络技术为主导的新军事革命的兴起,信息网络已迅速延伸到军事领域的每一个角落,网络对抗作为一种新的作战方式登上舞台[1-2]。在网络对抗中,从截获的通信流比特数据中识别出对方的协议类型,挖掘其协议规范是获取对方网络结构情况甚至于高层信息的基础。现有的网络安全检测手段和协议识别方法都需要完整的协议规范作为先验知识,所以,自动的未知协议逆向工程成为当今研究的热点。
现有的协议逆向方法大致分为两类[3]:基于网络流量分析的方法和基于执行轨迹分析方法。前者依据报文字节取值的变化频率和特征来提取协议报文格式。后者是在二进制代码层跟踪服务器程序处理报文各个字段所调用的不同指令,从而推导各个字段的语法语义。相对于执行轨迹分析,网络流量分析的实现与协议平台无关,并且不需要二进制执行信息,更为通用,也因此得到研究者的广泛关注[4]。PI项目[5]最早提出基于网络流量分析的协议逆向方法,该方法引入生物信息学中的渐进序列比对算法,有效地降低了大规模样本序列比对的时间复杂度,但这种方法适用于各字段都是固定长度的报文,如果报文中存在可变长度的字段,比对结果会产生很大的误差。Paxson[6]等人提出一种协议识别方案RolePlayer,该方法实现了对捕获的数据流中的终端信息、长度域、Cookie等语义字段的定位,并通过关键字段的替换达到自动交互的效果。但这种方法没有提取出报文格式,流量稍有变化就无法识别。此外,上述两种方法都是针对于单一格式的数据流,不适用于网络对抗中存在的混合着多种协议的数据流。
基于上述问题,本文提出一种二进制协议逆向方法,该方法利用字节在网络流中取值变化的规律,实现了不同类未知协议数据帧的分离和报文格式的域划分。在此基础上结合语义对报文进行字段定界,并通过多序列比对和迭代搜索挖掘变长域,达到提取报文格式的目的。
1 系统框架
基于网络流量分析方法的基本思想是通过比对多个相同类型的报文来推导报文格式。首要解决的问题是如何将样本集中的不同报文聚成不同的类,使得每一类中只包含一种类型的报文,才能确保后续协议逆向的准确度;其次是要考虑如何在确保字节对齐的基础上比对同一字段在多个报文中的取值进行字段的定界从而获取报文格式。
因此,本文将协议逆向分成两个阶段,即数据帧分离阶段和协议格式提取阶段。首先抽取网络流的字节取值特性进行关联项的挖掘,建立关联树,遍历关联树得到的关联规则作为聚类中心达到帧分离的目的;然后对相同格式的报文序列进行字段定界以及可变域的序列比对,最后提取协议的格式包括固定域、长度域、目的域以及一些特定语义字段如地址、标识符等。图1表示系统的整体框架与流程。
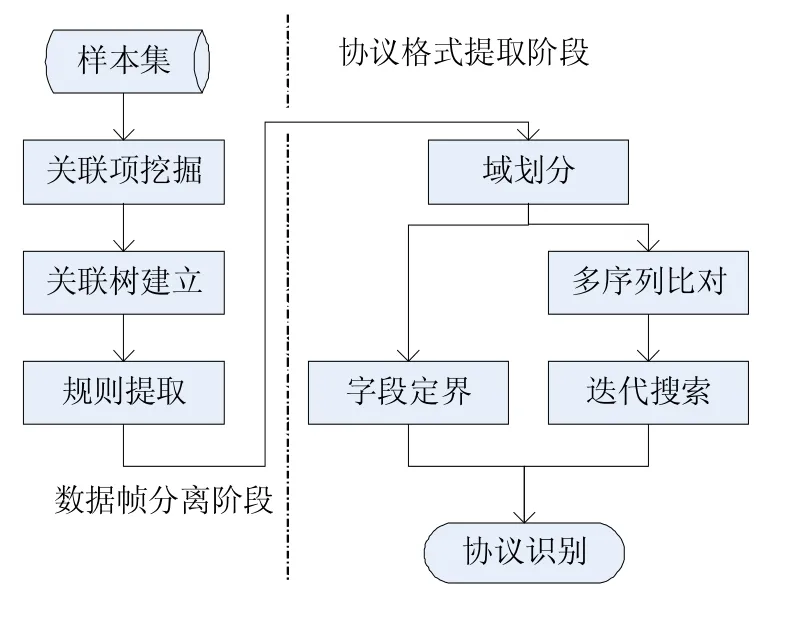
图1 系统框架与流程
2 基于关联树的帧分离方法
