
面向维吾尔语关键词检索的等宽切词算法和基于清浊音结构的切词算法实现与对比分析
2016-05-04 02:56木合塔尔沙地克布合力齐姑丽瓦斯力
中文信息学报 2016年2期
木合塔尔·沙地克,布合力齐姑丽·瓦斯力, 李 晓
(1. 新疆教育管理信息中心,新疆 乌鲁木齐 830049; 2. 新疆教育学院 数学学院,新疆 乌鲁木齐 830043; 3. 中国科学院 新疆理化技术研究所,新疆 乌鲁木齐 830011)
面向维吾尔语关键词检索的等宽切词算法和基于清浊音结构的切词算法实现与对比分析
木合塔尔·沙地克1,布合力齐姑丽·瓦斯力2, 李 晓3
(1. 新疆教育管理信息中心,新疆 乌鲁木齐 830049; 2. 新疆教育学院 数学学院,新疆 乌鲁木齐 830043; 3. 中国科学院 新疆理化技术研究所,新疆 乌鲁木齐 830011)
该文提出了面向维吾尔语关键词检索的两种切词算法,并给出MATLAB实现的算法代码及详细说明;在同等条件下对两种算法的切词效果和关键词识别效率进行对比分析;提出两种算法的优化方法和构想。
维吾尔语;敏感词检索;切词;广播新闻
1 引言
维吾尔语属于阿尔泰语突厥语族,其语言特点与汉语大不相同,因为维吾尔语是黏着语言,而汉语不是。现代维吾尔语有32个音素(每个音素用一个字母来表示),其中八个元音均为浊音,24个辅音中,14个音素为浊音,10个音素为清音[1]。我们在“维吾尔语广播新闻敏感词检索系统的研究”[2]中,对维吾尔语音素进行声学特征分析,提出面向维吾尔语敏感词检索的两种切词算法:等宽切词算法和基于维吾尔语单词清浊音结构的(不等宽)切词算法。这两种算法均可用于维吾尔语关键词检索。
等宽切词算法基本思想来源于分帧原理,即以敏感词长度(采样点)为词长,以帧长为词移,对广播新闻语音文件进行单词切分,如图1所示。
基于清浊音结构的切词算法基本原理是:根据敏感词清浊音结构,以敏感词音素数为词长,以音素为词移,对广播新闻语音文件进行单词切分,不符敏感词清浊音结构的语音段视为垃圾语音,如图2所示(图左:敏感词清浊音波形,图右:有效切词结果)。
本文分析所用的语音文件和敏感词均来自于新疆人民广播电台新疆新闻在线维吾尔语网站“新闻60分”节目的不同的语音段。语音文件内容为kiyin ot öchüriwilindi,其时长:1.366秒,采样点:10 931,频率: 8 000,位数: 16,单声道;敏感词内容为ot,其时长:0.15秒,采样点:1 201,其他参数与上面语音文件一致。算法词长:1 201,词移:200。

图1 等宽单词切分算法示意图
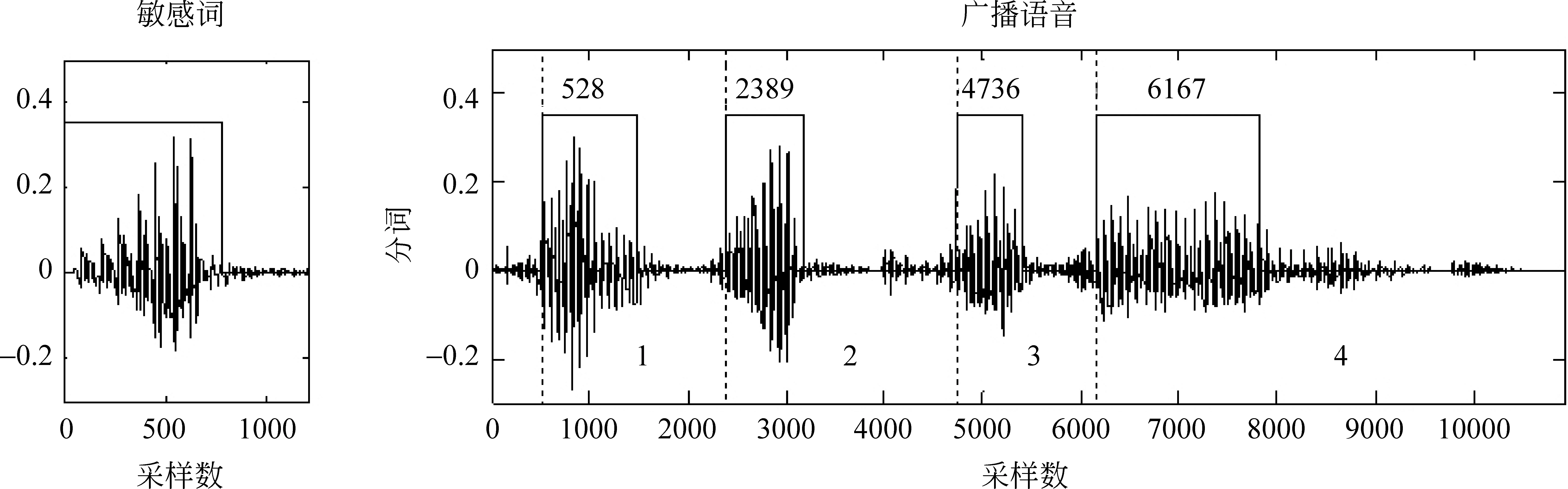
图2 基于清浊音结构的切词算法示意图
本文首先分别对两种算法切词结果进行分析,然后对两种算法关键词检索结果进行对比研究,最后提出优化思路。
2 等宽切词算法分析
等宽切词是用可移动的有限长度窗口进行加权的方法实现的,就是用一定的窗函数w(n)来乘s(n),从而形成加窗语音信号[3]。窗函数w(n)的选择(形状和长度),对语音识别的影响很大,为此应选择合适的窗,使其参数更好地反映语音信号的变化特性。设该加权方法用T[]表示,它可以是线性的或非线性的,可以是时不变的或者时变的,所有切词语音段经处理后便可以得到时间序列,用Qn表示[3],如式(1)所示。
(1)
本文用矩形窗来进行单词切分:

下面是等宽切词算法Matlab实现代码及详细说明[4-7]。
function dkseg(x,nt,deltaN);
%等宽切词算法
%x——广播新闻语音文件
%nt——关键词长度
%deltaN——词移
nx=length(x); % --- 取广播新闻语音长度
j=1;
for i=1:deltaN:nx % --- 切词
a=i; % --- 确定切词起始点
b=i+nt; % --- 确定切词终止点
if b>nx
b=nx;
end
seg=x(a:b); % --- 切词语音片段
