
汉语阅读理解测验的认知诊断研究
——以中国政府奖学金本科来华留学生预科教育汉语综合统一考试为例
2016-06-05 14:59陈璐欣王佶旻
中国考试 2016年2期
陈璐欣 王佶旻
汉语阅读理解测验的认知诊断研究
——以中国政府奖学金本科来华留学生预科教育汉语综合统一考试为例
陈璐欣 王佶旻
中国政府奖学金本科来华留学生预科教育汉语综合统一考试是北京语言大学汉语考试与教育测量研究所研制的新型汉语考试。该考试用以衡量预科生结业的语言水平,它的特点是集基础汉语和专业汉语为一体,对预科的语言能力进行全面测评。为更好地了解预科生阅读能力的认知模式,为考生和学校提供诊断性评价,我们采用融合模型(Fusion Model,FM)对2014年5月参加该考试的532名理工类被试在阅读理解部分的作答情况进行诊断性研究。研究发现:①该批被试对信息查找能力掌握得较好,对信息转译能力掌握得不理想;②不同高校在汉语教学上存在一定偏向;③该部分试题中第93题对于被试来说较难,第89题、91题、93题和94题在属性完备性上不够理想,建议进行调整和修改。
融合模型;预科教育;阅读理解;认知诊断
1 引言
2014年北京语言大学汉语考试与教育测量研究所受国家留学基金管理委员会的委托,研发了用于来华留学生预科教育结业考核的汉语综合统一考试。该考试是集基础汉语和专业汉语为一体的新型汉语考试,根据学生所学专业的不同分为理工、经贸、医学和文科四个版本。
为了使学校和教师更加详细地了解学生汉语知识(技能)的掌握情况,我们拟在考试的分数报告中提供诊断性评价。为此,我们需要在该考试的认知诊断研究方面开展一系列的探索性工作。
2 研究背景及文献综述
2.1 阅读理解微技能研究情况
目前,学者们对测试领域中的阅读理解能力进行了多方面的探索,但仍没有统一的定论。Lenon(1970)认为阅读理解能力可以分为一般言语因素、对语义明确的文字内容的理解能力、对隐含意义的理解能力和鉴赏能力。Jeremy Harmer(1983)则把阅读理解技能和听力理解技能一并定义为接收性技能。Freedle&Kostin(1991)从SAT测验考查文章主旨能力的题目中发现8个变量。Buck&Tatsuoka(1995,1996)运用规则空间模型分析第二语言测验中的阅读理解多项选择题目,确定了12种主要技能与8种交互技能。
张志公(1979)认为阅读能力包括理解、记忆和速度。武永明(1990)则认为阅读能力结构包括认读能力、理解能力、评价鉴赏能力和创造运用能力。韩雪屏、张春林(1983)认为阅读能力是一个多因素、多层次交叉的组合。刘守立(1989)从感受的角度提出阅读能力包括语感、文感、情感。莫雷(1990,1992)从教育心理学的角度长期而系统地研究了小学六年级、初中三年级和高中三年级学生的阅读理解能力。
2.2 融合模型理论