由OSI模型可知,网络协议是一组不同层次上多种协议的组合,上层协议的格式一般通过下层协议中的格式标识字段来决定。这种网络协议严格分层的特点为协议聚类提供了根本依据。此外,绝大多数的网络协议都会在报文格式中定义若干个控制字段用来标识报文的类型和传递控制信息,这些字段通常是协议的各种命令和响应码,如果以控制字段为基准,可以对相同类型的报文作进一步的比对得到更为精准的字段格式。无论是标识字段还是控制字段都会在样本集中频繁的出现[7],可以挖掘出来作为关键字,本文称之为关联项。
将同一位置上的所有关联项看作同一层,根据置信度把不同层次的关联项联系起来就形成一棵关联树,遍历该关联树得到的每一条路径就对应一条关联规则。将关联规则作为聚类中心,就可以把数据流中不同协议分离开。
2.1关联项的挖掘
根据协议标识字段以及控制字段的取值较为固定的特点[9],以字节为单位对样本中所有序列进行从左往右逐一扫描,若某位置上字节的取值种类不超过类型上限阈值,则将该位置上所有的字节取值作为关联项候选项。
本文使用文献[7]中的频繁串挖掘方法,实现仅对样本集的序列扫描一次,即可得到任意长度模式序列的计数。挖掘出的频繁特征由频繁项及其在序列中的偏移量组成,第i个频繁项表示为(fi,pi),其中pi表示该频繁项的起始位置。假设样本集Q共挖掘出n个频繁项,按照起始位置从小到大的排列顺序构成特征集F={f1,f2,…,fn}。
为了确保后续协议逆向的准确性,必须对候选项进行筛选和合并操作。首先,筛选掉对应的序列条数少于最小类下限阈值的候选项;其次对于偏移量连续的候选项进行合并,减少后续建树的时间复杂度。
2.2关联树的建立
为了更好的说明关联树建立的过程,若位置i上找出k个候选项,则定义该位置的特征向量为:
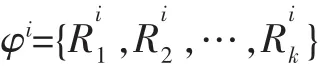
这里假设总共在四个位置上挖掘到关联项,对应的特征向量分别为:
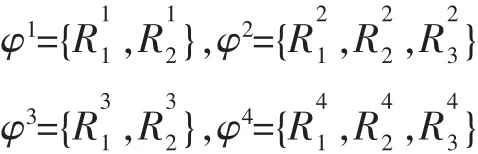
下面分三个步骤对于上述特征向量建立关联树:
(1)将同一位置上所有关联项看作同一层,分别计算相邻两层中所有关联项之间的置信度,若置信度大于0,则将两关联项相连,结果如图2所示。
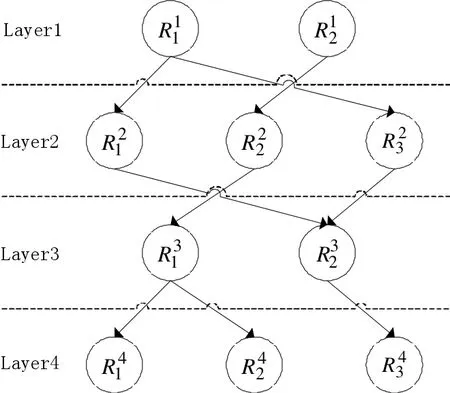
图2 关联树初始化

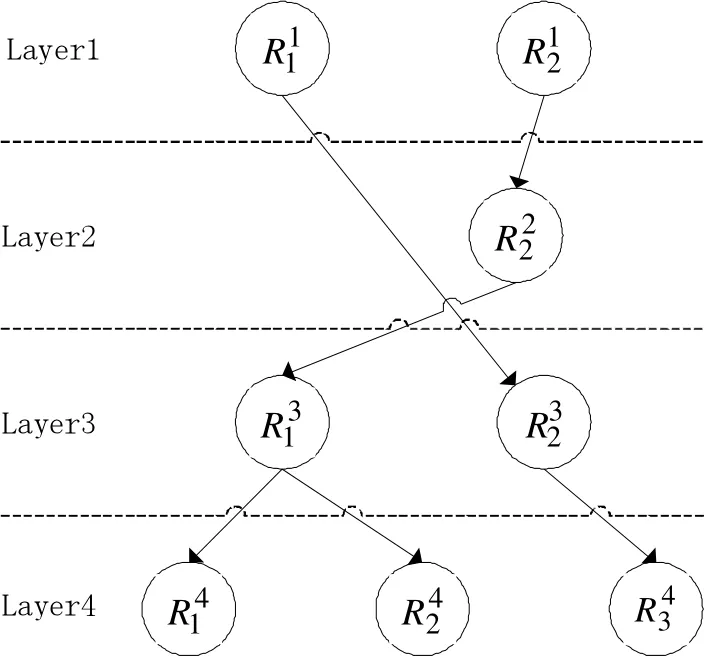
图3 关联树化简
(3)对关联树进行遍历得到最终的关联规则,其中每条关联规则都与一种协议格式相对应,但由于某种协议可能具有不同的状态,因此同一协议可能对应多条关联规则。
3 格式识别
网络协议报文是由若干个字段组成,其中字段为具有特定语义的最小不可分割的连续字节序列。根据各字段在网络流中的取值变化情况,可以将其分成固定域与可变域两类[10]。变长域作为可变域中的一种特定语义字段,其起始位置和内容长度在不同报文实例中均可能不同,容易证明,一旦可变域中包含了变长域,后续则不可能出现对齐的固定域。
根据上述思想,提出一种基于域划分的格式识别方法。方法以样本集S为输入,主要分为以下四个阶段:
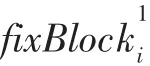

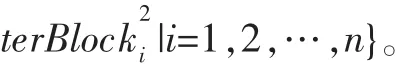
(4)对于集合中每一个alterBlock2i调用函数lengthValidate()进行长度字段匹配,达到变长域的挖掘的目的。
3.1字段定界
根据2.1节中的统计结果,计算各对齐字节的取值变化率θi:
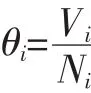
其中Vi表示第i个字节取值的变化次数,Ni表示序列个数。
考虑到同一字段中取值变化率相似的特点,将变化率差值不超过5%[11]的连续字节划分为字段。此外可以通过特定语义字段的特性对划分结果进行核实和校对,本文主要考虑以下特性:
(1)请求报文和响应报文中的源地址和目的地址两个字段是相互对调的;
(2)在(1)的基础上出现某连续字节在请求报文和响应报文中取值相同,但是分别在连续的请求报文和连续的响应报文中取值不重复,那么合并该字节;
(3)将序列两两相减取长度差值,若存在某连续字节(通常优先取两个字节)的差值等于序列长度差值,那么合并该连续字节为长度字段。
3.2变长域的挖掘
变长域通常由长度字段和目的字段组成,首先解析出长度字段,然后就可以根据长度字段的取值内容进一步确定目的字段的范围。
长度字段搜索是一个内部迭代的过程,其核心思想是:从报文的首部开始假定字节(组)L为长度字段(一般为1~2个字节),根据字节L的取值截取相应长度的字节序列S作为目的字段,当满足如下条件之一即可结束本次搜索:1)字节L的取值对应的长度超出了搜索范围;2)序列S的后续字节个数小于默认长度,本文设置为2。每次搜索结果用长度向量(offset,count)的形式保存,其中offset表示首个长度字段的位置,count表示变长域中(L,S)组合的个数。最终迭代搜索之后得到一个长度向量集合。
每一条序列报文都对应这样一个向量集合,若集合存在交集,那么该交集就是最终识别的变长域中的长度字段。
4 实验与结果分析
4.1数据集的获取
本文对四种常见二进制协议进行实验,分别是ICMP、ARP、DNS、OICQ协议。将数据集分成两部分,一部分作为训练集,另外一部分作为测试集,其中训练集只包含上述四种标准协议,测试集中另外包含未出现的自定义协议用来测试该方法对于未知协议的识别能力。在数据获取的过程中,尽可能多的获取相同格式报文的不同实例,保证样本的多样性,避免产生过多冗余的关联项,从而提高后续格式提取的准确度。
4.2聚类效果分析
对测试集中的四种标准协议按照前面介绍的频繁项发掘方法,设置合适的阈值构造关联树如图4所示。遍历上述关联树,得到的关联规则与协议对应关系如下表1所示。
由统计结果可以看出,以规则1,2为聚类中心的协议类型为DNS,以规则3为聚类中心的协议类型为OICQ,以规则4为聚类中心的协议类型为ICMP,以规则5,6为聚类中心的协议类型为ARP。在分离四种协议的基础上根据DNS和ARP协议中的标识符进一步划分了子类。说明随着挖掘的关联项层次越深,聚类的粒度越细,格式越精确。