filename=[′seg_′ int2str(j)]; % --- 保存名称
save(filename,′seg′,′-ASCII′, ′-double′); % --- 存储切词语音片段
test.case{j}=filename; % --- 结构数组中存放切词语音片段名称
test.begin{j}=int2str(a); % --- 结构数组中存放切词起始点信息
test.end{j}=int2str(b); % --- 结构数组中存放切词终止点信息
if b==nx
test.info=int2str(j);
break;
end
j=j+1;
end
save(′seg_test′,′test′); % --- 存储切词语音片段结构数组
该算法将语音文件等分重叠的50个单词,运行所用时间为0.12秒左右,图3是语音文件波形(第一行)和用等宽切词算法对语音文件进行切词的前八个单词的波形图(第二、三行)。

图3 等宽切词算法切词结果图(前八个单词)
图3中可以看到,第一个单词区间为1~1 200,第二单词区间为200~1 400,第三单词区间为400~1 600等,是连续重叠的等宽语音块。等宽切词算法切词数多,基本覆盖所有语音,提供足够的候选,提高正识率,反而会增加存储空间的开销并所需检索时间较长。
3 基于清浊音结构的切词算法分析
基于清浊音结构的切词算法是基于帧的统计,即是一组多元高斯分布X=[x1,x2,x3,x4,x5],其五个参数分别为x1:语音信号短时能量;x2:语音信号短时过零率;x3:单位采样延迟的短时自相关系数;x4:p阶线性预测的第一个预测系数;x5:p阶线性预测的预测误差归一化能量。X被称为特征向量,用于基于帧的清、浊音检测。五个参数是根据它们区分清、浊音的能力来确定的[8-10]。下面是基于清浊音的切词算法Matlab实现代码及详细说明[4-7]。
function vuseg(x, nt , m_mgcvu, N)
%基于清浊音的切词算法
%x——广播新闻语音文件
%nt——关键词长度
% m_mgcvu——关键词清浊音结构
%N——帧长
Sx=voiunvoi(x,N,0.1,0.3);
m_dian=[0];
m_lenSx=length(Sx);
for i=1:m_lenSx-1
if Sx(i) ~= Sx(i+1)
m_dian=[m_dian, i]; %转折终点下标
end
end
m_dian=[m_dian, m_lenSx]; %转折终点下标
m_phoneme=[];
m_lenDian=length(m_dian);
for i=2:m_lenDian
m_phoneme=[m_phoneme Sx(m_dian(i))];
end
if m_phoneme(1) == m_mgcvu(1)
m_start=1;
else
m_start=2;
end
delete(′seg_*.*′);
m_loop=0;
m_lenMgcvu=length(m_mgcvu);
m_lenPhoneme=length(m_phoneme);
m_lenPercent1=round(nt /2); %容错下线
m_lenPercent2=round(nt * 2); %容错上线
clear test;
for i=m_start:2:m_lenPhoneme
m_begin=m_dian(i)+1;
if i+m_lenMgcvu > m_lenDian
break;
else
m_end=m_dian(i+m_lenMgcvu);
end
%如果切词长度小于或大于关键词长度50%视为垃圾语音
if m_end - m_begin < m_lenPercent1 || m_end - m_begin > m_lenPercent2
continue;
end
m_loop=m_loop+1;
seg=x(m_begin:m_end);