融合模型(Fusion Model,FM)是为了克服统一模型下一些参数不能估计的问题而产生的新模型。它不要求属性间具有层级关系,而语言能力的微技能间很多都不具备层级关系,因此这个模型比较适合语言测验的认知诊断研究。
融合模型自被提出以来,已有不少学者对其进行了相关的研究。Montero etc.(2003)将FM应用于高等学校几何课程考试中。Bolt&Fu(2004)将融合模型拓展到多级评分模型。Jang E.E(2005)的研究结果显示属性的数量不能过多,否则统计上会无法识别。Henson&Douglas(2005)的模拟研究表明FM的正确诊断率受测验属性个数及属性间相关程度的影响。车芳芳(2010)应用融合模型对初中生的代数学习进行了认知诊断研究。赵明晨(2014)应用融合模型对被试的汉字字形意识进行了诊断性研究。
3 实证研究
3.1 研究内容
我们尝试采用不考虑属性间层级关系的融合模型来对汉语综合统一考试(理工类)模拟卷中阅读理解测验部分进行认知诊断研究。具体内容包括:
(1)分析被试总体在阅读理解微技能上的掌握情况,了解其阅读理解能力水平;
(2)对比不同学校的被试在阅读理解微技能掌握上的差异,具体为各学校提供一些教学反馈;
(3)对被试个体在阅读理解微技能上的掌握情况进行分析并给出诊断报告;
(4)对比两名得分相同的被试在阅读理解微技能掌握上的差别,依据被试的具体情况给出诊断意见。
3.2 被试的构成
被试为2014年5月参加汉语综合统一考试(理工类)模拟考试的532名被试。
3.3 研究材料
本研究所采用的材料为2014年汉语综合统一考试(理工类)模拟卷中理解短文部分,共21道单项选择题。
3.4 研究方法、过程及结果
3.4.1 测试数据分析
短文理解部分的每一题采用0/1记分,我们以学生在每一题上的作答分数为分析数据,对题目变量进行因素分析,结果显示有7个因素的特征值大于1,方差解释累计比例达53.21%,其余各变量上也有少量的方差解释比例,因此,我们依据旋转成分矩阵中项目负荷值大于0.4来选取题目提炼阅读理解微技能,且以负荷值大于0.2来建立Q矩阵。
根据对试题的分析,我们提炼并定义了7种阅读理解微技能:
依据Q矩阵,我们使用融合模型专用软件Ar-peggio对数据进行分析(见表1、表2)。

表1 阅读理解微技能的定义

表2 阅读理解微技能Q矩阵
第一步,参数估计
(1)MCMC收敛检验
本研究使用R软件绘制马尔科夫链图来判定MCMC是否收敛。通过观察,我们发现在链长30000,预烧期15000时各参数显示收敛,以第94题的链图和后验分布为例(见图1)。
(2)参数估计结果
表5中的Pk值能较好地表示出被试在哪些技能上掌握得较好(Pk值大者),在哪些技能上掌握得不好(Pk值小者)。因此,技能由易到难依次排列为:S3(信息抽取能力)、S4(信息查找能力)、S5(概括推理能力)、S2(信息定位理解能力)、S6(句间关系理解能力)、S7(相关信息归纳能力)、S1(信息转译能力)。