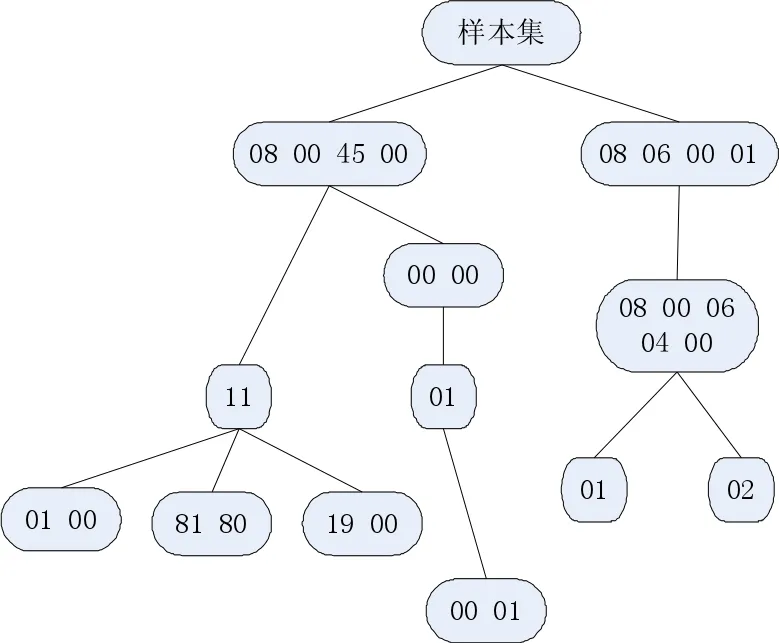
图4 关联树示例

表1 关联规则与协议对应关系
4.3格式识别效果分析
为了对比结构识别的准确率,将本文方法和文献[8]方法的识别结果相对比,其中标准协议的识别结果和Wireshark的解析结果进行对比,未知协议和预先定义的语法语义规则对比,统计字段边界划分正确的字段所占比率,如图5所示。
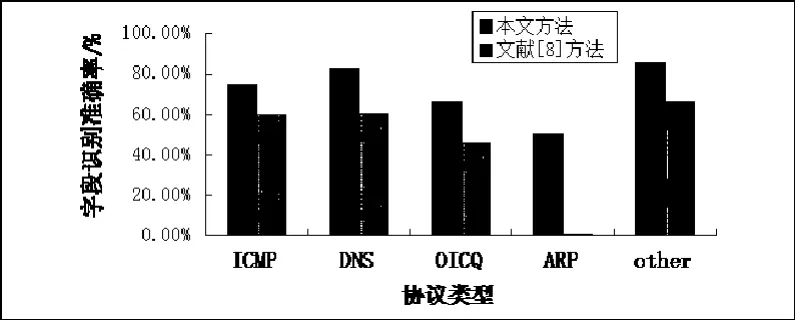
图5 字段识别正确率对比
由图5中的对比数据可以看出,对于结构固定的ICMP协议两个方法的识别准确率相差相对较小,而对于存在变长域的DNS协议和具有较长冗余负载数据的OICQ协议,本文方法的优势比较明显,因为文献[8]中的方法对字段的划分必须通过多序列对比来判断,而变长域和负载数据都会对序列比对的过程进行干扰,降低识别率。对于ARP协议,两种方法的识别率都不高,文献[8]方法的识别率更是接近于0,这是因为ARP协议产生的报文实例过于单一化,从字节对齐的方面考虑完全无法进行字段划分,只有根据文中3.1节提到的语义特性才能对某些字段进行推断。
变长域由于其起始位置和内容长度在不同报文实例中均可能不同,在逆向解析中识别度较低。为提高变长域的识别率,本文做了如下技术处理:(1)结合域划分和多序列对比对待测试报文序列进行处理,缩小可变域的搜索区域,同时减少搜索算法对于取值较小字节的敏感度;(2)在相同格式的多个报文实例中进行推断结果的验证,减小变长域的误报率。将DNS作为实验数据统计长度字段的识别率、误识别率和搜索时间开销,统计结果如表2所示。
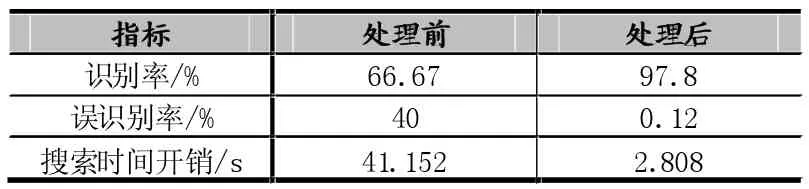
表2 识别率、误识别率和搜索时间开销比较
由表2可以看出,利用域划分和多序列比对算法对报文序列进行处理之后,通过缩小可变域的搜索区域大幅度减小了时间开销,并在此基础上提高了长度字段的识别率和降低误识别率。说明本方法对于类似DNS这种变长域结构较集中的协议,长度字段搜索的效率和准确率都有大幅度提高。
5 结语
针对目前基于网络流量分析方法只适用于较为单一数据帧格式的逆向解析以及在序列较长情况下对变长域的逆向准确率不高而且效率低下的问题。本文首先利用协议的层次结构通过挖掘关键字之间的关联规则对不同格式的协议进行聚类;然后对于同一类中的序列进行格式提取,在字段定界过程中增加语义特性的判断,在变长域挖掘之前对序列进行域划分并截取,大幅度缩减比对序列的长度,在提高长度字段识别准确率的同时减小了算法的时间复杂度。在下一步的工作中,将研究网络协议其他语义字段的逆向。
参考文献:
[1]黄汉文.空间网络对抗研究[J].航天电子对抗,2009,01:7-9+33.