filename=[′seg_′ int2str(m_loop)]; % --- 保存名称
save(filename,′seg′,′-ASCII′, ′-double′); % --- 存储切词语音片段
test.case{m_loop}=filename; % --- 结构数组中存放切词语音片段名称
test.begin{m_loop}=int2str(m_begin); % --- 结构数组中存放切词起始点信息
test.end{m_loop}=int2str(m_end); % --- 结构数组中存放切词终止点信息
end
test.info=int2str(m_loop);
save(′seg_test′,′test′); % --- 存储切词语音片段结构数组
该算法将语音文件分为三个有效单词(若不考虑敏感词清浊音结构和敏感词长度比例限制条件,可分为12个单词,其中九个单词清浊音结构不符要求或切词长度小于敏感词长度的50%,把它们视为垃圾语音),所用时间为0.016秒左右。图4是语音文件波形(第一行)和用基于清浊音结构的切词算法对语音文件进行切词的三个单词的波形图(第二行)。
图4中可以看到,第一个单词区间为502~2 409,第二单词区间为2 410~4 774,第三单词区间为6 153~10 931,是不连续、不重叠、不等宽的语音块。基于清浊音结构的切词算法切词数少,占用空间小,提高检索速度,但忽略的垃圾语音较多,可选的候选有限,反而提高误警率。
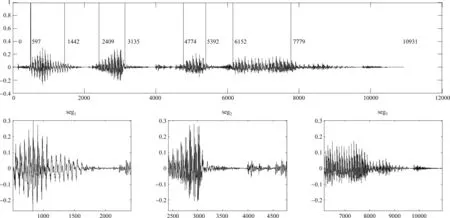
图4 基于清浊音结构的切词算法切词结果图
4 两个算法结果对比分析
从切词角度对比,基于清浊音结构的切词算法运行速度比等宽切词算法快7~8倍,切词数量小16~17倍。同等条件下两种算法切词结果对比,如表1所示。
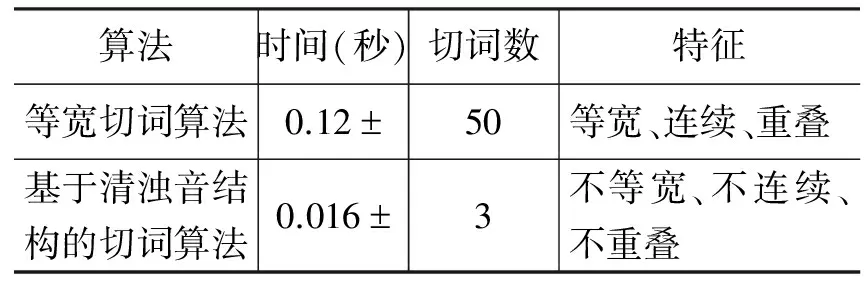
表1 同等条件下两种算法切词结果对比
从实际检索结果来看,等宽切词算法检索所用时间为6秒左右,基于清浊音结构的切词算法检索所用时间1秒多一点。等宽切词算法的正确率远远高于基于清浊音结构的切词算法,这也符合我们预先估计的结果。
5 结论
基于清浊音结构的切词算法的关键是关键词清浊音结构的确定。如果关键词清浊音组成结构均匀,即清浊音交替出现,其识别效率比等宽切词算法高;如果关键词清浊音组成结构不均匀,其正确率低于等宽切词算法。另外,在基于清浊音结构的切词算法中,我们把维吾尔语音素粗分清浊音两种,其实维吾尔语音素可分为:塞音、擦音、鼻音、边音、擅音等[1-2, 8]。如果算法充分考虑这些特征因素,将会提高算法识别效率。
用加窗函数对信号进行等宽切词实际上是用一个窗截取信号。本文等宽切词算法用的加窗函数为矩形窗。因两个信号的时域相乘,在频域相卷积,矩形窗频谱高频成分将影响语音信号的高频部分[3]。一般在语音识别的前端处理中,用高频分量幅度较小的窗形,以避免这些影响。如汉明(Hamming)窗的带宽是矩形窗的两倍,但带外衰减却比矩形窗大得多。根据切词处理的要求,以不影响或减少影响处理需要的语音特性为标准来选择窗形较为适宜。如果我们选用汉明窗来进行单词切分,也许会提高算法效率。
[1] 哈力克·尼亚孜. 基础维吾尔语[M], 新疆大学出版社.
[2] 木合塔尔·沙地克. 维吾尔语广播新闻敏感词检索系统的研究[D].中国科学院大学:新疆理化技术研究所, 2013.
[3] 王炳锡,屈丹,彭煊等.实用语音识别基础.北京:国防工业出版社,2005.
[4] Thierry Dutoit , Ferran Marqu'es. Applied Signal Processing A MATLABTM Based Proof of Concept[M]. Springer Science Business Media, LLC 2009.
[5] 张雪英, 数字语音处理及MATLAB仿真[M], 电子工业出版社, 2010.