第三步,模型拟合检验
我们使用MAD指标来检验模型的拟合度。
表6中,MAD=0.7546-0.7241=0.0305,差别很小;pdiff值为0.5003,表示掌握者和未掌握者存在较大的差别,区分较为明显。因此,我们认为数据与模型拟合较好,所得结果可靠。
第四步,内部效度检验

图1 第94题技能1的链图和后验分布图
表3 Q矩阵的参数估计结果数据表(、、)
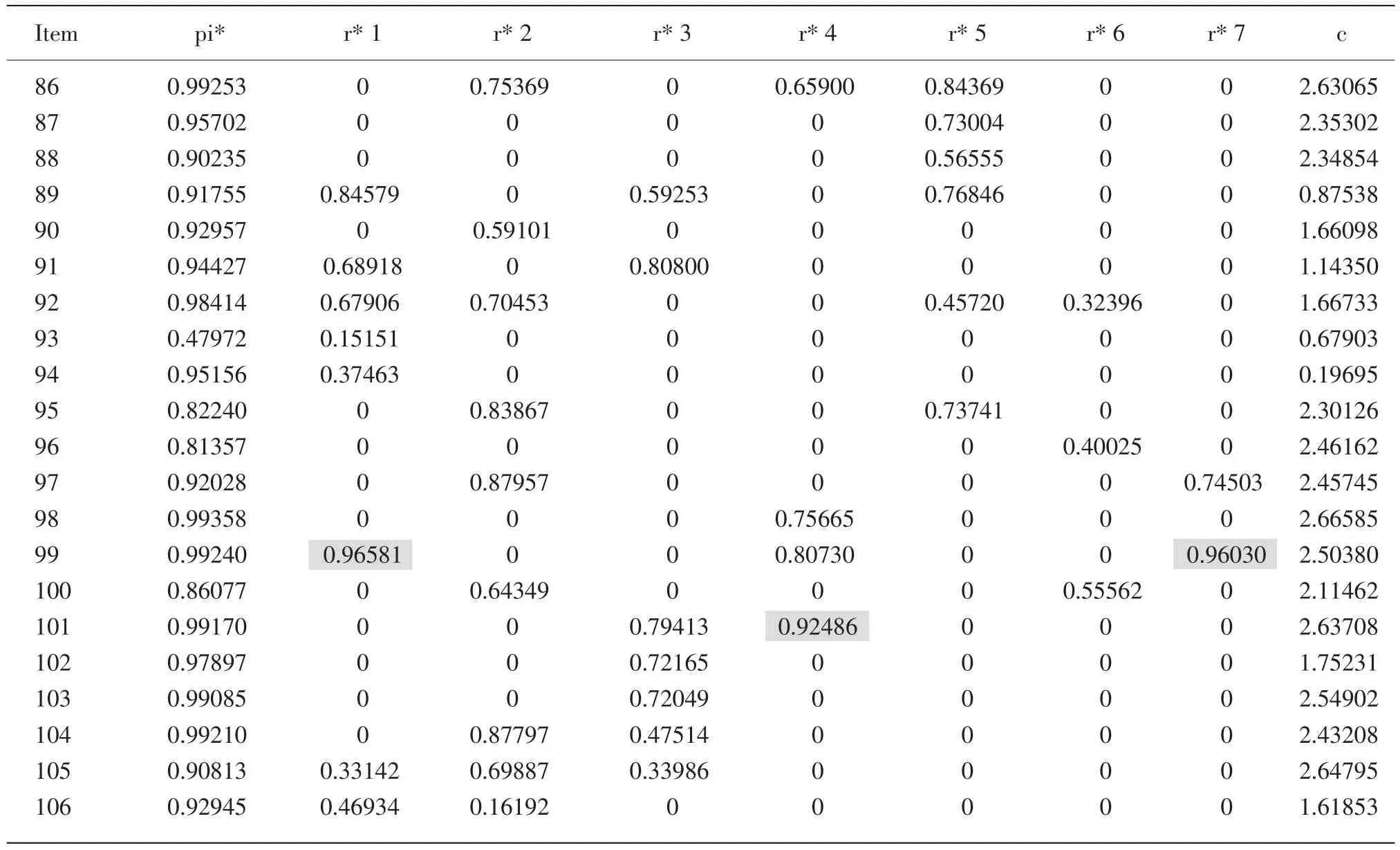
表3 Q矩阵的参数估计结果数据表(、、)
Item pi* r*1 r*2 r*3 r*4 r*5 r*6 r*7 c 86 0.99253 0 0.75369 0 0.65900 0.84369 0 0 2.63065 87 0.95702 0 0 0 0 0.73004 0 0 2.35302 88 0.90235 0 0 0 0 0.56555 0 0 2.34854 89 0.91755 0.84579 0 0.59253 0 0.76846 0 0 0.87538 90 0.92957 0 0.59101 0 0 0 0 0 1.66098 91 0.94427 0.68918 0 0.80800 0 0 0 0 1.14350 92 0.98414 0.67906 0.70453 0 0 0.45720 0.32396 0 1.66733 93 0.47972 0.15151 0 0 0 0 0 0 0.67903 94 0.95156 0.37463 0 0 0 0 0 0 0.19695 95 0.82240 0 0.83867 0 0 0.73741 0 0 2.30126 96 0.81357 0 0 0 0 0 0.40025 0 2.46162 97 0.92028 0 0.87957 0 0 0 0 0.74503 2.45745 98 0.99358 0 0 0 0.75665 0 0 0 2.66585 99 0.99240 0.96581 0 0 0.80730 0 0 0.96030 2.50380 100 0.86077 0 0.64349 0 0 0 0.55562 0 2.11462 101 0.99170 0 0 0.79413 0.92486 0 0 0 2.63708 102 0.97897 0 0 0.72165 0 0 0 0 1.75231 103 0.99085 0 0 0.72049 0 0 0 0 2.54902 104 0.99210 0 0.87797 0.47514 0 0 0 0 2.43208 105 0.90813 0.33142 0.69887 0.33986 0 0 0 0 2.64795 106 0.92945 0.46934 0.16192 0 0 0 0 0 1.61853