[2]张春瑞,刘渊,李芬,王开云.无线网络对抗关键技术研究综述[J].计算机工程与设计,2012,08:2906-2910+2975.
[3]赵咏,姚秋林,张志斌,郭莉,方滨兴. TPCAD:一种文本类多协议特征自动发现方法[J].通信学报,2009,S1:28-35.
[4]黎敏,余顺争.抗噪的未知应用层协议报文格式最佳分段方法[J].软件学报,2013,03:604-617.
[5]BEDDOE M. Protocol Information Project[EB/OL].[2012-18]. http://www.4tphi.net/~awalters/PI/pi.pdf.
[6]Weidong Cui,et al. Protocol-Independent Adaptive Replay of Application Dialog. In The 13th Annual Network and Distributed System Security Symposium(NDSS 2006.
[7]金凌.面向比特流的未知帧头识别技术研究[D].上海交通大学,2011.
[8]Han J,Pei J,Yin Y,et al. Mining Frequent Patterns without Candidate Generation: A Frequent-Pattern Tree Approach[J]. Data Mining & Knowledge Discovery,2004,8(1):53-87.
[9]Cui W,Kannan J,Wang H J. Discoverer: Automatic Protocol Reverse Engineering from Network Traces[C]. In Proceedings of the 16th USENIX Security Symposium(Security'07. 2007.
[10]黄笑言,陈性元,祝宁,唐慧林.基于字节熵矢量加权指纹的二进制协议识别[J].计算机应用研究,2015,02:493-497.
[11]潘璠,洪征,杜有翔,吴礼发.基于递归聚类的报文结构提取方法[J].四川大学学报(工程科学版),2012,06:137-142.
Reverse Engineering for Binary Protocol Based on Network Traces
CHEN Jia-ying
(College of Electrical Engineer,Southwest Jiaotong University,Chengdu 610031)
Abstract:
Keywords:
对未知网络协议进行逆向解析在网络对抗应用中具有重要意义。提出一种基于关联树构造的聚类方法,通过挖掘网络协议不同层次上关键字之间的联系构造关联树,将遍历树得到的关联规则作为聚类的中心,从而达到对不同协议数据帧分离的效果;此外在字段定界过程中增加语义特性的判断,在域划分的基础上利用多序列比对和迭代搜索实现变长域的挖掘。实验表明,该方法在二进制协议聚类上效果显著,同时提高字段识别准确度,在协议逆向领域具有较高应用价值。
二进制协议;数据帧分离;关联树;协议逆向
文章编号:1007-1423(2016)13-0011-05
DOI:10.3969/j.issn.1007-1423.2016.13.003
作者简介:
陈佳莹(1991-),女,江西抚州人,研究生,研究方向为计算机网络、协议逆向
收稿日期:2016-01-07修稿日期:2016-04-25
Reverse engineering for unknown network protocol has played an important role in the field of network countermeasure. Proposes a cluster method based on relevance-tree construction,first excavates the relationship between keywords in each layer of network protocol,then the relevance rules obtained by traversing the tree is used as the center of clustering and finally frames in different format was separated. In addition,protocol structure is extracted by identifying field boundaries and scanning variable region using multiple sequence alignment and iterative algorithm. Experiments show that the proposed method produces a remarkable effect in cluster and improves the accuracy of field identification,which is of important application value.
Binary Protocol;Data Frame Separation;Relevance-Tree;Reverse Engineer
猜你喜欢
汽车电器(2022年9期)2022-11-07
电脑爱好者(2021年23期)2021-12-08
销售与市场(营销版)(2021年10期)2021-11-21
空间科学学报(2021年6期)2021-03-09
中国外汇(2019年11期)2019-08-27
办公室业务(2019年13期)2019-08-01
销售与市场(营销版)(2019年6期)2019-06-21
计算机应用与软件(2018年10期)2018-10-24
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