[6] Brian Hahn, Dan Valentine. Essential Matlab For Engineers and Scientists[M]. Academic Press, 2010.
[7] 史峰,郑森,陈冰等. MATLAB函数速查手册[M]. 中国铁道出版社, 2011.
[8] 木合塔尔·沙地克, 布合力齐姑丽·瓦斯力, 李晓. 基于维吾尔语单词清、浊音组成结构特征的连续语音单词切分算法[J]. 西北师范大学学报(自然科学版), 已录用.
[9] John R Deller, Jr., John H L. Hansen, John G Proakis. Discrete-Time Processing of Speech Signals[M]. IEEE Press, NY 2000.
[10] Lawrence R Rabiner, Ronald W Schafer. Theory and Applications of Digital Speech Processing[M]. Publishing House of Electronics Industry, 2011.
Implementation and Comparative Analyses of Mono-space Based and Voiced/Unvoiced Phoneme Based Word Segmentation of Uyghur for Keyword Search
Muhetaer Shadike1, Buheliqiguli Wasili2, LI Xiao3
(1. Xinjiang Education Management Information Center, Urumchi, Xinjiang 830049, China; 2. Xinjiang Education Institute, Urumchi,Xinjiang 830043,China; 3. Xinjiang Institute of Physics & Chemistry CAS, Urumchi, Xinjiang 830011, China)
In this paper we introduce two word segmentation methods for Uyghur key word search. They are realized in MATLAB code, and their performances are investigated on the same condition. At last gives some idea for optimizations.
Uyghur; sensitive word spotting; word segmentation; broadcast news

木合塔尔·沙地克(1973—),博士,主要研究领域为多语种文字语音识别技术。E⁃mail:muhtar_xjedu@163.com布合力齐姑丽·瓦斯力(1981—),硕士,主要研究领域为概率论与数理统计、数学模型等。E⁃mail:2397300750@qq.com李晓(1957—),研究员,博士生导师,主要研究领域为民族语言文字信息处理和识别。E⁃mail:xiaoli@ms.xjb.ac.cn
1003-0077(2016)02-0207-06
2013-10-17 定稿日期: 2014-04-10
新疆自治区高校科研计划项目(XJEDU2012S46);新疆多语种信息技术重点实验室项目(049807)
TP391
A
猜你喜欢
中国民族博览(2019年10期)2019-11-29
科学与财富(2019年27期)2019-10-25
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
自动化学报(2017年4期)2017-06-15
专利代理(2016年1期)2016-05-17