表4 三次降元后的Q矩阵的参数估计结果数据表(、、)
Item pi* r*1 r*2 r*3 r*4 r*5 r*6 r*7 c 86 0.9927 0 0.8064 0 0.7110 0.8559 0 0 2.5028 87 0.9597 0 0 0 0 0.7443 0 0 2.3854 88 0.9096 0 0 0 0 0.5687 0 0 2.4268 89 0.9005 0.8182 0 0.5280 0 0.7300 0 0 1.1557 90 0.9331 0 0.6472 0 0 0 0 0 1.6193 91 0.9451 0.6701 0 0.8379 0 0 0 0 1.2251 92 0.9851 0.6237 0.7785 0 0 0.5651 0.4143 0 1.6850 93 0.4480 0.1626 0 0 0 0 0 0 1.1592 94 0.9421 0.4276 0 0 0 0 0 0 0.2529 95 0.8246 0 0.8811 0 0 0.7365 0 0 2.2638 96 0.8251 0 0 0 0 0 0.4252 0 2.4956 97 0.9369 0 0.8715 0 0 0 0 0.6921 2.5817 98 0.9935 0 0 0 0.8425 0 0 0 2.4774 99 0.9919 0 0 0 0.8474 0 0 0 2.2772 100 0.8644 0 0.6808 0 0 0 0.5616 0 2.2719 101 0.9911 0 0 0.8103 0 0 0 0 2.4406 102 0.9792 0 0 0.7832 0 0 0 0 1.6615 103 0.9897 0 0 0.7115 0 0 0 0 2.6161 104 0.9934 0 0.8349 0.4936 0 0 0 0 2.5723 105 0.9085 0.5018 0.5959 0.4409 0 0 0 0 2.6221 106 0.9386 0.5859 0.1758 0 0 0 0 0 1.5456

表5 三次降元后的Q矩阵的参数估计结果数据表(Pk)
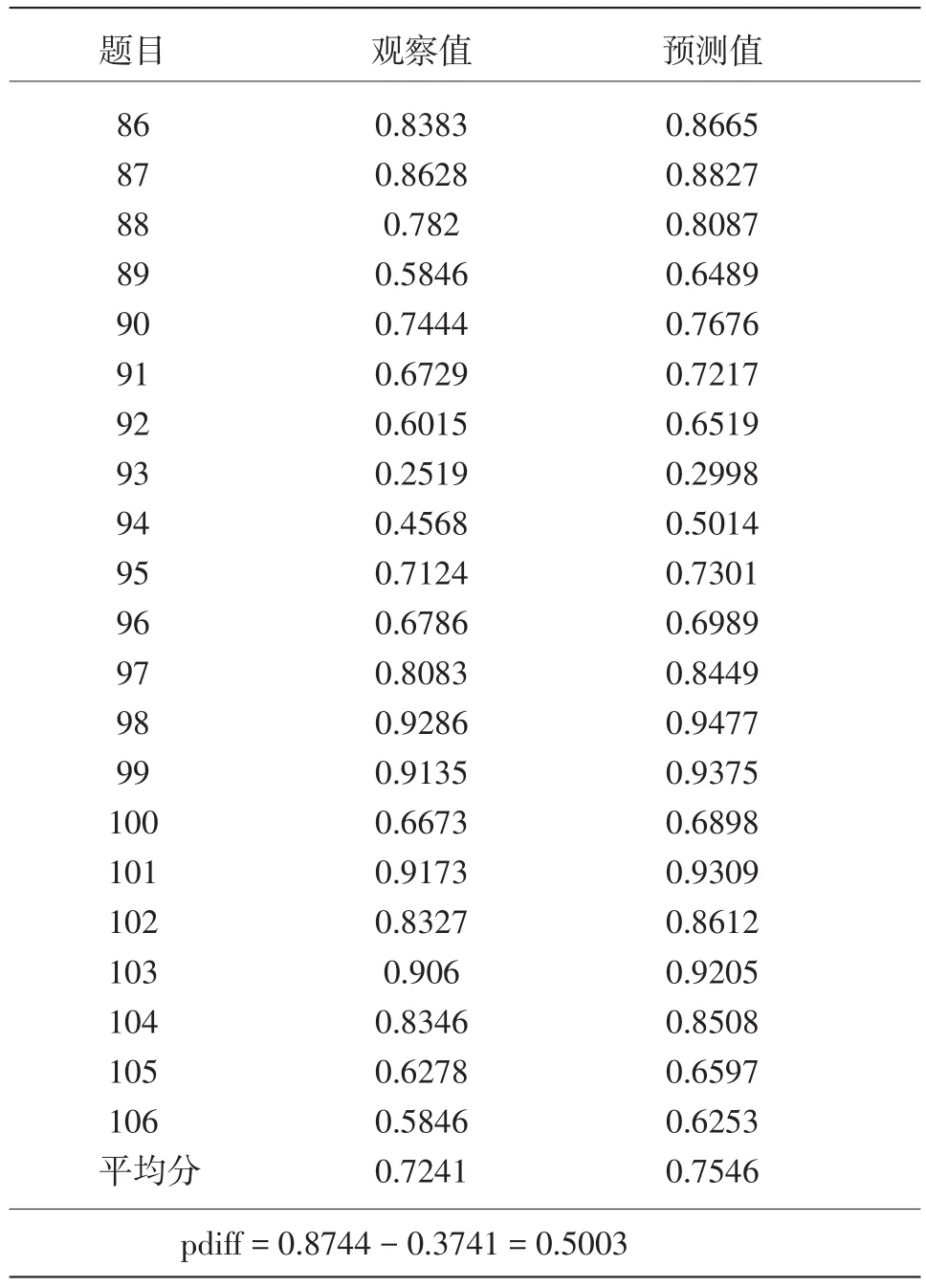
表6 被试在各题上的观察值和预测值
我们以项目掌握统计量(IMstats)和被试掌握统计量(EMstats)来看模型的内部效度,即看试题是否有效地划分了不同能力水平的被试。
IMstats将每一个试题根据被试技能掌握情况的估计值来划分,具体分为掌握者(masters)和未掌握者(non-masters)。
依据表7绘制题目所涉技能掌握者与未掌握者正确作答比例情况分布图,见图2。
图2中横轴1~21代表第86~106题,纵轴代表全体被试的平均分。从图2我们可以看出在每一个项目上掌握者的整体分数都要高于未掌握者的,这表明,该模型在本套数据上具有较高的内部效度。
另外,EMstats是将被试掌握项目的值与一个标准值比较,当被试掌握项目的值明显低于或高于标准值时,被试的作答情况将被作为异常值标记出来。
表8中显示有10名项目掌握者但作答分数低于估计标准值的被试的作答反应与Arpeggio估计的属性掌握情况不一致,其余被试掌握项目的情况与估计一致。
综上表明该测验中对技能的认知诊断的内部效度较高。
3.4.2 技能掌握情况归类
我们根据融合模型所提供的被试在每一题目所含每种属性上的后验掌握概率(PPM值)来看被试对各阅读理解微技能的掌握情况。当PPM≥0.5时,认为被试掌握了该微技能;当PPM<0.5时,认为被试未掌握该微技能。由于被试数量较多,在此仅提供前10名被试的PPM值。
以被试8为例,我们可以看到该被试有5个PPM值大于0.5,分别是技能3、4、5、6、7,即被试掌握了信息抽取能力、信息查找能力、概括推理能力、句间关系理解能力和相关信息归纳能力;PPM<0.5的技能是技能1和2,即被试未掌握信息转译能力和信息定位理解能力(见表9)。
另外,我们还统计出全体被试在各属性上的掌握情况报告(表10)以及全体被试的知识结构情况报告(表11)。
由表10我们可以看出,被试对于技能1、2的掌握情况偏低,这说明预科学生不能很好地结合上下文内容来理解词语所要表达的潜层含义,难以进行信息的含义转换,且对文段中的相关目标信息不能准确定位和理解。

表7 项目所涉技能掌握者与未掌握者情况
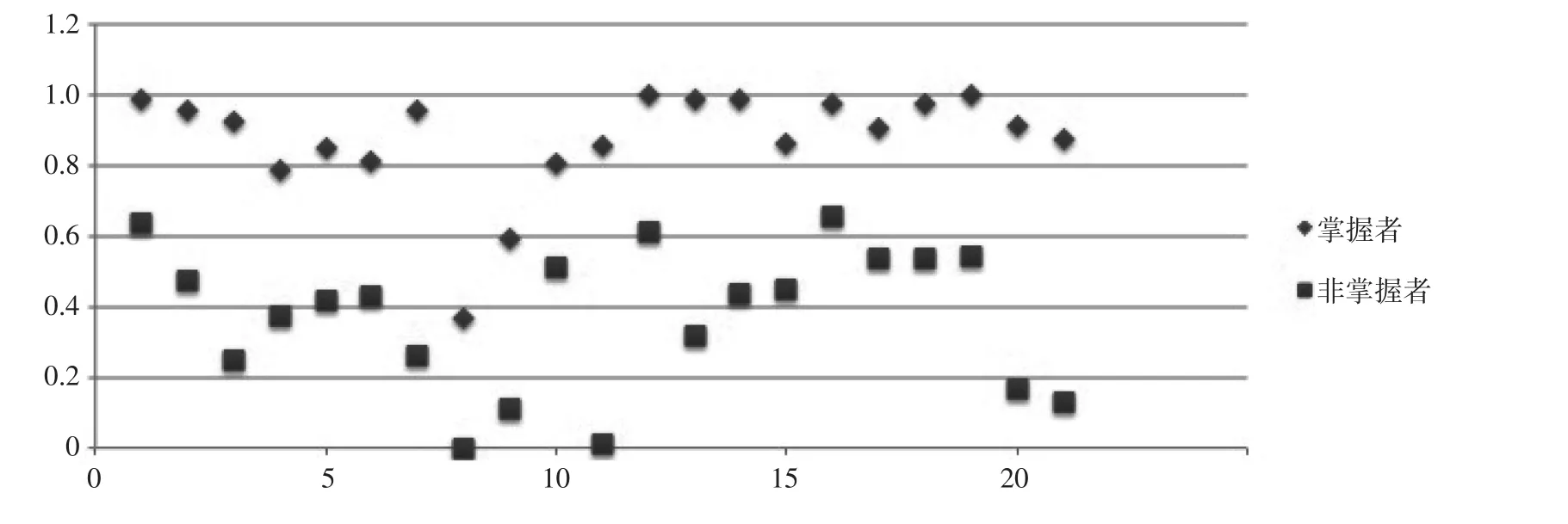
图2 题目所涉技能掌握者与未掌握者正确作答比例情况分布

表8 被试被标记的情况
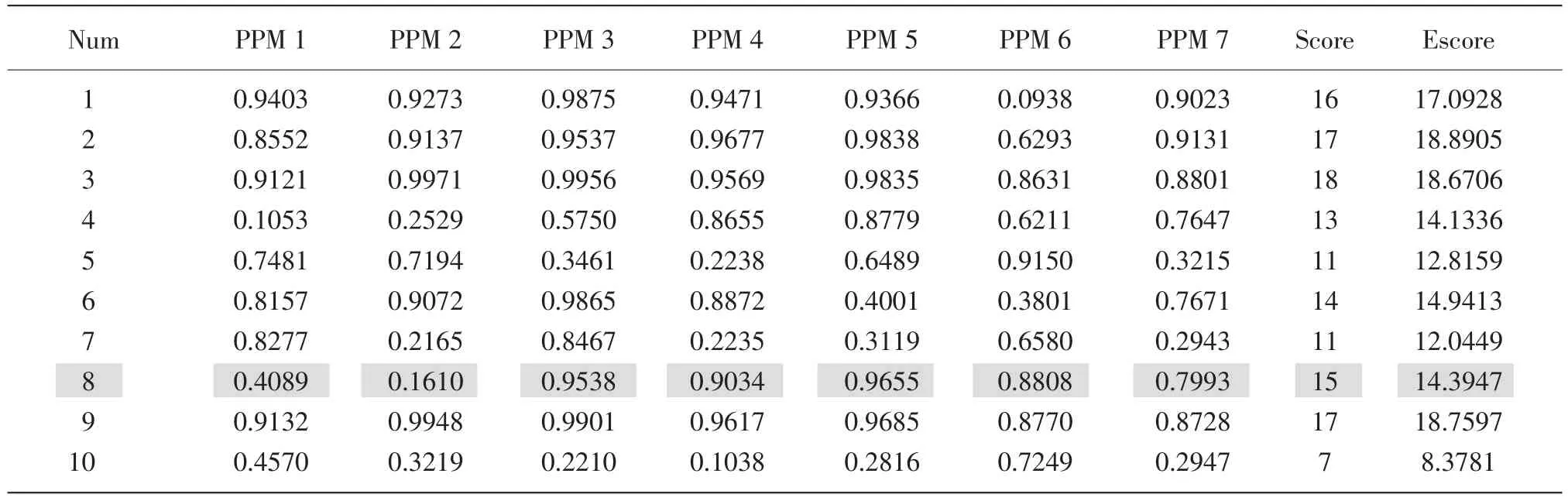
表9 前10名被试的PPM值

表10 全体被试在各属性上的掌握情况报告
表11为77种被试的技能掌握模式。表中“0”表示被试未掌握该技能,“1”表示掌握该技能,如0011001就表示被试只掌握了技能3、4、7。
从表11中我们可以看出,被试的属性掌握模式划分较细,分布较分散。其中,掌握全部技能的人数最多,占42.3%;其次是除技能6未掌握而其余技能都掌握的模式(1111101),占6.02%;然后是除技能2未掌握,其余技能都掌握的模式(1011111),占4.14%。
4 诊断报告及其分析
4.1 全体被试的认知诊断报告
经过统计分析,我们得到了汉语综合统一考试(模拟卷)的532名理工类被试在传统阅读理解部分的参数报告,现为全体被试提供以下诊断报告:
1)从总体看,近75%的学生的阅读理解技能掌握良好。
2)该批学生能够查找或抽取与题干相关的重要信息。
3)一部分学生可能对于隐含的句间关系掌握不够理想。
4)学生在信息定位理解能力上的表现稍差,其原因可能是学生虽然理解题干及选项的含义,但不能很好地对应到文段中,从而无法正确作答。
5)学生在信息转译能力上的掌握率最低,其原因可能是学生难以将词语放在文段中进行整体信息加工,从而不能充分了解词语在文段中所要表达的真正含义。
综上,我们针对该批被试的认知诊断情况,提出以下诊断性建议:
1)对一些常用词语应多用例句来拓展学生对词语的理解和使用,让学生深入理解和掌握词语的含义。
2)鼓励学生在学习中尝试用不同的方式来表达相同意思,帮助学生提高语言表达和应用能力。
3)教师可以引导学生用自己的强项能力去提升弱项技能,如通过对长句或复杂文段进行信息查找、抽取、归纳来强化学生对句子整体内容的理解能力。

表11 全体被试的知识结构情况报告
4.2 基于学校的认知诊断报告
在对被试总体进行认知诊断的基础上,我们以被试人数相差不大的天津大学(代码311,被试131名)和东北师范大学(代码811,被试133名)来了解不同高校被试群体在阅读理解微技能掌握上的差异,如表12、表13所示。
图3中,横轴“m”代表“masters”(掌握者比例),“nm”代表“non-masters”(未掌握者比例)。通过上述统计,可以看出,东北师范大学的被试对各属性的掌握情况整体优于天津大学。两所大学的被试都在技能4上表现最好,在技能1上的表现相对较差。此外,天津大学的被试难掌握技能3和技能7,而东北师范大学的被试则难掌握技能2和技能6。
(1)天津大学被试对技能掌握情况的认知诊断
根据表12,我们对天津大学被试的认知诊断报告如下:
1)学生对信息查找能力、概括推理能力掌握得比较好,属于强项技能。句间关系理解能力和信息定位理解能力的掌握情况次之,属于需强化的技能。
2)被试阅读理解能力发展不够均衡。学生在信息抽取能力上掌握不足,使之不能够准确把握并提取文段的关键内容而导致被试对相关信息归纳困难。

表12 天津大学被试在各属性上的掌握情况报告
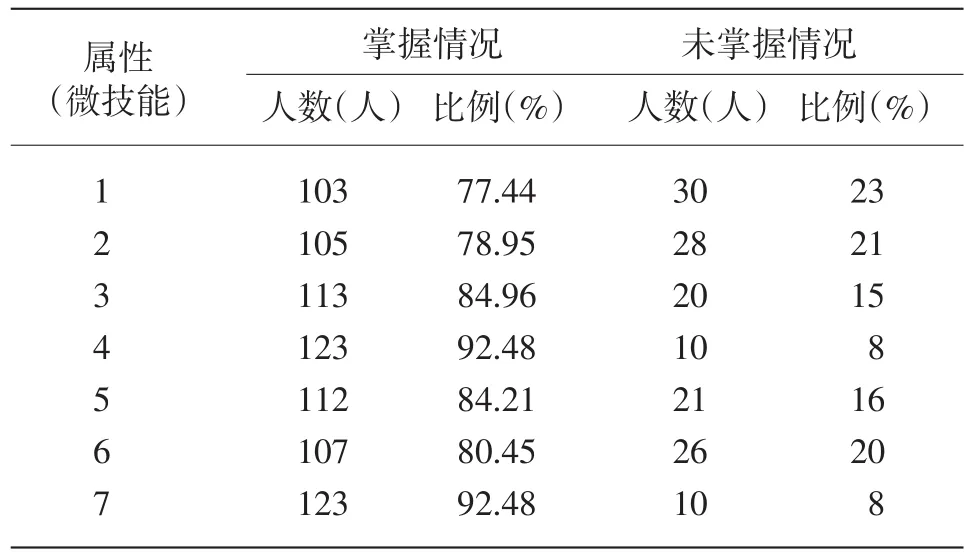
表13 东北师范大学被试在各属性上的掌握情况报告

图3 天津大学和东北师范大学被试各属性掌握情况对比
3)被试在信息转译能力上掌握情况最不理想,属于弱项阅读理解技能。
(2)东北师范大学被试对技能掌握情况的认知诊断
根据表13,我们对东北师范大学被试的认知诊断如下:
1)该批被试的阅读理解能力较强,在信息查找能力和相关信息归纳能力上掌握得较好。80%以上的被试在信息抽取能力、概括推理能力和句间关系理解能力上掌握较好,为强项技能。
2)被试在信息定位理解能力和信息转译能力上掌握情况表现稍差,属于学生的弱项阅读理解技能。
4.3 单个被试的认知诊断报告
我们以46号被试为例,诊断其阅读理解微技能掌握情况,并给出相应的诊断意见(见表14)。
依据上述统计,我们对第46号被试出示如下诊断报告:
1)考生在短文阅读理解部分的得分为11分。
2)考生能读懂词汇和语法都较简单的文章,能通过关键词准确地抽取答题信息,并对相关信息内容进行归纳和简单的逻辑推理。
3)考生能在一定程度上能将文段中的关键信息进行意义转换,但理解句子间关系的能力上掌握得并不扎实。
4)由于信息定位理解能力和信息查找能力间的相互影响,导致该生在这两项技能的掌握上都不理想(见图4)。
因此,我们给出以下诊断意见:
1)该生阅读能力弱,需通过多方面共同提高自身的阅读水平。
2)多阅读简单的小短文,阅读中可对一些关键信息进行标示,以此来提高对关键信息的查找能力、信息定位理解能力。
3)加强和巩固基础词语的基本含义及用法,尝试用不同的词语或话语来表达相同含义。
4)补充基本的语法知识,充分了解一些表示句子间关系的基本语法。
5)多练习句子、段落信息内容的提取、归纳和推理,有意识地提高自己的概括推理能力、相关信息归纳能力。
4.4 得分相同的被试的认知诊断比较分析
因为认知诊断还可以从微观上区分两名得分相同的被试所拥有的不同认知结构,因此,我们以被试5和被试7为例来了解他们在阅读理解微技能掌握上的差异。
从表15和图5中,我们可以看出两被试虽然得分都为11分,但在技能掌握上却不同。虽然被试5和被试7都掌握技能1、6,但被试5对技能6的掌握优于被试7,而被试7在技能1、3的掌握上优于被试5。两被试都未掌握技能4、7,且PPM值均低于0.35,都为“低水平且未掌握者”,但被试5在技能7上的情况略好于被试7。再次,被试5掌握了技能2、5,而被试7则未掌握;被试7掌握了技能3,而被试5未掌握。
综上,我们需要用不同的方式对两被试进行补救教学。如对被试5,其较弱的阅读理解微技能是信息抽取能力、信息查找能力和相关信息归纳能力,那么,在教学中考虑让学生先尝试去把握句子的关键信息,再尝试对句子进行整体理解,最后慢慢过渡到对文段整体的理解,逐步提升被试寻找和提取文段关键信息的能力,最终提高其对文段内容的归纳能力。

表14 第46号被试的属性掌握情况

图4 第46号被试的技能掌握分布

表15 被试5和被试7的属性掌握情况

图5 被试5和被试7的属性掌握情况对比
[1]Bolt,D.&Fu,J.B.A polytomous extension of the fusion model and its Bayesian parameterestimation[C].Paper presented at NCME,San Diego,USA,2004.
[2]Buck,G.,&Tatsuoka,K.Investigation of the linguistic,cognitive and method attributes underlying test task performance:a pilot analysis using Rule Space Methodology[M].Language Testing Research Cloogquium,Long Beach,CA,1995.
[3]Buck,G.,Tatsuoka,K.&Kostin,I.Rule space analysis of a multiplechoice reading comprehension test.In Analysis of language test per-formance using a cognitivediagnosticapproach[C].Symposium con-ducted at the National Council on Measurement in Education Annu-al Conference,1996.
[4]Freedle,R.&Kostin,I.The prediction of SAT reading comprehen-sion item difficulty for expository prose passages(ETS Research Re-port RR 91-29)[D].1991.
[5]Henson,R.&Douglas,J.Test construction for cognitive diagnosis[J]. Applied Psychological Measurement,2005,29/4:262-277.
[6]Jang,E.E.A validity narrative:Effects of reading skill diagnosis on teaching and learning in the context of NG TOEFL[M].Unpublished doctoral dissertation,University of Illinois,Champaign.2005.
[7]Jeremy Harmer.The Practice of English Language Teaching[M]. New York:Longman Group Limited,1983:144-145.
[8]Lenon,舒运祥,译.外语测试理论与方法[M].北京:世界图书出版社,1999.
[9]Montero,D.&Monfils,L.&Wng,J.&Yen,W.&Julian,M.&Moody,M. Investigation of the application of cognitivediagnostic testing to a high school end of course examination[M].Presented paper at the Annual meeting of the National Council on Measrement in Educa-tion,Chicago,Illinois,2003.
[10]韩雪屏,张春林.阅读学与阅读教学[J].教育研究,1983(9).
[11]刘守立.阅读教学论[M].合肥:安徽教育出版社,1989.
[12]莫雷.小学六年级学生语文阅读能力结构的因素分析研究[J].心理科学通讯,1990(1).
[13]莫雷.初中三年级学生语文阅读能力结构的因素分析研究[J].心理学报,1990(1).
[14]莫雷.高中三年级学生语言阅读能力结构的因素分析研究[J].应用心理学,1990(1).
[15]莫雷.中小学生语文阅读能力结构的发展特点[J].心理学报,1992(4).
[16]武永明.阅读能力结构初探[J].语文教学通讯,1990(9).
[17]张志公.谈语文教学中的阅读问题[J].中学语文,1979(4).
[18]车芳芳.融合模型在初中代数认知诊断中的应用[D].华东师范大学硕士论文,2010.
[19]赵明晨.汉语作为第二语言的学习者汉字字形意识的诊断性研究[D].北京语言大学硕士论文,2014.
A Study of Cognitive Diagnostic Assessment Based on Fusion Model For Reading Comprehensive Test:A Case Study of CPT(Science and Engineering)
CHEN Luxin&WANG Jimin
Chinese Proficiency Test(CPT)is the new exam which is researched and developed by Chinese Examination and Education Survey Institute in Beijing Language and Culture University,and is used to understand language skill situation of preparatory student.It is the basic Chinese and the specialized Chinese as one to assessment the language ability of student.So,we adopt Fusion Model(FM)to do cognitive diagnostic studies to 532 sciences&engineering subjects’response on reading comprehension section of CPT in May,2014 in order to understand cognitive mode of preparatory student in reading comprehension skill and provide diagnostic evaluation for student&teacher.The study found that:Firstly,these subjects master“searching ability”,but non-master“translation ability”.Secondly,the subjects in different school have some different knowledge structure in reading comprehension.Thirdly,we suggest adjust and amend some items,for example,the item 93 is too difficult to the subjects,and the item 89,item91,item 94 are lacking some attributes in Q matrix.
Fusion Model;Preparatory Education;Reading Comprehension;Cognitive Diagnostic
G405
A
1005-8427(2016)02-0023-12
本研究得到国家社科基金青年项目(12CYY028)和教育部新世纪优秀人才支持计划(NCET-13-0690)的支持。
陈璐欣,女,北京语言大学汉语考试与教育测量研究所,硕士研究生(北京 100083)
王佶旻,女,北京语言大学汉语考试与教育测量研究所,所长,教授,博士生导师(北京 100083)
猜你喜欢
心理学报(2022年9期)2022-09-06
中国典型病例大全(2022年12期)2022-05-13
广东教学报·教育综合(2022年49期)2022-04-27
课堂内外·教师版(2022年3期)2022-04-25
课程教育研究(2021年44期)2021-04-13
环球时报(2020-09-25)2020-09-25
职业技术(2019年9期)2019-10-11
湖北函授大学学报(2019年4期)2019-06-04
体育时空(2017年5期)2017-06-17
课程教育研究·学法教法研究(2016年14期)2016-06-29
